测试学习记录,仅供参考!
Requests 模块
Python requests库是一个常用的 Python HTTP客户端请求库,是一个简单易用、功能强大的库,特别适合用来与 RESTful API 进行交互,用于发送各种HTTP请求,如GET、POST、PUT、DELETE等,并处理返回的响应。使用 requests 库,开发者可以轻松地添加头部信息、发送表单数据、上传文件、管理会话、处理 Cookies 、使用代理等;它还可以支持 SSL 证书验证、连接超时设置、会话对象复用等高级功能。
|--------|---|---|
| 测试网址 | http://httpbin.org/ ||
| 测试网址 | https://httpbin.org/ ||
| 开源项目地址 | https://github.com/Runscope/httpbin ||
|  |||
|||
httpbin 是一个使用 Python + Flask 编写的 HTTP HTTP Request & Response Service,是一个开源项目,主要用于测试 HTTP 库;可以向它发送请求,然后它会按照指定的规则进行请求返回;httpbin.org 可以测试 HTTP 请求和响应的各种信息,比如 cookie、ip、headers 和登录验证等,且支持 GET、POST 等多种方法,对 web 开发和测试很有帮助;httpbin支持HTTP/HTTPS,支持所有的HTTP动词,能模拟302跳转乃至302跳转的次数,还可以返回一个HTML文件或一个XML文件或一个图片文件(还支持指定返回图片的格式)。
|-----------------------|---|---|
| 常用接口地址 |||
| get请求网址 | https://httpbin.org/get ||
| post请求网址 | https://httpbin.org/post ||
| put请求网址 | https://httpbin.org/put ||
| patch请求网址 | https://httpbin.org/patch ||
| delete请求网址 | https://httpbin.org/delete ||
| 返回headers信息 | https://httpbin.org/headers ||
| 返回访问此链接的IP(httpbin)地址 | https://httpbin.org/ip ||
| 返回USER-AGENT信息 | https://httpbin.org/user-agent ||
四、测试练习
GET 请求
GET 请求,HTTP 默认的请求方法就是GET 请求方法;
- 没有请求体;
- 数据必须在 1K 之内;
- GET 请求数据会暴露在浏览器的地址栏中;
GET 请求常用的操作:
- 在浏览器的地址栏中直接给出URL,那么就一定是 GET 请求;
- 点击页面上的超链接也一定是 GET 请求;
- 提交表单时,表单默认使用 GET 请求,但可以设置为 POST;
用途:GET 方法主要用于从服务器请求数据。可用于读取操作,并且结果会被显示给用户,如浏览网页。
参数传递:GET 方法的参数通过 URL 传递,通常以键值对的形式附加在 URL 之后。例如:http://example.com/index.php?name=value\&anothername=value2。
安全性:由于 GET 请求的参数在 URL 中可见,因此不适合传输敏感信息,如密码或个人信息。
缓存:GET 请求的结果可以被浏览器缓存,也可以被书签保存。
数据量限制:GET 方法由于参数在 URL 中传递,因此对传输的数据量有限制(URL 长度限制)。
基本语法
# 导入请求库
import requests
# 发送GET请求
r = requests.get('http://httpbin.org/get')
# 打印响应内容
print(r.text)r: 是一个Response对象,一个包含服务器资源的对象;
get(url): 是一个Requests对象,构造一个向服务器请求资源的Requests;
先导入请求库,然后构建简单的get请求方法,设置请求目标网址,最后输出响应信息的一个简单流程。
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate, br",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.32.3",
"X-Amzn-Trace-Id": "Root=1-66bb30c2-51bb647253f6ec0336be35a0"
},
"origin": "183.156.54.185",
"url": "http://httpbin.org/get"
}
进程已结束,退出代码为 0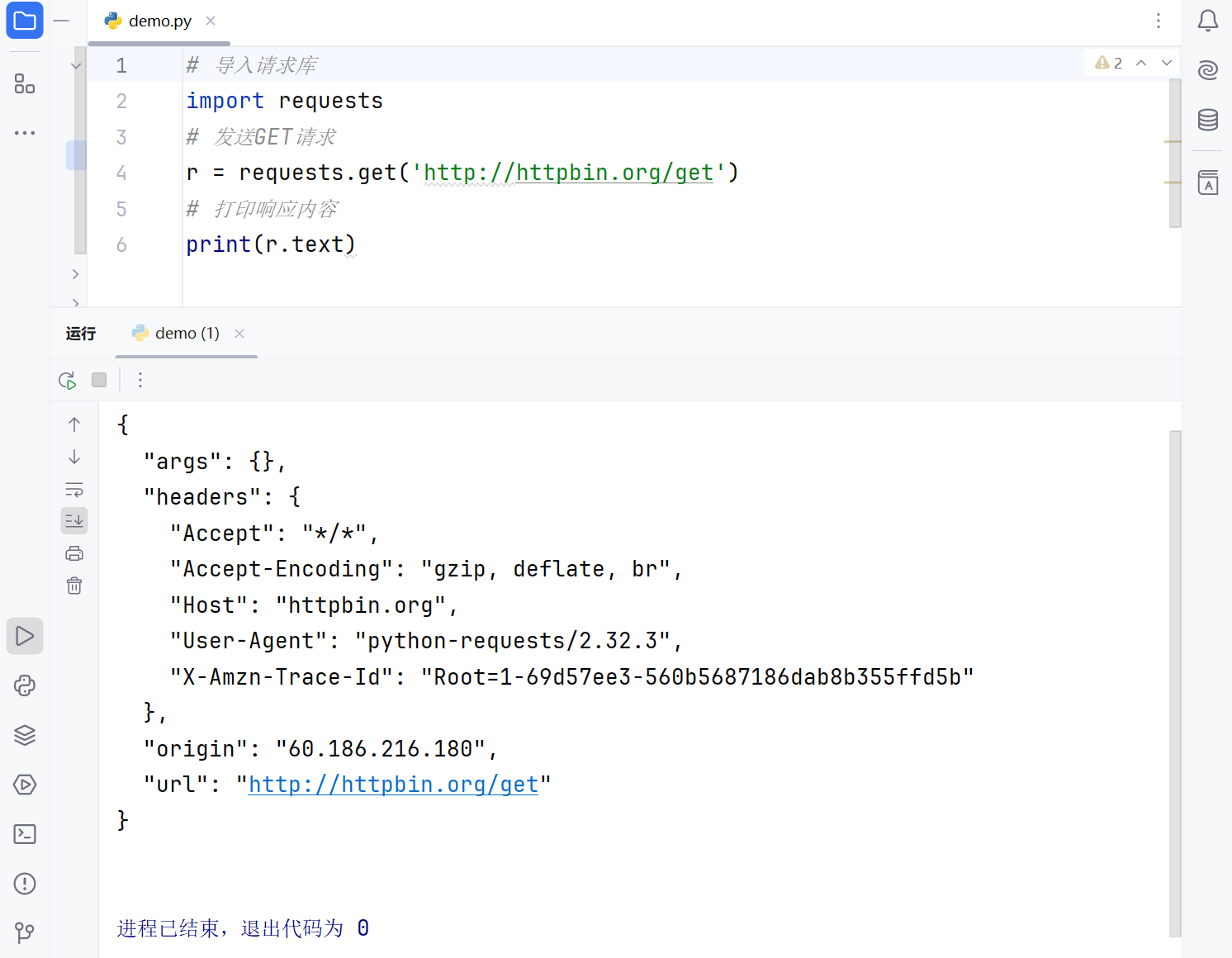
成功发送get请求,返回结果包含有请求头,URL,IP等信息。
下面解释各行代码意思,了解代码的意图;
{
"args": {}, #空值,表示在GET请求中没有包含任何查询字符串参数。
#请求头headers包含的列出内容
"headers": {
"Accept": "*/*", #指示客户端可以处理的MIME类型
"Accept-Encoding": "gzip, deflate", #指示客户端可以接受的内容编码格式
"Host": "httpbin.org", #指示服务器正在访问的主机名
"User-Agent": "python-requests/2.31.0", #包含了发出请求的用户代理的信息
"X-Amzn-Trace-Id": "Root=1-661cb1d9-5734386062c81b176d2d6f2b" #用于AWS X-Ray跟踪的请求ID
},
"origin": "112.224.144.133", #表示发出请求的客户端的IP地址
"url": "http://httpbin.org/get" #表示请求的URL
}使用带参数的get请求和传递参数
http://example.com/resource?param1=value1¶m2=value2¶m3=value3- http://example.com/resource 是资源的URL;
- param1=value1¶m2=value2¶m3=value3 是查询字符串,包含了三个参数;
- param1, param2, param3 是参数的名称(键);
- value1, value2, value3 是与参数名称相对应的值;
对于GET的请求,如若想要添加多余的信息,一般需要在URL后面拼接,用一个【 ?】分割,参数传递过来后再使用【 & 】的符号分割即可;例如若想要添加两个参数,其中"name是China,age是5000",然后来构造这个请求连接;
r = requests.get('http://httpbin.org/get?name=China&age=5000')这行代码构造完毕,接下来再使用 params这个用来传递参数,方便添加代码,简洁了然;
提醒:构造好的代码理论上可以直接执行,但是一般情况下,此信息数据会用字典来存储。
import requests
# 设置参数
data = {
'name':'China',
'age':5000
}
# url拼接
r = requests.get('http://httpbin.org/get',params=data)
print(r.text)
{
"args": {
"age": "5000",
"name": "China"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate, br",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.32.3",
"X-Amzn-Trace-Id": "Root=1-66bb3347-2beb2bb0202bad3a760059c1"
},
"origin": "183.156.54.185",
"url": "http://httpbin.org/get?name=China&age=5000"
}
进程已结束,退出代码为 0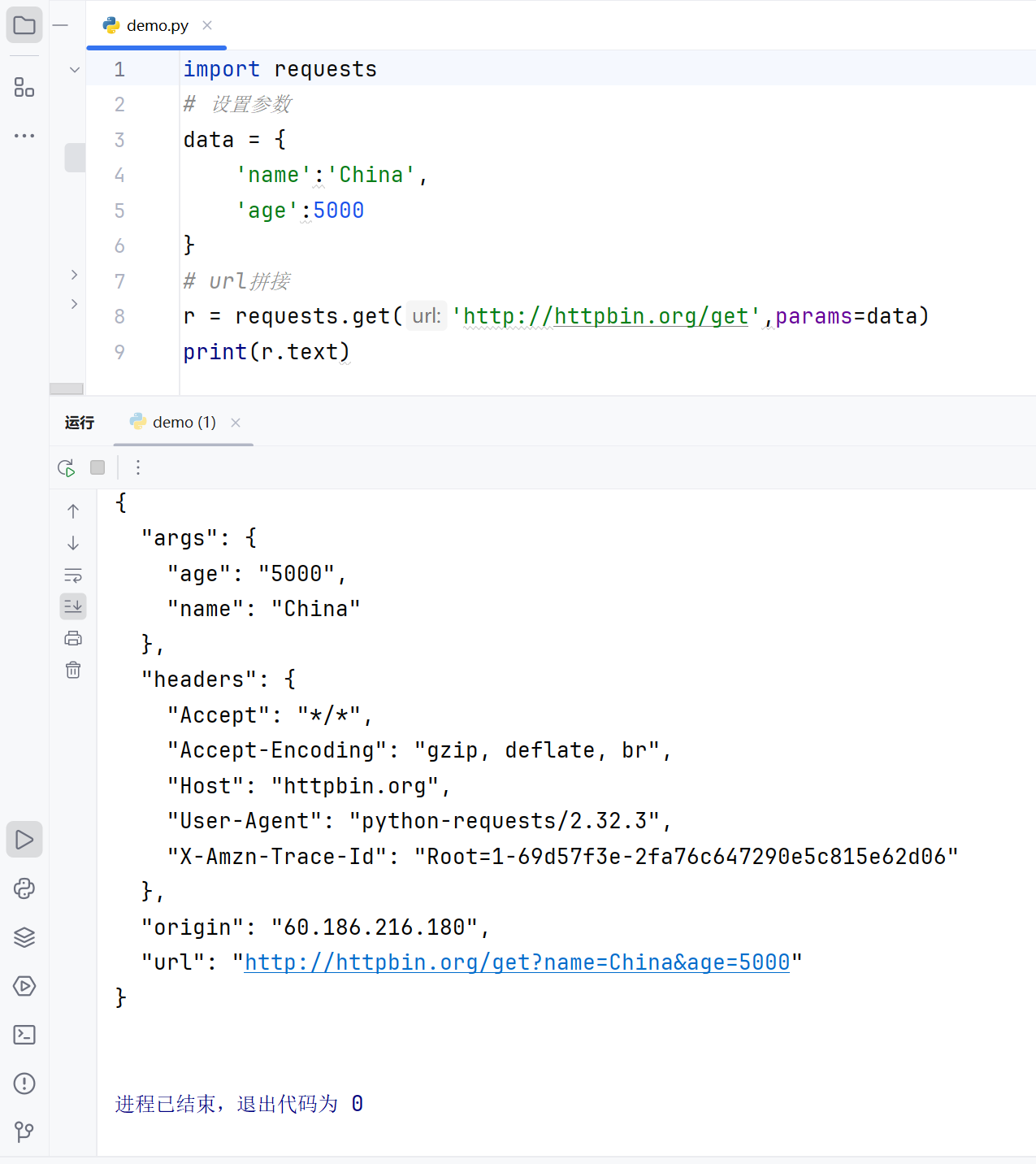
带参数的GET请求->params
# 百度搜索"软件测试"
url = 'https://www.baidu.com/s?wd=软件测试&pn=1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36'}
import requests
response = requests.get(url=url, headers=headers)
print(response.text)
# 如果查询关键词是中文或者有其他特殊符号,则不得不进行url编码
from urllib.parse import urlencode
wd = '软件测试'
encode_res = urlencode({'k': wd}, encoding='utf-8')
keyword = encode_res.split('=')[1]
print(keyword)
# 然后拼接成url
url = 'https://www.baidu.com/s?wd=%s&pn=1' % keyword
response = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36'})
res1 = response.text
省略。。。--(烦请自行查看)带参数的GET请求->headers
url = 'https://www.baidu.com/s?wd=软件测试&pn=1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36'}
# 通常我们在发送请求时都需要带上请求头,请求头是将自身伪装成浏览器的关键,常见的有用的请求头如下
import requests
response = requests.get('https://www.zhihu.com/explore')
response.status_code # 500
# 自己定制headers
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36',
}
respone = requests.get('https://www.zhihu.com/explore', headers=headers)
print(respone.status_code)
# 输出结果
200
进程已结束,退出代码为 0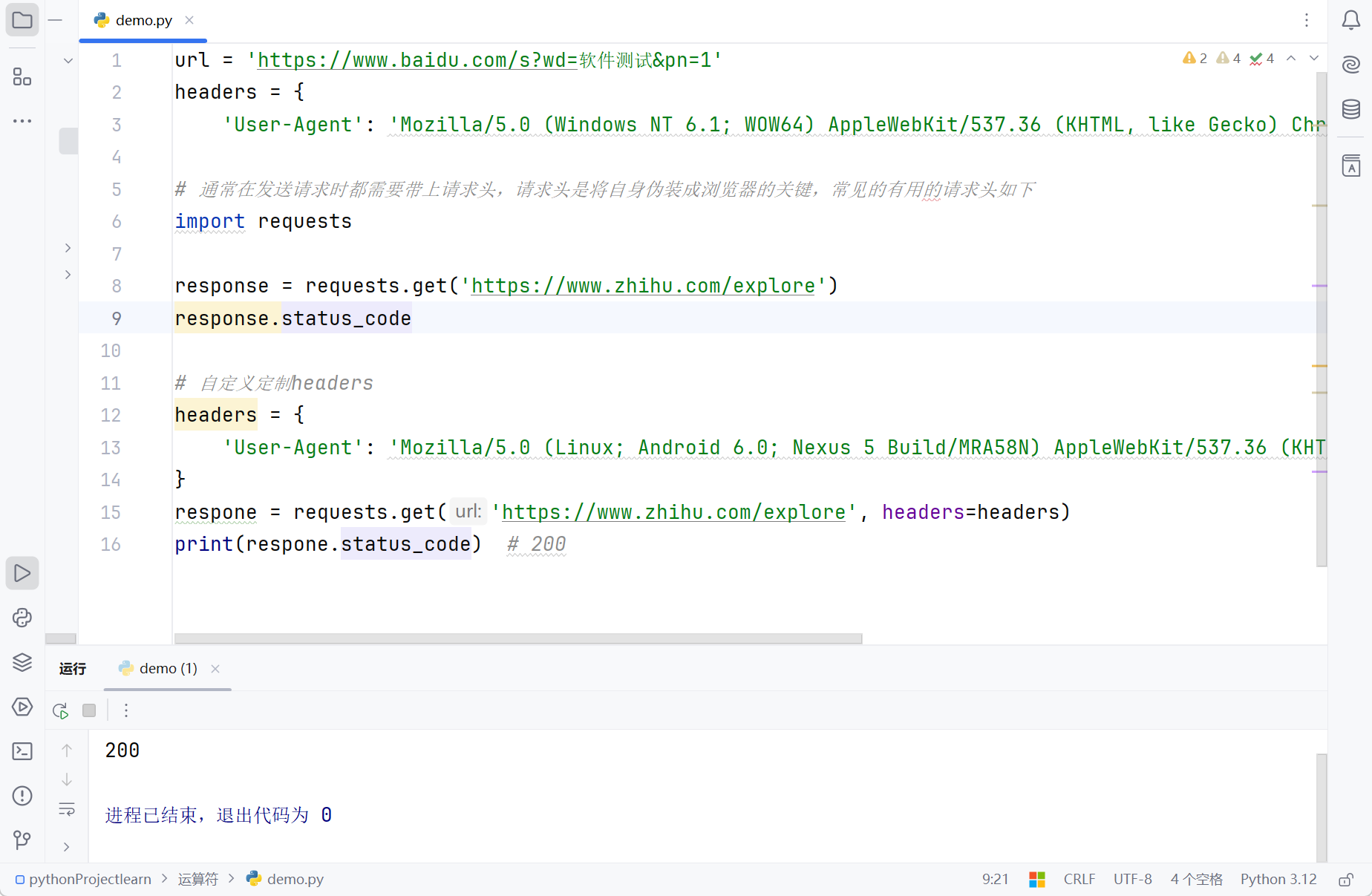
带参数的GET请求->cookies
因为用户名、密码,cookies --提供的均是模拟数据,所以结果是假的-false →仅供参考,建议使用真实数据信息;
#登录github,然后从浏览器中获取cookies,以后就可以直接拿着cookie登录了,无需输入用户名密码
#用户名:admin 邮箱123456@qq.com 密码123456
import requests
Cookies={'user_session':'wGMHFJKgDcmRIVvcA14_Wrt_3xaUyJNsBnPbYzEL6L0bHcfc',
}
response=requests.get('https://github.com/settings/emails',cookies=Cookies)
print('123456@qq.com' in response.text) #True
# 输出结果
False
进程已结束,退出代码为 0源码分析:requests 请求调用的是 session 请求,session 和 requests 请求的区别在于,Session 可以自动管理 cookie,而 requests 在需要 cookie 认证时,请求需要携带 cookies 参数。
POST 请求
requests.post() 用法与 requests.get() 完全一致,特殊的是 requests.post() 有一个 data 参数,用来存放请求体数据。
POST 请求
- 数据不会出现在地址栏中;
- 数据的大小没有上限;
- 有请求体;
- 请求体中如果存在中文,会使用URL编码;
用途:POST 方法主要用于向服务器提交数据,以创建或更新资源。可用于产生副作用的操作,如表单提交。
参数传递:POST 方法的参数在请求体中传递,不会显示在 URL 中。这使得 POST 方法可以传输更大量的数据。
安全性:POST 方法相对 GET 方法来说更安全,因为参数不会在 URL中 暴露。
缓存:POST 请求的结果通常不会被浏览器缓存,也不能被书签保存。
数据量限制:POST 方法没有数据量限制,理论上可以传输更大量的数据,但实际上可能受到服务器配置或HTTP 库的限制。
基本语法
# 导入请求库
import requests
# 发送请求
r = requests.post('http://www.httpbin.org/post', data={'username': 'China', 'password': 5000})
# text 接收返回内容
print(r.text)post方法用于提交数据,跟get方法不同;
{
"args": {},
"data": "",
"files": {},
"form": {
"password": "5000",
"username": "China"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate, br",
"Content-Length": "28",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "www.httpbin.org",
"User-Agent": "python-requests/2.32.3",
"X-Amzn-Trace-Id": "Root=1-66bb3493-3e096d9d551ab3cc660a66d5"
},
"json": null,
"origin": "183.156.54.185",
"url": "http://www.httpbin.org/post"
}
进程已结束,退出代码为 0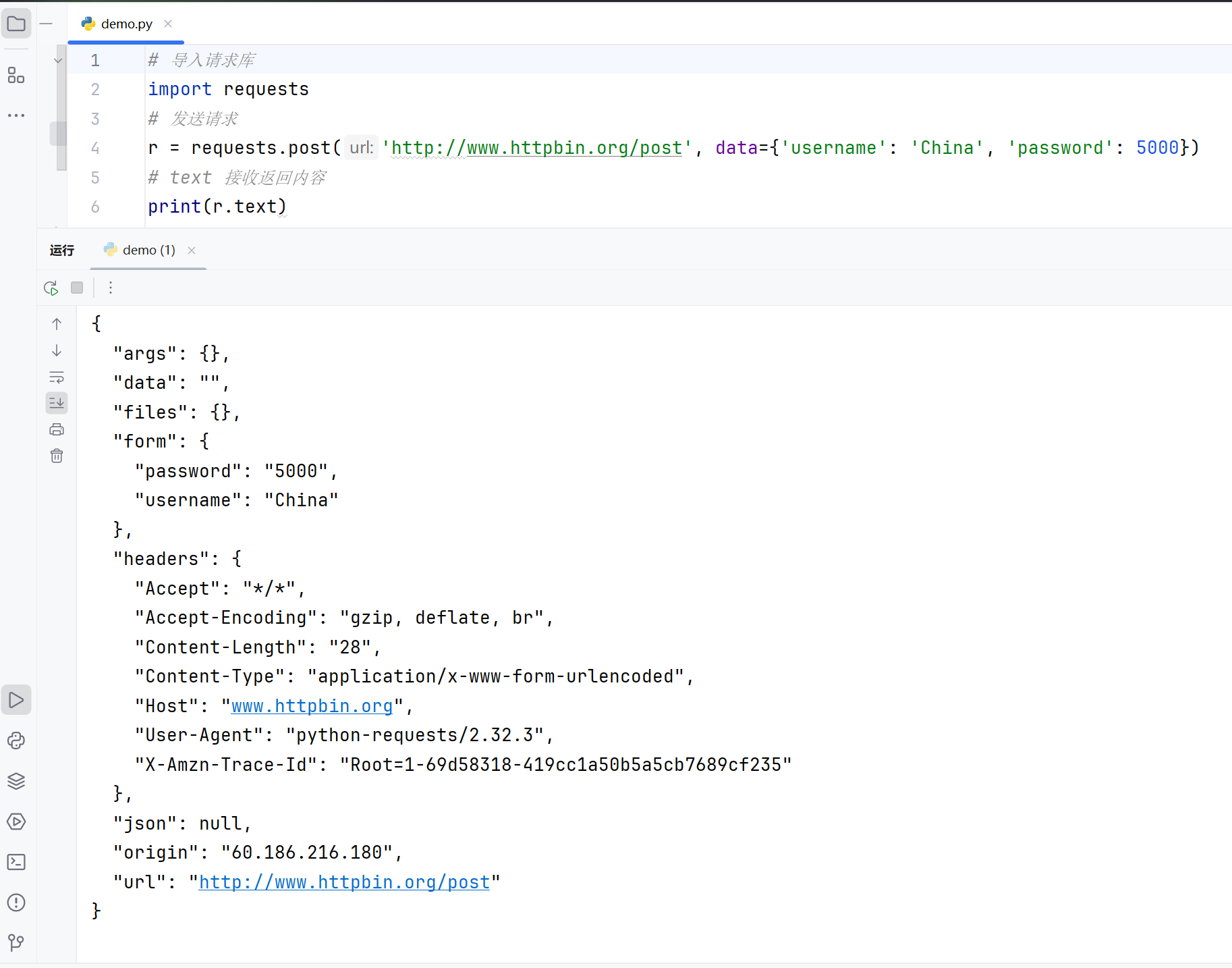
r作为变量名代表"response"的缩写,这是一个广泛接受的做法,用于表示HTTP请求的响应对象;当然,也可以使用其他变量名,如response、res等。
# post请求方式以及请求路径和协议版本
POST /path/to/resource HTTP/1.1
# 指定IP地址
Host: www.example.com
# 请求体的类型
Content-Type: application/x-www-form-urlencoded
# 请求体的长度
Content-Length: [length]
# 请求体的内容
[key1=value1&key2=value2] 这个 post 请求参数的语法格式一般不需要太重视(按实际需要),因为这是基于 HTTP 协议的原始请求格式,无需手动构造请求函数,高级的 HTTP 客户端库(如 Python 的requests库)会帮助处理这些细节。
解析json
# 解析json
import requests
import json
response = requests.get('http://httpbin.org/get')
# 方法一,略微复杂
res1 = json.loads(response.text)
# 方法二,直接获取json数据
res2 = response.json()
# True
print(res1 == res2)
# 输出结果
True
进程已结束,退出代码为 0response.json() 得到对应的 json 格式的数据,类似于字典;
requests.exceptions获取异常类型
import requests
# 可以查看requests.exceptions获取异常类型
from requests.exceptions import *
try:
r = requests.get('http://www.baidu.com', timeout=0.00001)
except ReadTimeout:
print("随机打印的except ReadTimeout是'++++++:'")
# except ConnectionError: #网络不通
# print('------')
# except Timeout:
# print('123456')
except RequestException:
print("随机打印的except RequestException是'Error'")未完待续。。。