一句话总结
来自 Hugging Face 团队的系统实验:用 1.7B 小模型生成 486B token,效果碾压已有方案,成本降低 30 倍
- 论文标题:How Can We Synthesize High-Quality Pretraining Data?
- 论文地址 :https://arxiv.org/pdf/2604.13977
- 作者背景:Hugging Face
- 代码地址 :https://github.com/huggingface/finephrase
- 开源数据集 :https://huggingface.co/datasets/HuggingFaceFW/finephrase
大模型预训练正在经历一场数据革命。从早期精心策划的 Wikipedia、BookCorpus,到大规模网络爬取的 C4、FineWeb,再到如今的合成数据时代 ------ 可爬取的互联网文本正在逼近天花板,而模型对高质量训练数据的需求却有增无减。"用 AI 改写网页文本"成了当下的热门解法:Nemotron-CC 改写了 2 万亿 token,Phi-4 和 Qwen3 等新一代模型都在预训练中大量使用了合成数据
但一个关键问题始终悬而未决:合成数据的设计空间如此庞大,到底该怎么选?用什么提示词改写?用多大的模型?源数据的质量重不重要?
Hugging Face 团队最近的一项工作给出了迄今最系统的回答。他们生成了超过 1 万亿 token 的合成数据,沿着三个维度做了严格的控制实验,得出了几条颇为颠覆直觉的结论。
实验设计
研究者将合成数据的设计空间拆成了三个正交维度,分别做控制变量实验:
- 改写策略:用什么样的 prompt 把原始网页文本转化成合成数据
- 生成器模型:用多大的模型来做改写
- 数据源:原始数据的质量是否重要,是否需要混合数据集
发现一:结构化教学格式碾压传统改写
研究者提出了四种"结构化教学格式":math(数学应用题)、faq(常见问答)、table(结构化表格)、tutorial(分步教程),并和已有的八种改写策略做了对比(构造语料训练 Qwen2 模型,在 12 个基准上评估性能)


结果泾渭分明。已有方案中只有 Diverse QA Pairs 能明显超过 DCLM 基线(14.58 v.s. 13.77),其余改写方式(摘要、蒸馏、知识提取等)大多没什么帮助
而四种结构化格式全部大幅领先:
| 格式 | 宏平均分 | 相比 DCLM |
|---|---|---|
| math | 15.31 | +1.54 |
| table | 14.83 | +1.06 |
| faq | 14.45 | +0.68 |
| tutorial | 14.30 | +0.53 |
math 和 table 甚至超过了此前最优的 Diverse QA Pairs。这说明把散乱的网页文本重新组织成结构化信号,比单纯的润色改写更有价值
发现二:1B 模型就够了,大模型反而更贵但不更好
接下来是一个有点让人意外的结论
研究者用 Gemma 3 家族(从 270M 到 27B)测试了模型规模对合成数据质量的影响。结果是:1B 模型(15.31)的效果优于 27B 模型(14.76)。性能在 1B 处就已经饱和,继续增大模型不仅没有收益,反而有所下降
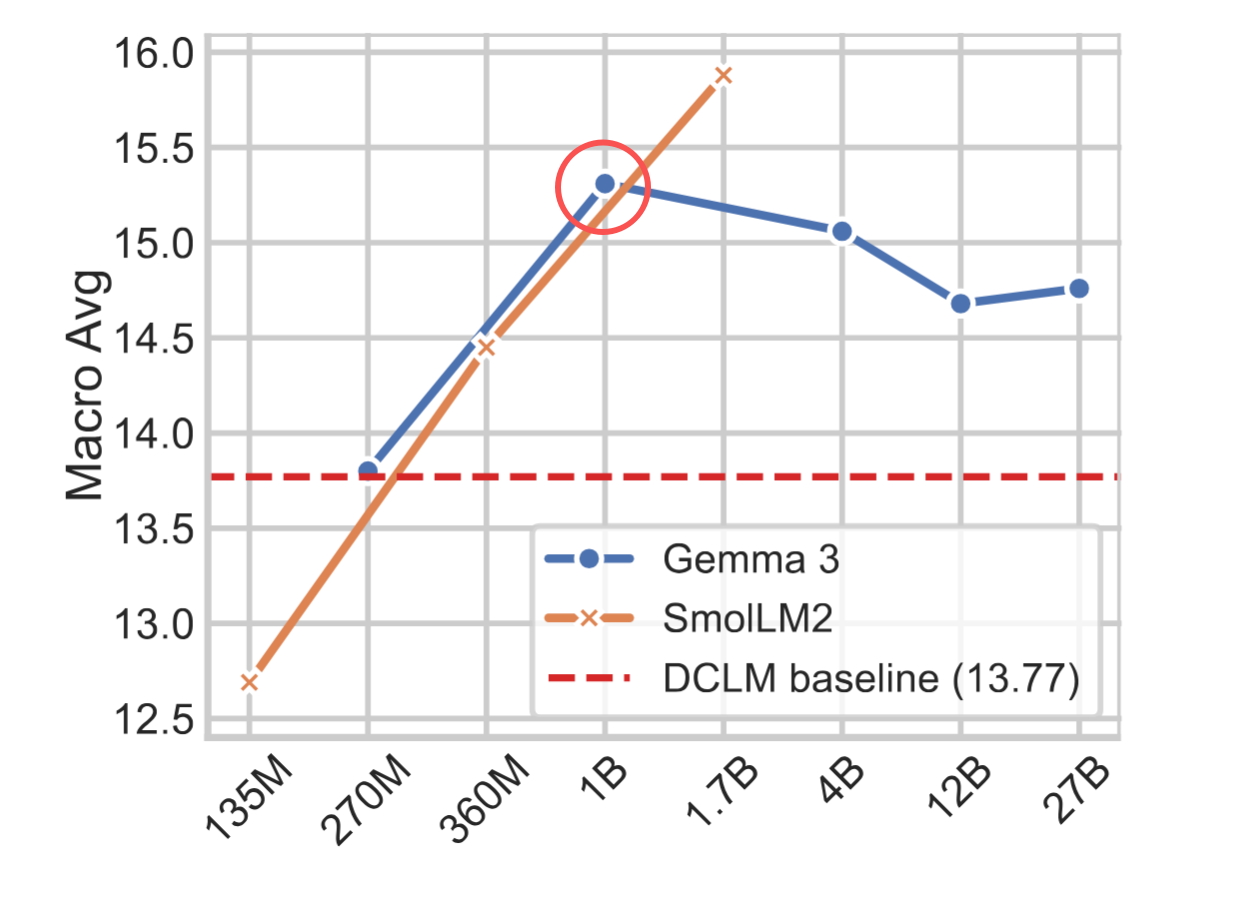
唯一的例外是 REWIRE 的 Guided Rewrite------这个 prompt 包含复杂的多步推理和角色扮演指令,确实需要稍大一些的模型(4B 优于 1B)。但对于结构化教学格式来说,1B 完全够用。
发现三:多样性胜过一致性
在模型家族对比中,SmolLM2 1.7B 以 16.55 的宏平均分大幅领先其他五个家族(优势从 1 到 2 分不等)。这个相对小众的模型为什么能脱颖而出?
研究者深挖了背后的原因,发现了一个名为"模板坍塌"(Template Collapse)的现象:
对比 SmolLM2 和 Qwen 3 在 math prompt 下的输出------Qwen 3 的指令遵循率是 100%,每个输出格式完美。但 115 个输出以完全相同的文本开头,长度也集中在很窄的区间。SmolLM2 虽然只有 68% 的格式完整率,但最常见的开头模式只出现了 3 次,长度从 4 到 4000 token 不等。
结果恰恰是"不那么听话"的 SmolLM2 训练效果更好。
原因在于 Qwen 3"太一致了"------大量重复的模式稀释了训练信号,模型本质上在反复学习近乎相同的文本。而 SmolLM2 的输出多样性保留了丰富的结构变化,给模型提供了更多有价值的学习信号
发现四:精心挑选混合数据
合成数据能完全替代原始网页数据吗?答案是不能。
纯合成数据训练不如混合训练。将合成数据与原始 web 数据按 50/50 混合后,所有格式的性能都有提升,其中 tutorial 提升了将近 2 分。原因是合成数据无法提供自然文本中丰富的语言多样性,像常识推理(HellaSwag、PIQA)这类能力会明显下降
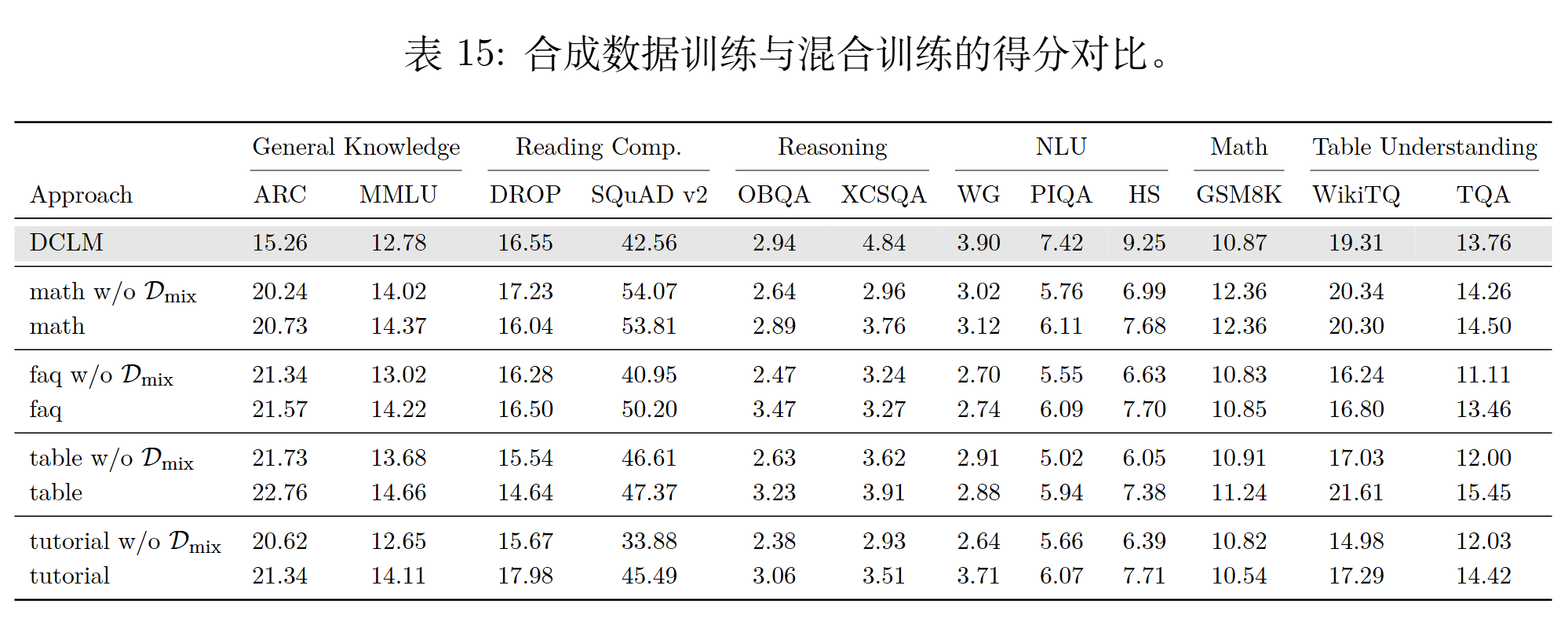
更有价值的发现是:用于混合的 web 数据(mix-in)的质量,比被改写的源数据(source)的质量更关键。 当 mix-in 固定为高质量时,即使用低质量数据作为改写源,性能差距也从 4.67 分压缩到了 1.78 分
这意味着改写管线可以成功"回收"低质量网页文本------只要搭配高质量的 mix-in 数据一起训练,垃圾数据也能被洗成有效的训练 token,相当于大幅扩展了可用数据的储备池
FinePhrase:486B Token 的实践验证
基于以上所有发现,研究者构建了 FinePhrase 数据集:
- 生成器:SmolLM2 1.7B
- 格式:math + faq + table + tutorial 四种结构化教学格式
- 规模:13.5 亿样本,486B completion token
- 效率:100 张 H100 + suffix-32 投机解码,每 GPU 约 9200 tok/s
- 成本:约 14,700 GPU 小时,比 REWIRE(Llama 70B)便宜 30 倍,比 Cosmopedia(Mixtral 8x7B)便宜 13 倍
| 方案 | 生成器 | 生成量 | GPU 小时 | tok/GPU-hr |
|---|---|---|---|---|
| Cosmopedia | Mixtral 8x7B | 25B | >10K | <2.5M |
| REWIRE | Llama 3.3 70B | 400B | ~352K | ~1.1M |
| FinePhrase | SmolLM2 1.7B | 486B | ~14.7K | ~33.1M |
FinePhrase-Table 达到了 17.18 的最高宏平均分,比 DCLM 基线高 3.41 分,比 Nemotron-HQ-Synth 高 3.63 分。不过也存在权衡:结构化格式在事实知识和阅读理解上大幅领先,但在 HellaSwag 等常识推理任务上略逊,这也再次印证了原始 web 数据作为 mix-in 的不可替代性