一、MinerU2.5-pro
整体结构总览
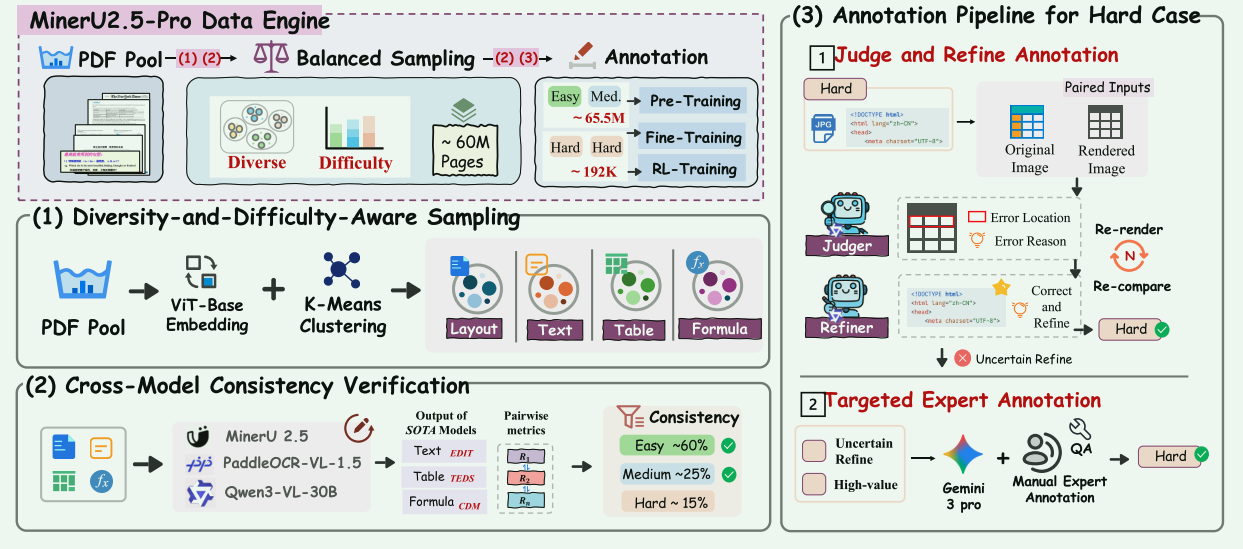
这张图完整展示了 MinerU2.5-Pro 用来打造训练数据的"数据引擎"流水线,核心分为三大阶段:
- 多样性+难度感知采样(DDAS):从海量PDF中筛选出多样、均衡的候选数据
- 跨模型一致性校验(CMCV):自动给数据打"Easy/Medium/Hard"难度标签
- 难样本标注流水线 :对Hard样本进行高精度修正与人工标注
最终产出分层数据,分别用于预训练、微调、强化学习三个阶段。
1. 多样性+难度感知采样(DDAS)
核心目标:解决「数据分布不均、难场景缺失」的问题
流程拆解:
- 输入:PDF Pool(海量PDF池)
所有待处理的原始PDF文件。 - ViT-Base Embedding
把PDF页面转成向量特征,相当于给每个页面拍了一张"特征身份证",方便后续聚类。 - K-Means Clustering
用K-Means算法把页面按特征分成不同簇,按Layout(版面)、Text(文本)、Table(表格)、Formula(公式) 四个维度分别聚类。
这一步的作用是:把"长得像"的页面分到一起,保证最终数据覆盖所有版面类型(比如单栏、双栏、多栏、密集表格、复杂公式等),避免数据单一。
2. 跨模型一致性校验(CMCV)
核心目标:自动给数据打难度标签,零成本判断"难不难"
流程拆解:
- 输入:上一步聚类后的样本
每个页面的文本、表格、公式内容。 - 多模型推理
同时用三个不同架构的模型处理这些样本:- MinerU2.5(目标模型,要提升的那个)
- PaddleOCR-VL-1.5(OCR专用模型)
- Qwen3-VL-30B(通用多模态大模型)
- 成对一致性校验(Pairwise metrics)
对不同类型的内容,用专门的指标判断输出是否一致:- 文本:EDIT(编辑距离)
- 表格:TEDS(表格相似度指标)
- 公式:CDM(公式匹配度)
- 难度分级(Consistency)
根据三个模型的输出一致性,自动分成三档:- Easy(约60%):目标模型和至少一个外部模型结果一致,标注可信
- Medium(约25%):两个外部模型结果一致,但目标模型不一致,是目标模型的短板
- Hard(约15%):三个模型结果全不一致,属于"谁都搞不定"的难题,需要后续精修
3. 难样本标注流水线(Annotation Pipeline for Hard Case)
核心目标:把"谁都搞不定"的Hard样本,变成高质量标注数据
分为两步,层层兜底:
① Judge and Refine Annotation(自动判断+修正)
这是整个流程的"黑科技":
- 输入:Hard样本(原图 + 模型生成的结构化标注)
比如一张带表格的图片,和模型生成的HTML表格代码。 - 生成配对输入(Paired Inputs)
把模型生成的标注(如HTML表格、LaTeX公式)重新渲染成图片,得到"原图"和"渲染图"两张图。 - Judger(裁判模型)
用大模型(如Gemini)对比原图和渲染图,找出标注错误的位置和原因。 - Refiner(修正模型)
根据裁判的反馈,修正标注内容,再重新渲染、对比,直到修正成功。
这一步能修复绝大多数模型标注错误,解决"模型能生成结构,但不知道结构对不对"的问题。 - 分支 :
- 修正成功 → 得到高质量Hard标注数据
- 修正失败 → 进入下一步人工兜底
② Targeted Expert Annotation(专家人工标注)
针对自动修正也搞不定的样本:
- 用Gemini 3 Pro先做一轮辅助处理,降低人工成本
- 再由人工专家进行标注和QA校验
- 最终得到100%准确的Hard样本标注(约19.2万条)
最终数据产出 & 用途
整个流水线跑完,会产出三层数据,分别对应不同训练阶段:
| 数据类型 | 数量 | 用途 |
|---|---|---|
| Easy + Medium | ~65.5M | 大规模预训练,打基础 |
| Hard(自动修正) | 大量 | 微调阶段,针对性解决短板 |
| Hard(人工精标) | ~192K | 强化学习(RL)阶段,对齐评测指标 |
一句话总结这张图
MinerU2.5-Pro 的 Data Engine,就是一套全自动、分层级的高质量训练数据生产流水线 :
先用聚类保证数据多样性,再用多模型一致性自动分级难度,最后用"渲染对比+人工兜底"解决难样本标注问题,最终给模型提供了"广、全、准、难"的训练数据。
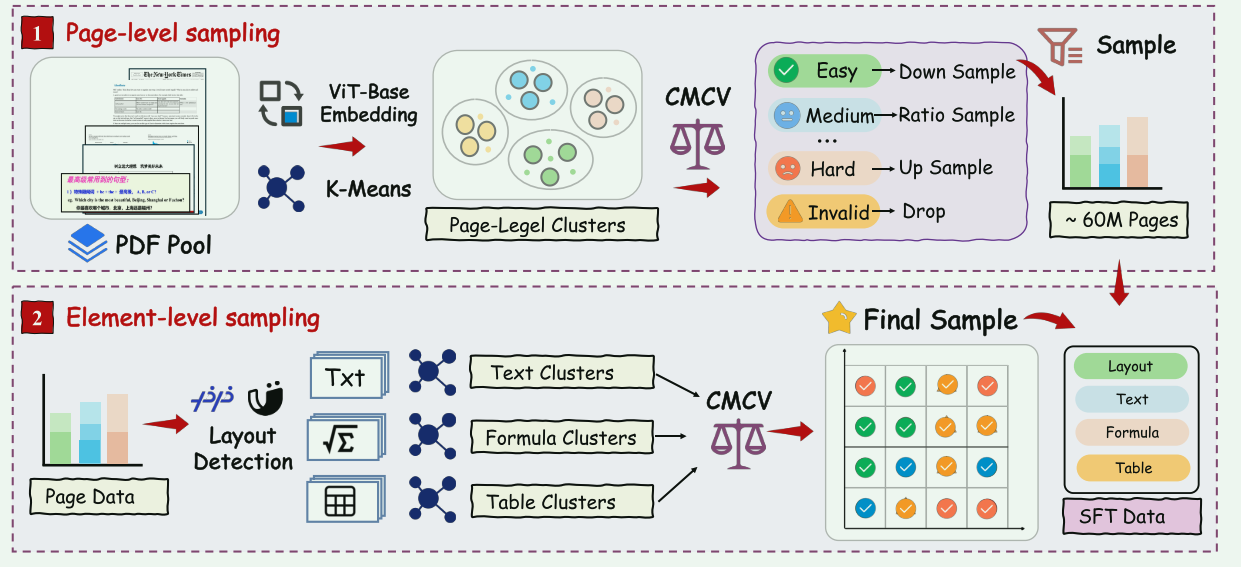
这实是完整的数据采样流水线,分为 "页面级" → "元素级" → "最终产出" 三个核心阶段。
整体逻辑
这张图展示了如何从原始PDF池中,经过广度采样(Page-level) 和 深度采样(Element-level),最终产出均衡、高质量、可直接用于SFT(有监督微调)的约6000万页样本。
① 第一阶段:Page-level sampling(页面级采样)
这一步解决**"数据广覆盖、分难度、定比例"** 的问题。
- PDF Pool(输入池)
原始海量PDF文档。 - ViT-Base Embedding + K-Means
- ViT:把每一页PDF图片转换成向量特征(Embedding),用数字表示页面的"长相"(布局、元素密度等)。
- K-Means:把特征相似的页面聚类(Page-Level Clusters),保证采样到的页面类型多样,不会全是单栏文本,也有复杂表格、多栏布局等。
- CMCV(跨模型一致性校验)判难度
对每个簇的页面进行难度判断,输出分级:- ✅ Easy(简单):少采(Down Sample)。
- ⚖️ Medium(中等):按比例采(Ratio Sample)。
- 🔥 Hard(困难):多采(Up Sample)。
- ❌ Invalid(无效):直接丢弃(Drop)。
- 产出:经过这一步,得到约6000万页的基础样本集,且整体难度分布符合预期。
② 第二阶段:Element-level sampling(元素级采样)
这一步解决**"细粒度、学难点"** 的问题。在页面级数据基础上,拆解到最小单元。
- Page Data(页面数据)
上一步的页面级样本。 - Layout Detection(版面检测)
把页面拆分成4类核心元素:- 🌊 Layout(版面块)
- 📝 Txt(纯文本)
- 📐 Formula(公式)
- 📋 Table(表格)
- 分元素聚类 + CMCV
对每一类元素分别做聚类和难度判断(再次执行CMCV逻辑),确保每一类元素的采样都覆盖其自身的复杂度梯度。 - Final Sample(最终样本)
整合所有元素的采样结果,形成多维度、高难度、全覆盖的最终样本库。
③ 最终输出:SFT Data
最终生成的高质量样本集(SFT Data),直接用于模型的有监督微调,确保模型既能学懂通用版面,又能攻克复杂公式、表格等硬骨头。
一句话总结
先按页面整体特征 做广度采样和难度分级,再按文本/公式/表格等细粒度元素做深度采样,层层筛选,最终产出完美适配微调需求的高质量数据。