上篇文章:Linux:缓冲区
目录
我们在使用Linux操作系统时,每天都在和"文件"与"目录"打交道。创建一个文件、写入一行代码、保存退出......这一切显得如此自然。但是,你是否好奇过,这些无形的数据究竟是如何安放在有形的物理介质上的?操作系统又是如何高效地管理这浩如烟海的数据的?
今天,就让我们向下深挖,从冰冷的机房硬件开始,一步步揭开Linux磁盘与文件系统的神秘面纱。
1.理解硬件
1.1IT物理基础设施:机房、机柜与服务器
在企业级IT架构中,数据的物理载体由以下三个核心层级构成:
数据中心(机房):为IT设备提供标准运行环境的物理空间。其核心系统包括恒温恒湿空调系统(精密空调)、不间断电源系统(UPS/双路市电)、消防灭火系统以及骨干网络接入设备,以保障硬件处于高可用状态。

机柜(Rack):符合工业标准的19英寸宽度的金属框架设备,通常高度为42U(1U=44.45mm)。其作用是高密度地物理承载、固定服务器及网络设备,并提供标准化的理线槽道和冷热隔离散热风道。

服务器(Server):执行计算和存储任务的实体计算节点。存储型服务器的前端通常配置有热插拔硬盘背板,物理磁盘通过托架直接接入背板的SAS/SATA接口,受主板或独立的RAID控制卡管理与调度。

核心存储介质:机械磁盘(HDD)
机械硬盘(HDD)是现代计算机体系中少有的依赖纯机械物理运动进行数据读写的外设。其特征为读写延迟高(毫秒级,受寻道与旋转时间限制),但存储密度大且单位容量成本低。


1.2磁盘物理结构
拆解机械硬盘外壳后,其核心电磁机械组件如下:
-
盘片(Platter):通常由铝合金或玻璃基板制成,表面涂覆有高矫顽力的磁性介质材料。数据通过介质磁极的翻转(N/S)进行物理记录。单块硬盘内部通常层叠多张盘片。
-
主轴马达(Spindle):驱动盘片组件进行恒速旋转的无刷电机。标准企业级硬盘转速一般为 7200 RPM 或 10000 RPM,转速直接决定了磁盘的旋转延迟(Rotational Latency)。
-
读写磁头(Head):采用巨磁阻效应(GMR)或垂直磁记录技术(PMR/SMR)的电子元件。盘片旋转时,磁头利用空气动力学原理悬浮于盘片上方极近距离(纳米级别)进行数据的磁电信号转换。
-
传动臂(Actuator Arm):物理承载磁头并在盘片径向区间进行机械移动的金属臂。
-
音圈马达(Voice Coil Motor, VCM):通过闭环伺服控制系统产生电磁力,驱动并精准定位传动臂,使磁头能够准确悬浮于目标磁道上方。

1.3磁盘的存储结构
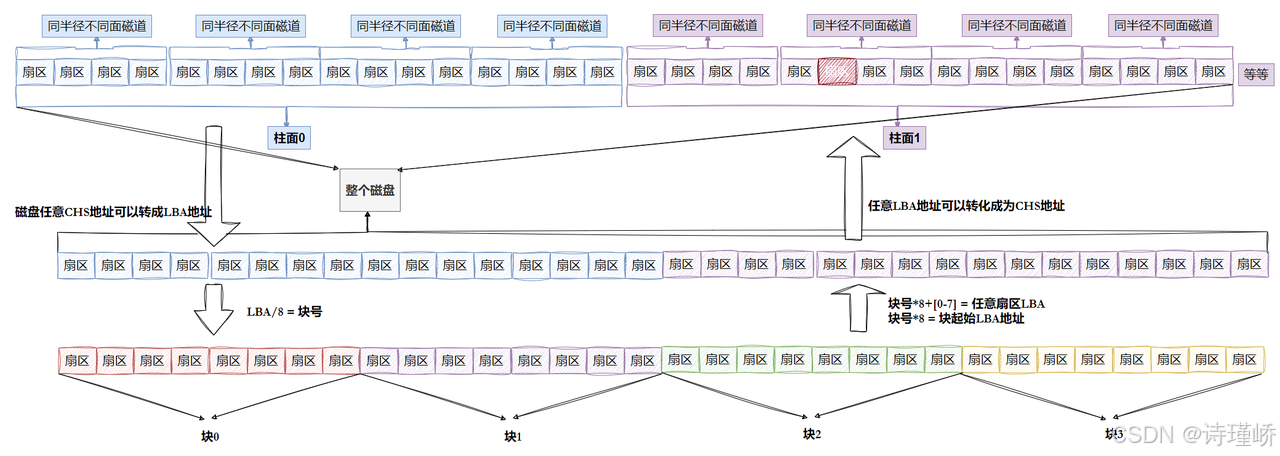
磁盘的数据存储遵循严格的几何结构布局,我们将其分为柱面,磁道,扇区:
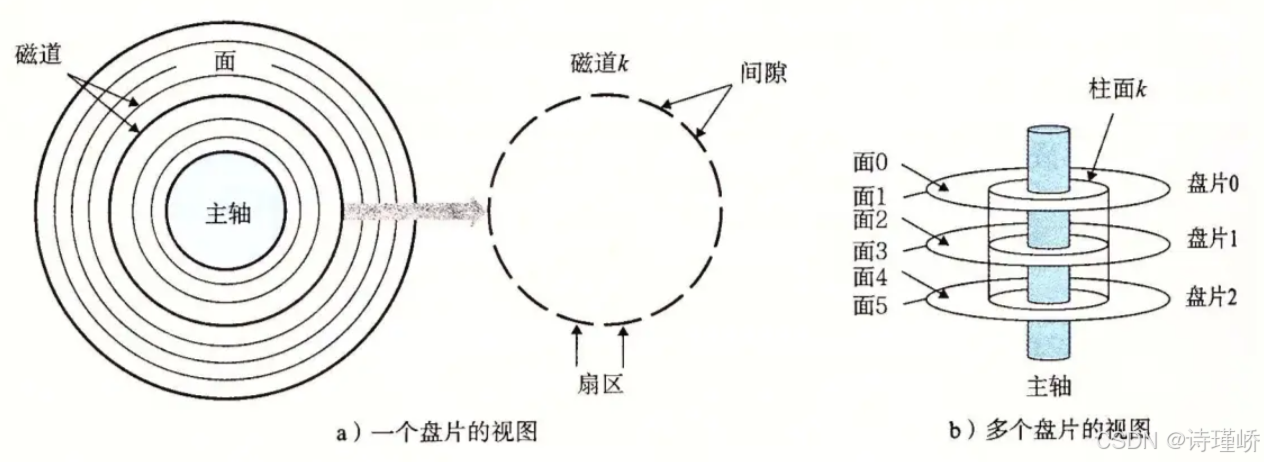
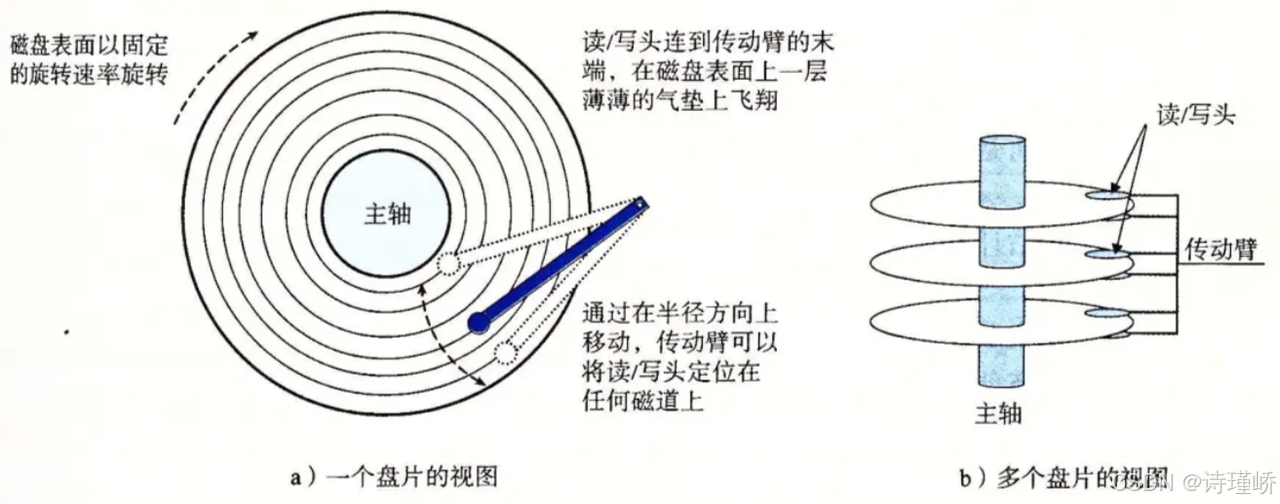
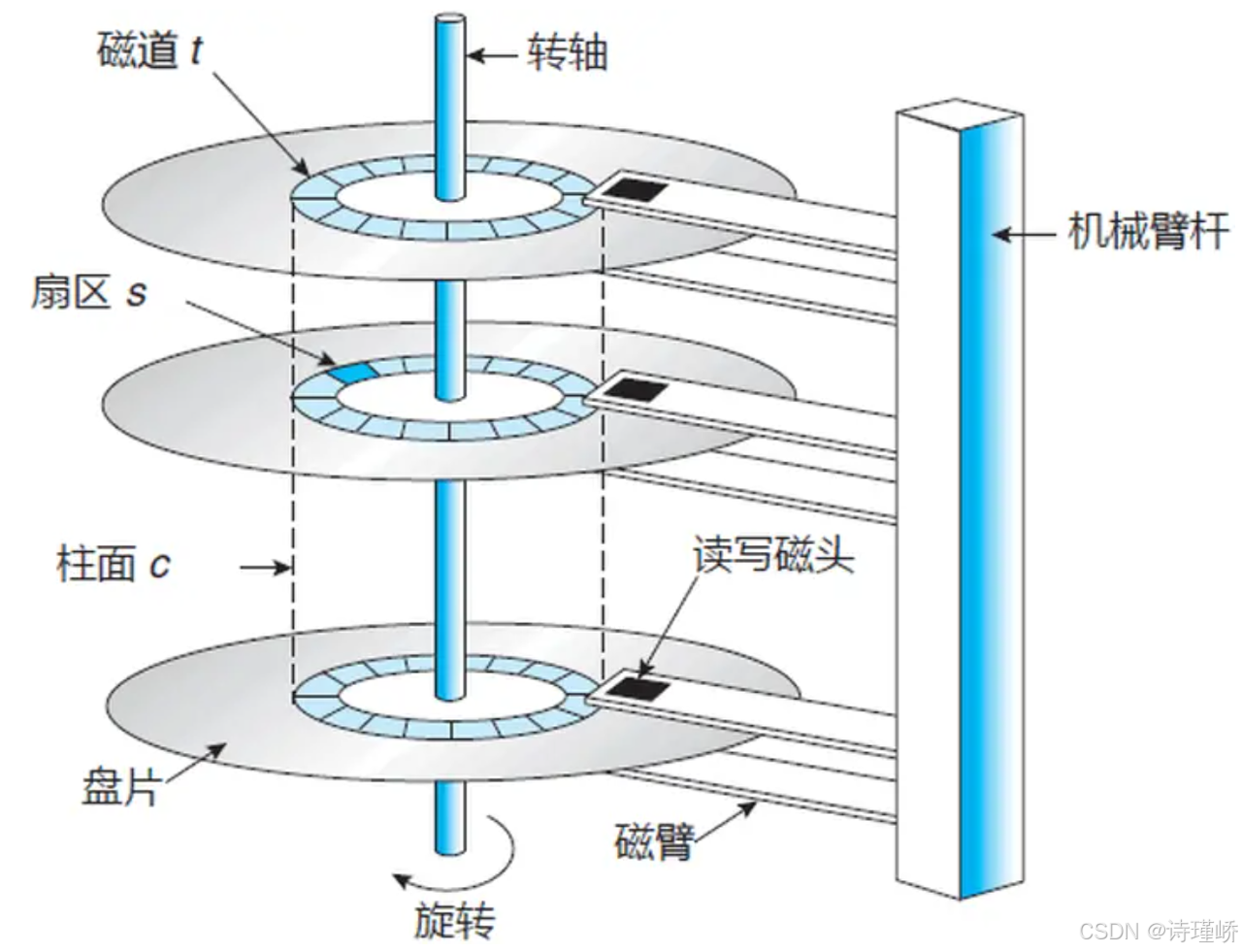
如上图所示:
柱面(Cylinder):硬盘中所有盘面上,半径相同的磁道在垂直方向上构成的圆柱面实体。最上面为柱面0
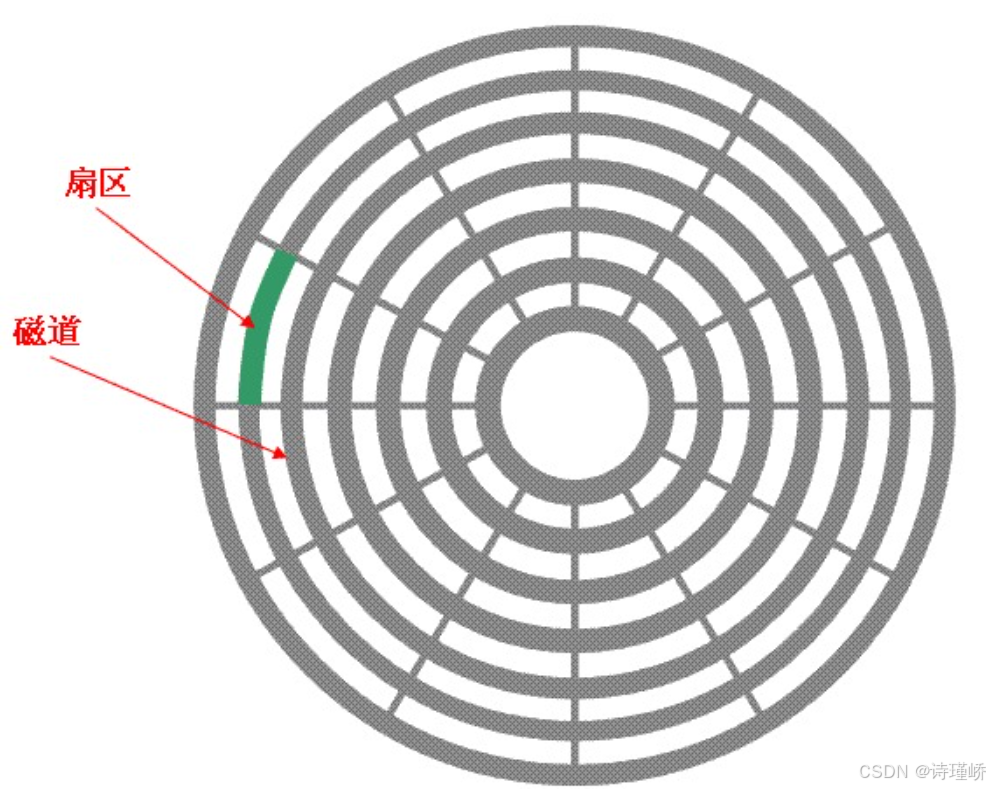
磁道(Track):在盘片表面,以主轴马达为圆心,划分出的不同半径的同心圆。最外围定义为0磁道,向圆心方向递增。
扇区(Sector):磁盘读写数据的最小物理单位。在标准格式化下,传统扇区容量为512 Bytes(高级格式化AF标准为4KB)。盘片同心圆上的一小段圆弧即为一个扇区。
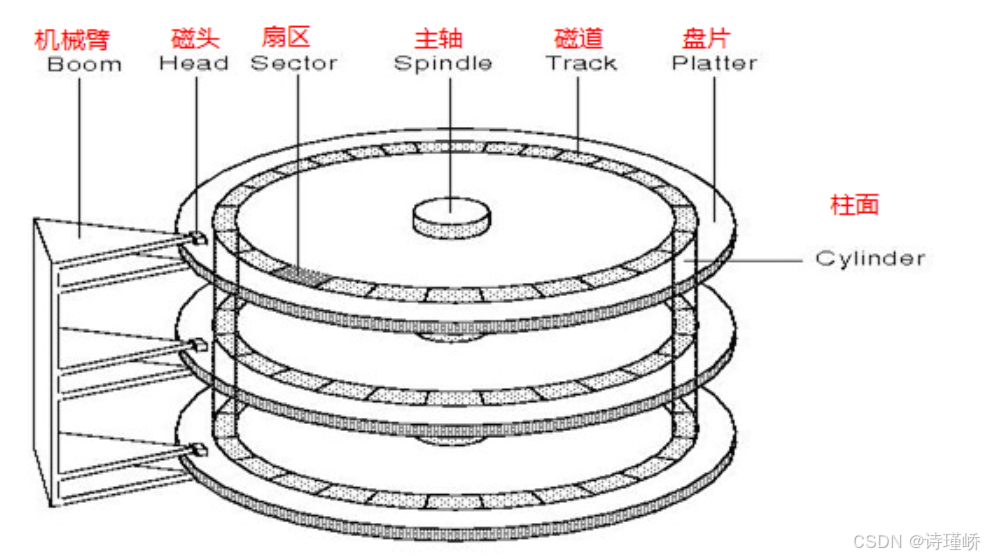
扇区是从磁盘读出和写入信息的最小单位,通常大小为512字节。
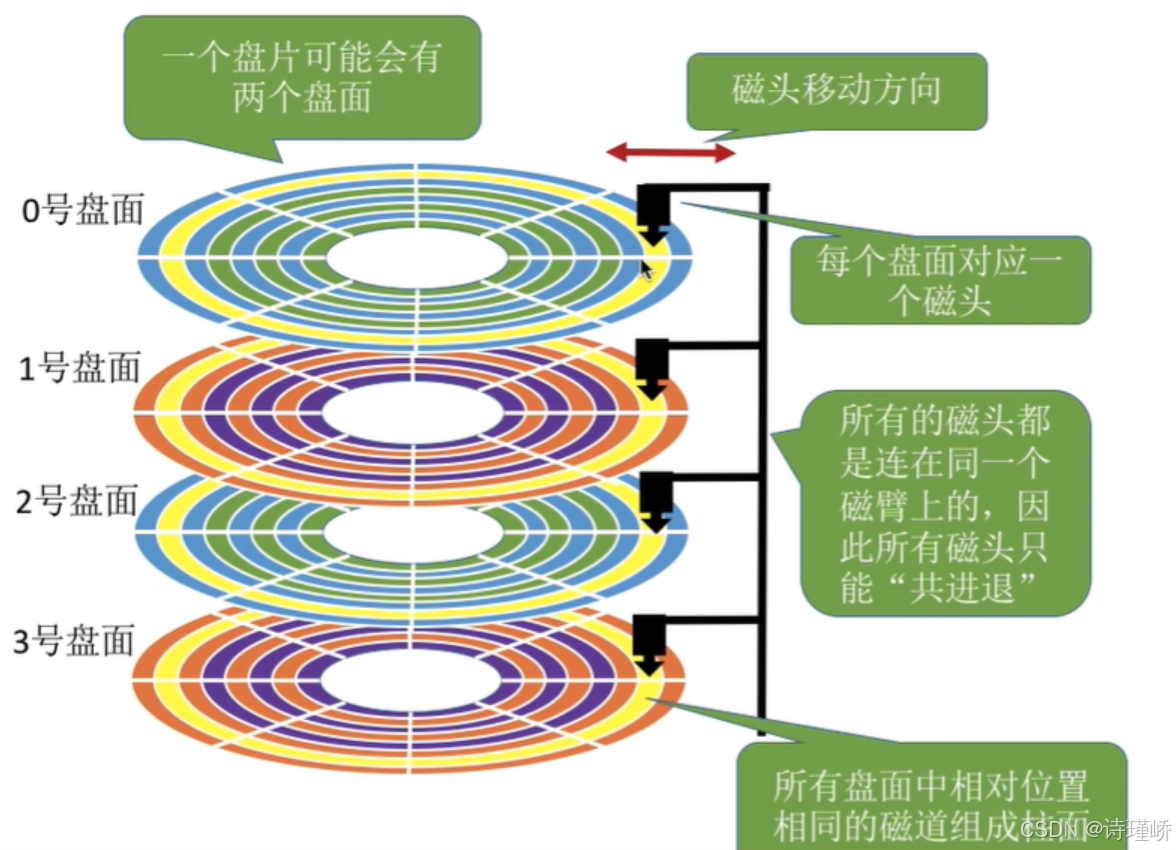
磁头(head)数:每个盘般有上下两面,分别对应1个磁头,共2个磁头
磁道(track)数:磁道是从盘外圈往内圈编号0磁道,1磁道.,靠近主轴的同圆于停靠磁头,不存储数据
柱(cylinder)数:磁道构成柱面,数量上等同于磁道个数
扇区(sector)数:每个磁道都被切分成很多扇形区域,每道的扇区数量相同
圆盘(platter)数:就是盘的数量
磁盘容量=磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数
细节:传动臂上的磁头是共进退的
1.4磁盘的物理寻址机制:CHS模式
通过上述的了解,我们理解了柱面,磁道,扇区。
而扇区时磁盘读写数据的最小物理单位,那么我们要怎么样才能定位一个扇区呢?
我们通过CHS地址定位法来实现定位。
在CHS模式下,数据读取操作包含三步指令:
-
输入柱面号(C):音圈马达驱动传动臂寻道。
-
输入磁头号(H):激活目标盘面对应的特定磁头。
-
等待扇区(S):等待盘片旋转,使目标扇区经过活跃磁头下方,执行信号读取。
之所以是这样的定位顺序,是因为物理结构导致的。(在1.5.3章节也会通过逻辑解释)
物理寻址联动原理: 硬盘的所有传动臂是刚性连接的,所有磁头只能同步进行径向运动。这意味着当系统需要读取某个特定磁道时,所有磁头都会同时定位到自身所在盘面的该磁道上(即定位到特定的柱面)。
注意
CHS寻址对早期的磁盘常有效,知道哪个磁头,读取哪个柱上的第扇区就可以读到数据了。但是CHS模式持的硬盘容量有限,因为系统8bit来存储磁头地址,10bit来存储柱面地址,6bit来存储扇区地址,而一个扇区共有512Byte,这样使用CHS寻址块硬盘最容量为256*1024*63*512B=8064MB(1MB=1048576B)(若按1MB=1000000B来算就是8.4GB)
在Linux中,我们通过命令查看磁盘和分区表的物理与逻辑属性:
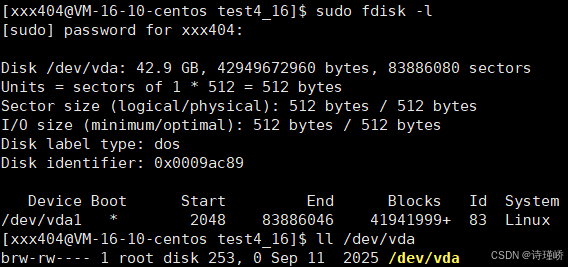
图中显示物理磁盘 /dev/vda 的总容量约为 42.9 GB,由 83,886,080 个扇区组成,每个扇区的物理和逻辑大小均为 512 字节。 底部信息表明该磁盘目前划分了一个主分区 /dev/vda1(作为启动分区),格式为 Linux 原生系统,从第 2048 个扇区开始分布。
1.5磁盘的逻辑结构
1.5.1抽象理解
如下图的磁带所示,其原本是被卷起来的,而我们也可以将磁带"拉直",形成线性结构:


那么,磁盘本质上是硬质的,但是逻辑上我们可以把磁盘想象为卷在一起的磁带,那么磁盘的逻辑存储结构我们也可以类似于:

这样,每一个扇区,就有了一个线性地址(其实就是数组下标),而这种地址被叫做LBA。
1.5.2逻辑块地址(LBA)
为突破CHS的容量寻址极限并屏蔽底层物理机械差异,现代硬盘控制器全面引入了LBA(Logical Block Address)机制。
LBA是一种线性地址抽象协议。它将三维立体的CHS几何结构,映射为一个一维的、从0开始递增的线性数组。
LBA地址由操作系统抽象而成,对于整个数组不需要物理定义,只需要知道有多少个扇区,就能推断出地址空间!
-
操作系统视角:内核仅使用LBA数值(如LBA 10000)向磁盘控制器发起I/O请求,无需关注数据位于哪个盘面或磁道。
-
硬件固件层:磁盘自身的微控制器和固件维护着 LBA 到 物理 CHS(或物理块地址 PBA)的映射表。固件接收到LBA请求后,内部执行算法转换,驱动马达和磁头完成物理I/O。
1.5.3从逻辑上深度理解磁盘
首先要先深度理解柱面:
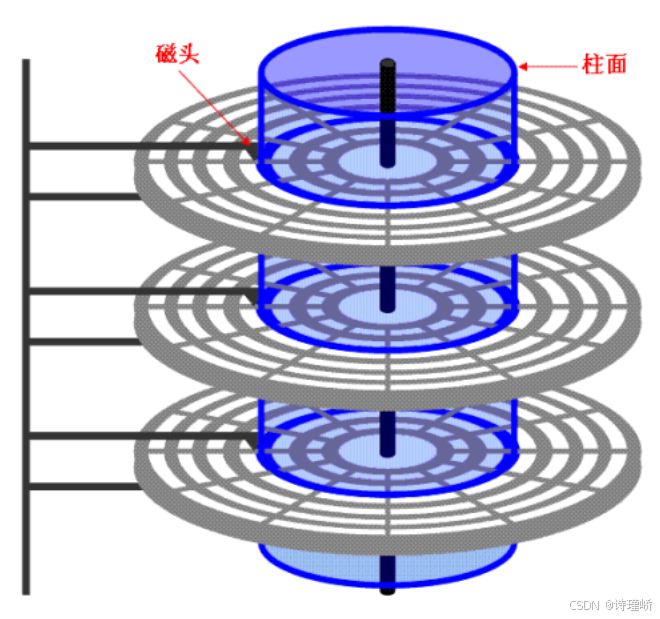
在磁盘中,有一个细节:传动臂上的磁头是共进退的。
而柱面是一个逻辑上的概念,其实就是每一面上,相同半径的磁道逻辑上构成柱面。所以,磁盘物理上分了很多面,逻辑上,磁盘整体是由"柱面"卷起来的。
所以,一个磁盘的真实情况是:
磁道:某一盘面的某一个磁道展开:

它就是一个一维数组。
柱面:整个磁盘所有盘面的同一个磁道,即柱面展开:
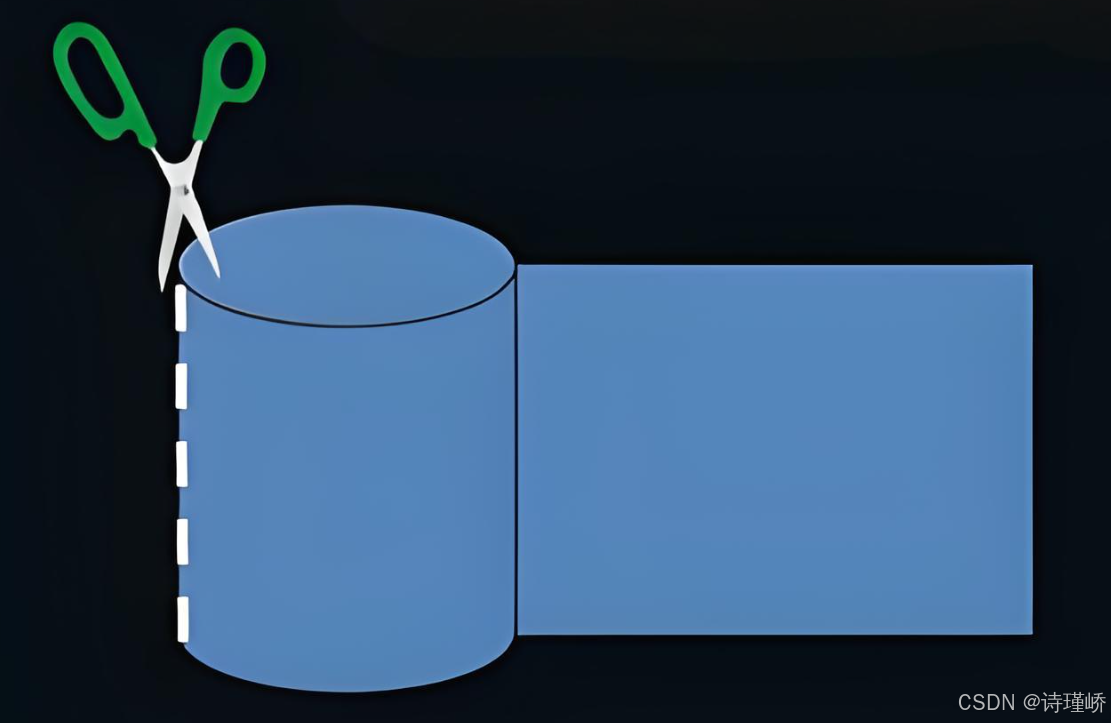
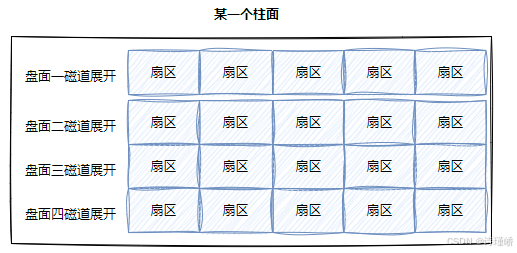
柱面上的每个磁道,扇区个数都是一样的。而上图表示的,不就是一个二维数组吗。
注意:柱面,磁道都是从0开始计数,扇区是从1开始计数。
整盘:
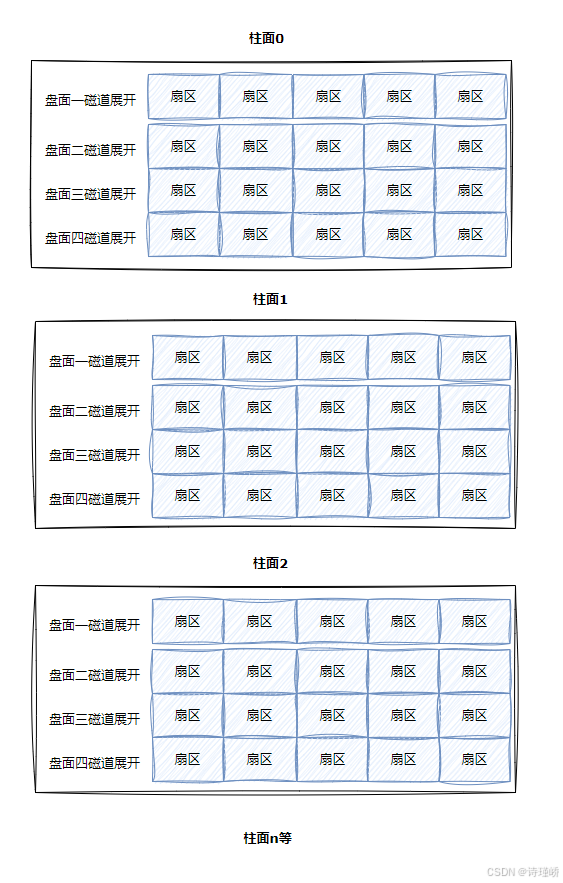
整个磁盘展开,不就是多张二维的扇区数组表吗,那么其逻辑上,就是三维数组。
所以,从三维数组中理解,寻找一个扇区,就是先找到一个柱面(Cylinder),再确定柱面内哪一个磁道(其实就是磁头位置,Head),在确定扇区(Sector),所以就有了CHS。
在C/C++中,所有数组在我们看来,其实全部都是一维数组:

所以,每一个扇区都有一个下标,我们叫做LBA(Logical Block Address)地址,其实就是线性地址。
那么,我们怎么计算得到这个LBA地址呢?将CHS转换为LBA地址即可。

**注意:**操作系统只需要使用LAB即可,而LBA与CHS可以相互转换,其转换工作是由磁盘自己来做的(固件:硬件电路,伺服系统)。
1.6CHS与LBA地址的相互转换
CHS转换为LBA地址:
磁头数 * 每磁道扇区数 = 单个柱面的扇区总数
LBA = 柱面号C * 单个柱面的扇区总数 + 磁头号H * 每磁道扇区数 + 扇区号S - 1
即:LBA = 柱面号C *(磁头数*每磁道扇区数) + 磁头号H * 每磁道扇区数 + 扇区号S - 1
扇区号通常是从1开始的,在LBA中,地址是从0开始的
柱面和磁道都是从0开始编号的
总柱面,磁道个数,扇区总数等信息,在磁盘内部会自动维护,上层开机的时候,会获取到这些参数。
LBA转换为CHS地址:
柱面号 C = LBA //(磁头数*每磁道扇区数)【就是单个柱面的扇区总数】
磁头号H = (LBA % (磁头数 * 每磁道扇区数)) // 每磁道扇区数
扇区号S = (LBA % 每磁道扇区数) + 1
"// ":表示除取整
所以,从此往后,在磁盘使者看来,根本就不关心CHS地址,而是直接使用LBA地址,磁盘内部自己转换。
所以从现在开始,磁盘就是一个元素为扇区的一维数组,数组的下标就是每个扇区的LBA地址。OS使用磁盘,就可以用一个数字访问磁盘扇区了。
LBA与CHS的本质就是将一维数组的下标转换为三维数组的下标。
2.文件系统
当磁盘暴露为以LBA为下标的一维逻辑扇区数组后,直接对扇区进行管理会导致系统元数据开销过大且效率低下。因此,操作系统引入了文件系统(如Linux下的Ext2/3/4)来规范数据的存储、寻址与空间回收。
2.1存储的逻辑单元:"块"概念
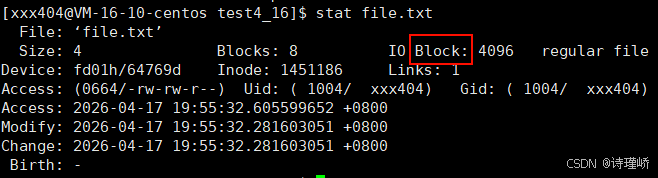
硬盘就是典型的"块"设备,操作系统读取硬盘数据时,不会一个一个扇区地读,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"。
硬盘的每个分区是被划分为一个一个的"块",一个"块"的大小是由格式化的时候确定的,并且不可以更改,最常见的是4KB(4 * 1024 = 4096),即连续八个扇区组成一个"块"。
"块"是文件系统与底层设备进行数据交互(文件存取)的最小逻辑I/O单位。
注意:
磁盘是一个三维数组,我们把它看待成为一个"一维数组",数组下标就是LBA,每个元素都是扇区。
每个扇区都有LBA,那么8个扇区一个块,每一个块的地址我们都可以算出来。
知道LBA:块号 = LBA / 8
知道块号: LBA = 块号 * 8 + n (n是块内第几个扇区)
2.2逻辑空间划分:分区(Partition)
分区是对底层线性LBA空间的逻辑切片。
功能:将一整块物理硬盘划分为多个独立、逻辑隔离的区域,每个区域可独立格式化并挂载不同的文件系统,从而实现系统数据、用户数据或交换空间(Swap)的隔离。
磁盘是可以被分为多个分区的,以Windows观点来看,可以将一块盘分为C,D,E盘。而这个C,D,E就是分区。分区从实质上来说,就是对硬盘的一种格式化。但是Linux的设备都是以文件形式存在,那么是怎么进行分区的呢?
在传统MBR分区表中,分区的起止边界通常以"柱面"为对齐单位;在现代GPT分区表中,则直接以LBA地址范围作为划分界限。我们以柱面为例。
柱面是分区的最小单位,我们可以利用参考柱面号码的方式来进行分区,其本质就是设置每个区的起始柱面和结束柱面号。此时,我们可以将硬盘上的柱面(分区)进行平铺,将其想象为一个大平面,如下图所示:

注意:
柱面大小一致,扇区个位一致,那么其实只要知道每个分区的起始和结束柱号,知道每一个柱多少个扇区,那么该分区多大,其实也就清楚了

2.3元数据结构:索引节点(inode)
文件系统设计的核心原则是将文件属性(元数据)与文件内容(实际数据)分离存储。这种机制通过引入inode(Index Node)实现。
-
数据块(Data Block):专用于持久化存储文件的实际内容流。一个大文件会被系统切割并分配到多个可能不连续的数据块中。
-
索引节点(inode):一个固定大小(通常为128或256 Bytes)的数据结构,每一个文件必然对应且仅对应一个inode。
当我们使用ls -l时,可以看到文件名,也可以看到文件元数据(属性):

这每行包含7列:
模式
硬链接数
文件所有者
组
大小
最后修改时间
文件名
ls -l读取存储在磁盘上的文件信息,然后显示出来:
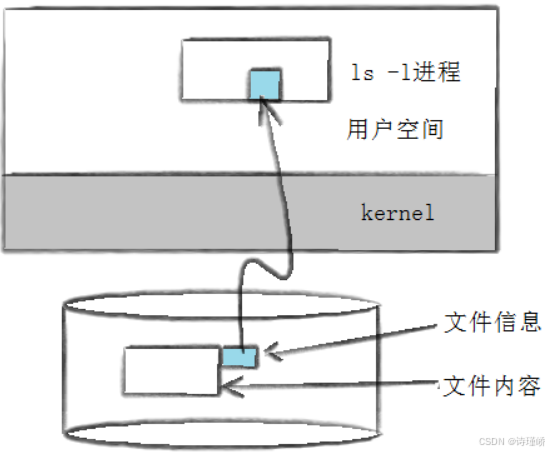
此时,我们要思考一个问题,文件数据都存储在"块"中,那么很显然,我们还必须找到一个地方存储文件的元信息(属性信息),比如文件的创建者,文件的创建日期,文件的大小等等。
这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。

每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。为了能解释清楚inode,我们需要深入了解一下文件系统。
注意:
Linux下文件的存储是属性和内容分离存储的
Linux下,保存文件属性的集合叫做inode,一个文件,一个inode,inode内有一个唯一的标识符,叫做inode号。
inode内部核心属性包含:
-
文件类型及访问权限(Mode)
-
属主与属组(UID/GID)
-
文件大小(Size)
-
时间戳(MAC Time:修改时间、访问时间、状态改变时间)
-
硬链接数(Links Count)
-
块指针数组(Block Pointers):记录该文件内容所分布的所有Data Block的物理/逻辑块号。对于大文件,通过直接指针、一级、二级甚至三级间接索引表进行寻址。
inode源码
cpp
/*
* Structure of an inode on the disk
*/
struct ext2_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Creation time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks; /* Blocks count */
__le32 i_flags; /* File flags */
union {
struct {
__le32 l_i_reserved1;
} linux1;
struct {
__le32 h_i_translator;
} hurd1;
struct {
__le32 m_i_reserved1;
} masix1;
} osd1; /* OS dependent 1 */
__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */
__le32 i_generation; /* File version (for NFS) */
__le32 i_file_acl; /* File ACL */
__le32 i_dir_acl; /* Directory ACL */
__le32 i_faddr; /* Fragment address */
union {
struct {
__u8 l_i_frag; /* Fragment number */
__u8 l_i_fsize; /* Fragment size */
__u16 i_pad1;
__le16 l_i_uid_high; /* these 2 fields */
__le16 l_i_gid_high; /* were reserved2[0] */
__u32 l_i_reserved2;
} linux2;
struct {
__u8 h_i_frag; /* Fragment number */
__u8 h_i_fsize; /* Fragment size */
__le16 h_i_mode_high;
__le16 h_i_uid_high;
__le16 h_i_gid_high;
__le32 h_i_author;
} hurd2;
struct {
__u8 m_i_frag; /* Fragment number */
__u8 m_i_fsize; /* Fragment size */
__u16 m_pad1;
__u32 m_i_reserved2[2];
} masix2;
} osd2; /* OS dependent 2 */
};
/*
* Constants relative to the data blocks
*/
#define EXT2_NDIR_BLOCKS 12
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1)
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1)
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1)
备注:EXT2_N_BLOCKS = 15注意:文件名属性未纳入到inode数据结构内部,inode的大小一般是128字节或者256字节,任何文件的内容大小可以不同,但是属性大小一定是相同的。
inode结构中不直接存储文件名,文件名作为目录条目(Directory Entry)的数据内容单独存在于目录文件的数据块中,并建立文件名字符串到特定inode号的映射。
总结
我们已经知道硬盘是典型的"块"设备,操作系统读取硬盘数据的时候,读取的基本单位是"块"。"块"又是硬盘的每个分区下的结构,难道"块"是随意的在分区上排布的吗?那要怎么找到"块"呢?还有就是上提到的存储件属性的inode,又是如何放置的呢?
文件系统就是为了组织管理这些,我们下篇文章见!!!
本章完。