1.进程是什么
(1)OS是一开机就被加载到内存的。
(2)OS是必然要对所有被加载到内存的程序进行管理的(采用先描述再组织的方式)。因此OS会为每一个被加载到内存的程序开一个struct记录其的所有属性和两个指针分别指向下一个struct和指向用户程序的数据和代码空间。OS中的这个结点链就叫进程列表。
有进程=内核数据结构对象(进程列表中的一个结点)+用户对应的数据与代码。
(3)在进程列表中每一个struct结点叫PCB(进程控制块)。而在linux中每一个struct结点又取名test_struct。linux中进程的所有属性都能直接/间接在test_struct中找到。
于是对进程再理解就有=PCB(task_struct)+自己的数据与代码。
通过上述操作后,OS对进程的处理又变成了对链表的增删查改。
CPU处理进程的顺序并不是根据用户的代码和数据空间,而是根据OS中的task_struct来确定处理顺序。
2.task_struct的大致内容
1.标识符:每一个进程都有独属于自己的标识符(类似于身份id)
2.状态
3.优先级(CPU调用进程的顺序)
4.内存计数器
5.内存指针:找到该进程中的数据与代码
PCB中的管理进程是用双链表进行管理的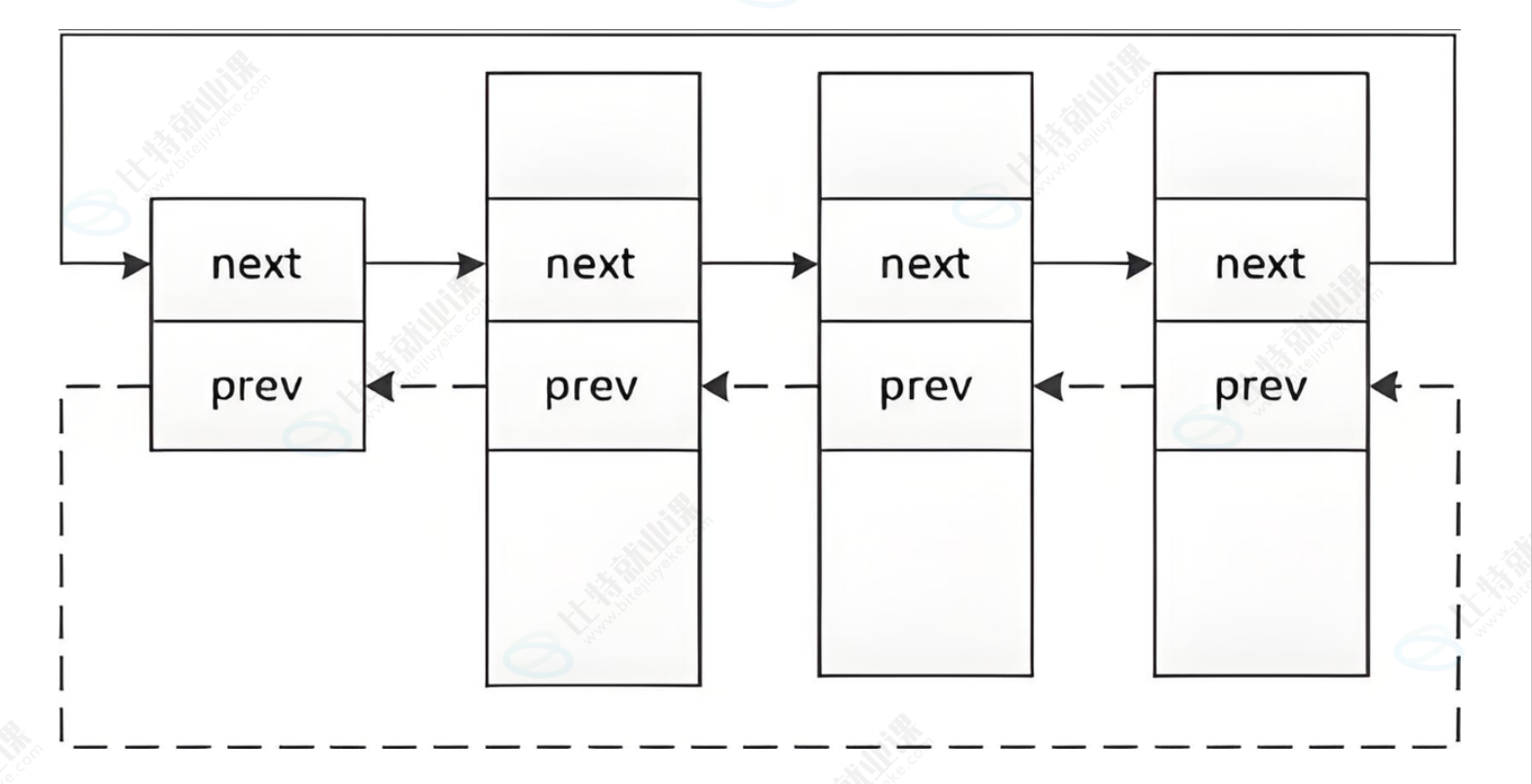
3.一堆指令与进程的理解
我们的所有用于运行的工具,指令,自己的程序,运行起来都是进程。
getpid():函数,返回当前程序的进程id.
cpp
#include<stdio.h>
#include<unistd.h>
int main()
{
while(1)
{
usleep(100);
printf("我是一个进程,pid是%d\n",getpid());
}
return 0;
}结果:
cpp
我是一个进程,pid是2166ps axj:指令,查看当前系统的所有进程(top也可以,q就可以推出查看)
同一行想要使用多条指令,就用;或&&(二者的功能一样)
cpp
//二者的效果一样
[fengyouyinli@VM-0-2-centos lesson3]$ ps axj|head -1;ps axj|grep test|grep -v grep
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
522 3141 3141 522 pts/1 3141 S+ 0 0:04 ./test
1 7122 7122 7122 ? -1 Ssl 1001 0:00 /home/fengyouyinli/.VimForCpp/nvim test.c test
[fengyouyinli@VM-0-2-centos lesson3]$ ps axj|head -1 && ps axj|grep test|grep -v grep
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
522 3141 3141 522 pts/1 3141 S+ 0 0:05 ./test
1 7122 7122 7122 ? -1 Ssl 1001 0:00 /home/fengyouyinli/.VimForCpp/nvim test.c testctrl + c的本质是杀死进程。
kill -9 + 进程pid:也可以杀死一个进程。
进程的别名叫任务。
/proc:以文件的形式去查找进程也就是存储进程的文件,即内存的数据也能以文件的形式展现,这里面的文件数据是随着内存情况而动态变化的.
ll打开一个/proc中的进程时,有两个显著的文件(cwd和exe)
cpp
[root@VM-0-2-centos lesson3]# ll /proc/5839
total 0
//无关的都删了
lrwxrwxrwx 1 fengyouyinli fengyouyinli 0 Apr 18 18:53 cwd -> /home/fengyouyinli/lesson3
lrwxrwxrwx 1 fengyouyinli fengyouyinli 0 Apr 18 18:53 exe -> exe:记录该进程对应的可执行文件的绝对路径。
在进程还在内存运行时删除掉可执行文件,该进程大概率也能继续运行,因为可执行文件中的数据和代码的部分在内存中拷贝了一份。
cwd:对应的可执行文件所在路径的绝对路径。
用途:如fopen一个文件
cpp
fopen("test.txt","w");当该文件不存在时就会在该可执行文件所在路径下生成一个新文件,该文件可以成功生成是因为,在生成前,OS会为该文件的路径前拷贝上cwd的路径而已。
chair("一个绝对路径");//该函数可以将该进程的cwd路径修改为指定的路径。
通过这个我们也就能明白指令中直接使用文件名就能在当前路径生成的原因了:
所有指令都是进程,运行时都是在文件名前加上了cwd中的绝对路径的。
getppid:一个函数,得到父进程的id.
cpp
#include<stdio.h>
#include<unistd.h>
int main()
{
while(1)
{
usleep(1000);
printf("我是一个进程,pid是%d,我的父进程的pid是%d\n",getpid(),getppid());
}
return 0;
}结果:
cpp
我是一个进程,pid是10891,我的父进程的pid是10649查阅能发现:
cpp
[root@VM-0-2-centos lesson3]# ls -l /proc/10649/exe
lrwxrwxrwx 1 root root 0 Apr 18 19:13 /proc/10649/exe -> /usr/bin/bash可以发现当前的进程的父进程为bash(命令行解释器)
说明命令行解释器也是一个一打开系统就会创建的进程,同时每一个用户登录就会为其分配一个bash,该用户退出就回收该bash.因此我们输入的指令都是传给bash然后由bash进行分析与处理的。
4.在一个程序中创建子进程的方式
fork():一个函数,用于在一个进程中创建一个他的子进程,这两个进程会同时运行后面的代码。
解释:这里的子进程的数据几乎完全取之于父进程,子进程的task_struct大多数数据从父进程中拷贝而来,因此子进程的task_struct实际是与父进程指向同一块数据与代码。(因此子进程只能运行于父进程一样的内容)(运行到哪的信息也直接复制了)
共享的另一个原因就是没有新的程序加载,因此子程序只能依赖于父程序。(更直白的说就是fork函数只是拷贝修改一份新的task_struct而已)
1.fork有两个返回值
对父进程返回子进程的id,对子进程返回0.
在操作上我们可以根据这个特性来对而这进行不同的代码操作(使用if语句)
1.返回值不同的原因:
一般一个父进程能有多个子进程,因此需要知道子进程的id来进行管理。而子进程只会有一个父进程且可以直接就得到父进程的id,因此只需返回说明自身一定创建成功的值即可。
2.一个函数返回两个值的原因
一个函数到了return代码时说明其的核心功能已经完成了且return本身就是一条独立的语句。而fork的核心功能就是创建拷贝修改子PCB甚至放入调度队列中,即在return前子进程就已经创建甚至调度完了,因此到return语句时就已经是有两个进程运行了。
3.id能同时有两个值的原因
进程具有独立性,即父/子进程有一方挂了,也不会丝毫影响一点对方。
原因:
(1)代码设置位置可读,因此没有进程能修改它
(2)父子一方有想修改数据时,OS就会在底层将这个要被修改的数据拷贝一份,让要修改数据的进程去修改这个拷贝。(这也就是写时拷贝)
总的来说有不需修改的数据就共用,要修改的数据就采用写时拷贝保持相对独立。