文章目录
-
- [1. 引言](#1. 引言)
- [2. Pinecone 核心概念](#2. Pinecone 核心概念)
-
- [2.1 什么是 Pinecone](#2.1 什么是 Pinecone)
- [2.2 Pinecone 架构](#2.2 Pinecone 架构)
- [2.3 Serverless vs Pod-based](#2.3 Serverless vs Pod-based)
- [3. Pinecone 账号设置](#3. Pinecone 账号设置)
-
- [3.1 创建账号](#3.1 创建账号)
- [3.2 获取 API Key](#3.2 获取 API Key)
- [3.3 配置环境变量](#3.3 配置环境变量)
- [4. LangChain Pinecone 集成实战](#4. LangChain Pinecone 集成实战)
-
- [4.1 环境准备](#4.1 环境准备)
- [4.2 初始化配置](#4.2 初始化配置)
- [4.3 创建索引](#4.3 创建索引)
- [4.4 文档加载与存储](#4.4 文档加载与存储)
- [4.5 查看索引信息](#4.5 查看索引信息)
- [5. 向量搜索方法详解](#5. 向量搜索方法详解)
-
- [5.1 基本相似度搜索](#5.1 基本相似度搜索)
- [5.2 带分数的相似度搜索](#5.2 带分数的相似度搜索)
- [5.3 元数据过滤搜索](#5.3 元数据过滤搜索)
- [5.4 最大边际相关性搜索(MMR)](#5.4 最大边际相关性搜索(MMR))
- [5.5 通过 ID 删除文档](#5.5 通过 ID 删除文档)
- [6. Pinecone 的优势](#6. Pinecone 的优势)
-
- [6.1 性能优势](#6.1 性能优势)
- [6.2 功能优势](#6.2 功能优势)
- [6.3 适用场景](#6.3 适用场景)
- [7. Pinecone vs Redis 对比](#7. Pinecone vs Redis 对比)
-
- [7.1 架构对比](#7.1 架构对比)
- [7.2 性能对比](#7.2 性能对比)
- [7.3 成本对比](#7.3 成本对比)
- [7.4 选择建议](#7.4 选择建议)
- [8. 常用向量数据库对比](#8. 常用向量数据库对比)
-
- [8.1 InMemoryVectorStore(内存向量存储)](#8.1 InMemoryVectorStore(内存向量存储))
- [8.2 Chroma](#8.2 Chroma)
- [8.3 Pinecone](#8.3 Pinecone)
- [8.4 FAISS](#8.4 FAISS)
- [8.5 Redis(RedisSearch 向量数据库)](#8.5 Redis(RedisSearch 向量数据库))
- [8.6 对比表格](#8.6 对比表格)
- [8.7 选型总结](#8.7 选型总结)
- [9. 常见问题与解决方案](#9. 常见问题与解决方案)
-
- [9.1 向量维度不匹配](#9.1 向量维度不匹配)
- [9.2 API Key 未设置](#9.2 API Key 未设置)
- [9.3 索引不存在](#9.3 索引不存在)
- [9.4 元数据过滤无效](#9.4 元数据过滤无效)
- [10. 总结](#10. 总结)

1. 引言
在构建 RAG(检索增强生成)系统时,选择合适的向量数据库至关重要。Pinecone 作为一款专为 AI 应用设计的云原生向量数据库,以其 Serverless 架构、高性能和易用性,成为开发者的首选。本文将深入探讨 Pinecone 的核心概念、架构设计以及与 LangChain 的集成实战。
2. Pinecone 核心概念
2.1 什么是 Pinecone
Pinecone 是一款完全托管的云原生向量数据库,专为机器学习和 AI 应用设计。它提供了高性能的向量相似度搜索能力,无需管理基础设施,开箱即用。
核心特性:
- Serverless 架构:按需付费,自动扩展,无需管理服务器
- 高性能:毫秒级查询响应,支持数十亿级向量
- 实时更新:支持动态添加、删除和更新向量
- 元数据过滤:结合元数据进行精确过滤
- 混合搜索:支持向量搜索和关键词搜索结合
- 多云部署:支持 AWS、GCP、Azure
2.2 Pinecone 架构
Pinecone 采用分布式架构,将索引和数据分离,实现高可用和高性能:
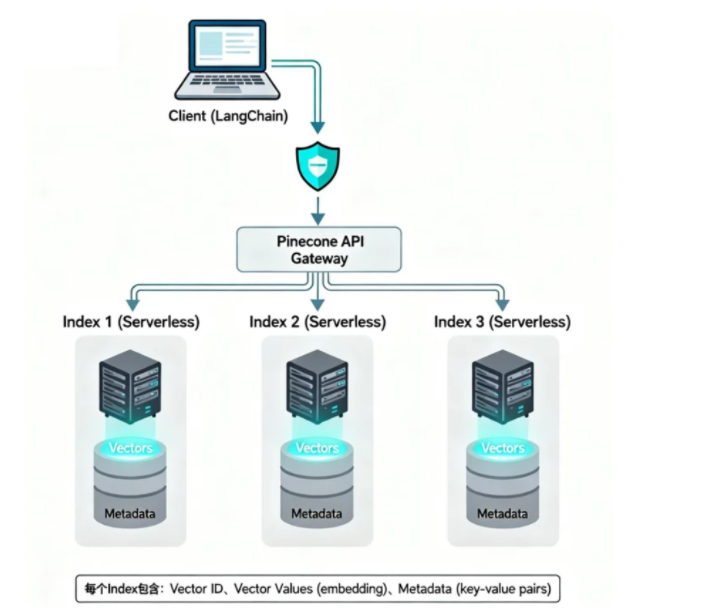
关键组件说明:
-
Client(客户端):
- 通过 Python SDK 或 REST API 与 Pinecone 交互
- LangChain 提供了
PineconeVectorStore封装
-
Pinecone API Gateway:
- 统一的 API 入口
- 负责请求路由和负载均衡
- 处理认证和授权
-
Index(索引):
- 每个索引是一个独立的向量数据库
- 支持 Serverless 和 Pod-based 两种模式
- 包含向量数据和元数据
-
Vectors + Metadata:
- Vector ID:唯一标识符
- Vector Values:向量嵌入(如 3072 维)
- Metadata:键值对形式的元数据(如 category、num、source)
工作流程:
- 创建索引:指定维度、相似度度量(cosine/euclidean/dotproduct)
- 写入数据:上传向量和元数据到索引
- 查询请求:发送查询向量和过滤条件
- 返回结果:返回最相似的向量及其元数据
2.3 Serverless vs Pod-based
Pinecone 提供两种部署模式:
① Serverless(推荐)
- 特点:按需付费,自动扩展,无需管理容量
- 优点:成本低,适合变化的工作负载
- 缺点:冷启动可能有延迟
- 适用场景:开发测试、中小规模应用
② Pod-based
- 特点:预留资源,固定容量
- 优点:性能稳定,延迟可预测
- 缺点:成本较高,需要容量规划
- 适用场景:大规模生产环境
3. Pinecone 账号设置
3.1 创建账号
根据图片内容,Pinecone 账号创建流程如下:
- 访问官网 :https://www.pinecone.io/
- 注册账号:使用邮箱或 Google 账号注册
- 选择计划 :
- Starter:免费,适合开发测试
- Standard:按需付费,适合生产环境
- Enterprise:企业级,定制化方案
3.2 获取 API Key
创建账号后,需要获取 API Key:
- 登录 Pinecone 控制台
- 进入 API Keys 页面
- 点击 Create API Key
- 复制生成的 API Key
重要提示:
- API Key 只显示一次,请妥善保存
- 不要将 API Key 提交到代码仓库
- 使用环境变量存储 API Key
3.3 配置环境变量
方式一:在代码中设置
python
import os
os.environ["PINECONE_API_KEY"] = "your-api-key-here"方式二:使用 .env 文件
bash
# .env 文件
PINECONE_API_KEY=your-api-key-here
python
from dotenv import load_dotenv
load_dotenv() # 自动加载 .env 文件方式三:系统环境变量
bash
# Linux/Mac
export PINECONE_API_KEY=your-api-key-here
# Windows
set PINECONE_API_KEY=your-api-key-here4. LangChain Pinecone 集成实战
4.1 环境准备
安装依赖:
bash
pip install langchain-pinecone langchain-google-genai pinecone-client依赖说明:
langchain-pinecone:LangChain 的 Pinecone 集成langchain-google-genai:Google Gemini 嵌入模型pinecone-client:Pinecone Python SDK
4.2 初始化配置
python
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_pinecone import PineconeVectorStore
from pinecone import Pinecone, ServerlessSpec
# 初始化嵌入模型
embeddings = GoogleGenerativeAIEmbeddings(model="gemini-embedding-001")
# 初始化 Pinecone 客户端(自动从环境变量读取 API Key)
pc = Pinecone()
index_name = "md-documents"配置参数说明:
| 参数 | 说明 | 示例 |
|---|---|---|
model |
嵌入模型名称 | gemini-embedding-001 |
index_name |
索引名称 | md-documents |
dimension |
向量维度 | 3072(gemini-embedding-001) |
metric |
相似度度量 | cosine/euclidean/dotproduct |
4.3 创建索引
python
# 检查索引是否存在,不存在则创建
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=3072, # gemini-embedding-001 的维度
metric="cosine",
spec=ServerlessSpec(
cloud="aws",
region="us-east-1"
)
)
print(f"创建索引: {index_name}")
else:
print(f"索引已存在: {index_name}")参数详解:
-
dimension:必须与嵌入模型的维度一致
gemini-embedding-001:3072 维text-embedding-ada-002:1536 维text-embedding-3-small:1536 维text-embedding-3-large:3072 维
-
metric:相似度度量方法
cosine:余弦相似度(推荐,适合文本)euclidean:欧氏距离dotproduct:点积
-
spec:部署规格
ServerlessSpec:Serverless 模式cloud:云服务商(aws/gcp/azure)region:部署区域
4.4 文档加载与存储
python
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.document_loaders.markdown import UnstructuredMarkdownLoader
# 加载 Markdown 文档
loader = UnstructuredMarkdownLoader("test.md", mode="elements")
documents = loader.load()
# 设置基于 token 的文本分割器
splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=200,
chunk_overlap=50,
)
# 分割文档
chunks = splitter.split_documents(documents)
# 添加元数据
for i, chunk in enumerate(chunks, start=1):
chunk.metadata["category"] = "qa"
chunk.metadata["num"] = i
# 创建向量存储
vector_store = PineconeVectorStore(
index_name=index_name,
embedding=embeddings
)
# 添加文档到向量存储
print("添加文档到 Pinecone...")
ids = vector_store.add_documents(chunks)
print(f"添加了 {len(ids)} 个文档")工作流程:
- 加载文档 :使用
UnstructuredMarkdownLoader加载 Markdown 文件 - 分割文档 :使用
CharacterTextSplitter按 token 分割 - 添加元数据:为每个 chunk 添加 category 和 num 字段
- 创建向量存储 :初始化
PineconeVectorStore - 上传向量 :调用
add_documents()自动嵌入并上传
4.5 查看索引信息
python
# 查看索引统计信息
index = pc.Index(index_name)
stats = index.describe_index_stats()
print(f"索引统计: {stats}")
# 输出示例:
# {
# 'dimension': 3072,
# 'index_fullness': 0.0,
# 'namespaces': {'': {'vector_count': 42}},
# 'total_vector_count': 42
# }5. 向量搜索方法详解
5.1 基本相似度搜索
python
# 相似性搜索
docs = vector_store.similarity_search(
query="Claude skill是什么",
k=2, # 返回前 2 个最相似的文档
)
for i, doc in enumerate(docs, 1):
print(f"文档 {i}: {doc.page_content[:100]}...")输出示例:
文档 1: 什么是 Claude Skills...
文档 2: Claude Skills 实战:从安装到实践...5.2 带分数的相似度搜索
python
# 带分数的相似性搜索
docs_with_score = vector_store.similarity_search_with_score(
query="Claude skill是什么",
k=2,
)
for i, (doc, score) in enumerate(docs_with_score, 1):
print(f"文档 {i} (分数: {score:.4f}): {doc.page_content[:100]}...")输出示例:
文档 1 (分数: 0.8523): 什么是 Claude Skills...
文档 2 (分数: 0.7891): Claude Skills 实战:从安装到实践...分数说明:
- 使用
cosine度量时,分数范围 -1, 1 - 分数越高,相似度越高
- 通常相似度 > 0.7 表示高度相关
5.3 元数据过滤搜索
python
# 根据元数据过滤
docs = vector_store.similarity_search(
query="Claude skill是什么",
k=2,
filter={"category": "qa", "num": {"$lte": 3}} # num <= 3
)
for i, doc in enumerate(docs, 1):
print(f"文档 {i}: {doc.page_content[:100]}...")
print(f"元数据: {doc.metadata}")过滤器语法:
| 操作符 | 说明 | 示例 |
|---|---|---|
$eq |
等于 | {"category": {"$eq": "qa"}} |
$ne |
不等于 | {"category": {"$ne": "test"}} |
$gt |
大于 | {"num": {"$gt": 5}} |
$gte |
大于等于 | {"num": {"$gte": 5}} |
$lt |
小于 | {"num": {"$lt": 10}} |
$lte |
小于等于 | {"num": {"$lte": 10}} |
$in |
在列表中 | {"category": {"$in": ["qa", "doc"]}} |
$nin |
不在列表中 | {"category": {"$nin": ["test"]}} |
组合过滤器:
python
# AND 条件
filter = {
"$and": [
{"category": "qa"},
{"num": {"$lte": 3}}
]
}
# OR 条件
filter = {
"$or": [
{"category": "qa"},
{"category": "doc"}
]
}5.4 最大边际相关性搜索(MMR)
python
# MMR 搜索
docs = vector_store.max_marginal_relevance_search(
query="Claude skill是什么",
k=2,
fetch_k=10, # 先获取 10 个候选文档
lambda_mult=0.5, # 多样性参数(0-1,越小越多样)
)
for i, doc in enumerate(docs, 1):
print(f"文档 {i}: {doc.page_content[:100]}...")MMR 参数说明:
k:最终返回的文档数量fetch_k:初步获取的候选文档数量lambda_mult:多样性参数- 0:最大多样性
- 1:最大相关性
- 0.5:平衡相关性和多样性
MMR 使用场景:
- 避免返回重复或过于相似的文档
- 在 RAG 系统中提供更全面的上下文
- 推荐系统中增加结果多样性
5.5 通过 ID 删除文档
python
# 删除指定 ID 的文档
vector_store.delete(ids=["doc-id-1", "doc-id-2"])
# 删除所有文档
index = pc.Index(index_name)
index.delete(delete_all=True)6. Pinecone 的优势
6.1 性能优势
- 毫秒级响应:查询延迟通常在 10-50ms
- 高吞吐量:支持每秒数千次查询
- 自动扩展:Serverless 模式自动处理负载变化
- 全球部署:支持多区域部署,降低延迟
6.2 功能优势
- 完全托管:无需管理基础设施
- 实时更新:支持动态添加、删除、更新向量
- 元数据过滤:强大的过滤能力,支持复杂查询
- 混合搜索:结合向量搜索和关键词搜索
- 高可用:99.9% SLA 保证
6.3 适用场景
| 场景 | 适用性 | 说明 |
|---|---|---|
| 小规模数据(< 100万向量) | ⭐⭐⭐⭐⭐ | Serverless 模式成本低 |
| 中等规模数据(100万-1000万) | ⭐⭐⭐⭐⭐ | 自动扩展,性能稳定 |
| 大规模数据(> 1000万) | ⭐⭐⭐⭐⭐ | Pod-based 模式支持 |
| 实时更新需求 | ⭐⭐⭐⭐⭐ | 支持动态更新 |
| 元数据过滤需求 | ⭐⭐⭐⭐⭐ | 强大的过滤能力 |
| 生产环境 | ⭐⭐⭐⭐⭐ | 高可用,完全托管 |
7. Pinecone vs Redis 对比
7.1 架构对比
| 特性 | Pinecone | Redis |
|---|---|---|
| 部署方式 | 云端托管 | 自托管/云端 |
| 架构 | Serverless/Pod-based | 内存数据库 + RediSearch |
| 持久化 | 自动持久化 | RDB/AOF |
| 扩展性 | 自动扩展 | 手动扩展 |
7.2 性能对比
| 指标 | Pinecone | Redis |
|---|---|---|
| 查询延迟 | 10-50ms | 1-10ms(内存) |
| 吞吐量 | 高 | 非常高 |
| 数据规模 | 数十亿级 | 百万-千万级 |
| 冷启动 | 有(Serverless) | 无 |
7.3 成本对比
| 项目 | Pinecone | Redis |
|---|---|---|
| 基础设施 | 无需管理 | 需要管理 |
| 计费方式 | 按需付费 | 按实例付费 |
| 免费额度 | Starter 计划 | 无(需自建) |
| 运维成本 | 低 | 中等 |
7.4 选择建议
选择 Pinecone 的场景:
- 不想管理基础设施
- 需要全球部署和高可用
- 数据规模较大(> 100万向量)
- 需要自动扩展
选择 Redis 的场景:
- 已有 Redis 基础设施
- 需要极低延迟(< 10ms)
- 数据规模较小(< 100万向量)
- 需要完全控制数据
8. 常用向量数据库对比
8.1 InMemoryVectorStore(内存向量存储)
特点:
- 数据存储在内存中
- 速度最快
- 不持久化(程序关闭后数据丢失)
- 适合小规模数据和测试
使用场景:
- 快速原型开发
- 小规模数据集
- 临时测试
8.2 Chroma
特点:
- 开源向量数据库
- 支持本地持久化
- 轻量级,易于使用
- 支持元数据过滤
使用场景:
- 中小规模应用
- 本地开发和测试
- 需要持久化存储
代码示例:
python
from langchain_community.vectorstores import Chroma
vector_store = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db" # 持久化目录
)8.3 Pinecone
特点:
- 云端托管向量数据库
- 高性能、可扩展
- 支持大规模数据
- 需要 API Key
使用场景:
- 生产环境
- 大规模数据
- 需要高可用性
8.4 FAISS
特点:
- Facebook 开源
- 高性能相似度搜索
- 支持多种索引方法
- 适合大规模数据
使用场景:
- 大规模向量搜索
- 需要高性能
- 本地部署
8.5 Redis(RedisSearch 向量数据库)
特点:
- 基于 Redis 生态,利用 RedisSearch 模块实现向量存储与搜索
- 支持内存存储,性能极高
- 支持持久化(RDB/AOF)
- 原生支持向量索引(HNSW 算法)
- 支持元数据过滤与混合查询(向量+标量)
- 兼容 Redis 生态,易于集成
使用场景:
- 需要极高性能的实时向量检索
- 已有 Redis 基础设施的项目
- 需要结合缓存与向量搜索的场景
- 中小到大规模数据(取决于 Redis 内存容量)
代码示例:
python
from langchain_community.vectorstores import Redis
from langchain_community.embeddings import GoogleGenerativeAIEmbeddings
# 初始化嵌入模型
embeddings = GoogleGenerativeAIEmbeddings(model="gemini-embedding-001")
# 创建 Redis 向量存储
vector_store = Redis.from_documents(
documents=chunks,
embedding=embeddings,
redis_url="redis://localhost:6379",
index_name="my_vector_index", # RedisSearch 索引名
)8.6 对比表格
| 特性 | InMemoryVectorStore | Chroma | Pinecone | FAISS | Redis |
|---|---|---|---|---|---|
| 持久化 | ❌ | ✅ | ✅ | ✅ | ✅ |
| 云端托管 | ❌ | ❌ | ✅ | ❌ | ❌(可自托管) |
| 性能 | 快 | 中 | 快 | 非常快 | 非常快 |
| 易用性 | 简单 | 简单 | 中等 | 复杂 | 中等 |
| 成本 | 免费 | 免费 | 付费 | 免费 | 免费(自托管) |
| 适用规模 | 小 | 中 | 大 | 大 | 中~大 |
| 混合查询支持 | ❌ | ✅ | ✅ | ❌ | ✅ |
| 生态集成 | 无 | 独立 | 云服务 | 独立 | Redis 生态 |
8.7 选型总结
在选择向量存储方案时,需综合考虑数据规模、性能需求、持久化要求、成本预算及开发复杂度:
- 快速验证与小数据:优先选 InMemoryVectorStore(内存快但易失)或 Chroma(轻量且支持本地持久化)。
- 生产级高可用:Pinecone(云端托管,省心但付费)或 Redis(自托管灵活,生态强大)。
- 极致性能与可控性:FAISS(本地高性能搜索,适合技术团队自主优化)。
- 已有 Redis 基础设施:直接使用 RedisSearch 向量模块,低成本集成向量检索与缓存能力。
9. 常见问题与解决方案
9.1 向量维度不匹配
错误信息:
Vector dimension 3072 does not match the dimension of the index 768解决方案:
确保嵌入模型的维度与索引配置一致:
python
# 查看嵌入模型维度
embeddings = GoogleGenerativeAIEmbeddings(model="gemini-embedding-001")
test_vector = embeddings.embed_query("test")
print(f"向量维度: {len(test_vector)}") # 3072
# 创建索引时使用相同维度
pc.create_index(
name=index_name,
dimension=3072, # 与嵌入模型一致
metric="cosine"
)9.2 API Key 未设置
错误信息:
PineconeException: API key is required解决方案:
python
import os
os.environ["PINECONE_API_KEY"] = "your-api-key-here"
# 或使用 .env 文件
from dotenv import load_dotenv
load_dotenv()9.3 索引不存在
错误信息:
NotFoundException: Index 'md-documents' not found解决方案:
python
# 检查索引是否存在
if index_name not in pc.list_indexes().names():
pc.create_index(...)9.4 元数据过滤无效
问题:过滤器没有生效,返回了不符合条件的文档
解决方案:
确保元数据字段在上传时已正确设置:
python
# 添加元数据时
chunk.metadata["category"] = "qa" # 确保字段名一致
chunk.metadata["num"] = i # 确保类型正确(int)
# 查询时
filter = {"category": "qa", "num": {"$lte": 3}}10. 总结
Pinecone 作为云原生向量数据库,凭借其 Serverless 架构、高性能和易用性,成为构建 RAG 系统的优秀选择。通过与 LangChain 的无缝集成,开发者可以快速构建生产级的 AI 应用。
核心要点:
- Pinecone 是完全托管的云原生向量数据库
- 支持 Serverless 和 Pod-based 两种部署模式
- 提供丰富的搜索方法:相似度搜索、元数据过滤、MMR 搜索
- 适合各种规模的向量搜索场景
- 与 LangChain 无缝集成