网上的AOP日志教程,代码基本都长一样:定义一个注解,写一个切面,方法前后各打一行log.info。跑通了,教程结束。
这种代码到了生产环境几乎没用。线上排查问题的时候,你需要的不是「某个方法被调了」这种信息。你需要知道这次请求的链路ID、调用方IP、传入的业务参数、方法耗时、异常类型和错误码。教程里那种只打方法名的日志,在日志平台里搜出来跟没搜一样。
我从三个线上项目里提取了AOP日志的实现代码,整理出生产环境真正在用的写法。这三个项目分别是一个通用框架层的日志starter、一个带业务模块分类的中型项目、一个几十个微服务的大型项目。它们的AOP日志实现各有侧重,合在一起刚好覆盖了生产环境需要考虑的所有问题。
生产级AOP日志要解决什么
先看全局。生产环境的AOP日志需要解决三个层面的问题:
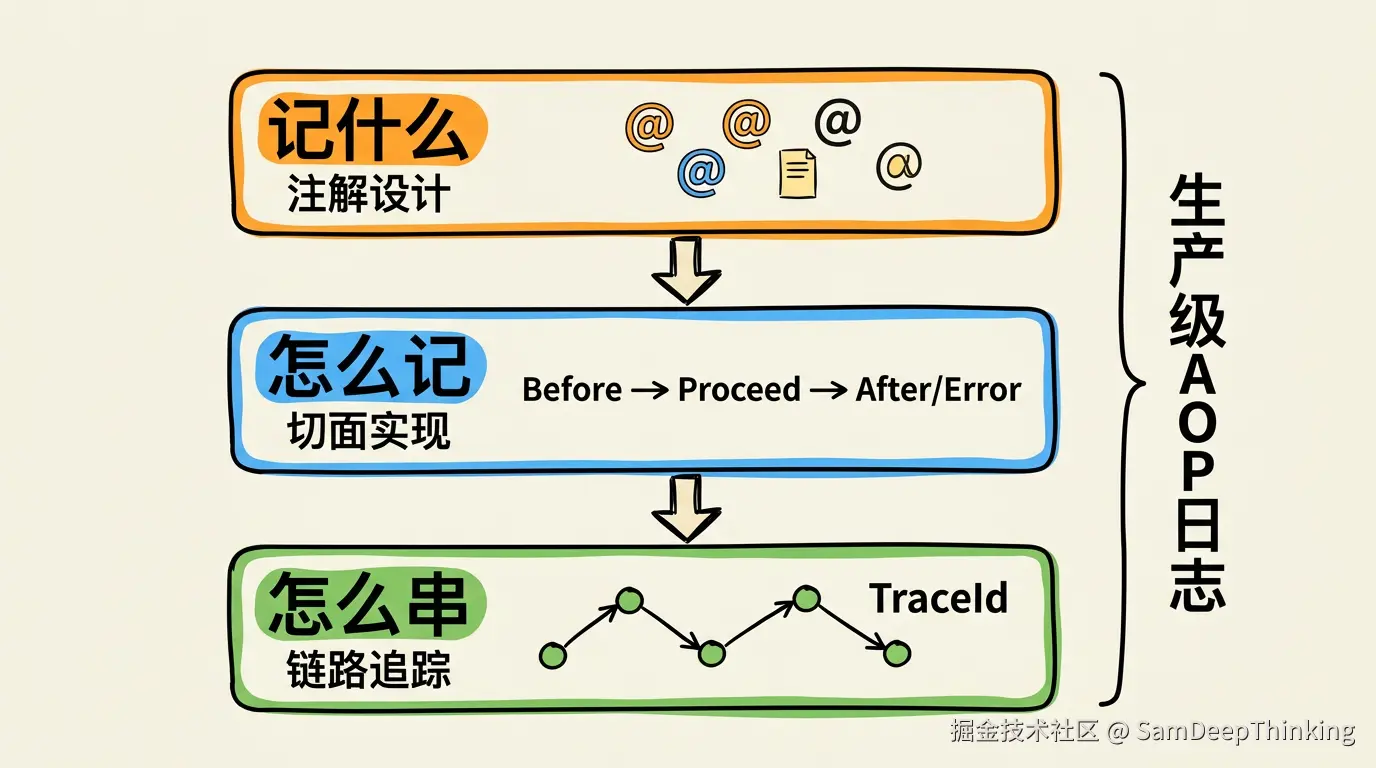
记什么,注解设计决定了日志携带哪些业务信息。是只打方法名,还是带上模块编码、事件类型、耗时阈值?
怎么记,切面实现决定了日志的生命周期管理和异常处理策略。正常返回和抛异常的日志怎么区分?业务异常和系统异常用什么级别?
怎么串,链路追踪决定了跨服务调用时日志能不能关联起来。一个请求从网关进来,经过3个微服务,最终写了数据库,你能不能用一个ID把这条链路上所有的日志串起来?
教程通常只讲第二层的皮毛,生产环境三层都要做到位。下面按这三个层面逐个展开。
注解设计
教程里的日志注解通常就一个空壳:
less
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Log {
}这种注解只能告诉切面「这个方法需要记日志」,至于记什么、怎么分类,切面得自己去猜。
生产环境里的注解设计分化出了几种不同的思路。
带业务分类的注解
其中一个项目用的是ModuleLog注解,强制要求标注模块和事件:
less
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface ModuleLog {
// 模块编码,从枚举取值
String moduleCode();
// 模块名称
String moduleName();
// 事件编码
String eventCode();
// 事件名称
String eventName();
}用的时候长这样:
less
@GetMapping("/getOrderDetail")
@ModuleLog(
moduleCode = "order",
moduleName = "订单",
eventCode = "getOrderDetail",
eventName = "查询订单详情"
)
public Result<OrderDetailVO> getOrderDetail(...) {
}moduleCode和moduleName是从一个统一的枚举里取值,不允许随便写字符串。这样做的好处是日志带上了业务语义,你在日志平台里可以直接按模块筛选,也可以针对特定模块配置告警规则。比如订单模块的异常率突然升高,运维能第一时间收到通知,不需要从一堆混在一起的日志里肉眼去找。
带屏蔽控制的注解
框架层还提供了一个LogIgnore注解,用来处理参数或返回值太大的情况:
less
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface LogIgnore {
// 忽略入参
boolean ignoreArgs() default false;
// 忽略返回结果
boolean ignoreReturn() default false;
}有些接口的入参是一个很大的JSON对象,或者返回值是一个几千条记录的列表。把这些内容全序列化成字符串写进日志,IO开销会很大,甚至可能拖慢接口响应。LogIgnore就是用来解决这个问题的,在方法上标注一下,切面在采集参数的时候会跳过序列化。
带性能阈值的注解
另一个项目用了不同的思路。它的TimeLogPrint注解可以设一个耗时阈值,只有超过阈值的调用才记录:
less
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface TimeLogPrint {
// 打印名称,默认用方法名
String value() default "";
// 耗时阈值(毫秒),0表示总是记录
long costTime() default 0;
// 是否打印入参
boolean args() default true;
// 是否打印出参
boolean result() default true;
}这种设计适合高频调用的接口。比如一个正常情况下50ms返回的接口,你不想每次都打日志,但超过200ms的时候需要记录下来做排查。costTime就是这个阈值。
四种模式对比
四种注解设计模式放在一起对比:
| 模式 | 代表注解 | 适用场景 | 核心特点 |
|---|---|---|---|
| 纯标记型 | @Log | 框架层自动记录所有Controller | 零配置,切面自动采集所有信息 |
| 业务分类型 | @ModuleLog | 需要按模块、事件检索和告警 | 日志带业务语义,便于分类管理 |
| 性能监控型 | @TimeLogPrint | 高频接口,只关注慢调用 | 支持耗时阈值,超标才记录 |
| 选择屏蔽型 | @LogIgnore | 参数或返回值数据量大 | 按需关闭入参/出参的序列化 |
实际项目里这几种模式不是互斥的,经常组合使用。框架层用@Log做兜底,确保每个接口都有基础日志;业务层叠加@ModuleLog,给日志加上业务分类;个别接口参数特别大的,再加一个@LogIgnore屏蔽入参序列化。
切面实现
注解定义好了,切面才是干活的部分。
为什么生产环境都用@Around
@Before和@After是两个独立的方法,它们之间没法共享状态。你想在@Before里记录开始时间,在@After里计算耗时,你得把开始时间存到ThreadLocal或者成员变量里,引入额外的复杂度。异常场景更麻烦:@AfterThrowing能拿到异常对象,但它和@AfterReturning是互斥的,你没法在一个统一的地方根据「正常还是异常」做不同的日志处理。
@Around把整个方法的前、中、后都包在一个方法里,开始时间、返回值、异常对象都是局部变量,天然共享。你可以根据异常类型用不同的日志级别,可以在finally里做资源清理,可以决定异常是重新抛出还是转换后再抛。
模板方法模式
框架层的切面代码极其精简,只有一行核心逻辑:
java
@Aspect
public class RestControllerAspect {
@Pointcut("@within(org.springframework.web.bind.annotation.RestController)")
public void pointcut() {
}
@Around("pointcut()")
public Object around(ProceedingJoinPoint proceedingJoinPoint)
throws Throwable {
return new HttpLogBuilder(proceedingJoinPoint).save().thenReturn();
}
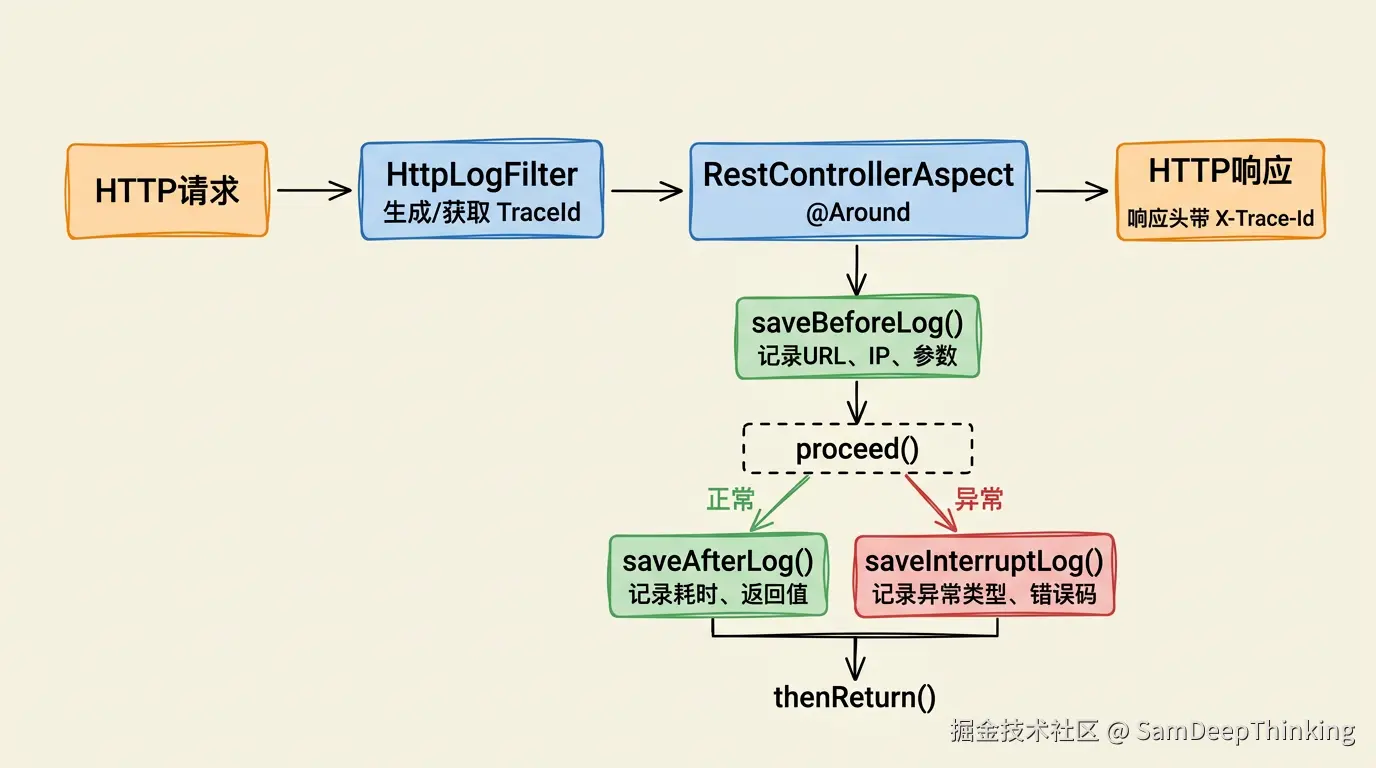
}切面本身没有任何日志逻辑,所有的工作都委托给了HttpLogBuilder。HttpLogBuilder继承自一个抽象的LogBuilder类,这里用的是模板方法模式。
LogBuilder定义了日志记录的完整生命周期:
csharp
public abstract class LogBuilder {
private final ProceedingJoinPoint proceedingJoinPoint;
private Object result;
private long beginTime;
private long finishTime;
private Throwable throwable;
// 三个抽象方法,由子类实现
protected abstract void saveBeforeLog();
protected abstract void saveAfterLog();
protected abstract void saveInterruptLog();
public LogBuilder save() throws Throwable {
beginTime = System.currentTimeMillis();
saveBeforeLog();
try {
result = proceedingJoinPoint.proceed();
finishTime = System.currentTimeMillis();
saveAfterLog();
} catch (Throwable e) {
throwable = e;
finishTime = System.currentTimeMillis();
saveInterruptLog();
}
return this;
}
public Object thenReturn() throws Throwable {
if (null != throwable) {
throw throwable;
}
return result;
}
}save()方法是整个模板的骨架,执行顺序是:记录开始时间 → saveBeforeLog() → 执行目标方法 → 正常则saveAfterLog(),异常则saveInterruptLog() → 记录结束时间。
这里有个设计细节值得注意:save()和thenReturn()是分开的两个方法。save()负责执行目标方法和记录日志,thenReturn()负责处理异常的重新抛出。save()的catch块里故意没有直接throw,而是把异常存到了成员变量里,等thenReturn()的时候再抛。这样做是为了确保不管目标方法是正常返回还是抛异常,日志记录的逻辑都一定能执行完。如果在catch里直接throw,而saveInterruptLog()本身又出了异常(比如JSON序列化报错),原始的业务异常就会被覆盖掉,排查问题的时候拿到的是日志框架的异常而不是业务异常。
框架层根据不同的使用场景,提供了多个LogBuilder子类:HttpLogBuilder处理HTTP请求、GenericLogBuilder处理通用方法调用、还有针对Dubbo、RocketMQ、XxlJob的专用子类。切面只负责选择合适的Builder,具体的日志格式和处理逻辑全在Builder里。这种分离让新增一种日志场景变得很简单:写一个新的Builder子类,再写一个对应的切面注册上去。
HTTP日志的具体实现
HttpLogBuilder是最常用的子类,专门处理HTTP请求的日志。它的三个方法实现了完整的请求日志采集:
less
public class HttpLogBuilder extends LogBuilder {
private static final Logger LOGGER =
LoggerFactory.getLogger(HttpLogBuilder.class);
@Override
protected void saveBeforeLog() {
LOGGER.info(
"url[{}] ip[{}] action[{}:{}] status[invoke] args[{}]",
HttpLogUtil.getUri(),
WebUtils.getIP(),
GenericLogUtil.getClassName(getProceedingJoinPoint()),
GenericLogUtil.getMethodName(getProceedingJoinPoint()),
GenericLogUtil.toJsonString(
GenericLogUtil.getArgs(getProceedingJoinPoint()))
);
}
@Override
protected void saveAfterLog() {
LOGGER.info(
"url[{}] code[{}] action[{}:{}] status[success] cost[{}] result[{}]",
HttpLogUtil.getUri(),
HttpLogUtil.getHttpStatus(),
GenericLogUtil.getClassName(getProceedingJoinPoint()),
GenericLogUtil.getMethodName(getProceedingJoinPoint()),
Math.max(getFinishTime() - getBeginTime(), 0),
GenericLogUtil.toJsonString(
GenericLogUtil.getReturn(
getProceedingJoinPoint(), getLogData()))
);
}
@Override
protected void saveInterruptLog() {
if (getThrowable() instanceof BusinessException) {
BusinessException exception =
(BusinessException) getThrowable();
LOGGER.warn(
"url[{}] action[{}:{}] status[fail] cost[{}] error[{}] message[{}]",
HttpLogUtil.getUri(),
GenericLogUtil.getClassName(getProceedingJoinPoint()),
GenericLogUtil.getMethodName(getProceedingJoinPoint()),
Math.max(getFinishTime() - getBeginTime(), 0),
exception.getCode(),
exception.getMessage()
);
return;
}
// 未知异常
LOGGER.warn(
"url[{}] action[{}:{}] status[fail] cost[{}] error[internal-error]",
HttpLogUtil.getUri(),
GenericLogUtil.getClassName(getProceedingJoinPoint()),
GenericLogUtil.getMethodName(getProceedingJoinPoint()),
Math.max(getFinishTime() - getBeginTime(), 0),
getThrowable()
);
}
}这段代码有几个关键的设计决策。
日志格式用的是key[value]的固定格式,实际输出长这样:
css
url[/api/order/detail] ip[192.168.1.100] action[OrderController:getOrderDetail] status[invoke] args[{"id":123}]
url[/api/order/detail] code[200] action[OrderController:getOrderDetail] status[success] cost[45] result[{...}]这种格式在日志平台里可以直接用正则提取字段做索引。你可以在Kibana里写一条查询:status:fail AND url:/api/order/*,瞬间筛出订单模块所有失败的请求。纯文本的日志做不到这种精度。
异常分级处理也值得看一下。BusinessException是业务异常,代码逻辑正常走完了,只是业务规则不满足(比如库存不足、权限不够),这种用warn级别就够了。参数校验异常InvalidParamException同理。只有捕获到未预期的Exception才意味着代码出了真正的Bug,需要用更高的告警等级。如果不做这个区分,你的告警系统会被大量的业务异常淹没,真正需要关注的系统异常反而被埋在里面。
saveAfterLog里调用了getLogData()而不是直接getResult()。这个方法在LogBuilder里有一段逻辑:生产环境下返回一个占位符而不是真实的返回值。接口返回值经常是很大的JSON对象,全序列化到日志里IO开销太高,只有非生产环境才打印完整返回值,生产环境只记录请求参数和耗时。
业务层的补充切面
框架层的RestControllerAspect会自动拦截所有Controller方法,不需要加注解。业务层在这个基础上可以叠加自己的切面,做更精细的日志记录。
ModuleLogAspect就是一个典型的补充切面。它只在异常时记录(正常情况框架层已经记了),而且带上了业务模块信息:
less
@Aspect
@Component
@Slf4j
public class ModuleLogAspect {
@Around("@annotation(moduleLog)")
public Object around(ProceedingJoinPoint pjp, ModuleLog moduleLog)
throws Throwable {
try {
return pjp.proceed();
} catch (InvalidParamException e) {
// 参数异常不额外记录,直接抛出
throw e;
} catch (BusinessException e) {
logException(pjp, moduleLog, e);
throw e;
} catch (Exception e) {
logException(pjp, moduleLog, e);
throw e;
}
}
private void logException(
ProceedingJoinPoint pjp,
ModuleLog moduleLog,
Throwable e) {
Object[] args = pjp.getArgs();
Object firstArg =
args != null && args.length > 0 ? args[0] : null;
StructuredLog.error(log)
.message(moduleLog.eventName() + "失败")
.exception(e)
.moduleCode(moduleLog.moduleCode())
.moduleName(moduleLog.moduleName())
.eventCode(moduleLog.eventCode())
.eventName(moduleLog.eventName())
.put("param", JSON.toJSONString(firstArg))
.log();
}
}这个切面的设计思路跟框架层不同:它不是全量记录的,只关注异常场景。InvalidParamException直接跳过,BusinessException和其他Exception才记录,并且带上了模块编码和事件名称。这样在日志平台搜索的时候,可以快速按模块筛选异常,比如「找出订单模块最近一小时所有的异常日志」。
结构化日志
前面的ModuleLogAspect里用了一个StructuredLog来输出日志。结构化日志是生产环境和教程代码之间差异最大的部分之一。
教程里的日志输出通常是这样的:
c
log.info("方法{}执行完成,参数:{},返回值:{}", methodName, args, result);这种纯文本日志在控制台上看着还行,到了ELK或者Loki这样的日志平台上,你没法直接对「方法名」「参数」「返回值」做字段查询。只能做全文搜索,效率差距很大。
StructuredLog用Builder模式构建了一个带业务字段的JSON日志输出工具:
typescript
@Slf4j
public class StructuredLog {
private final Map<String, Object> fields = new LinkedHashMap<>();
private final LogLevel level;
private final Logger logger;
private String message;
private Throwable throwable;
// 静态工厂方法,传入调用方的logger
public static StructuredLog info(Logger logger) {
return new StructuredLog(LogLevel.INFO, logger);
}
public static StructuredLog error(Logger logger) {
return new StructuredLog(LogLevel.ERROR, logger);
}
// 通用键值对
public StructuredLog put(String key, Object value) {
if (key != null && value != null) {
fields.put(key, value);
}
return this;
}
// 预设的业务字段快捷方法
public StructuredLog userId(String userId) {
return put("userId", userId);
}
public StructuredLog shopId(Integer shopId) {
return put("shopId", shopId);
}
public StructuredLog moduleCode(String moduleCode) {
return put("moduleCode", moduleCode);
}
public StructuredLog costTime(Long costTime) {
return put("costTime", costTime);
}
// 输出日志
public void log() {
String logContent = buildLogContent();
switch (level) {
case ERROR:
if (throwable != null) {
logger.error(logContent, throwable);
} else {
logger.error(logContent);
}
break;
// INFO、WARN、DEBUG同理
}
}
private String buildLogContent() {
StringBuilder sb = new StringBuilder();
if (message != null && !message.isEmpty()) {
sb.append(message).append(" || ");
}
// JSON格式输出,便于日志平台解析
sb.append(JSON.toJSONString(fields));
return sb.toString();
}
}调用的时候:
vbscript
StructuredLog.error(log)
.message("查询订单详情失败")
.exception(e)
.moduleCode("order")
.moduleName("订单")
.eventCode("getOrderDetail")
.put("param", JSON.toJSONString(request))
.log();输出的日志长这样:
bash
查询订单详情失败 || {"moduleCode":"order","moduleName":"订单","eventCode":"getOrderDetail","param":"{"id":123}"}前半段是可读的消息文本,后半段是JSON格式的结构化字段。||作为分隔符。日志平台可以按||拆分,右边的JSON直接解析成字段做索引。你在Kibana或Grafana里就能用moduleCode:order AND eventCode:getOrderDetail这样的条件精确查询。
StructuredLog还有一个设计值得注意:它给常见的业务字段预设了快捷方法(userId、shopId、moduleCode、costTime等),同时保留了通用的put()方法。预设字段保证了团队内日志字段命名的一致性,不会出现一个人写userId另一个人写user_id的情况。这种一致性在日志平台做聚合分析的时候尤其关键。
日志不是写给自己看的,是写给三个月后凌晨三点被叫起来排查问题的那个人看的。 结构化的日志格式,加上统一的字段命名,能让排查效率有质的提升。
链路追踪
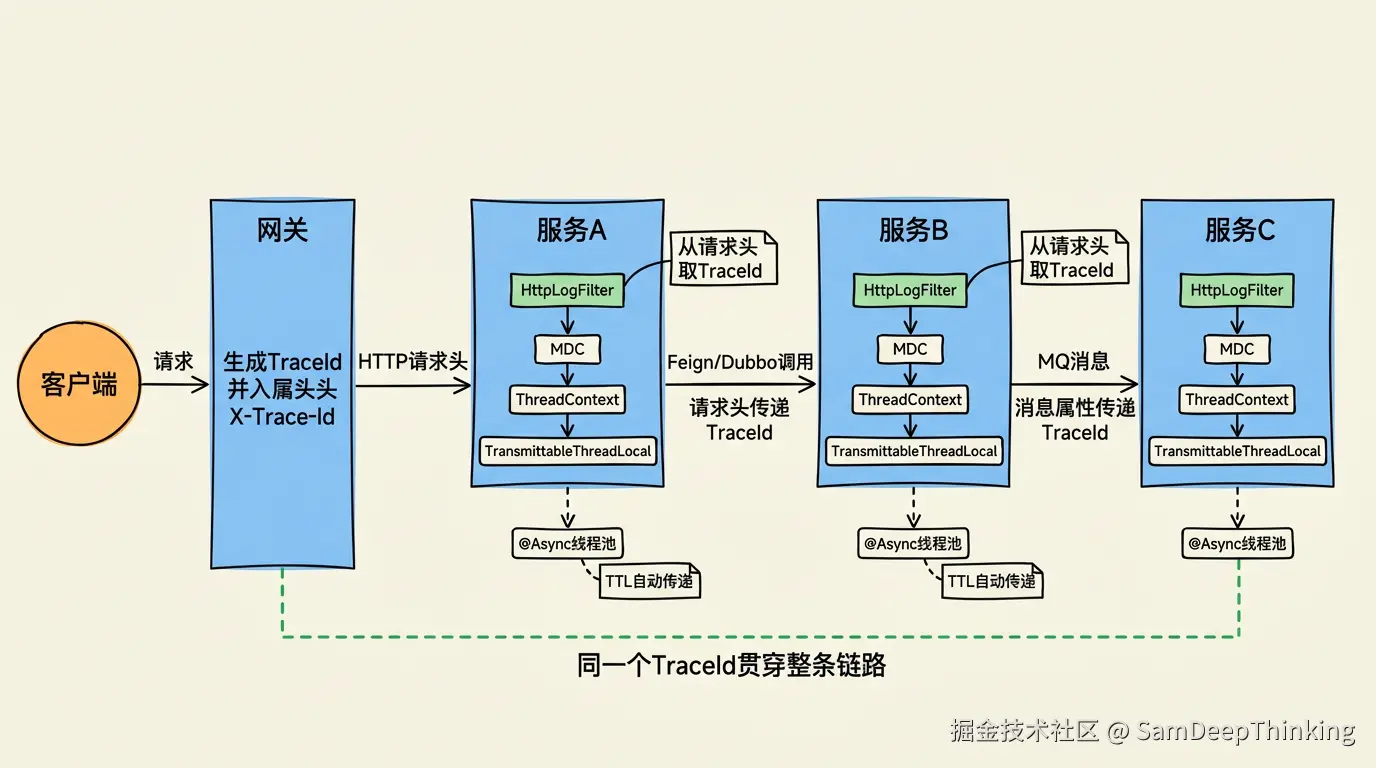
一个请求进来,调了3个微服务,写了2次数据库,发了1条消息。这些操作分散在不同的服务实例上,日志也分散在不同的日志文件里。怎么把它们串起来?靠链路ID。
链路ID的生成和传递
框架层用一个HttpLogFilter在请求入口处理链路ID:
scala
public class HttpLogFilter extends TraceIdHandler implements Filter {
@Override
public void doFilter(
ServletRequest request,
ServletResponse response,
FilterChain filterChain)
throws IOException, ServletException {
try {
if (request instanceof HttpServletRequest
&& response instanceof HttpServletResponse) {
// 从请求头取链路ID
String traceId = ((HttpServletRequest) request)
.getHeader("X-Trace-Id");
// 没有就生成一个新的UUID
traceId = settingTraceId(traceId);
// 写入响应头
((HttpServletResponse) response)
.addHeader("X-Trace-Id", traceId);
}
filterChain.doFilter(request, response);
} finally {
// 请求结束,清理线程变量
clearContext();
}
}
}如果上游(比如网关或者其他微服务)已经在请求头里带了X-Trace-Id,Filter就直接沿用;如果没有(说明这是链路的起点),就生成一个UUID。生成之后写入响应头,前端拿到响应后也能拿到链路ID。用户反馈问题的时候把链路ID发过来,后端直接在日志平台搜这个ID就能看到完整的调用链路。
三层存储
生成了链路ID之后,要把它放到当前线程的上下文里,后续所有的日志输出都自动带上这个ID。TraceIdHandler做这件事:
typescript
public class TraceIdHandler {
public String settingTraceId(String traceId) {
if (StringUtils.isBlank(traceId)) {
traceId = GenericLogUtil.generateTraceId();
}
// 存到自定义的上下文里(支持线程池传递)
LogContext.putTraceId(traceId);
// 存到SLF4J的MDC里
MDC.put("traceId", traceId);
// 存到Log4j2的ThreadContext里
ThreadContext.put("traceId", traceId);
return traceId;
}
public void clearContext() {
LogContext.clear();
ThreadContext.remove("traceId");
MDC.remove("traceId");
}
}链路ID被存了三份:LogContext、SLF4J MDC、Log4j2 ThreadContext。为什么要存三份?因为不同的日志框架从不同的地方读取上下文变量。用Logback的项目从MDC读,用Log4j2的项目从ThreadContext读,业务代码里需要主动获取链路ID的时候从LogContext读。三个都设置了,不管项目用哪个日志框架都能取到值。
在日志配置文件里用%X{traceId}引用这个变量,每一行日志就会自动带上链路ID,不需要在业务代码里手动传递。
TransmittableThreadLocal
LogContext的实现用了TransmittableThreadLocal:
typescript
public class LogContext {
private static final TransmittableThreadLocal<String> traceIdTL =
new TransmittableThreadLocal<>();
public static void putTraceId(String traceId) {
traceIdTL.set(traceId);
}
public static String getTraceId() {
return traceIdTL.get();
}
public static void clear() {
traceIdTL.remove();
}
}这里用的是TransmittableThreadLocal而不是普通的ThreadLocal,这个选择直接关系到链路ID在异步场景下能不能正常传递。
普通ThreadLocal只在当前线程有效。业务代码里一旦用了@Async或者自定义线程池,新线程里的ThreadLocal就是空的,链路ID断了。这是生产环境里链路断裂最常见的原因。查一个请求的日志,前半截有traceId,到了某个异步操作之后突然没了,后面的日志全搜不到。
TransmittableThreadLocal是阿里开源的一个库(maven坐标是com.alibaba:transmittable-thread-local),它能在线程池提交任务的时候,自动把父线程的ThreadLocal值拷贝给子线程。配合TtlExecutors.getTtlExecutorService()对线程池做一层包装,链路ID在@Async、CompletableFuture、自定义线程池这些场景下都能正常传递。
MDC和ThreadContext本身不具备这个能力,所以才额外需要LogContext用TransmittableThreadLocal存一份。在异步线程里,即使MDC的值丢了,也可以从LogContext取到链路ID重新设置回MDC。
自动装配
框架层的日志能力是通过Spring Boot自动装配提供给业务服务的。业务服务在pom.xml里引入starter依赖,不需要写任何配置代码,切面、过滤器、拦截器全部自动生效。
LogAutoConfiguration是装配的入口:
typescript
@Configuration
@EnableConfigurationProperties(LogProperties.class)
@ConditionalOnProperty(
prefix = "app.log",
name = "enable",
havingValue = "true",
matchIfMissing = true)
public class LogAutoConfiguration {
// Web应用才注册HTTP相关组件
@Bean
@ConditionalOnWebApplication
public RestControllerAspect restControllerAspect() {
return new RestControllerAspect();
}
// 过滤器注册,优先级最高
@Bean
@ConditionalOnWebApplication
public FilterRegistrationBean<HttpLogFilter> httpLogFilterRegistration() {
FilterRegistrationBean<HttpLogFilter> registration =
new FilterRegistrationBean<>();
registration.setFilter(new HttpLogFilter());
registration.addUrlPatterns("/*");
registration.setOrder(Ordered.HIGHEST_PRECEDENCE);
return registration;
}
// 引了XxlJob依赖才注册定时任务切面
@Bean
@ConditionalOnMissingBean
@ConditionalOnClass(
name = "com.xxl.job.core.log.XxlJobFileAppender")
public XxlJobLogAspect xxlJobLogAspect() {
return new XxlJobLogAspect();
}
// 引了Dubbo依赖才注册RPC切面
@Bean
@ConditionalOnMissingBean
@ConditionalOnClass(
name = "org.apache.dubbo.config.ServiceConfig")
public RpcServiceAspect rpcServiceAspect() {
return new RpcServiceAspect();
}
// 引了RocketMQ依赖才注册消息队列切面
@Configuration
@ConditionalOnClass(
name = "com.example.framework.mq.RocketMQProducer")
protected static class RocketMqConfig {
@Bean
@ConditionalOnMissingBean
public RocketMqProducerAspect rocketMQTemplateAspect() {
return new RocketMqProducerAspect();
}
@Bean
@ConditionalOnMissingBean
public RocketMqListenerAspect rocketMqListenerAspect() {
return new RocketMqListenerAspect();
}
}
}整个配置类的设计思想是按需装配。@ConditionalOnWebApplication保证只有Web应用才注册HTTP相关组件。@ConditionalOnClass按类路径判断:项目引了Dubbo依赖就自动装配Dubbo日志切面,引了RocketMQ依赖就装配消息队列日志切面,引了XxlJob依赖就装配定时任务日志切面。没引对应依赖的服务,相关的切面根本不会被创建,不会有任何额外开销。
HttpLogFilter的注册优先级设成了Ordered.HIGHEST_PRECEDENCE,保证它是第一个执行的过滤器。链路ID在所有后续过滤器和切面执行之前就已经设置好了,后面的日志输出都能带上这个ID。
配合spring.factories做自动发现,业务服务引入依赖后,每个Controller方法的调用自动有日志,每个请求自动有链路ID,异常自动按类型分级。需要加业务分类的,在方法上标一个@ModuleLog;需要屏蔽大参数的,标一个@LogIgnore。
落地检查清单
把生产级AOP日志需要考虑的点整理成一张表:
| 检查项 | 说明 |
|---|---|
| 注解是否携带业务语义 | 模块编码、事件类型、操作类型,便于按业务维度检索和告警 |
| 切面是否用@Around | @Before+@After无法共享状态,无法统一处理异常分级 |
| 异常是否分级处理 | 业务异常warn,系统异常error,参数校验异常可跳过 |
| 日志格式是否结构化 | JSON或key[value]固定格式,能被日志平台解析成字段 |
| 字段命名是否统一 | 团队内userId、shopId、traceId等字段名保持一致 |
| 链路ID是否用TransmittableThreadLocal | 普通ThreadLocal在线程池场景下会丢失 |
| 链路ID是否写入响应头 | 前端拿到链路ID可以直接发给后端排查 |
| 大参数是否有屏蔽机制 | @LogIgnore防止日志序列化拖慢接口响应 |
| 生产环境是否屏蔽返回值 | 返回值数据量通常很大,生产环境可以只记占位符 |
| 是否通过starter自动装配 | 业务方引入依赖即可,不需要手动配置切面和过滤器 |
小结
AOP日志在很多人印象里是一个入门级的话题,面试的时候答个@Around加ProceedingJoinPoint就过了。实际上在生产环境里,它承载的东西比面试答案里讲的多得多。注解不只是一个空标记,它是日志的数据模型定义;切面不只是打两行log,它要处理异常分级、性能控制、上下文传递;日志输出格式直接决定了线上排查的效率。
从更大的视角看,AOP日志切面是整个可观测性体系的基础设施。日志、指标、链路追踪是可观测性的三个维度,一个设计到位的AOP切面能同时为这三个维度提供数据:切面记录的耗时可以转化为接口响应时间的指标,链路ID可以在分布式追踪系统里关联完整的调用链,异常日志可以触发告警。写好这一层,相当于给每个服务入口自动装了一个观测点,业务开发者不需要额外操心,服务上线就自带完整的可观测能力。
希望这篇内容可以帮到你。
我最近在知乎写了一个秒杀专栏(应付6000万会员级别的)和开了星球,有兴趣的可以订阅和加入,一起交流。
- 知乎账号:SamDeepThinking
- 星球:老码头的技术浮生录