介绍:
- 核心思想主要是利用多线程的方法,让多个环境并行的运行,在探索性策略的情况下,让agent能够在每一个step都有更多的探索性,尽快找到最优策略。
- 抛弃DQN,DDPG,等算法中的replay buffer,采用on-line的方式学习。replay buffer会将数据存储起来供学习,其数据来源于旧的policy,on-line的方式的数据来自于刚刚更新的新policy。
- 在多线程的情况下,每个agent有独立的环境,也面对不同的state,在多核cpu上,每个agent以不同的策略独立探索,大大增加了数据的多样性,同时数据天然的是相互独立的。
- 网络参数是在线程之间异步更新的,而且是Lock free的,不需要互斥。
该方法可以用在不同的算法上,论文中介绍了四种算法的异步应用:
Async Q-Learning和Async n-Step Q-Learning:


在主线程上维护一个统一的global net,每个线程有独立的local net。当线程内满足terminal或特定步数后,更新local net。当所有线程的总步数满足特定条件后,将local net的参数复制给global net。
在n-step Q-Learning中,线手机n步的数据,再更新参数。这里n-step的最后一步的return计算方式和中间步骤的计算方式不太一样,最后一步是
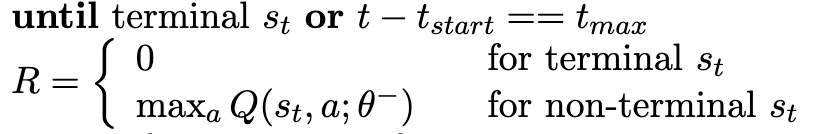
而中间步是:
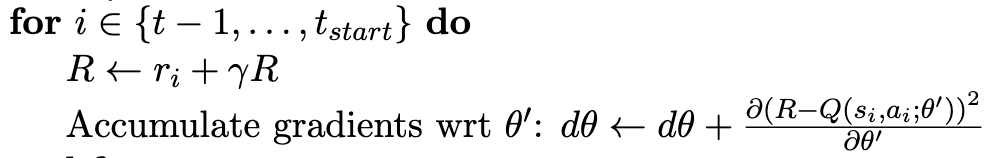
且需要每一步累计梯度。
Async one-Step SARSA和Async n-Step SARSA
和Async Q-Learning基本差不多,主要是把TD-target从变成了
Async Advantage Actor-critic

一个global的公共critic用来输出q-value,一个global的公共actor用来输出policy
这里也采用了n-step的方法,先收集一部分数据。也因此在更新过程中,它的优势函数就用
代替了标准A2C算法中的
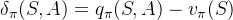
同时,将策略的entropy添加的目标函数中,可以组织网络过早的收敛到次优解,从而改善探索性。包含entropy的目标函数是:
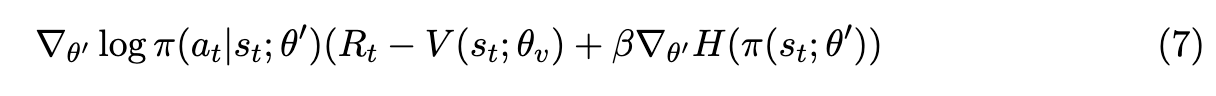
其中H就是策略的entropy,超参数β控制熵正则化项的强度。