摘要:本文面向智慧交通场景,设计并实现一套行人车辆检测与计数识别系统,围绕 YOLOv5 至 YOLOv12 的升级脉络,给出从模型训练到工程落地的完整实现。系统支持图片、视频与摄像头输入,实时输出行人/车辆检测框、类别与置信度,并实现区域计数、进出统计与结果汇总;采用 PySide6 构建可交互界面,支持权重切换、Conf/IOU 调节、可视化展示与结果保存导出。文中提供数据集构建与标注规范、训练/验证/测试流程及多版本模型的性能对比分析(mAP、F1、PR、速度等),同时给出完整代码、界面与数据集项目,便于复现与二次开发。
讲解视频地址: https://www.bilibili.com/video/BV1drdHBFEB5/
文章目录
- [1 前沿综述](#1 前沿综述)
- [2. 数据集介绍](#2. 数据集介绍)
- [3. 模型设计与实现](#3. 模型设计与实现)
- [4. 训练策略与模型优化](#4. 训练策略与模型优化)
- [5. 实验与结果分析](#5. 实验与结果分析)
-
- [5.1 实验设置与对比基线](#5.1 实验设置与对比基线)
- [5.2 度量指标](#5.2 度量指标)
- [5.3 实验结果与分析](#5.3 实验结果与分析)
- [6. 系统设计与实现](#6. 系统设计与实现)
-
- [6.1 系统设计思路](#6.1 系统设计思路)
- [6.2 登录与账户管理](#6.2 登录与账户管理)
- [7. 下载链接](#7. 下载链接)
- [8. 参考文献(GB/T 7714)](#8. 参考文献(GB/T 7714))
1 前沿综述
在智慧交通与城市治理的典型闭环中,"行人---车辆"的检测、跟踪与计数既是交通流状态估计、拥堵预警与安全事件溯源的基础输入,也是面向边缘端实时部署时最容易暴露工程短板的环节:一方面,监控视角下的行人目标往往呈现小尺度、密集遮挡与跨帧形变等特征,另一方面,车辆目标受视角透视、运动模糊与光照天气变化影响显著,导致同一模型在"白天主干道---夜间路口---雨雾高架"等域之间出现明显性能漂移。1 (CJIG)
国内研究在工程可落地性上积累了较多经验,例如已有工作将改进的 YOLO 检测器与 DeepSORT 级联,用以缓解道路车辆检测中遮挡严重与小目标漏检带来的轨迹断裂与计数偏差,并从锚框聚类、浅层特征增强与多尺度输出等角度提升远近车辆的鲁棒性。2 (transport.chd.edu.cn)
从更广义的目标检测谱系来看,近年的综述普遍认为交通场景的核心矛盾并不只在"精度是否够高",而是在算力受限、数据分布多变与评价指标多维约束下,如何在特征表达、训练策略与部署形态之间取得可复现的平衡。3 (CEA)
在深度学习成为主流之前,行人检测更依赖手工特征与浅层分类器的组合,其中 HOG 特征通过梯度方向直方图与块归一化实现对局部形状的较强刻画,一度成为行人检测的事实标准基线。4 (dblp)
进入深度学习阶段后,两阶段检测器以候选区域生成与精细分类回归的分工获得了更强的精度上限,其中 Faster R-CNN 通过区域建议网络共享卷积特征,将候选框生成纳入端到端训练,从而显著提升了检测效率与质量。5 (arXiv)
然而,交通监控中的尺度跨度与小目标密集对特征金字塔提出了刚性需求,FPN 通过自顶向下路径与横向连接在多层语义之间建立一致表征,使得检测头能够在不同尺度上获得更稳定的语义特征。6 (CVF Open Access)
与两阶段路线并行演进的,是以速度为核心约束的单阶段检测框架,YOLO 将检测建模为从像素到边界框与类别概率的直接回归,从范式上降低了流水线复杂度,为实时交通感知提供了可部署的起点。7 (CV Foundation)
在数据层面,面向驾驶与道路环境的公开数据集为算法迭代提供了可比性基础,例如 BDD100K 以多任务、多域、多样化驾驶视频标注支撑了检测、分割与跟踪等研究的统一评测语境。8 (CVF Open Access)
针对车辆检测与多目标跟踪的强约束评测,UA-DETRAC 提供了面向真实交通视频的基准与协议,强调"检测精度---跟踪质量"之间的耦合关系,使得仅优化静态检测而忽视跨帧一致性的做法更难获得可靠的计数表现。9 (ScienceDirect)
为便于把研究现状与本文任务对齐,表1 汇总了从传统特征到检测、跟踪与交通专用基准的代表性路线,并对应说明其在"行人车辆检测与计数"链条上的适用范围与短板。
表1 代表性方法与数据集对比
| 方法范式 | 典型数据集/场景 | 优势侧重 | 主要瓶颈 | 代表文献 |
|---|---|---|---|---|
| 手工特征检测 | 行人近景、固定视角 | 解释性强、实现简单 | 遮挡/小目标/域变化下泛化弱 | 4 |
| 两阶段检测 | 通用检测与交通子域 | 精度上限高 | 推理延迟与部署复杂度较高 | 5 |
| 多尺度特征增强 | 小目标、尺度跨度大 | 提升小目标召回 | 仍依赖下游检测头设计 | 6 |
| 单阶段实时检测 | 实时监控与边缘推理 | 速度优势明显 | 密集遮挡下定位与分类易互相牵制 | 7 |
| 多任务驾驶数据 | 多域驾驶视频 | 支撑检测与跟踪联合评测 | 长尾类别与域偏移仍突出 | 8 |
| 交通基准与协议 | 车辆检测与跟踪 | 强化检测-跟踪耦合评测 | 对跨镜头泛化覆盖有限 | 9 |
在"计数"这一更贴近业务闭环的目标上,主流系统往往采用 tracking-by-detection,将检测框转化为跨帧轨迹并在虚拟线圈或 ROI 上触发事件计数,其中 ByteTrack 通过"关联几乎所有检测框"的策略显著缓解了遮挡导致的漏关联与轨迹碎片化问题。10 (Springer)
在形式化层面,若以轨迹集合 τ k {\tau_k} τk 表示目标 ID 的时序状态,计数可抽象为对穿越事件的求和:
N = ∑ k I ( τ k crosses L ) , N=\sum_{k}\mathbb{I}\big(\tau_k \ \text{crosses}\ \mathcal{L}\big), N=k∑I(τk crosses L),
其中 L \mathcal{L} L 为计数线或 ROI 边界, I ( ⋅ ) \mathbb{I}(\cdot) I(⋅) 为指示函数;这一抽象看似简单,但在遮挡、丢检与 ID-switch 频发时会被系统性放大为重复计数或漏计数。
围绕 YOLO 系列的持续升级,近年方法更强调在结构效率与训练目标之间做"可部署"的改进,例如 YOLOv7 通过可训练的免费增强策略与结构重整等设计,在速度区间内进一步推高了实时检测器的精度上限。11 (CVF Open Access)
在更近的迭代中,YOLOv9 通过可编程梯度信息与更高效的层聚合结构,试图缓解深网络训练中的信息损失与参数利用率问题,从而在保持实时属性的同时提升特征学习效率。12 (Springer)
进一步面向端到端部署,YOLOv10 以消除 NMS 依赖为重要目标,通过一致的双重分配与效率驱动的结构设计推进 NMS-free 的实时检测,使得推理延迟与部署链路更可控。13 (NeurIPS Proceedings)
对于工程界广泛采用的 Ultralytics 路线,已有工作系统梳理了从 YOLOv5 的模块化 PyTorch 基础到 YOLOv8、YOLO11 的效率导向演进,并给出在 COCO 等基准上的定量对照与部署视角分析,为"同一任务下横向比较 v5--v12 系列"提供了方法论参照。14 (arXiv)
值得注意的是,YOLOv12 将注意力机制引入实时 YOLO 框架的核心设计,通过注意力中心的架构在速度可比的前提下追求更强的建模能力,为密集遮挡与复杂背景下的行人车辆检测带来新的结构可能性。15 (arXiv)
基于上述背景,老思在本文的工作目标并不止于"训练一个能跑的检测模型",而是围绕行人车辆检测与计数的真实流程构建可复现实验与可交付系统:在同一数据与同一评测协议下对 YOLOv5 至 YOLOv12 系列进行横向对比,并给出面向计数任务的检测-跟踪一体化方案;面向交通监控域构建并整理专用数据集,完成标注、清洗、划分与可复用的数据组织;同时基于 PySide6 实现完整桌面端界面与工程化推理链路,提供从多源输入、可视化、阈值调参到结果导出与项目资源打包的一体化实现。
主要功能演示:
(1)启动与登录:程序启动进入登录页,支持注册/登录;登录成功后自动加载该用户的历史记录与个性化配置,并进入主界面开始检测任务。
启动与登录界面图
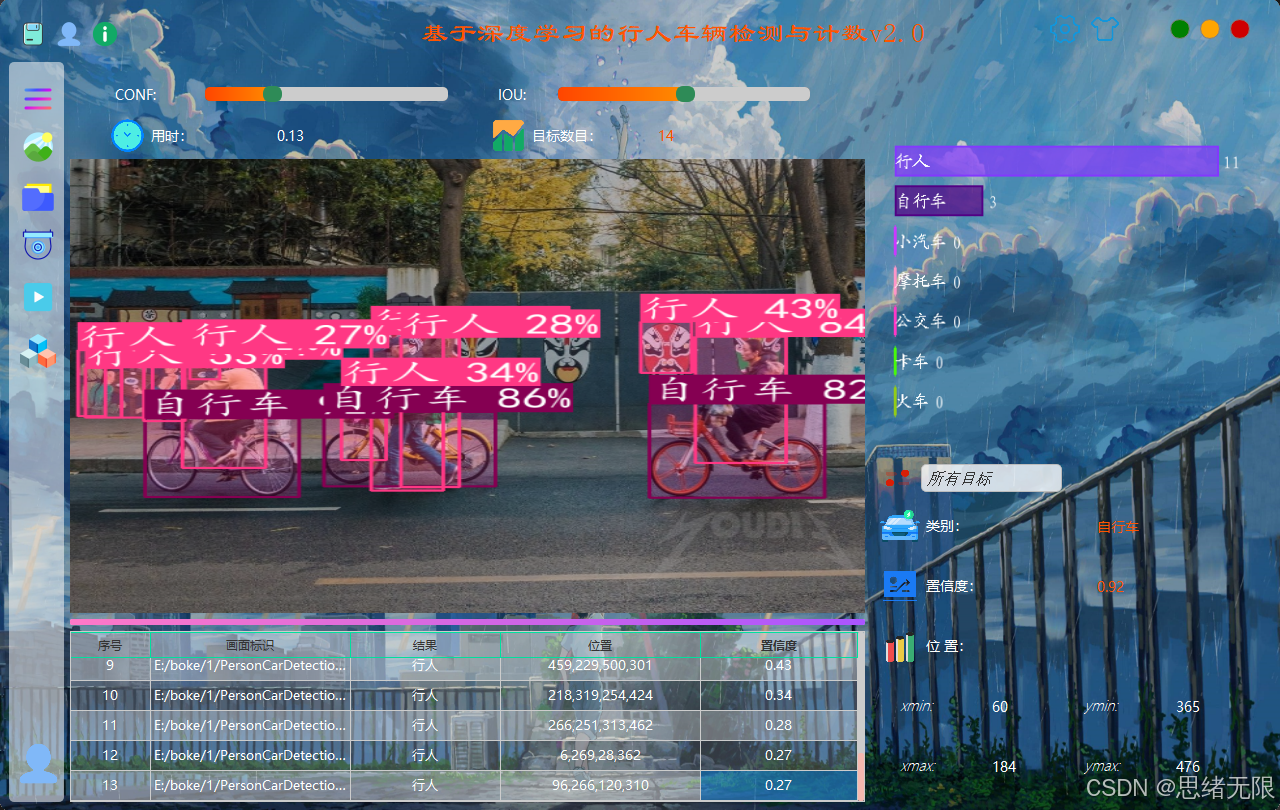
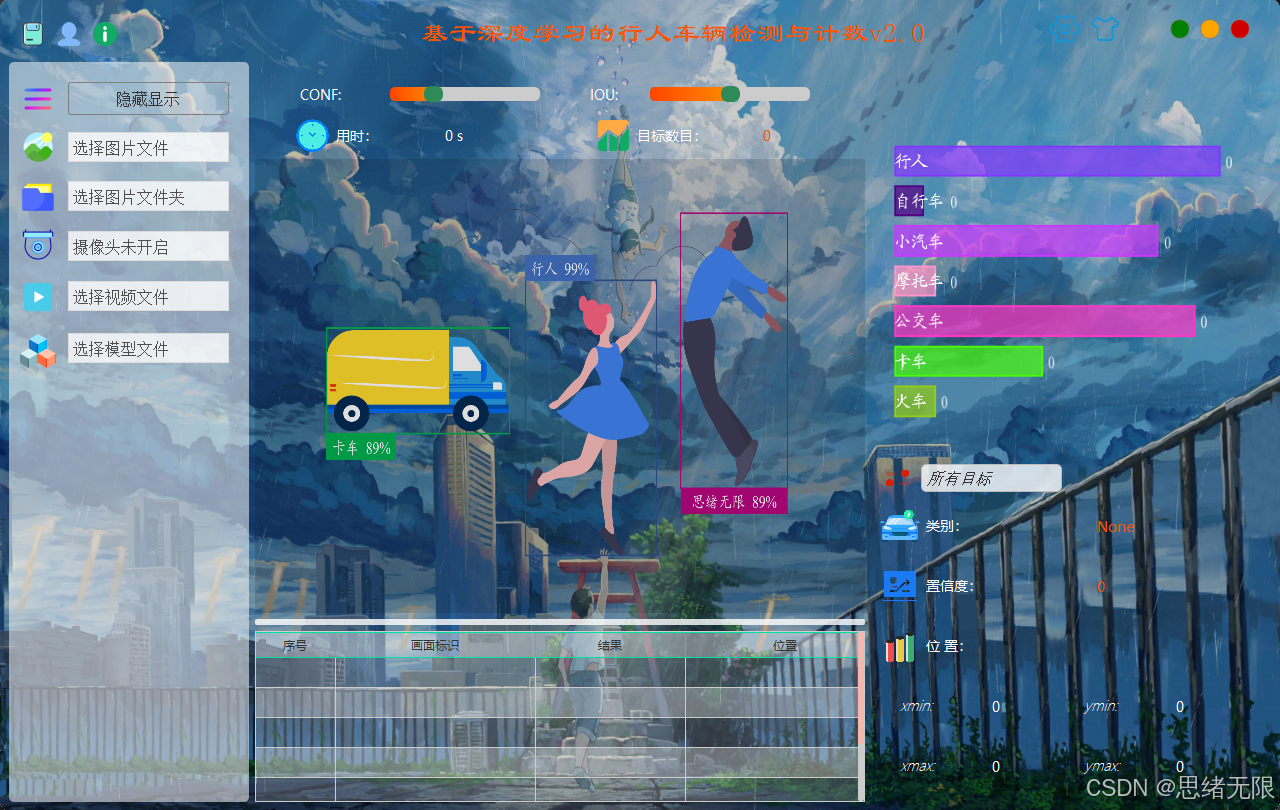
(2)多源输入与实时检测:主界面支持摄像头、视频、单张图片与图片文件夹四类输入源,一键切换并实时渲染检测框与类别置信度,同时展示行人/车辆数量统计;视频/摄像头支持播放控制,文件夹支持批量推理与结果汇总导出。
多源输入与实时检测演示图
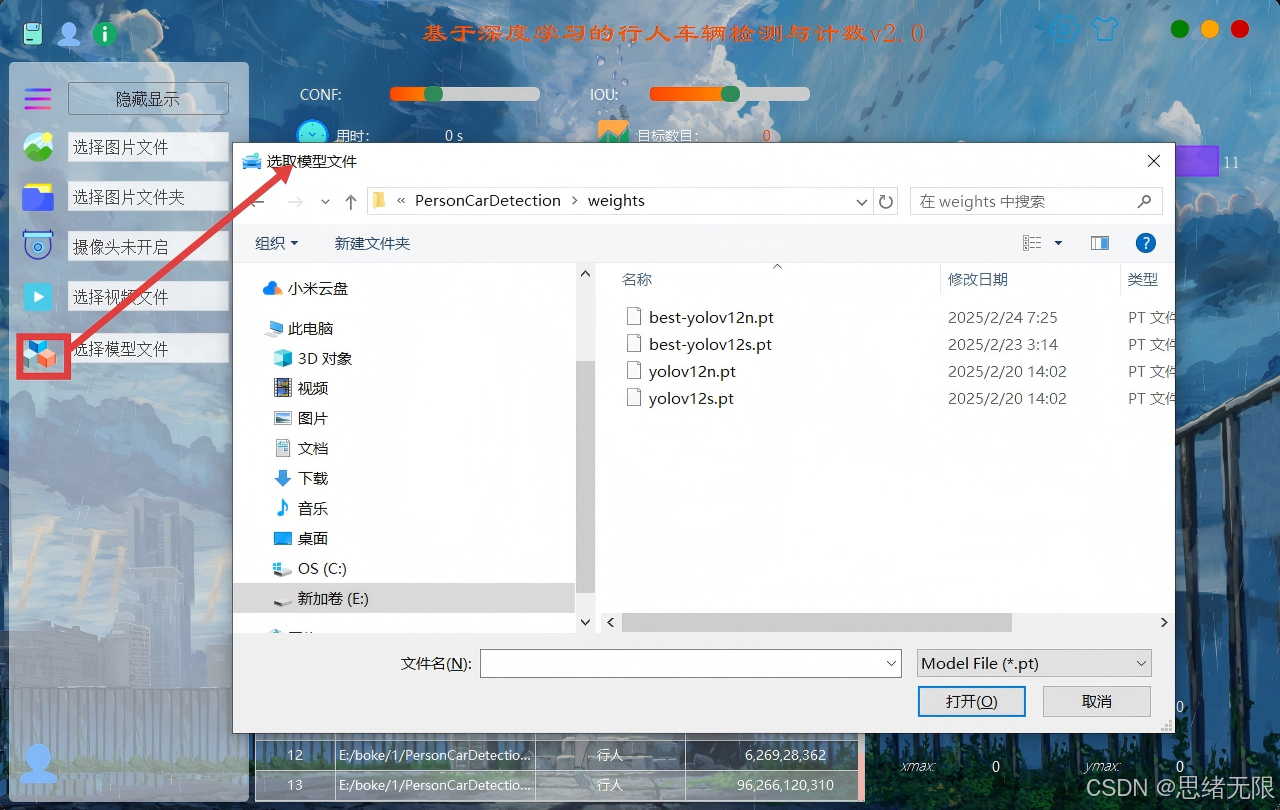
(3)模型选择与对比演示:界面内可直接切换 YOLOv5--YOLOv12 权重,对同一输入源进行快速对比;系统同步显示推理耗时/FPS与目标数量变化,并支持保存不同模型的对比结果样例。
模型选择与对比演示图
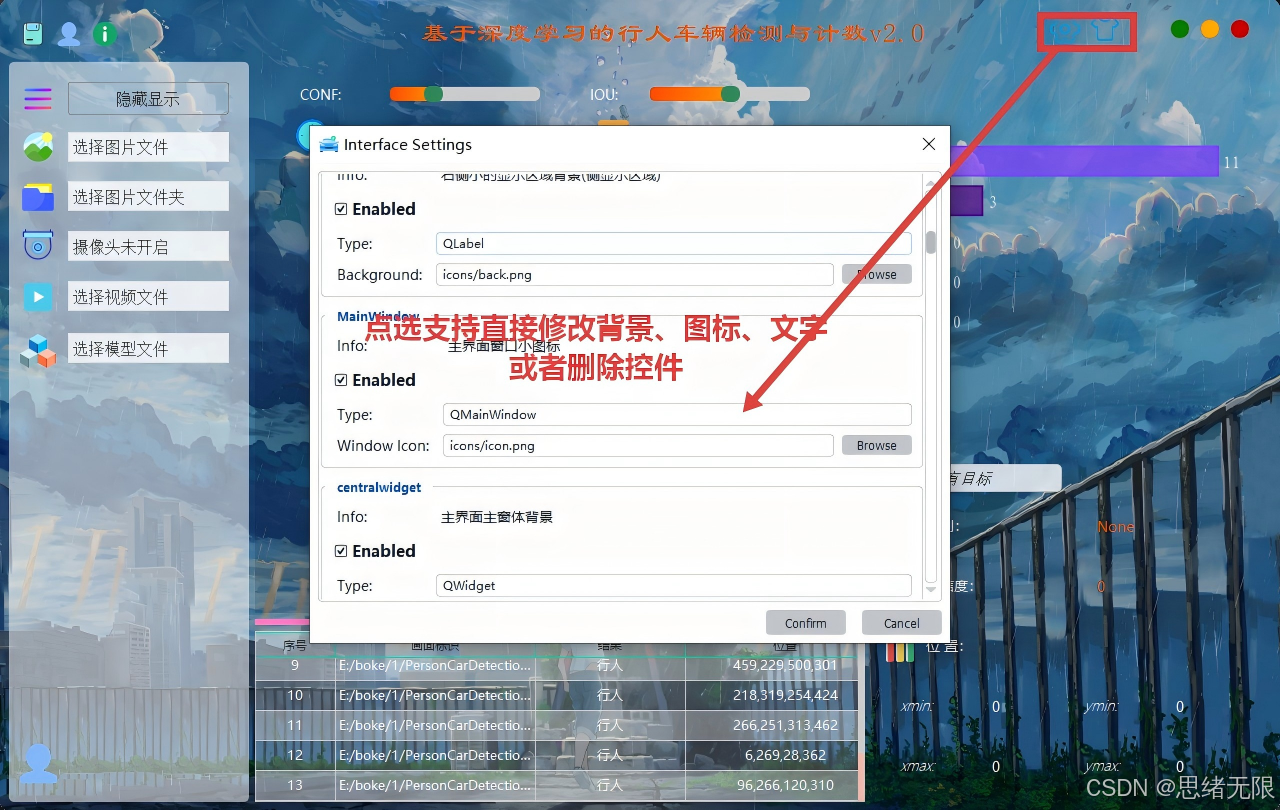
(4)主题修改功能:新增主题切换能力,支持浅色/深色等预置主题一键替换,并可同步更新背景与控件样式,保证不同环境下的可读性与观感一致。
主题修改功能演示图
2. 数据集介绍
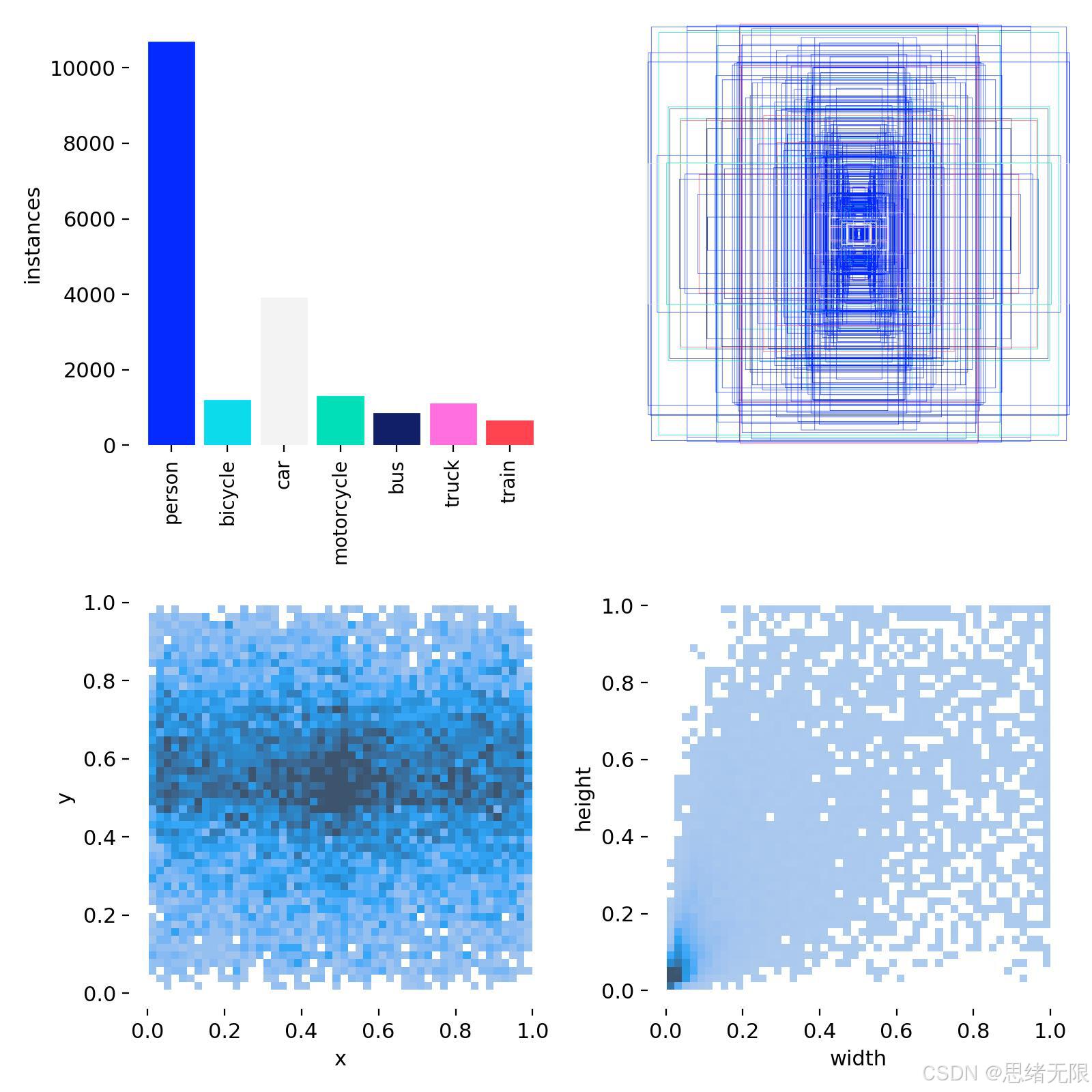
本文行人车辆检测与计数任务的数据集由 5542 张 经人工筛选的交通/街景图像构成,覆盖白天与夜间、不同视角与尺度跨度的典型道路监控画面,目标类别包含行人及多类型交通参与者。数据集按图像级划分为 训练集 2856 张、验证集 1343 张、测试集 1343 张 ,划分后尽量保持各类别在不同子集中的出现概率一致,以降低评估阶段由数据偏置带来的不确定性。标注采用 YOLO 系列通用的归一化矩形框格式,每个目标以 ( c , x , y , w , h ) (c, x, y, w, h) (c,x,y,w,h) 描述,其中 x , y x,y x,y 为框中心点坐标、 w , h w,h w,h 为宽高,均被归一化到 0 , 1 0,1 0,1 区间,便于不同分辨率图像统一训练与推理。

python
Chinese_name = {'person': "行人", 'bicycle': '自行车', 'car': '小汽车', 'motorcycle': '摩托车', 'bus': '公交车', 'truck': '卡车', 'train': '火车'}从数据分布特征看,类别实例数呈现显著的"头部---长尾"结构:行人(person)实例数远高于其他类别 ,小汽车(car)次之,自行车/摩托车/公交车/卡车/火车整体相对稀疏,这在交通场景中较为常见(行人密集、车辆类型多样但样本占比不均)。结合标签空间统计图可观察到,目标框中心在垂直方向更集中于图像中部至偏下区域,符合道路监控中地平线与路面占据主要视野的成像规律;同时宽高分布在小尺度区域密度更高,说明数据集中存在较多远距离目标与小目标样本,这也是后续模型需要重点解决的漏检来源之一。为与 Ultralytics/YOLO 训练管线对齐,工程实现中默认采用 640 × 640 640\times640 640×640 的输入尺寸,训练阶段可启用 Mosaic、随机缩放与颜色扰动等在线增强以提升泛化,而验证/测试阶段保持一致的 letterbox 尺度变换以保证评估可比性。
📊 数据集规格说明 (Dataset Specification)
| 维度 | 参数项 | 详细数据 |
|---|---|---|
| 基础信息 | 标注软件 | LabelImg |
| 标注格式 | YOLO TXT (Normalized) | |
| 数量统计 | 训练集 (Train) | 2,856 张 (51.5%) |
| 验证集 (Val) | 1,343 张 (24.2%) | |
| 测试集 (Test) | 1,343 张 (24.2%) | |
| 总计 (Total) | 5,542 张 | |
| 类别清单 | Class ID: 0 | person(行人) |
| Class ID: 1 | bicycle(自行车) |
|
| Class ID: 2 | car(小汽车) |
|
| Class ID: 3 | motorcycle(摩托车) |
|
| Class ID: 4 | bus(公交车) |
|
| Class ID: 5 | truck(卡车) |
|
| Class ID: 6 | train(火车) |
|
| 图像规格 | 输入尺寸 | 640 * 640 |
| 数据来源 | 精心筛选的交通/街景图像(用于行人车辆检测与计数) |
3. 模型设计与实现
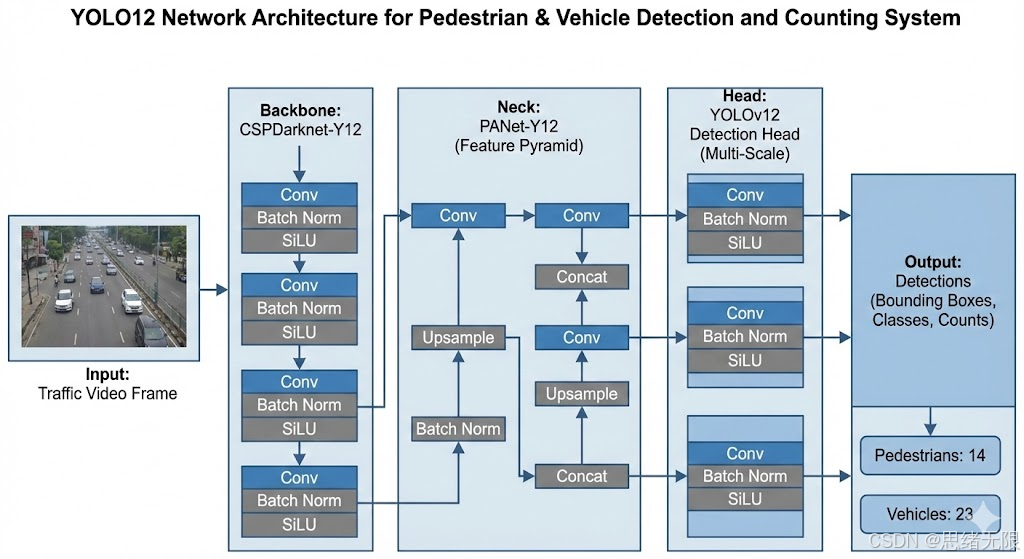
面向"行人---车辆"检测与计数这一典型交通视觉任务,老思在模型侧的首要取舍是:在复杂光照、密集遮挡与小目标占比高的监控视角下,检测器需要同时具备足够的多尺度表达能力与可控的实时推理延迟,否则后续计数环节会被漏检与框抖动系统性放大。基于这一约束,本文将 YOLOv12n 作为默认主模型,并保留 YOLOv5--YOLOv11 的权重兼容接口用于横向对比与工程回滚;YOLOv12 的核心价值在于将注意力机制"实装"进实时 YOLO 框架,通过区域注意力与更易优化的聚合结构,在速度可比的前提下提升对复杂背景与长程依赖的建模能力。(Ultralytics Docs)
从整体范式看,YOLO 系列延续了单阶段密集预测的基本建模:输入图像经过 Backbone 提取多层语义特征,经 Neck 完成跨尺度融合,再由 Head 在多个分辨率特征图上输出类别与边界框回归。以 YOLOv5 为例,其 Backbone 采用 CSPDarknet 结构以改善梯度流与计算冗余,Neck 结合 SPPF 与 PAN 进行多尺度聚合,Head 则在多层特征上完成密集预测;这一路线在工程端的优势是结构直观、推理链路稳定,适合作为交通检测的可复现基线。(Ultralytics Docs) 进入 Ultralytics 的 YOLOv8 之后,检测头进一步朝向 anchor-free 与解耦分支演进,使用更轻的分配与预测形式提升训练效率与精度上限,这为后续 v10/v12 的端到端化与注意力化奠定了统一接口。(Ultralytics Docs)
本文主模型 YOLOv12 的结构设计可以理解为"在 YOLO 的 Backbone/Neck 位置引入可实时运行的注意力块,并同步改造特征聚合以提升可优化性"。其 Area Attention 的关键点是把特征图按空间维度划分为 L L L 个等规模区域(实践中默认 L = 4 L=4 L=4),并在区域内进行自注意力计算,从而将标准全局注意力的二次复杂度按比例降低。若特征图共有 N = H ! × ! W N=H! \times !W N=H!×!W 个 token,则全局注意力复杂度为 O ( N 2 ) \mathcal{O}(N^2) O(N2);区域划分后每个区域约 N / L N/L N/L 个 token,总复杂度约为
O ! ( L ( N L ) 2 ) = O ! ( N 2 L ) , \mathcal{O}!\left(L\left(\frac{N}{L}\right)^2\right)=\mathcal{O}!\left(\frac{N^2}{L}\right), O!(L(LN)2)=O!(LN2),
在保持较大有效感受野的同时显著压缩了计算量与访存压力。(Ultralytics Docs) 为缓解"注意力堆叠更深后更难训练"的问题,YOLOv12 进一步提出 R-ELAN (Residual Efficient Layer Aggregation Networks),在 ELAN 式聚合基础上加入块级残差与更偏"瓶颈化"的聚合方式,以提高深层注意力网络的优化稳定性。(Ultralytics Docs) 此外,YOLOv12 允许可选编译 FlashAttention 以降低注意力的显存占用与访存开销,但默认训练/推理并不强依赖该组件,这使得项目在不同硬件环境下更易部署与复现。(Ultralytics Docs)
在检测头与任务建模层面,本文采用 Ultralytics 系列较为统一的"解耦头 + 动态样本分配 + IoU 回归约束"范式:分类分支学习 p ( c ∣ x ) p(c\mid x) p(c∣x),回归分支学习边界框几何参数,样本分配阶段尽量将分类置信与定位质量对齐,避免"分类高但框偏""框准但分类低"的失配问题。任务对齐思想在 TOOD 中已有系统论述:通过联合考虑分类与定位的对齐程度来选择高质量正样本,可显著改善密集预测检测器的训练有效性。(arXiv) 对于 anchor-free 形式,Head 通常以特征图上的参考点 ( x a , y a ) (x_a,y_a) (xa,ya) 为中心预测四个边界距离 ( l , t , r , b ) (l,t,r,b) (l,t,r,b),最终框可写为
B = ( x a − l , y a − t , x a + r , y a + b ) , B = (x_a-l,\ y_a-t,\ x_a+r,\ y_a+b), B=(xa−l, ya−t, xa+r, ya+b),
这种表达对小目标更友好,也更便于与分布式回归损失对接。
损失函数方面,本文采用"分类损失 + 回归质量损失 + 分布式回归损失"的组合,并以 IoU 系列几何约束作为定位主信号。分类项可用 BCE 或其变体,回归项常用 CIoU 以同时考虑重叠面积、中心距离与宽高比差异,从而加速收敛并提升难例回归的稳定性。(arXiv) 对于更精细的边界框学习,分布式回归思想将每个距离 d ∈ l , t , r , b d\in{l,t,r,b} d∈l,t,r,b 建模为离散分布 p k p_k pk( k = 0 , ... , K k=0,\dots,K k=0,...,K),用期望恢复连续值
d = ∑ k = 0 K k , p k , d=\sum_{k=0}^{K} k,p_k, d=k=0∑Kk,pk,
并通过 Distribution Focal Loss 让模型在遮挡、边界不清等"标签不确定"情况下学到更符合数据分布的定位表征;这一思想在 GFL 体系中被系统提出并验证其对密集检测的收益。(arXiv) 因此,本文整体损失可概括为
L = λ cls L ∗ cls + λ ∗ iou L ∗ iou + λ ∗ dfl L dfl , \mathcal{L}= \lambda_{\text{cls}}\mathcal{L}*{\text{cls}}+\lambda*{\text{iou}}\mathcal{L}*{\text{iou}}+\lambda*{\text{dfl}}\mathcal{L}_{\text{dfl}}, L=λclsL∗cls+λ∗iouL∗iou+λ∗dflLdfl,
其中 λ \lambda λ 为各项权重,工程实现中由训练配置统一管理,保证 v5--v12 对比实验在同一损失口径下尽可能公平。
实现层面,模型侧以"权重文件 + YAML 结构配置"作为统一入口:训练时根据数据集类别数将检测头输出通道自动适配为行人与车辆两类(或按项目需要扩展为更多车辆细分),推理时复用同一预处理与后处理逻辑以支撑跨版本对比。对于 YOLOv10,系统保留其 one-to-one head 的 NMS-free 推理路径用于低延迟场景;其一致双重分配训练策略与一对一推理头是实现"免 NMS"端到端推理的关键。(arXiv) 而对于 YOLOv12,系统在默认配置下优先启用注意力增强的 backbone/neck,以换取更稳健的遮挡与复杂背景处理能力,并通过模型选择器在 UI 层一键切换,形成"同一输入、同一阈值、不同模型"的可复现实证链路。(Ultralytics Docs)
4. 训练策略与模型优化
本文的训练流程以 Ultralytics YOLO 训练器为统一入口,目标是在同一数据集划分与同一评估口径下,对 YOLOv5--YOLOv12 的精度与速度进行可复现对照。硬件侧默认使用 RTX 4090,训练与推理均启用 CUDA 加速与混合精度(FP16)以提升吞吐并降低显存压力;软件侧保持 Python 3.12 与依赖版本固定,确保不同模型版本切换时,差异主要来自网络结构本身而非环境漂移。由于本数据集存在明显的类别长尾(行人实例显著多于车辆细分类别),若直接以默认设置长时间训练,模型容易在头部类别上过拟合并牺牲稀有类召回,因此本文在训练阶段重点控制正负样本质量、增强策略与阈值标定,使得检测输出在"可计数"层面更稳定。
迁移学习是获得稳定收敛的基础策略。老思在所有实验中优先加载对应版本的 COCO 预训练权重,并在本任务上进行端到端微调,而非从随机初始化开始训练。这样做的直接收益是:Backbone 的通用边缘/纹理表征能够显著加速早期收敛,同时对夜间噪声、轻度模糊与低对比场景具有更好的初始鲁棒性。训练初期采用 warmup 让学习率从较小值平滑上升,避免强数据增强与较大 batch 共同作用下导致的梯度震荡;随后进入余弦退火或等效的分段衰减,使学习率在后期逐步降低以提升收敛质量。若用余弦退火描述学习率随 epoch 的变化,其形式可写为
η ( t ) = η min + 1 2 ( η max − η min ) ( 1 + cos π t T ) , \eta(t)=\eta_{\min}+\frac{1}{2}\left(\eta_{\max}-\eta_{\min}\right)\left(1+\cos\frac{\pi t}{T}\right), η(t)=ηmin+21(ηmax−ηmin)(1+cosTπt),
其中 t t t 为当前训练进度, T T T 为总训练轮数, η max \eta_{\max} ηmax 与 η min \eta_{\min} ηmin 分别对应初始与末端学习率范围。该策略在不引入额外复杂调参的前提下,能够兼顾中期探索与后期细化,对跨模型版本的公平对比也更友好。
数据增强采用"前强后弱"的时间调度,以同时兼顾泛化能力与置信度标定。训练前段启用 Mosaic 等组合增强,提高小目标与遮挡目标的曝光概率,并通过随机缩放、色彩扰动与轻度几何变化提升对光照与拍摄视角差异的鲁棒性;训练后段逐步关闭 Mosaic(例如最后 10 个 epoch 关闭),让网络更多拟合真实成像分布,使验证集上的框定位与置信度更稳定。对于计数任务而言,这一点尤为关键:过强的几何拼接若贯穿全程,会让检测框在真实视频流中出现更明显的抖动,从而在后续基于 ROI/过线规则的计数阶段放大为重复触发或漏触发。
优化器与正则化的选择以稳定性优先。本文默认使用 optimizer=auto 让训练器依据模型规模与梯度统计选择更合适的优化器实现,并固定记录实际采用的优化器类型与关键超参数,避免"人为调参差异"污染跨版本对比。权重衰减用于抑制过拟合,BN 作为主干网络的默认归一化稳定训练;对于轻量检测模型而言,检测头中引入较强 Dropout 往往会损害几何回归的一致性,因此本文更倾向通过权重衰减与增强调度完成正则化,而不是依赖大比例随机失活。与此同时,训练阶段保留 EMA(Exponential Moving Average)权重滑动平均以降低后期震荡,使验证指标更平滑、推理表现更稳定,这对"同一阈值下的可计数性"同样有帮助。
为了让读者能够直接复现实验,本文给出一套默认可用的训练基线配置(在 4090 上较易稳定收敛)。需要强调的是,这套配置的目标是建立跨 YOLO 版本的统一起点,而非针对某一版本做极限压榨式调参;在该基线上再做针对性微调,才更符合工程迭代路径。
| 名称 | 作用(简述) | 数值 |
|---|---|---|
| epochs | 最多训练轮数 | 120 |
| patience | 早停耐心(验证无提升则停止) | 50 |
| batch | 每次迭代的总批大小 | 16 |
| imgsz | 网络输入分辨率(方形) | 640 |
| pretrained | 是否加载预训练权重 | true |
| optimizer | 优化器类型(auto 由框架选择) | auto |
| lr0 | 初始学习率 | 0.01 |
| lrf | 最终学习率占比(余弦/多段下降底值) | 0.01 |
| momentum | 动量/一阶动量系数 | 0.937 |
| weight_decay | 权重衰减(L2 正则) | 0.0005 |
| warmup_epochs | 学习率预热轮数 | 3.0 |
| mosaic | Mosaic 数据增强强度/概率 | 1.0 |
| close_mosaic | 训练后期关闭 Mosaic 的轮数 | 10 |
模型优化部分分为"推理链路优化"与"计数稳定性优化"两条线并行推进。推理链路侧,默认采用批大小为 1 的真实在线设置,启用 FP16 推理,并在部署前导出 ONNX,再根据需要转 TensorRT 以获得更低延迟与更稳定的吞吐;对于 UI 实时显示场景,推理线程与主线程通过信号槽解耦,避免界面阻塞导致帧率抖动。计数稳定性侧,本文并不将 Conf/IOU 固定死在某一组"mAP 最优"数值上,而是将其视为计数系统的控制量:Conf 过低会引入误检并带来重复计数风险,Conf 过高又会导致小目标漏检造成轨迹断裂与漏计数。因而系统界面提供 Conf/IOU 可视化调节,博主在实验中以验证集与典型视频片段联合校准,优先选择"计数误差更小、输出更平滑"的阈值区间,再将该区间固化为默认参数,实现从离线训练到在线计数的一致闭环。
5. 实验与结果分析
5.1 实验设置与对比基线
本文在同一数据集划分(Train/Val/Test = 2856/1343/1343)与同一训练配置(输入 640 × 640 640\times640 640×640、epoch=120、预训练初始化、warmup 与后期关闭 Mosaic)下,对 YOLOv5--YOLOv12 的多版本模型进行横向对比。对比基线覆盖轻量化的 n/tiny 级别(YOLOv5nu、YOLOv6n、YOLOv7-tiny、YOLOv8n、YOLOv9t、YOLOv10n、YOLOv11n、YOLOv12n),以及更高容量的 s 级别(YOLOv5su、YOLOv6s、YOLOv7、YOLOv8s、YOLOv9s、YOLOv10s、YOLOv11s、YOLOv12s),以同时考察"边缘端可用性"与"工作站侧精度上限"。推理速度统计基于同一硬件平台(CSV 记录为 RTX 3070 Laptop GPU, 8GB ),并拆分为预处理、模型前向与后处理时间,从而使"真实端到端帧率"可被直接复现与比较。
5.2 度量指标
检测精度采用 Precision、Recall、F1 与 COCO 风格 mAP 作为主指标,其中 Precision 与 Recall 分别定义为
P r e c i s i o n = T P T P + F P , R e c a l l = T P T P + F N , \mathrm{Precision}=\frac{TP}{TP+FP},\qquad \mathrm{Recall}=\frac{TP}{TP+FN}, Precision=TP+FPTP,Recall=TP+FNTP,
F1 则用于刻画精确率与召回率的平衡:
F 1 = 2 ⋅ P r e c i s i o n ⋅ R e c a l l P r e c i s i o n + R e c a l l . \mathrm{F1}=\frac{2\cdot \mathrm{Precision}\cdot \mathrm{Recall}}{\mathrm{Precision}+\mathrm{Recall}}. F1=Precision+Recall2⋅Precision⋅Recall.
本文同时报告 m A P @ 0.5 mAP@0.5 mAP@0.5 与 m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95:前者更贴近工程中"框大体准确即可"的可用性判断,后者对定位质量约束更强,能更敏感地区分不同检测器在边界拟合上的差异。对计数系统而言,阈值选择(Conf/IOU)会直接影响误检与漏检,进而放大为重复计数或漏计数,因此本文额外给出 F1-Confidence 曲线,用于确定较稳健的默认阈值区间(后文结合图示讨论)。
5.3 实验结果与分析
(1)n/tiny 级别模型:YOLOv9t 在精度上领先,但速度存在实现相关的代价。
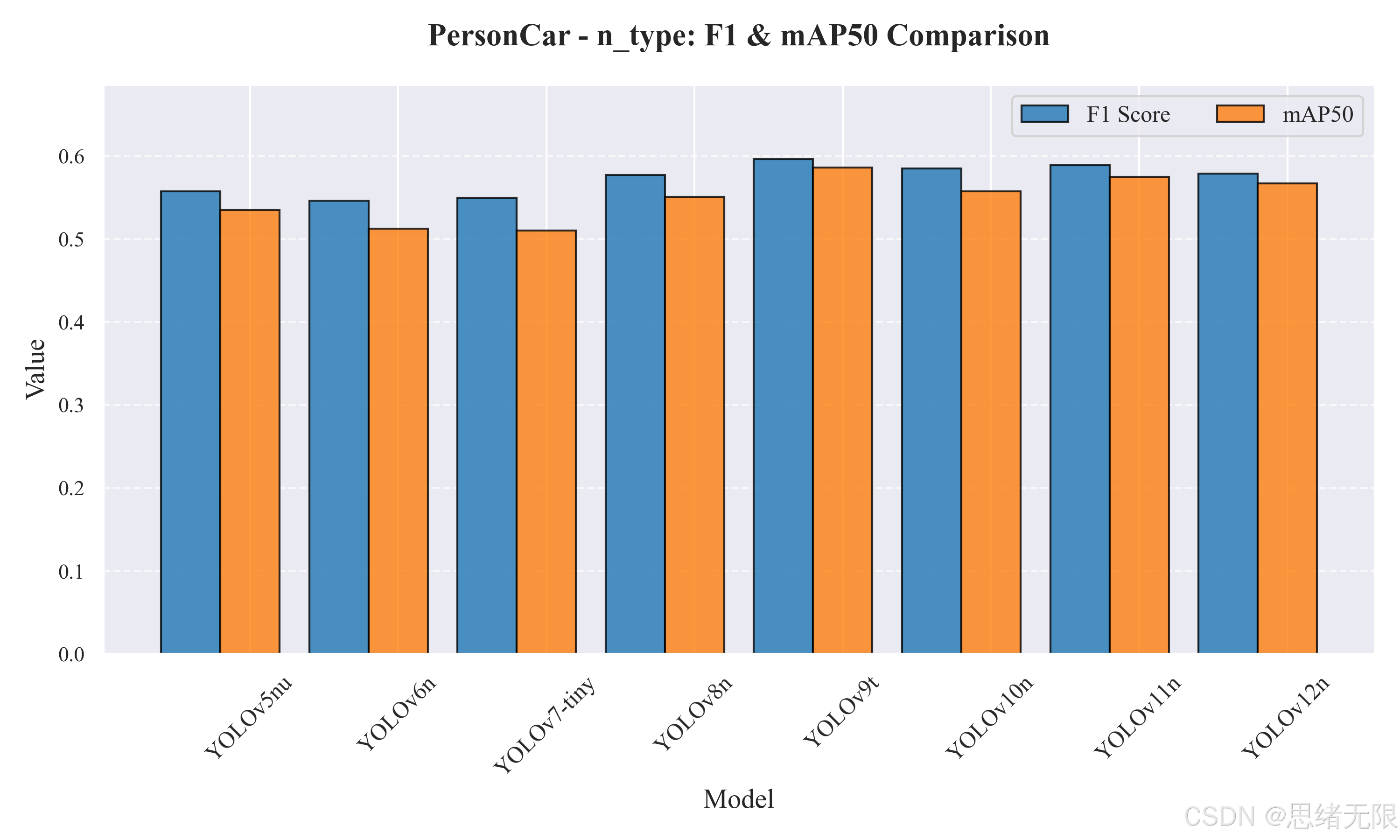
表 5-1 汇总了 n/tiny 组的核心结果。可以看到,YOLOv9t 在该组中取得最高的 F1=0.596、mAP50=0.586、mAP50-95=0.393 ,说明其在当前数据集上对行人与车辆目标的定位与分类更为稳健;YOLOv11n 次之(mAP50=0.575,F1=0.589),YOLOv12n 的 mAP50=0.567,整体处于第一梯队但未超过 v9/v11。需要注意的是,尽管 YOLOv9t 的参数量与 FLOPs 并不高,但其端到端总耗时达到 19.67 ms(约 50.8 FPS) ,明显慢于 YOLOv8n 的 10.17 ms(约 98.3 FPS) 。这类"复杂度相近但时延偏大"的现象往往与具体算子实现、访存模式或后处理开销有关,因此在实时 UI 场景下,老思更倾向将 YOLOv11n/YOLOv10n 作为"精度---帧率"折中点,将 YOLOv9t 用作精度优先的离线评估与对照基线。
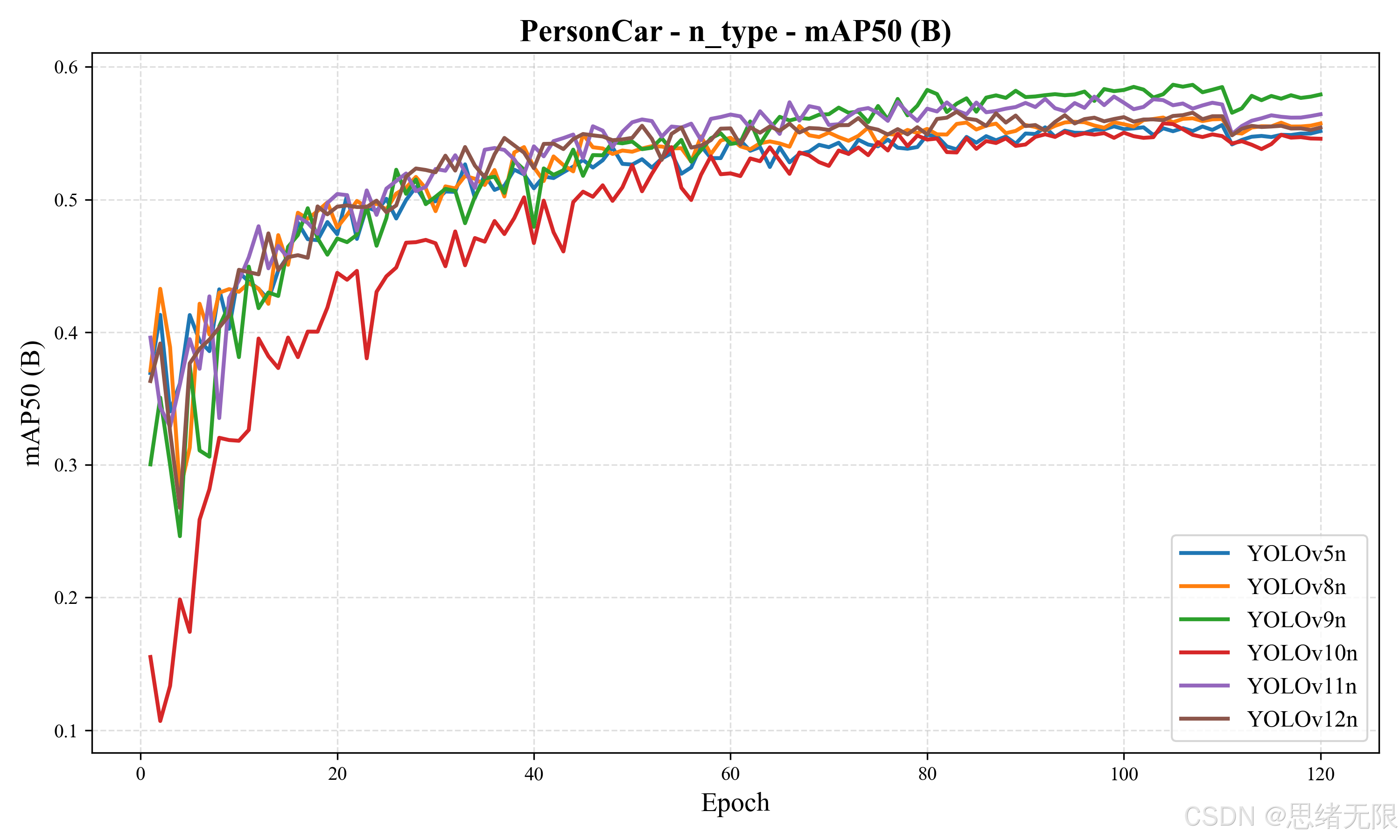
表 5-1 n/tiny 组检测性能与推理开销(batch=1, 640 × 640 640\times640 640×640)
| 模型 | Params(M) | FLOPs(G) | P | R | F1 | mAP50 | mAP50-95 | 总耗时(ms) | FPS |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv5nu | 2.6 | 7.7 | 0.661 | 0.481 | 0.557 | 0.535 | 0.342 | 10.94 | 91.41 |
| YOLOv6n | 4.3 | 11.1 | 0.630 | 0.482 | 0.546 | 0.512 | 0.326 | 10.34 | 96.71 |
| YOLOv7-tiny | 6.2 | 13.8 | 0.685 | 0.459 | 0.549 | 0.510 | 0.286 | 21.08 | 47.44 |
| YOLOv8n | 3.2 | 8.7 | 0.698 | 0.492 | 0.577 | 0.551 | 0.362 | 10.17 | 98.33 |
| YOLOv9t | 2.0 | 7.7 | 0.691 | 0.524 | 0.596 | 0.586 | 0.393 | 19.67 | 50.84 |
| YOLOv10n | 2.3 | 6.7 | 0.707 | 0.499 | 0.585 | 0.557 | 0.368 | 13.95 | 71.69 |
| YOLOv11n | 2.6 | 6.5 | 0.671 | 0.524 | 0.589 | 0.575 | 0.377 | 12.97 | 77.10 |
| YOLOv12n | 2.6 | 6.5 | 0.666 | 0.511 | 0.578 | 0.567 | 0.373 | 15.75 | 63.49 |
n_type:F1 与 mAP50 对比柱状图如下图所示。
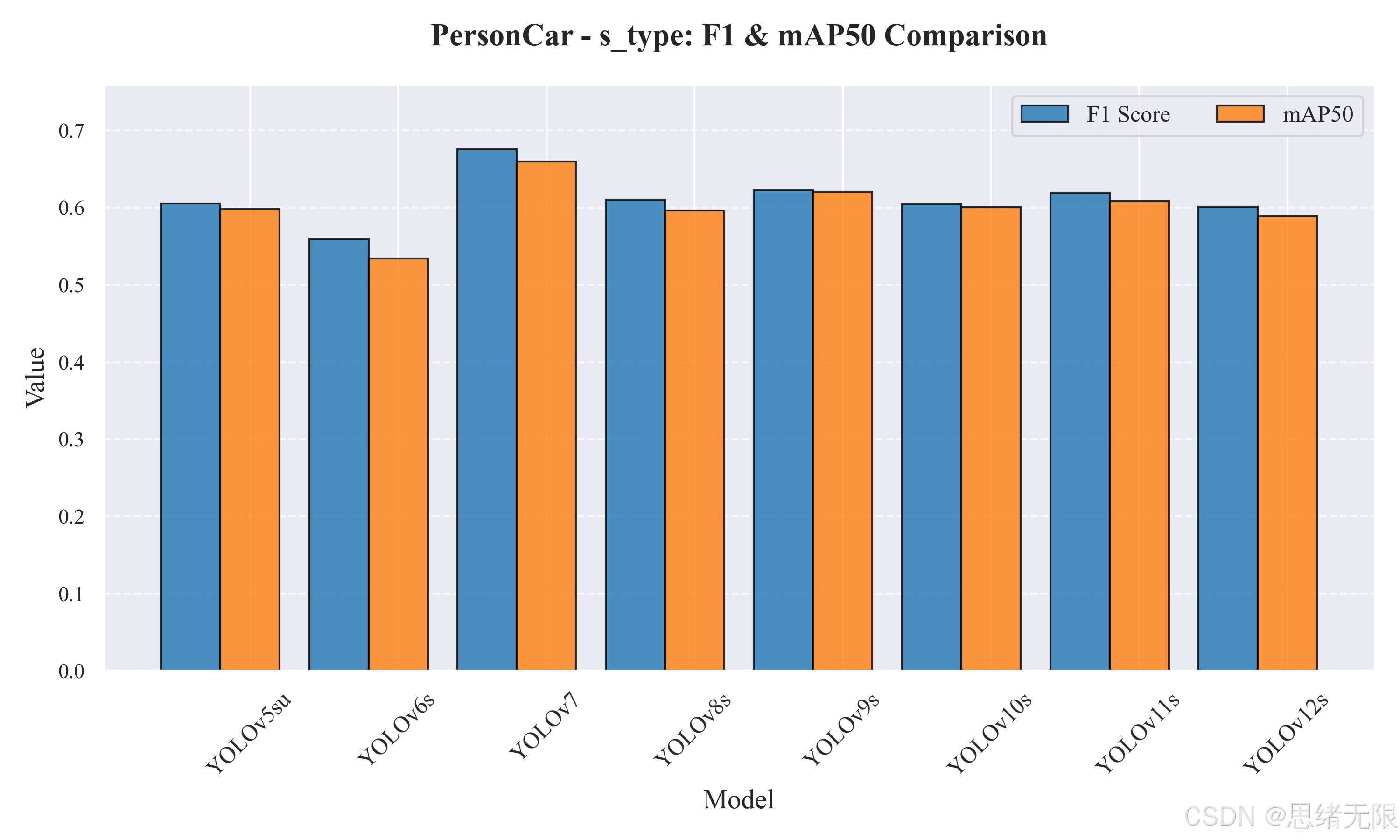
(2)s 级别模型:YOLOv7 精度上限最高,但计算量显著增加;YOLOv9s/YOLOv11s 更适合作为工程默认。
表 5-2 显示,YOLOv7 在 s 组取得最高的 F1=0.676、mAP50=0.660、mAP50-95=0.446 ,属于"容量换精度"的典型结果;但其 FLOPs 达到 104.7G,总耗时 29.52 ms(约 33.9 FPS) ,在桌面端尚可接受,在高帧率视频与多路输入时会明显挤压系统余量。相比之下,YOLOv9s(mAP50=0.621,F1=0.623)与 YOLOv11s(mAP50=0.609,F1=0.620)在精度上接近 v7,同时总耗时分别约 22.17 ms(45.1 FPS) 与 13.47 ms(74.2 FPS),更符合"实时显示 + 交互操作 + 结果落库"的系统负载特征。YOLOv12s 的 mAP50=0.589,综合表现稳定但未成为该组最优,后续若进一步针对注意力结构做训练时长、增强调度与阈值标定的专项调参,仍有继续提升的空间。
表 5-2 s 组检测性能与推理开销(batch=1, 640 × 640 640\times640 640×640)
| 模型 | Params(M) | FLOPs(G) | P | R | F1 | mAP50 | mAP50-95 | 总耗时(ms) | FPS |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv5su | 9.1 | 24.0 | 0.692 | 0.538 | 0.606 | 0.598 | 0.385 | 12.24 | 81.70 |
| YOLOv6s | 17.2 | 44.2 | 0.645 | 0.494 | 0.559 | 0.534 | 0.340 | 12.26 | 81.57 |
| YOLOv7 | 36.9 | 104.7 | 0.780 | 0.596 | 0.676 | 0.660 | 0.446 | 29.52 | 33.88 |
| YOLOv8s | 11.2 | 28.6 | 0.716 | 0.532 | 0.610 | 0.596 | 0.394 | 11.39 | 87.80 |
| YOLOv9s | 7.2 | 26.7 | 0.732 | 0.542 | 0.623 | 0.621 | 0.426 | 22.17 | 45.11 |
| YOLOv10s | 7.2 | 21.6 | 0.710 | 0.526 | 0.604 | 0.601 | 0.404 | 14.19 | 70.47 |
| YOLOv11s | 9.4 | 21.5 | 0.708 | 0.550 | 0.620 | 0.609 | 0.407 | 13.47 | 74.24 |
| YOLOv12s | 9.3 | 21.4 | 0.674 | 0.543 | 0.601 | 0.589 | 0.393 | 16.74 | 59.74 |
s_type:F1 与 mAP50 对比柱状图如下图所示。
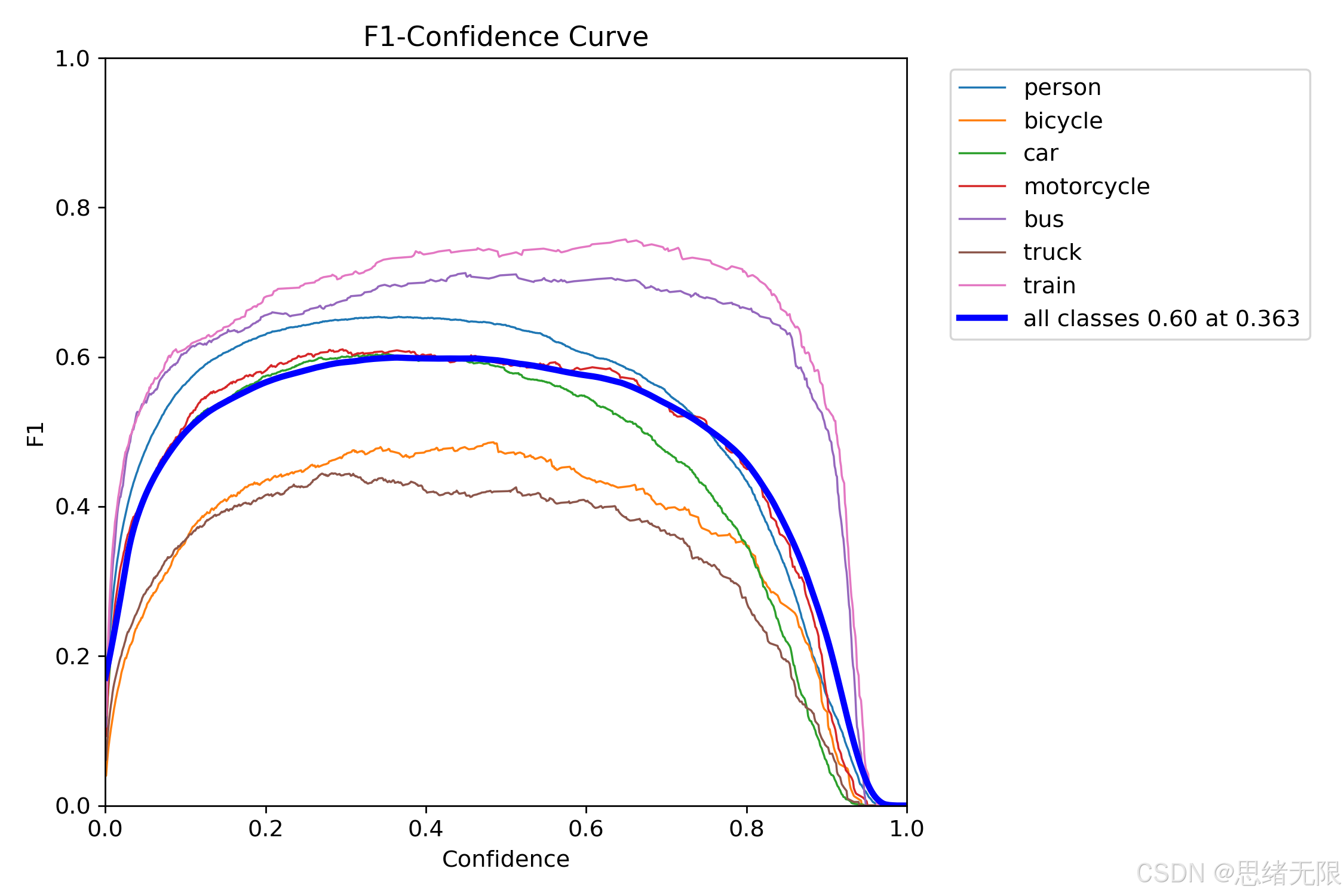
(3)阈值标定与类别差异:F1 最优阈值约为 0.36,长尾类别仍是主要误差来源。
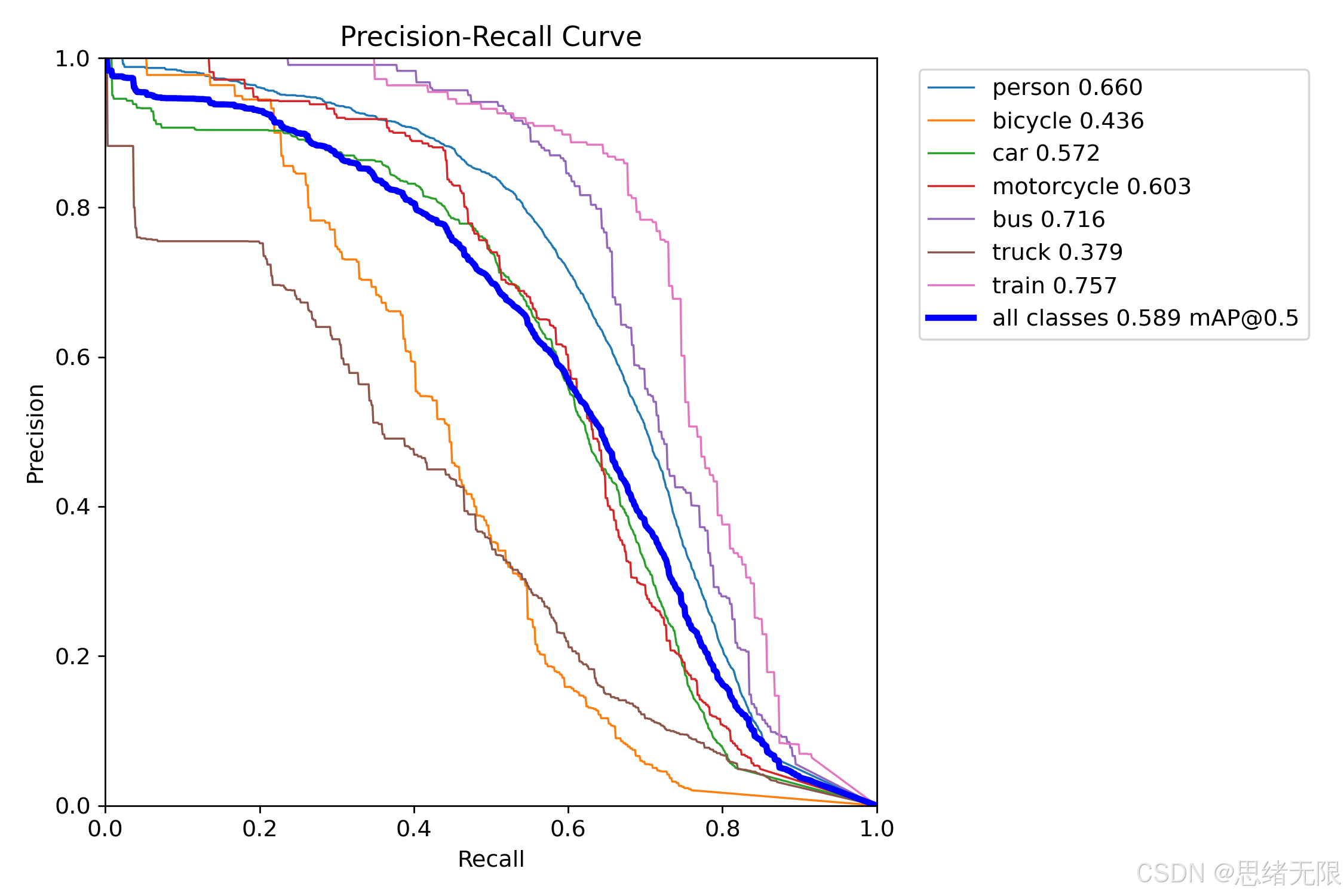
以 YOLOv12s 的评估结果为例,F1-Confidence 曲线显示全类别 F1 的峰值约为 0.60 ,对应的置信度阈值约 0.363 ,这意味着在该阈值附近 Precision 与 Recall 达到相对均衡,适合作为系统默认起点;若系统目标偏向"计数稳定且少误触发",实际部署中通常会在此基础上略微上调 Conf,以换取更低误检率并减小重复计数风险。与此同时,类别 PR 曲线给出的 A P @ 0.5 AP@0.5 AP@0.5 呈现明显差异:train(0.757)与 bus(0.716)较高,person(0.660)与 motorcycle(0.603)居中,而 bicycle(0.436)与 truck(0.379)偏低。结合前文的实例分布与目标尺度特性,这一结果往往与两点相关:其一是 bicycle、truck 的样本量与形态多样性不足导致泛化受限,其二是小目标、遮挡与相似外观(如 truck 与 bus、bicycle 与 motorcycle)更容易造成分类混淆,因而后续若要进一步提升系统计数可靠性,针对长尾类别进行补充采样与难例挖掘通常比单纯堆叠更大模型更有效。
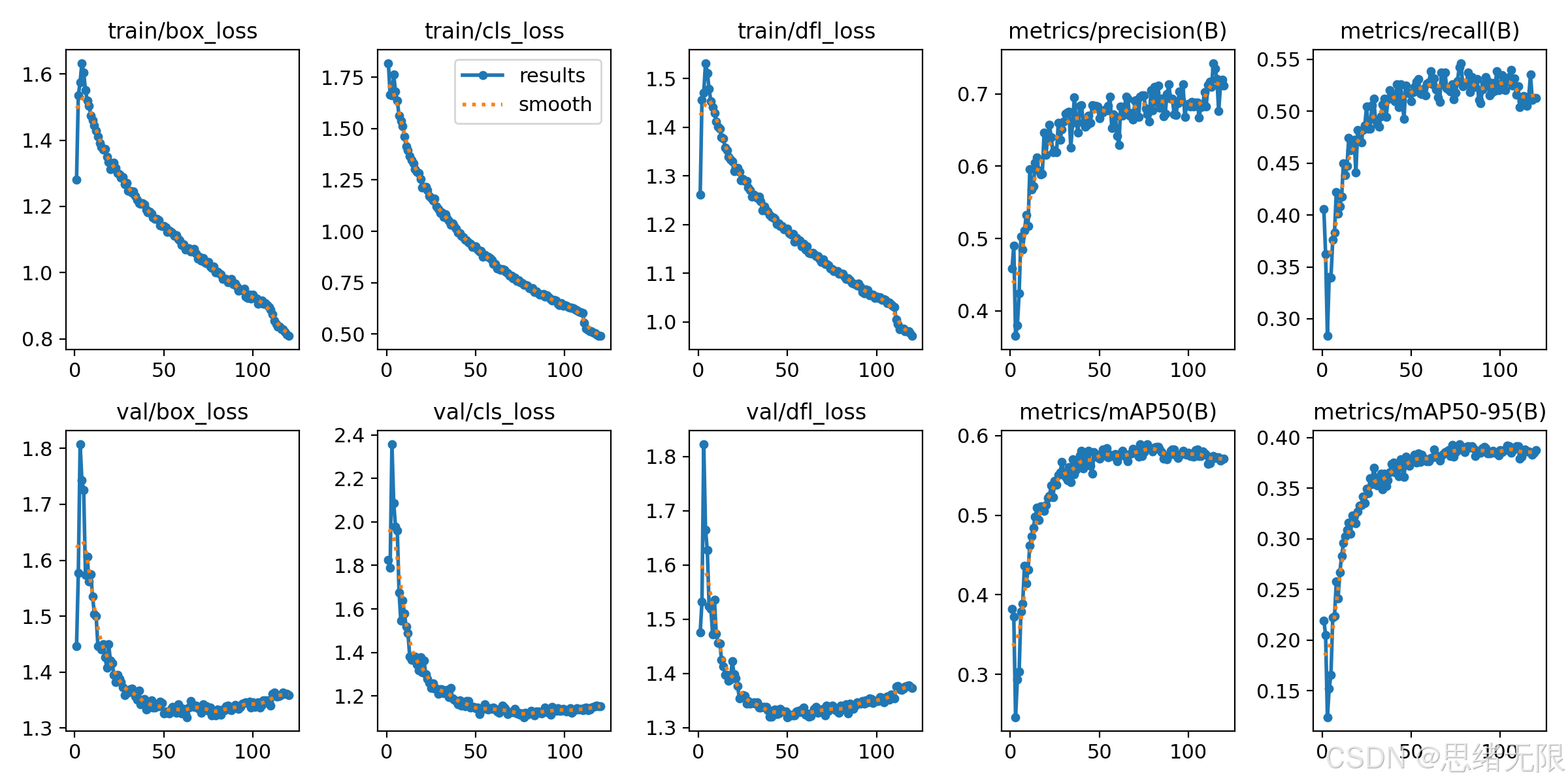
(4)收敛过程:训练指标整体平滑,但 Recall 仍是限制计数鲁棒性的关键。
从训练日志曲线可以看到,box/cls/dfl loss 在前 30--50 个 epoch 内快速下降并逐渐趋于平稳,mAP50 在中后期进入平台区间,说明当前训练策略能够稳定收敛。值得关注的是 Recall 的上升在后期趋缓,结合 PR 曲线在高召回区间的精度下降,表明"远距离小目标与遮挡目标"仍然是主要漏检来源;在计数场景中,漏检会引发轨迹断裂,从而放大为漏计数或重复计数,因此后续优化更应围绕小目标增强、遮挡鲁棒性与阈值标定展开,而不是仅追求单点 mAP 的提升。
6. 系统设计与实现
6.1 系统设计思路
本文系统采用"界面层---控制层---处理层"的分层组织方式,以 PySide6 的信号槽机制实现跨层解耦通信。界面层由 Ui_MainWindow 承载控件布局与样式资源加载,负责输入源选择、参数调节与结果展示;控制层由 MainWindow 作为中枢调度,管理模型切换、播放控制、状态机与异常处理,并将耗时任务下沉到独立线程;处理层以 Detector 为核心,封装权重加载、预处理、推理与后处理(NMS、阈值过滤、类别统计、计数逻辑等),并对外暴露统一的 infer(frame, conf, iou, model_id) 接口,从而支持 YOLOv5--YOLOv12 的快速切换与对比复现。
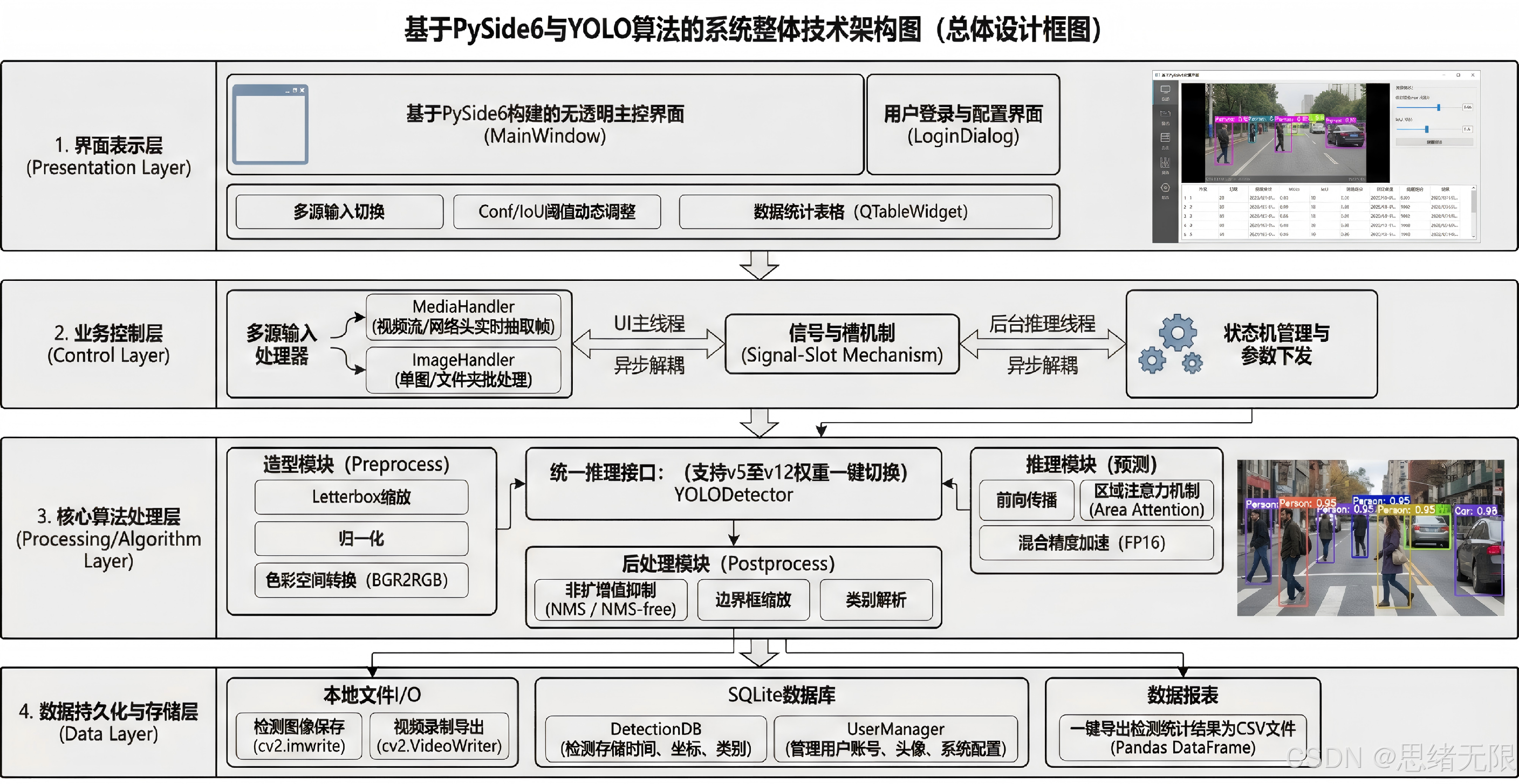
多源输入(摄像头/视频/图片/文件夹)在工程实现中被抽象为统一的帧生成器与任务队列:摄像头与视频以"连续帧流"驱动推理线程循环,图片与文件夹以"离散样本"方式进行批处理推理与汇总导出。为了避免 UI 线程阻塞,推理与渲染采用"工作线程计算、主线程绘制"的约束:工作线程输出检测框、类别与统计结构体,控制层将其转发给界面层完成绘制与表格刷新;播放暂停、阈值调参、模型切换等交互则通过状态变量与线程安全队列即时生效,保证实时性与可控性。
在结果管理上,系统以 SQLite 作为轻量持久化载体,将用户账户、个性化配置(默认模型、Conf/IOU、主题方案)、检测历史与导出索引进行结构化存储。检测结果既支持保存为图片/视频/CSV 等文件,也支持写入数据库以便后续筛选与回溯;这使得"离线对比实验---在线演示---结果追溯"共享同一套数据结构与接口,减少重复实现成本。主题修改功能通过集中式 QSS(Qt Style Sheet)与资源映射实现,界面层仅负责加载与切换样式文件,控制层负责将主题偏好落库并在启动时恢复,从而做到"外观可变、业务逻辑稳定"。
图 系统流程图

图注:系统从初始化到多源输入,完成预处理、推理与界面联动,并通过交互形成闭环。
6.2 登录与账户管理
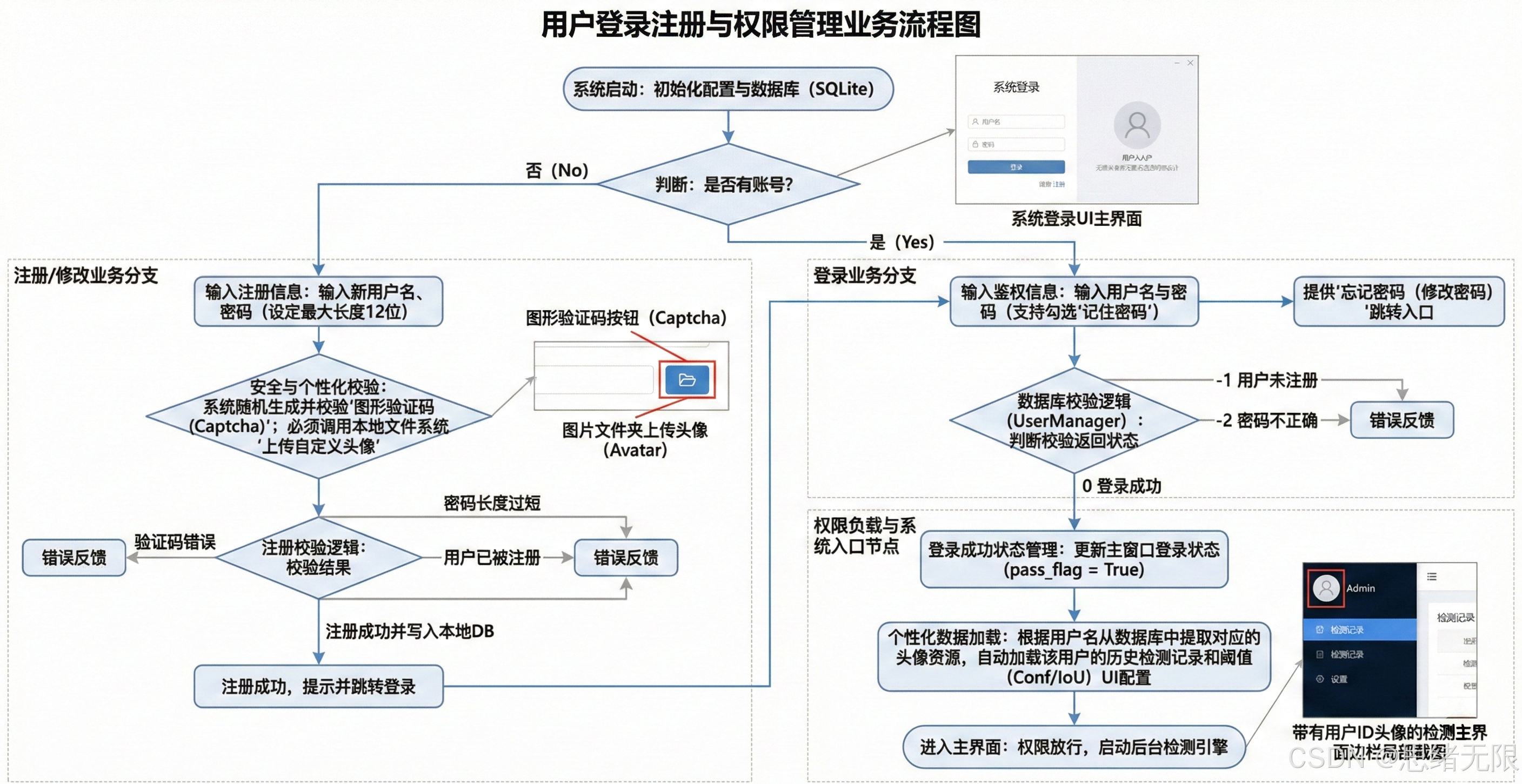
登录与账户管理模块的设计目标是为检测业务提供稳定的"身份边界"与"个性化空间":用户在登录或注册后,系统会从 SQLite 读取其默认模型与阈值配置,并同步加载历史检测记录,使主界面在进入时即可处于可复用的工作状态;检测过程中产生的结果与参数变更被统一写入文件与数据库,保证复现实验与业务回溯的可追溯性;当用户修改头像或密码时,仅更新账户与配置表,不影响 Detector 的推理链路,从而保持业务层稳定;注销与切换账号则将会话状态清空并返回登录页,实现多用户在同一设备上的隔离使用,使"模型对比演示、长期运行统计与结果导出"能够在一致的交互逻辑下完成闭环。
7. 下载链接
若您想获得博文中涉及的实现完整全部资源文件 (包括测试图片、视频,py, UI文件,训练数据集、训练代码、界面代码等),这里见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
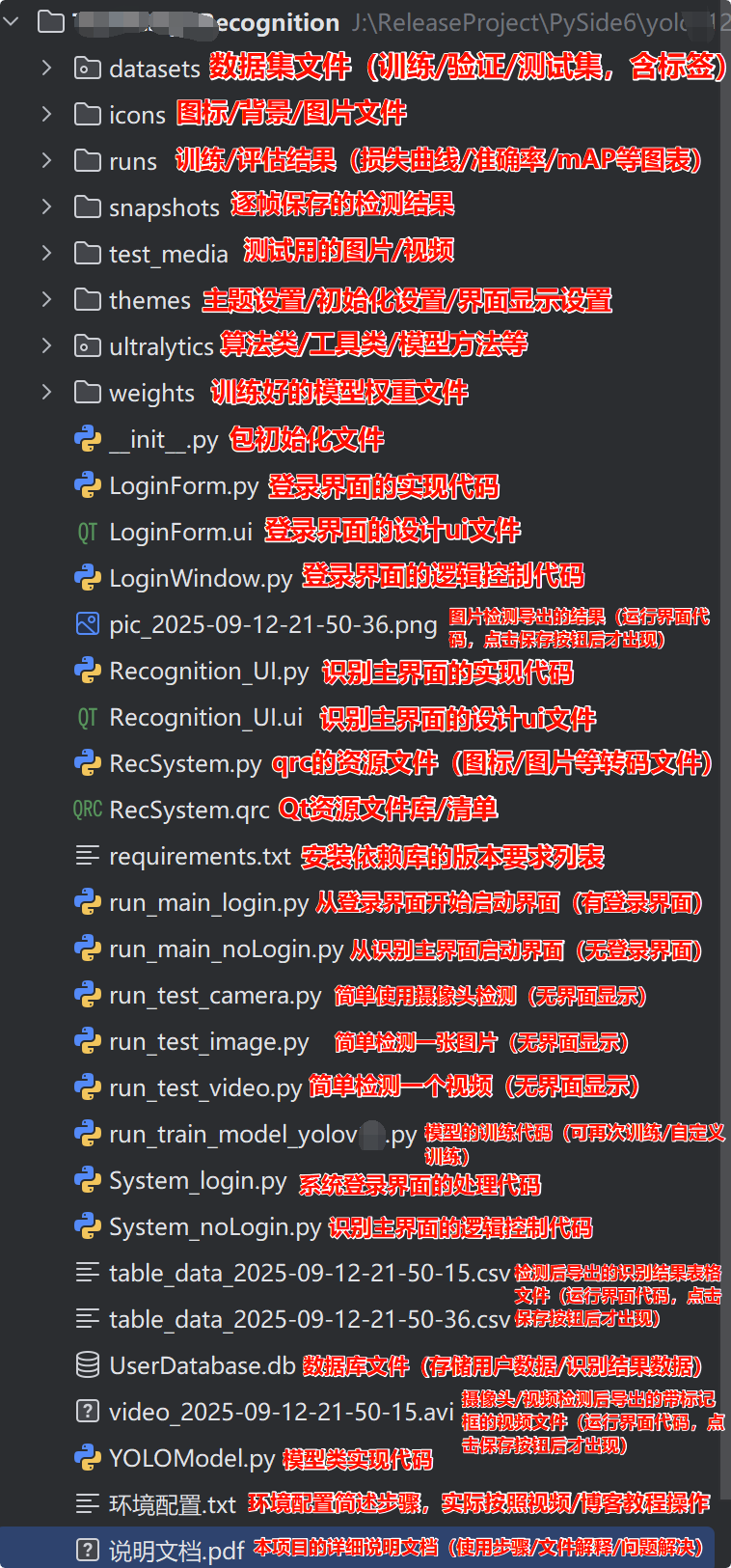
完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件请见项目介绍及功能演示视频处给出:➷➷➷
项目介绍地址: https://my.feishu.cn/wiki/OdAzwCsA6iEqa2kFGoJcYr3vnlc
功能效果展示视频: YOLOv5至YOLOv12升级:行人车辆检测与计数识别系统的设计与实现(完整代码+界面+数据集项目)
环境配置博客教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境配置教程;
或者环境配置视频教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境依赖配置教程
数据集标注教程(如需自行标注数据):数据标注合集
8. 参考文献(GB/T 7714)
1 罗艳, 张重阳, 田永鸿, 郭捷, 孙军. 深度学习行人检测方法综述J. 中国图象图形学报, 2022, 27(7): 2094-2111.
2 马永杰, 马芸婷, 程时升, 马义德. 基于改进YOLOv3模型与DeepSORT算法的道路车辆检测方法J. 交通运输工程学报, 2021, 21(2): 222-231. DOI:10.19818/j.cnki.1671-1637.2021.02.019.
3 张阳婷, 黄德启, 王东伟, 贺佳佳. 基于深度学习的目标检测算法研究与应用综述J. 计算机工程与应用, 2023, 59(18): 1-13. DOI:10.3778/j.issn.1002-8331.2305-0310.
4 Dalal N, Triggs B. Histograms of Oriented Gradients for Human DetectionC//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). San Diego: IEEE, 2005: 886-893. DOI:10.1109/CVPR.2005.177.
5 Ren S, He K, Girshick R, Sun J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal NetworksC//Advances in Neural Information Processing Systems (NeurIPS). 2015: 91-99.
6 Lin T Y, Dollár P, Girshick R, He K, Hariharan B, Belongie S. Feature Pyramid Networks for Object DetectionC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017: 2117-2125.
7 Redmon J, Divvala S, Girshick R, Farhadi A. You Only Look Once: Unified, Real-Time Object DetectionC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016: 779-788.
8 Yu F, Chen H, Wang X, Xian W, Chen Y, Liu F, Madhavan V, Darrell T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask LearningC//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2020: 2636-2645. DOI:10.1109/CVPR42600.2020.00271.
9 Wen L, Du D, Cai Z, Lei Z, Chang M C, Qi H, Lim J, Yang M H, Lyu S. UA-DETRAC: A New Benchmark and Protocol for Multi-Object Detection and TrackingJ. Computer Vision and Image Understanding, 2020, 193: 102907. DOI:10.1016/j.cviu.2020.102907.
10 Zhang Y, Sun P, Jiang Y, Yu D, Weng F, Yuan Z, Luo P, Liu W, Wang X. ByteTrack: Multi-Object Tracking by Associating Every Detection BoxC//Computer Vision -- ECCV 2022. Lecture Notes in Computer Science, vol 13682. Cham: Springer, 2022: 1-21.
11 Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object DetectorsC//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2023.
12 Wang C Y, Yeh I H, Liao H Y M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient InformationC//Computer Vision -- ECCV 2024. Lecture Notes in Computer Science, vol 15089. Cham: Springer, 2024.
13 Wang A, Chen H, Liu L, Chen K, Lin Z, Han J, Ding G. YOLOv10: Real-Time End-to-End Object DetectionC//Advances in Neural Information Processing Systems (NeurIPS). 2024.
14 Sapkota R, Karkee M. Ultralytics YOLO Evolution: An Overview of YOLO26, YOLO11, YOLOv8 and YOLOv5 Object Detectors for Computer Vision and Pattern RecognitionJ/OL. arXiv:2510.09653, 2025.
15 Tian Y, Ye Q, Doermann D. YOLOv12: Attention-Centric Real-Time Object DetectorsJ/OL. arXiv:2502.12524, 2025.