大家好,我是子衡,嵌入式 AI 工程师,《嵌入式AI:让单片机学会思考》主理人,专注AI在MCU上的落地实践。
零基础速通嵌入式AI(关注我免费领取嵌入式AI资料)
很多嵌入式工程师一听到"AI""神经网络""模型部署"这几个词,第一反应不是兴奋,而是本能地往后退一步。原因也很真实。
一是觉得自己不会 Python;
二是觉得自己没学过深度学习;
三是觉得 AI 这种东西,应该是算法工程师、研究生、做大模型的人才碰的,和写 STM32、做驱动、调外设的自己没太大关系。
其实,"在 STM32 上跑通第一个AI 模型"这件事,实际门槛并没有很多人想象得那么高。
如果你现在会用 STM32CubeMX、会写一点 C、会烧录程序、会看串口输出,那么你距离 TinyML 的第一个 Demo,其实已经没有你想象中那么远了。
一、误区:单片机跑 AI,不等于单片机训练 AI
很多人一提到"单片机跑 AI",脑子里会自动补出一个非常夸张的画面:
MCU 在板子上一边采数据,一边自己训练神经网络,一边还要更新参数。
然后马上得出结论:这肯定不可能,STM32 哪有这个算力。其实,这就是最典型的误解。因为在绝大多数 TinyML 项目里,训练和推理是分开的。
我公众号中的"老演员"上场,就是下面的这个TinyML的工作流:
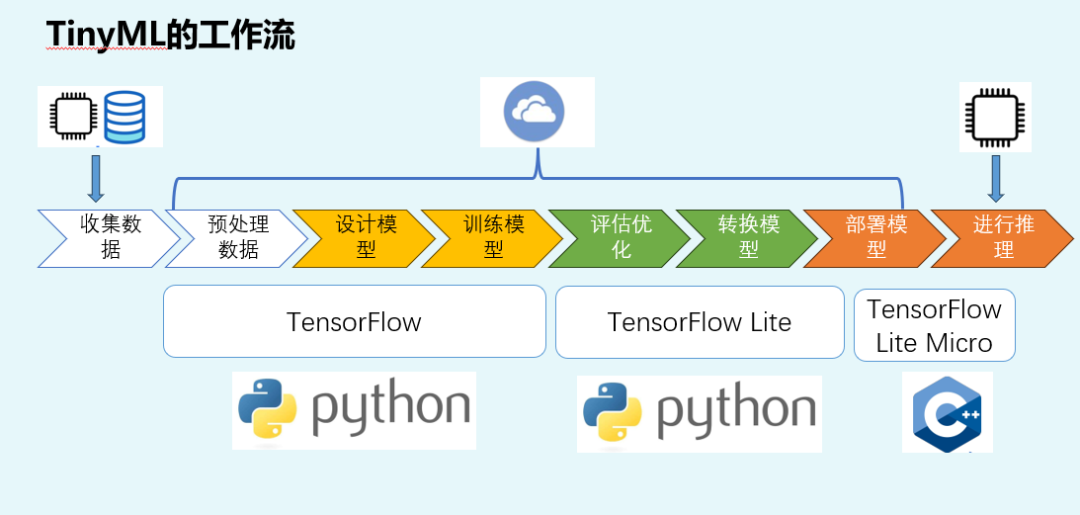
从上面图片可以看出,其实模型训练,是在PC或者云端进行的。我们可以用 TensorFlow、Keras、Edge Impulse,或者别的训练工具,把模型先训练好。
推理,才发生在MCU上。也就是把已经训练好的模型放进 MCU,让它接收输入数据,然后算出结果。
训练:吃大量数据,反复调整参数,计算量很大,通常在 PC 上完成。
推理:拿一个已经固定好的模型,根据输入算输出,计算量远小于训练,可以在 MCU 上完成。
所以,对于嵌入式工程师来说,需要先认清楚一句话:
我不是先去做 AI 研究,我是先把一个训练好的模型,放进 STM32,让它真实运行起来。
二、为什么 TinyML 的入门 Demo,几乎都喜欢用正弦波?
如我的文章中介绍的"在STM32F103单片机上跑通AI模型:为什么选正弦波作为Hello World?",运行正弦波模型就是TInyML世界的Helloworld。它简单、干净、直观,而且特别适合把整条流程一次讲明白。
所谓正弦波 Demo,本质上就是:让模型学习y=sinx(x)这个函数关系。
如果模型学得对,MCU 输出的曲线就会和真实正弦曲线很接近;如果模型没学好,曲线会明显偏掉。
其实,我们在实际产品的设计过程中,完全可以参考正弦波y=sinx(x)函数去训练更复杂的公式或者曲线。

三、不会 Python,可以学 TinyML 吗?
答案是可以,但我们不能完全不碰。
这里要分层看。
第一层:我们可以先不会"写训练代码",但不能永远不理解训练流程
入门阶段,我们完全可以先用现成的notebook、现成的训练脚本,甚至先用别人已经训练好的模型,把注意力放在部署与推理这部分。
这时候最重要的事情不是自己写复杂的训练程序,而是理解:理解数据长什么样;模型输入输出是什么;STM32上如何调用推理;结果如何验证。
这一步的目标很明确:先把第一个 Demo 跑起来,再回头补 Python。
第二层:我们至少要会"看懂"和"改少量"Python
真正做项目的时候,我们迟早还是要接触 Python的。因为数据处理、模型训练、模型转换这些环节,绝大多数都在 Python 生态里完成。
但这里的重点不是"先把 Python 学成高级开发",而是:我们至少能看懂数据读进来了没有;知道训练参数在哪改;知道模型最后是怎么导出成 .tflite 的;知道归一化参数以后 MCU 端要同步。
也就是说,TinyML 对 Python 的要求,和"做一个 Python 后端项目"完全不是一回事。
第三层:越往后走,Python 会越来越重要,但不是第一个门槛
如果我们后面要自己设计数据采集方案、自己做模型实验、自己优化精度和资源占用,那 Python 一定得补。
但那是第二阶段、第三阶段的事,不是"第一个 STM32 跑 AI Demo"的前置条件。
四、不会深度学习,可以学 TinyML 吗?
这个问题和"会不会Python"其实一样,不过很多人把顺序搞反了。
很多人一想到深度学习,就想到反向传播、梯度下降、损失函数、激活函数、卷积、量化感知训练......然后立刻放弃。
但对嵌入式工程师的入门阶段来说,最先需要掌握的,不是这些推导,而是下面几件更实际的事。
-
第一,我们要知道模型本质上就是输入和输出之间的一种映射关系。
-
第二,我们要知道训练阶段是在"调参数",推理阶段是在"用参数"。
-
第三,我们要知道 MCU 上真正跑起来的,是一个已经固定好的模型,不是训练过程本身。
-
第四,我们要知道嵌入式端最重要的有时不是模型精度,而是资源、延迟、稳定性、可验证性。
我们先把这四件事吃透,再回头补神经网络理论,理解速度会快很多。因为这个时候,我们脑子里不再只有抽象名词,而是已经有了工程对象:
输入是什么,输出是什么,模型多大,放在哪里,怎么调用,推理一次要多久,RAM 够不够。
嵌入式工程师最大的优势,不是先会公式,而是天然擅长把复杂系统拆成模块。
五、为什么说:嵌入式工程师其实比很多人更适合学 TinyML?
原因很简单,因为我们嵌入式工程师有天然优势。
很多纯算法背景的人,训练模型可能很强,但一旦到了 MCU 上,就会遇到一堆不习惯的问题:没有操作系统;没有动态内存;没有大容量 RAM;外设、采样、定时器、DMA、串口输出,全都得自己管。
而这些,恰恰是嵌入式工程师的主场。
我们可能不熟悉神经网络,但我们熟悉:资源约束;实时性;数据采样;中断和主循环;内存布局;部署与验证。
这意味着,当我们要补上TinyML的知识的时候,不是全部重新学习,而是在现有能力上加一层新能力。 不是从 0 到 1 全部重来,而是从"会写嵌入式程序"升级到"会让嵌入式系统带一点智能"。
从职业发展看,真正危险的不是我们现在不会 AI,而是还一直把 AI 当成"和我无关",或者把AI当成我们的"搜索引擎"或者聊天工具。
六、学习TInyML,最正确的学习顺序,不是先啃理论,而是先跑通闭环
根据我的经验,学习TInyML的正确的顺序应该是:
第一步:先理解TinyML的整体流程
不需要去背诵神经网络的各类名词,搞清楚TInyML中的整个工作流程即可。
第二步:先跑通一个最小 Demo
如我们前面文章中讲解的那样,跑通一个正弦波模型就是一个最好的起点。
第三步:理解 TFLite Micro 的核心结构
当我们已经看到模型在 STM32 上跑起来了,再去理解 Model、Interpreter、Tensor、Tensor Arena,这些概念会非常快。因为我们知道它们不是书本名词,而是工程里的真实对象。
第四步:补一点 Python 和最基础的数据处理
这时候再去看 notebook、训练脚本、数据切分、归一化,会轻松很多。
因为我们知道这些东西最后是为谁服务的。
第五步:最后再碰真实传感器项目
比如动作识别、声音检测、模拟量异常检测、振动预测维护。
到了这一步,TinyML 才真正开始从 Demo 走向应用。
七、最后说一句最实在的话
不会 Python,不代表你不能学 TinyML。;不会深度学习,不代表不能在 STM32 上跑起第一个模型; 不会自己设计模型,也不代表不能先把推理链路打通。
真正能把人挡在门外的,往往不是技术本身,而是错误的学习顺序。
所以,我们需要先接受这样一个事实:
"我现在的目标,不是成为算法专家,而是先让 STM32 真正跑起第一个 AI 模型。"
当我们理解了上面的逻辑,就会"让单片机运行AI"这件事变得简单很多。