
上一章我们学习了八大排序的前六个方法,今天我们讲完最后两个,再对总体进行总结复习,挑战一些进阶的排序算法学习。废话不多说,步入正题,发车!
1.归并排序
归并排序算法思想:
归并排序(MERGE-SORT)是建⽴在归并操作上的⼀种有效的排序算法,该算法是采⽤分治(Divide and Conquer)的⼀个⾮常典型的应⽤。将已有序的⼦序列合并,得到完全有序的序列;即先使每个⼦序列有序,再使⼦序列段间有序。若将两个有序表合并成⼀个有序表,称为⼆路归并。
归并排序核心步骤:
代码实现:
void _MergeSort(int* a, int left, int right, int* tmp) { if (left >= right) { return; } int mid = left + (right - left) / 2; _MergeSort(a, left, mid, tmp); _MergeSort(a, mid + 1, right, tmp); int begin1 = left, end1 = mid; int begin2 = mid + 1, end2 = right; int index = begin1; while (begin1 <= end1 && begin2 <= end2) { if (a[begin1] < a[begin2]) { tmp[index++] = a[begin1++]; } else { tmp[index++] = a[begin2++]; } } while (begin1 <= end1) { tmp[index++] = a[begin1++]; } while (begin2 <= end2) { tmp[index++] = a[begin2++]; } for (int i = left;i <= right;i++) { a[i] = tmp[i]; } } void MergeSort(int* a, int n) { int* tmp = (int*)malloc(sizeof(int) * n); _MergeSort(a, 0, n - 1, tmp); free(tmp); tmp = NULL; }
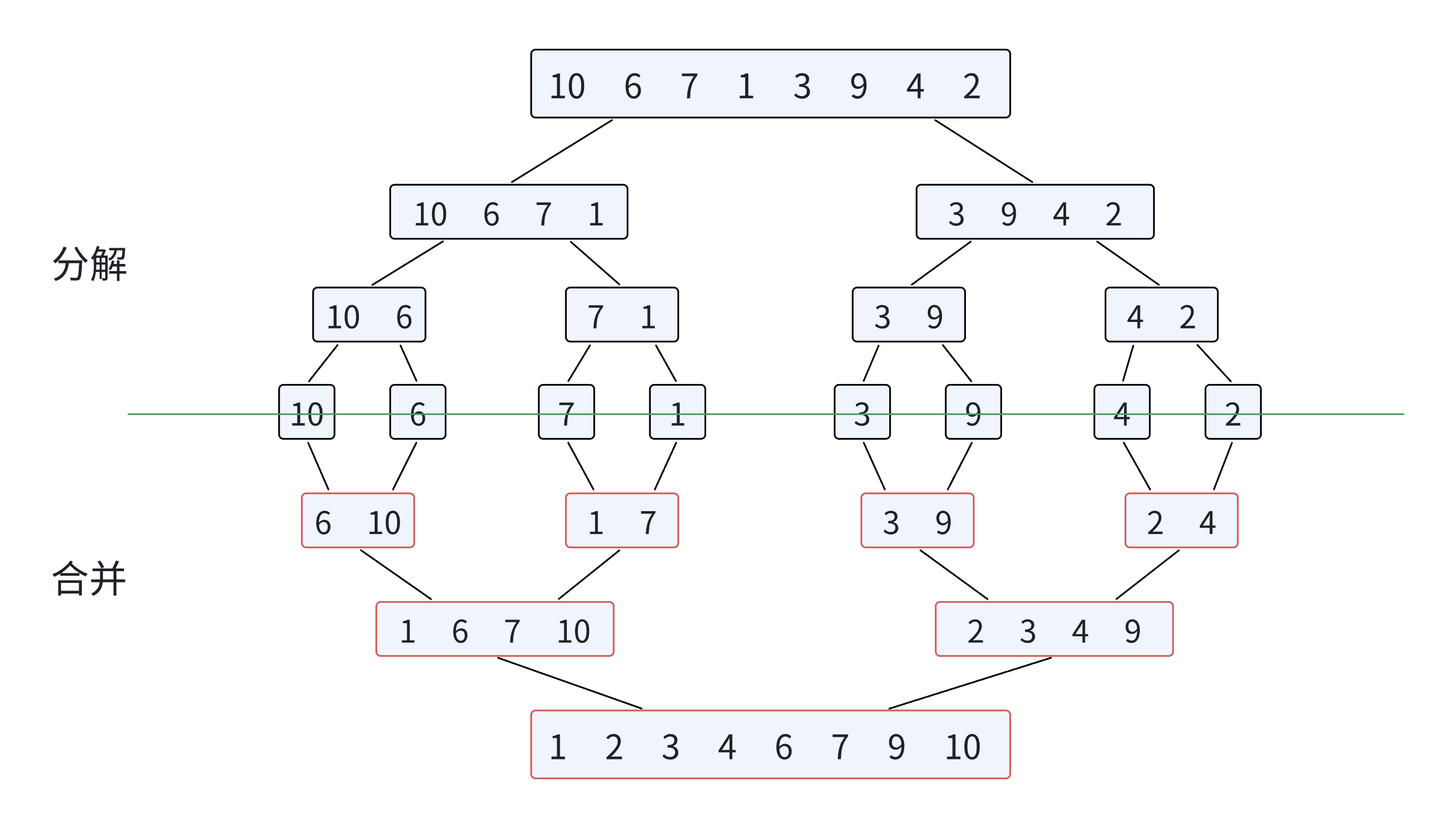
归并排序特性总结:
1. 时间复杂度: O (nlogn)
2. 空间复杂度: O (n)
2.计数排序(非比较排序)
计数排序⼜称为鸽巢原理,是对哈希直接定址法的变形应⽤。
核心算法步骤:
1.统计相同元素出现次数。
2.根据统计的结果将序列回收到原来的序列中。代码实现:
void CountSort(int* a, int n) { int min = a[0], max = a[0]; for (int i = 1;i < n;i++) { if (a[i]>max) max = a[i]; if (a[i] < min) min = a[i]; } int range = max - min + 1; int* count = (int*)malloc(sizeof(int) * range); if (count == NULL) { perror("malloc fail"); return; } memset(count, 0, sizeof(int) * range); for (int i = 0;i < n;i++) { count[a[i] - min]++; } int j = 0; for (int i = 0;i < range;i++) { while (count[i]--) { a[j++] = i + min; } } }
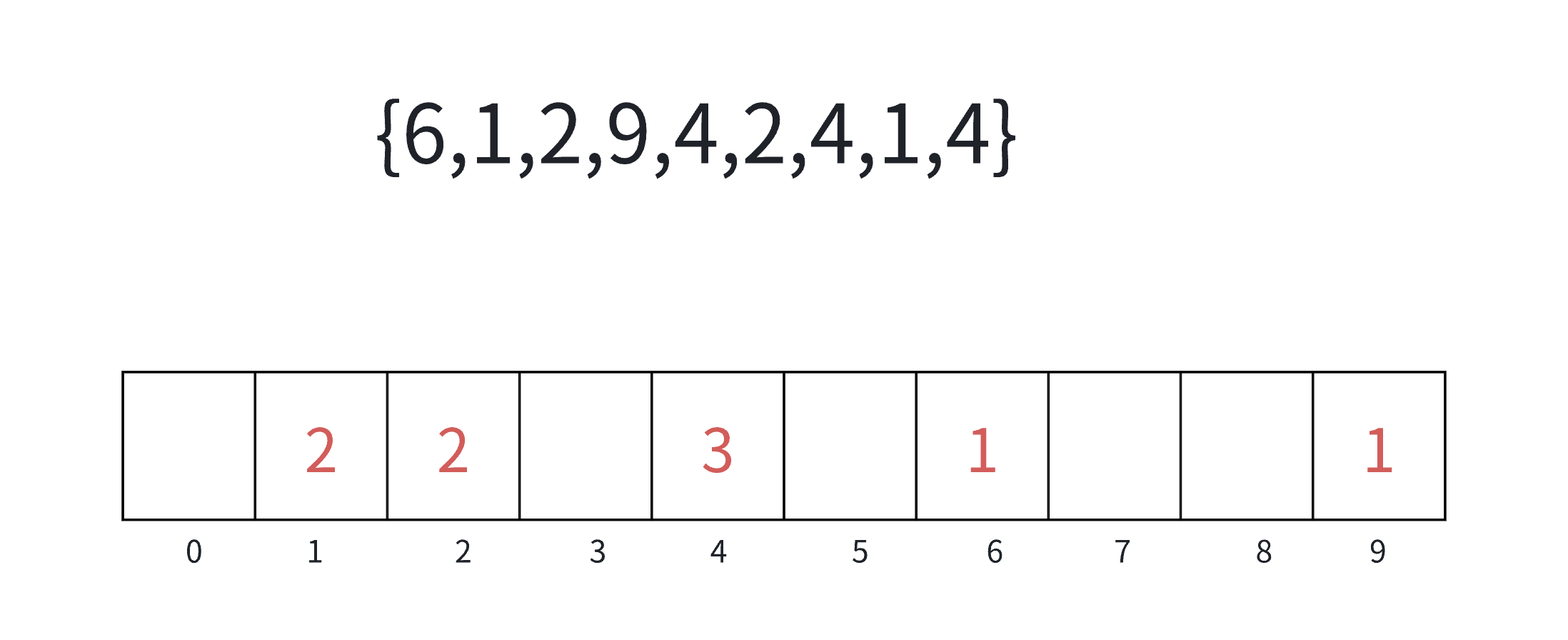
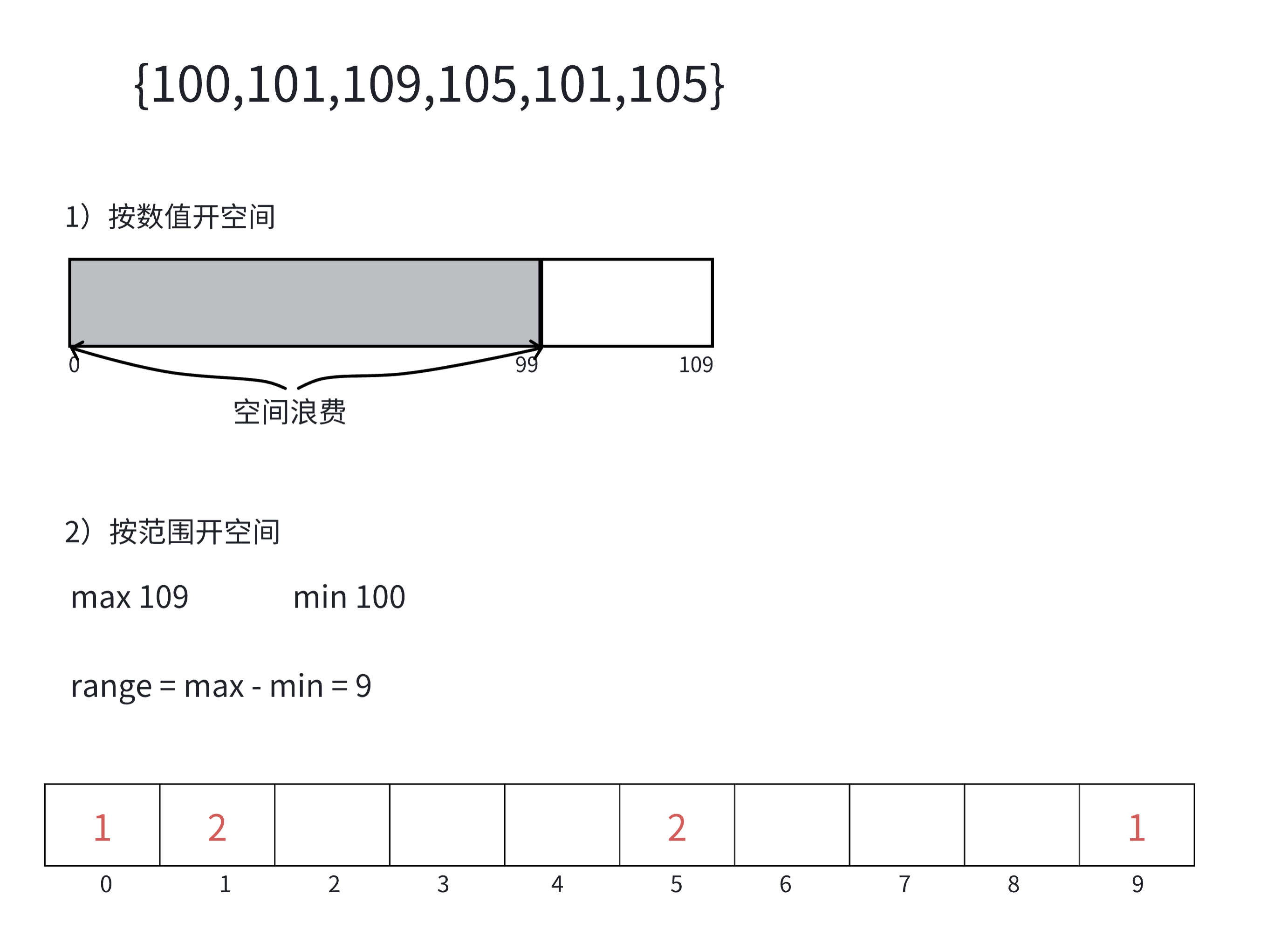
计数排序的特性:
计数排序在数据范围集中时,效率很⾼,但是适⽤范围及场景有限。
时间复杂度: O (N + range)
空间复杂度: O (range)
3.八大算法总结归纳
排序算法复杂度及稳定性分析
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,ri=rj,且ri在rj之前,⽽在排序后的序列中,ri仍在rj之前,则称这种排序算法是稳定的;否则称为不稳定的。|--------|---------------------------------|-----------------|-----------------|--------------------------|-----|
| 排序算法 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
| 冒泡排序 | O(*n^*2 ) | O(n) | O(*n^*2 ) | O(1) | 稳定 |
| 直接选择排序 | O(*n^*2 ) | O(*n^*2 ) | O(*n^*2 ) | O(1) | 不稳定 |
| 直接插⼊排序 | O(*n^*2 ) | O(n) | O(*n^*2 ) | O(1) | 稳定 |
| 希尔排序 | O(nlog n) ~ O(*n^*2 ) | O(*n ^*1.3 ) | O(*n^*2 ) | O(1) | 不稳定 |
| 堆排序 | O(nlog n) | O(nlog n) | O(nlog n) | O(1) | 不稳定 |
| 归并排序 | O(nlog n) | O(nlog n) | O(nlog n) | O(n) | 稳定 |
| 快速排序 | O(nlog n) | O(nlog n) | O(*n^*2 ) | O(log n) ~ O(n) | 不稳定 |
| 计数排序 | O(n+ range) | O(n) | O(n^2) | O(n+ range) | 不稳定 |
算法步骤总结(纯手写)
自己总结的步骤,如有不合理的请见谅哦!
1.冒泡算法:通过两次for循环将每个数都两两对比,最后排序。
2**.直接选择排序****:创建maxi和mini指针遍历数组,每次寻找最大值和最小值,然后将其与数组尾头交换,第一遍时数组左右分别是最小值和最大值,然后让begin和end分别缩进1,再次循环步骤,直到相遇。**
3.直接插入排序:通过for循环将每个数都能插入到位置,定义end为起始位置,tmp记录下一位置数据,然后将end位置数据与tmp对比,小就继续走,大则交换位置,然后将tmp再次与之前的数据进行同样对比,此时数组在i的位置之前数据是有序的,重复循环,知道i走到倒数第二个数据进行最后一次对比。
4.希尔排序:定义gap为数组大小,然后利用while循环将gap以gap =n/3+1逐渐缩小,以每次gap的值为间隔,进行数据对比和交换(与直接插入排序类似),经过gap的缩小,使相邻数据的大小差距变小,数组逐渐有序,最后当gap=1时,即为直接插入排序,此时交换的次数就少了,效率提高。
5.堆排序:先掌握向下调整算法来建堆,知道父节点,然后child = parent * 2 + 1找到左孩子,通过左孩子判断右孩子是否存在,如果都存在,也知道升序建大堆,降序建小堆,判断左右孩子的大小情况,将大小与父节点交换,然后孩子成为父节点,循环程序。将数组建立大(小)堆后,交换arr【0】根节点与arr【end】尾节点,进行循环建堆,循环输出,知道全部输出为有序数组。
6.归并排序: 通过找中间值mid,对数组进行分解,将其不断二分,直到全部变为单个数组,再通过定义两组begin和end保证原数组的位置不丢失和定义index保存数组开头位置,用while循环将两个数组合并,将其按大小关系存储到*tmp指向的空间中,当其一全部存储后,再将其二存储进空间(由于递归,此时每次数组的大小有序),最后*tmp指向的空间中存储了有序数据,再将其依次导入到arr数组中。
7.快速排序:通过寻找基准值,不断使数组的左右序列元素小于或大于基准值,形成递归后,区间变小,基准值所影响的数组区间也小,数组整体逐渐有序。(此处的难点就在于如何寻找基准值)。
8.计数排序:先通过for循环遍历数组,找到最小值和最大值,通过max-min+1算出统计数据范围,后为每个数据申请空间,用于后续统计数据个数,使用for循环,遍历数组,用counta\[i - min]++来统计次数,最后按照次数(count--)依次输出(i+min)数据到数组中。
快排的版本总结
1.hoare版本:创建左右指针,分别位于数组头尾,左指针向右遍历数组,找比基准值大的数据,右指针向左遍历数组,找比基准值小的数据,当都找到时,交换左右指针的数据,以此形成循环,直到左右指针相遇,最后左右指针指向的数据再交换基准值,返回右指针。
2.挖坑法版本:创建左右指针,初始key为左指针指向数据为基准追。右指针在保证不遇到左指针的情况下,向左遍历寻找比key小的数据,找到了,将数据填入坑中,原来位置形成新坑;左指针向右遍历寻找比key大的数据,找到了,将数据填入坑中,原来位置形成新坑,形成循环,当左右指针相遇之前,将key值放入坑中,返回此时下标值。
3.lomuto版本:以左边的第一个数据为基准值,创建双指针prev为left,cur为prev+1,保证cur不走到右边尽头的情况下,让cur向右遍历数组,当cur指向数据小于基准值且prev与cur没重合(位于开头且数据符合无需交换),交换双指针的数据,让prev向右移动;大于基准值,cur则继续走,当cur走到右边尽头时,交换基准值与prev所指数据,返回prev。(小的留左边,大的向右推)
5.非递归--栈版本:创建一个栈,将左右下标志压入,当栈不为空,取栈顶两次,分别为begin和end,再在begin,end区间内找基准值,用到lomuto法,此时数组变为begin,keyi-1和keyi+1,end 此时循环左右下标志入栈,缩小范围,使数组被分为多个,最后当数组大小为1时,跳出循环,此时原数组有序。