前面我们阅读了这篇文章的骨架,是以问题为导向,对目前FF3D的395篇论文做了分类解读,然后分别介绍了数据集与评价体系,最后是下游应用与未来方向,在上文中,我们跟随作者梳理了当前的几种3D表征方式。接下来重点来看一看具体的几个研究方向在做什么。
4 Research Directions
尽管学界已逐渐收敛到统一的范式(第2节),前馈式重建仍然存在许多开放性的挑战,吸引了大量的研究关注。
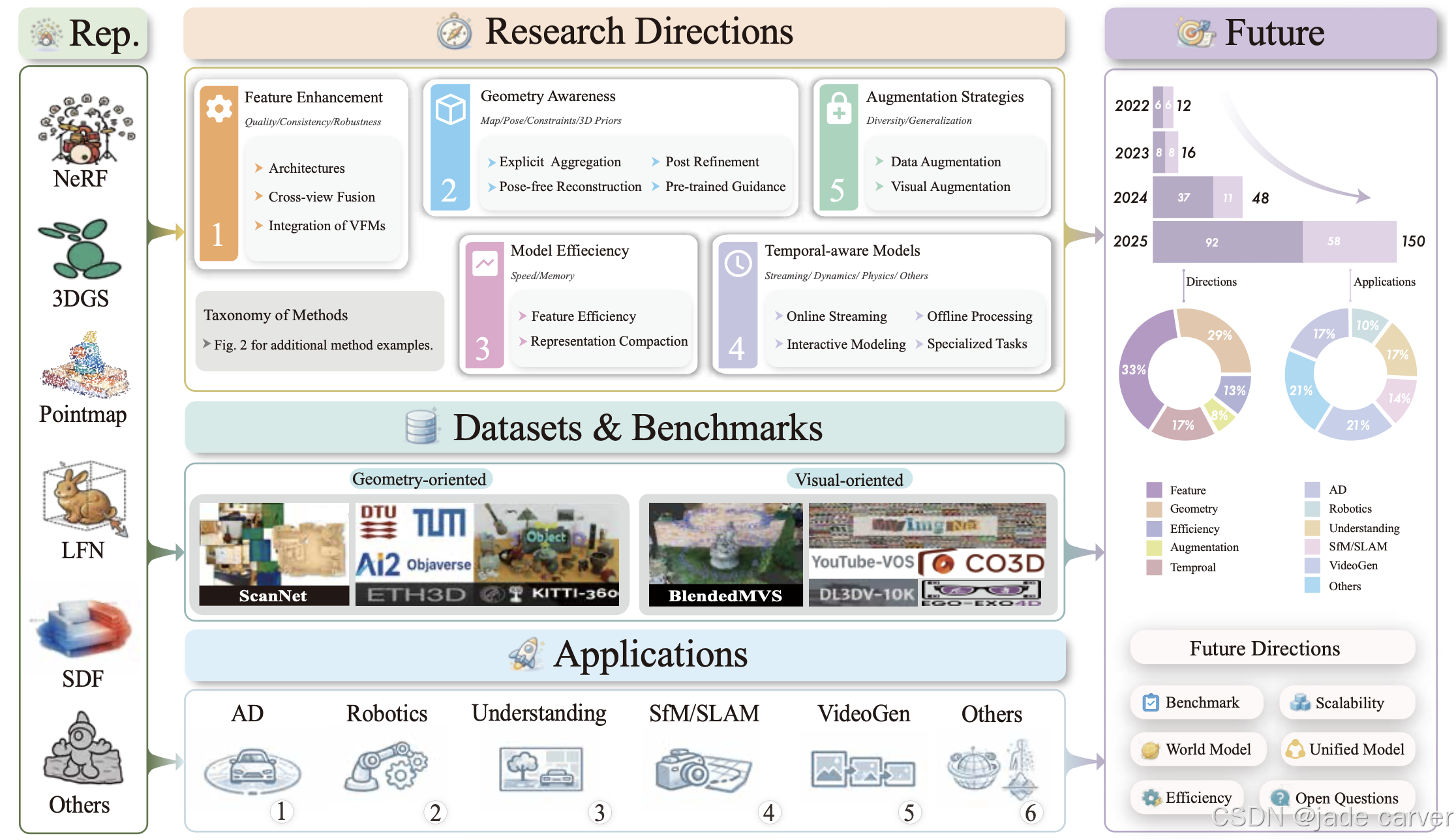
如图2所示,我们将这些方法组织为五个方向:1)特征增强 (第4.1节),通过更优的架构、跨视图融合或视觉基础模型的集成,提升隐式表示的质量;2)几何感知 (第4.2节),引入几何先验以解决深度模糊性问题,并处理稀疏或无助教输入(即无相机位姿)的情况;3)模型效率 (第4.3节),降低计算和内存开销,以便于实际部署;4)数据增广策略 (第4.4节),利用数据或视觉增广来提升泛化能力;5)时序感知模型(第4.5节),将范式扩展到动态场景和流式输入场景。这种以问题为导向的分类方式跨越了不同的输出表示。
无论是基于NeRF、3DGS还是点图的方法,都可能出现在上述五个方向中的任何一个,因为其解决的核心挑战决定了它们的分类归属。为简洁起见,本节仅收录具有代表性的方法。

4.1 Feature Enhancement
在前馈式神经渲染模型中,隐式特征图是整个网络的枢纽。其质量直接决定了3D场景解码的效果,因此,提升这些特征的质量对于增强渲染精度和模型泛化能力至关重要 。为增强前馈模型中的特征,已有大量研究从以下三个方向展开:1)网络架构(第4.1.1节) ------特征提取器从早期基于CNN的条件机制,逐步演进到Transformer及状态空间模型,以获取更丰富的全局上下文信息;2)跨视图融合(第4.1.2节) ------将来自多个视图的特征聚合为几何上一致的表示;3)视觉基础模型的融合(第4.1.3节)------引入预训练的几何与语义先验知识,而不完全依赖从3D数据中学习全部表示。
4.1.1 Architectures
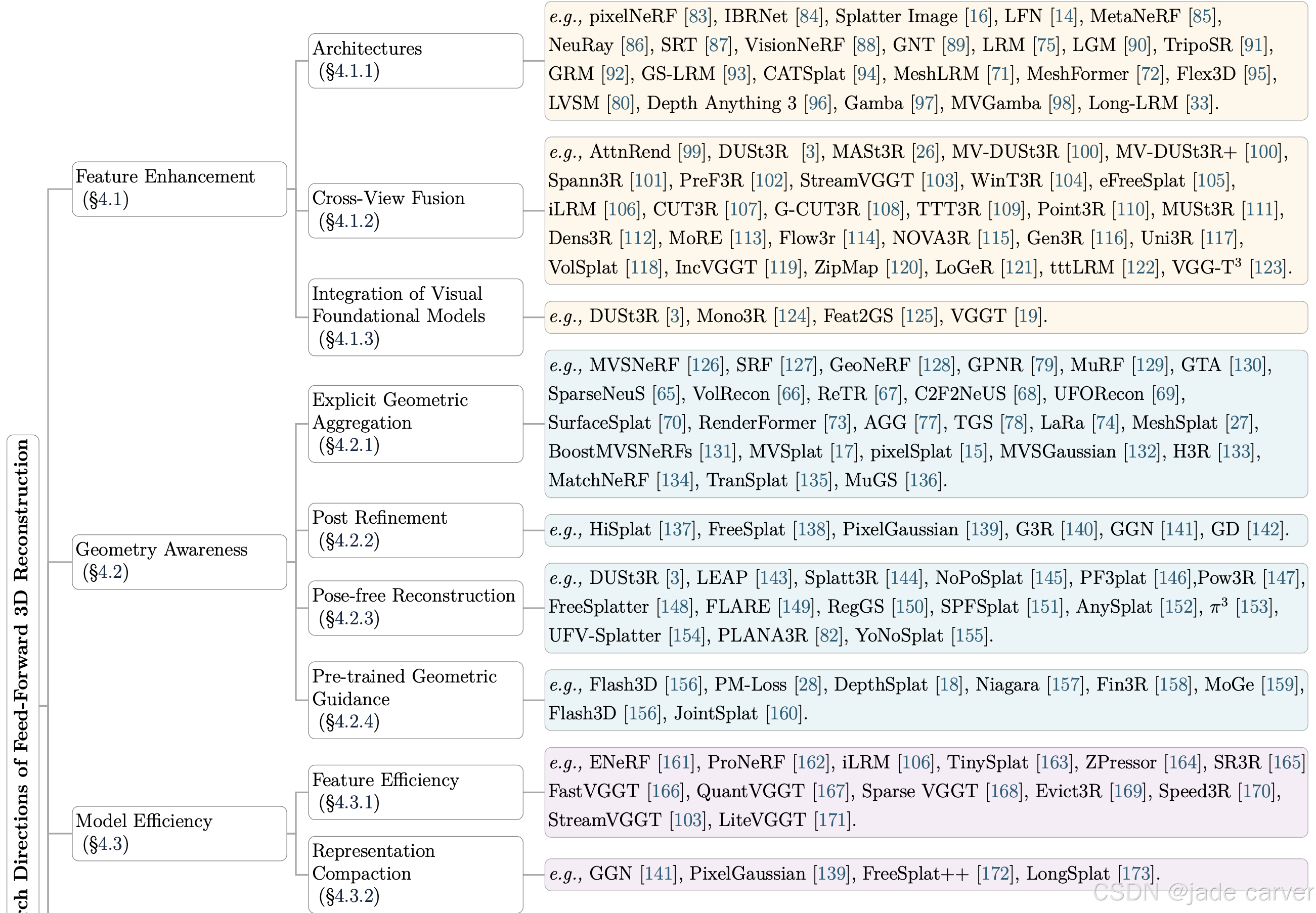
特征提取架构的设计是整个重建流程的基石。如图3所示,学界探索了多种编码器主干网络,从早期的ResNet 209 逐步演进到ViT 208,以注入丰富的视觉与几何知识。下面将主要涉及的文章以及架构做成列表。
网络架构方面,经过了从最早的CNN 系列到Transformer ,再到Mamba的过程,整体趋势是不断增强全局上下文建模能力、跨视图信息融合能力以及模型的可扩展性。具体如下表:
早期前馈式神经渲染方法(基于CNN/U-Net)
| 方法 | 核心架构 | 特点描述 |
|---|---|---|
| PixelNeRF 83 | 全卷积网络 | 从单视图或少视图预测NeRF,将射线MLP构建为邻近视图局部图像特征的聚合函数 |
| IBRNet 84 | 射线Transformer | 学习连续视图插值函数,沿查询射线联合处理密度、遮挡和颜色混合 |
| Splatter Image 16 | U-Net | 从单张图像预测像素对齐的3D高斯球 |
| 卷积占用网络 64 | 卷积编码器 + 隐式占用解码器 | 结合卷积编码器的表达能力与隐式占用解码器 |
| LFN 14 | 神经隐式函数 | 将场景表示为4D光场 |
| NeuRay 86 | 可见性预测 | 预测输入视图中3D点的可见性,增强特征一致性 |
| C3-GS 220 | 上下文感知编码器 | 跨空间维度和尺度混合信息,保留局部几何线索用于高斯预测 |
基于Transformer的特征提取架构
| 方法 | 核心架构 | 特点描述 |
|---|---|---|
| SRT 87 | Transformer解码器 | 将输入图像处理为场景表示的潜在特征,最小化新视图重建误差 |
| RePAST 221 | 注意力机制 + 相对位姿 | 将成对相对相机位姿信息融入注意力机制,消除对全局参考系选择的依赖 |
| GNT 89 | 两阶段Transformer | 视图Transformer沿极线聚合信息,射线Transformer在光线行进采样点处解码渲染新视图 |
| VisionNeRF 88 | ViT + CNN | ViT提取全局上下文,与CNN局部特征融合以条件化NeRF体积渲染 |
| LRM 75 | ViT + Transformer解码器 | ViT编码单图特征,Transformer解码器扩展为三平面特征网格 |
| Instant3D 76 | ViT + Transformer解码器 | 同LRM核心架构 |
| TripoSR 91 | 基于LRM架构 | 在数据处理、模型设计和训练技巧上进行了实质性改进 |
| GRM 92 | LRM派生 | 直接输出3DGS参数,无需中间三平面 |
| GS-LRM 93 | LRM派生 | 直接输出3DGS参数,简化重建流程 |
| MeshLRM 71 | LRM + 可微marching cubes | 将LRM从NeRF重定向到网格输出 |
| MeshFormer 72 | 3D稀疏体素 + Transformer + 3D卷积 | 将特征存储在3D稀疏体素中,混合Transformer与3D卷积 |
| Flex3D 95 | Transformer扩展 | 支持可变数量的输入视图及其对应视角 |
| LVSM 80 | 纯Transformer | 完全数据驱动的新视图合成,不依赖显式3D表示 |
| VGGT 19 | 基础模型 + 多任务预训练 | 通过多任务预训练(相机位姿、深度图、点云)学习通用视觉几何特征空间 |
| Depth Anything 3 96 | 单平面Transformer | 无额外特殊设计,使用纯Transformer实现 |
基于状态空间模型(Mamba)的特征提取架构
| 方法 | 核心架构 | 特点描述 |
| Gamba 97 | Mamba-based GambaFormer | 将单图到3DGS重建建模为序列预测,支持token长度的线性扩展 |
| MVGamba 98 | Mamba + 跨视图自优化 | 扩展到多视图输入 |
| Long-LRM 33 | 状态空间模型 | 处理长图像序列的大场景重建,避免Transformer的二次复杂度问题 |
|---|
架构演进路线总结
早期CNN/U-Net方法
-
核心贡献:建立图像特征到3D表示的映射基础
-
代表方法:PixelNeRF(全卷积条件化)、IBRNet(射线Transformer)、Splatter Image(U-Net预测3DGS)、NeuRay(可见性预测增强一致性)
Transformer方法
-
两阶段Transformer:GNT(视图Transformer + 射线Transformer)
-
LRM系列:LRM/Instant3D(ViT + Transformer解码器 → 三平面特征网格);GRM/GS-LRM(直接输出3DGS参数);MeshLRM/MeshFormer(输出网格)
-
基础模型:VGGT(多任务预训练学习通用视觉几何特征);Depth Anything 3(纯平面Transformer)
-
位姿处理改进:RePAST(将相对位姿融入注意力机制,消除全局参考系依赖)
状态空间模型方法
-
Gamba/MVGamba:将重建建模为序列预测,支持线性token长度扩展
-
Long-LRM:处理长图像序列大场景重建,避免Transformer二次复杂度问题
| 阶段 | 代表架构 | 关键特点 | 主要局限/演进方向 |
| 早期CNN/U-Net | PixelNeRF, IBRNet, Splatter Image | 从图像对齐特征查询进行辐射评估 | 全局上下文捕捉能力有限 |
| Transformer引入 | SRT, GNT, VisionNeRF | 自注意力提取全局上下文,支持跨视图信息交互 | 长序列下二次复杂度高 |
| 基础模型集成 | LRM系列, VGGT, Depth Anything 3 | 大规模预训练,通用视觉几何先验 | 计算资源需求大 |
| 状态空间模型 | Gamba, MVGamba, Long-LRM | 线性复杂度,支持长序列处理 | 相对较新,生态不如Transformer成熟 |
|---|
4.1.2 Cross-View Fusion
增强隐式表示的一个关键方面在于融合来自多个视角的信息,以形成一个连贯且几何一致的3D场景。实现这一目标需要建立鲁棒的跨视图特征对应关系,有效捕捉输入图像之间的空间关系。
现有方法主要沿以下几个方向演进:
注意力与Transformer融合:从AttnRend的多视图ViT注意力,到iLRM的迭代优化与两阶段注意力,核心是提升不同视图间特征的一致性与表达效率。
几何优先的坐标回归(DUSt3R系列):将特征增强问题转化为直接的3D坐标与相机几何回归,通过稠密点图预测实现跨视图对齐。MASt3R、MV-DUSt3R、MUSt3R等方法进一步引入匹配损失、多视图解码器、对称架构等,实现更鲁棒、可扩展的融合。
超越像素对齐的统一几何模型:Dens3R、MoRE、NOVA3R等不再局限于像素级预测,而是学习全局场景表示或联合预测多种几何量,甚至结合视频扩散与开放词汇理解。
长序列与动态场景的全局一致性:当输入变为长序列或视频时,主要挑战转向如何在有限内存下保持全局一致。代表性思路包括:
- 持久记忆机制(PreF3R、Spann3R)
- 压缩全局状态(CUT3R)
- 测试时训练(TTT3R、ZipMap、LoGeR、tttLRM、VGG-T3)
- 免训练增量推理(IncVGGT)
总体趋势是从单次前馈的静态多视图融合 ,逐步演进到支持可变长度、动态场景、实时性与全局一致性兼顾的增量式、记忆增强或测试时训练的框架。
基于注意力与Transformer的跨视图特征增强
| 方法 | 核心机制 | 特点描述 |
|---|---|---|
| AttnRend 99 | 多视图ViT编码器 + 跨视图注意力 | 利用注意力机制融合视图与相机位姿,提取高一致性特征 |
| eFreeSplat 105 | 自监督ViT + 跨补全预训练 + 高斯对齐模块 | 通过2D U-Net迭代优化高斯参数,超越极线方法 |
| LGM 90 | 非对称U-Net | 高吞吐量骨干网络,直接回归3DGS参数 |
| iLRM 106 | 迭代式跨视图优化 + 两阶段注意力 | 多次反馈特征,降低计算成本的同时提升重建质量 |
几何优先的特征增强方法(DUSt3R系列)
| 方法 | 核心机制 | 特点描述 |
|---|---|---|
| DUSt3R 3 | 稠密坐标回归 | 从无位姿图像对同时预测点图与相对相机位姿 |
| MASt3R 26 | 稠密局部特征头 + 匹配损失 + 快速双向匹配 | 增强DUSt3R的匹配能力 |
| MV-DUSt3R 100 | 多视图解码器模块 | 促进跨视图信息交换 |
| MV-DUSt3R+ 100 | 多参考视图 + 高斯预测头 | 支持直接渲染监督,数秒重建大场景 |
| MUSt3R 111 | 对称架构 + 内存机制 | 与参考视图选择无关,可扩展至大量视图 |
| WinT3R 104 | 滑动窗口Transformer | 固定延迟窗口内推理,以最小延迟换取全局一致性 |
超越像素对齐的统一几何基础模型
| 方法 | 核心机制 | 特点描述 |
|---|---|---|
| Dens3R 112 | 统一几何基础模型 | 联合预测点图、深度、法线等稠密几何量 |
| MoRE 113 | 混合专家架构 | 提升跨不同几何任务的可扩展性与专业化 |
| Flow3r 114 | 分解光流预测 | 从无标注单目视频学习可扩展视觉几何 |
| NOVA3R 115 | 全局场景表示 | 从无位姿图像解码完整非模态几何 |
| Gen3R 116 | 几何与外观潜在对齐 | 连接前馈重建与视频扩散,用于场景级3D生成 |
| Uni3R 117 | 语义3D高斯基元联合重建 | 统一渲染、深度预测与开放词汇3D理解 |
| VolSplat 118 | 体素对齐预测策略 | 直接从3D特征回归高斯函数 |
长序列与动态场景的全局一致性增强
| 方法 | 核心机制 | 特点描述 |
|---|---|---|
| PreF3R 102 | 空间记忆网络 | 持久全局场景表示,增量融合时序信息 |
| Spann3R 101 | 外部3D空间记忆 | 存储逐点特征,基于3D位置写入更新 |
| CUT3R 107 | 压缩状态表示 | 处理图像流,可推断未观察结构,支持动态场景 |
| G-CUT3R 108 | 预训练位姿+深度先验 | 增强CUT3R |
| TTT3R 109 | 测试时训练 + 闭式学习率 | 从记忆状态和新观测推导更新率,增强长度泛化 |
| Point3R 110 | 以点为中心的因果重建 | 极简设计,强实时性 |
| IncVGGT 119 | VGGT免训练增量变体 | 内存受限的长程重建,无需完整序列处理 |
| ZipMap 120 | 测试时训练 + 压缩隐式状态 | 线性时间双向重建 |
| LoGeR 121 | 分块处理 + 滑动窗口注意力 + 测试时训练记忆 | 全局一致的长上下文重建 |
| tttLRM 122 | 测试时训练层 | 线性复杂度长上下文自回归3D重建 |
| VGG-T3 123 | 测试时训练蒸馏 | 将变长表示蒸馏为固定MLP,线性扩展 |
4.1.3 Integration of Visual Foundation Models
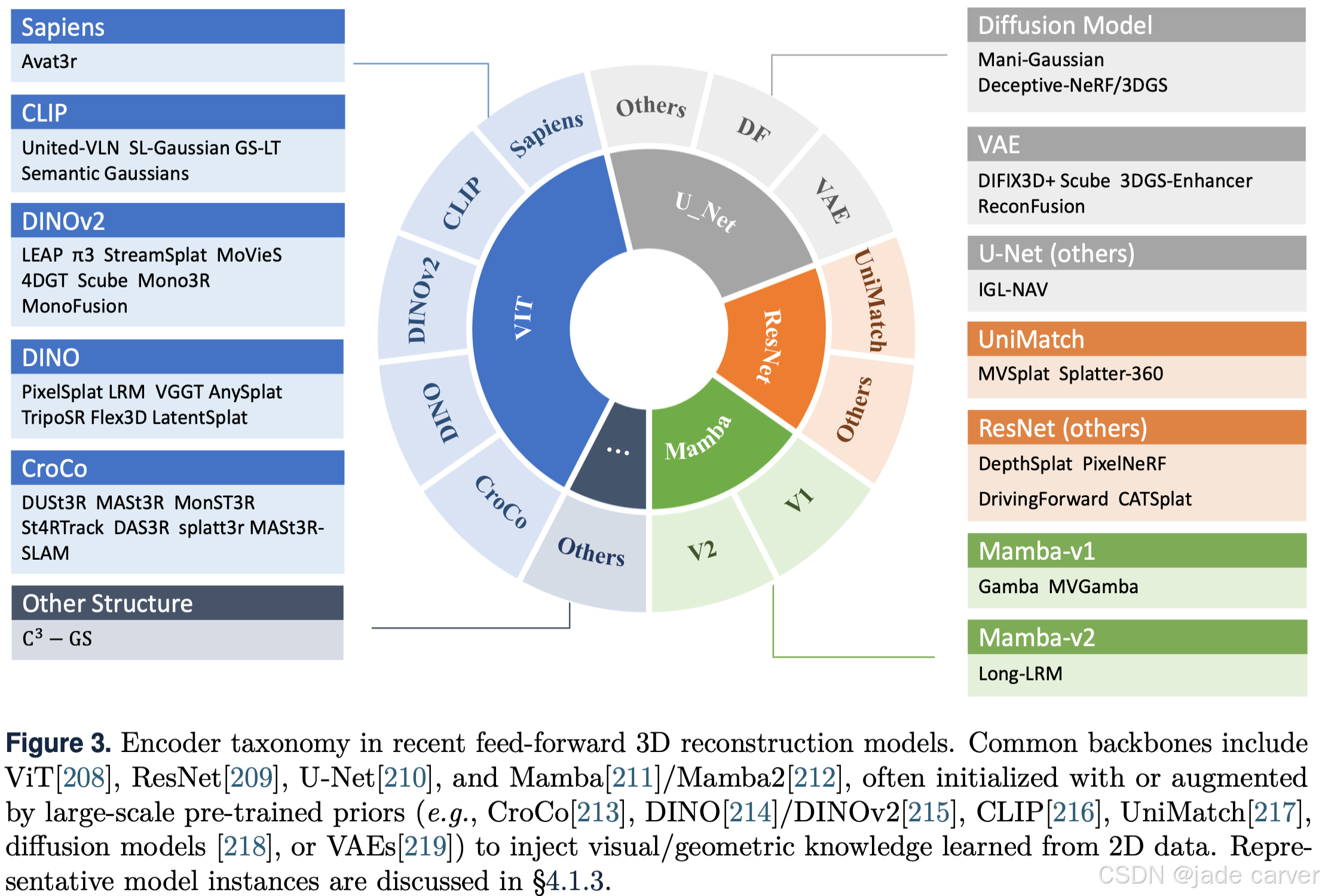
利用大规模预训练基础模型,将强大的视觉和几何先验知识注入3D重建流程,是一个重要的研究范式。这些模型通过迁移从海量且多样化的2D数据集中学到的知识来增强隐式表示,显著提升了泛化能力和数据效率。现有方法主要体现为以下几种范式:
预训练对应模型的集成:如 DUSt3R 使用 CroCo 建立图像间的特征对应关系,为后续重建奠定基础。
单视图先验的注入:如 Mono3R 通过单目引导细化模块,将单视图几何先验与多视图立体特征融合,在弱纹理或遮挡等对应关系薄弱的区域显著提升重建质量。
通用2D基础模型的探测:如 Feat2GS 展示了无需重新训练大型3D网络,仅通过轻量级解码器即可从预训练的2D模型(分割、扩散、识别等)中提取有效的3D几何先验,直接映射为3DGS表示,证明了2D特征中已经蕴含了丰富的3D信息。
多模态(文本)先验的引入:如 CATSplat 利用视觉-语言模型的文本语义作为条件,在视觉信息不足时补偿缺失信息,增强重建的结构合理性。
总体趋势是从单一预训练模型的使用 (如对应关系模型)逐步扩展到多种2D基础模型的探测 ,再到跨模态(视觉-语言)先验的融合 ,核心目标都是通过迁移大规模2D数据中蕴含的先验知识,提升前馈式3D重建的泛化能力、数据效率以及在困难区域(弱对应、视觉信息有限)的重建质量。
| 方法 | 所用预训练模型/先验 | 核心机制 | 特点描述 |
|---|---|---|---|
| DUSt3R 3 | CroCo 213 | 将预训练模型纳入前馈重建框架 | 最早在图像间建立鲁棒特征对应关系 |
| Mono3R 124 | 单视图先验 159, 215 | 单目引导细化模块 + 多视图立体特征融合 | 增强对应关系薄弱区域的重建质量 |
| Feat2GS 125 | 分割、扩散、识别、表示学习等2D模型 | 轻量级解码器直接映射为3DGS参数 | 无需重新训练大型3D网络,证明2D特征已蕴含丰富几何先验 |
| CATSplat 94 | 视觉-语言模型 | 基于语言导出的语义信息调节重建 | 在视觉信息有限时补偿缺失信息,增强结构合理性 |
4.2 Geometry Awareness
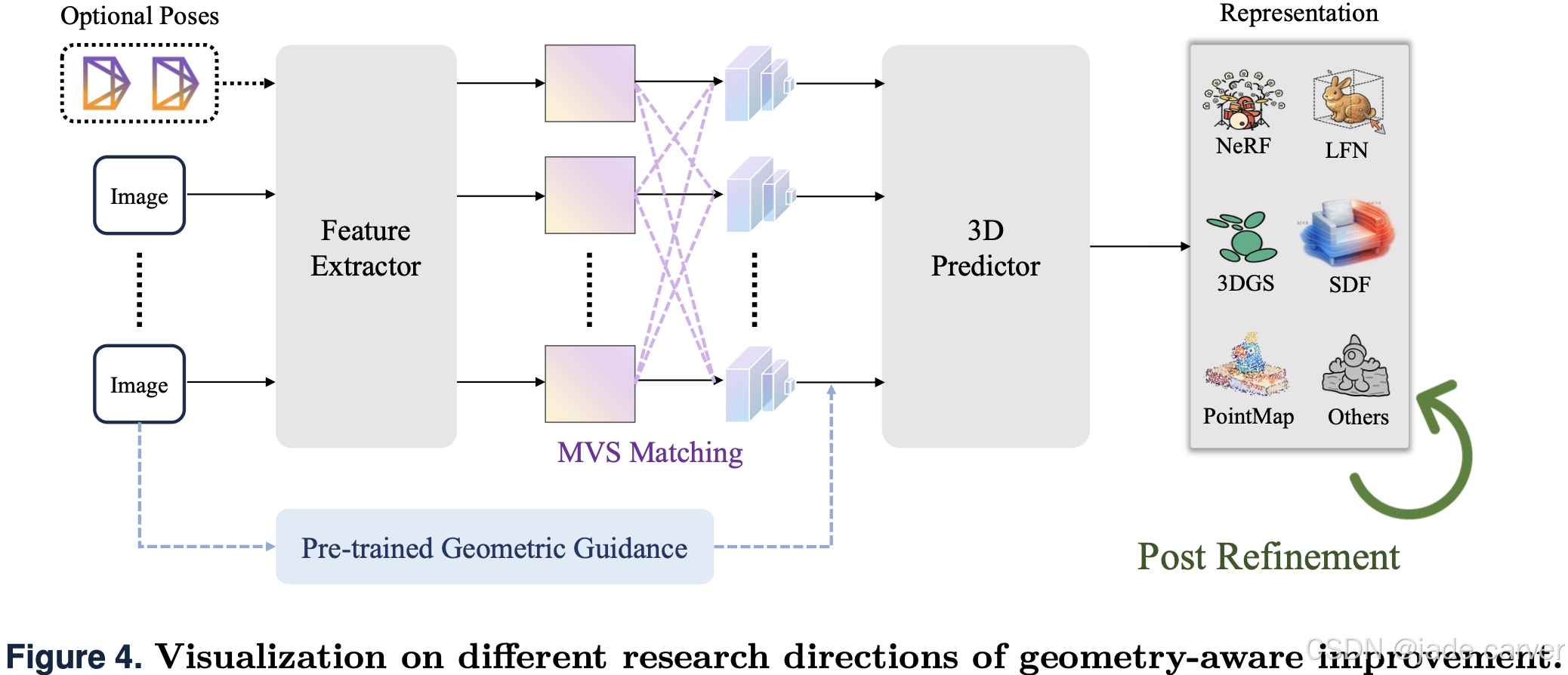
前馈式3D重建的一个核心挑战在于如何鲁棒且准确地推断底层场景几何。如图4所示,几何感知流程通常将图像(以及可选的相机位姿)通过特征提取器和3D预测器输入,以生成各种表示形式,而不同的研究方向则从互补的角度改进这一流程 。重建形状的保真度至关重要,因为它直接决定了最终输出的照片真实感和多视图一致性,并能防止漂浮物或表面畸变等伪影。因此,该领域的研究重点是开发能够融入更强几何推理能力的架构 。这一追求产生了多种策略,大致可分为以下几类:1)显式几何聚合(第4.2.1节) :引入代价体积、极线约束等结构,将多视图关系具体化;2)后处理细化(第4.2.2节) :迭代优化生成的基元,以更好地捕捉复杂几何;3)无位姿重建(第4.2.3节) :通过联合推断几何和相机位姿,消除对已知相机参数的依赖;4)预训练几何引导(第4.2.4节):从基础模型迁移丰富的几何先验,以提升重建质量。
4.2.1 Explicit Geometric Aggregation
仅依赖2D图像特征可能导致几何歧义。为了解决这一问题,近期方法引入了显式几何聚合机制,对多视图之间的几何关系进行编码。这些方法的主要区别在于如何构建和传播几何证据,涵盖了从代价体积和对应约束到表面感知建模及几何引导的高斯预测等多种方式。现有方法主要沿着以下几个方向演进:
代价体积构建(MVSNeRF → GeoNeRF → BoostMVSNeRFs):最经典的显式聚合方式,通过平面扫描构建代价体积并用3D卷积聚合,提供强几何先验。演进方向是从单尺度到级联、从室内到城市尺度。
对应关系推理(SRF → GPNR → MatchNeRF → GTA):避免完整代价体积的高成本,通过立体对应、极线约束或特征相似度作为几何代理,在大基线、稀疏视角下表现出色。
表面感知表示(SparseNeuS → VolRecon → ReTR → C2F2NeUS → UFORecon → SurfaceSplat):结合SDF与体积渲染或网格与Transformer,专注于高保真表面重建。演进趋势是从有限视图稳定到零样本泛化,再到任意视图集的鲁棒性。
高斯+混合表示(AGG, TGS, LaRa, MeshSplat):将显式几何聚合扩展到高斯泼溅框架,引入三平面-高斯混合、2DGS、级联上采样等策略,兼顾效率与几何质量。
MVS + 3DGS融合(pixelSplat → MVSplat → MVSGaussian → TranSplat):将MVS中的平面扫描代价体积原理与3DGS的可微分渲染相结合,实现轻量级、高精度的前馈高斯重建。演进方向包括概率采样、深度置信图、单目先验等增强。
混合架构(H3R, MuGS):通过潜在体积、普吕克坐标条件注意力、多线索统一(MVS + 单目深度)等方式,在几何一致性与计算效率之间取得平衡,特别改善了无纹理等困难区域的性能。
总体趋势是从纯NeRF体积渲染 逐步扩展到高斯泼溅和混合表示 ,从稠密代价体积 演进到更轻量、更鲁棒的对应关系推理 ,从依赖已知位姿 走向更灵活的几何先验融合,核心目标是提升前馈重建的几何精度、泛化能力以及在挑战性场景(稀疏视图、大基线、无纹理区域)下的鲁棒性。
基于代价体积的显式几何聚合方法
| 方法 | 核心机制 | 特点描述 |
|---|---|---|
| MVSNeRF 126 | 平面扫描变换 + 3D卷积聚合 | 首次探索代价体积引导NeRF重建 |
| GeoNeRF 128 | 级联代价体积 + Transformer渲染器 | 两阶段设计,专门建模几何与遮挡 |
| BoostMVSNeRFs 131 | 尺度感知先验 + 自适应机制 | 适用于城市级和开放环境 |
| MuRF 129 | 目标视图视锥体体积 + 3D卷积 | 多平面对齐目标相机,捕捉上下文信息 |
基于对应关系与特征相似性的几何聚合方法
| 方法 | 核心机制 | 特点描述 |
|---|---|---|
| SRF 127 | 神经立体框架,图像对立体对应 | 避免完整构建代价体积 |
| GPNR 79 | 极线几何 + 局部块聚合 | 不依赖体积渲染,大基线鲁棒 |
| MatchNeRF 134 | 特征余弦相似度作为几何代理 | 形式化特征相似性与密度的关联 |
| GTA 130 | 显式编码几何变换到注意力机制 | 增强表示效率和几何感知能力 |
基于表面感知的几何聚合方法
| 方法 | 核心机制 | 特点描述 |
|---|---|---|
| SparseNeuS 65 | SDF表面 + 体积渲染 | 有限视图下几何稳定性 |
| VolRecon 66 | SRDF + 基于射线的渲染 | 改进监督质量与泛化能力 |
| ReTR 67 | Transformer + 元射线token | 零样本神经表面重建 |
| C2F2NeUS 68 | 每视图代价平截头体 + 级联融合 | 从粗到细,高保真表面重建 |
| UFORecon 69 | 移除对预定义视图组合的依赖 | 鲁棒于稀疏、未对齐或偏置输入 |
| SurfaceSplat 70 | SDF粗略几何 + 3DGS渲染细化 | 混合方法,更准确的表面重建 |
| RenderFormer 73 | Transformer直接渲染三角网格 | 基于3D位置编码,感知显式网格几何 |
基于高斯与混合表示的几何聚合方法
| 方法 | 核心机制 | 特点描述 |
|---|---|---|
| AGG 77 | 三平面粗表示 + 3D高斯上采样 | 级联流程 |
| TGS 78 | 混合三平面-高斯中间表示 | Transformer解码,单视图重建 |
| LaRa 74 | 高斯体积 + Transformer分组注意力 | 高效大规模前馈辐射场 |
| MeshSplat 27 | 每视图2DGS预测 | 无需真实3D地面数据,稀疏视图网格提取 |
集成MVS与3DGS的方法
| 方法 | 核心机制 | 特点描述 |
|---|---|---|
| pixelSplat 15 | 3D空间概率分布 + 可微采样 | 学习预测高斯均值分布 |
| MVSplat 17 | 平面扫描代价体积 + 特征相似性 | 轻量级高精度重建 |
| MVSGaussian 132 | MVS点云 + 3D高斯优化融合 | 结合MVS精度与3DGS效率 |
| TranSplat 135 | 深度置信图 + 单目深度先验 | 解决有限视图重叠和不可靠匹配问题 |
混合架构方法
| 方法 | 核心机制 | 特点描述 |
|---|---|---|
| H3R 133 | 紧凑潜在体积 + 普吕克坐标条件注意力 | 强制3D一致性,细化弱纹理区域对应 |
| MuGS 136 | 投影-采样深度一致性 + 概率体积正则化 | 统一MVS体积证据与单目深度线索 |
4.2.2 Post Refinement
一系列后处理细化工作专注于改进高斯生成,以更好地捕捉复杂几何。高斯后处理细化方法的核心目标是:在单次前馈预测的基础上,进一步优化生成的高斯表示,以更好地捕捉复杂几何细节。现有方法主要体现为以下几种策略:
分层/渐进式细化:HiSplat 和 FreeSplat 采用从粗到精的策略。HiSplat 分层生成粗略和精细高斯,并用误差感知模块引导;FreeSplat 通过像素级对齐逐步聚合更新局部和全局高斯。这类方法先保证整体结构,再细化局部细节。
自适应分布调整:PixelGaussian 根据局部几何复杂度动态调整高斯的数量和分布,在几何复杂区域分配更多高斯,简单区域减少高斯,实现效率与质量的平衡。
结构化关系建模:GGN 构建高斯图来建模不同视角下高斯组之间的关系,通过池化层聚合,实现更高效的表示。
前馈稠密化学习:GD 直接从大规模数据集中学习先验,在前馈框架中单次前向生成精细高斯,无需逐场景优化,在稀疏视图下仍具有强泛化能力。
前馈-优化混合范式:G3R 作为纯前馈与经典优化的折中,先用网络快速预测初步表示,再通过可微分渲染器的梯度反馈进行迭代细化,结合了前馈的效率和优化的精度。
总体趋势是:从单次前馈预测 向可迭代细化、自适应分配、结构化建模 的方向演进;同时,利用大规模数据先验 (GD)和结合梯度优化反馈(G3R)成为提升复杂几何捕捉能力的重要补充手段。
| 方法 | 核心机制 | 特点描述 |
|---|---|---|
| HiSplat 137 | 分层生成(粗略高斯 → 精细高斯)+ 误差感知模块 | 先重建大尺度结构,再细化细节 |
| FreeSplat 138 | 像素级对齐 + 局部与全局高斯三元组逐步聚合更新 | 渐进式聚合与更新 |
| PixelGaussian 139 | 动态框架,根据局部几何复杂度自适应调整高斯分布与数量 | 按需分配高斯,提高效率 |
| GGN 141 | 高斯图建模组间关系 + 高斯池化层聚合 | 高效表示不同视角的高斯组 |
| GD 142 | 前馈框架学习稠密化输出,单次前向生成精细高斯 | 利用大规模数据集先验,无需逐场景优化,泛化能力强 |
| G3R 140 | 前馈预测 + 可微分渲染器梯度反馈迭代细化 | 纯前馈与优化方法的折中,结合两者优势 |
4.2.3 Pose-Free Reconstruction
无位姿重建是前馈式3D重建迈向实用化的关键一步,核心挑战在于同时推断几何结构和相机参数。现有方法主要沿以下几条路线发展:
奠基性工作(辐射场/点图):LEAP 最早探索了完全抛弃位姿的思路;DUSt3R 将成对重建统一为点图回归,成为该领域的基石;Pow3R 增加了条件机制以利用可用的辅助信息;π3 则通过置换等变架构提升了鲁棒性和可扩展性。
3DGS社区的无位姿重建:
- 直接适配:Splatt3R 直接沿用 MASt3R 的几何框架。
- 规避位姿估计:NoPoSplat 巧妙地在单规范视图局部坐标系中预测所有高斯,完全绕过位姿估计。
- 先验辅助:PF3plat、UFV-Splatter 利用预训练模型(单目深度、对应模型)提供先验。
- 级联学习:FLARE 先估计位姿再学习几何。
- 配准式:RegGS 先局部重建再全局配准。
端到端联合预测:AnySplat、SPFSplat/SPFSplatV2 在架构中集成了可微分位姿估计或直接联合预测位姿和高斯,实现零标注或无需位姿监督。
专用场景:PLANA3R 专注于室内公制重建,YoNoSplat 支持任意数量图像的灵活输入。
总体趋势是从依赖已知位姿 向无位姿、端到端、零标注 演进;从专门的点图/辐射场方法 向高效3DGS方法 迁移;从成对重建 向多视图、任意数量视图 扩展;同时,利用预训练先验 (深度、对应模型)和可微分位姿估计模块成为提升无位姿重建精度和鲁棒性的关键技术。
无位姿重建的奠基性工作(辐射场与点图)
| 方法 | 核心机制 | 特点描述 |
|---|---|---|
| LEAP 143 | 基于特征相似性聚合到共享神经体积 | 完全抛弃显式相机位姿,直接从数据学习几何 |
| DUSt3R 3 | 成对重建 → 稠密点图回归 | 统一方法,学习强几何先验,无需已知相机参数 |
| Pow3R 147 | DUSt3R + 轻量级条件机制 | 可融入内参、相对位姿等辅助信息提高精度 |
| π3 153 | 完全置换等变架构 | 预测仿射不变位姿和尺度不变点图,对输入顺序鲁棒且高度可扩展 |
无位姿重建的3DGS方法
| 方法 | 核心机制 | 特点描述 |
|---|---|---|
| Splatt3R 144 | 适配MASt3R几何框架 | 从无标定图像对直接预测高斯泼溅属性 |
| NoPoSplat 145 | 在单规范视图局部坐标系中预测所有高斯 | 巧妙规避位姿估计和全局对齐 |
| PF3plat 146 | 预训练单目深度+对应模型 → 粗略对齐 → 轻量级细化 | 适用于更复杂场景 |
| FreeSplatter 148 | 精简Transformer直接解码 | 将多视图token解码为统一参考系中的3D高斯 |
| FLARE 149 | 级联学习:先估计位姿,再学习全局几何结构 | 用估计的位姿初始化高斯中心 |
| RegGS 150 | 基于配准的框架 + 高斯混合模型新度量 | 将局部高斯对齐为全局一致场景 |
| UFV-Splatter 154 | 自适应框架 + 几何先验迁移 | 使预训练模型能处理不利视角 |
| AnySplat 152 | 几何Transformer + 可微分位姿估计模块 | 零标注流程,端到端训练,质量媲美依赖位姿的方法 |
| SPFSplat 151 | 联合预测相机外参和高斯基元 + 重投影损失 + 渲染损失 | 单前馈网络,无需位姿监督 |
| SPFSplatV2 228 | 掩码注意力 + 可学习位姿token | 改进相机位姿估计精度和整体效率 |
| PLANA3R 82 | 平面3D基元 | 室内场景公制3D重建,无需显式平面监督 |
| YoNoSplat 155 | 单前馈模型 | 从任意数量(已位姿或未位姿)图像重建高质量3DGS |
4.2.4 Pre-trained Geometric Guidance
提升重建保真度的一个有前景的策略是直接注入从强大的预训练模型中导出的几何线索。现代单目估计器在预测深度、法线和光流方面已经取得了显著的鲁棒性。集成这些现成的先验知识,可以使模型绕过几何学习中困难的冷启动问题。现有方法主要分为以下几类:
深度先验的直接集成:DepthSplat 建立了多视图深度估计与3DGS之间的协同关系,甚至用3DGS作为深度模型的无监督训练目标。PM-Loss 则通过点图正则化损失提升深度先验的质量(边界平滑性)。Flash3D 将单目深度模型扩展为完整的3D重建器,实现单图像3D重建。
基础模型权重的迁移初始化:AnySplat 使用 VGGT 的权重初始化几何Transformer,利用大规模预训练带来的强几何表示能力。
蒸馏精细几何细节:Fin3R 通过轻量级 LoRA 适配器,从强大的单目教师模型中蒸馏出精细几何细节来丰富编码器。
多模态几何线索融合:Niagara 同时集成单目深度和法线估计,JointSplat 融合光流和深度信息进行概率联合优化,以捕捉更精细的几何结构。
总体趋势是从仅依赖输入图像特征 转向主动注入外部预训练几何先验 ;从单一先验(如深度) 扩展到多模态先验(深度+法线+光流) ;从将先验作为额外输入 演进到用先验进行网络初始化、蒸馏、或作为正则化损失。这种策略显著提升了前馈方法在单视图、稀疏视图以及遮挡区域的几何重建质量。
| 方法 | 所用先验 | 核心机制 | 特点描述 |
|---|---|---|---|
| DepthSplat 18 | 预训练单目深度特征 | 多视图深度估计与3DGS协同,可微3DGS作为深度模型的无监督训练目标 | 建立深度估计与3DGS的强协同联系 |
| PM-Loss 28 | 前馈点图模型 | 基于点图的正则化损失,强制物体边界几何平滑性 | 产生更干净深度先验,减少3DGS伪影 |
| AnySplat 152 | VGGT 19 权重 | 用VGGT初始化几何Transformer | 获得更好的几何表示 |
| Fin3R 158 | 单目教师模型 159 | LoRA适配器蒸馏精细几何细节 | 丰富编码器的几何细节 |
| Flash3D 156 | 预训练单目深度估计 229--232 | 扩展单目深度模型为完整3D重建器:先预测初始高斯层,再添加后续层 | 单图像3D重建,处理遮挡 |
| Niagara 157 | 单目深度 + 法线估计 | 几何仿射场 + 3D自注意力 | 增强单视图重建,捕捉更精细几何细节 |
| JointSplat 160 | 像素级光流 + 深度信息 | 概率联合优化 | 融合光流与深度信息改进前馈3DGS |