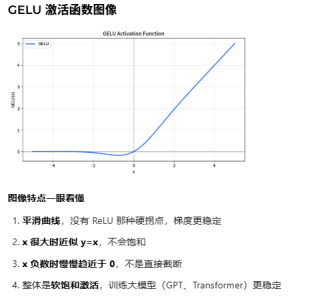
1 GPT整体框架
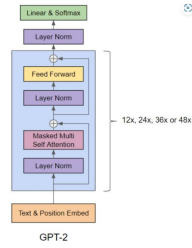 标题GPT整体架构
标题GPT整体架构
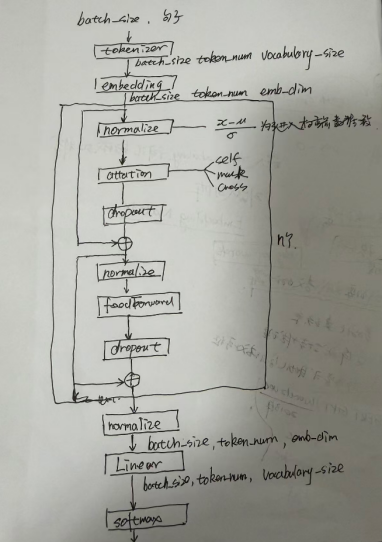 标题GPT框架细节
标题GPT框架细节
2 重要概念
batch_size、
token_num(实际token的数量,当前输入的句子通过分割后所有的token的数量)、vocabulary_size(字典维度)、
embed_dim(嵌入向量的维度)、
head_num(多头注意力的个数)、
head_dim(每个头的维度)、
context_length(最大上下文长度)
2.1 Tokenizer
Token,现在都是通过统计
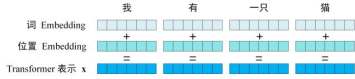
例如,我有一只猫;首先要拆开一个一个的词,我|有|一只|猫,形成四个token向量;
2.2 Embedding
之前的做法都是先用 word2vec、GloVe 等独立算法在大语料上预训练出词向量,再把这些固定向量丢给下游模型(RNN、CNN、简单 Transformer)使用。
但是,现在的模型都是吧Embedding层,作为模型的第一层,Embedding 权重是模型参数的一部分 , 训练时,嵌入层和所有 transformer 层一起反向传播、一起更新 。
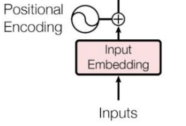
具体的过程如下图所示:Transformer 中单词的输入表示 x由单词 Embedding 和位置 Embedding (Positional Encoding)相加得到。
|----------------------------------------------------------------------------|
|  |
|
|  |
|
2.3 位置嵌入Positional Embedding
单词的 Embedding 有很多种方式可以获取,一般都是 Word2Vec、Glove 等算法预训练得到。
Transformer 中除了单词的 Embedding,还需要使用位置 Embedding 表示单词出现在句子中的位置。在传统的 RNN 的结构,来顺序操作来预测文字。为了并行计算,Transformer结构中,将输入词之间的相对位置关系,通过编码来表示出来。 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。
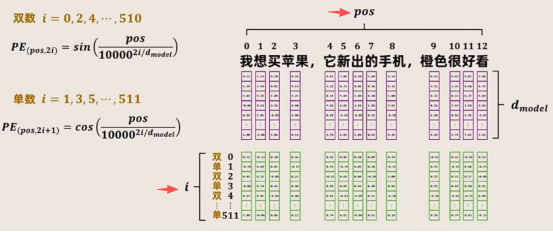
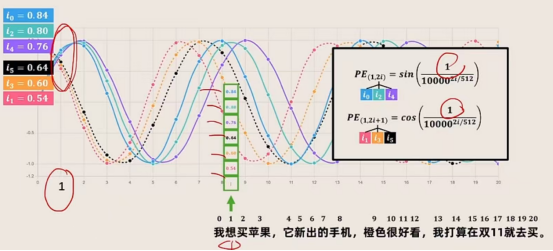
位置 Embedding 用PE表示,PE的维度与单词 Embedding 是一样的。PE 可以通过公式计算得到,计算公式如下:
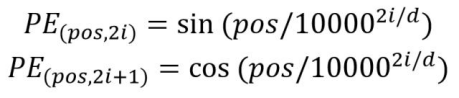
假如,输入表示为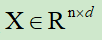 ,用来表示一个n个词元的d维嵌入向量表示,同样,位置编码的形状也需要同样的大小
,用来表示一个n个词元的d维嵌入向量表示,同样,位置编码的形状也需要同样的大小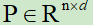 ,最终,得到Transformer的输入X+P的向量。
,最终,得到Transformer的输入X+P的向量。
这里的i表示emb_dim嵌入维度中的序号,pos是表示在token_num中的序号,整体计算如下图所示:
2.4 线性单元
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
|  |
|  |
|
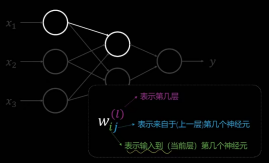
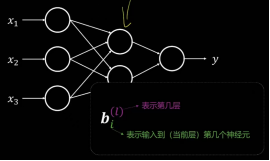
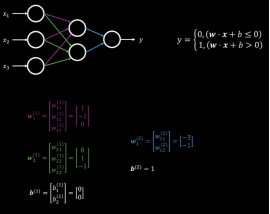 标题线性传导单元Wx+b
标题线性传导单元Wx+b
nn.Linear(d_in, d_out, bias=qkv_bias)。例如上图,<<线性传导单元Wx+b>>。实际上是一个矩阵相乘的.
2.5 Normal节点
nn.LayerNorm(patch_dim)。这个过程就是将输入数据的平均值和分布规范化到一个合理的范围内
公式如下:
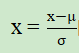
2.6 Attantion注意力的算法模块
Q是查询矩阵,表示对事物的偏好。
K 是键值矩阵,表示事物本身的特征。
QK点积后,表达的是注意力概念,QK输出参量,那么就是自注意力。这里解释下,点积,表示两个向量的相关度,也是一个向量在另外一个向量上的投影,投影就是表示两个向量的相关度。
V表示值,表示事物内容的表达,只不过是使用向量来进行表达。
下面看代码,先看如何生成Q矩阵,实际上就是将x张量,通过Wq和x进行矩阵相乘,这里实际从embed_dim转为了head_dim的空间。同理,K矩阵和V矩阵都是同样的方法来生成。
self.W_query = nn.Linear(embed_dim, head_dim, bias=qkv_bias)
self.W_key = nn.Linear(embed_dim, head_dim, bias=qkv_bias)
self.W_value = nn.Linear(embed_dim, head_dim, bias=qkv_bias)
self.register_buffer("mask", torch.triu(torch.ones(context_length, context_length), diagonal=1))
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# shape 变为:[b, heads, num_tokens, head_dim]
queries = queries.view(b, token_num, self.head_num, self.head_dim).transpose(1, 2)
keys = keys.view(b, token_num, self.head_num, self.head_dim).transpose(1, 2)
values = values.view(b, token_num, self.head_num, self.head_dim).transpose(1, 2)
attn_scores = queries @ keys.transpose(2, 3) # Changed transpose
if self.mask is not None:
attn_scores.masked_fill_(self.mask.bool()[:token_num, :token_num], -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
context_vec = (attn_weights @ values).transpose(1, 2)
context_vec = context_vec.contiguous().view(b, token_num, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec2.7 FeedForward模块
nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),) 将维度放大后,进行激活,然后再将维度缩小到初始大小。