目录
[全连接神经网络 - 最基础的(人工)神经网络](#全连接神经网络 - 最基础的(人工)神经网络)
[2.网络层的 输入维度 和 输出维度](#2.网络层的 输入维度 和 输出维度)
[3.GELU (大模型)](#3.GELU (大模型))
[1. 均匀分布初始化](#1. 均匀分布初始化)
[2. 正态分布初始化](#2. 正态分布初始化)
[3.全0 初始化](#3.全0 初始化)
[4.全1 初始化](#4.全1 初始化)
[5.固定值 初始化](#5.固定值 初始化)
[6. kaiming 初始化,也叫做 HE 初始化 偏置是全0](#6. kaiming 初始化,也叫做 HE 初始化 偏置是全0)
[7. Xavier 初始化,也叫做 Glorot 初始化](#7. Xavier 初始化,也叫做 Glorot 初始化)
一、神经网络介绍
是什么:参考生物神经元的计算模型,计算逻辑包括 加权求和+激活函数
生物神经网络,由多个生物神经元连接组成
1.树突:接收输入信号,进行加权求和
2.细胞核:对加权求和的信号进行非线性处理
3.轴突:输出细胞核处理之后的信号

人工神经网络,由多个人工神经元链接组成
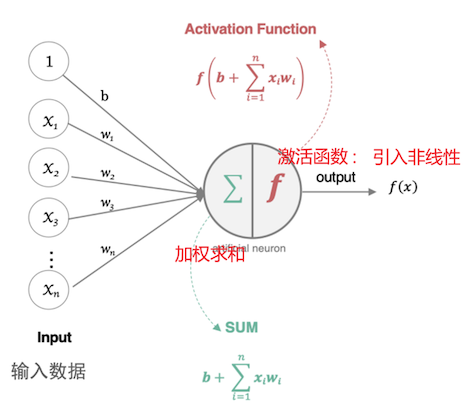
计算模型为:
1.加权求和:对输入特征进行加权求和
2.激活函数:对加权求和结果进行非线性处理
全连接神经网络 - 最基础的(人工)神经网络
也简称为: MLP/ FCN/ DNN
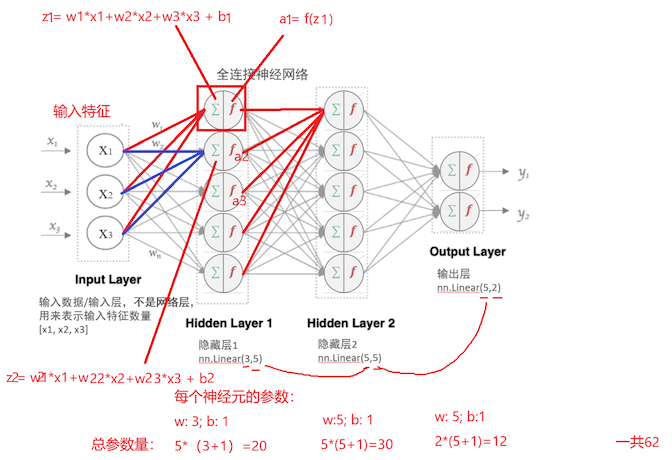
1.人工神经网络的组成:
输入层/ 数据 (Input layer) -> 隐藏层(Hidden layer) -> 输出层(Output layer); 最小单元是神经元
多个神经元 -> 网络层 -> 神经网络
2.网络层 的 输入维度 和 输出维度
nn.Linear(input_dim, output_dim)
输入维度:当前层的输入特征数量
输出维度:当前层的输出特征数量/神经元数量
如:上图示例****的输入/输出维度
Hidden layer 1 -> nn.Linear**(3,5)**左边输入 3个特征,获得5个输出
Hidden layer 2 -> nn.Linear**(5,5)**左边输入 3个特征,获得5个输出
Output layer -> nn.Linear**(5,2)**左边输入 5个特征,获得2个输出
3.网络层参数量的计算方式
参数量 = (权重参数量 + 偏置参数量)* 输出维度
权重参数量**:输入维度 * 输出维度**
偏置参数量**:1* 输出维度**
比如: (3,4) = 3 * 4 + 1 * 3 = (3+1) * 4 = 16
(输入维度+1) * 输出维度 = (input_dim + 1)* output_dim
这里的1: 表示 B 偏置
如:上图示例
Hidden layer 1 ->nn.Linear**(3,5)-> 参数数量 =( 3 + 1)* 5 = 20**
Hidden layer 2 ->nn.Linear**(5,5)** -> 参数数量 =( 5 + 1)* 5 = 30
Output layer -> nn.Linear**(5,2) ->参数数量= (5 + 1) * 2 =12**
++总参数量 = 20 + 30 + 12 = 62个++
4.网络中数据的前向传播方向:
++由前向后传,输入层 -> 隐藏层 -> 输出层,不能反向传数据++
二、激活函数
是什么:非线性函数
作用:引入非线性
1.没有引入非线性因素的网络等价于一个线性模型
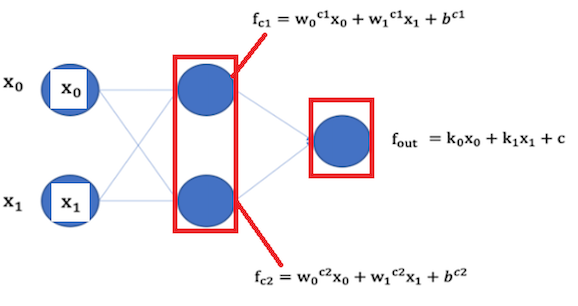
2.根据通用逼近定理,给网络增加激活函数,引入非线性,使得网络可以逼近任意函数,提升网络对复杂问题的拟合能力
常见激活函数
| 激活函数 | 输出范围 | 是否梯度消失 | 速度 | 是否解决死亡 ReLU | 适用位置 |
|---|---|---|---|---|---|
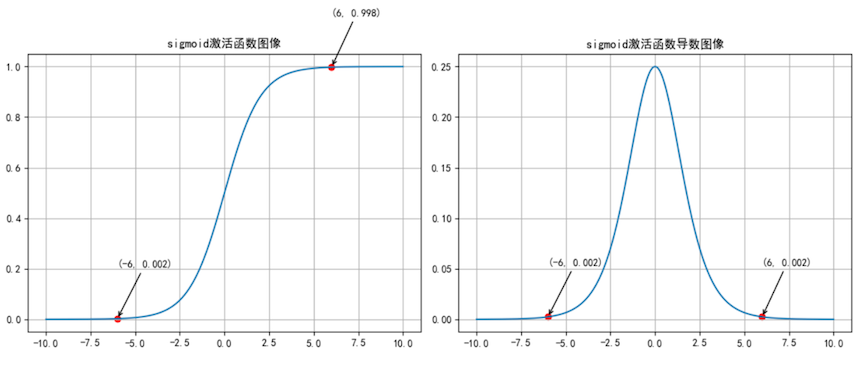
| Sigmoid | (0,1) | 严重饱和 | 慢 | × | 二分类输出层 |
| Tanh | (-1,1) | 饱和 | 慢 | × | 传统 RNN |
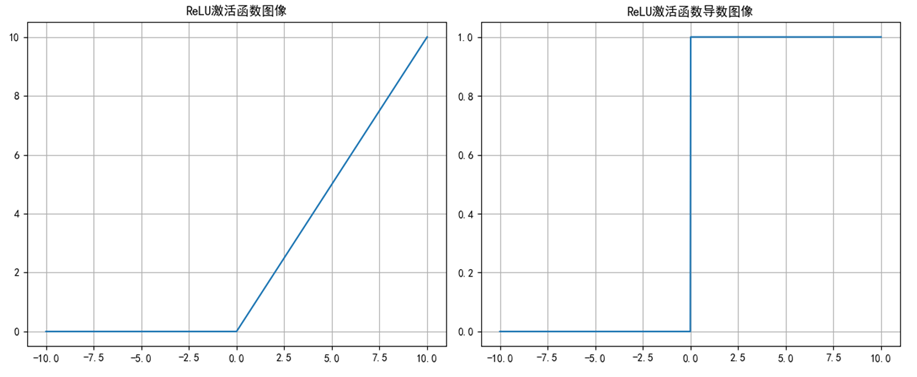
| ReLU | [0,+∞) | 不饱和 | 极快 | ×(会死亡) | CNN / 全连接隐藏层(主流) |
| Leaky ReLU | (-∞,+∞) | 不饱和 | 快 | ✅ | 改进 ReLU |
| GELU | (-∞,+∞) | 不饱和 | 中等 | ✅ | Transformer / 大模型 |
| Softmax | (0,1) 和为 1 | - | 中等 | - | 多分类输出层 |
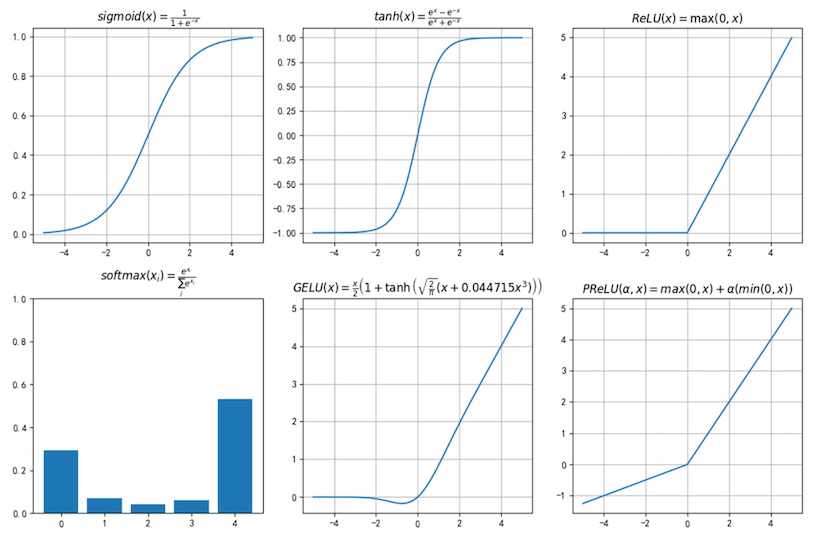
1.Sigmoid
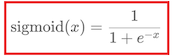
2.ReLU
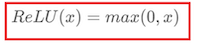
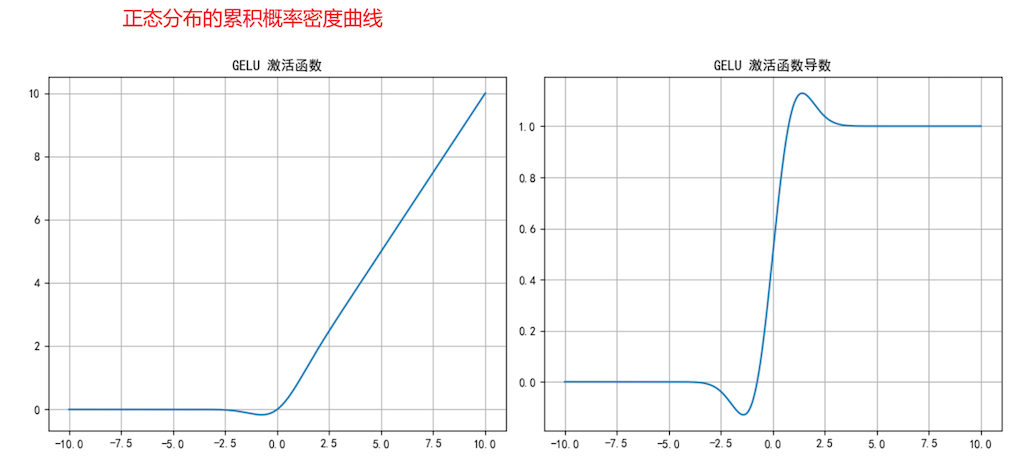
3.GELU (大模型)
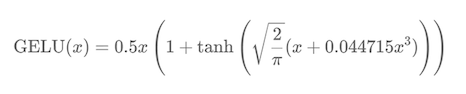
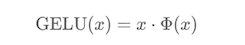
4.Softmax
输出和为1的概率分布,用于多分类问题的输出层
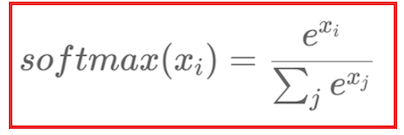
Xi. 的 i 通常为 -1 ,也就是特征轴
运算 y = torch.softmax (x, dim = -1) 或 y = F.softmax(x, dim = -1)
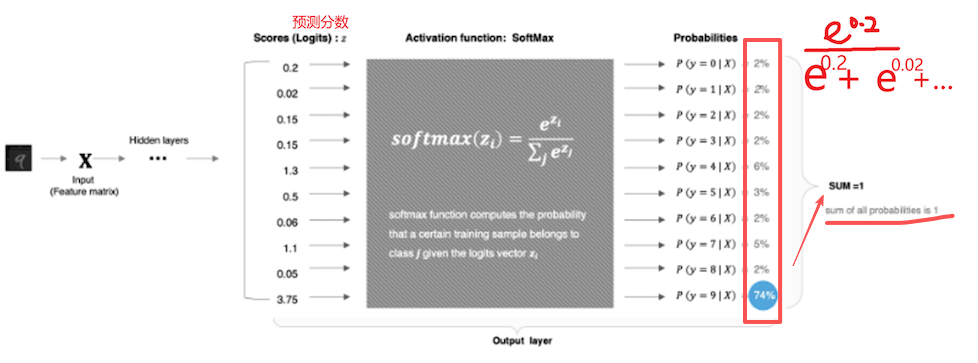
一次 计算后 -> 下图1 概率分布图 概率最大的那个类别也就是模型预测类别
二次 计算后 -> 下图2 不改变数据之间大小关系,多次计算后会均匀分布。精度溢出。
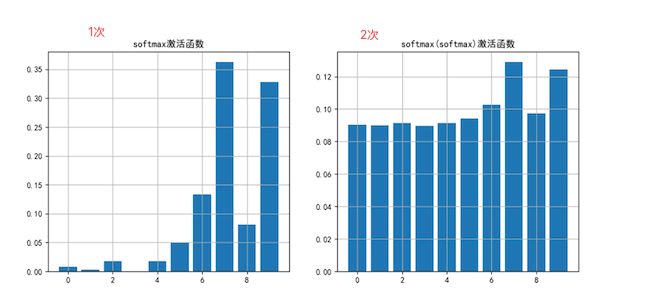
总结:
激活函数的选择方法
隐藏层: 优先级
Relu ------> Leaky Relu / PReLu / GELU ------> (Tanh)
输出层:
多分类问题选择 softmax
二分类问题选择 sigmoid 或 softmax
回归问题多数选择 identity (就是没有激活函数),正数ReLu,区间Sigmoid / Tanh
SoftMax 和 Sigmoid 用于二分类的区别:
1.softmax 输出两个概率,对应负类和正类
2.sigmoid 输出一个概率,对应正类概率,负类概率 = 1 - 正类概率
三、参数初始化
是什么?? 创建神经网络时,初始化网络层的参数
作用: 1. 防止 梯度消失 或 梯度爆炸
-
提高收敛速度
-
打破对称性:
如果所有神经元的参数都一样,则输出数据经过前向传播,再反向传播时,得到的梯度相同。
W新 = W旧 - 学习率 lr * 梯度 grad,结果都一样。模型就无法训练网络
++注意: 通常采用pytorch默认参数初始化方式,特殊情况下,才需要手动设置++
w 和 b 初始化
初始化的方法:
1. 均匀分布初始化
python
# 1.定义一个线性层,输入维度3,输出维度5
linear = nn.Linear(3,5)
# 2.对权重w进行初始化
nn.init.uniform_(linear.weight)
# 3.对偏置b进行初始化
nn.init.uniform_(linear.bias)
# 4.打印权重和偏置
print(f"w:{linear.weight}, shape: {linear.weight.shape}")
print(f"b:{linear.bias}, shape: {linear.bias.shape}")2. 正态分布初始化
python
# 1.定义一个线性层,输入维度3,输出维度5
linear = nn.Linear(3,5)
# 2.对权重w进行初始化
nn.init.normal_(linear.weight)
# 3.对偏置b进行初始化
nn.init.normal_(linear.bias)3.全0 初始化
python
nn.init.zeros_(linear.bias)4.全1 初始化
5.固定值 初始化
python
nn.init.constant_(linear.bias,val=0.5)6. kaiming 初始化,也叫做 HE 初始化 偏置是全0
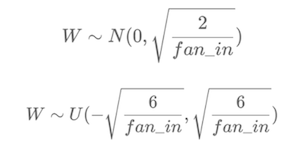

python
nn.init.kaiming_normal_(linear.weight)7. Xavier 初始化,也叫做 Glorot 初始化
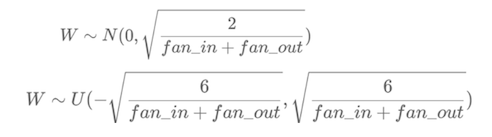
python
nn.init.xavier_normal_(linear.weight)极少数场景,需要手动参数初始化:
权重W:
relu网络: kaiming
非relu网络:xavier
偏置: 全0: (简单,计算快)