目录
[1 VGG](#1 VGG)
[(1) VGG块](#(1) VGG块)
[(2) VGG架构](#(2) VGG架构)
[(3) 优缺点分析](#(3) 优缺点分析)
[2 代码实现](#2 代码实现)
[(1) Vgg块](#(1) Vgg块)
[(2) Vgg网络(Vgg-11为例)](#(2) Vgg网络(Vgg-11为例))
[(3) 训练](#(3) 训练)
前言
我们知道由LeNet→AlexNet,其发展方向为用更大、更深的网络以更有效地提取高层特征,并让深让层网络变得可训练。
LeNet解决手写数字(MNIST)识别问题,将"人工特征提取"转变为"自动特征学习"。
首次引入"卷积"概念,模仿生物视觉,认为像素局部相关,没必要全连接,通过使用卷积核"权值共享"的理念大大减少了参数两,让模型在当时有限的算力下变得可能;同时通过池化"下采样"引入平移、缩放和变形的不变性。
但受限于算力和数据集规模,模型很浅(2层卷积),激活函数使用sigmoid或tanh,极易发生梯度消失。
AlextNet则在 ImageNet 这种大规模、高分辨率的数据集上证明了深度学习的统治力。
它从LeNet的5层增加到8层,引入ReLU激活函数(这是分水岭,ReLU让深层网络的收敛速度更快)、Dropout及数据增强(深层网络参数多,必须通过正则化来防止死记硬背);另外,AlexNet使用11×11和5×5的大卷积核来不辍较大的空间上下文,并利用双GPU分块计算解决算力瓶颈。
其设计逻辑在于:既然浅层不够,那就加深,并用ReLU和Dropout保证"能跑通"且"不跑偏"。
那我们今天的主角------VGG的逻辑如何呢?
1 VGG
VGG认为,能不能用更深更大的网络?但怎么加深呢?加深全连接层是一件很贵的的事情,加深卷积层的话,怎么加?------ 将卷积层组成块,以块为单位继续叠加。
如果说,AlexNet打开了深度学习的大门,那么VGG则是给这个大门装上了工业化的流水线。它的核心思想极度纯粹:把卷积和缩小,把层数堆深。

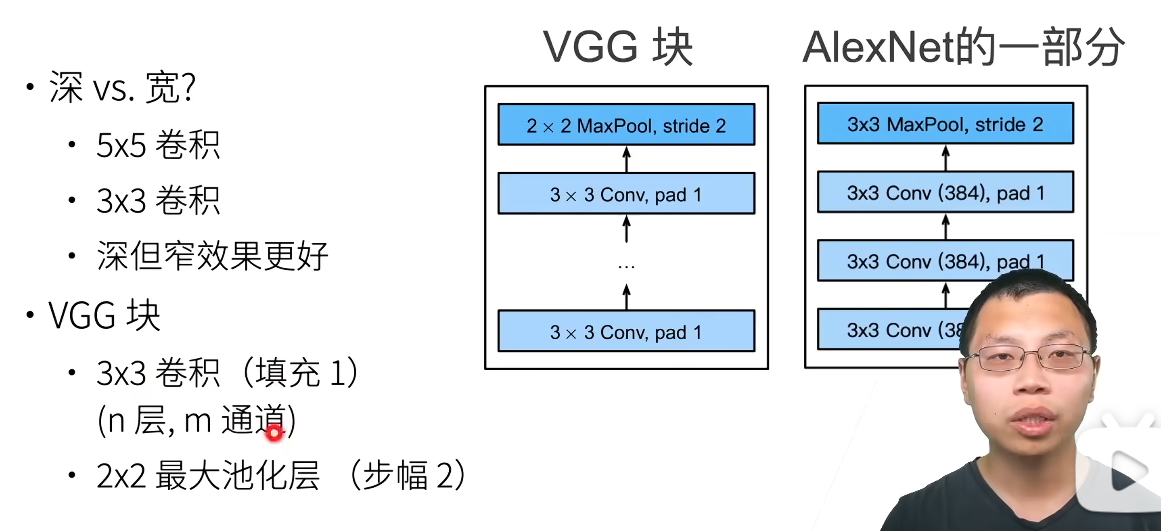
(1) VGG块
研究者发现,使用深而窄的3×3卷积核比浅而宽的卷积核效果更好。更深的卷积层意味着更多的非线性(++可以使用更多次的激活函数(ReLU)++,这让网络能够学习更为复杂的特征)。
VGG将池化层的卷积核换成了2×2的大小,另外卷积核设定为*(3×3 COnv,pad 1,stride 2)*固定设置,将层数和通道数作为超参数调整。
更少的参数量-好处:假设通道数为C,三个 3×3 的参数量是:,而一个 7×7 是
。VGG用更少的参数实现了更深的特征提取。
在深度学习中,一个标准的卷积层参数量公式为:
(注:这里暂不考虑偏置项 Bias,因为在大型网络中它占比较小)
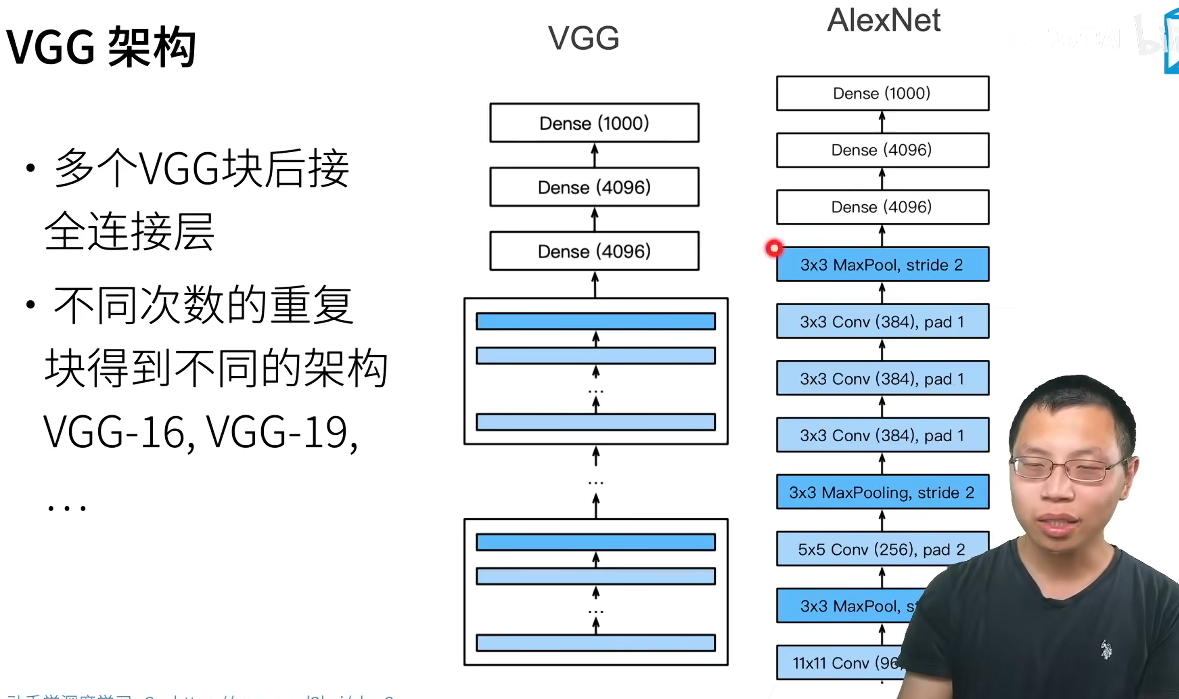
(2) VGG架构
VGG的结构非常规整,像搭积木一样,可以分为5各阶段(Blocks):
++(以VGG-16为例)++
① Block 1-2:浅层特征提取,每层卷积后紧跟池化(MaxPool)。
② Block 3-5:深层特征提取,卷积层数量增加,通道数逐渐从64增加到128、256......
③ 全连接层(FC):同AlexNet(4096→4096→1000).
规律总结:每经过一个池化层空间分辨率(长宽)减半,但通道数翻倍。这种"高而瘦"的结构设计成为了后来无数神经网络的模板。
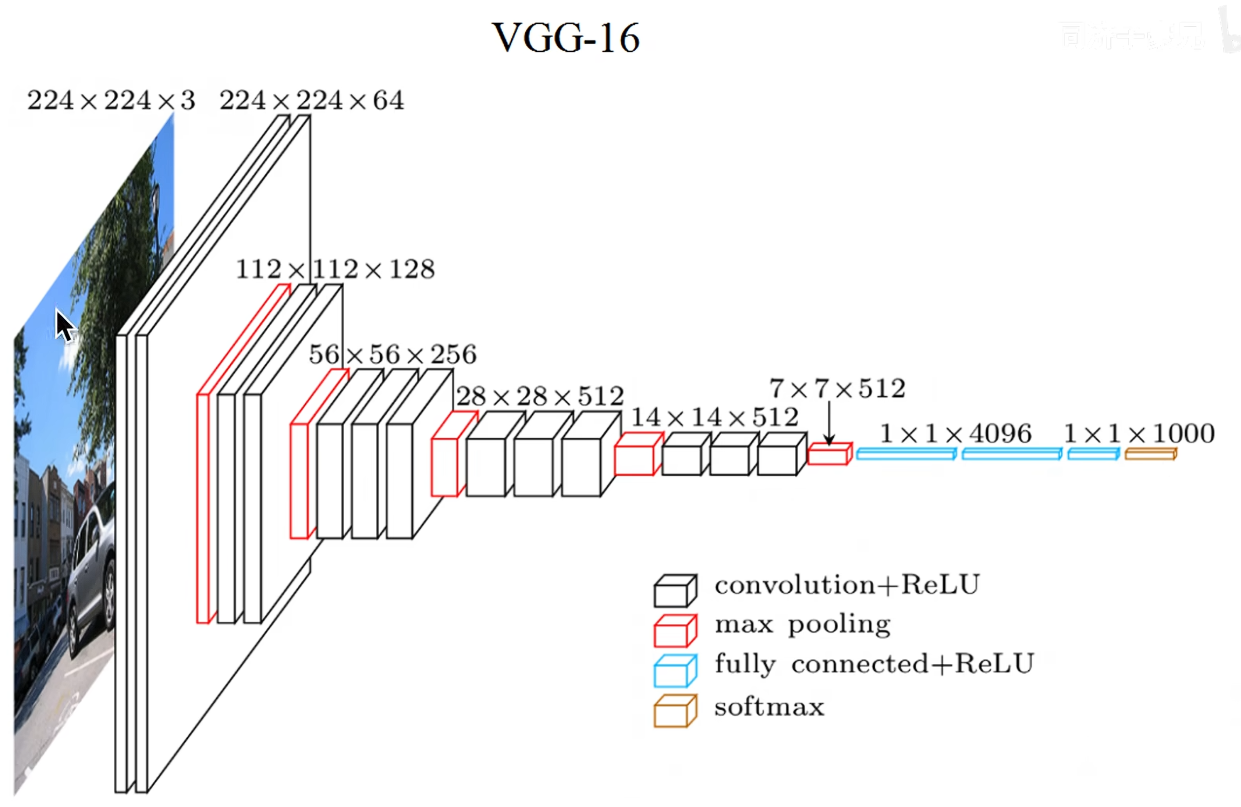
下面是Vgg-16的架构图:
(3) 优缺点分析
优点:
- 极简主义:结构同意,代码实现简单(基本就是循环堆叠)
- **迁移学习灵活性强:**即便在今天,VGG-16和VGG-19的特征提取能力依然非常稳健,常被用作计算机视觉任务(如感知损失LPIPS、风格迁移、目标检测)的Backbone(骨干网络)。
缺点:
- *参数量巨大:虽然卷积层参数少了,但是在进入FC之前,已经通过更深的网络提取了维度更高的特征,导致的一个全连接层的权重变得巨大。*(这也是为什么后来的ResNet取消了中间的4096全连接层,改用全局平均池化(Global Average Pooling)),直接把参数量从上亿级别降到了千万级别)。
- **计算资源消耗大:**由于特征图在浅层非常大,卷积计算非常耗时。
- **梯度消失隐患:**虽然VGG证明了深度(16-19层)的有效性,但当它想继续往50层、100层突破时候,遇到了严重的梯度消失问题,直到后来的ResNet出现才得以解决。
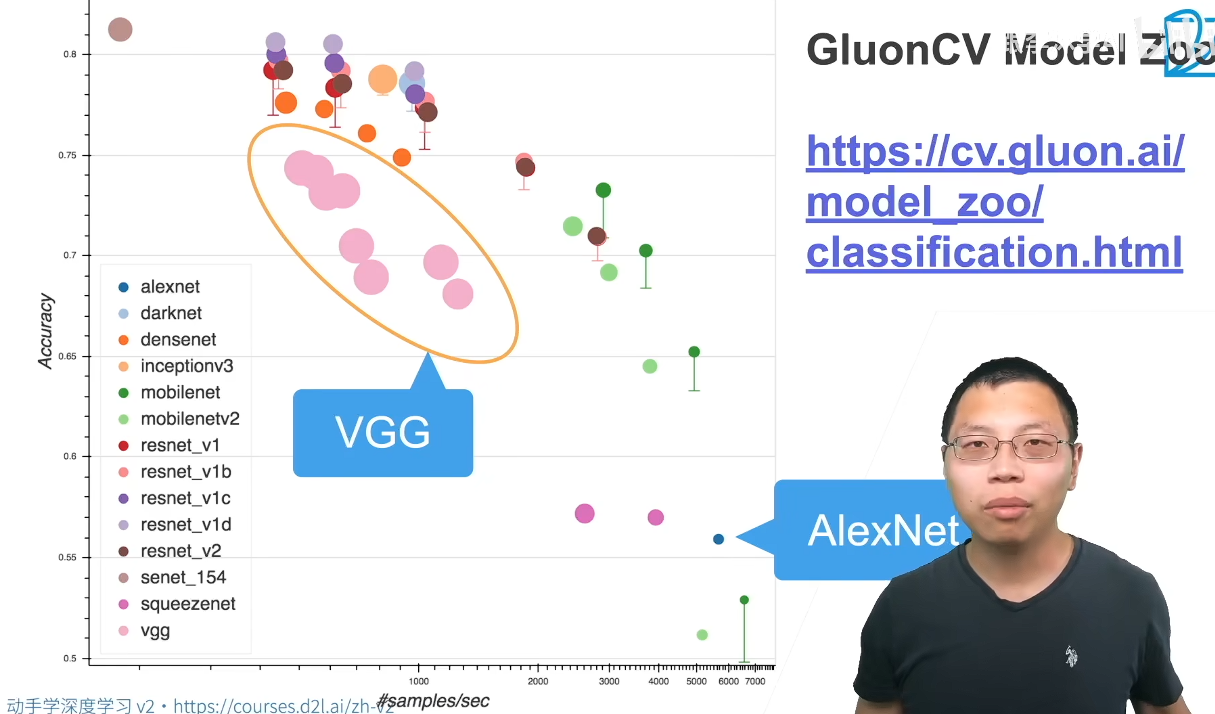
AlexNet 在计算效率上非常高,但是其准确率只在0.56左右,而VGG(不同的循环叠加发展为一系列变体)的准确率要高很多,但是计算效率变低,因为它更深了。下面的点越大表示占用内存越多,VGG是比较占用内存的网络。
2 代码实现
(1) Vgg块
python
import torch
from d2l import torch as d2l
from torch import nn
def VGGBlock(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers) # 构造成一个块(2) Vgg网络(Vgg-11为例)
python
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
def vgg(conv_arch):
conv_blks = []
in_channels = 1
for (num_convs, out_channels) in conv_arch:
conv_blks.append(VGGBlock(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(),
nn.Dropout(0.5), nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(0.5), nn.Linear(4096, 10))
net = vgg(conv_arch)观察每层输出的形状:
python
X = torch.randn(1, 1, 224, 224)
for blk in net:
X = blk(X)
print(blk.__class__.__name__,'output shape:\t' , X.shape)
(3) 训练
由于VGG-11比 AlexNet计算量更大,因此我们构建了一个通道数比较少的网络。
(所有通道数除以4)
python
ratio = 4
small_conv_arch = [ (pair[0], pair[1] // ratio) for pair in conv_arch ]
net = vgg(small_conv_arch)
python
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
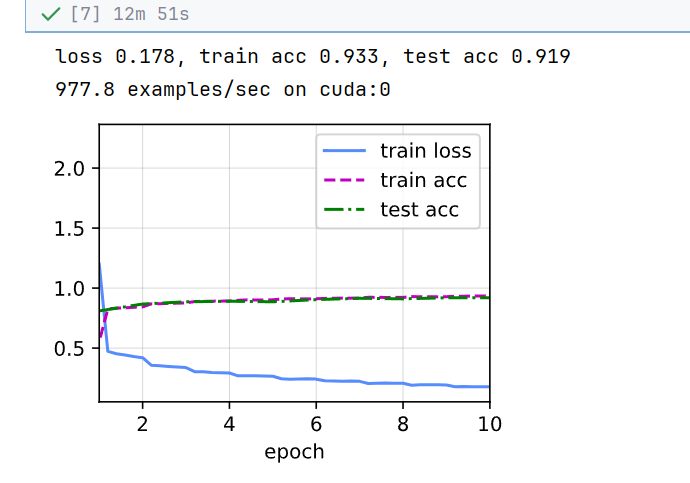
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())//输出:
总结
VGG使用可重复使用的卷积块来构建深度卷积神经网络,不同的卷积块个数和超参数可以得到不同复杂度的变种。
这种网络结构化和网络架构设计思想对之后的深度学习网络的发展有着重要影响。