NeRF是近年来神经网络发展的一大丰碑,几年前第一遍看这篇论文的时候几乎马上就爱上了这个研究(这个体验是很少的,大部分论文看一遍要么盲目地觉得我上我也行,要么直接不知道它想干嘛)。不过由于走学术弯路和工作重心不在这等等原因,一直也没仔细去看这一系列的工作。直到最近开始看可微渲染相关的内容,才觉得这块得好好补一补。于是从旧笔记堆里又把这篇原始论文翻出来开始研究。
这篇博客就是之前写的官方代码运行的记录,主要介绍如何在Windows以及Linux上快速运行起Nerf的代码(Pytorch版本,注意官方实现用的是Tensorflow,但这个Pytorch版本也被非常多人作为参考标准,如果要保证100%复现,可能得去看Tensorflow的版本),以及数据集的简单分析。
代码运行
Windows+Linux
大部分操作是一样的,因此没有分开写,差别的地方已经注明了。
源码拷贝
bash
git clone https://github.com/yenchenlin/nerf-pytorch.git
cd nerf-pytorch虚拟环境配置
注意,这份代码是六七年前开源的,之后没改过。
Ubuntu
bash
conda create -n nerf_pytorch python=3.9
conda activate nerf_pytorch
pip install -r requirements.txt一般上面那些就行,但因为年代久远的问题,可能会出现兼容性错误。比如我用的是RTX4090,用requiremnts里面的pytorch版本就会出问题。因此使用支持CUDA12.1的2.5.1。如果不想搞两遍也可以删掉requirements.txt的相关内容然后自己用最后一句话装一下就好,这样的话numpy也可以用2.0的版本。
bash
# 老显卡一般只需要这一步就行
# 降级 NumPy 到 1.x 版本。
pip install "numpy<2"
# 新显卡还需要这两步操作。
# 卸载当前 PyTorch
pip uninstall torch torchvision torchaudio
# 安装支持 CUDA 12.1 的 PyTorch(RTX 4090 需要)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121windows
bash
conda create -n nerf_pytorch python=3.9
conda activate nerf_pytorch
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
pip install imageio
pip install imageio-ffmpeg
pip install matplotlib
pip install configargparse
pip install tensorboard
pip install tqdm
pip install opencv-python运行示例
下载数据
安装git和wget(Linux下不需要这一步,如果没有git命令行安装一下即可)
Windows下运行下一步的sh文件需要git,没有的话需要先安装:
windows上没有wget命令,因此也需要配置上去,方法是:
1、下载wget二进制安装包,地址:https://eternallybored.org/misc/wget/
2、解压安装包,将wget.exe 拷贝到C:\xx\Git\mingw64\bin中(这里的地址和git的安装位置有关)
数据下载
在Windows下,需要在sh文件所在的位置后右键选择"Git Bash Here",然后在控制台上输入(Linux上直接终端cd到对应位置输入即可):
bash
bash download_example_data.sh下载完成的数据在data文件夹中。
训练神经网络
完成上述操作后只需运行如下命令即可进行训练:
bash
python run_nerf.py --config configs/lego.txt训练完后会在logs/lego_test/lego_test_spiral_100000_rgb.mp4路径下生成mp4文件,这也是imageio-ffmpeg这个库的作用。(整个过程需要的时间比较感人,RTX 4090:3h左右,A4000:9h左右)
如果希望保留控制台的训练过程,也可以使用下面的命令:
bash
python run_nerf.py --config configs/lego.txt 2>&1 | tee output.log数据集分析
下载下来的数据集里面有两个文件夹,分别是nerf_llff_data和nerf_synthetic。文件夹中分别只有一个场景,后者是由blender渲染生成的乐高积木推土机,也是论文出现频次最多的一个场景:
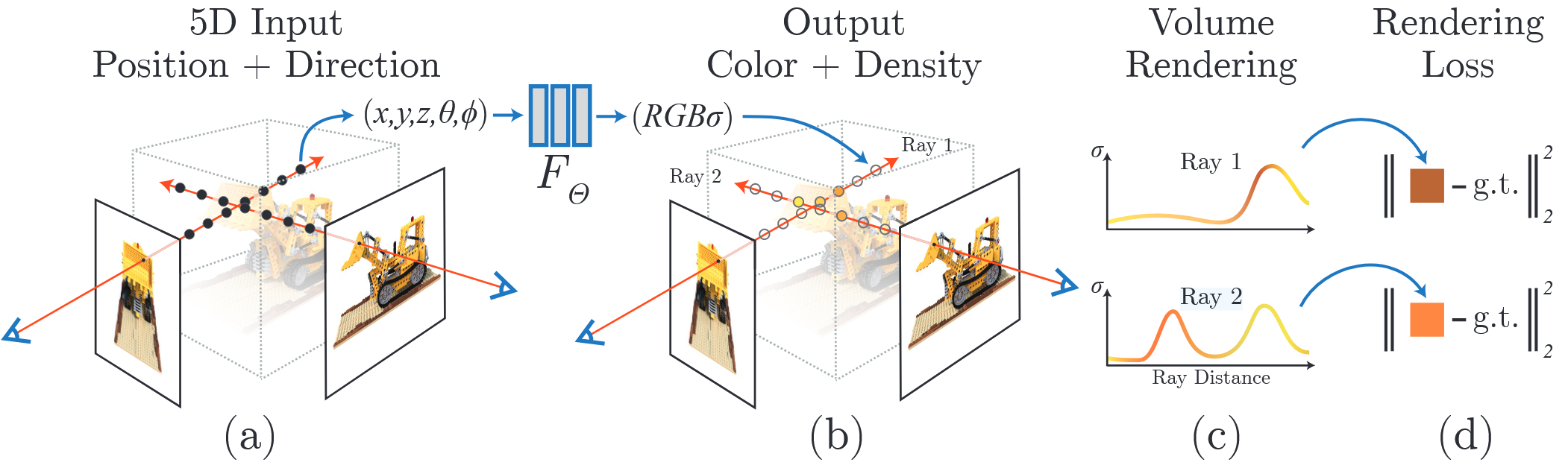
nerf一次只能训练一个场景的内容,因此看懂单个场景里面有什么也就知道nerf要求的数据的样子了。
单场景数据结构
单个场景的数据结构如下:
-
lego
- test
- 不同视角的深度图、渲染图
- train
- 不同视角的渲染图
- val
- 不同视角的渲染图
transforms_test.json
transforms_train.json
- 不同视角的渲染图
transforms_val.json
- test
每个json文件中分别存储相机的水平视场角以及多帧图像中的每一帧图像存放的路径和世界坐标系。虽然相机的内参没有直接在json文件中给出,但Nerf使用的是理想针孔相机模型,可通过水平视场角计算得到。
在run_nerf.py文件的images, poses, render_poses, hwf, i_split = load_blender_data(args.datadir, args.half_res, args.testskip)这个语句后面加入如下代码,可以将各个图像的拍摄相机视锥进行可视化:
python
# 可以在这里使用Open3D将各个相机可视化出来
# poses里面存放着相机的外参,hwf存放着图像的高宽和焦距
import open3d as o3d
# 遍历所有的相机位姿
camera_frames = []
for i in range(poses.shape[0]):
# Blender transform_matrix 是相机到世界(c2w, OpenGL: +X 右, +Y 上, -Z 朝前)
# Open3D 的 create_camera_visualization 期望 extrinsic 为世界到相机(w2c, OpenCV: +Z 朝前, +Y 向下)
# 因此需要先取逆得到 w2c_opengl,再做 OpenGL -> OpenCV 轴变换 (flip y,z)
w2c_opengl = np.linalg.inv(poses[i])
flip_yz = np.eye(4)
flip_yz[1, 1] = -1
flip_yz[2, 2] = -1
extrinsic = flip_yz @ w2c_opengl
# 构建相机内参
intrinsic = np.array([[hwf[2], 0, hwf[1]/2],
[0, hwf[2], hwf[0]/2],
[0, 0, 1]
])
cameraLines = o3d.geometry.LineSet.create_camera_visualization(
view_width_px=int(hwf[1]), view_height_px=int(hwf[0]),
intrinsic=intrinsic, extrinsic=extrinsic, scale=0.5)# 这里scale是相机图标的大小,设置为0.5视觉效果会比较好
if i in i_split[0]: # 训练集为蓝色
cameraLines.paint_uniform_color((0, 0, 1)) # Blue
elif i in i_split[1]: # 验证集为黄色
cameraLines.paint_uniform_color((1, 1, 0)) # Yellow
else: # 测试集为红色
cameraLines.paint_uniform_color((1, 0, 0)) # Red
camera_frames.append(cameraLines)
vizualizer = o3d.visualization.Visualizer()
vizualizer.create_window(window_name='Camera Pose', width=800, height=600)
for camera in camera_frames:
vizualizer.add_geometry(camera)
vizualizer.run()
vizualizer.destroy_window()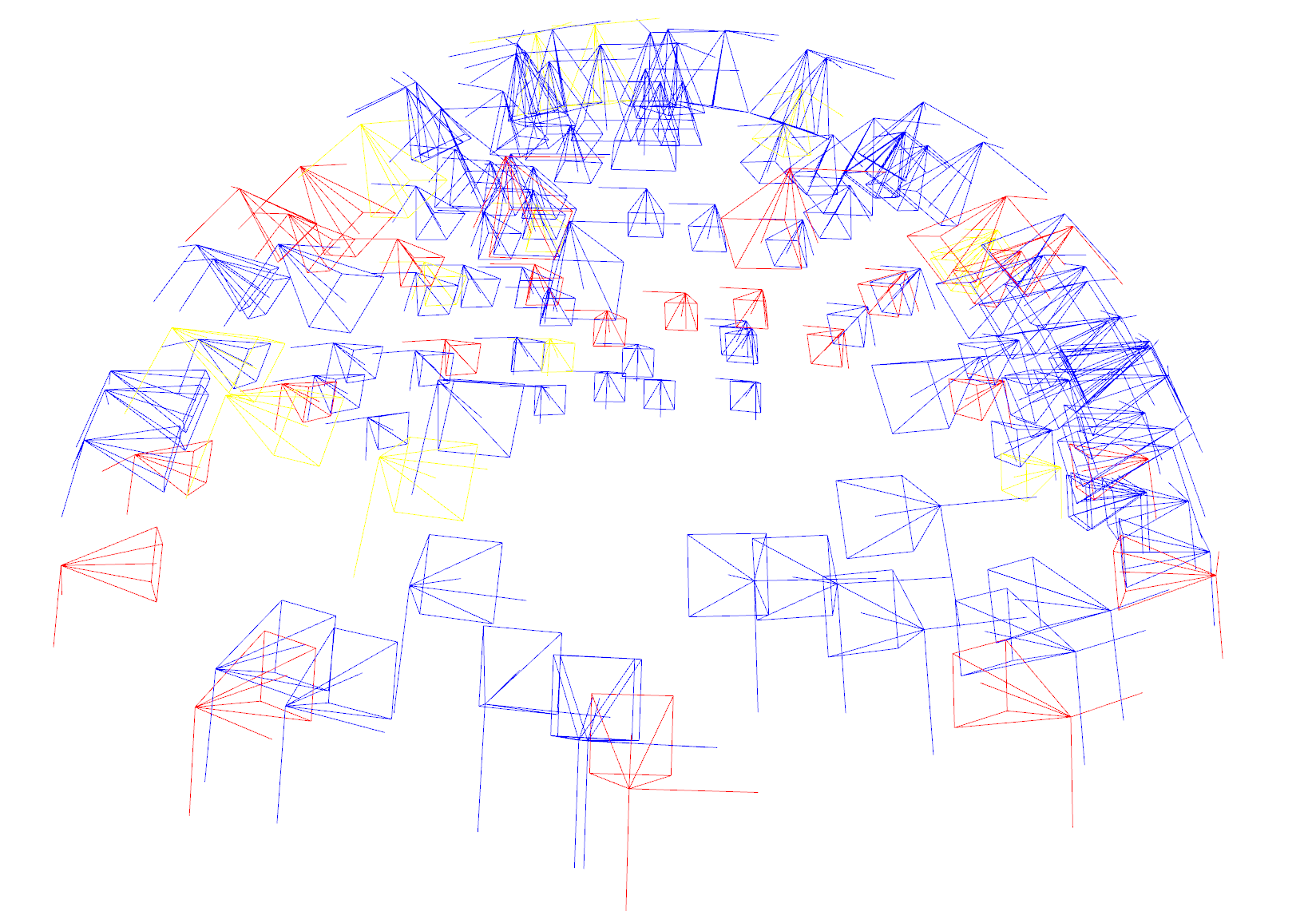 其中训练数据为蓝色,验证数据为黄色而测试数据为红色。
其中训练数据为蓝色,验证数据为黄色而测试数据为红色。