这篇文章将详细解析NeRF的原理,开始之前推荐下列的视频:
【较真系列】讲人话-NeRF全解(原理+代码+公式)_哔哩哔哩_bilibili
本篇博客大部分内容是参考这位博主的,建议初学者可先看一遍视频,后面有兴趣再看这篇博客。
另外,本篇博客会在介绍原理的过程中贴出pytorch版nerf的实现代码,以供参考。但有一句说一句,代码写的比较抽象,各种莫名奇怪的lambda 封装给搞懂这篇论文增加了很多工作量。。。如果实在忍受不了作者的实现,可以看看其他复现的代码。
总览
研究神经网络类的算法,一般的顺序是先看输入和输出是什么东西,然后看下损失函数怎么计算,最后看看网络结构中有什么骚操作,基本就对算法理解得七七八八了。
然而,对于NeRF 类的算法却不是这样的,原因在于光看 NeRF网络的输入和输出很难和它要做的新视角图像生成(进一步处理即可实现三维重建)这件事情建立联系,这也算是NeRF 类算法最难的地方。
具象化一点,可以看论文图 2:
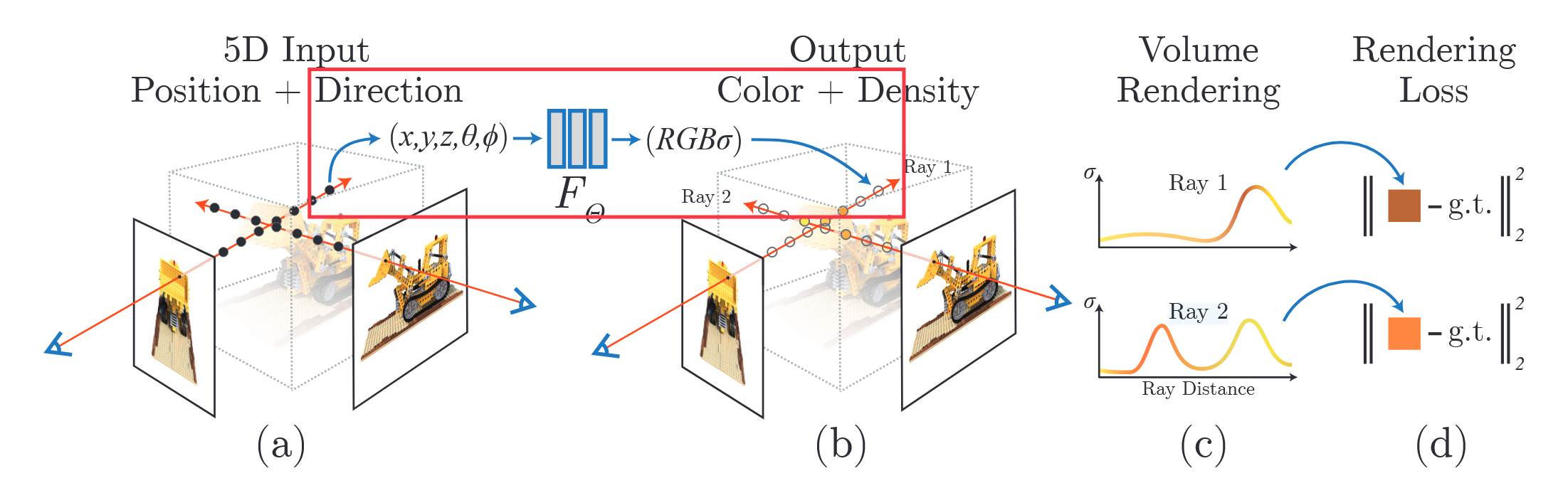
这张图基本上展示了算法的全貌,然而初一看可以说是蒙圈的,原因在于神经网络出现的地方在只占图中的一小块(别的神经网络论文基本上算法全貌就是一个神经网络的输入、输出、结构这些东西),而且初看着也不大明白为什么输入点的空间坐标以及朝向,预测点对应的RGB颜色值以及密度 σ \sigma σ(个人感觉严谨一点不应该将 σ \sigma σ视为密度,而是单位长度上粒子的不透明度率,因此后面全部写成这个)就可以实现新视角的预测。
为了更好的展开原理的介绍,我们先以问题+回答的形式整体聊一下它是怎么做的,后面再详细解释各个部分的内容。
问题1:需要准备什么样的数据?
答:可以参考第一篇博客( NeRF论文复现1 --- 代码运行和数据集分析,尤其是最后那张图),需要准备从多个不同视角拍摄的同一场景的多张图像,以及拍摄图像时相机的世界坐标系以及内参。
问题2:NeRF是怎么应用这些数据的?
答:在回答这个问题之前,需要明确两个前提条件。
- NeRF用的相机模型为小孔成像模型。
- NeRF使用的渲染模型为体渲染模型。
上面两个前提条件规定了一件事情,那就是图像上的一个像素点的颜色,由相机焦点与像素点的连线的方向(严格意义上讲应该是反方向才对,但论文为了方便把成像平面"翻转"到透镜的另一侧)的这根光线碰到的物体的颜色和不透明度决定。这是计算机图形学(CG)里面非常初级的假设,然而NeRF的操作直接将其与计算机视觉(CV)结合在了一块,这里可以后面细品。
总之,我们要知道图像上的一个像素点的颜色由以焦点为起点,穿过翻转过后的图像的像素点的这根射线(光线)所决定。因此,NeRF在训练的时候并不是将一整张图像扔进去训练的,而是先在图像上采样一些像素点,然后以焦点为起点,做穿过这些像素点的射线,即将图像上的一个像素处理成"空间坐标+方向向量+RGB值"的形式。
问题3:光线是不是得做采样啊,不然岂不是无法计算?
答:是的,NeRF限定了光线的有效值范围,并提出了粗、细网络对光线进行采样。具体的,先在光线上均匀采样一些点,扔进去粗网络做训练。然而依据粗网络吐出来的不同点对最终颜色影响的权重信息,在重要的位置上采样更多的点然后扔进精网络进行训练。具体细节会在后面介绍。
问题4:光线碰到的物体对最终像素点的颜色的影响怎么算啊?
答:使用体渲染进行计算,具体细节后面会介绍。
问题5:神经网络在哪里用到,怎么用到?
答:射线采样之后可以得到这根线上的多个点,每个点包含坐标位置和朝向信息,将这些点逐个扔进神经网络之后它会吐出其对应的颜色和单位长度不透明度率。这两个值用来在体渲染算法中算像素点的颜色。
问题6:神经网络吐出来的是个中间值,怎么计算LOSS啊?
答:这个本人认为是NeRF最让人拍案叫绝的地方。假设一根光线上采样100个点,我们让这100个点流过100次神经网络将得到100个中间值,然后将这100个中间值通过体渲染算法计算可以得到像素点的颜色值。这个过程是可微分的,因此这个颜色值就可以用来算LOSS!!!第一次看差点站了起来,秒啊,妙不可言!
OK,问题回答完了,下面将对比较重要的部分内容进行分析。
体渲染
回顾初中物理知识,我们之所以能看到物体呈现出某种颜色,是因为来自光源的光线照射到物体表面后,物体不会吸收所有波长的光,而是有选择性地吸收一部分光,并将剩余的另外一部分光通过反射或透射的方式送入我们的眼睛。这些最终进入眼睛的光信号被视网膜感知,并由大脑解读为相应的颜色。在这一过程中,光线也可以多次打到不同的物体之后再进入眼睛,这时不同物体就都会对这个光线最终的结果产生影响。模拟这个过程用到的就是评价3A游戏时常常被提起的光追技术。
NeRF这篇文章用到的渲染技术则相对简化,用的是一种称之为体渲染的模拟渲染技术,如上面提到的论文图2所示。它从小孔成像模型的最终结果出发,即从焦点出发,沿着焦点到翻转过后的图像的一个像素点的方向做一根射线(称之为光线),那么这个像素点的颜色肯定是这根光线碰到的所有粒子的颜色影响的叠加。而它碰到一个粒子之后还能继续前进的前提是这个粒子有透光的特性。
从这个模型不难看出,其直接简化的是别的方向打过来的光通过粒子散射或折射之后,也可能和我们设定的这根光线的方向相同,从而对我们最终像素产生影响。为了解决这个问题,论文又将光线方向作为参数传给粒子,这一操作使得同一个粒子在不同方向上的颜色是可学习的,从而弱化简化模型带来的影响。而后续研究中,比如高斯溅射使用球谐函数来拟合不同方向的颜色,应该能更好地拟合出颜色的连续性,从而降低神经网络的搜索空间。
公式分析
言归正传,NeRF中使用的体渲染公式如下:
C ( s ) ^ = ∫ 0 + ∞ T ( s ) σ ( s ) C ( s ) d s { { \hat { C ( s ) } = \displaystyle \int _ { 0 } ^ { + \infty } T ( s ) \sigma(s) C(s) ds } } C(s)^=∫0+∞T(s)σ(s)C(s)ds
其中, σ ( s ) \sigma(s) σ(s)表示在 s s s点处,单位长度上粒子的不透明度率。那么 σ ( s ) d s \sigma ( s ) d s σ(s)ds表示的就是在 d s ds ds这段微小距离内粒子的不透明度。
C ( s ) C(s) C(s)则是在 s s s点处,粒子发出的颜色。则 C ( s ) σ ( s ) d s C(s)\sigma ( s )d s C(s)σ(s)ds表示的是这段微小距离中粒子在没有别的阻碍的情况下对像素值贡献的颜色值。这说明不透明度越高,粒子本身颜色对最终像素颜色影响越大,可以想象一个橙色的玻璃,如果完全不透明,那么我们可以看到的就只有橙色本身了。
最后, T ( s ) T ( s ) T(s)表征的是 s s s点之前的透光率,可见上图(C)的上下两个子图的对比。如果前面透光率低,也就是光线在碰到粒子之前已经被沿途的粒子衰减了很大的能量,那么即便这个粒子本身密度很高,对最终的像素颜色影响也不大。
从整体上看这个公式,其对光线的表达也不完全符合现实,其没有考虑光线透过粒子之后不同颜色的光会被不同程度地削弱。比如一道光穿过了红色的玻璃,这道光红色部分被削弱的就没有其他部分那么多。当然,通过给粒子不同的方向学习不同的颜色,也可以弥补这个模型的缺陷。
这个公式中, σ ( s ) \sigma(s) σ(s)和 C ( s ) C(s) C(s)是通过输入粒子的坐标及光线朝向到神经网络之后神经网络吐出来的,而 T ( s ) T ( s ) T(s)需要进一步分析,其具体公式如下:
T ( s ) = e − ∫ 0 s σ ( t ) d t T ( s ) = e ^ { - \int _ { 0 } ^ { s } { \sigma ( t ) d t } } T(s)=e−∫0sσ(t)dt
之所以长这样,可以用下图解释:
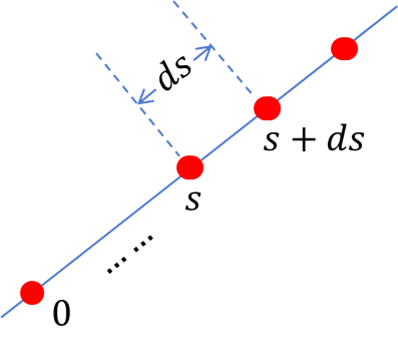
对于起始点来说,有 T ( 0 ) = 1 T(0)=1 T(0)=1;
而对于后面的点来说,有 T ( s + d s ) = T ( s ) × 光线透光率 ( d s ) T(s +ds)=T(s)\times 光线透光率(ds) T(s+ds)=T(s)×光线透光率(ds),即 s s s点之前的透光率乘以点 s s s到点 s + d s s+ds s+ds这段小距离的透光率。
而点 s s s到点 s + d s s+ds s+ds这段距离的透光率等于: 1 − σ ( s ) d s 1 - \sigma ( s ) d s 1−σ(s)ds,其中 σ ( s ) d s \sigma ( s ) d s σ(s)ds是 d s ds ds这个一小段的不透光率。有:
T ( s + d s ) = T ( s ) × 1 − σ ( s ) d s T(s +ds)=T(s)\times 1 - \\sigma ( s ) d s T(s+ds)=T(s)×1−σ(s)ds T ( s + d s ) = T ( s ) − T ( s ) σ ( s ) d s T(s +ds)=T(s) - T(s)\sigma ( s ) d s T(s+ds)=T(s)−T(s)σ(s)ds T ( s + d s ) − T ( s ) = − T ( s ) σ ( s ) d s T(s +ds)-T(s) =- T(s)\sigma ( s ) d s T(s+ds)−T(s)=−T(s)σ(s)ds d T ( s ) = − T ( s ) σ ( s ) d s dT(s) =- T(s)\sigma ( s ) d s dT(s)=−T(s)σ(s)ds d T ( s ) T ( s ) = − σ ( s ) d s \frac { d T ( s ) } { T ( s ) } = - \sigma ( s ) d s T(s)dT(s)=−σ(s)ds
两边同时取 0 0 0到 t t t的积分有:
∫ 0 t d T ( s ) T ( s ) = ∫ 0 t − σ ( s ) d s \int _{ 0 } ^ { t } \frac { d T ( s ) } { T ( s ) } = \int _ { 0 } ^ { t } - \sigma ( s ) d s ∫0tT(s)dT(s)=∫0t−σ(s)ds ∫ 0 t 1 T ( s ) d T ( s ) = ∫ 0 t − σ ( s ) d s \int _{ 0 } ^ { t } \frac { 1 } { T ( s ) }d T ( s ) = \int _ { 0 } ^ { t } - \sigma ( s ) d s ∫0tT(s)1dT(s)=∫0t−σ(s)ds ln T ( s ) ∣ 0 t = ∫ 0 t − σ ( s ) d s \ln T ( s ) \, \vert _ { 0 } ^ { t } = \int _ { 0 } ^ { t } - \sigma ( s ) d s lnT(s)∣0t=∫0t−σ(s)ds ln T ( t ) − ln T ( 0 ) = ∫ 0 t − σ ( s ) d s \ln T (t) -\ln T ( 0 ) = \int _ { 0 } ^ { t } - \sigma ( s ) d s lnT(t)−lnT(0)=∫0t−σ(s)ds ln T ( t ) − ln 1 = ∫ 0 t − σ ( s ) d s \ln T (t) -\ln 1 = \int _ { 0 } ^ { t } - \sigma ( s ) d s lnT(t)−ln1=∫0t−σ(s)ds ln T ( t ) = ∫ 0 t − σ ( s ) d s \ln T (t) = \int _ { 0 } ^ { t } - \sigma ( s ) d s lnT(t)=∫0t−σ(s)ds
将左右两边同时放在 e e e的指数部分,得:
T ( t ) = e ∫ 0 t − σ ( s ) d s T ( t ) = e ^ { \int _ { 0 } ^ { t } - \sigma ( s ) d s } T(t)=e∫0t−σ(s)ds
这个就是我们前面所说的 T ( t ) T ( t ) T(t)这个公式的推导过程。
离散化
不过,到这里并没有结束,因为这个公式是连续的,计算机处理不了,因此需要将其离散化。离散化的操作就是认为一段区间内,粒子的颜色和单位长度的不透明度率都是一样的。这个时候,公式
C ( s ) ^ = ∫ 0 + ∞ T ( s ) σ ( s ) C ( s ) d s { { \hat { C ( s ) } = \displaystyle \int _ { 0 } ^ { + \infty } T ( s ) \sigma(s) C(s) ds } } C(s)^=∫0+∞T(s)σ(s)C(s)ds T ( t ) = e ∫ 0 t − σ ( s ) d s T ( t ) = e ^ { \int _ { 0 } ^ { t } - \sigma ( s ) d s } T(t)=e∫0t−σ(s)ds
将变为如下的公式:
C ^ ( r ) = ∑ i = 1 N T i ( 1 − e − σ i δ i ) c i \hat { C } ( r ) = \sum _ { i = 1 } ^ { N } T _ { i } ( 1 - e ^ { - \sigma _ { i } \delta _ { i } } ) c _ { i } C^(r)=i=1∑NTi(1−e−σiδi)ci T i = e − ∑ j = 1 i − 1 σ j δ j (其中 δ j 表示区间长度) \begin{array} { r } { T _ { i } = e ^ { - \sum _ { j = 1 } ^ { i - 1 } \sigma _ { j } \delta _ { j } } } \end{array}(其中\delta _ { j }表示区间长度) Ti=e−∑j=1i−1σjδj(其中δj表示区间长度)
推理如下:
因为已经假设了在一段区间内粒子的颜色和单位长度的不透明度率是一样的,因此可以将一段区间贡献的颜色值写成 I i I_i Ii。这个时候颜色将表达为:
C ^ ( r ) = ∑ i = 1 N I i \hat { C } ( r )= \sum _ { i = 1 } ^ { N } I_i C^(r)=i=1∑NIi
设 t i t_i ti为区间起点, t i + 1 t_{i+1} ti+1为区间终点,有:
I i = ∫ t i t i + 1 T ( t ) σ i C i d t = σ i C i ∫ t i t i + 1 T ( t ) d t = σ i C i ∫ t i t i + 1 e ∫ 0 t − σ ( s ) d s d t I_i=\displaystyle \int _ { t_i } ^ { t_{i+1}} T ( t ) \sigma_i C_i dt =\sigma_i C_i\displaystyle \int _ { t_i } ^ { t_{i+1}} T ( t ) dt =\sigma_i C_i\displaystyle \int _ { t_i } ^ { t_{i+1}} e ^ { \int _ { 0 } ^ { t } - \sigma ( s ) d s } dt Ii=∫titi+1T(t)σiCidt=σiCi∫titi+1T(t)dt=σiCi∫titi+1e∫0t−σ(s)dsdt = σ i C i ∫ t i t i + 1 e − ∫ 0 t i σ ( s ) d s + ∫ t i t σ ( s ) d s d t = σ i C i ∫ t i t i + 1 e − ∫ 0 t i σ ( s ) d s e − ∫ t i t σ ( s ) d s d t =\sigma_i C_i\displaystyle \int _ { t_i } ^ { t_{i+1}} e ^ { - \\int _ { 0 } \^ { t_i } \\sigma ( s ) d s+\\int _ { t_i } \^ { t } \\sigma ( s ) d s } dt =\sigma_i C_i\displaystyle \int _ { t_i } ^ { t_{i+1}} e ^ { - \int _ { 0 } ^ { t_i } \sigma ( s ) d s } e ^ { - \int _ { t_i } ^ { t } \sigma ( s ) d s } dt =σiCi∫titi+1e−∫0tiσ(s)ds+∫titσ(s)dsdt=σiCi∫titi+1e−∫0tiσ(s)dse−∫titσ(s)dsdt
因为从 0 → t i 0→t_i 0→ti这段距离的透光率是定值 T i T_i Ti,因此上述公式等于:
σ i C i T i ∫ t i t i + 1 e − ∫ t i t σ ( s ) d s d t \sigma_i C_i T_i\displaystyle \int _ { t_i } ^ { t_{i+1}} e ^ { - \int _ { t_i } ^ { t } \sigma ( s ) d s } dt σiCiTi∫titi+1e−∫titσ(s)dsdt
其中:
T i = e ∫ 0 t i − σ ( s ) d s = e − ∑ j = 1 i − 1 σ i δ i T_i= e ^ { \int _ { 0 } ^ { t_i } - \sigma ( s ) d s }= e ^ { - \sum _ { j = 1 } ^ { i - 1 } \sigma _ { i } \delta _ { i } } Ti=e∫0ti−σ(s)ds=e−∑j=1i−1σiδi
进一步看到内层积分的内部,因为已经假定了 σ \sigma σ在区间内是个定值,而 t n → t t_n \to t tn→t表示区间起点到当前点的距离,因此公式进一步写作:
σ i C i T i ∫ t i t i + 1 e − σ i ( t − t i ) d t \sigma_i C_i T_i\displaystyle \int _ { t_i } ^ { t_{i+1}} e ^ { - \sigma _i (t-t_i) } dt σiCiTi∫titi+1e−σi(t−ti)dt = σ i C i T i − 1 σ i e − σ i ( t − t i ) ∣ t i t i + 1 = \sigma _ { i } C _ { i } T_i - \\frac { 1 } { \\sigma _ { i } } e \^ { - \\sigma _ { i } ( t - t _ { i } ) } \\, \| _ { t _ { i } } \^ { t _ { i + 1 } } =σiCiTi−σi1e−σi(t−ti)∣titi+1 = σ i C i T i { − 1 σ i e − σ i ( t i + 1 − t i ) − e − σ i ( t i − t i ) } = \sigma _ { i } C _ { i } T_i \{- \frac { 1 } { \sigma _ { i } } e \^ { - \\sigma _ { i } ( t_{i+1} - t _ { i } ) } -e \^ { - \\sigma _ { i } ( t_{i} - t _ { i } ) }\} =σiCiTi{−σi1e−σi(ti+1−ti)−e−σi(ti−ti)} = σ i C i T i { − 1 σ i e − σ i ( t i + 1 − t i ) − 1 } = \sigma _ { i } C _ { i } T_i \{- \frac { 1 } { \sigma _ { i } } e \^ { - \\sigma _ { i } ( t_{i+1} - t _ {i } ) } -1\} =σiCiTi{−σi1e−σi(ti+1−ti)−1} = C i T i ( 1 − e − δ i σ i ) = C _ { i } T_i (1-e ^ { - \delta_i\sigma _ { i } }) =CiTi(1−e−δiσi)
这个就是 I i I_i Ii的最终表达,此时有:
C ^ ( r ) = ∑ i = 1 N I i = ∑ i = 1 N C i T i ( 1 − e − δ i σ i ) \hat { C } ( r )= \sum _ { i = 1 } ^ { N } I_i= \sum _ { i = 1 } ^ { N } C _ { i } T_i (1-e ^ { - \delta_i\sigma _ { i } }) C^(r)=i=1∑NIi=i=1∑NCiTi(1−e−δiσi)
就是论文给出的体渲染公式,由该公式可以求得像素点颜色的构成。
如果看代码的话,还需将公式进一步整理一下:
C ^ ( r ) = ∑ i = 1 N C i e − ∑ j = 1 i − 1 σ j δ j ( 1 − e − δ i σ i ) \hat { C } ( r )= \sum _ { i = 1 } ^ { N } C _ { i } e ^ { - \sum _ { j = 1 } ^ { i - 1 } \sigma _ { j } \delta _ { j } } (1-e ^ { - \delta_i\sigma _ { i } }) C^(r)=i=1∑NCie−∑j=1i−1σjδj(1−e−δiσi)
设 α i = 1 − e − σ i δ i \alpha _ { i } = 1 - e ^ { - \sigma _ { i } \delta _ { i } } αi=1−e−σiδi,则上式等于:
C ^ ( r ) = ∑ i = 1 N C i e − ( δ 1 σ 1 + δ 2 σ 2 + . . . + δ i − 1 σ i − 1 ) ( 1 − e − δ i σ i ) \hat { C } ( r )= \sum _ { i = 1 } ^ { N } C _ { i } e ^ { - (\delta_1\sigma_1+\delta_2\sigma_2+...+\delta_{i-1}\sigma_{i-1})} (1-e ^ { - \delta_i\sigma _ { i } }) C^(r)=i=1∑NCie−(δ1σ1+δ2σ2+...+δi−1σi−1)(1−e−δiσi) C ^ ( r ) = ∑ i = 1 N C i e − δ 1 σ 1 e − δ 2 σ 2 . . . e − δ i − 1 σ i − 1 ( 1 − e − δ i σ i ) \hat { C } ( r )= \sum _ { i = 1 } ^ { N } C _ { i } e ^ { - \delta_1\sigma_1}e ^ { -\delta_2\sigma_2}...e ^ { -\delta_{i-1}\sigma_{i-1}} (1-e ^ { - \delta_i\sigma _ { i } }) C^(r)=i=1∑NCie−δ1σ1e−δ2σ2...e−δi−1σi−1(1−e−δiσi) C ^ ( r ) = ∑ i = 1 N C i ( 1 − α 1 ) ( 1 − α 2 ) . . . ( 1 − α i − 1 ) α i \hat { C } ( r )= \sum _ { i = 1 } ^ { N } C _ { i } (1-\alpha _ { 1 })(1-\alpha _ { 2 })...(1-\alpha _ { i-1 }) \alpha _ { i } C^(r)=i=1∑NCi(1−α1)(1−α2)...(1−αi−1)αi C ^ ( r ) = C 1 α 1 ( 1 − α 0 ) + C 2 α 2 ( 1 − α 1 ) ( 1 − α 0 ) + . . . + C i α i ( 1 − α i − 1 ) ( 1 − α i − 2 ) . . . ( 1 − α 0 ) \hat { C } ( r )= C_1\alpha _1(1-\alpha_0)+C_2\alpha 2(1-\alpha_1)(1-\alpha_0)+...+C_i\alpha i(1-\alpha{i-1})(1-\alpha{i-2})...(1-\alpha_0) C^(r)=C1α1(1−α0)+C2α2(1−α1)(1−α0)+...+Ciαi(1−αi−1)(1−αi−2)...(1−α0)
这个公式的实现在代码的run_nerf.py文件中的raw2outputs函数中,整理如下:
python
# 体渲染部分,输入的是神经网络的输出raw,以及对应的深度值z_vals(点距离小孔多远)和光线方向rays_d,输出的是rgb_map等渲染结果
def raw2outputs(raw, z_vals, rays_d, raw_noise_std=0, white_bkgd=False, pytest=False):
"""Transforms model's predictions to semantically meaningful values.
Args:
raw: [num_rays, num_samples along ray, 4]. Prediction from model.
z_vals: [num_rays, num_samples along ray]. Integration time.
rays_d: [num_rays, 3]. Direction of each ray.
Returns:
rgb_map: [num_rays, 3]. Estimated RGB color of a ray.
disp_map: [num_rays]. Disparity map. Inverse of depth map.
acc_map: [num_rays]. Sum of weights along each ray.
weights: [num_rays, num_samples]. Weights assigned to each sampled color.
depth_map: [num_rays]. Estimated distance to object.
"""
# 求deltas,即分段距离
dists = z_vals[...,1:] - z_vals[...,:-1] # 这段代码计算了相邻深度值之间的差值,得到每个采样点对应的距离增量_vals[...,:-1] 取出每条光线除最后一个采样点外的所有深度值,形状为 [N_rays, N_samples-1]。z_vals[...,1:] 取出每条光线除第一个采样点外的所有深度值,形状为 [N_rays, N_samples-1]
dists = torch.cat([dists, torch.Tensor([1e10]).expand(dists[...,:1].shape)], -1) # [N_rays, N_samples],在射线的最后一个采样点后面添加一个非常大的距离,表示射线在该点之后将继续延伸很远
dists = dists * torch.norm(rays_d[...,None,:], dim=-1) # [N_rays, N_samples],将距离增量乘以光线方向的范数,即在三维空间中计算实际的距离增量
rgb = torch.sigmoid(raw[...,:3]) # [N_rays, N_samples, 3]
noise = 0.
if raw_noise_std > 0.:
noise = torch.randn(raw[...,3].shape) * raw_noise_std
# Overwrite randomly sampled data if pytest
# 这里是为了测试时使用固定的随机数,确保结果可复现
if pytest:
np.random.seed(0)#设置随机种子为0
noise = np.random.rand(*list(raw[...,3].shape)) * raw_noise_std
noise = torch.Tensor(noise)
# 这又是作者的封装操作,就不能好好把步骤写出来,一定得先封装成函数!
raw2alpha = lambda raw, dists, act_fn=F.relu: 1.-torch.exp(-act_fn(raw)*dists)
# 得到alpha值,raw模型输出的第四个通道是单位长度不透明度率,由公式推导可得alpha=1-exp(-sigma*delta)
alpha = raw2alpha(raw[...,3] + noise, dists) # [N_rays, N_samples]
# weights = alpha * tf.math.cumprod(1.-alpha + 1e-10, -1, exclusive=True)
# 累计乘法,这种加速算子理解起来比较费劲,有AI可以让AI拆开来看看,也可看着公式理解
weights = alpha * torch.cumprod(torch.cat([torch.ones((alpha.shape[0], 1)), 1.-alpha + 1e-10], -1), -1)[:, :-1]
rgb_map = torch.sum(weights[...,None] * rgb, -2) # [N_rays, 3]
depth_map = torch.sum(weights * z_vals, -1) # 求深度图,直接用权重加权平均深度值
disp_map = 1./torch.max(1e-10 * torch.ones_like(depth_map), depth_map / torch.sum(weights, -1))# 归一化后的深度图
acc_map = torch.sum(weights, -1) # 累计不透明度
if white_bkgd:
rgb_map = rgb_map + (1.-acc_map[...,None])
return rgb_map, disp_map, acc_map, weights, depth_map射线粒子的采样
由前面的体渲染公式可知,Nerf需要获得射线上的多个点的颜色和单位不透明度率来实现像素的渲染,这两个信息是通过将点的坐标和方向向量输入到神经网络来实现学习和预测的。
因为我们不可能无限制的采集射线上的点,因此采集哪些点就成了一个比较重要的问题。
Nerf中通过构建粗/细网络来实现这一功能(注意,两个网络在结构上是完全一样的,只是训练时输入的对象不一样)。对于粗网络,取射线从2→6这一段均匀采样64个点然后进行训练。这一网络将输出这64个点的颜色和单位长度不透明度率,后者非常关键,因为它指明了对应位置是否存在物体而不是空气。因此,对于细网络,将借助粗网络得到的密度结果来进一步采样,在物体附近多分配采样点。
那这个操作是怎么完成的呢?
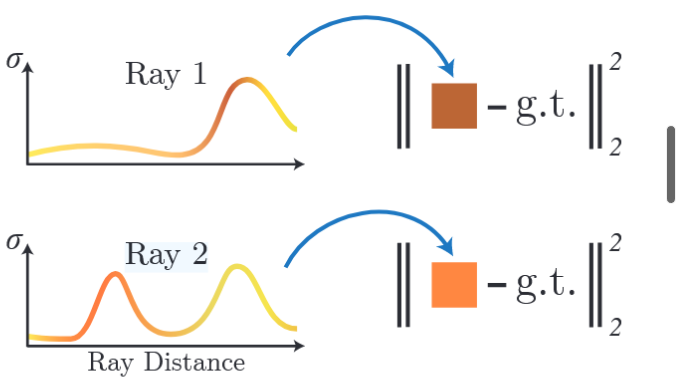
这里可能最容易想到的是直接用网络输出的 σ \sigma σ值来求分布。但仔细一想就会发现这一操作是有问题的。可看上图,对于上面的子图,我们明显需要把点分布在波峰附近。但对于下面的子图是否应该均匀分配在两个波峰上呢?答案是否定的,因为前面的波峰可能已经吸收了大部分的能量,后续的波峰在事实上对像素颜色的影响是显然小于前面的波峰的(比如有一面墙挡住了光线,那这面墙后面还有没有墙影响就很小)。如果对后面的波峰分布相同权重的点的个数,那这些分配到后面波峰附近的点对像素结果的影响将远远小于前面波峰附近的点,这将不利于网络的收敛。
因此论文使用的权重是上面推出的体渲染公式中每个点的颜色的权重部分,即 C ^ ( r ) = C 1 α 1 ( 1 − α 0 ) + C 2 α \hat { C } ( r )= C_1\alpha _1(1-\alpha_0)+C_2\alpha C^(r)=C1α1(1−α0)+C2α 2 ( 1 − α 1 ) ( 1 − α 0 ) + . . . + C i α i ( 1 − α 2(1-\alpha_1)(1-\alpha_0)+...+C_i\alpha i(1-\alpha 2(1−α1)(1−α0)+...+Ciαi(1−α i − 1 ) ( 1 − α i − 2 ) . . . ( 1 − α 0 ) {i-1})(1-\alpha{i-2})...(1-\alpha_0) i−1)(1−αi−2)...(1−α0)中的 α 1 ( 1 − α 0 ) \alpha 1(1-\alpha_0) α1(1−α0)、 α 2 ( 1 − α 1 ) ( 1 − α 0 ) \alpha 2(1-\alpha_1)(1-\alpha_0) α2(1−α1)(1−α0)、...、 α i ( 1 − α i − 1 ) ( 1 − α i − 2 ) . . . ( 1 − α 0 ) \alpha i(1-\alpha{i-1})(1-\alpha{i-2})...(1-\alpha_0) αi(1−αi−1)(1−αi−2)...(1−α0)这一部分,将其写成 w 1 w_1 w1、 w 2 w_2 w2、...、 w i w_i wi这样的形式,然后进行归一化,得到点的权重公式为 w ^ i = w i / Σ j = 1 N c w j \hat { w } _ { i } ~ = ~ w _ { i } \big / \Sigma _ { j = 1 } ^ { N _ { c } } \, w _ { j } w^i = wi/Σj=1Ncwj。(注意,论文中 w i w _ { i } wi写成 w i = T i ( 1 − exp ( − σ i δ i ) ) w _ { i }= T _ { i } ( 1 - \exp ( - \sigma _ { i } \delta _ { i } ) ) wi=Ti(1−exp(−σiδi)),这和上述说的是等效的。)
另外,论文中把概率密度函数直接写成PDF,我一开始还不知道是什么鬼愣了一下。。。
在代码实现中,其操作是先将PDF转换为累计分布函数CDF:
C D F ( i ) = ∑ j = 1 i P D F ( j ) \mathrm { C D F } ( i ) = \sum _ { j = 1 } ^ { i } \mathrm { P D F } ( j ) CDF(i)=j=1∑iPDF(j)
然后取CDF的反函数,这样输入一个在0,1之间均匀采样得到的数到CDF的反函数中,将得到对应区间的索引,这个索引值可以认为是根据粗网络输出的光线密度分布加权采样的点。重复加权采样192个点,这些点将被用来训练细网络。
这里采样的具体操作在run_nerf_helpers.py的sample_pdf函数中,整理如下:
python
# 从权重分布中采样新的深度点
def sample_pdf(bins, weights, N_samples, det=False, pytest=False):
# Get pdf
weights = weights + 1e-5 # prevent nans
pdf = weights / torch.sum(weights, -1, keepdim=True) # 权重归一化,得到概率密度函数
cdf = torch.cumsum(pdf, -1)# 累计求和,得到累积分布函数
cdf = torch.cat([torch.zeros_like(cdf[...,:1]), cdf], -1) # (batch, len(bins)) # 在前面添加0,表示cdf从0开始
# Take uniform samples
# 在[0,1]区间内均匀采样
if det:
# 这里是为了测试时使用固定的采样点,确保结果可复现
u = torch.linspace(0., 1., steps=N_samples)
u = u.expand(list(cdf.shape[:-1]) + [N_samples])
else:
u = torch.rand(list(cdf.shape[:-1]) + [N_samples]) # 在[0,1]区间内均匀采样64+128=192个点
# Pytest, overwrite u with numpy's fixed random numbers
if pytest:
np.random.seed(0)
new_shape = list(cdf.shape[:-1]) + [N_samples]
if det:
u = np.linspace(0., 1., N_samples)
u = np.broadcast_to(u, new_shape)
else:
u = np.random.rand(*new_shape)
u = torch.Tensor(u)
# Invert CDF(用CDF反采样,定位u落在哪个区间)
u = u.contiguous() # 确保内存连续,便于后续索引运算
inds = torch.searchsorted(cdf, u, right=True) # 找到每个 u 落在哪个 CDF 区间
below = torch.max(torch.zeros_like(inds-1), inds-1) # 计算下界索引,避免越界
above = torch.min((cdf.shape[-1]-1) * torch.ones_like(inds), inds) # 计算上界索引,避免越界
inds_g = torch.stack([below, above], -1) # 得到点的上下界索引对
# cdf_g = tf.gather(cdf, inds_g, axis=-1, batch_dims=len(inds_g.shape)-2)
# bins_g = tf.gather(bins, inds_g, axis=-1, batch_dims=len(inds_g.shape)-2)
matched_shape = [inds_g.shape[0], inds_g.shape[1], cdf.shape[-1]] # 让CDF/Bins扩展到可按inds_g索引的形状
cdf_g = torch.gather(cdf.unsqueeze(1).expand(matched_shape), 2, inds_g) # 取上下界CDF值
bins_g = torch.gather(bins.unsqueeze(1).expand(matched_shape), 2, inds_g) # 取上下界深度值(bin)
denom = (cdf_g[...,1]-cdf_g[...,0]) # 计算区间占比,得到概率密度
denom = torch.where(denom<1e-5, torch.ones_like(denom), denom)# 防止除零
t = (u-cdf_g[...,0])/denom # 计算u在区间内的归一化位置
samples = bins_g[...,0] + t * (bins_g[...,1]-bins_g[...,0]) #采样
return samples位置编码
Nerf使用了位置编码的操作,原因在于作者发现如果直接输入 x 、 y 、 z x、y、z x、y、z/ θ 、 ϕ \theta、\phi θ、ϕ这样的坐标/角度信息,其重建出来的细节部分基本上会非常的模糊。原因在On the Spectral Bias of Neural Networks这篇论文有提到,是因为神经网络倾向于拟合低频信息,而高频的信息如图像的边缘或者噪声则难以被拟合,这属于喜忧参半的特性(好处是不太被噪声干扰)。另外,这篇论文还提到了如果将输入通过高频函数映射到高维空间,则神经网络能更好的拟合高频信息。
原因在于,高频基函数使得相邻输入的差异放大。比如:
- 低频基函数(如 c o s ( 2 0 π p ) cos(2^0πp) cos(20πp)) :当输入x从 0.1 轻微变化到 0.1001 时, c o s ( π ∗ 1 ∗ 0.1 ) = 0.9510565163 cos(π*1*0.1)=0.9510565163 cos(π∗1∗0.1)=0.9510565163, c o s ( π ∗ 1 ∗ 0.1001 ) = 0.950959388 cos(π*1*0.1001)=0.950959388 cos(π∗1∗0.1001)=0.950959388,相差 0.000097127487943 0.000097127487943 0.000097127487943,变化非常小。网络学习到的映射在这一点附近会很平滑。
- 高频基函数(如 c o s ( 2 9 π p ) = c o s ( 512 π p ) cos(2^9πp)=cos(512πp) cos(29πp)=cos(512πp)) :当输x入从 0.1 轻微变化到 0.1001 时, c o s ( π ∗ 512 ∗ 0.1 ) = − 0.8090169944 cos(π*512*0.1)=-0.8090169944 cos(π∗512∗0.1)=−0.8090169944, c o s ( π ∗ 512 ∗ 0.1001 ) = − 0.704436033 cos(π*512*0.1001)=-0.704436033 cos(π∗512∗0.1001)=−0.704436033,相差 0.1045809614 0.1045809614 0.1045809614。相比低频基函数,变化巨大。
这个正是我们想要的,因为我们的目标是让神经网络学习到高频信息,比如一个非常锐利的边缘,这个边缘在空间上表现出来的特征是位置的微小变化将造成像素颜色的巨大变化。比如在x=0.1时希望输出是红色,在x=0.1001时则希望输出是蓝色。在没有高频映射的时候,网络接收到的两个标量输入0.1和0.1001几乎一模一样,它很难学会输出完全不同的结果,最终会"平均"成一个模糊的紫色。这是光谱偏差,模型倾向于学习平滑的解。但当我们对输入进行高频映射后,网络接收到的两个高维向量γ(0.1)和γ(0.1001)天差地别。网络可以轻松地为这两个完全不同的输入分配完全不同的输出(红色和蓝色),从而完美地表示出这个高频突变。
论文使用的高频函数如下:
γ ( p ) = ( sin ( 2 0 π p ) , cos ( 2 0 π p ) , ⋯ , sin ( 2 L − 1 π p ) , cos ( 2 L − 1 π p ) ) \gamma ( p ) = \big ( \sin \bigl ( 2 ^ { 0 } \pi p \bigr ) , \cos \bigl ( 2 ^ { 0 } \pi p \bigr ) , \cdots , \sin \bigl ( 2 ^ { L - 1 } \pi p \bigr ) , \cos \bigl ( 2 ^ { L - 1 } \pi p \bigr ) \big ) γ(p)=(sin(20πp),cos(20πp),⋯,sin(2L−1πp),cos(2L−1πp))
可以看到每个 L L L对应 s i n sin sin和 c o s cos cos一对相同频率的基函数,坐标输入为 x 、 y 、 z x、y、z x、y、z,将他们归一化到 − 1 , 1 -1,1 −1,1这个区间之后代入上面的公式。取 L = 10 L=10 L=10,则最终我们将得到 2 ∗ 3 ∗ 10 = 60 2*3*10=60 2∗3∗10=60个值作为真正的输入(事实上代码中把原来的xyz也加进去了,输出为63个值)。同理,取 L = 4 L=4 L=4也可将 θ 、 ϕ \theta、\phi θ、ϕ映射为 2 ∗ 3 ∗ 4 = 24 2*3*4=24 2∗3∗4=24(注意,这里论文虽然写的是 θ 、 ϕ \theta、\phi θ、ϕ,但实际的方向用的是单位向量,因此最后算的时候是 ∗ 3 *3 ∗3,此外也要加上原始单元向量三个值,总共是27个值)。这里的 L L L是超参数,作者认为在方向上颜色不应该突变那么厉害,因此取的比位置向量小很多。
这一部分的实现在run_nerf_helpers.py文件的get_embedder函数和Embedder类中,把代码抽出来如下:
python
import torch
import torch.nn as nn
# 位置编码器类,输入是三维坐标,输出是高维的正弦/余弦特征
class Embedder:
def __init__(self, **kwargs):
self.kwargs = kwargs
self.create_embedding_fn()
# 依据配置创建嵌入函数
def create_embedding_fn(self):
embed_fns = []
d = self.kwargs['input_dims'] # 输入维度,通常为3(x,y,z)
out_dim = 0
if self.kwargs['include_input']: # 是否包含原始输入
embed_fns.append(lambda x : x) # 直接返回输入
out_dim += d
max_freq = self.kwargs['max_freq_log2'] # 最大频率的对数值
N_freqs = self.kwargs['num_freqs'] # 频率数量
if self.kwargs['log_sampling']: # 频率按对数尺度采样
freq_bands = 2.**torch.linspace(0., max_freq, steps=N_freqs)
else:
freq_bands = torch.linspace(2.**0., 2.**max_freq, steps=N_freqs)
for freq in freq_bands:
for p_fn in self.kwargs['periodic_fns']:
embed_fns.append(lambda x, p_fn=p_fn, freq=freq : p_fn(x * freq))
out_dim += d
self.embed_fns = embed_fns
self.out_dim = out_dim
# 对输入进行位置编码
def embed(self, inputs):
return torch.cat([fn(inputs) for fn in self.embed_fns], -1)
# 返回一个"位置编码"函数(embed_fn)和该编码后的通道数(out_dim)
def get_embedder(multires, i=0):
if i == -1:
return nn.Identity(), 3 # 恒等变换,不进行位置编码
# 这是一个位置编码的配置参数字典
embed_kwargs = {
'include_input' : True, # 编码结果里包含原始输入三维坐标(x,y,z)
'input_dims' : 3, # 输入维度为 3(x,y,z)
'max_freq_log2' : multires-1, # 最高频率为 2^(multires-1)
'num_freqs' : multires, # 频率数量为 multires
'log_sampling' : True, # 频率按对数尺度采样
'periodic_fns' : [torch.sin, torch.cos], # 使用正弦和余弦函数进行编码
}
embedder_obj = Embedder(**embed_kwargs) # 创建位置编码器对象
# 这里这么写非常恶心,感觉像是为了炫技之类的骚操作。3
# 实际上的作用就是创建一个匿名函数,这个函数调用embedder_obj的embed方法对输入进行位置编码。
# eo=embedder_obj 是为了在lambda函数中绑定当前的embedder_obj对象,避免embedder_obj在函数调用时发生变化。
embed = lambda x, eo=embedder_obj : eo.embed(x)
return embed, embedder_obj.out_dim
# 主函数用于测试位置编码器
if __name__ == "__main__":
embed_fn, out_dim = get_embedder(multires=10, i=0) # 输入编码器的频率数量为10,i=0表示进行位置编码,输出编码函数和通道数
print(f"Output dimension: {out_dim}") # 输出编码后的通道数
#x = torch.randn(1, 3) # 随机生成一个三维坐标输入
# 生成一个测试输入点 (1, 3)
x = torch.tensor([[0.1, 0.2, 0.3]])
embedded_x = embed_fn(x) # 对输入进行位置编码
print(f"Embedded output shape: {embedded_x.shape}") # 输出编码结果的形状
print(f"Embedded output: {embedded_x}") # 输出编码结果网络结构
NeRF的网络结构可以说并没什么值得说的,输入是点的位置和视角(位置编码后,共63+27=90个值)。经过一堆全连接层之后输出。输出值总共有四个,为 R G B + σ RGB+\sigma RGB+σ值。具体的网络结构如下图所示:
值得注意的是视角信息是在很后面才被加入进去进行训练的,而且 σ \sigma σ值(单位长度上粒子的不透明度率)的输出和视角信息没有关系。这样设计的好处有二:
- 告诉网络 σ \sigma σ值与视角无关,从而压缩了一部分网络的搜索空间。
- 给网络一个模糊的指引,告诉网络空间位置中某一个点的颜色,大部分由这个点本来的位置决定(即物体本来应该的颜色),然后观测角度不同会以该点颜色为基础产生一定的变化。
网络结构的代码在run_nerf_helpers.py中,可整理如下:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class NeRF(nn.Module):
def __init__(self, D=8, W=256, input_ch=3, input_ch_views=3, output_ch=4, skips=[4], use_viewdirs=False):
"""
"""
super(NeRF, self).__init__()
self.D = D
self.W = W
self.input_ch = input_ch
self.input_ch_views = input_ch_views
self.skips = skips
self.use_viewdirs = use_viewdirs
self.pts_linears = nn.ModuleList(
[nn.Linear(input_ch, W)] + [nn.Linear(W, W) if i not in self.skips else nn.Linear(W + input_ch, W) for i in range(D-1)])
### Implementation according to the official code release (https://github.com/bmild/nerf/blob/master/run_nerf_helpers.py#L104-L105)
self.views_linears = nn.ModuleList([nn.Linear(input_ch_views + W, W//2)])
### Implementation according to the paper
# self.views_linears = nn.ModuleList(
# [nn.Linear(input_ch_views + W, W//2)] + [nn.Linear(W//2, W//2) for i in range(D//2)])
if use_viewdirs:
self.feature_linear = nn.Linear(W, W)
self.alpha_linear = nn.Linear(W, 1)
self.rgb_linear = nn.Linear(W//2, 3)
else:
self.output_linear = nn.Linear(W, output_ch)
def forward(self, x):
input_pts, input_views = torch.split(x, [self.input_ch, self.input_ch_views], dim=-1)
h = input_pts
for i, l in enumerate(self.pts_linears):
h = self.pts_linears[i](h)
h = F.relu(h)
if i in self.skips:
h = torch.cat([input_pts, h], -1)
if self.use_viewdirs:
alpha = self.alpha_linear(h)
feature = self.feature_linear(h)
h = torch.cat([feature, input_views], -1)
for i, l in enumerate(self.views_linears):
h = self.views_linears[i](h)
h = F.relu(h)
rgb = self.rgb_linear(h)
outputs = torch.cat([rgb, alpha], -1)
else:
outputs = self.output_linear(h)
return outputs
# 主函数用于测试NeRF网络
if __name__ == "__main__":
model = NeRF(D=8, W=256, input_ch=63, input_ch_views=27, output_ch=4, skips=[4], use_viewdirs=True)
print(model)
x = torch.randn(1, 63 + 27) # 随机生成一个输入样本,假设位置编码后维度为63,视角编码后维度为27
output = model(x)
print(f"Output shape: {output.shape}") # 输出的形状应为 (1, 4)
# 使用onnx导出模型
torch.onnx.export(model, x, "nerf_model.onnx", input_names=['input'], output_names=['output'], opset_version=11)
在上一小节射线粒子的采样中我们知道NeRF的网络事实上分为粗和精网络两个,因此训练时我们实际上需要两个一模一样的网络。
作者为了方便,在给出的代码中将两个网络的创建和相关的优化器设置、权重加载、批处理等相关操作封装在了一起,全部网络代码如下:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import os
from Embedder import get_embedder
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
np.random.seed(0)
class NeRF(nn.Module):
def __init__(self, D=8, W=256, input_ch=3, input_ch_views=3, output_ch=4, skips=[4], use_viewdirs=False):
"""
"""
super(NeRF, self).__init__()
self.D = D
self.W = W
self.input_ch = input_ch
self.input_ch_views = input_ch_views
self.skips = skips
self.use_viewdirs = use_viewdirs
self.pts_linears = nn.ModuleList(
[nn.Linear(input_ch, W)] + [nn.Linear(W, W) if i not in self.skips else nn.Linear(W + input_ch, W) for i in range(D-1)])
### Implementation according to the official code release (https://github.com/bmild/nerf/blob/master/run_nerf_helpers.py#L104-L105)
self.views_linears = nn.ModuleList([nn.Linear(input_ch_views + W, W//2)])
### Implementation according to the paper
# self.views_linears = nn.ModuleList(
# [nn.Linear(input_ch_views + W, W//2)] + [nn.Linear(W//2, W//2) for i in range(D//2)])
if use_viewdirs:
self.feature_linear = nn.Linear(W, W)
self.alpha_linear = nn.Linear(W, 1)
self.rgb_linear = nn.Linear(W//2, 3)
else:
self.output_linear = nn.Linear(W, output_ch)
def forward(self, x):
input_pts, input_views = torch.split(x, [self.input_ch, self.input_ch_views], dim=-1)
h = input_pts
for i, l in enumerate(self.pts_linears):
h = self.pts_linears[i](h)
h = F.relu(h)
if i in self.skips:
h = torch.cat([input_pts, h], -1)
if self.use_viewdirs:
alpha = self.alpha_linear(h)
feature = self.feature_linear(h)
h = torch.cat([feature, input_views], -1)
for i, l in enumerate(self.views_linears):
h = self.views_linears[i](h)
h = F.relu(h)
rgb = self.rgb_linear(h)
outputs = torch.cat([rgb, alpha], -1)
else:
outputs = self.output_linear(h)
return outputs
# 批处理函数,将大批量输入分割成小批量进行处理
def batchify(fn, chunk):
"""Constructs a version of 'fn' that applies to smaller batches.
"""
if chunk is None:
return fn
def ret(inputs):
# 把 inputs 按 chunk 大小沿第 0 维分成多个小块,对每个小块调用 fn 前向计算,
# 然后用 torch.cat 在第 0 维把所有结果拼回一个整体张量。这样做是为了分批处理大输入,降低显存占用。
return torch.cat([fn(inputs[i:i+chunk]) for i in range(0, inputs.shape[0], chunk)], 0)
return ret
# 网络前向传播的批处理函数
def run_network(inputs, viewdirs, fn, embed_fn, embeddirs_fn, netchunk=1024*64):
"""Prepares inputs and applies network 'fn'.
"""
inputs_flat = torch.reshape(inputs, [-1, inputs.shape[-1]])
embedded = embed_fn(inputs_flat)
if viewdirs is not None:
input_dirs = viewdirs[:,None].expand(inputs.shape)
input_dirs_flat = torch.reshape(input_dirs, [-1, input_dirs.shape[-1]])
embedded_dirs = embeddirs_fn(input_dirs_flat)
embedded = torch.cat([embedded, embedded_dirs], -1)
outputs_flat = batchify(fn, netchunk)(embedded)
outputs = torch.reshape(outputs_flat, list(inputs.shape[:-1]) + [outputs_flat.shape[-1]])
return outputs
# 创建NeRF模型,包括网络和优化器,如果预训练权重的加载
def create_nerf(args):
"""Instantiate NeRF's MLP model.
"""
embed_fn, input_ch = get_embedder(args.multires, args.i_embed)# 获得位置编码函数和编码后的通道数,输入参数为位置编码的最大频率和编码类型
input_ch_views = 0
embeddirs_fn = None
if args.use_viewdirs: # 加入视角编码时需要对视角向量进行编码
embeddirs_fn, input_ch_views = get_embedder(args.multires_views, args.i_embed)
#output_ch = 5 if args.N_importance > 0 else 4 #! 输出通道数,原代码设置为5但也没有用到,这里直接删掉了
output_ch = 4 # RGB + 密度
skips = [4] # 跳跃连接的位置
# 创建粗糙的NeRF模型
model = NeRF(D=args.netdepth, W=args.netwidth,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars = list(model.parameters())# 需要优化的参数列表
model_fine = None
if args.N_importance > 0: # 创建精细的NeRF模型
model_fine = NeRF(D=args.netdepth_fine, W=args.netwidth_fine,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars += list(model_fine.parameters())
# 这里把粗细网络的前向传播函数都封装成一个函数,这个作者特别喜欢干这种事。本质上在需要的时候调用run_network也是可以的。
# 可能作者觉得这样显得简洁牛逼吧,但增加了不止一点点理解难度
network_query_fn = lambda inputs, viewdirs, network_fn : run_network(inputs, viewdirs, network_fn,
embed_fn=embed_fn,
embeddirs_fn=embeddirs_fn,
netchunk=args.netchunk)
# 创建优化器
optimizer = torch.optim.Adam(params=grad_vars, lr=args.lrate, betas=(0.9, 0.999))
start = 0
basedir = args.basedir # 基础目录
expname = args.expname # 实验名称
##########################
# 加载检查点的权重
if args.ft_path is not None and args.ft_path!='None':
ckpts = [args.ft_path]
else:
ckpts = [os.path.join(basedir, expname, f) for f in sorted(os.listdir(os.path.join(basedir, expname))) if 'tar' in f]
print('Found ckpts', ckpts)
if len(ckpts) > 0 and not args.no_reload:
ckpt_path = ckpts[-1]
print('Reloading from', ckpt_path)
ckpt = torch.load(ckpt_path)
start = ckpt['global_step']
optimizer.load_state_dict(ckpt['optimizer_state_dict'])
# Load model
model.load_state_dict(ckpt['network_fn_state_dict'])
if model_fine is not None:
model_fine.load_state_dict(ckpt['network_fine_state_dict'])
##########################
# 这个字典封装了渲染时需要用到的参数,再次说一下,这个作者特别喜欢干这种事,非常无语!
render_kwargs_train = {
'network_query_fn' : network_query_fn, # 前向传播函数
'perturb' : args.perturb, # 抖动设置
'N_importance' : args.N_importance, # 额外精细采样数量
'network_fine' : model_fine,# 精细网络
'N_samples' : args.N_samples,# 粗采样数量
'network_fn' : model,# 粗网络
'use_viewdirs' : args.use_viewdirs,# 是否使用视角编码
'white_bkgd' : args.white_bkgd,# 白色背景设置
'raw_noise_std' : args.raw_noise_std,# 噪声标准差
}
# NDC only good for LLFF-style forward facing data
# 这里根据数据集类型设置是否使用NDC坐标
if args.dataset_type != 'llff' or args.no_ndc:
print('Not ndc!')
render_kwargs_train['ndc'] = False # 不使用NDC坐标
render_kwargs_train['lindisp'] = args.lindisp # 是否在线性视差中采样
render_kwargs_test = {k : render_kwargs_train[k] for k in render_kwargs_train} # 测试时的渲染参数等于训练时的
render_kwargs_test['perturb'] = False # 测试时不进行抖动
render_kwargs_test['raw_noise_std'] = 0. # 测试时不加噪声
# 返回训练和测试时的渲染参数,训练起始步数,需要优化的参数列表,优化器
return render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer
# 主函数用于测试NeRF网络
if __name__ == "__main__":
model = NeRF(D=8, W=256, input_ch=63, input_ch_views=27, output_ch=4, skips=[4], use_viewdirs=True)
print(model)
x = torch.randn(1, 63 + 27) # 随机生成一个输入样本,假设位置编码后维度为63,视角编码后维度为27
output = model(x)
print(f"Output shape: {output.shape}") # 输出的形状应为 (1, 4)
# 使用onnx导出模型
torch.onnx.export(model, x, "nerf_model.onnx", input_names=['input'], output_names=['output'], opset_version=11)损失函数
NeRF使用的损失函数非常简单,就是将一根光线体渲染出来的颜色拿去和颜色的真值做差之后取平方。论文使用的公式如下:
L = ∑ r ∈ R ∥ C \^ c ( r ) − C ( r ) ∥ 2 2 + ∥ C \^ f ( r ) − C ( r ) ∥ 2 2 \mathcal { L } = \sum _ { \mathbf { r } \in \mathcal { R } } \left \\left\\\| \\hat { C } _ { c } ( \\mathbf { r } ) - C ( \\mathbf { r } ) \\right\\\| _ { 2 } \^ { 2 } + \\left\\\| \\hat { C } _ { f } ( \\mathbf { r } ) - C ( \\mathbf { r } ) \\right\\\| _ { 2 } \^ { 2 } \\right L=r∈R∑ C\^c(r)−C(r) 22+ C\^f(r)−C(r) 22
因为存在这粗分割网络,和细分割网络,因此论文把两个网络的颜色差值都做了计算。需要注意的是,因为精网络的输入数据是从粗网络的输出计算而来的,而粗网络理论上不应该受精网络结果的影响,因此论文在代码中阻断了精网络往粗网络进行反向传播的路径。
总结
OK,到此终于把NeRF论文涉及到的方方面面全部讲完啦,尽管因为参考的pytorch版本代码写的非常抽象以至于产生了有点恶心的感觉(不知道官方提供的tensorflow版本代码如何),但整体看下来还是非常愉悦的。看的时候非常感慨,居然可以通过这么简洁的技巧将CV与CG结合在一起。