在处理复杂的工程系统或随时间演变的物理过程时(例如能源系统的状态追踪或电力负荷预测),传统的"点预测"往往显得捉襟见肘。仅仅给出一个绝对的预测数值,无法量化未来可能存在的风险与波动。
为了突破这一局限,我们需要从"确定性预测"走向"概率性预测"。本文将深入探讨一种强大的混合时间序列分析框架------ARIMA-KDE 预测模型。该模型巧妙地结合了 ARIMA 捕捉线性时间依赖关系的能力,以及 KDE(核密度估计)非参数化刻画误差分布的优势,不仅能给出高精度的预测均值,还能构建出科学、可靠的预测区间。
一、 ARIMA:剥丝抽茧,捕捉时序的内在动力学
在模型的上半场,我们依赖经典的时间序列基石------差分自回归移动平均模型(Autoregressive Integrated Moving Average, ARIMA)。ARIMA 的核心哲学是:过去的模式会延展至未来。
1. 平稳性:预测的基石
时间序列预测的前提是数据具有某种"惯性"或规律。如果数据的均值和方差随时间剧烈漂移,模型将无从下手。因此,建模的第一步是进行平稳性检验。
理论上,我们通常采用双重检验策略:
- ADF 检验:致力于发现数据中是否存在单位根(即非平稳的趋势)。
- KPSS 检验:反向假设数据是平稳的,用于捕捉 ADF 可能遗漏的特定非平稳特征。
当原始序列不满足平稳性时,ARIMA 模型中的 III(差分操作)便发挥作用。通过计算相邻数据点之间的差值,我们强行滤除宏观趋势,将非平稳序列"驯化"为平稳序列。
2. 阶数寻优与均值预测
在平稳序列的基础上,模型通过 AIC(赤池信息准则)或 BIC(贝叶斯信息准则)在自回归阶数 ppp 和移动平均阶数 qqq 之间进行博弈。
- AR 部分 试图用历史真实值的线性组合来解释当前值。
- MA 部分 则利用历史预测误差的线性组合来修正当前预测。
最终,通过严密的参数估计,ARIMA 能够输出一个点预测值。但这只是故事的开始,因为任何模型都不可能做到百分之百准确,剩下的残差(训练误差)中隐藏着极其重要的不确定性信息。
二、 KDE:拥抱未知,构建数据驱动的概率边界
在许多传统研究中,人们习惯假设 ARIMA 的预测残差服从标准的正态(高斯)分布。然而,在实际的动态系统中,误差分布往往存在长尾效应或偏态特征。强制套用正态分布会导致预测区间过宽(浪费信息)或过窄(带来风险)。
这就引出了模型的下半场:核密度估计(Kernel Density Estimation, KDE)。
1. 非参数估计的魅力
KDE 是一种非参数方法,它不预设任何具体的数学分布形式 ,而是完全让残差数据"自己说话"。
可以将 KDE 想象为在每一个训练误差的数据点上放置一个平滑的"核函数"(通常为高斯核)。将这些核函数叠加并取平均后,就能得到一条极其贴合真实误差形态的概率密度曲线。
2. 预测区间的精准圈定
一旦获得了高度逼真的误差概率密度函数,我们就可以通过积分计算出累积分布函数(CDF)。
此时,构建预测区间的逻辑变得异常清晰:
- 如果我们需要一个 90% 的置信区间,只需在 CDF 曲线上找到概率为 5% 和 95% 所对应的误差分位数值。
- 将这两个误差分位数分别叠加到 ARIMA 预测的点数值上,便自然生成了该时刻的预测下界 与预测上界。
这种由 KDE 驱动的区间,能够敏锐地感知历史误差的非对称性,从而在波动剧烈的区域适当放宽边界,在平稳区域精准收拢。
三、 模型评估:在"可靠性"与"敏锐度"之间走钢丝
对于这种区间预测模型,传统的 RMSE 或 MAE 指标已无法全面衡量其优劣。我们需要引入国际公认的区间评价双雄:PICP 与 PINAW。
- PICP(区间覆盖率,Prediction Interval Coverage Probability)
这是衡量模型**可靠性(安全性)**的核心指标。它反映了真实观测值实际落在我们绘制的预测区间内的概率。如果设定了 90% 的置信水平,一个优秀的模型其 PICP 应该非常接近或略高于 0.9。 - PINAW(归一化平均宽度,Prediction Interval Normalized Average Width)
这是衡量模型**敏锐度(有效性)**的核心指标。如果为了追求 100% 的覆盖率而将区间放得无限大,这种预测在工程上是毫无意义的。PINAW 考察的是在保证 PICP 的前提下,区间到底有多"窄"。宽度越窄,不确定性越小,模型的决策指导价值就越高。
四、 部分代码
c
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 导入数据(时间序列的单列数据)
result = xlsread('data.xlsx');
%% 数据集分析
num_size = 0.7; % 训练集占数据集比例
num_samples = length(result); % 样本个数
num_train_s = round(num_size * num_samples); % 训练集样本个数
%% 参数设置
result_org1 = result(1 : num_train_s); % 划分的用于平稳性分析数据
result_org=result_org1 ;
p_train = result_org; % 用于选择阶数
M = length(result_org); % 训练集样本个数
N = num_samples - M; % 测试集样本个数五、运行截图
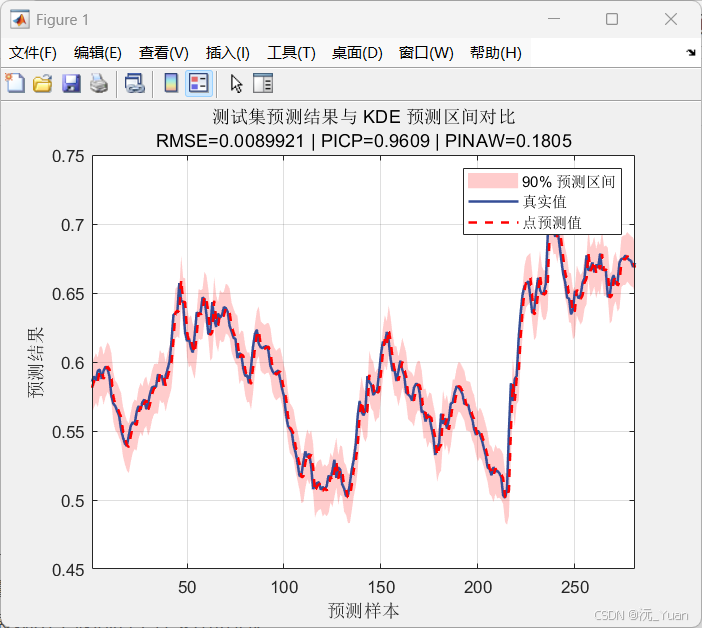
结语
ARIMA-KDE 混合模型展现了统计学与非参数方法的完美融合。ARIMA 负责挖掘时间序列的深度结构,提供精准的基准线;而 KDE 则负责丈量现实的复杂性,描绘出合理的容错边界。在面对需要严格风险控制与不确定性量化的技术场景时,这种模型展现出了极高的工程实用价值。