目录
[一、 架构总览:从线性走向螺旋](#一、 架构总览:从线性走向螺旋)
[二、 铺设底层逻辑:深度控制数组的构建](#二、 铺设底层逻辑:深度控制数组的构建)
[三、 核心引擎:迭代循环内的"思考与探索"](#三、 核心引擎:迭代循环内的“思考与探索”)
[意图拆解:引入蓝耘 GLM-5.1 的"大脑算力"](#意图拆解:引入蓝耘 GLM-5.1 的“大脑算力”)
[破壁检索:Tavily 的精准赋能与去噪](#破壁检索:Tavily 的精准赋能与去噪)
[四、 褪去繁杂:最终的沉淀与表达](#四、 褪去繁杂:最终的沉淀与表达)
[五、 成果呈现](#五、 成果呈现)
在智能财经分析领域,最忌讳的便是"浮于表面"。金融市场的运行逻辑从来不是简单的线性因果,而是由宏观政策、产业链博弈、企业基本面以及情绪面交织而成的复杂网络。面对突发的宏观动态(如美联储议息会议的超预期表态)或诡谲的个股异动(如财报前夕的放量暴跌),传统的分析方式往往显得捉襟见肘。
很多时候,我们依赖单次检索去寻找答案,但这充其量只能触达信息的冰山一角。普通的搜索引擎会返回大量同质化的快讯、充满噪音的股吧讨论或是晦涩的研报摘要。分析师若想实现"抽丝剥茧"式的深度调研,往往需要在几十个网页间来回切换,手动拼凑逻辑链条,这种低效的"人肉迭代"在瞬息万变的金融市场中是致命的。
为了打破这一困局,我们需要赋予系统自我驱动、层层递进的思考能力。本文将剥离冗杂的AI理论,直击实操核心------如何在 Dify 平台上,巧妙串联蓝耘 MaaS 的 GLM-5.1 模型与 Tavily 搜索引擎,构建一个具备"多轮迭代、深度溯源"能力的财经分析智能体。
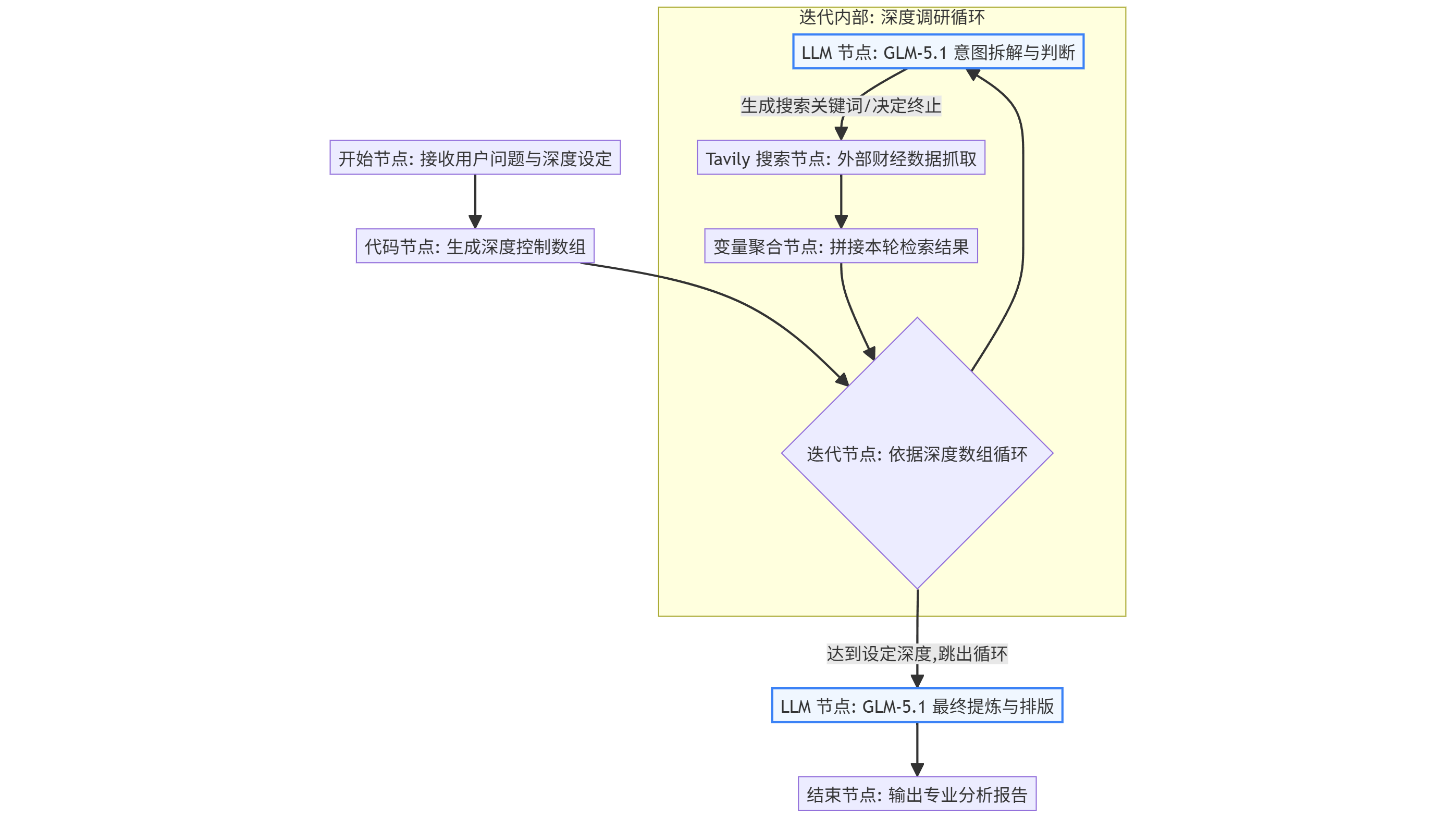
一、 架构总览:从线性走向螺旋
在动手配置之前,我们必须先完成思维方式的转换,俯瞰整个工作流的拓扑结构。
传统的 AI 分析工作流往往遵循"用户输入 - LLM 提取关键词 - 搜索引擎检索 - LLM 总结输出"的直线逻辑。这种架构致命的缺陷在于"一锤子买卖":如果第一次搜索没有命中核心数据,或者被表面的新闻标题误导,最终的输出必然是平庸甚至错误的。
本架构的核心颠覆在于引入了一个"迭代循环"。它如同一个不断向下钻取的地质钻头,每一次旋转都带着上一层的反馈,直到获取足够深度的信息才罢休。这种从"线性处理"走向"螺旋深挖"的范式转移,正是让 AI 从"信息整合工具"蜕变为"独立分析师"的关键。
二、 铺设底层逻辑:深度控制数组的构建
任何具备自主探索能力的系统,都必须配备一套"刹车机制"。如果让 AI 无休止地搜索下去,不仅会迅速耗尽 API 额度与 Token 预算,还会导致后期信息严重冗余,甚至使大模型产生"幻觉"。
工作流由默认的"开始"节点启航。我们在开始节点预设一个名为 depth(深度)的变量,默认值设为 3。随后,直接接入一个 Python 代码节点。
这段简短的 Python 脚本,看似简单,却是整个迭代机制的"发令枪"和"控制器":
def main(depth: int) -> dict:
depth = depth or 3
array = list(range(depth))
return {
"array": array,
"depth": depth
}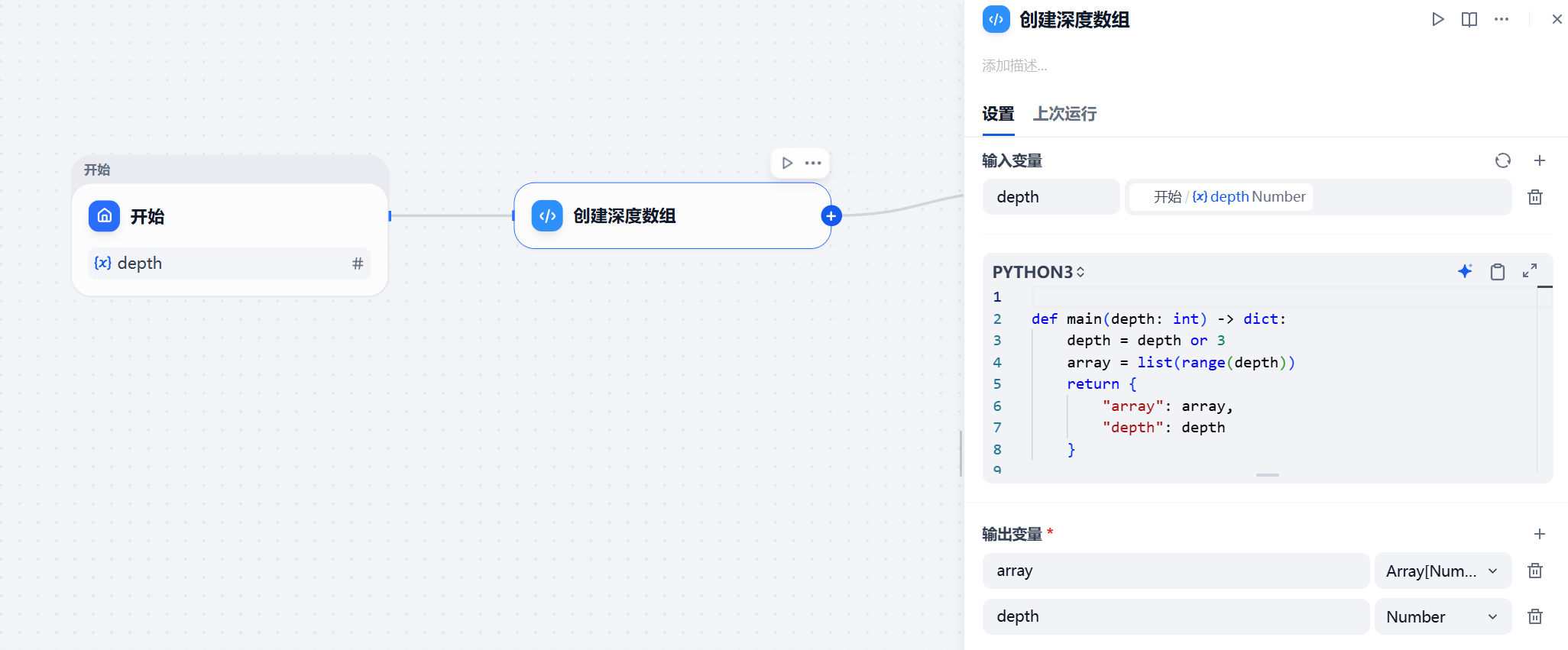
在这段代码中,我们首先做了一个容错处理(depth = depth or 3),即使用户没有输入深度值,系统也会默认执行 3 轮探索。最精妙之处在于 list(range(depth)) 这一句。Dify 的迭代节点需要一个数组作为驱动力,代码将一个抽象的数字(如 3)转化为了具体的列表 [0, 1, 2]。代码的输出直接对接 Dify 迭代节点的输入项 array,为后续的"步步紧逼"提供了清晰、可控的路径指引。
三、 核心引擎:迭代循环内的"思考与探索"
这是整个工作流的灵魂所在。在迭代节点内部,我们摒弃了直接搜索的做法,而是构建了一个微型的"思考-行动-观察"循环,完美契合了 Agent 的核心哲学。
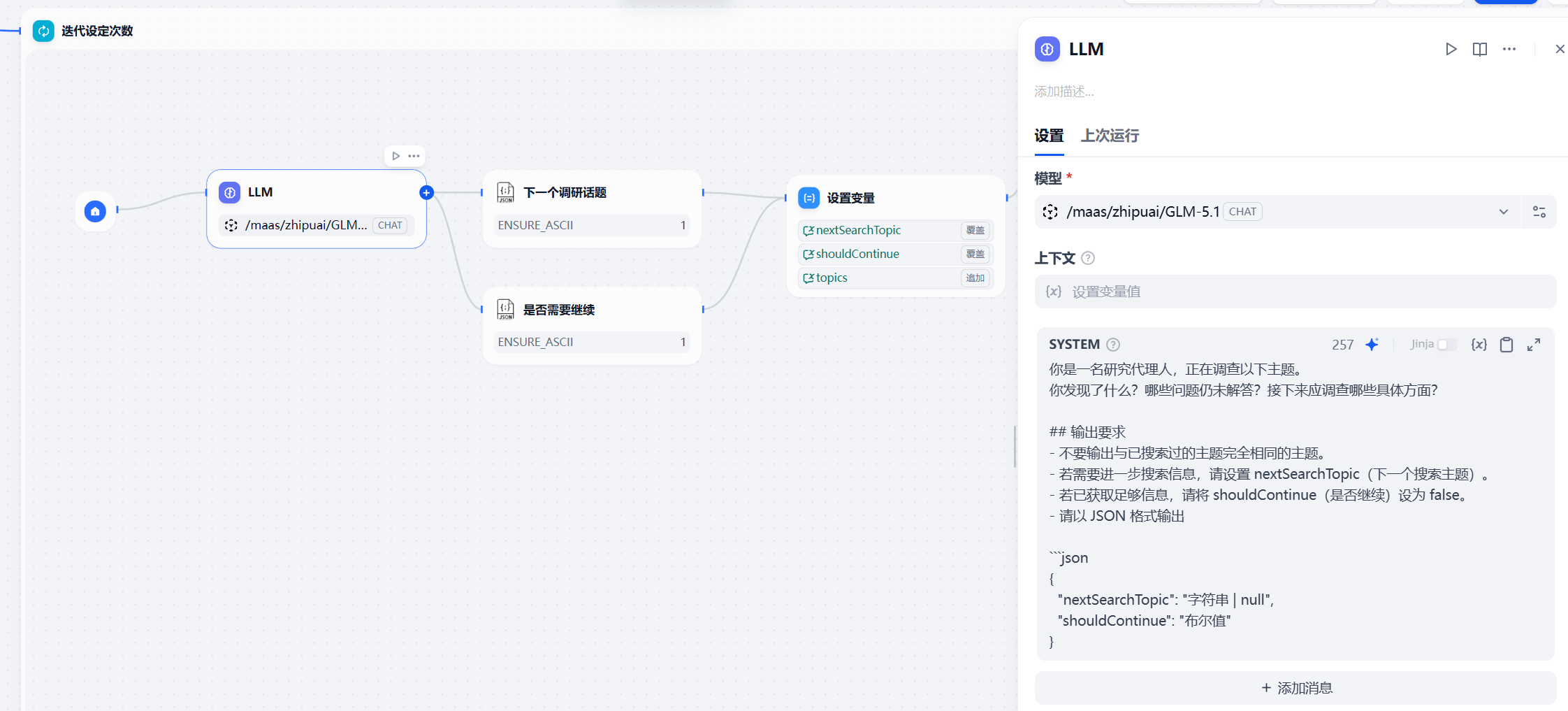
意图拆解:引入蓝耘 GLM-5.1 的"大脑算力"
当用户提出诸如"分析某新能源车企近期的供应链风险"这样宏大的命题时,第一步绝不是直接去搜,而是需要大模型进行"降维拆解"。
我们在 Dify 的模型供应商中,选择 OpenAI-API-compatible 接口,接入蓝耘 MaaS 平台 最新上线的 GLM-5.1 模型 。为什么选择 GLM-5.1?在金融场景下,模型的逻辑严密性和指令遵循能力至关重要。GLM-5.1 在长文本推理和复杂任务拆解上表现出了卓越的稳定性。
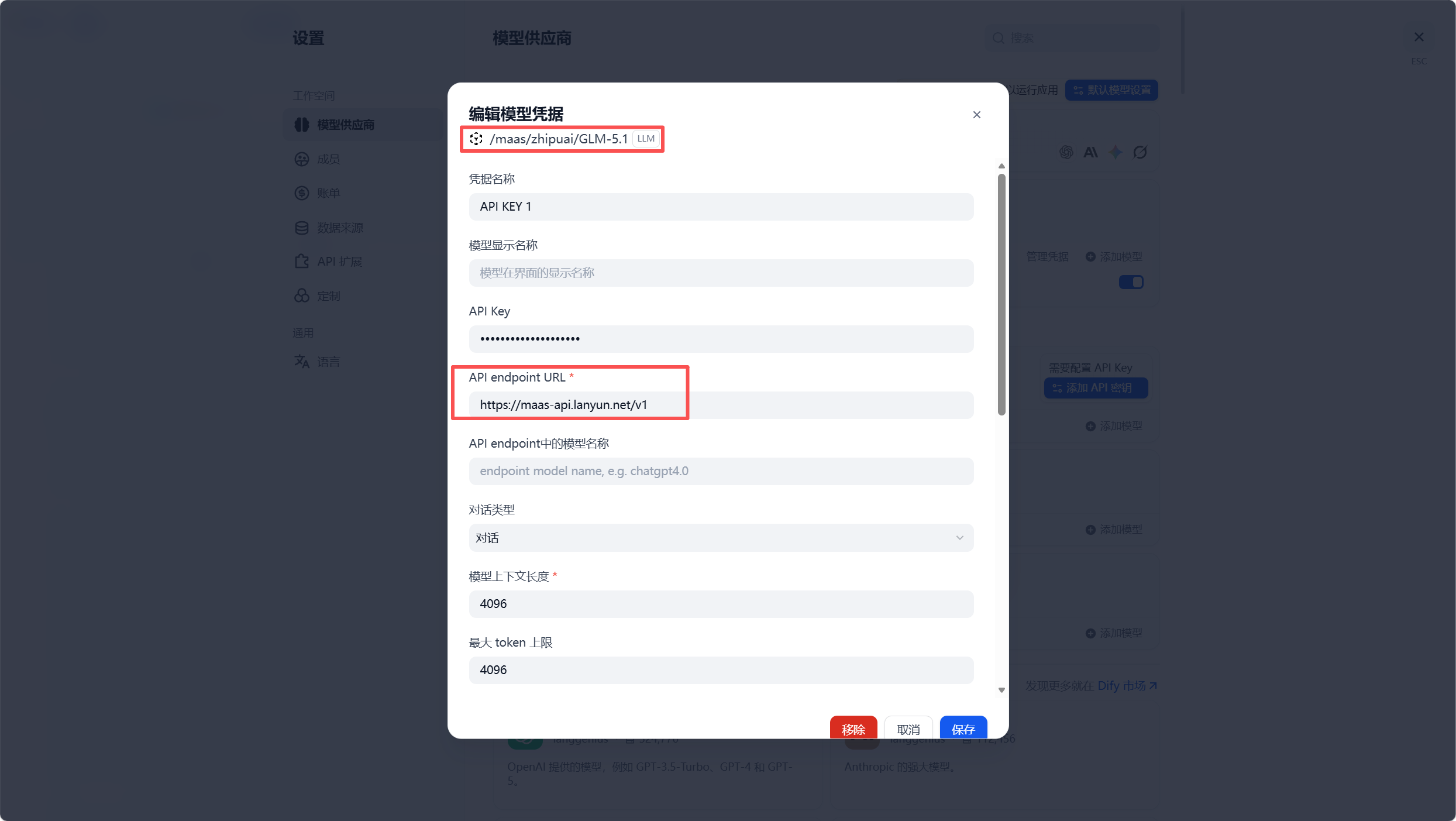
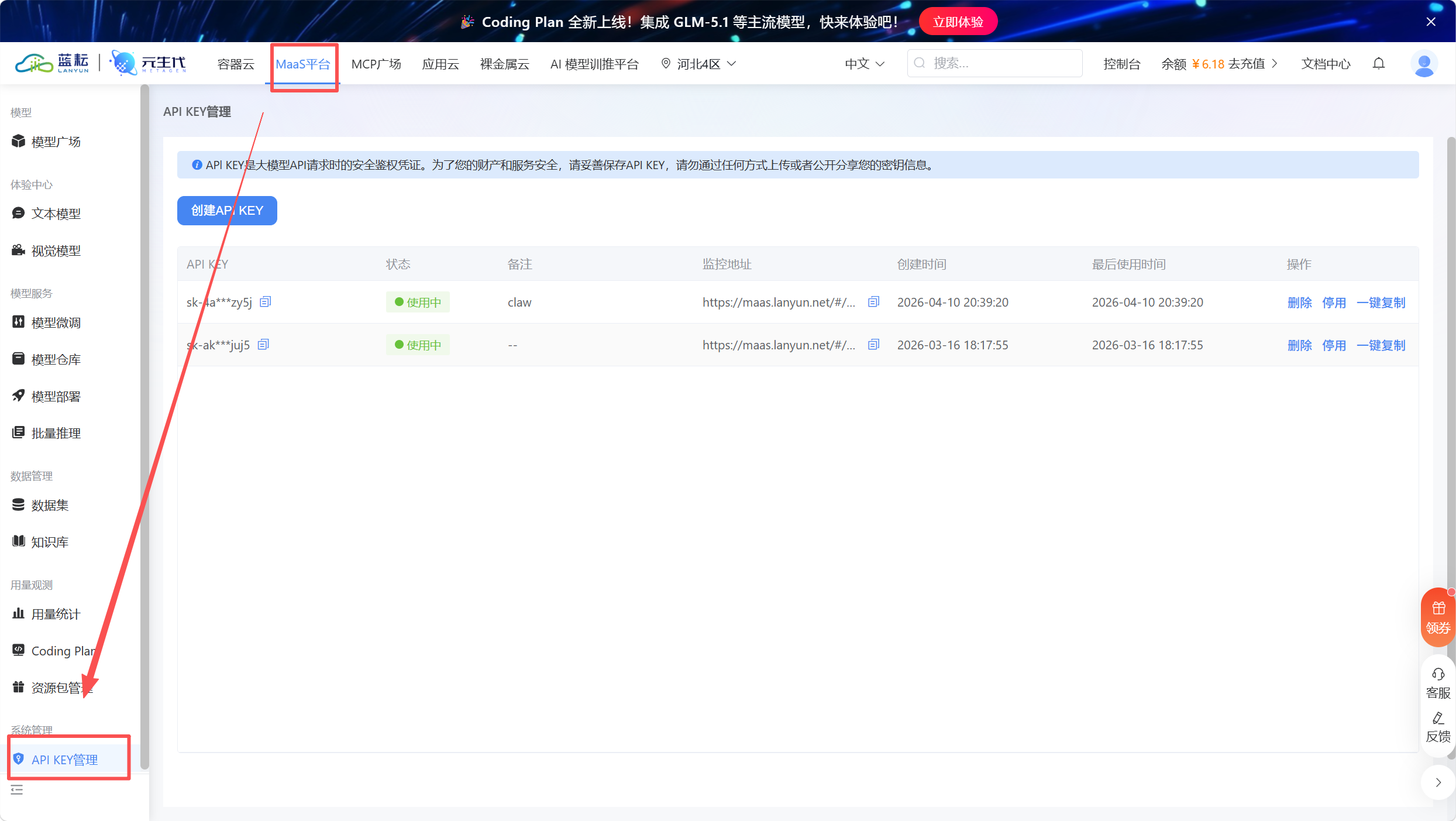
获取配置非常简单:直接进入蓝耘 MaaS 平台,随后点击控制台最下方的"API KEY 管理"即可一键生成并复制密钥,填入 Dify 的 API Key 配置项中。
破壁检索:Tavily 的精准赋能与去噪
有了 GLM-5.1 给出的精准"狙击坐标",接下来交由 Tavily 搜索引擎去执行扣动扳机的动作。
作为专为 AI Agent 设计的搜索引擎,Tavily 与传统搜索有着本质区别。登录 Tavily 官网注册即可获取 Key。在 Dify 的 HTTP 请求节点或直接使用 Tavily 插件时,我们可以设定参数,强制要求它只返回高信噪比的网页内容。
在金融领域,这一点堪称救命。普通的搜索结果中充斥着各种标题党和解盘师的废话,而 Tavily 能够有效过滤掉财经论坛里的噪音水贴,直接抓取研报原文、交易所公告或权威财经媒体的深度报道的核心段落。它返回的不是一堆链接,而是已经初步清洗过的结构化数据,这对于金融分析的数据清洁度至关重要。
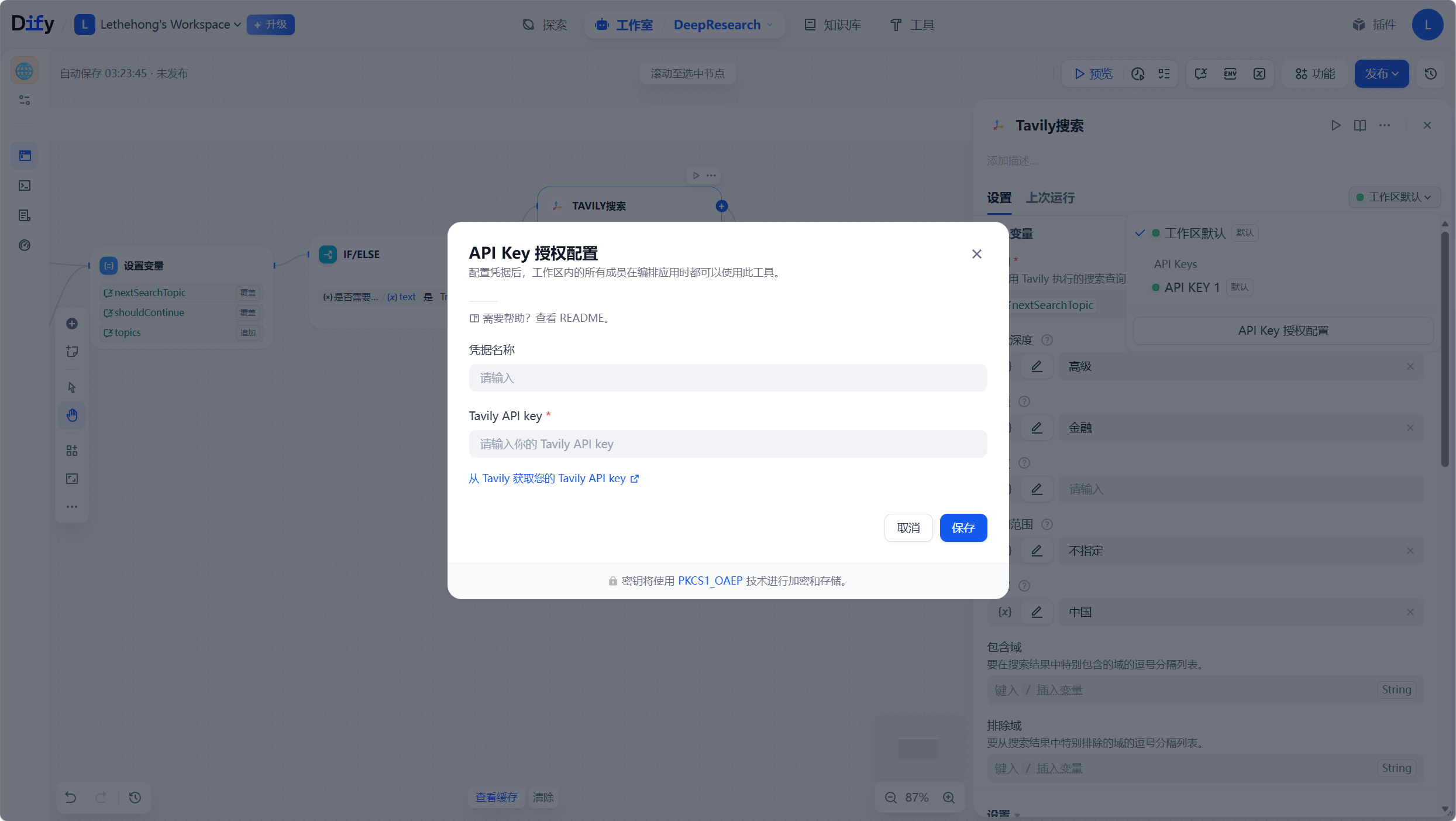
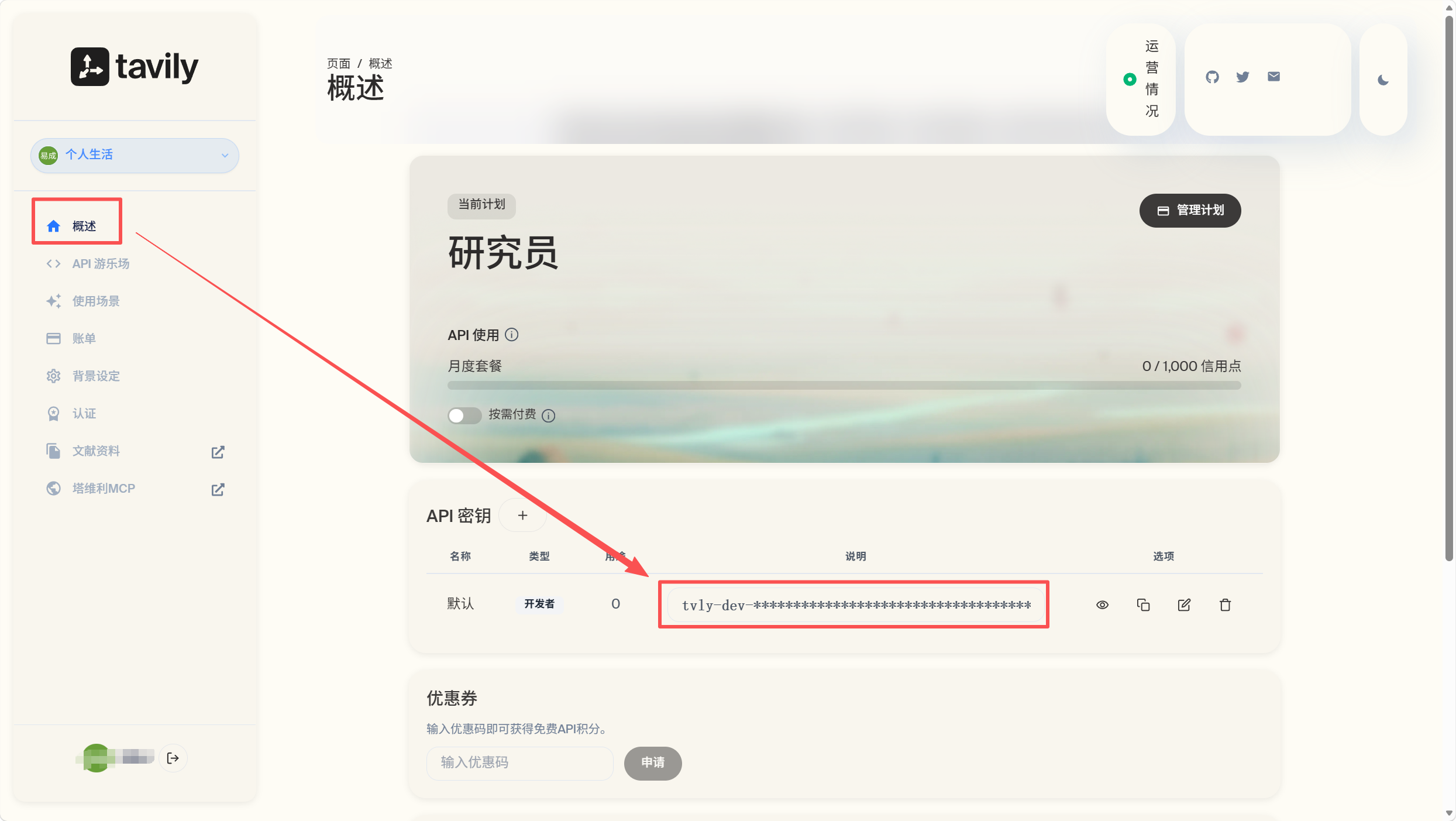
我们登录进来之后就可以直接看到key,复制填入上图的API key处即可
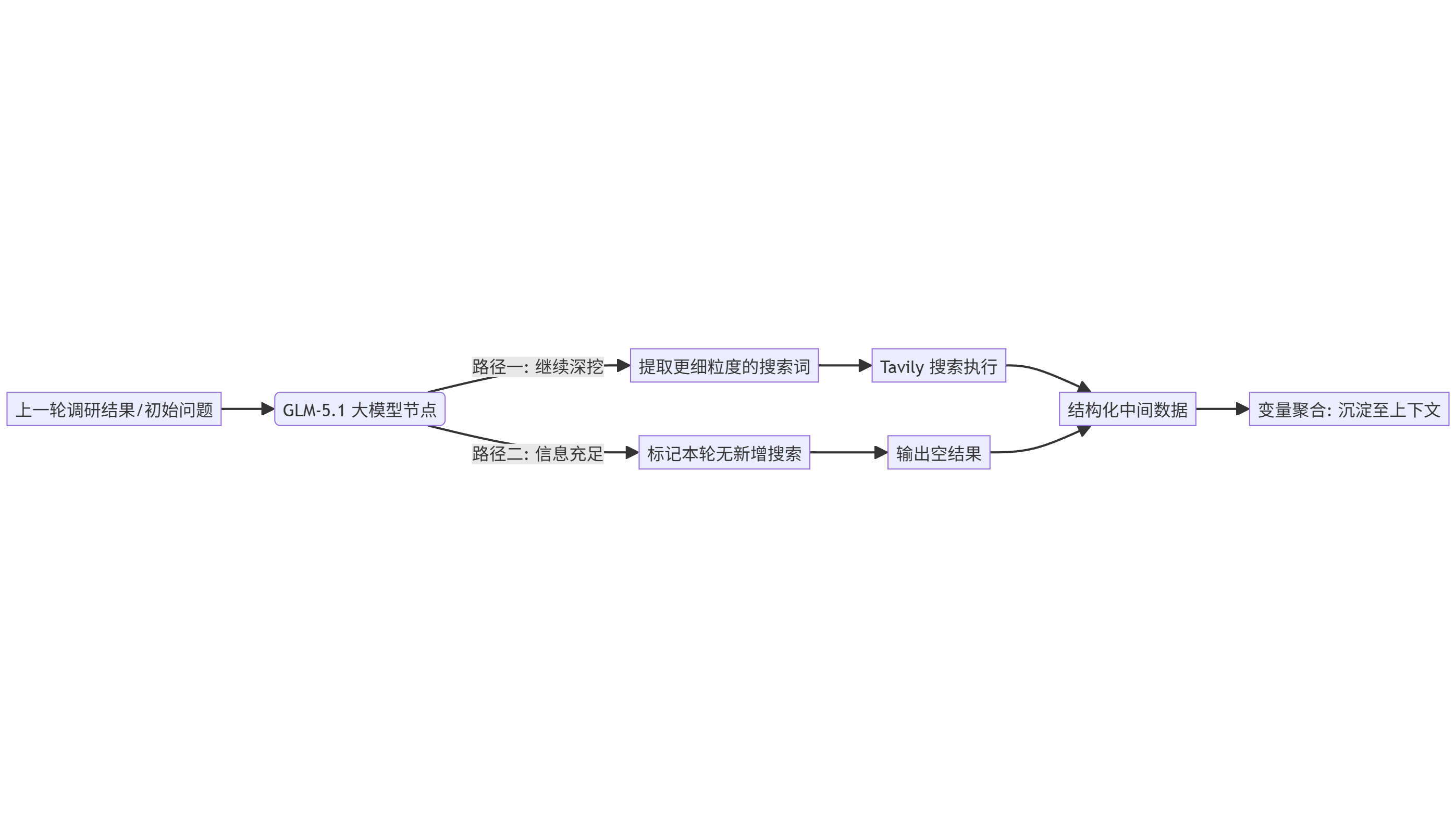
记忆拼图:变量聚合与上下文传承
在多轮迭代中,单次搜索的结果是碎片化的,如果彼此孤立,就失去了迭代的意义。我们需要一个"变量聚合"节点,将本轮 Tavily 返回的内容,与之前累积的中间格式结果进行拼接。
这就像是在不断完善一张调查草图的各个角落。第一轮我们知道了电池供应商可能出问题,第二轮聚合时,上下文中就包含了这一线索。此时,迭代再次回到 GLM-5.1 面前,模型看到新线索后,会进一步推理:"既然电池供应商产能不足,那么是否因为上游碳酸锂价格异动?或者该车企是否有替代供应商的预案?"于是,第三轮搜索指令应运而生,实现了真正的"顺藤摸瓜"。
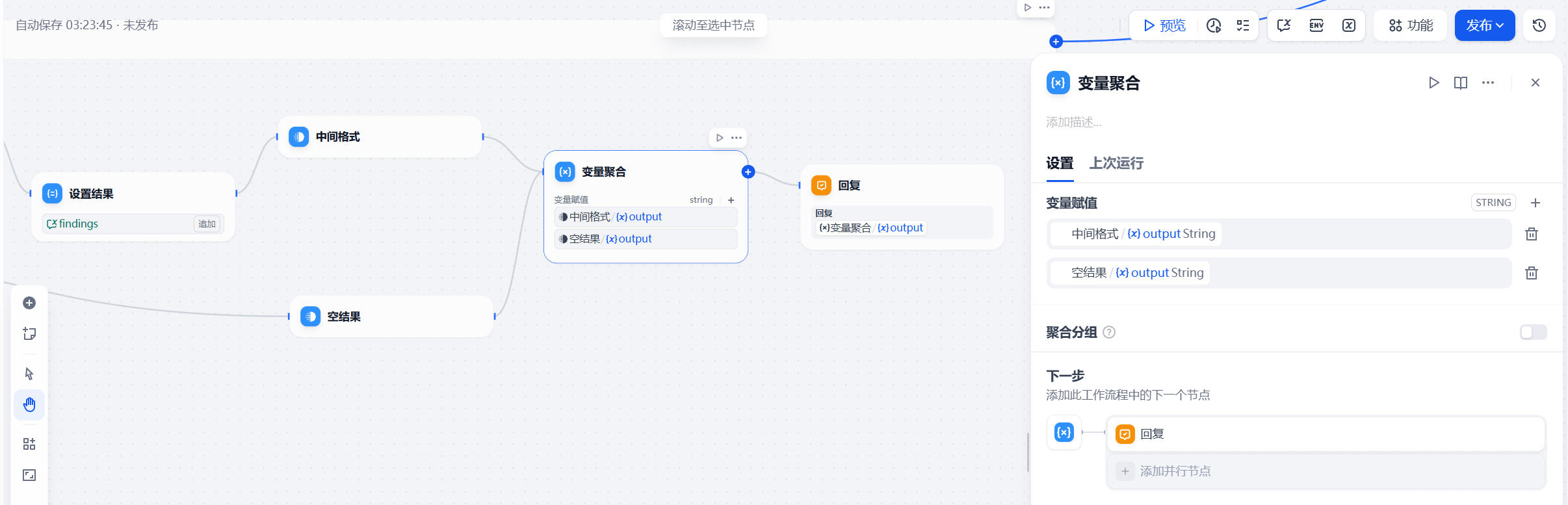
最后就是有了回复节点,那就要跳过迭代设定次数节点了,然后由LLM节点整理前面获取到的相关内容,最终回复结果
四、 褪去繁杂:最终的沉淀与表达
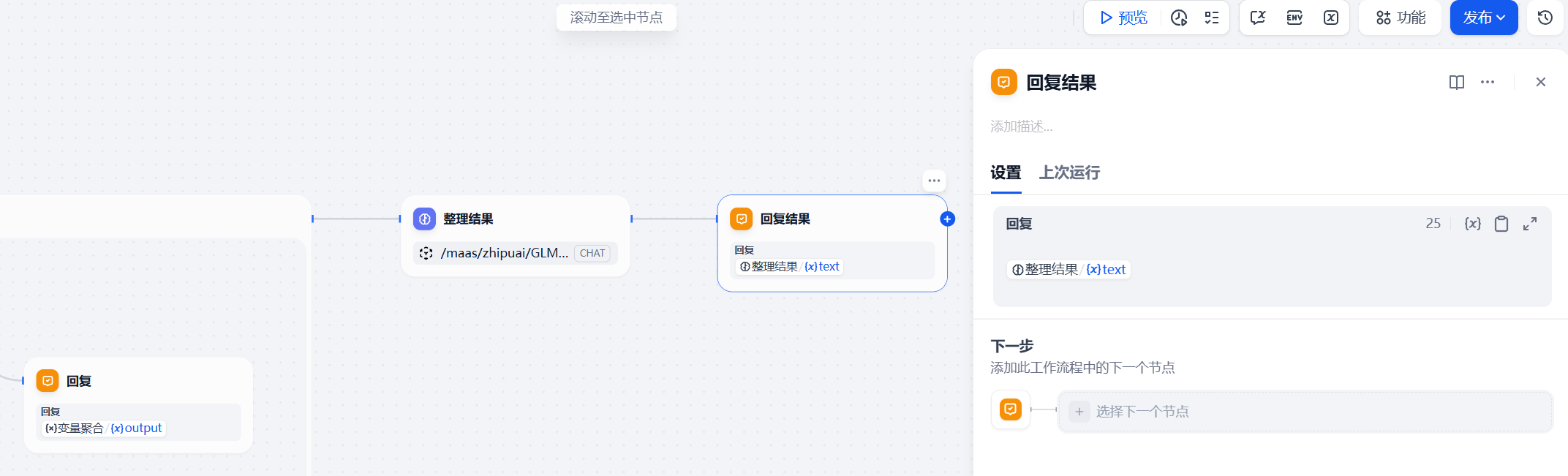
当迭代次数耗尽(达到 depth 设定的 3 次循环),工作流将跳过迭代节点,来到最后的收官阶段。
此时,系统面前摆着的是一份包含了多轮溯源、层层递进的原始素材库(可能高达数千字)。这些素材虽然详实、溯源清晰,但存在大量重复表述、口语化痕迹,且缺乏整体的行文结构。如果直接扔给用户,依然是一场灾难。
因此,我们需要再次唤醒蓝耘 GLM-5.1。在这个终极 LLM 节点中,系统指令发生了质的转变,从"敏锐的猎手"化身为"严谨的主笔分析师"。我们设定如下规则:
- 角色定位:顶尖券商首席分析师。
- 处理机制:彻底剔除前面素材中的重复项和无价值信息。
- 逻辑重构:按照"表象异动 -> 核心矛盾拆解 -> 微观数据交叉验证 -> 潜在风险与应对"的投研框架重新组织语言。
- 溯源要求:在关键论据处,必须保留 Tavily 返回的原始来源链接,以供人工复核。
经过这一步的"蒸馏",庞杂的底层数据被提炼成了高纯度的洞察。
五、 成果呈现
经过这套精密机制的运转,最终呈现给用户的不再是干瘪的几段通稿式摘要,而是一份具备"研究过程"的专业级报告。
在这份报告中,你可以清晰地看到逻辑链条是如何闭合的:从宏观层面的关税政策微调线索发现,到中观层面的特定零部件进口依赖度数据抓取,再到微观层面该车企资产负债表中隐匿的存货跌价准备交叉验证,每一个结论都有据可查,每一个链接都指向最源头的信源。



这种结合了蓝耘 GLM-5.1 的"大脑算力"、Tavily 的"触角感知"以及 Dify 的"流程调度"的架构,真正让财经分析从被动的"信息检索"跃升为了主动的"知识推理"。未来,在此基础上进一步叠加财报数据库的 API 接口以及企业知识图谱,我们完全有理由相信,个人投资者也将拥有一支堪比华尔街顶级投行团队的 AI 外脑。