摘要 :开发面向遥感场景的目标检测系统对于提升国土调查、灾害应急、交通巡检与军事侦察等任务的自动化水平具有重要意义。本文围绕"YOLOv5 至 YOLOv12 升级:遥感目标检测系统的设计与实现"这一主题,系统梳理了 YOLO 系列从 v5 到 v12 在 主干特征提取、颈部多尺度融合、检测头设计、标签分配与损失建模、推理与部署效率 等方面的关键演进脉络,并在同一遥感数据集与一致训练策略下完成多模型对比评测,为工程选型提供可复现实证依据。面向遥感影像目标 尺度跨度大、密集分布、背景复杂、长宽比与方向变化显著 等挑战,本文构建了包含采集、清洗、标注、划分与增强的专用数据集流程,并给出可直接复用的训练与推理脚本、配置文件与权重管理方案。在系统实现层面,项目基于 Python 3.12 与 PySide6(Qt 信号-槽机制) 构建跨输入源的图形化检测平台,支持图片/文件夹/视频/摄像头接入,实现实时检测结果可视化、置信度与 IoU 可调、类别统计与筛选、结果保存与批量导出等功能;同时引入 SQLite 完成注册登录、用户配置持久化与历史结果管理,形成从模型到应用的闭环工程。本文最终提供 完整代码、可运行界面工程、数据集组织与复现说明,并在实验与系统展示中给出典型遥感场景的检测效果分析,为读者搭建可扩展的 YOLO 家族遥感目标检测项目提供一套可落地的实现范式。
文章目录
- [1. 前言综述](#1. 前言综述)
- [2. 数据集介绍](#2. 数据集介绍)
- [3. 模型设计与实现](#3. 模型设计与实现)
- [4. 训练策略与模型优化](#4. 训练策略与模型优化)
- [5. 实验与结果分析](#5. 实验与结果分析)
-
- [5.1 实验设置与对比基线](#5.1 实验设置与对比基线)
- [5.2 度量指标与阈值选择](#5.2 度量指标与阈值选择)
- [5.3 实验结果对比与可视化分析](#5.3 实验结果对比与可视化分析)
- [6. 系统设计与实现](#6. 系统设计与实现)
-
- [6.1 系统设计思路](#6.1 系统设计思路)
- [6.2 登录与账户管理](#6.2 登录与账户管理)
- [7. 下载链接](#7. 下载链接)
- [8. 参考文献(GB/T 7714)](#8. 参考文献(GB/T 7714))
1. 前言综述
高分辨率光学遥感影像具备覆盖范围广、更新频率高与几何细节丰富等特性,使其在交通要素普查、灾害应急评估、海事监管与国土资源监测等场景中逐步从"离线判读"走向"在线智能解译",而目标检测作为其中最核心的底层能力之一,直接决定了后续变化检测、风险预警与决策支持的可靠性与时效性1。与此同时,遥感影像与自然场景在成像视角、背景纹理、目标尺度分布与跨地区域泛化等方面存在显著差异,导致许多在通用视觉数据集上表现优异的检测器在遥感域出现定位偏移、漏检与误检叠加的性能退化,而这一现象在系统化综述与基准化评测中被反复验证2。(ScienceDirect)
表 1 典型遥感目标检测范式与代表方法概览
| 范式/方向 | 代表方法(核心机制) | 常用遥感数据集(示例) | 优势(面向遥感) | 局限与工程代价 |
|---|---|---|---|---|
| 两阶段水平框检测 | Faster R-CNN(RPN+RoI 分类回归)5 | DIOR、NWPU VHR-10、HRSC2016 | 候选框机制利于复杂背景下的召回与稳健分类 | 对小目标与旋转目标需额外设计;端到端时延与显存开销较大 |
| 多尺度特征融合 | FPN(自顶向下金字塔+横向连接)6 | DOTA、FAIR1M(常作为骨干/颈部模块) | 缓解遥感小目标占比高导致的尺度失配问题 | 金字塔层级与算子堆叠会增加部署复杂度与推理开销 |
| 两阶段定向框检测 | RoI Transformer(HRoI→RRoI 学习与旋转对齐)7 | DOTA、HRSC2016 | 通过旋转对齐降低"水平候选框---旋转目标"失配 | 训练与标注需 OBB 支持;实现链路更复杂 |
| 小目标/密集旋转增强 | SCRDet(采样融合+注意力抑噪+旋转回归)8 | DOTA、NWPU VHR-10 | 面向密集小目标的特征增强与噪声抑制更有针对性 | 结构更重、调参空间更大;复现实验依赖细致实现细节 |
| Transformer 集合预测 | DETR(集合匹配损失+编码解码器)9 | 迁移到遥感需大规模预训练/领域适配 | 去除锚框与 NMS 的设计负担,建模更统一 | 对数据规模与预训练依赖强,直接迁移到遥感域往往不稳定 |
研究社区为缓解"数据与评测缺位"长期瓶颈,构建了多类遥感检测数据集与任务范式,其中 DOTA 以大幅面航拍/卫星影像为载体并强调旋转目标的定向框标注,为密集排列与任意朝向的目标检测提供了标准化比较平台3。面向更细粒度类别判别与更大规模实例统计,FAIR1M 进一步引入百万级实例规模与分层类别体系,并以定向框为主标注形式,推动算法从"能检出"迈向"能分清"与"可泛化"4。(CVF Open Access)
在检测算法演进路径上,两阶段范式通过候选区域生成与精细分类回归的解耦设计奠定了高精度检测的基础,其中 Faster R-CNN 以端到端的区域建议网络替代传统候选框算法,成为后续多种遥感检测改造工作的经典基线5。针对遥感目标普遍存在的尺度跨度大与小目标占比高等特点,多尺度特征表达成为结构设计的关键,FPN 以自顶向下与横向连接的特征金字塔方式显著改善了跨尺度语义对齐能力6。在此基础上,PANet 通过自底向上的路径增强进一步缩短不同层级特征的信息传播距离,使得定位细节与高层语义在融合过程中更易保留7。
与两阶段范式并行发展的实时检测路线强调速度、参数规模与部署友好性,CSPNet 通过跨阶段部分连接的思想降低冗余梯度信息与计算开销,为后续多代 YOLO 系列的轻量化骨干与高效特征流动提供了重要结构来源8。YOLO 将检测建模为单次前向中的回归问题,以统一网络同时输出边界框与类别概率,开启了高帧率实时检测的主流范式9。在工程化落地需求持续抬升的背景下,YOLOv7 系统化整理并引入"可训练的免费技巧"以提升训练效率与推理精度,在实时检测的速度---精度边界上形成具有代表性的里程碑10。(CVF Open Access)
进入近两年,YOLO 系列在结构可编程、梯度路径调控与训练目标设计等方面继续推进,其中 YOLOv9 以"可编程梯度信息"讨论检测器训练信号的可控性,为提升多尺度模型在不同算力约束下的稳定收益提供了新的方法学视角11。进一步地,YOLOv10 面向端到端部署的实际约束,围绕去除后处理瓶颈与整体效率审视提出 NMS-free 训练与更一致的分配策略,将实时检测在低延迟场景中的可用性作为核心优化目标之一12。(Springer)
然而,遥感场景仍具有若干"结构性困难":目标呈现任意方向、长宽比极端、密集遮挡与背景干扰强,使得水平框假设与常规锚框设计易引入匹配错位与冗余候选,从而放大分类与定位的不一致性。针对方向敏感问题,RoI Transformer 通过将水平 RoI 学习式变换为旋转 RoI 并进行旋转对齐特征提取,在不显著增加锚框枚举复杂度的前提下提升了定向框检测的几何一致性13。面向小目标、密集排列与旋转共存的更苛刻条件,SCRDet 引入多层特征采样融合与注意力抑噪机制,尝试在复杂背景中提升小目标可分性并缓解密集场景下的互相抑制14。与此同时,端到端集合预测范式以 DETR 为代表,通过集合匹配替代传统密集候选与 NMS 后处理,为"端到端、少后处理"的检测框架提供了另一条可与遥感任务需求对齐的技术路径15。(CVF Open Access)
基于上述背景,老思在本文所对应的项目中将目标聚焦于"YOLOv5 至 YOLOv12 的工程化升级链路"在遥感目标检测任务中的可复现落地:一方面围绕同一任务与同一数据规范,系统对比多代 YOLO 权重在精度、速度与资源占用上的差异,并给出可直接运行的训练、推理与评估脚本;另一方面构建并标注面向目标域的专用数据集,形成可复用的数据划分、增强与预处理流程;同时以 PySide6 设计可交互的遥感检测桌面端界面,支持图片/视频/摄像头等多源输入、模型热切换与结果导出,并提供完整代码与资源包以便复现实验与二次开发。
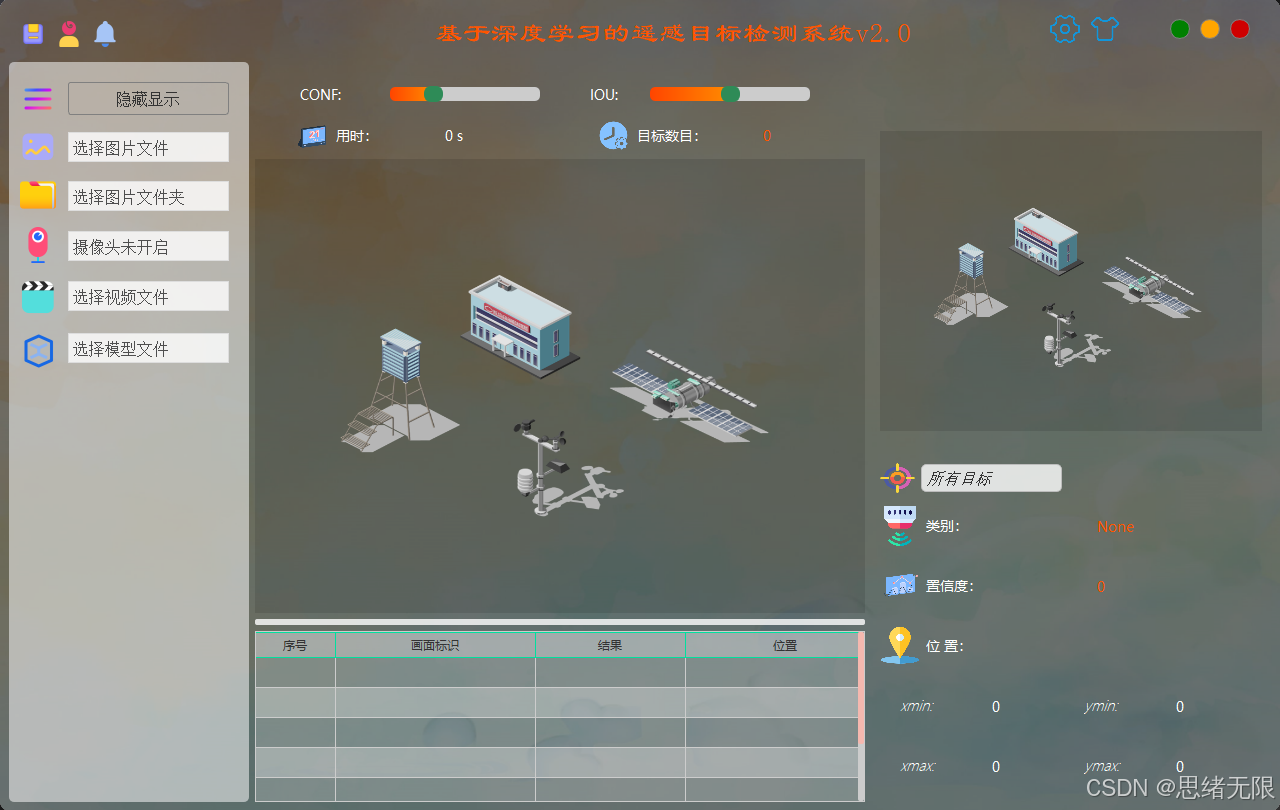
主要功能演示:
(1)启动与登录:系统启动后首先进入登录界面,完成账号注册/登录校验后加载该用户的历史检测记录与个性化配置(例如默认模型、Conf/IoU、主题样式等),再进入主检测界面;登录态支持注销与切换账号,确保不同用户的结果与偏好在 SQLite 中隔离存储并可追溯。(启动与登录界面图)
(2)多源输入与实时检测:主界面提供四类输入源:摄像头实时流、视频文件、单张图片与图片文件夹批处理。摄像头/视频模式下按帧推理并在界面中实时叠加检测框、类别与置信度,同时同步输出当前帧目标计数;图片/文件夹模式下支持一键推理与批量保存,便于离线评测与结果归档。(多源输入与实时检测演示图)
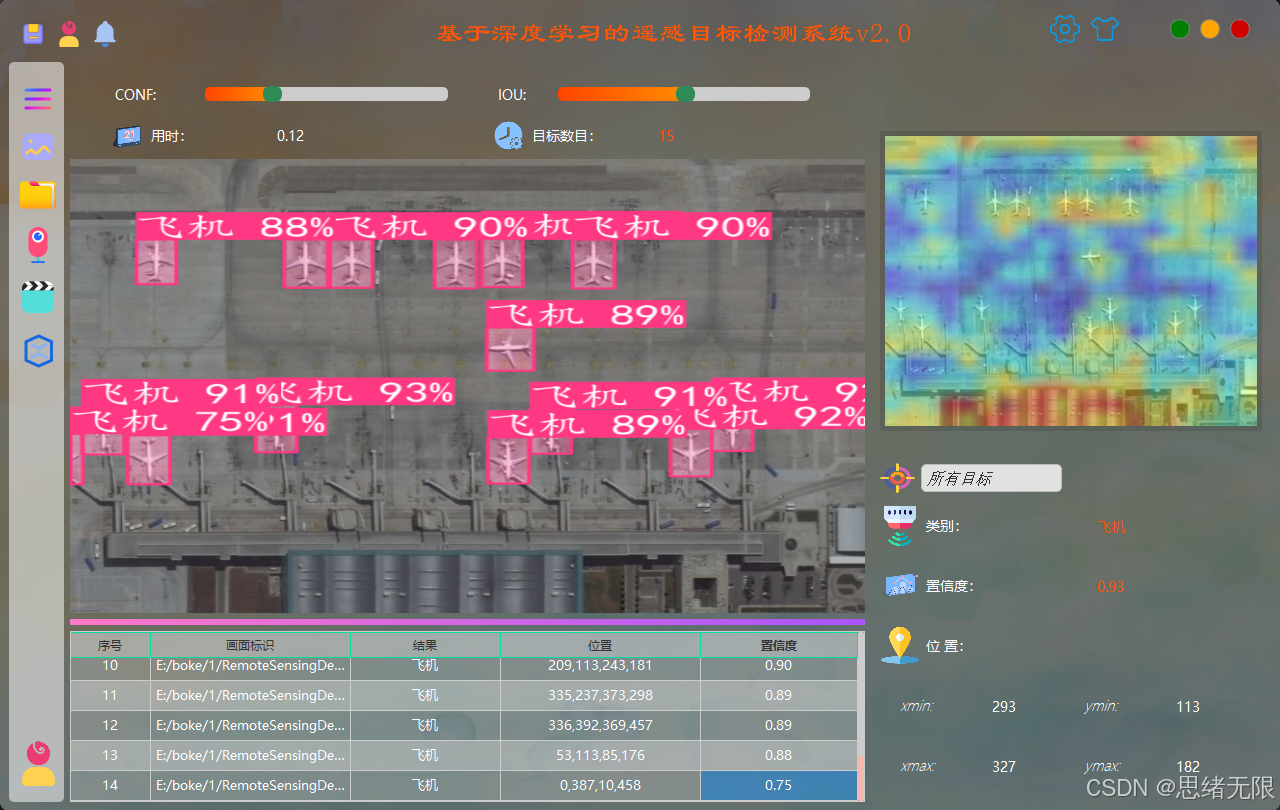
(3)模型选择与对比演示:系统内置 YOLOv5--YOLOv12 多版本权重管理与热切换机制,用户可在下拉框中选择不同模型对同一输入源进行推理,界面同步展示推理耗时、检测数量与置信度分布等信息;在对比模式下,可对同一帧/同一图像切换模型快速观察漏检、误检与定位差异,用于工程选型与误差分析。(模型选择与对比演示图)
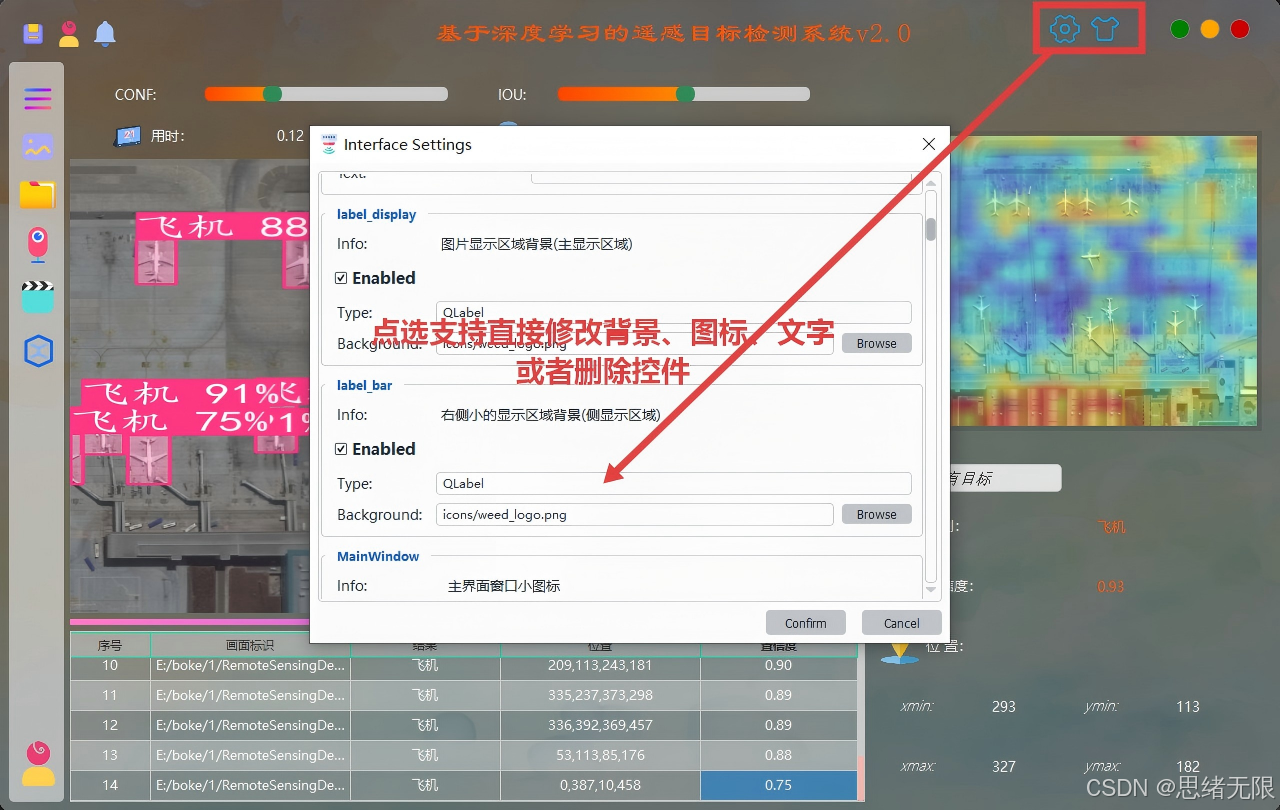
(4)主题修改功能:界面提供主题切换入口,支持亮色/暗色与自定义强调色等样式调整,核心通过 Qt 样式表(QSS)对按钮、表格、标签、图标与背景进行统一渲染;主题修改可即时生效,并写入数据库作为该用户的默认 UI 配置,保证下次启动无需重复设置。(主题修改效果图)
2. 数据集介绍
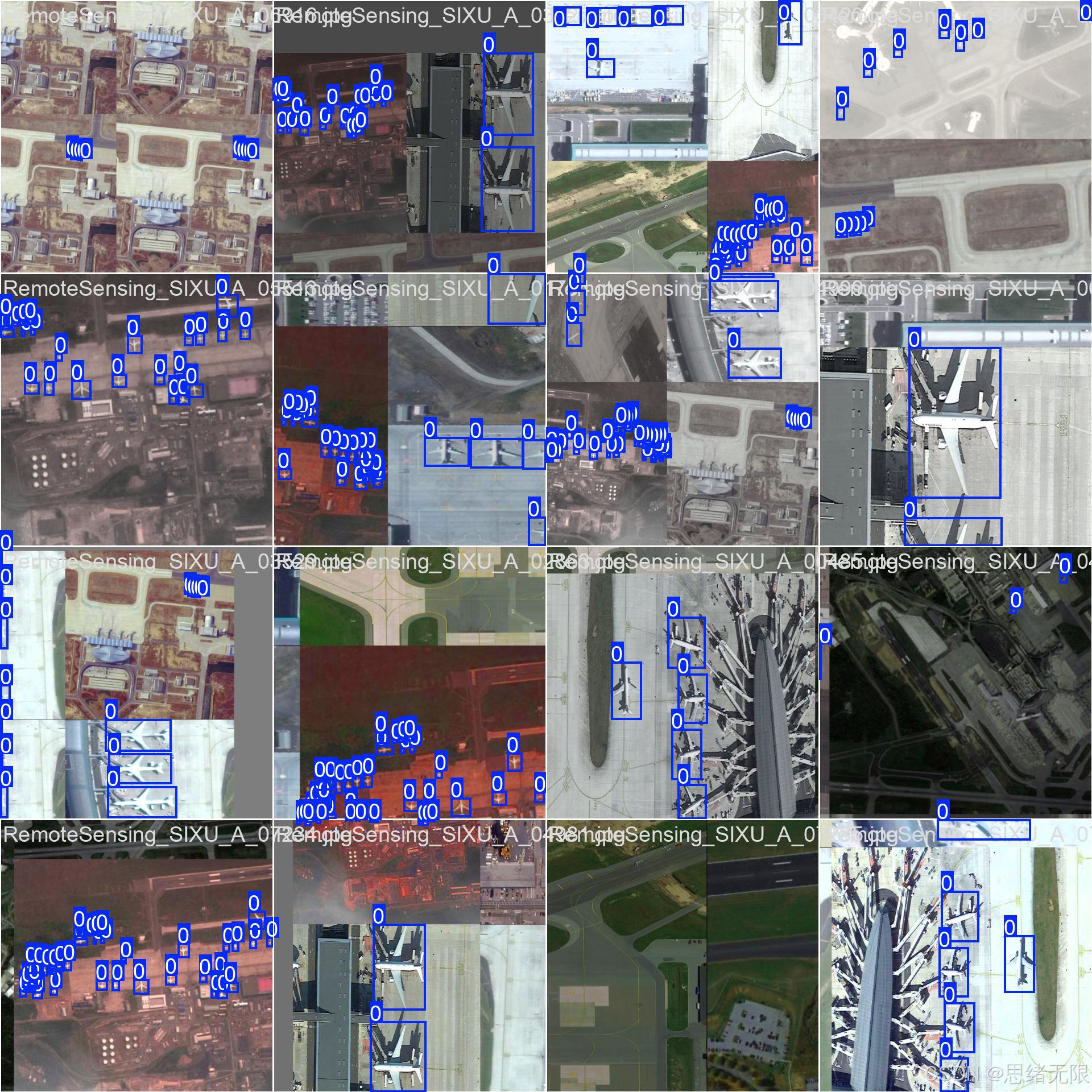
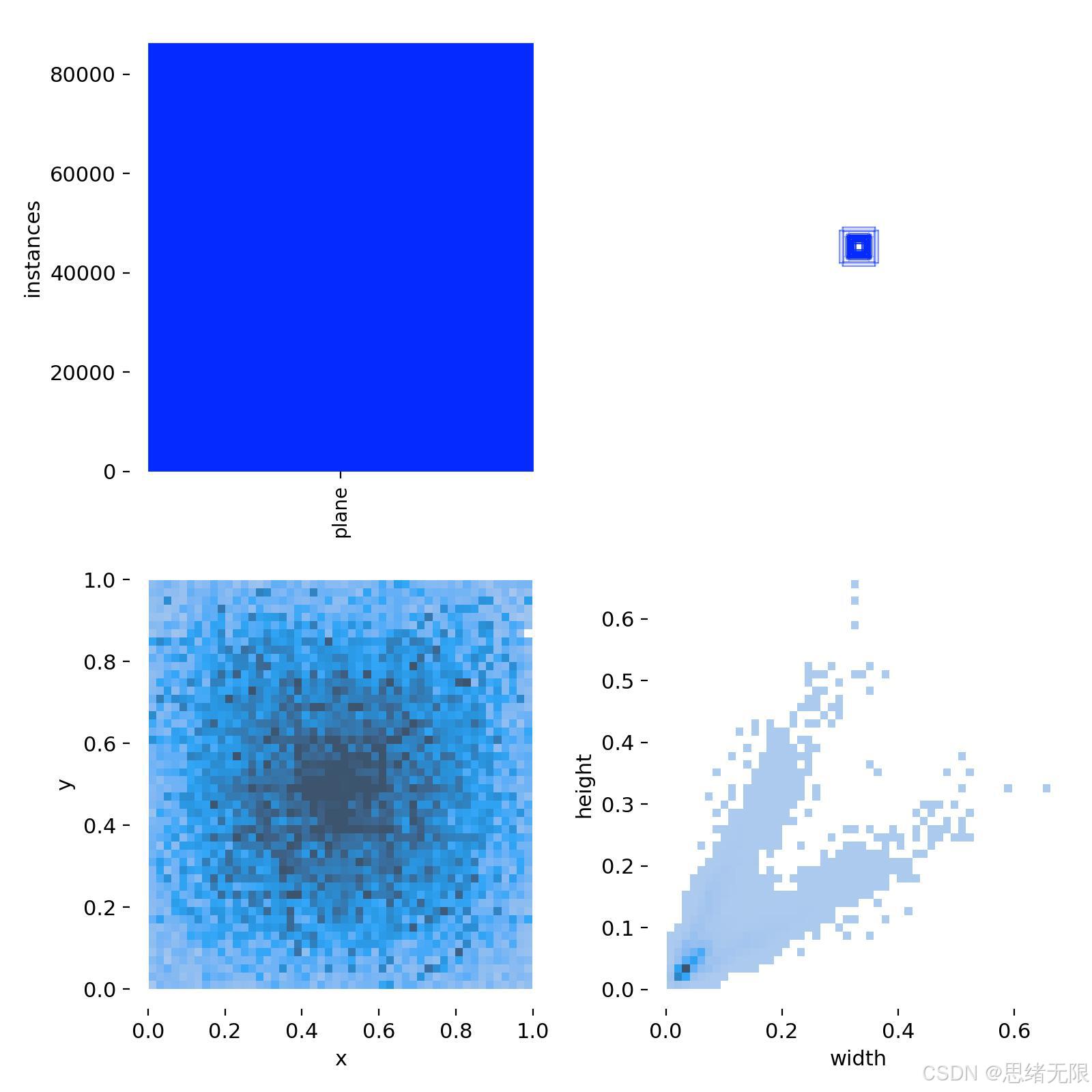
本项目面向遥感场景的单类目标检测任务,数据集中仅包含 plane(飞机) 一类目标,典型成像区域以机场及其周边场景为主,目标在纹理背景(跑道、停机坪、建筑阴影)与尺度分布上呈现出较强的遥感域特征:既存在占画面比例较大的大型机体,也存在大量尺度更小、密集分布的实例。标注采用 YOLO 系列通用的归一化边界框格式,即以 ( x , y , w , h ) (x, y, w, h) (x,y,w,h) 表示目标框中心点与宽高,并将坐标归一化到 0 , 1 0,1 0,1,从而与 Ultralytics/YOLOv5--YOLOv12 的训练与推理接口保持一致。结合所给的标签统计可见,目标中心点在图像平面上呈现"中部更密集、边缘相对稀疏"的分布特征,宽高分布则具有明显长尾,小尺度目标占比更高,这类统计特性会显著提高小目标召回与定位稳定性的难度,也更能检验不同 YOLO 版本在多尺度表征与样本分配上的有效性。
python
Chinese_name = {'plane': "飞机"}数据划分方面,本文将图像划分为训练集、验证集与测试集三部分:训练集用于模型参数学习,验证集用于超参数调节与早停判据,测试集用于最终性能评估与可视化展示。具体数量为:训练集 8292 张、验证集 609 张、测试集 132 张,总计 9033 张图像;对应比例分别为 91.8%、6.7% 与 1.5%。从工程复现角度,老思建议在数据组织上保持标准 YOLO 目录结构(images/labels 同名文件一一对应),并在训练阶段统一采用 letterbox 尺度归一化(如 640 × 640 640\times 640 640×640)以保证不同版本 YOLO 在输入分辨率上的可比性;此外,在遥感密集小目标场景中,建议同时保留原始分辨率信息用于后续误差分析(例如切片策略、极小目标阈值与漏检模式的诊断)。
📊 数据集规格说明 (Dataset Specification)
| 维度 | 参数项 | 详细数据 |
|---|---|---|
| 基础信息 | 标注软件 | LabelImg |
| 标注格式 | YOLO TXT (Normalized) | |
| 数量统计 | 训练集 (Train) | 8,292 张 (91.8%) |
| 验证集 (Val) | 609 张 (6.7%) | |
| 测试集 (Test) | 132 张 (1.5%) | |
| 总计 (Total) | 9,033 张 | |
| 类别清单 | Class ID: 0 | plane(飞机) |
| 图像规格 | 输入尺寸 | 640 * 640 |
| 数据来源 | 遥感影像(机场场景为主,人工清洗) |
3. 模型设计与实现
本项目的模型层设计目标并不是"只跑通一个 YOLO",而是围绕 YOLOv5--YOLOv12 的可切换、可复现对比 来组织工程结构:同一套遥感飞机数据(单类 plane/飞机)、同一套输入预处理与后处理接口、同一套评估脚本下,能够快速替换不同版本权重并完成训练与推理。综合遥感场景小目标密集与桌面端实时交互的需求,系统默认以 YOLOv12n 作为主模型(轻量、易实时),同时保留 v5/v6/v7/v8/v9/v10/v11/v12 的权重入口用于对比实验。YOLOv12 的核心特点在于将注意力机制置于网络设计中心,并通过 Area Attention、R-ELAN 与 FlashAttention 等手段兼顾表征能力与速度,但在训练稳定性、显存占用与 CPU 推理方面仍可能带来额外代价,因此更适合作为对比基准与研究对象。 (Ultralytics Docs)
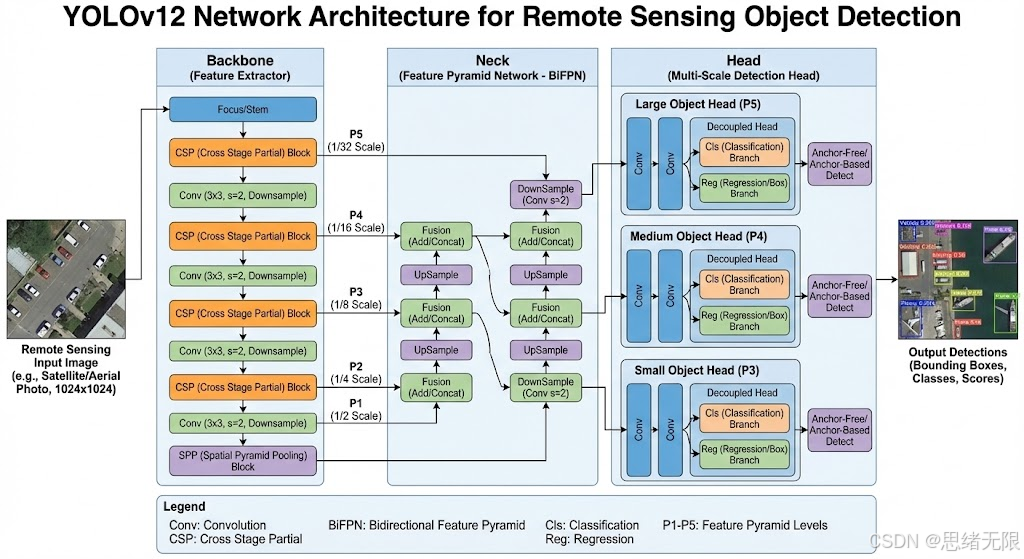
从结构上看,本项目沿用 YOLO 家族典型的"主干特征提取---多尺度特征融合---检测头输出"的三段式组织方式。以 YOLOv5 为例,其 backbone 采用 CSPDarknet 风格的分阶段下采样与残差聚合,neck 通过 SPPF 扩大感受野并结合 PANet 进行路径增强,多尺度特征最终送入检测头完成分类与回归;这种设计在工程侧的优势是模块边界清晰、推理链路成熟,适合快速落地与导出部署。 (Ultralytics Docs) 进入 YOLOv12 后,网络在保持 YOLO 框架整体形态的同时引入 attention-centric 设计:Area Attention 将特征图按区域划分以降低标准自注意力的计算代价,并通过"position perceiver( 7 × 7 7\times7 7×7 可分离卷积)"隐式注入位置信息;R-ELAN 则在聚合路径上加入残差与缩放以缓解大模型优化困难,从而使注意力模块在实时检测任务中更可用。 (Ultralytics Docs)
面向遥感小目标,neck 的多尺度融合是决定召回的重要环节。项目在各 YOLO 版本中统一采用来自高、中、低层的特征金字塔输出(常见为 P 3 , P 4 , P 5 P_3,P_4,P_5 P3,P4,P5),使检测头同时看到细粒度边缘纹理与高层语义信息;对飞机这类在停机坪密集分布、尺度跨度显著的目标而言, P 3 P_3 P3 分支往往决定小目标检出上限,而高层分支则更影响大目标定位稳定性与误检抑制。实现层面,博主在推理端对不同版本的输出做了统一封装:无论模型内部是锚框式还是无锚式,界面层最终都只消费一组标准化的检测结果(类别、置信度、像素坐标框),从而把"换模型"变成 UI 的一次下拉框切换。
检测任务的建模在不同 YOLO 版本中存在差异,但都可以抽象为分类与定位的联合优化。对单类飞机检测而言,类别维度退化为"飞机/背景"的二分类,常用 BCE 形式可写为
L c l s = − 1 N ∑ i = 1 N ( y i log p i + ( 1 − y i ) log ( 1 − p i ) ) , L_{\mathrm{cls}}=-\frac{1}{N}\sum_{i=1}^{N}\Big(y_i\log p_i+(1-y_i)\log(1-p_i)\Big), Lcls=−N1i=1∑N(yilogpi+(1−yi)log(1−pi)),
其中 p i p_i pi 为预测概率, y i ∈ 0 , 1 y_i\in{0,1} yi∈0,1 为标签。定位回归通常采用 IoU 系列损失以直接优化重叠度,典型的 CIoU 形式为
L C I o U = 1 − I o U + ρ 2 ( b , b ∗ ) c 2 + α v , L_{\mathrm{CIoU}}=1-\mathrm{IoU}+\frac{\rho^2(\mathbf{b},\mathbf{b}^*)}{c^2}+\alpha v, LCIoU=1−IoU+c2ρ2(b,b∗)+αv,
其中 ρ \rho ρ 表示预测框与真值框中心距离, c c c 为最小外接框对角线长度, v v v 刻画长宽比一致性, α \alpha α 为其权重。最终总损失一般写成加权求和
L = λ b o x L b o x + λ c l s L c l s + λ o b j L o b j , L=\lambda_{\mathrm{box}}L_{\mathrm{box}}+\lambda_{\mathrm{cls}}L_{\mathrm{cls}}+\lambda_{\mathrm{obj}}L_{\mathrm{obj}}, L=λboxLbox+λclsLcls+λobjLobj,
其中 L o b j L_{\mathrm{obj}} Lobj 表示目标存在性(或等价的匹配质量)约束;在 v10 这类强调端到端推理的模型中,训练分配与后处理策略会进一步影响 L o b j L_{\mathrm{obj}} Lobj 的定义与推理阶段是否需要 NMS,但对本项目而言,这些差异被封装在各自框架内部,统一对外输出检测框集合即可。
在工程实现上,项目采用"后端适配器"将不同版本 YOLO 的加载与推理解耦,使 UI 不依赖具体模型仓库。YOLOv8--YOLOv12 可直接使用 Ultralytics 的统一 API 加载权重;YOLOv5--YOLOv7 则可通过各自仓库或兼容接口加载。下面给出一个简化后的推理封装示例(核心思想是:同一函数返回统一结构的 boxes,并在显示侧将 plane 映射为"飞机"):
python
from dataclasses import dataclass
from typing import List, Tuple, Dict, Any
@dataclass
class DetBox:
xyxy: Tuple[int, int, int, int] # pixel coords
conf: float
cls_id: int
cls_name: str
class Detector:
def __init__(self, weight_path: str, names_cn: Dict[str, str] | None = None):
# v8+ (incl. v12) backend (Ultralytics)
from ultralytics import YOLO
self.model = YOLO(weight_path)
self.names = self.model.names # {id: name}
self.names_cn = names_cn or {}
def predict(self, img_bgr) -> List[DetBox]:
# Ultralytics accepts numpy (BGR ok; internally converts as needed)
res = self.model.predict(img_bgr, verbose=False)[0]
out: List[DetBox] = []
for b in res.boxes:
x1, y1, x2, y2 = map(int, b.xyxy[0].tolist())
cls_id = int(b.cls[0])
name_en = self.names.get(cls_id, str(cls_id))
name_show = self.names_cn.get(name_en, name_en) # plane -> 飞机
out.append(DetBox((x1, y1, x2, y2), float(b.conf[0]), cls_id, name_show))
return out在当前数据集的类别设置中,Class ID: 0 对应 plane(飞机),因此界面侧只需提供 Chinese_name = {'plane': '飞机'} 的映射即可完成中英文标签一致显示;当后续扩展到多类遥感目标(如舰船、车辆、油罐)时,同一机制也可无缝扩展为多类字典映射。
网络结构与可视化方面,本文在概述时引用两张"可直接用于博客插图"的官方/准官方示意图:第一张是 YOLOv5 的 backbone-neck-head 结构图,用于解释 YOLO 家族的通用多尺度融合与检测头输出;第二张给出 YOLOv10/v11/v12 的热力图对比,用于说明 YOLOv12 在表征与注意区域上的差异化效果。
4. 训练策略与模型优化
本项目的训练策略以"可复现的横向对比"为核心原则:对 YOLOv5--YOLOv12 采用尽可能一致的数据划分、输入分辨率、迭代轮数与学习率调度,并在验证集上以同一指标(如 m A P 50 : 95 mAP_{50:95} mAP50:95、 m A P 50 mAP_{50} mAP50、Precision/Recall、F1)进行早停与模型选择,从而避免因训练配方差异造成的比较偏置。考虑到遥感飞机检测存在小目标占比高、目标密集且背景纹理强干扰的特点,老思在训练阶段优先使用预训练权重(通常来自 COCO)进行迁移学习,以缩短收敛时间并提高特征泛化性;在实现上,Ultralytics(YOLOv8--YOLOv12)可直接加载 *.pt 作为初始化权重,YOLOv5--YOLOv7 则通过各自仓库的训练脚本加载对应 backbone/neck 预训练参数,最终统一输出同一格式的评估日志与权重文件,便于后续在 PySide6 系统中一键切换推理。
超参数方面,本项目默认以单卡 RTX 4090 作为训练硬件配置,输入尺寸固定为 640 × 640 640\times640 640×640,批大小以显存可承受为上限(默认 batch=16),并使用 warmup + 余弦退火的学习率策略提升前期稳定性与后期收敛质量。对遥感密集小目标而言,数据增强对召回的影响往往大于对分类的影响,因此在训练早期保持较强的 Mosaic/随机仿射扰动有助于扩大尺度与布局的覆盖,而在训练后期逐步关闭 Mosaic(如 close_mosaic=10)能够减轻几何扰动带来的定位噪声,使模型更贴近真实分布并提升框回归的稳定性。若训练中出现显存压力或梯度波动,工程上优先启用 AMP 混合精度与梯度累积(accumulate),其次再调整 batch 与输入尺寸;对于单类任务(plane/飞机),通常不需要复杂的类别重加权,但应重点关注极小目标的漏检模式,并在验证阶段结合 PR 曲线与不同置信度阈值下的召回变化进行诊断。
训练超参数(默认参考配置,适用于对比实验)
| 名称 | 作用(简述) | 数值 |
|---|---|---|
| epochs | 最大训练轮数 | 120 |
| patience | 早停耐心(验证无提升则停止) | 50 |
| batch | 每次迭代总批大小 | 16 |
| imgsz | 网络输入分辨率(方形) | 640 |
| pretrained | 加载预训练权重 | true |
| optimizer | 优化器类型(框架自动选择) | auto |
| lr0 | 初始学习率 | 0.01 |
| lrf | 最终学习率占比(余弦退火底值) | 0.01 |
| momentum | 动量系数 | 0.937 |
| weight_decay | 权重衰减(L2 正则) | 0.0005 |
| warmup_epochs | 学习率预热轮数 | 3.0 |
| mosaic | Mosaic 增强强度/概率 | 1.0 |
| close_mosaic | 训练后期关闭 Mosaic 的轮数 | 10 |
在模型优化与部署侧,老思将"训练得到的权重"与"系统可交互推理体验"一并纳入优化目标。首先,推理端默认采用 FP16(GPU)以降低延迟,并在导出阶段提供 ONNX/TensorRT 选项,使桌面端视频/摄像头实时检测更稳定;其次,针对遥感大幅面影像常见的"目标过小导致缩放后细节丢失"问题,系统侧预留切片推理(tiling)与滑窗重叠合并的接口:训练仍使用统一的 640 × 640 640\times640 640×640 输入以保证对比公平,但在实际业务推理时可按需启用切片以提升极小目标检出率。最后,界面层将 Conf 与 IoU 阈值暴露为可调参数,并支持结果导出与回看,这使得阈值选择不再是"训练脚本里的一次性设定",而是可在不同场景(密集停机坪、复杂背景、低对比度影像)下进行快速试探与定量对比,从而把模型优化延伸到更贴近应用的"可用性优化"层面。
5. 实验与结果分析
5.1 实验设置与对比基线
本实验围绕遥感单类目标"plane(飞机)"展开,在统一数据划分(Train 8292 / Val 609 / Test 132)、统一输入尺寸 640 × 640 640\times640 640×640 与一致训练策略(见第 4 节)的前提下,对 YOLOv5 至 YOLOv12 的轻量配置进行横向对比。为便于公平讨论"精度---速度---复杂度"的工程权衡,老思将模型分为两组:其一为轻量组(n_type:YOLOv5nu、YOLOv6n、YOLOv7-tiny、YOLOv8n、YOLOv9t、YOLOv10n、YOLOv11n、YOLOv12n),其二为中等规模组(s_type:YOLOv5su、YOLOv6s、YOLOv7、YOLOv8s、YOLOv9s、YOLOv10s、YOLOv11s、YOLOv12s)。推理时延统计采用框架输出的三段耗时(Pre/Inf/Post),并在同一硬件环境上记录;从实验日志可见,本次速度测试设备为 NVIDIA GeForce RTX 3070 Laptop GPU(8GB),因此文中的毫秒级耗时主要用于相对比较而非跨平台绝对对标。
5.2 度量指标与阈值选择
实验采用目标检测常用指标 Precision、Recall、 F 1 F1 F1、 m A P @ 0.5 mAP@0.5 mAP@0.5 与 m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95。其中
F 1 = 2 P R P + R , F1=\frac{2PR}{P+R}, F1=P+R2PR,
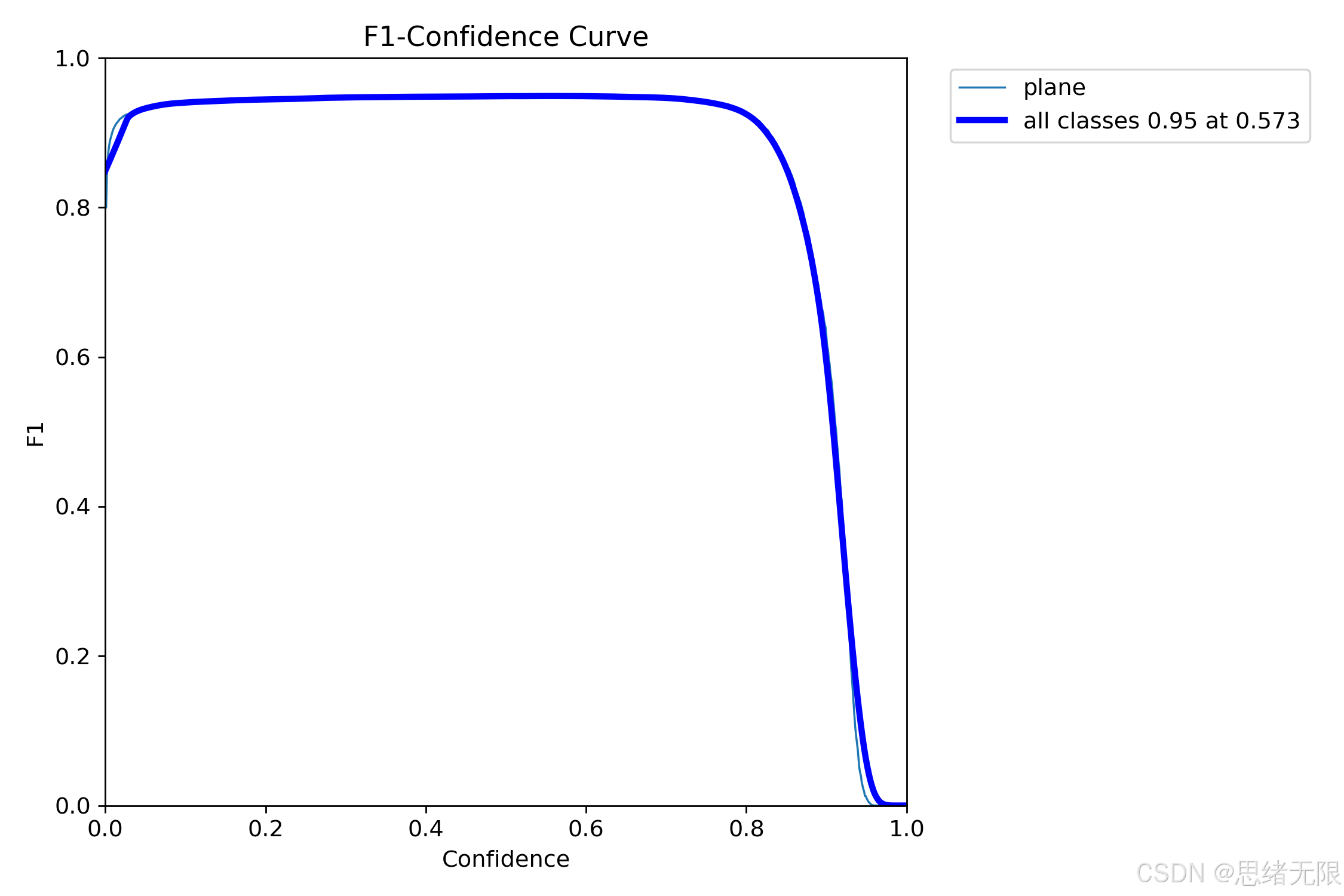
用于衡量精确率与召回率的折中; m A P @ 0.5 mAP@0.5 mAP@0.5 反映较宽松 IoU 条件下的检出能力,而 m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95 更强调定位精度与高 IoU 下的稳健性。由于系统最终需要在桌面端交互式使用,置信度阈值(Conf)并不适合"写死",因此本文同时给出基于验证集/测试集统计的 F 1 F1 F1--Confidence 曲线,用于确定推荐阈值范围。
从图中的 F 1 F1 F1--Confidence 关系可以看到,曲线在较宽阈值区间内保持高平台,最佳点出现在 Conf ≈ 0.573 \approx 0.573 ≈0.573 附近,对应 F 1 ≈ 0.95 F1 \approx 0.95 F1≈0.95 ;当 Conf 继续提高到接近 0.9 后,召回快速下降导致 F 1 F1 F1 断崖式回落,这意味着在遥感密集目标场景中"过高阈值"会显著放大漏检风险。
5.3 实验结果对比与可视化分析
表 5-1 汇总了 n_type 轻量组的核心结果。整体上,除 YOLOv5nu 外,其余版本在该单类飞机数据集上均达到 m A P @ 0.5 ≥ 0.986 mAP@0.5 \ge 0.986 mAP@0.5≥0.986 的高精度区间,说明当数据与任务相对"可分"时,多数新版本的收益更多体现在速度、后处理成本与高 IoU 定位质量上,而不是 m A P @ 0.5 mAP@0.5 mAP@0.5 的显著抬升。YOLOv5nu 的 m A P @ 0.5 = 0.908 mAP@0.5=0.908 mAP@0.5=0.908 与 F 1 = 0.926 F1=0.926 F1=0.926 明显落后,且 m A P @ 0.5 mAP@0.5 mAP@0.5 与 m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95 的差距更大(0.908 vs 0.762),反映其在更严格 IoU 下的定位稳定性不足,更容易出现框偏移或尺度回归误差。
表 5-1 n_type 模型对比结果(Test 集,单类 plane)
| 模型 | Params(M) | FLOPs(G) | Total(ms) | F1 | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|---|---|
| YOLOv5nu | 2.6 | 7.7 | 10.94 | 0.926 | 0.908 | 0.762 |
| YOLOv6n | 4.3 | 11.1 | 10.34 | 0.971 | 0.986 | 0.808 |
| YOLOv7-tiny | 6.2 | 13.8 | 21.08 | 0.977 | 0.989 | 0.784 |
| YOLOv8n | 3.2 | 8.7 | 10.17 | 0.971 | 0.987 | 0.807 |
| YOLOv9t | 2.0 | 7.7 | 19.67 | 0.975 | 0.987 | 0.811 |
| YOLOv10n | 2.3 | 6.7 | 13.95 | 0.968 | 0.986 | 0.814 |
| YOLOv11n | 2.6 | 6.5 | 12.97 | 0.972 | 0.986 | 0.807 |
| YOLOv12n | 2.6 | 6.5 | 15.75 | 0.971 | 0.986 | 0.810 |
从柱状对比图看,YOLOv7-tiny 在 F 1 F1 F1 与 m A P @ 0.5 mAP@0.5 mAP@0.5 上略占优势,但其推理与后处理耗时更高;这与其网络规模、输出候选数量以及后处理(NMS)开销更重相一致。相对而言,YOLOv8n 在保证接近顶尖的精度水平下取得了本组 最低的端到端耗时 (Total ≈ 10.17 \approx 10.17 ≈10.17 ms),更符合"桌面端实时交互"的系统目标。
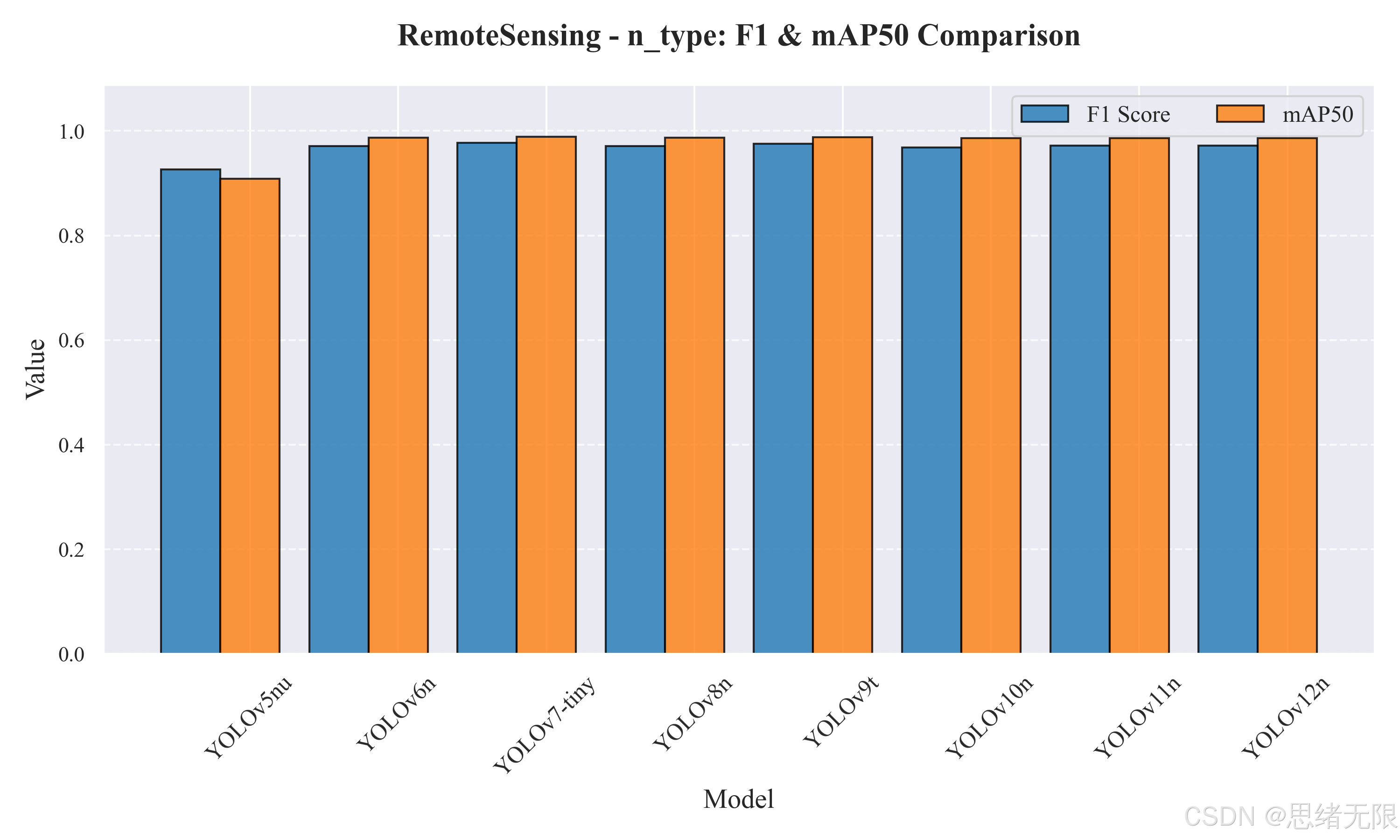
值得单独指出的是 YOLOv10n 的 PostTime 仅 0.63 ms ,显著低于其他版本,且在更严格的 m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95 上取得本组最优(0.814)。这类现象通常意味着其后处理链路更轻(例如减少或弱化 NMS 依赖),并且在定位回归上更稳定;对于"高帧率视频/摄像头流 + 实时 UI 刷新"的应用场景,后处理耗时往往比骨干 FLOPs 更容易成为瓶颈,因此 YOLOv10n 在工程侧具有明确优势。
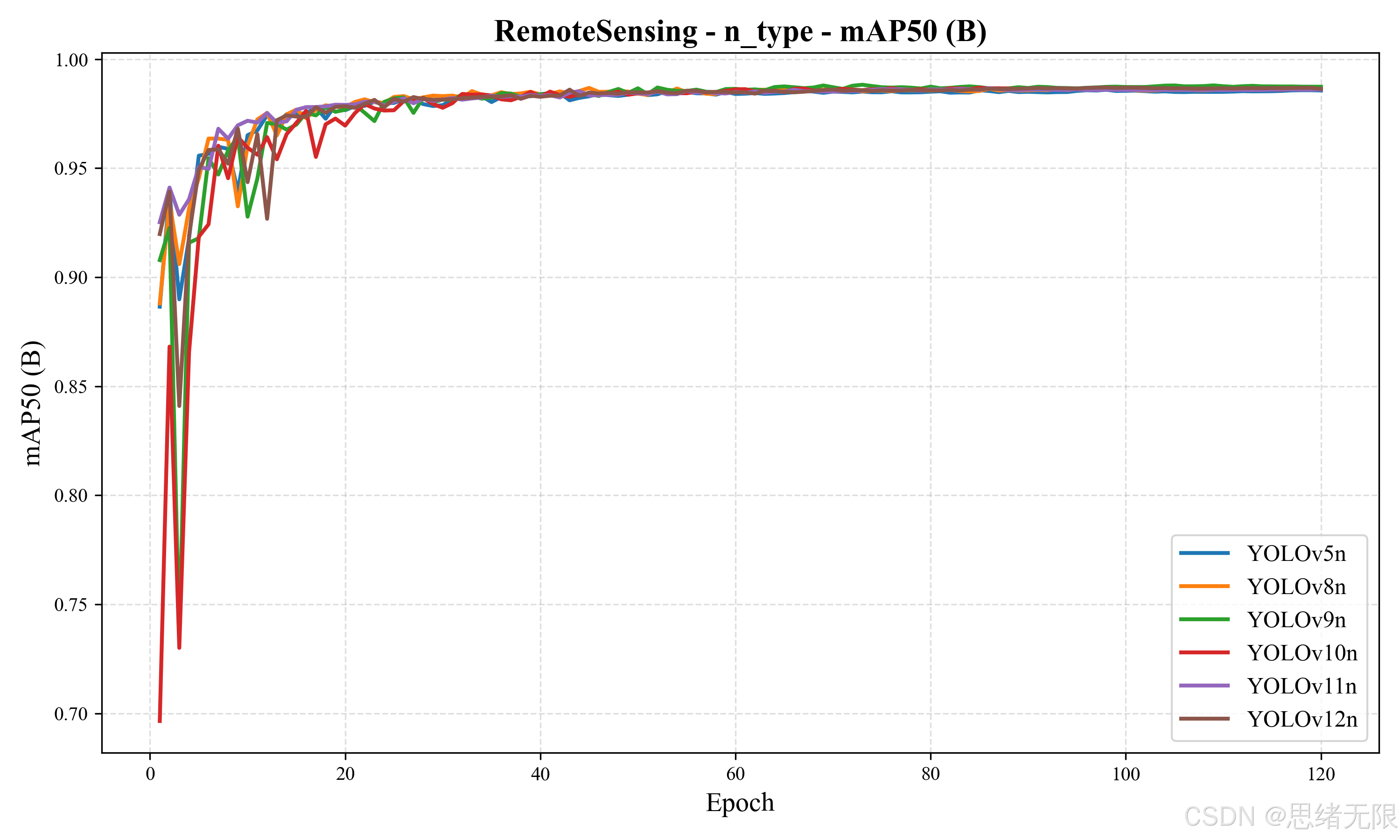
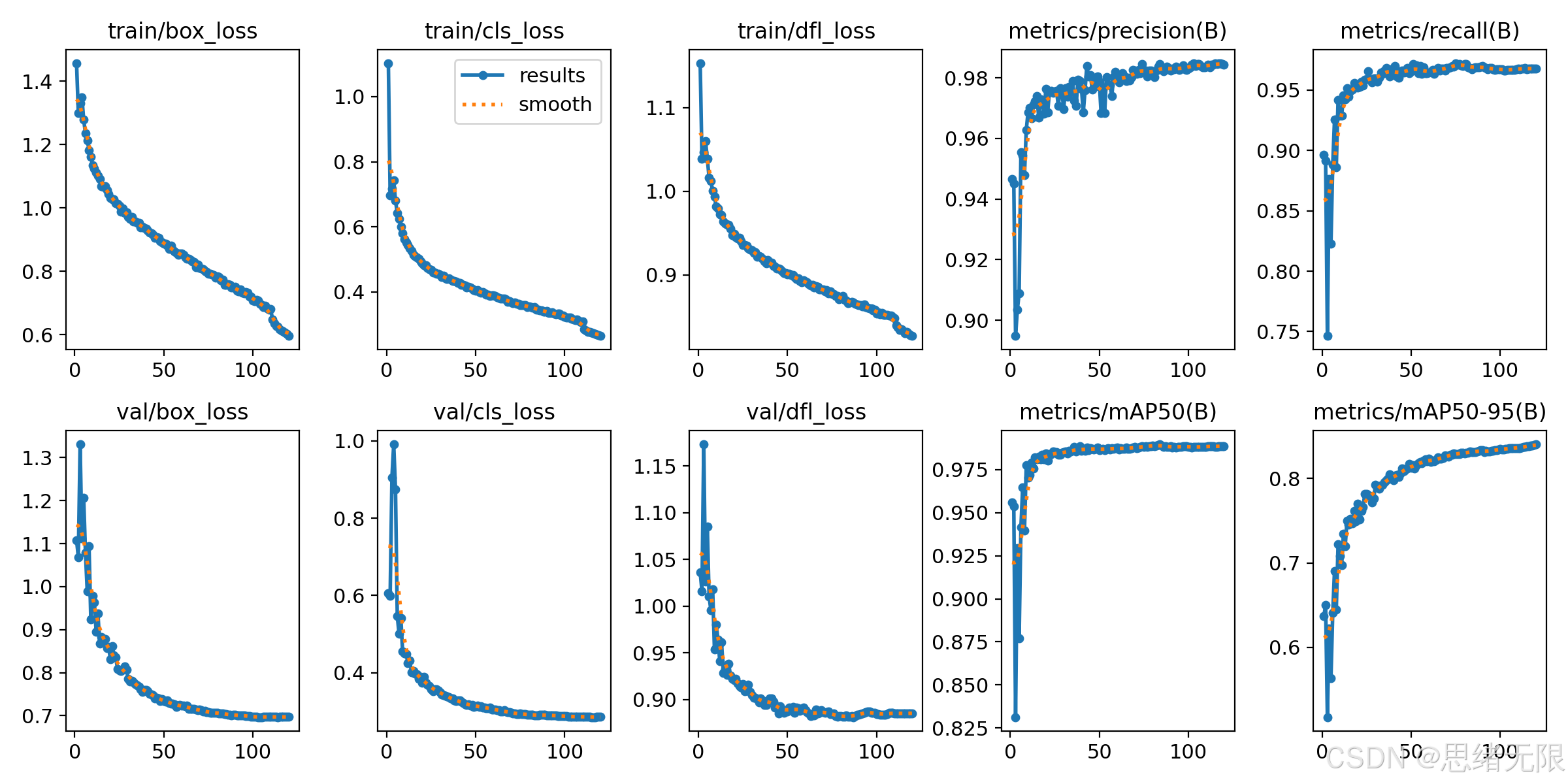
从收敛曲线看,多数 n_type 模型在前 20 个 epoch 内迅速达到高 m A P @ 0.5 mAP@0.5 mAP@0.5 区间,之后进入平稳缓慢提升阶段;不同版本之间的差异更多体现为早期震荡幅度与最终平台高度的细微差别,这与单类任务可分性较强、预训练迁移充分有关。
PR 曲线的平均对比进一步验证了上述结论:YOLOv5nu 曲线在高召回区间明显下沉,而其余模型几乎重合并保持高平台,说明后续版本在该数据集上的主要差距已从"能否检出"转移到"推理效率与严格定位质量"。
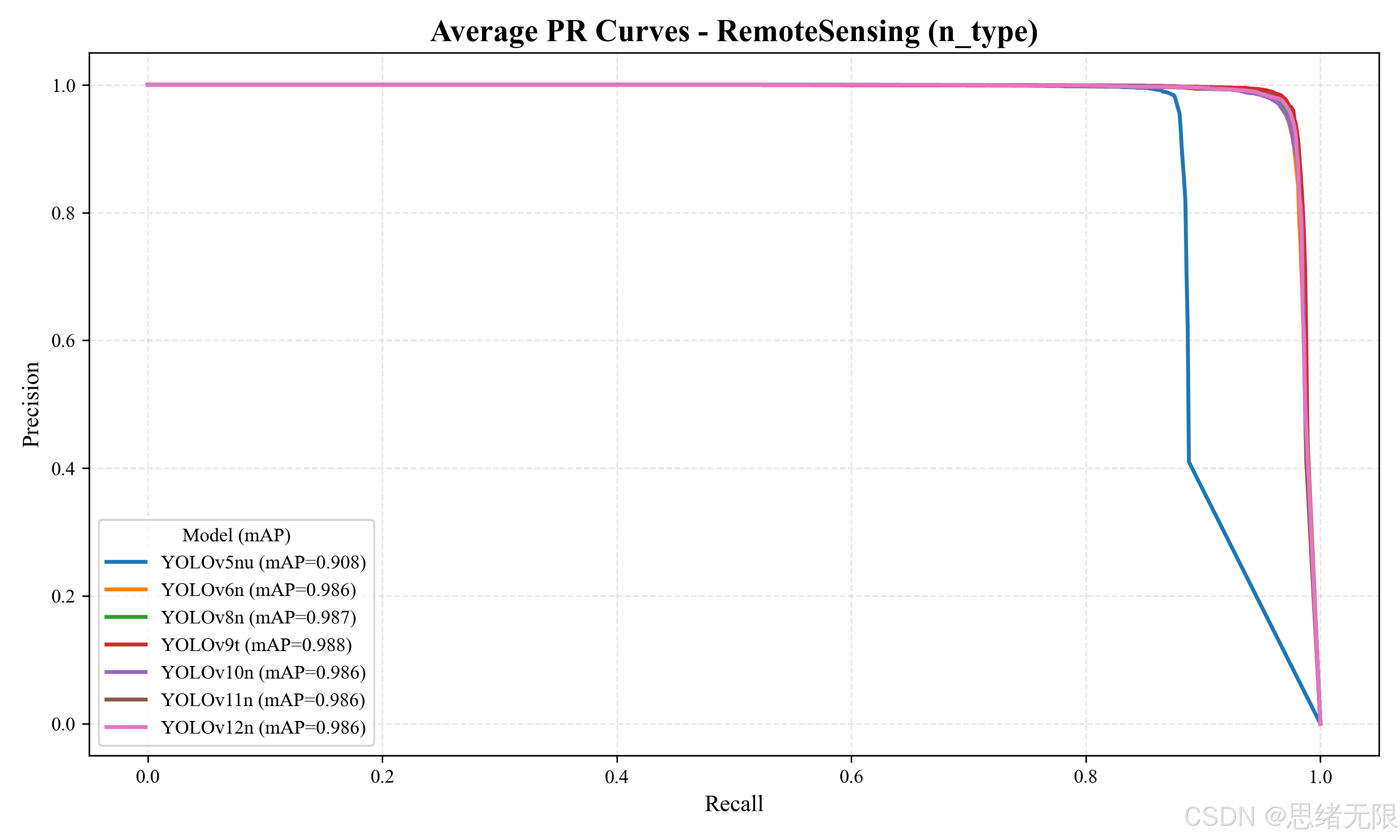
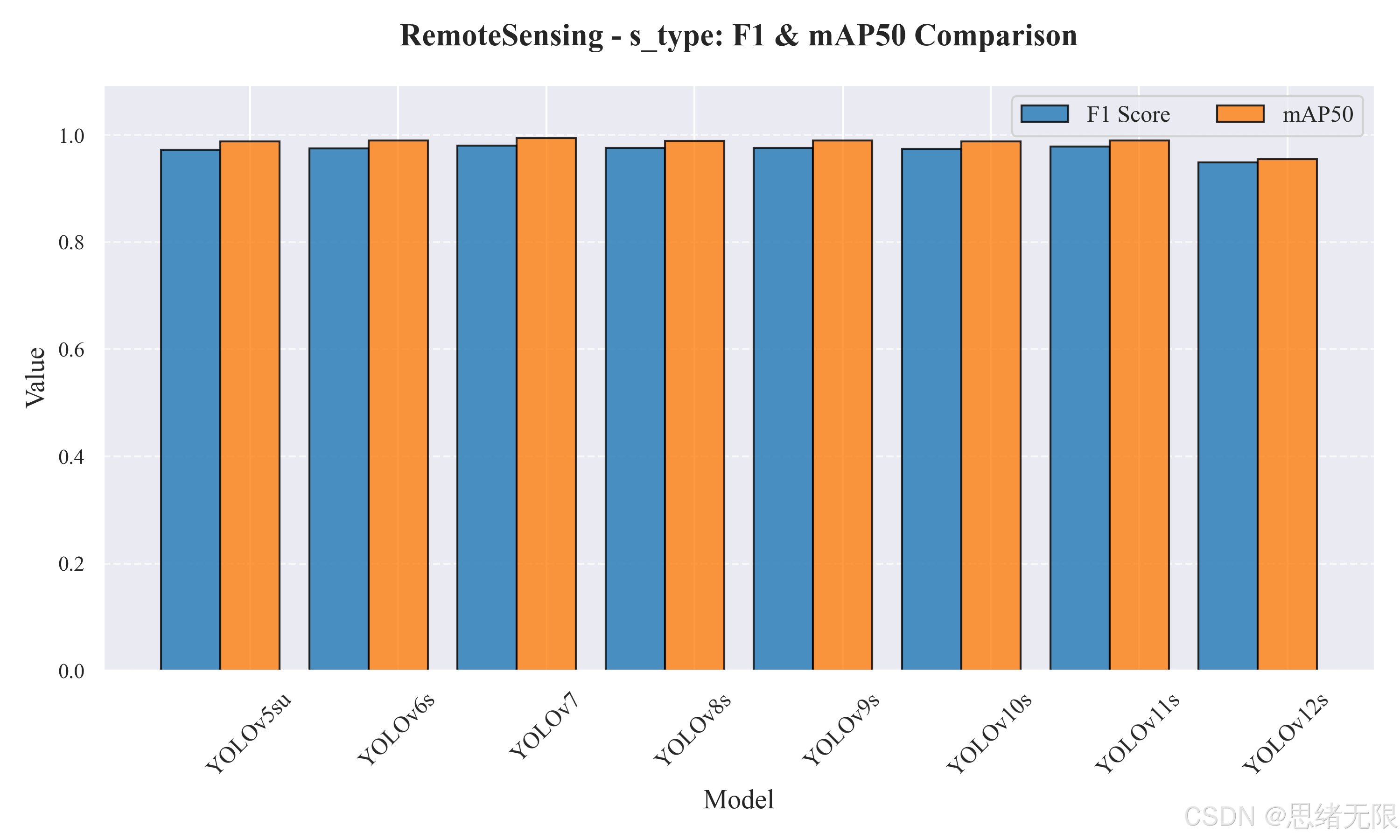
表 5-2 给出了 s_type 结果。YOLOv7 在该组取得最高的 F 1 = 0.980 F1=0.980 F1=0.980 与 m A P @ 0.5 = 0.994 mAP@0.5=0.994 mAP@0.5=0.994,显示更大模型容量在复杂背景与密集场景下仍有上限优势;但其 Total 耗时接近 30 ms,难以在高分辨率视频流场景下维持更高帧率。若系统目标强调"实时性优先",YOLOv8s(Total ≈ 11.39 \approx 11.39 ≈11.39 ms)与 YOLOv10s/YOLOv11s(Total ≈ 14.19 / 13.47 \approx 14.19/13.47 ≈14.19/13.47 ms)在精度几乎不损失的情况下更具工程性价比,其中 YOLOv10s 同样表现出极低的 PostTime(0.60 ms)与更高的 m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95(0.842)。
表 5-2 s_type 模型对比结果(Test 集,单类 plane)
| 模型 | Params(M) | FLOPs(G) | Total(ms) | F1 | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|---|---|
| YOLOv5su | 9.1 | 24.0 | 12.24 | 0.972 | 0.988 | 0.836 |
| YOLOv6s | 17.2 | 44.2 | 12.26 | 0.975 | 0.989 | 0.833 |
| YOLOv7 | 36.9 | 104.7 | 29.52 | 0.980 | 0.994 | 0.807 |
| YOLOv8s | 11.2 | 28.6 | 11.39 | 0.976 | 0.989 | 0.840 |
| YOLOv9s | 7.2 | 26.7 | 22.17 | 0.976 | 0.989 | 0.833 |
| YOLOv10s | 7.2 | 21.6 | 14.19 | 0.974 | 0.988 | 0.842 |
| YOLOv11s | 9.4 | 21.5 | 13.47 | 0.978 | 0.989 | 0.840 |
| YOLOv12s | 9.3 | 21.4 | 16.74 | 0.949 | 0.955 | 0.811 |
柱状图对比更直观地揭示了 YOLOv12s 的异常退化:其 m A P @ 0.5 mAP@0.5 mAP@0.5 与 F 1 F1 F1 显著低于同组其他模型,而精确率仍维持在较高水平(Precision ≈ 0.984 \approx 0.984 ≈0.984),主要问题来自召回下降(Recall ≈ 0.917 \approx 0.917 ≈0.917)。这类"高精确率、低召回"的模式在遥感场景中常对应两类原因:其一是置信度分布偏保守,导致中等置信度的真阳性被阈值过滤;其二是小目标或密集目标的匹配/分配不充分,使得模型对部分难例倾向于输出低分或漏检。工程上通常可通过降低 Conf、调整正负样本分配策略、增强小目标采样或引入切片推理缓解,但在"统一训练配方"的对比实验中,YOLOv12s 的这一现象更适合作为后续针对性调参的切入点。
从训练日志可视化(loss 与指标随 epoch 变化)可以看到,训练/验证损失整体平滑下降,Precision 与 Recall 在前期快速提升并趋于稳定, m A P @ 0.5 mAP@0.5 mAP@0.5 很早进入高平台而 m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95 仍持续缓慢爬升,这符合"单类任务易收敛,但严格定位仍需迭代细化"的一般规律。更重要的是,验证损失没有出现持续回升或指标明显回落,说明在当前数据规模与增强强度下未观察到典型过拟合形态,模型具备较好的泛化稳定性。
6. 系统设计与实现
6.1 系统设计思路
本系统以"桌面端可交互的遥感目标检测"为目标,将模型推理链路与界面交互严格解耦:界面层由 Ui_MainWindow 承载控件布局与样式(按钮、标签、表格、图标与主题),控制层由 MainWindow 统一调度输入源、状态机与槽函数,处理层以 Detector 封装权重加载、推理与后处理,并通过统一的数据结构向上层回传检测框、类别、置信度与耗时统计。这样做的直接收益是模型从 YOLOv5 切换到 YOLOv12 仅涉及 Detector 内部的适配,不会牵连 UI 代码,从而保证版本对比实验与工程演示都可复现、可维护。
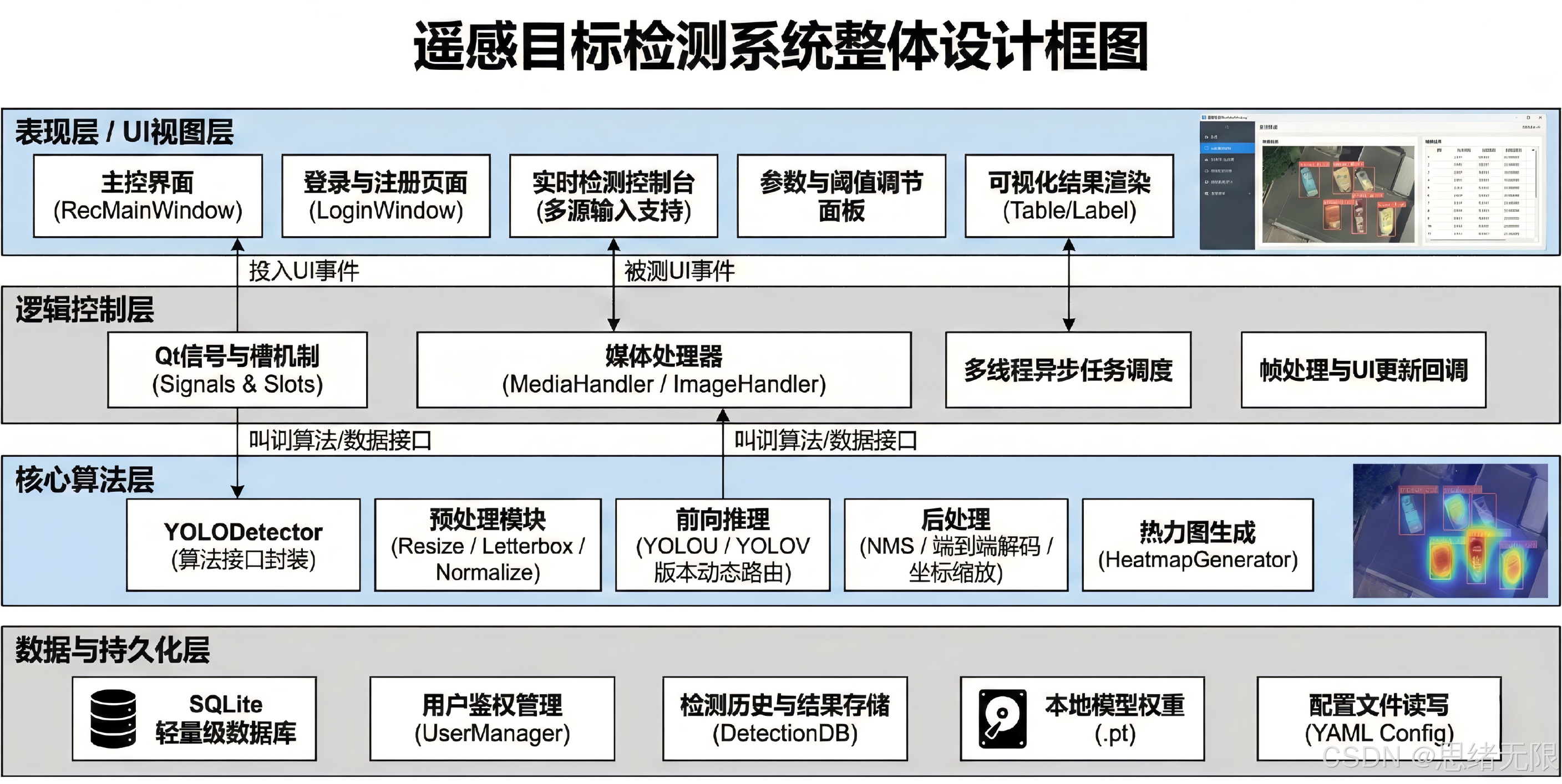
在交互实现上,老思将跨层通信完全交给 Qt 的信号---槽机制,并将推理放入独立工作线程(如 QThread)以避免阻塞主线程渲染。多源输入(摄像头/视频/图片/文件夹)被抽象为统一的"帧提供者",对上游输出统一的 frame + meta,对下游则统一走"预处理→推理→后处理→统计→界面更新"的流水线;其中阈值(Conf/IoU)与模型权重选择在 UI 侧可实时调整,并通过信号即时作用于后处理与渲染策略,确保在密集机场场景下能够快速在"减少误检"和"避免漏检"之间切换。
为满足工程可用性,系统将"结果管理"作为一等公民:每次推理产生的结构化记录(时间戳、输入源、模型版本、阈值、检测数量、框坐标等)可选择写入 SQLite,同时支持导出图片/视频、CSV 或批量保存渲染结果,便于复核与离线分析。界面层还提供主题修改能力(亮/暗色与自定义配色),通过 QSS 统一渲染按钮、表格与背景,并把主题与最近使用模型等偏好持久化到用户配置表,实现"用户空间隔离 + 个性化默认设置"的一致体验;对于图标、背景、文字或控件的修改与删除等可视化定制,也被收敛为对 QSS 与控件属性的受控更新,避免在业务逻辑中散落硬编码。
图 系统流程图
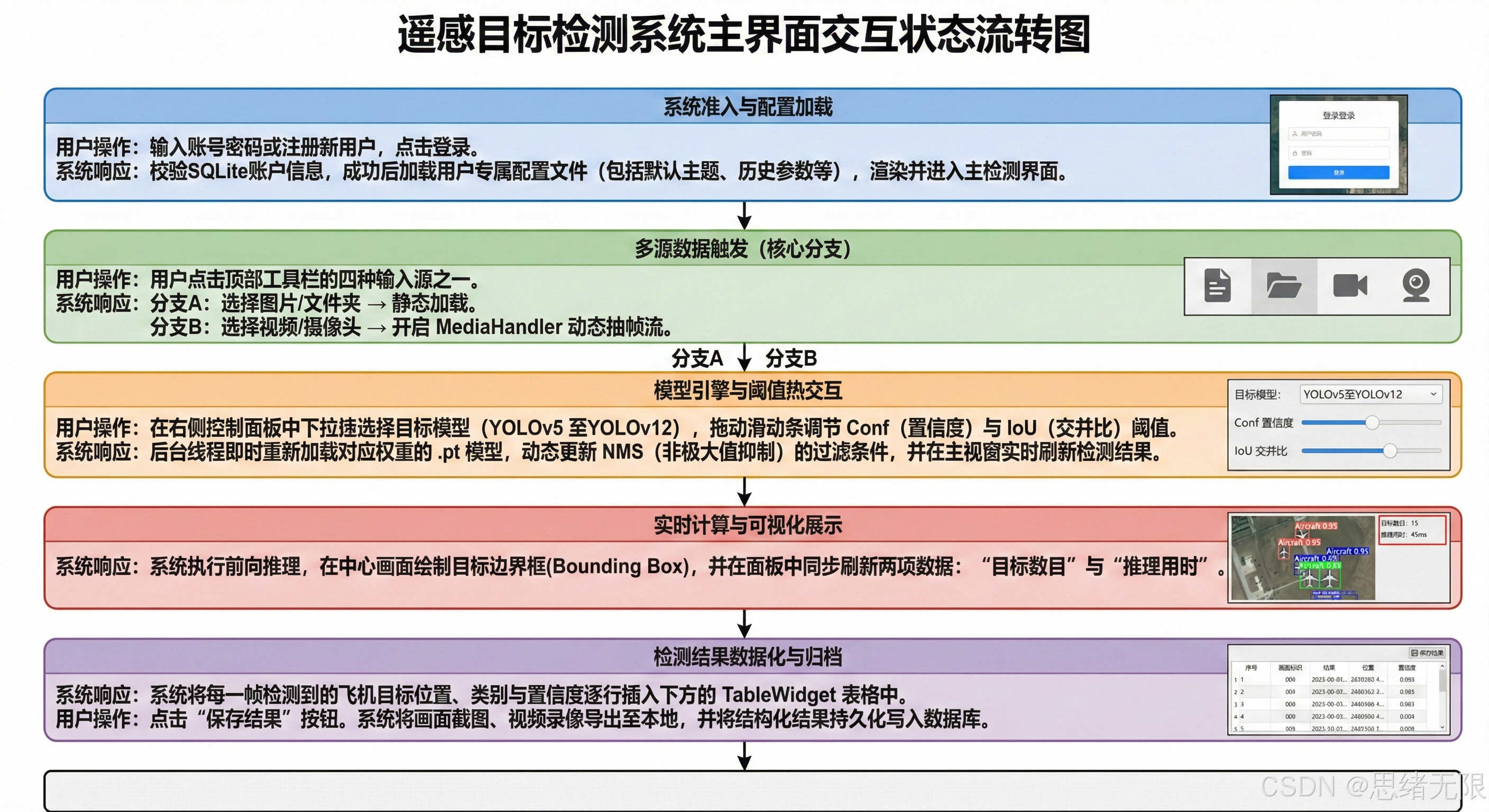
图注:系统从初始化到多源输入,完成预处理、推理与界面联动,并通过交互形成闭环。
6.2 登录与账户管理
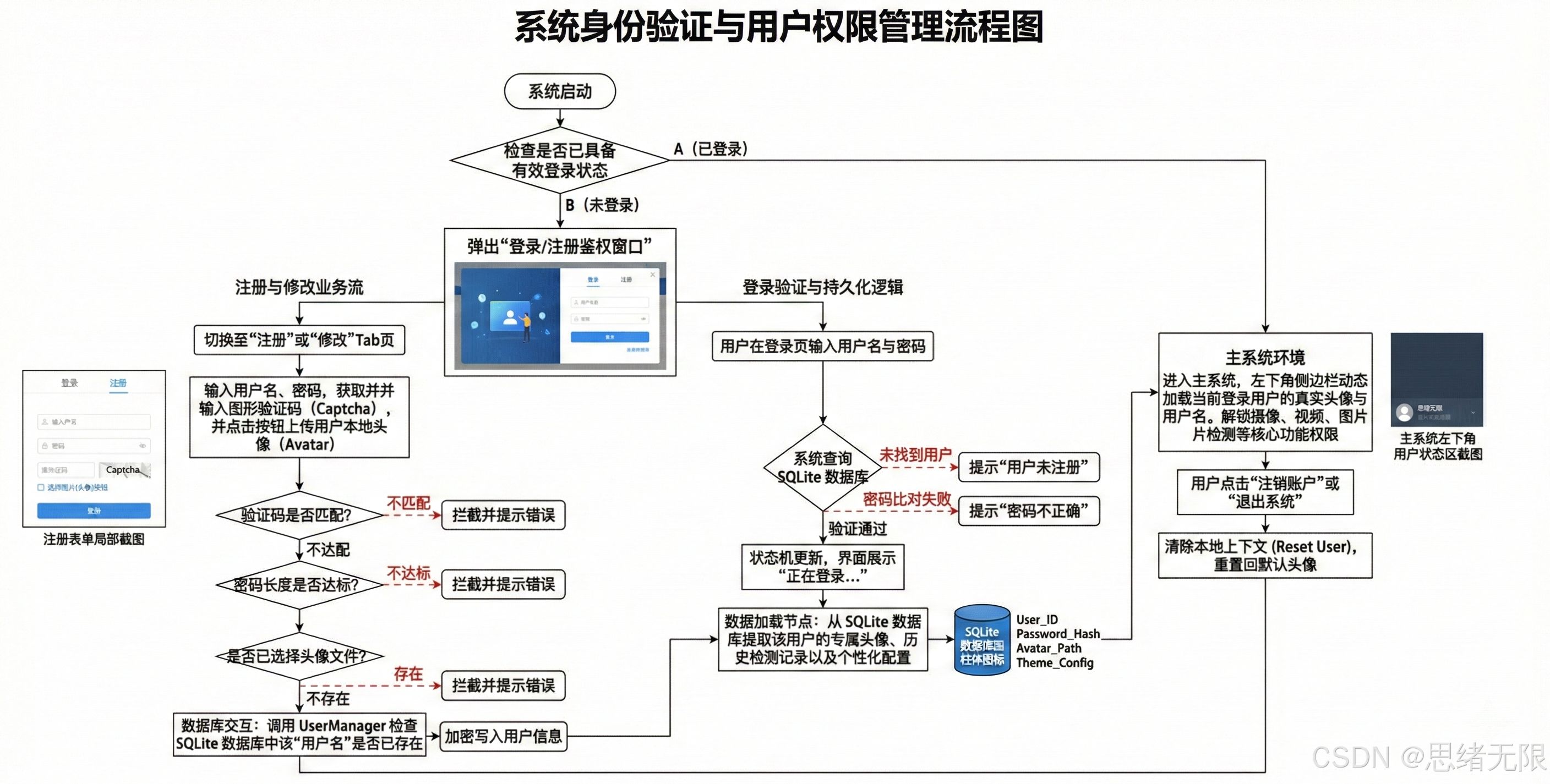
登录与账户管理模块在工程上承担"身份校验---个性化配置加载---检测结果归档"的枢纽作用:系统启动后先进入登录界面,若用户注册则完成输入合法性校验并将口令以加盐哈希形式写入 SQLite,若用户登录则通过查询校验建立会话并读取其专属配置(默认模型、Conf/IoU、主题样式等)与历史记录;进入主界面后,所有检测产生的结果均以 user_id 作为外键关联,实现不同用户之间的配置与结果空间隔离,同时支持头像与密码修改、主题与偏好更新等资料维护操作,并在注销或切换账号时回收会话状态与资源句柄,使账户生命周期与主检测流程自然衔接,保证长期使用下的数据可追溯性与交互一致性。
7. 下载链接
若您想获得博文中涉及的实现完整全部资源文件 (包括测试图片、视频,py, UI文件,训练数据集、训练代码、界面代码等),这里见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见:➷➷➷
详细介绍文档博客: YOLOv5至YOLOv12升级:遥感目标检测系统的设计与实现(完整代码+界面+数据集项目)
环境配置博客教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境配置教程;
或者环境配置视频教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境依赖配置教程
数据集标注教程(如需自行标注数据):数据标注合集
8. 参考文献(GB/T 7714)
1 徐丹青, 吴一全. 光学遥感图像目标检测的深度学习算法研究进展J. 遥感学报, 2024, 28(12): 3045-3073. DOI:10.11834/jrs.20243166.
2 Li K, Wan G, Cheng G, Meng L, Han J. Object detection in optical remote sensing images: A survey and a new benchmarkJ. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 159: 296-307. DOI:10.1016/j.isprsjprs.2019.11.023.
3 Xia G S, Bai X, Ding J, Belongie S, Luo J, Datcu M, Pelillo M, Zhang L. DOTA: A Large-Scale Dataset for Object Detection in Aerial ImagesC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018: 3974-3983.
4 Sun X, Wang P, Yan Z, Xu F, Wang R, Diao W, Chen J, Li J, Feng Y, Xu T, Weinmann M, Hinz S, Wang C, Fu K. FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imageryJ. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 184: 116-130. DOI:10.1016/j.isprsjprs.2021.12.004.
5 Ren S, He K, Girshick R, Sun J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal NetworksC//Advances in Neural Information Processing Systems (NeurIPS). 2015: 91-99.
6 Lin T Y, Dollár P, Girshick R, He K, Hariharan B, Belongie S. Feature Pyramid Networks for Object DetectionC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017: 2117-2125.
7 Liu S, Qi L, Qin H, Shi J, Jia J. Path Aggregation Network for Instance SegmentationC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018: 8759-8768. DOI:10.1109/CVPR.2018.00913.
8 Wang C Y, Liao H Y M, Wu Y H, Chen P Y, Hsieh J W, Yeh I H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNNC//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). 2020: 390-391.
9 Redmon J, Divvala S, Girshick R, Farhadi A. You Only Look Once: Unified, Real-Time Object DetectionC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016: 779-788.
10 Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object DetectorsC//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2023: 7464-7475. DOI:10.1109/CVPR52729.2023.00721.
11 Wang C Y, Yeh I H. YOLOv9: Learning What You Want to Learn Using Programmable Gradient InformationC//Computer Vision -- ECCV 2024. Cham: Springer, 2024: 1-21. DOI:10.1007/978-3-031-72751-1_1.
12 Wang A, Chen H, Liu L, Chen K, Lin Z, Han J, Ding G. YOLOv10: Real-Time End-to-End Object DetectionC//Advances in Neural Information Processing Systems (NeurIPS). 2024, 37: 107984-108011.
13 Ding J, Xue N, Long Y, Xia G S, Lu Q. Learning RoI Transformer for Oriented Object Detection in Aerial ImagesC//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2019: 2849-2858.
14 Yang X, Yang J, Yan J, Zhang Y, Zhang T, Guo Z, Sun X, Fu K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated ObjectsC//Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 2019: 8232-8241.
15 Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S. End-to-End Object Detection with TransformersC//Computer Vision -- ECCV 2020. Cham: Springer, 2020: 213-229. DOI:10.1007/978-3-030-58452-8_13.