摘要 :开发面向智慧课堂的人员检测与计数系统,对于课堂出勤统计、教学秩序管理与安全监管具有重要应用价值。本文围绕"YOLOv5 至 YOLOv12 升级"的技术主线,系统性梳理从早期 YOLO 系列到新一代模型在结构设计、训练策略与推理部署上的关键演进,并以"教室人员检测与计数"为核心任务给出一套可复现实战方案。系统端采用 Python 3.12 与 PySide6 构建桌面级可视化界面,支持图片、视频与摄像头多源输入,提供检测框与人员数量实时统计、置信度与 IoU 阈值可调、结果截图与日志保存、推理帧率显示等功能;在算法端对 YOLOv5、YOLOv6、YOLOv7、YOLOv8、YOLOv9、YOLOv10、YOLO11 与 YOLOv12 进行统一数据集、统一指标的对比实验,分析不同模型在准确率、速度与参数规模之间的权衡关系,并给出适配教室场景的工程化优化建议(如小目标鲁棒性、遮挡与密集目标处理、低照度与视角变化适应等)。此外,本文配套构建并整理教室场景数据集,完成标注、预处理与训练/验证/测试划分,提供完整项目代码与可运行界面工程,便于读者复现训练、验证、推理与部署全流程,为智慧课堂视觉感知应用提供可直接落地的参考实现。
文章目录
- [1. 前言综述](#1. 前言综述)
- [2. 数据集介绍](#2. 数据集介绍)
- [3. 模型设计与实现](#3. 模型设计与实现)
- [4. 训练策略与模型优化](#4. 训练策略与模型优化)
- [5. 实验与结果分析](#5. 实验与结果分析)
-
- [5.1 单模型阈值选择与收敛性分析](#5.1 单模型阈值选择与收敛性分析)
- [5.2 多模型对比实验结果(n 型轻量模型)](#5.2 多模型对比实验结果(n 型轻量模型))
- [5.3 多模型对比实验结果(s 型模型)](#5.3 多模型对比实验结果(s 型模型))
- [6. 系统设计与实现](#6. 系统设计与实现)
-
- [6.1 系统设计思路](#6.1 系统设计思路)
- [6.2 登录与账户管理](#6.2 登录与账户管理)
- [7. 下载链接](#7. 下载链接)
- [8. 参考文献(GB/T 7714)](#8. 参考文献(GB/T 7714))
1. 前言综述
课堂人员检测与计数是智慧教室数据闭环中的基础视觉能力,其研究可视为人群计数与密度估计问题在室内教育场景的一个特化分支。1 (ScienceDirect)
在算法评测层面,MS COCO 以覆盖多类别、多尺度与复杂背景的标注方式,成为目标检测领域事实上的通用基准。2 (Springer)
两阶段检测器以 Faster R-CNN 为代表,通过候选框与 RoI 特征对齐获得较强的定位精度,但其计算与工程链路较长。3
单阶段方法如 SSD 以密集预测替代候选框生成,使实时检测在通用硬件上更易落地。4
YOLO 将检测统一为单网络回归任务并显著提高吞吐率,为视频流中的人员检测与瞬时计数提供了可部署的实时基线。5
针对小目标与尺度分布极不均匀的室内场景,FPN 的自顶向下融合与横向连接能够在较低额外开销下增强多尺度表征。6
若课堂出现局部拥挤或遮挡严重,基于密度图回归的 CSRNet 通过空洞卷积扩大感受野,可在高密度区域给出更稳定的计数估计。7
在遮挡占比较高的人体检测问题上,CrowdHuman 通过提供头部、可见区域与全身多层标注,为评估"遮挡鲁棒性"提供了更贴近真实监控画面的数据支撑。8
随着 Transformer 引入检测任务,DETR 以集合预测与二分图匹配损失替代传统 anchor 设计与 NMS 逻辑,推动检测框架向更端到端的方向演化。9
面向视频计数,ByteTrack 强调对低置信度检测框的再关联以缓解遮挡导致的漏检与轨迹断裂,从而为"连续时间上的人数统计"提供更平滑的计数序列。10 (Springer)
国内针对教室监管与统计的研究也开始融合检测与时序建模,例如丛帅等在河北大学学报提出目标检测与迁移时间序列结合的教室人员检测思路。11 (HBU XBZRB)
在系统层面,Gupta 等在《Multimedia Tools and Applications》对多版本 YOLO 进行人员检测与计数对比,提示在同一任务上仍需综合考虑精度、延迟与部署复杂度。12
面向最新 YOLO 演进,YOLOv9 在训练信息流与特征聚合设计上引入可编程梯度信息与 GELAN 结构,强调"信息保真"的可训练性以提升参数利用率。13 (arXiv)
YOLOv10 进一步提出无 NMS 的端到端范式以降低部署端后处理开销,并在注释中给出 NeurIPS 2024 camera-ready 版本信息。14 (arXiv)
最新的 YOLOv12 则以注意力为中心重审实时检测器设计,在文中报告其在保持低延迟的同时获得更高精度的经验结果。15 (arXiv)
表 1 代表性研究与方法对比(面向教室人员检测与计数)
| 方法范式 | 代表工作 | 常用数据集(示例) | 优点(与课堂任务的相关性) | 局限与课堂适配提示 |
|---|---|---|---|---|
| 通用评测基准 | MS COCO2 | COCO | 多尺度、复杂背景,便于横向比较检测器上界 | 教室画面类别单一但遮挡强,需做域适配与再标注 |
| 两阶段检测 | Faster R-CNN3 | COCO | 定位精度强,对"少量人员+高精细框"友好 | 延迟较高,难直接满足实时计数与 UI 低卡顿 |
| 单阶段检测 | SSD4 | COCO/VOC | 速度与精度折中,易做轻量化部署 | 小目标召回受限,后排学生易漏检 |
| 实时检测主线 | YOLO5 | COCO | 高吞吐,适合视频流逐帧检测与工程落地 | 计数稳定性依赖阈值与后处理策略,需配套工程约束 |
| 多尺度增强 | FPN6 | COCO | 提升小目标/远端目标召回,契合教室透视场景 | 融合方式与主干匹配度影响大,需结合具体 YOLO 版本调参 |
| 密度回归计数 | CSRNet7 | ShanghaiTech 等 | 拥挤区域计数更稳,对"局部密集"课堂片段有效 | 输出为密度图,缺少实例框,不利于 UI 标注与结果导出 |
| 遮挡评测数据 | CrowdHuman8 | CrowdHuman | 强遮挡标注有利于验证鲁棒性 | 仍与教室域存在差异,需结合自建教室数据再训练/微调 |
| 视频稳定计数 | ByteTrack10 | MOT17/MOT20 | 通过关联提高时间一致性,计数曲线更平滑 | 引入跟踪带来系统复杂度,需权衡"稳定性---延迟" |
| 教室场景研究 | 丛帅等11 | 自建教室数据 | 将检测与时序建模结合,面向真实教室需求 | 数据与公开基准差异大,复现与泛化需更标准的数据规范 |
| 多版本比较视角 | Gupta 等12 | COCO/自建集 | 给出跨版本 YOLO 的精度与速度权衡方法论 | 结论对数据分布敏感,建议在目标教室域重做基准 |
| 新一代结构与训练 | YOLOv913 | COCO | 强调训练信息流与结构效率,利于"精度/算力"再平衡 | 与具体工程框架耦合较深,需验证导出与推理链路一致性 |
| 端到端与部署效率 | YOLOv1014 | COCO | 无 NMS 思路降低后处理开销,利于端侧延迟稳定 | 对训练策略与匹配机制更敏感,需严格复现超参与数据增强 |
| 注意力实时化探索 | YOLOv1215 | COCO | 以注意力增强表征并追求实时性,适合复杂背景教室画面 | 注意力算子与部署后端兼容性需验证,尤其是 ONNX/TensorRT |
从教室应用出发,人员检测与计数面临的关键技术难点更偏"工程场景真实约束":其一,固定机位下的透视畸变会导致前排大目标与后排小目标并存,且学生之间、学生与桌椅之间的遮挡呈现高频与强随机性;其二,黑板反光、窗外强光与投影屏闪烁会引入显著的光照域偏移,训练集与部署环境一旦不一致,误检与漏检往往同时上升;其三,课堂统计并不只关心单帧检测精度,更需要在视频时间轴上给出稳定计数与可解释的变化来源,这会牵涉到检测阈值选择、计数策略(逐帧计数/区域计数/跟踪计数)以及实时 UI 回显的一致性;其四,在"可用即部署"的约束下,模型不仅要在 640 × 640 640\times 640 640×640 等常用输入尺寸获得高 mAP,还要兼顾 CPU/ONNX 或 TensorRT 端的延迟、显存占用与多源输入切换时的吞吐稳定性。
因此,老思在这篇博客的定位不是重复某个单一检测模型的原理介绍,而是围绕"YOLOv5 至 YOLOv12 的迭代谱系"把算法比较、数据集构建与可运行系统工程串起来:在同一教室人员数据集上系统对比多代 YOLO 族模型的检测与计数效果,并给出可复现实验配置;以 PySide6 实现面向非算法用户的桌面端交互界面,覆盖图片/视频/摄像头输入、阈值调参与结果保存;同时整理数据标注、预处理、划分与项目资源包,使读者能够以最小代价复现与二次开发。
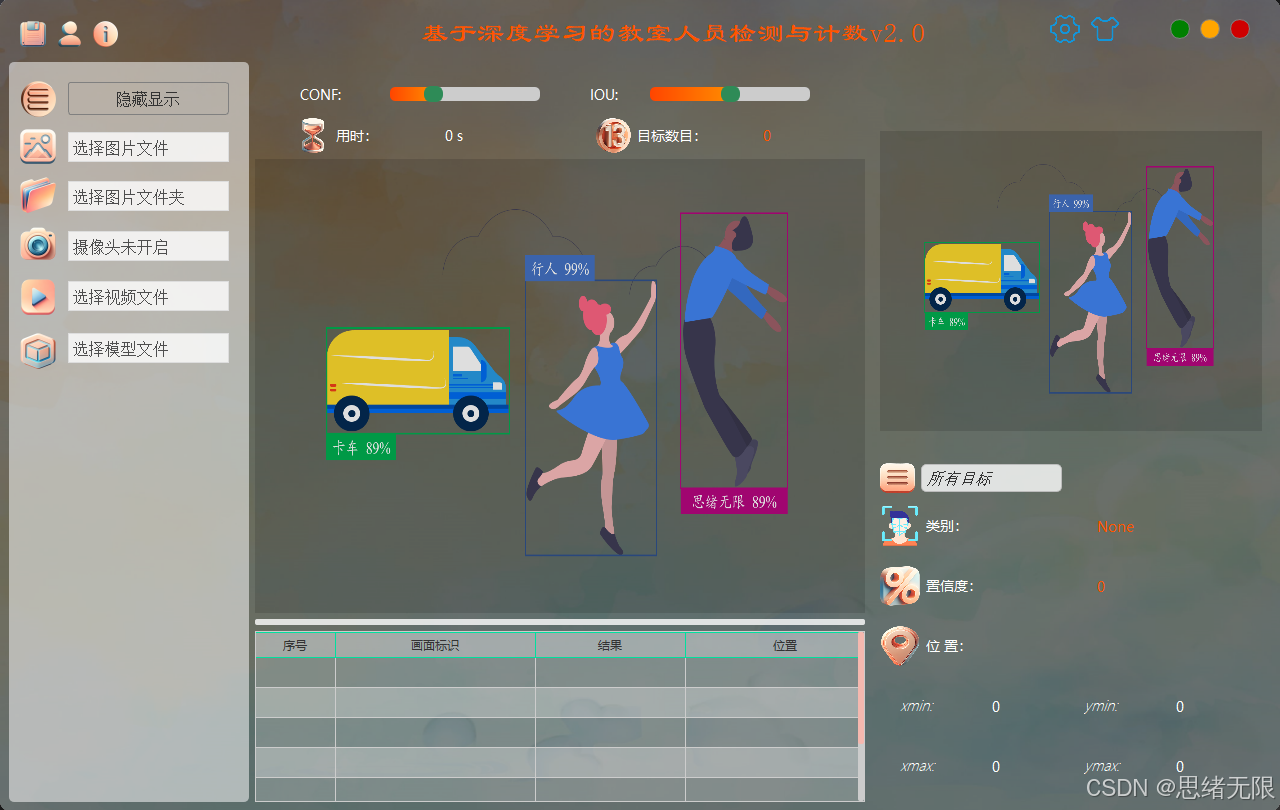
主要功能演示:
(1)启动与登录:系统启动后默认进入登录页,用户可完成注册、登录与密码修改,账户信息与历史检测记录写入 SQLite,实现"不同用户独立空间"的数据隔离;登录成功后自动加载用户偏好(上次选择的模型、阈值、主题等),减少重复配置。
启动与登录界面图
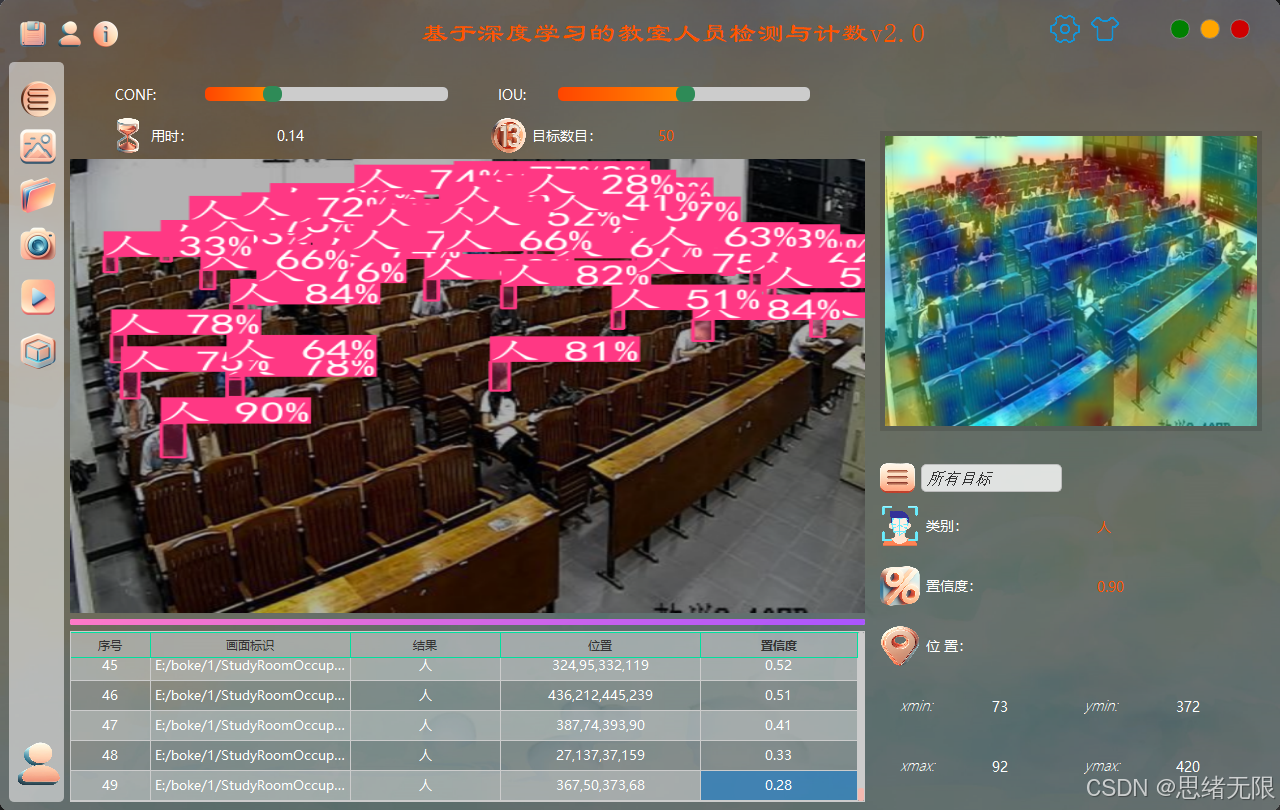
(2)多源输入与实时检测(摄像头/视频/图片/文件夹):主界面提供统一输入入口,支持摄像头实时流、视频文件、单张图片与图片文件夹批量推理;检测过程中同步显示目标框、置信度与当前人数统计,并支持暂停/继续、逐帧浏览与结果保存,保证"实时可用"和"离线批处理"两类场景都能覆盖。
多源输入与实时检测演示图
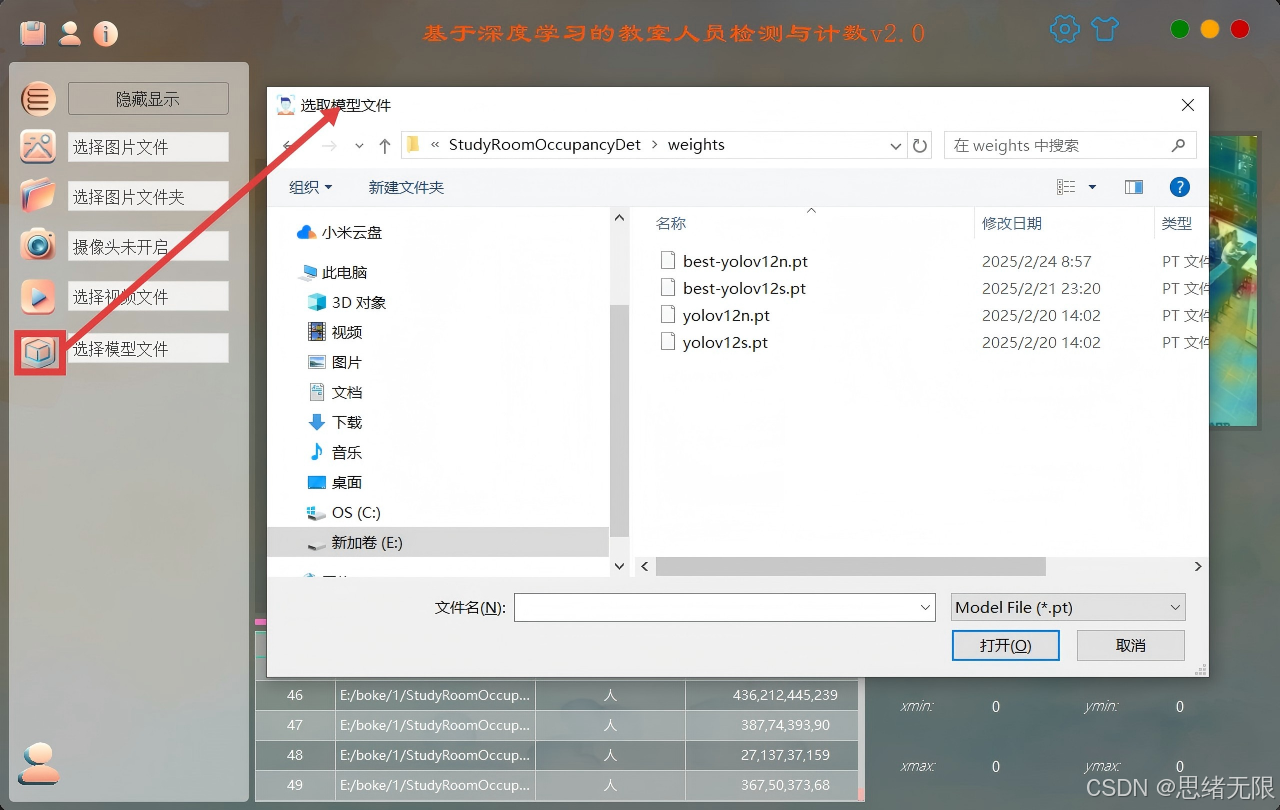
(3)模型选择与对比演示:界面内置 YOLOv5--YOLOv12 多版本权重切换入口,用户可一键选择不同模型进行推理,对同一输入快速对比检测框稳定性、漏检/误检与推理帧率差异;同时提供统一的 Conf/IoU 参数调节以保证横向对比的可控性,便于做工程选型。
模型选择与对比演示图
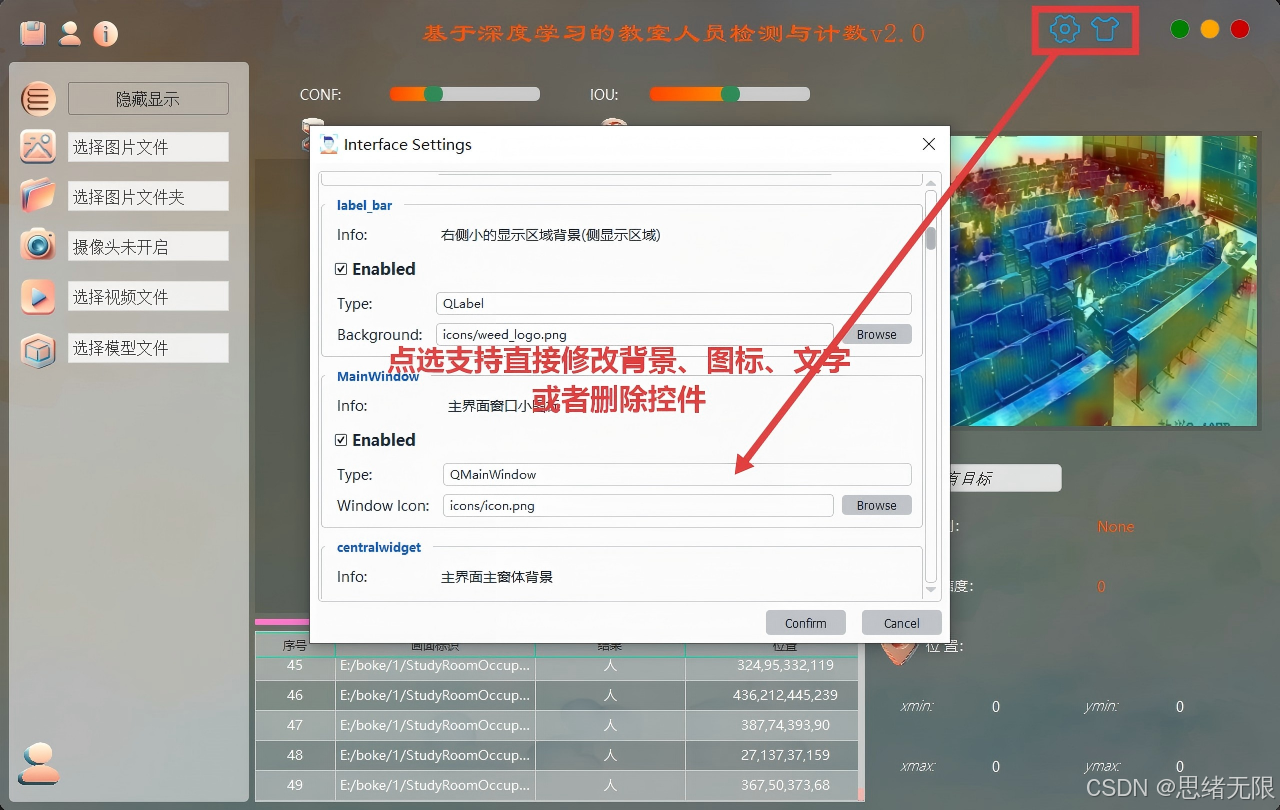
(4)主题修改功能:系统提供主题切换与视觉自定义能力(如亮色/暗色主题、主色调、背景图与图标风格),在不影响检测逻辑的前提下实现界面观感快速调整;主题配置随用户保存并在下次登录自动恢复,从而兼顾展示效果与长期使用的舒适性。
主题修改功能演示图
2. 数据集介绍
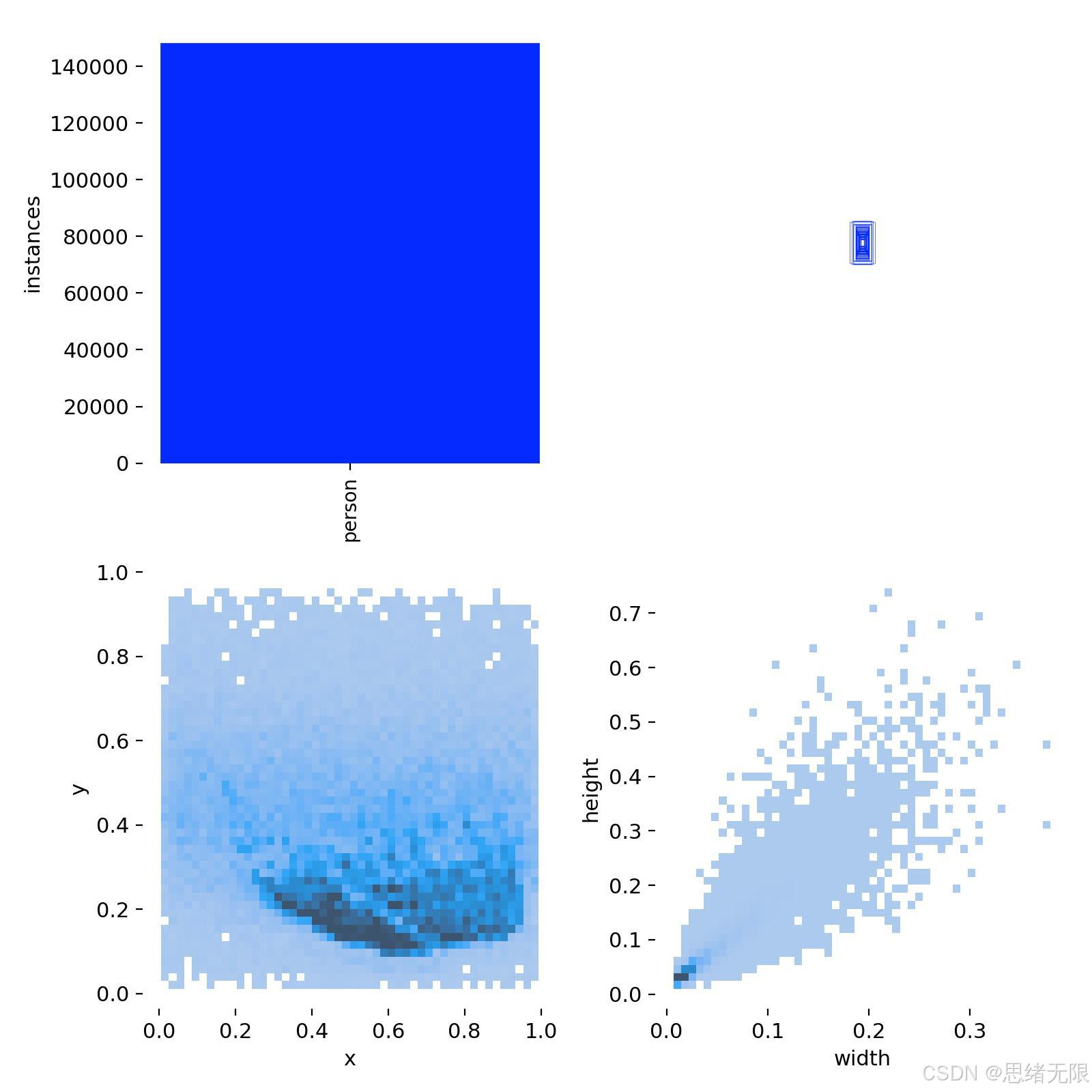
本项目面向教室/自习室场景的人员检测与计数任务,构建了一个单类别目标检测数据集,类别仅包含 person(中文标签为"人")。从你提供的标注可视化样例可以看到,数据覆盖了较丰富的真实课堂干扰因素:一方面存在固定机位带来的强透视效应,后排人物呈现明显的小目标与密集分布;另一方面光照条件差异显著(自然光、投影/屏幕反光、低照度与灰度画面并存),同时桌椅遮挡、同排遮挡与局部拥挤导致的"部分可见"样本较多。这类数据分布决定了模型训练的主要矛盾并不在"类别区分",而在于对小目标召回、遮挡鲁棒性与密集区域的定位稳定性。为了对 YOLOv5--YOLOv12 的跨版本能力做公平比较,本数据集统一采用 YOLO 检测标注范式(每个实例对应一个边界框),计数结果由检测到的 person 框数量直接得到,从而避免了密度回归类方法在实例级可解释性与工程导出上的不便。

python
Chinese_name = {'person': "人"}从标签统计图(labels)与相关性图(labels_correlogram)可见,标注框中心点在图像平面上呈现明显的空间聚集,主要集中在教室座位区的下半部与中右区域,这与固定摄像头俯视拍摄的构图一致;同时宽高分布呈现强烈的长尾特征,大量框的尺度偏小,反映出后排学生与远距离视角带来的"极小目标占比高"。在训练时,老思建议采用与 Ultralytics 训练脚本一致的输入规范:将图像按比例缩放并 letterbox 到 640 × 640 640\times640 640×640,同时对标注框做归一化;训练阶段启用 Mosaic、随机仿射、HSV 抖动与水平翻转等增强以提高密集与遮挡条件下的泛化能力,并在训练后期关闭 Mosaic 以减少几何扰动、提升收敛稳定性。这样的预处理与增强策略与教室场景的主要误差来源(远距离小目标与遮挡)具有较好的对齐性,也便于不同 YOLO 版本在同一数据处理链路上进行横向对比。
📊 数据集规格说明 (Dataset Specification)
| 维度 | 参数项 | 详细数据 |
|---|---|---|
| 基础信息 | 标注软件 | LabelImg |
| 标注格式 | YOLO TXT (Normalized) | |
| 数量统计 | 训练集 (Train) | 5,990 张 (70.0%) |
| 验证集 (Val) | 1,712 张 (20.0%) | |
| 测试集 (Test) | 855 张 (10.0%) | |
| 总计 (Total) | 8,557 张 | |
| 类别清单 | Class ID: 0 | person(人) |
| 图像规格 | 输入尺寸 | 640 * 640 |
| 数据来源 | 教室/自习室固定机位视频抽帧与场景化采集(人工清洗) |
3. 模型设计与实现
面向"教室人员检测与计数"这一目标任务,老思在模型层面的核心取舍是:检测必须在遮挡密集、尺度变化大、光照不均(背光、夜间红外)与视角极端(吊顶俯视、走廊斜视)等场景下保持稳定,而计数则要求检测结果在视频流中具有较小的抖动与可控的误检率。因此,本项目采用"检测为主、计数为辅"的建模方式:首先以单类目标检测(person)作为主任务输出边界框与置信度,其次在后处理阶段以阈值筛选后的有效检测框数量作为帧级计数,并在视频模式下提供可选的时间平滑策略以抑制瞬时波动(例如对计数序列做滑动窗口中位数/均值滤波)。在工程实现上,模型推理统一封装在 Detector 类中,通过 Ultralytics 接口加载 YOLOv5--YOLOv12 系列权重,输入来自摄像头/视频/图片/文件夹的帧在完成尺度归一与张量化后送入网络,输出经解码与(可选)NMS/NMS-free 逻辑得到最终检测框,并同步回传 UI 完成渲染与统计。(Ultralytics Docs)
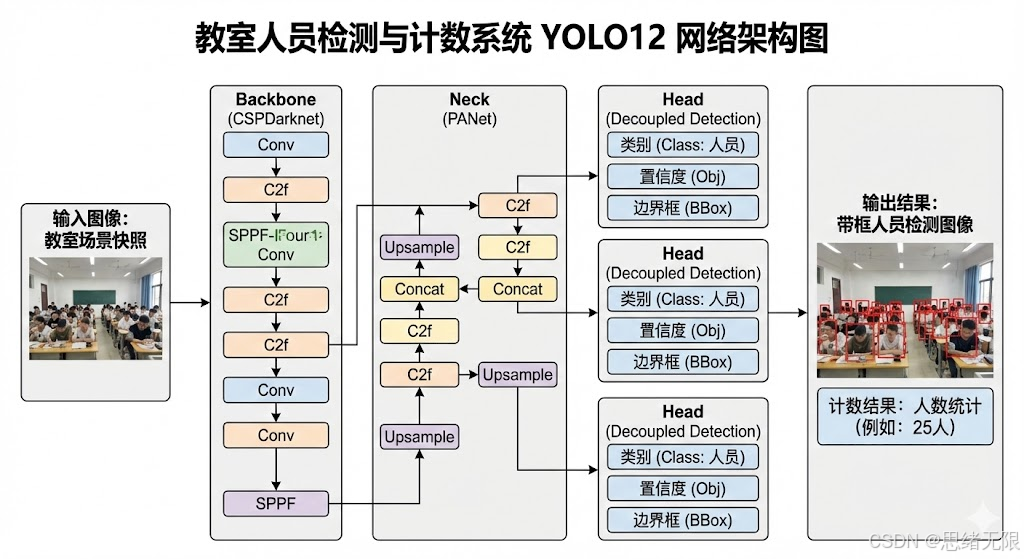
从架构演进角度看,YOLOv5 到 YOLOv12 的升级主线可以概括为:主干网络在保持分层特征提取的同时,不断强化梯度流与特征聚合的效率;颈部网络持续沿着 FPN/PAN 的多尺度融合范式优化;检测头则从早期的耦合式、Anchor-based、显式 objectness 分支,逐步转向解耦式、Anchor-free 与端到端推理友好的设计。以 YOLOv5 为起点,其典型结构由 CSP 系列主干与 PAN-FPN 颈部构成,检测头将分类、置信度与回归耦合在同一分支中,依赖预设锚框并在推理阶段通过 NMS 去重,这一设计在小目标密集的教室场景中容易因遮挡导致候选框高度重叠,从而对阈值与 NMS 超参更敏感。随后 YOLOv8 系列在保持整体范式不变的前提下,将骨干的核心模块替换为更利于梯度传递的结构,并将检测头改为解耦式,同时转向 Anchor-free 预测,使分类与回归的优化目标更"干净",在拥挤人群的边界框回归稳定性上通常更占优。(mmyolo.readthedocs.io)
进一步地,YOLOv10 的关键变化在于端到端友好的 NMS-free 思路:训练阶段保留"一对多"的丰富监督以提升召回,同时额外引入"一对一"分支用于推理期的唯一匹配,从而在部署侧减少对 NMS 的依赖并降低延迟;其一致性双重分配(dual assignment)的动机,本质上是让训练与推理的匹配目标尽可能对齐,避免"训练时依赖大量候选、推理时再强行筛掉"的目标偏移。(Ultralytics Docs) 这一点对于教室计数同样重要:当后处理链路更简洁、候选更一致时,计数对阈值扰动的敏感性往往更低。
在本博客的默认主模型选择上,我们以 YOLOv12n 作为"升级上限"的代表进行讲解与工程落地,但同时保留 YOLOv5--YOLOv11 的权重切换接口用于对比实验与部署权衡。YOLOv12 的突出特征是"注意力机制中心化"的网络设计:它尝试在维持 YOLO 实时性的约束下引入更强的全局建模能力,并通过更克制的注意力结构降低二次复杂度与显存访存开销。具体而言,YOLOv12 使用 Area Attention 将特征图按条带/区域进行等分重排,在保持较大感受野的同时避免复杂的窗口切分与重组操作;并提出 R-ELAN(Residual Efficient Layer Aggregation Networks)在聚合块级引入残差与缩放,缓解注意力模型在大尺度配置下的优化不稳定问题;同时在注意力实现上采用更高效的算子策略(如 FlashAttention 以减少显存读写瓶颈、移除显式位置编码并通过卷积式"位置感知"补偿位置信息)。(Ultralytics Docs) 这些设计对教室场景的直观价值在于:在强遮挡与复杂背景下,注意力模块更容易形成"人-人""人-桌椅"等上下文关系的全局依赖,从而在边界框回归与前景激活上表现得更集中,减少把桌椅边缘、黑板反光等误当作人体局部的概率。
损失函数与任务建模方面,本项目延续 Ultralytics 系列检测器的主流组合:分类分支以二元交叉熵(BCE)或其加权变体为基础,回归分支采用 IoU 类损失(如 CIoU)度量几何一致性,并引入分布式回归思想的 Distribution Focal Loss(DFL)提升边界定位精度。(Ultralytics Docs) 其中,若将边界回归的四个距离(左、上、右、下)离散为 0 , 1 , ... , R 0,1,\dots,R 0,1,...,R 个桶,并预测对应概率 p i p_i pi,则距离的期望解码为
d ^ = ∑ i = 0 R i ⋅ p i , \hat d=\sum_{i=0}^{R} i\cdot p_i, d^=i=0∑Ri⋅pi,
DFL 则通过对真实距离在相邻桶上的软分配,使回归从"直接拟合连续值"转为"学习更稳定的离散分布",在小尺度人体框(远景座位区)尤其常见收益。与之配合的 CIoU 可写为
L CIoU = 1 − IoU + ρ 2 ( b , b g t ) c 2 + α v , L_{\text{CIoU}} = 1-\text{IoU}+\frac{\rho^2(\mathbf{b},\mathbf{b}^{gt})}{c^2}+\alpha v, LCIoU=1−IoU+c2ρ2(b,bgt)+αv,
其中 ρ ( ⋅ ) \rho(\cdot) ρ(⋅) 表示预测框与真值框中心距离, c c c 是最小外接框对角线长度, v v v 刻画长宽比一致性, α \alpha α 为权重系数。样本分配策略上,Ultralytics/YOLOv8 之后的实现通常采用任务对齐(Task-Aligned)思想,通过分类置信与回归质量的联合指标选择正样本,例如
t = s α , u β , t=s^{\alpha},u^{\beta}, t=sα,uβ,
其中 s s s 为对应类别的预测分数, u u u 为预测框与真值框的 IoU, α , β \alpha,\beta α,β 控制两者的权重。(mmyolo.readthedocs.io) 对单类 person 检测而言,这类分配方式可以更直接地压制"高分类分但框很飘"的伪正样本,最终表现为计数更稳、误检更少。
工程实现层面,为了让 YOLOv5--YOLOv12 在同一套 PySide6 系统内可插拔切换,老思在代码结构上采用了"模型无关的推理接口 + 模型相关的权重与配置"分离策略:UI 层只关心 Detector.infer(frame, conf, iou) 的统一返回格式(边界框、类别、置信度),而具体是 YOLOv5 的耦合头 + NMS,还是 YOLOv10 的 NMS-free 分支,抑或 YOLOv12 的注意力骨干,都封装在 Detector 内部通过 Ultralytics YOLO(weights) 初始化与 model.predict(...) 调用完成。这样做的直接收益是:一方面,系统可在"准确率优先/速度优先/稳定性优先"的不同需求间快速切换模型;另一方面,也便于在同一数据集与同一 UI 交互逻辑下开展公平对比实验,为后续的结果分析章节提供一致的测评基线。(Ultralytics Docs)
4. 训练策略与模型优化
教室人员检测与计数的训练目标并不只是追求验证集 mAP 的数值抬升,更关键的是让模型在"远距离小目标、密集遮挡、光照域偏移"三类高频误差源下保持稳定输出,从而使计数结果在视频流中不出现明显抖动。为保证 YOLOv5 至 YOLOv12 的跨版本对比具有可重复性,老思在实验设计上尽量统一数据划分、输入尺寸、增强策略与学习率日程,仅在少数"版本实现差异较大"的环节(如 YOLOv10 的端到端推理习惯、不同版本默认损失与分配策略)保持框架默认,以避免人为改动造成额外变量。训练与推理均基于 Ultralytics 训练脚本完成,GPU 采用 RTX 4090,默认启用 AMP 混合精度以兼顾吞吐与显存占用;数据加载侧使用缓存与多进程 worker 减少 I/O 抖动,使"训练曲线波动"更接近模型本身的收敛特性而非管线瓶颈。
在初始化策略上,本项目默认加载 COCO 预训练权重进行迁移学习,这一点对教室场景尤为重要:单类 person 数据虽然标注量可观,但画面纹理与光照条件复杂,若从零训练往往会出现收敛慢、早期误检偏高的问题。微调阶段通常不建议长时间冻结骨干,因为教室画面与通用街景存在显著域差异;更稳妥的做法是在训练初期用较小学习率快速对齐检测头与高层语义,再逐步让全网络共同适配场景分布。为了抑制"密集遮挡下的重复框"和"极小目标漏检",训练过程中保留较强的数据增强(Mosaic、随机仿射、尺度抖动与颜色扰动),但在训练后期关闭 Mosaic,让模型在接近真实几何分布的样本上完成最终收敛,这通常能显著改善推理阶段框的位置稳定性与计数一致性。
优化器与学习率日程方面,默认采用框架自动选择(optimizer=auto),其在不同 YOLO 版本和不同规模(n/s/m)模型上往往能给出更稳健的初值;若需固定对比,可统一为 SGD+momentum 或 AdamW,并保持权重衰减一致。学习率采用带预热的余弦退火更适合本任务:预热用于抑制迁移学习初期的梯度震荡,余弦退火则在中后期缓慢降低学习率以获得更平滑的收敛轨迹,其形式可写为
η ( t ) = η min + 1 2 ( η 0 − η min ) ( 1 + cos ( π t T ) ) , \eta(t)=\eta_{\min}+\frac{1}{2}\big(\eta_{0}-\eta_{\min}\big)\left(1+\cos\left(\pi\frac{t}{T}\right)\right), η(t)=ηmin+21(η0−ηmin)(1+cos(πTt)),
其中 t t t 为当前迭代步, T T T 为总迭代步, η 0 \eta_0 η0 与 η min \eta_{\min} ηmin 分别对应初始与末端学习率。与此同时,EMA(指数滑动平均)在人员检测任务上通常能提升验证阶段的稳定性,表现为 PR 曲线更平滑、同等阈值下误检波动更小;早停(patience)用于防止"后期过拟合导致计数偏移",尤其是在数据存在明显机位偏置时更为必要。
面向部署的模型优化主要围绕"速度与计数稳定性"展开。训练侧可通过更贴近部署分辨率的输入尺寸(默认 640 × 640 640\times640 640×640)减少推理时的尺度迁移;若教室机位较高、远端小目标占比极大,可在不超出显存的前提下将 imgsz 提升到 768 或 960,以换取小目标召回,但需要同时关注延迟与 UI 实时性。推理侧建议在保持同一 conf 与 iou 策略的前提下进行版本对比:对 YOLOv5/8/11 等依赖 NMS 的模型,iou 过低会导致密集区域被过度抑制而漏计,过高则重复框增多而多计;对 YOLOv10 这类更端到端的推理风格,应优先保证训练与导出链路一致,避免在导出后引入额外后处理而破坏其"一对一"输出假设。最终部署时,若目标是实时摄像头计数,建议启用 FP16,并优先选择 ONNX/TensorRT 等后端以降低帧间延迟波动,从而让"计数曲线"在时间轴上更稳定。
为便于复现实验,本文默认使用的关键训练超参数如下(可直接对应到 Ultralytics 的 train 配置)。
| 名称 | 作用(简述) | 数值 |
|---|---|---|
| epochs | 最大训练轮数 | 120 |
| patience | 早停耐心 | 50 |
| batch | 批大小 | 16 |
| imgsz | 输入分辨率 | 640 |
| pretrained | 预训练权重 | true |
| optimizer | 优化器 | auto |
| lr0 | 初始学习率 | 0.01 |
| lrf | 末端学习率比例 | 0.01 |
| momentum | 动量系数 | 0.937 |
| weight_decay | 权重衰减 | 0.0005 |
| warmup_epochs | 预热轮数 | 3.0 |
| mosaic | Mosaic 强度/概率 | 1.0 |
| close_mosaic | 后期关闭 Mosaic | 10 |
5. 实验与结果分析
本节实验以"教室人员检测与计数"为目标,统一在同一数据划分(Train/Val/Test = 5990/1712/855)与同一输入分辨率( 640 × 640 640\times640 640×640)下,对 YOLOv5--YOLOv12 系列进行横向评估。计数策略采用实例级检测计数:对每帧输出的 person 框在置信度阈值 τ \tau τ 与 IoU 阈值 γ \gamma γ 的约束下完成筛选与去重,最终人数记为有效检测框个数。对比的核心目的并不只是追求单一指标最优,而是回答两个更工程化的问题:其一,在密集遮挡与小目标占比高的教室画面中,哪些模型在高召回区域仍能维持较低误检,从而保证计数稳定;其二,在可视化系统实时推理约束下,精度提升是否值得以参数规模与延迟为代价。
度量指标方面,检测性能采用 Precision、Recall、 F 1 F_1 F1、mAP@0.5 与 mAP@0.5:0.95(记为 mAP50-95);其中
F 1 = 2 P R P + R , F_1=\frac{2PR}{P+R}, F1=P+R2PR,
用于刻画误检(Precision)与漏检(Recall)之间的折中,更贴近"计数偏差"的直观来源。推理效率则统计单帧预处理、网络前向与后处理耗时(Pre/Inf/Post),并给出总延迟 T = Pre + Inf + Post T=\text{Pre}+\text{Inf}+\text{Post} T=Pre+Inf+Post。需要说明的是,你提供的耗时统计来自 NVIDIA GeForce RTX 3070 Laptop GPU (8GB) 的实际评测日志,因此绝对数值会随硬件变化,但模型间相对趋势仍具有参考意义。
5.1 单模型阈值选择与收敛性分析
在人员检测计数任务中,置信度阈值 τ \tau τ 是最敏感的工程超参数之一: τ \tau τ 过低会引入桌椅边缘、遮挡人体局部等伪检从而"多计"; τ \tau τ 过高则会漏掉远端小目标与遮挡目标从而"少计"。从你给出的 F1-Confidence 曲线可以直接读出一个可用的默认设置:当 τ ≈ 0.402 \tau\approx0.402 τ≈0.402 时取得峰值 F 1 ≈ 0.94 F_1\approx0.94 F1≈0.94,说明该阈值附近能够在误检与漏检之间取得较稳定的平衡,适合作为 UI 的默认置信度起点(后续再由用户按场景调节)。
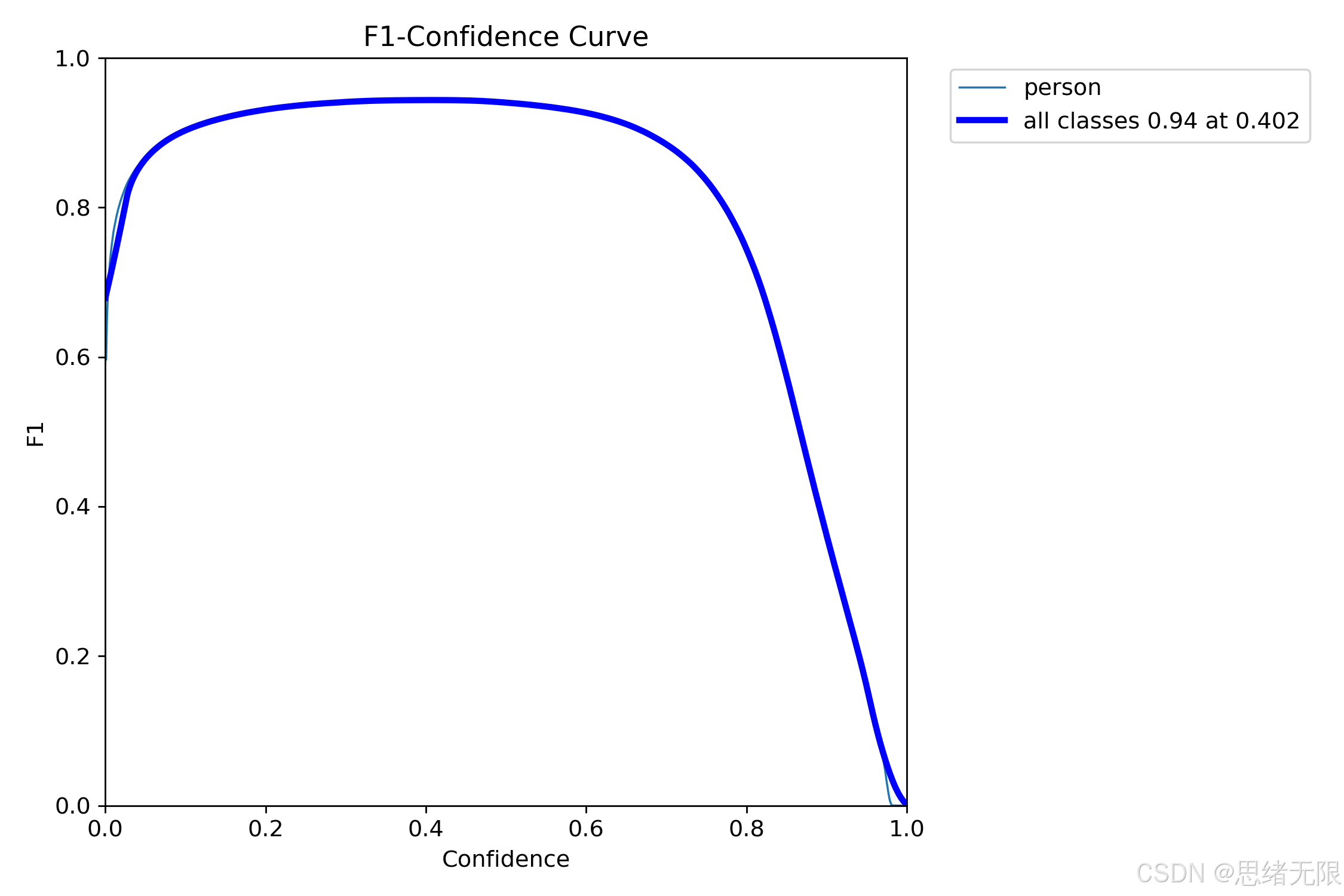
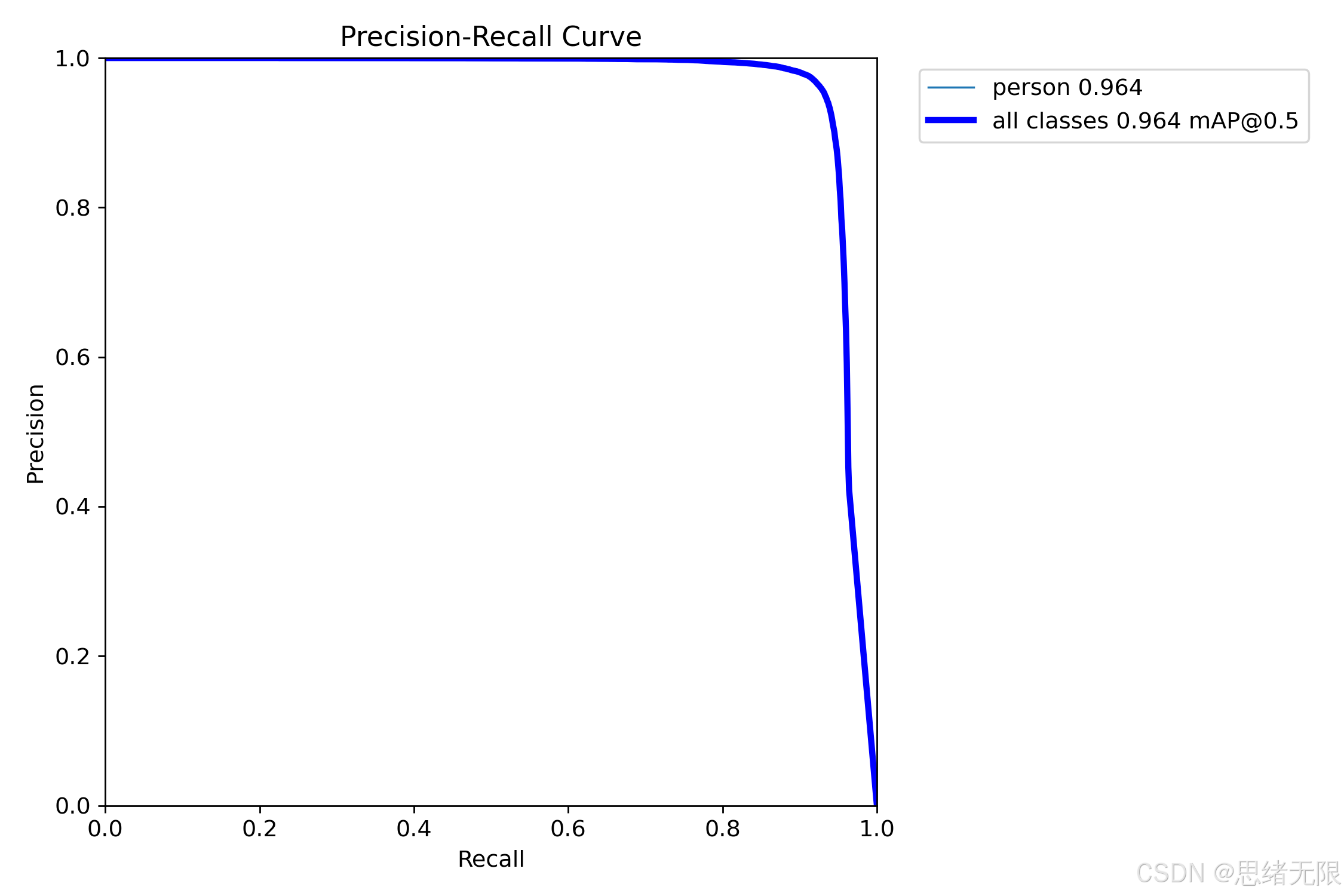
与之对应的 PR 曲线显示,模型在大部分召回区间内 Precision 维持在接近 1 的水平,直到 Recall 接近 1 时才快速下坠;这意味着在该数据分布下,"把召回推到极限"需要付出显著的误检代价。对计数系统而言,这种形态反而是可控的:将阈值设在 0.35 ∼ 0.45 0.35\sim0.45 0.35∼0.45 的区间通常即可获得较高的稳定性,而无需用极低阈值换取边际召回。图中给出的 mAP@0.5 为 0.964(单类 person),说明整体检测上界较高。
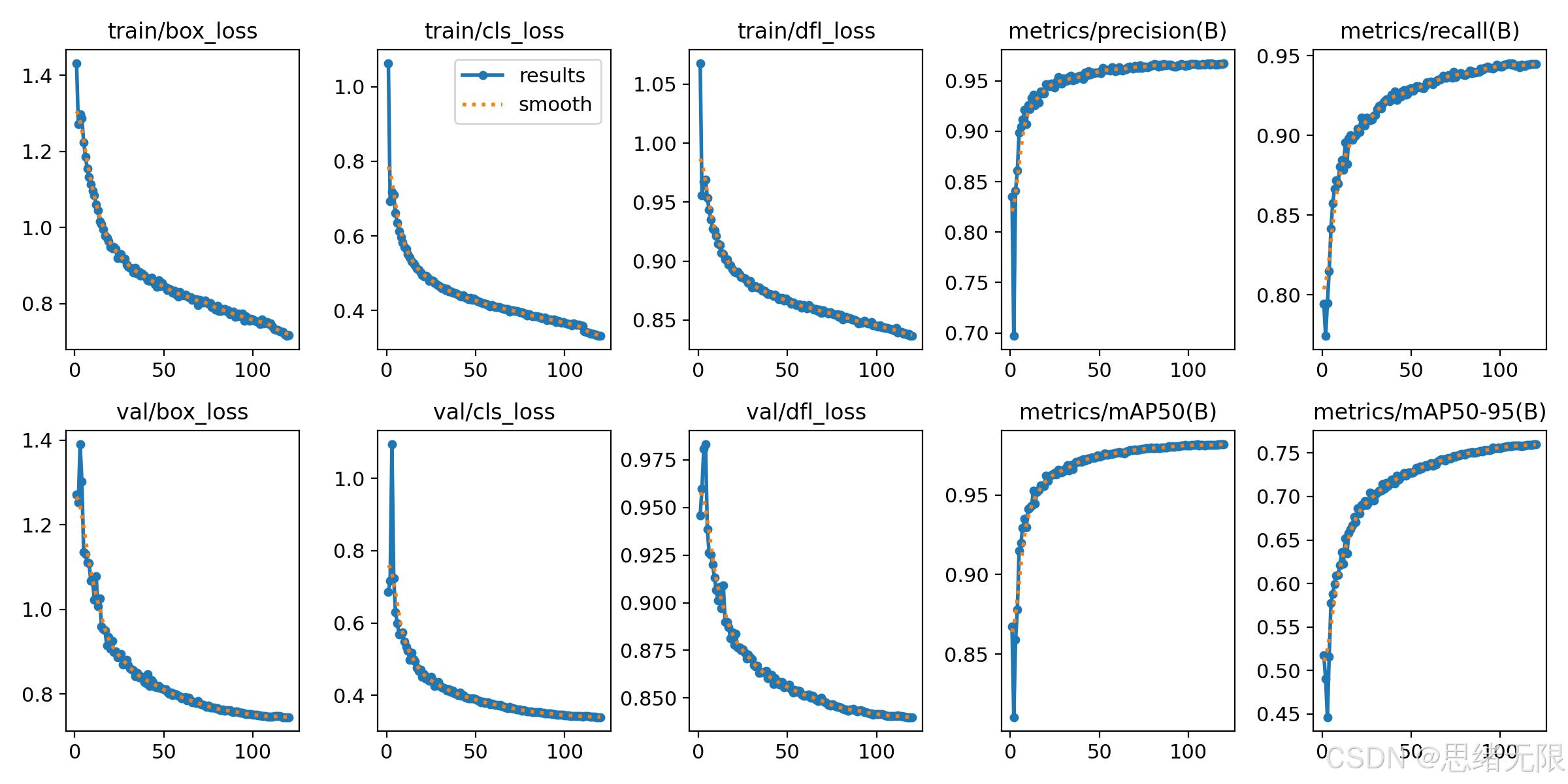
训练过程的收敛性可由损失曲线与验证指标曲线共同判断。你提供的训练可视化结果显示:train/box_loss、train/cls_loss、train/dfl_loss 与相应的验证损失均呈持续下降并逐渐趋于平稳的形态,且验证指标(Precision、Recall、mAP50、mAP50-95)在前 30--50 个 epoch 内快速上升,随后进入缓慢爬升阶段;这类曲线一般意味着优化过程稳定、未出现明显的后期"指标回落型过拟合"。从工程视角看,这也解释了为什么在计数系统中采用早停(patience)往往更合理:当 mAP 曲线进入平台期后继续训练的收益很有限,但会增加训练成本。
5.2 多模型对比实验结果(n 型轻量模型)
在 n 型轻量模型组中,YOLOv5nu、YOLOv6n、YOLOv7-tiny、YOLOv8n、YOLOv9t、YOLOv10n、YOLOv11n、YOLOv12n 的整体精度都处于高位,但差异主要体现在两个维度:其一是 F 1 F_1 F1 与 mAP50 的微小差距是否足以抵消推理延迟的上升;其二是 mAP50-95(更严格的定位质量指标)是否对密集遮挡下的重复框抑制更有利。横向柱状图直观展示了这一点:大部分模型的 mAP50 都接近 0.97, F 1 F_1 F1 也集中在 0.92--0.94 之间,说明在该数据集上"版本差距"更多表现为工程权衡而非代际碾压。
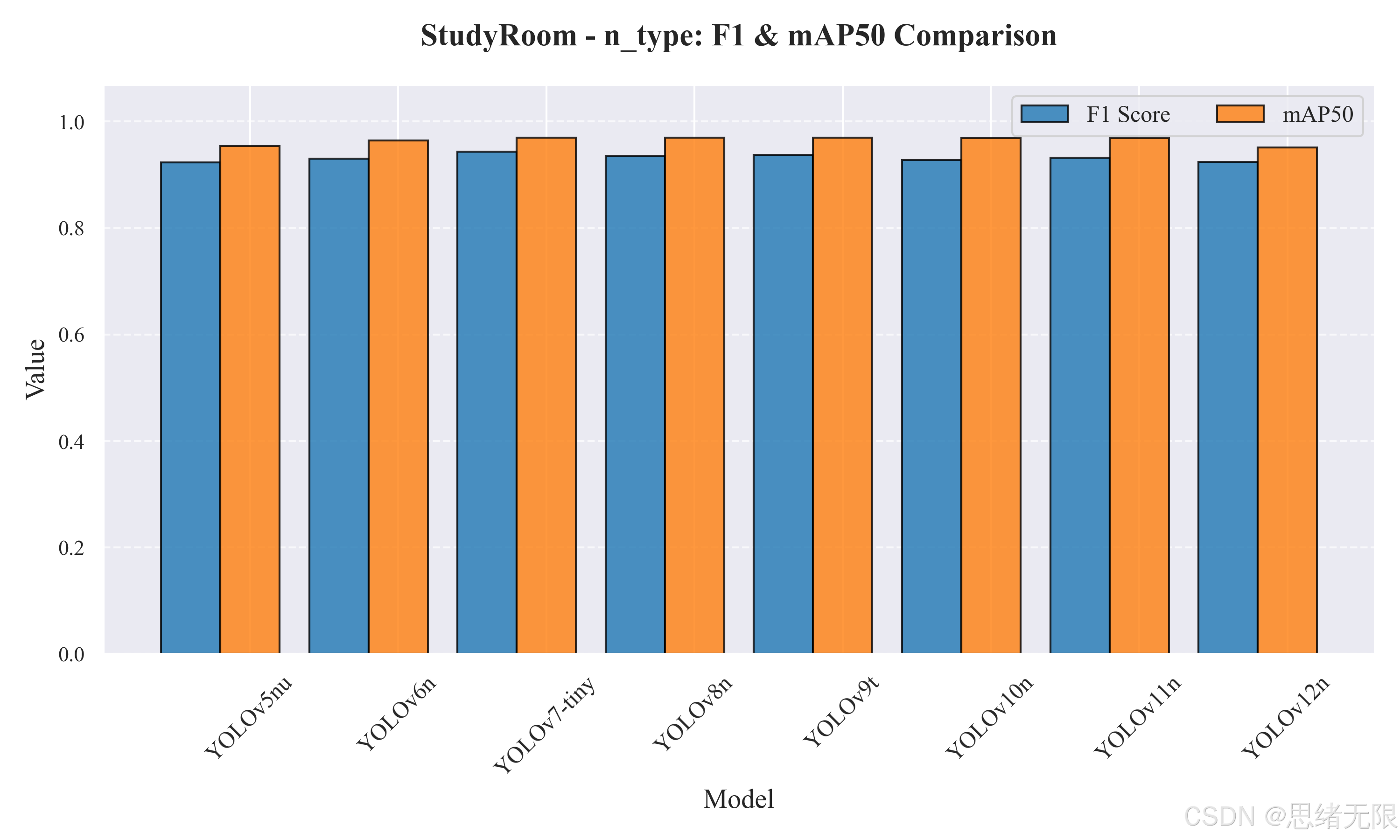
为了避免仅凭柱状图做定性判断,表 5-1 汇总了你提供的 n 型评测日志(含参数量、计算量、关键指标与单帧总延迟)。可以看到,YOLOv7-tiny 在 F 1 F_1 F1 与 mAP50 上取得最高值( F 1 = 0.943 F_1=0.943 F1=0.943,mAP50=0.970),但其总延迟显著偏高;YOLOv8n 在延迟最低的同时给出接近最优的 mAP50 与较高 F 1 F_1 F1,因此更符合"实时计数 UI"的默认选型;YOLOv10n 的 mAP50-95 最优(0.714),这通常意味着定位质量更稳定,在密集遮挡区域更不易出现框漂移与重复框,但其延迟较 YOLOv8n 有一定增加。YOLOv12n 在该组上 mAP50 偏低(0.951),更像是"需要更贴合该场景的训练细节(例如更长 schedule 或更高分辨率)"才能释放优势的情况;从 PR 曲线形态上看,它在高召回端更早出现精度下滑,也会放大计数抖动风险。
表 5-1 n 型模型在 StudyRoom 数据集上的综合对比(测试集)
| Model | Params(M) | FLOPs(G) | F1 Score | mAP50 | mAP50-95 | TotalTime(ms) |
|---|---|---|---|---|---|---|
| YOLOv5nu | 2.6 | 7.7 | 0.923 | 0.954 | 0.690 | 10.94 |
| YOLOv6n | 4.3 | 11.1 | 0.930 | 0.964 | 0.700 | 10.34 |
| YOLOv7-tiny | 6.2 | 13.8 | 0.943 | 0.970 | 0.646 | 21.08 |
| YOLOv8n | 3.2 | 8.7 | 0.936 | 0.970 | 0.709 | 10.17 |
| YOLOv9t | 2.0 | 7.7 | 0.937 | 0.969 | 0.698 | 19.67 |
| YOLOv10n | 2.3 | 6.7 | 0.928 | 0.969 | 0.714 | 13.95 |
| YOLOv11n | 2.6 | 6.5 | 0.932 | 0.969 | 0.707 | 12.97 |
| YOLOv12n | 2.6 | 6.5 | 0.924 | 0.951 | 0.695 | 15.75 |
从训练过程的 mAP50 演化曲线看,各模型在前 10--20 个 epoch 内迅速逼近高位,之后进入缓慢提升阶段。值得注意的是,YOLOv10n 在最初几个 epoch 的指标明显偏低,随后快速追平并稳定在较高水平,这与端到端训练范式更依赖稳定样本分配与学习率预热的经验现象一致;对工程复现而言,意味着 YOLOv10n 更需要严格遵守统一的预热与增强配置,否则早期震荡更容易放大。
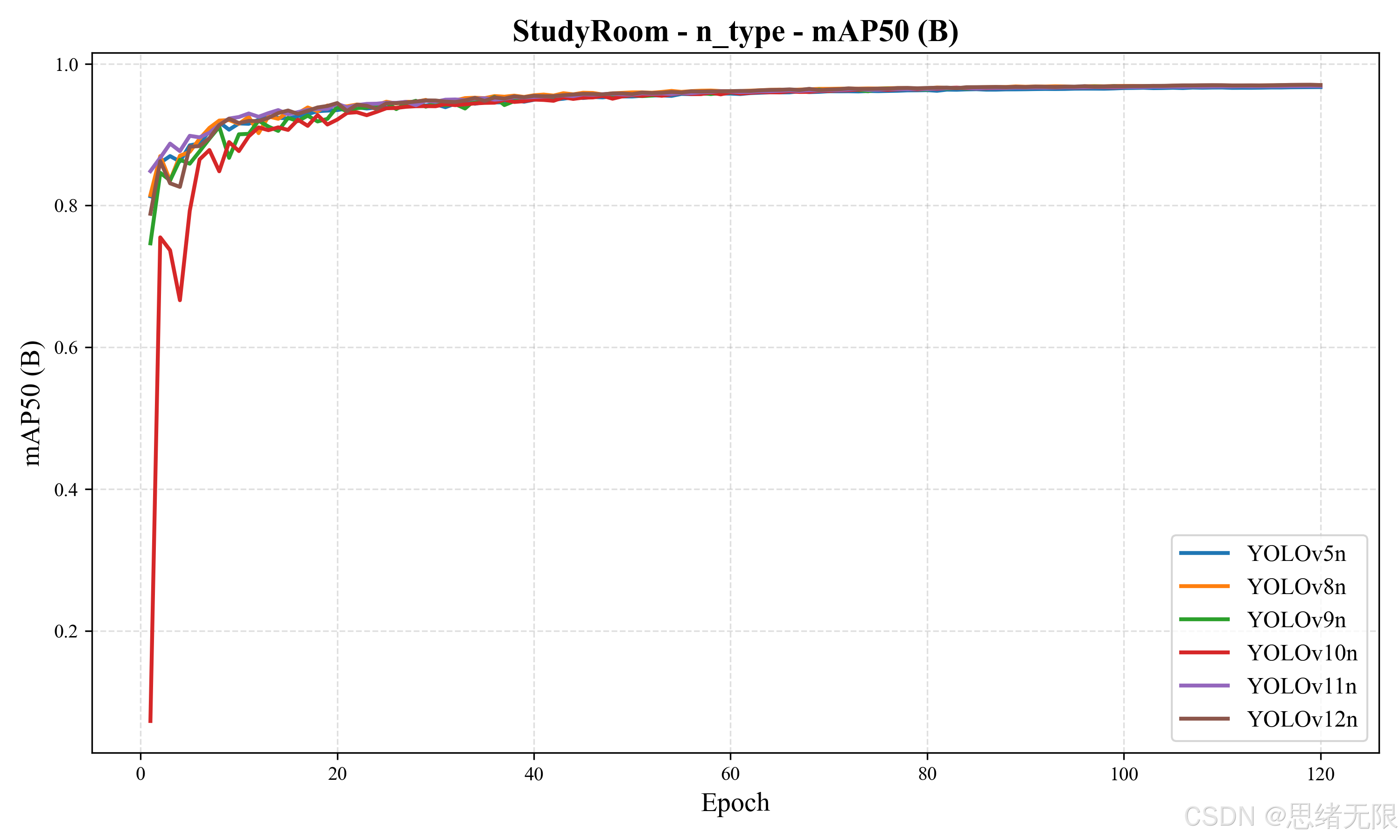
结合"实时 UI + 计数稳定性"的目标,老思更倾向将 YOLOv8n 作为 n 型默认部署模型:它在该数据集上几乎不牺牲 mAP50,却显著降低延迟;若在密集遮挡的座位区出现"框抖动/重复框"导致计数波动,则可进一步尝试 YOLOv10n 或 YOLOv11n,以更高的 mAP50-95 换取更稳的定位质量。
5.3 多模型对比实验结果(s 型模型)
在 s 型模型组中,整体精度进一步抬升,且 mAP50-95 普遍高于 n 型,这在"远端小目标定位"与"遮挡边界框回归"上通常更有收益。柱状图显示,各模型的 F 1 F_1 F1 与 mAP50 差异依然不大,但 s 型组整体更靠近 1,说明增加容量后模型对复杂光照与遮挡模式的拟合更充分。
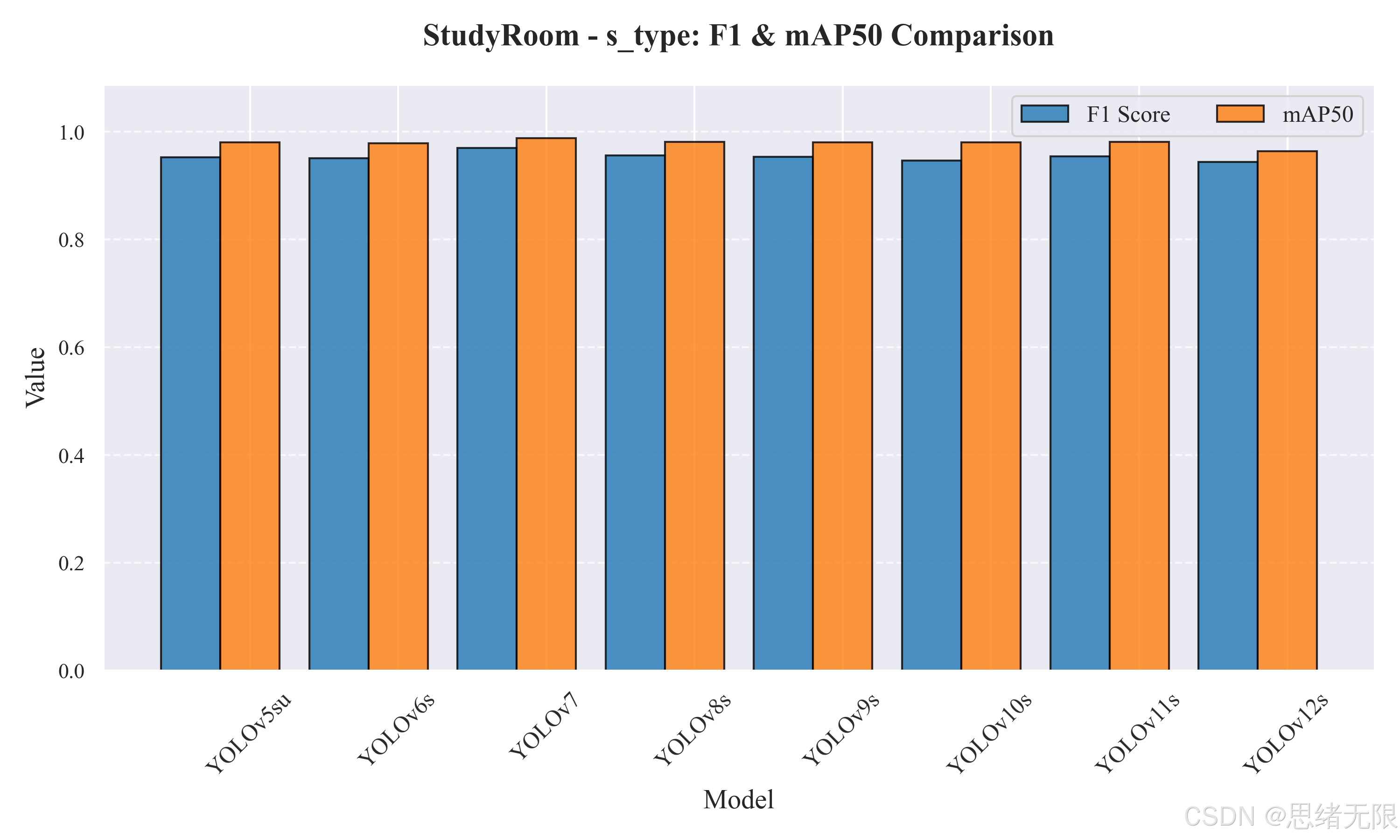
表 5-2 给出 s 型综合对比。YOLOv7 在 F 1 F_1 F1(0.970)与 mAP50(0.988)上取得最高,但其参数量与计算量远高于其它模型,并直接反映为显著的推理延迟(约 29.5ms/帧),对实时计数界面会带来更明显的卡顿风险;与之相比,YOLOv8s 在保持较低延迟的同时取得该组最高的 mAP50-95(0.758),意味着它在严格 IoU 条件下的定位质量更好,往往更利于减少密集场景的"重复计数"。YOLOv10s 与 YOLOv11s 的 mAP50-95 接近 YOLOv8s,且延迟仍可接受,是偏向"定位更稳"的备选;YOLOv12s 在该组同样表现出 mAP50 与 F 1 F_1 F1 下滑,更像是需要进一步贴合数据分布的训练设定才能恢复优势。
表 5-2 s 型模型在 StudyRoom 数据集上的综合对比(测试集)
| Model | Params(M) | FLOPs(G) | F1 Score | mAP50 | mAP50-95 | TotalTime(ms) |
|---|---|---|---|---|---|---|
| YOLOv5su | 9.1 | 24.0 | 0.953 | 0.981 | 0.751 | 12.24 |
| YOLOv6s | 17.2 | 44.2 | 0.951 | 0.978 | 0.749 | 12.26 |
| YOLOv7 | 36.9 | 104.7 | 0.970 | 0.988 | 0.752 | 29.52 |
| YOLOv8s | 11.2 | 28.6 | 0.956 | 0.982 | 0.758 | 11.39 |
| YOLOv9s | 7.2 | 26.7 | 0.954 | 0.980 | 0.749 | 22.17 |
| YOLOv10s | 7.2 | 21.6 | 0.947 | 0.981 | 0.756 | 14.19 |
| YOLOv11s | 9.4 | 21.5 | 0.954 | 0.981 | 0.756 | 13.47 |
| YOLOv12s | 9.3 | 21.4 | 0.944 | 0.964 | 0.743 | 16.74 |
从 s 型的 mAP50 收敛曲线看,模型间在早期的上升速度与后期的平台高度差异很小,说明在该数据集规模下,多数模型已经能较快捕获"教室人员"的主要视觉模式;因此工程上更值得关注的是"高召回端的误检控制",即 PR 曲线在靠近右端的下坠位置。
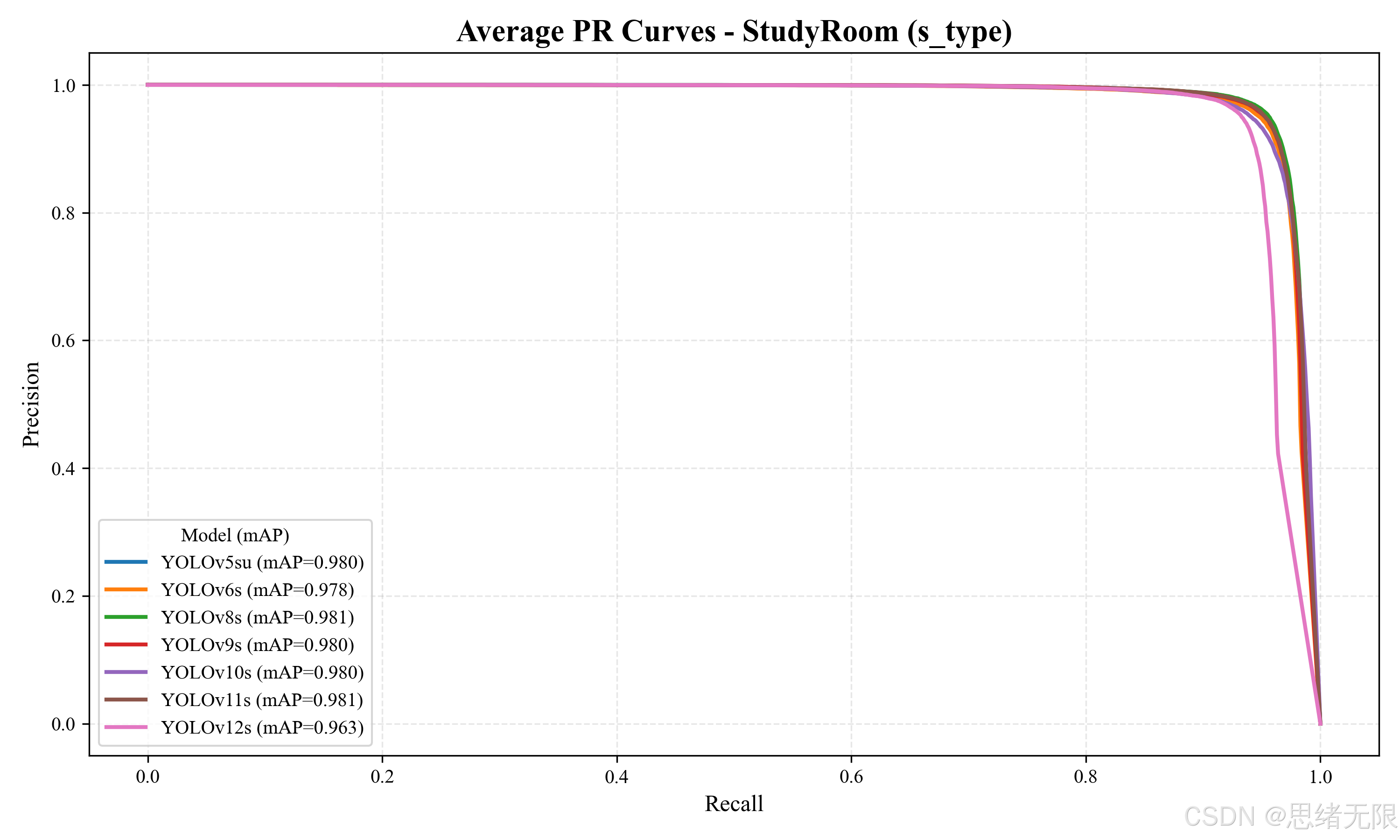
综合精度、定位质量与实时性,老思更倾向将 YOLOv8s 作为 s 型的优先推荐:它在 mAP50-95 上给出该组最好结果,同时延迟最低,适合在"需要更稳计数、但仍希望接近实时"的场景使用;若仅追求离线最高精度,可以选择 YOLOv7,但需要接受更高的推理成本,并在系统端采取降帧或异步推理以避免界面阻塞。
6. 系统设计与实现
6.1 系统设计思路
本项目以"可复现的人员检测与计数"为主线,将算法推理与界面交互解耦:界面层负责输入源管理、参数交互与可视化呈现,处理层负责模型加载、推理与后处理。整体采用典型的三层对象组合方式组织模块:MainWindow 作为控制中枢负责状态机与槽函数调度,Ui_MainWindow 负责控件布局与主题渲染,Detector 负责统一封装 YOLOv5--YOLOv12 权重的加载与推理接口。这样的分层使得模型版本升级不会破坏 UI 逻辑,同时也便于后续加入新的后端(ONNX/TensorRT)或扩展新的输入源。
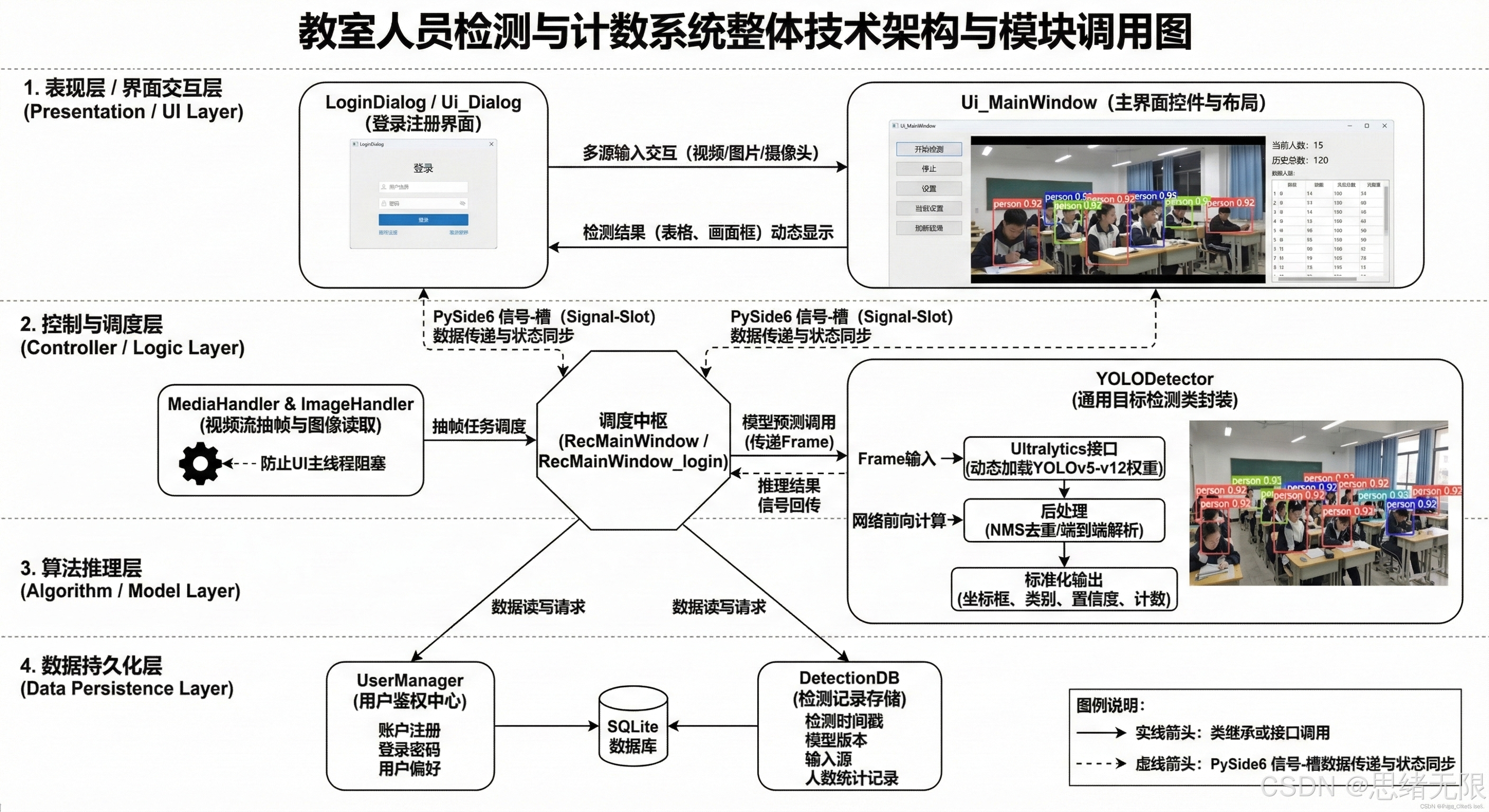
在跨层通信上,系统以 PySide6 的信号-槽机制作为"弱耦合契约":输入线程/定时器产生帧数据后发射信号,Detector 完成推理并返回标准化结果(框坐标、类别、置信度与计数),最终由 MainWindow 统一驱动界面更新与统计面板刷新。对于视频与摄像头模式,推理循环被设计为"可暂停、可停止、可保存"的状态机,避免 UI 阻塞;对于图片与文件夹模式,推理流程保持一致,仅将数据源从流式帧替换为批量迭代,保证操作体验一致性。
数据持久化采用 SQLite:一方面用于账户体系(注册/登录/修改资料/注销/切换账号),另一方面用于检测记录的结构化存储(时间戳、输入源、模型版本、阈值、计数结果与导出路径等)。这样做的直接收益是"每个用户独立配置与结果空间",并且能在系统重启后恢复上次使用习惯(默认模型、Conf/IoU、主题),从而把实验平台与工程应用融合到同一个桌面端框架中。
图 系统流程图
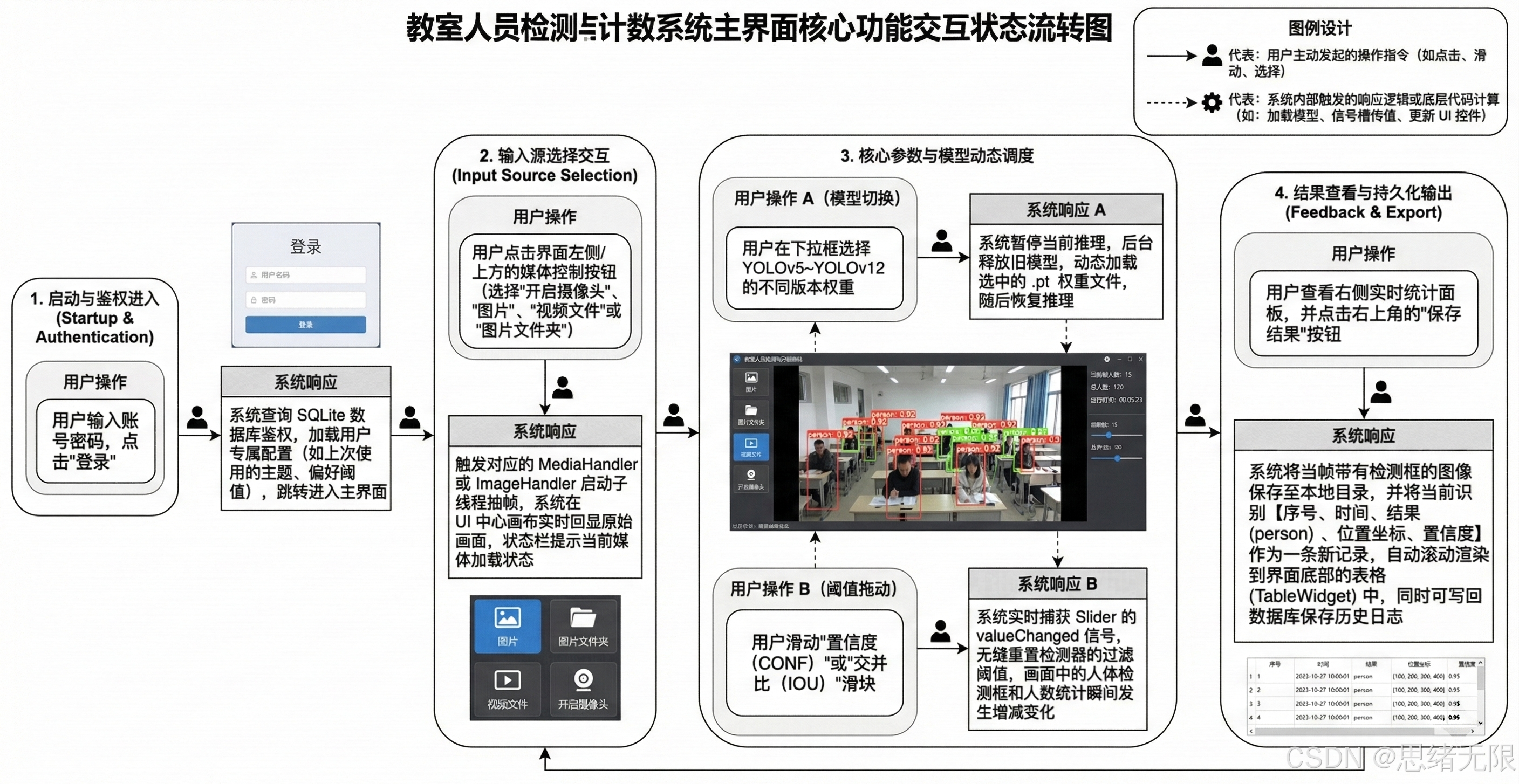
图注:系统从初始化到多源输入,完成预处理、推理与界面联动,并通过交互形成闭环。
6.2 登录与账户管理
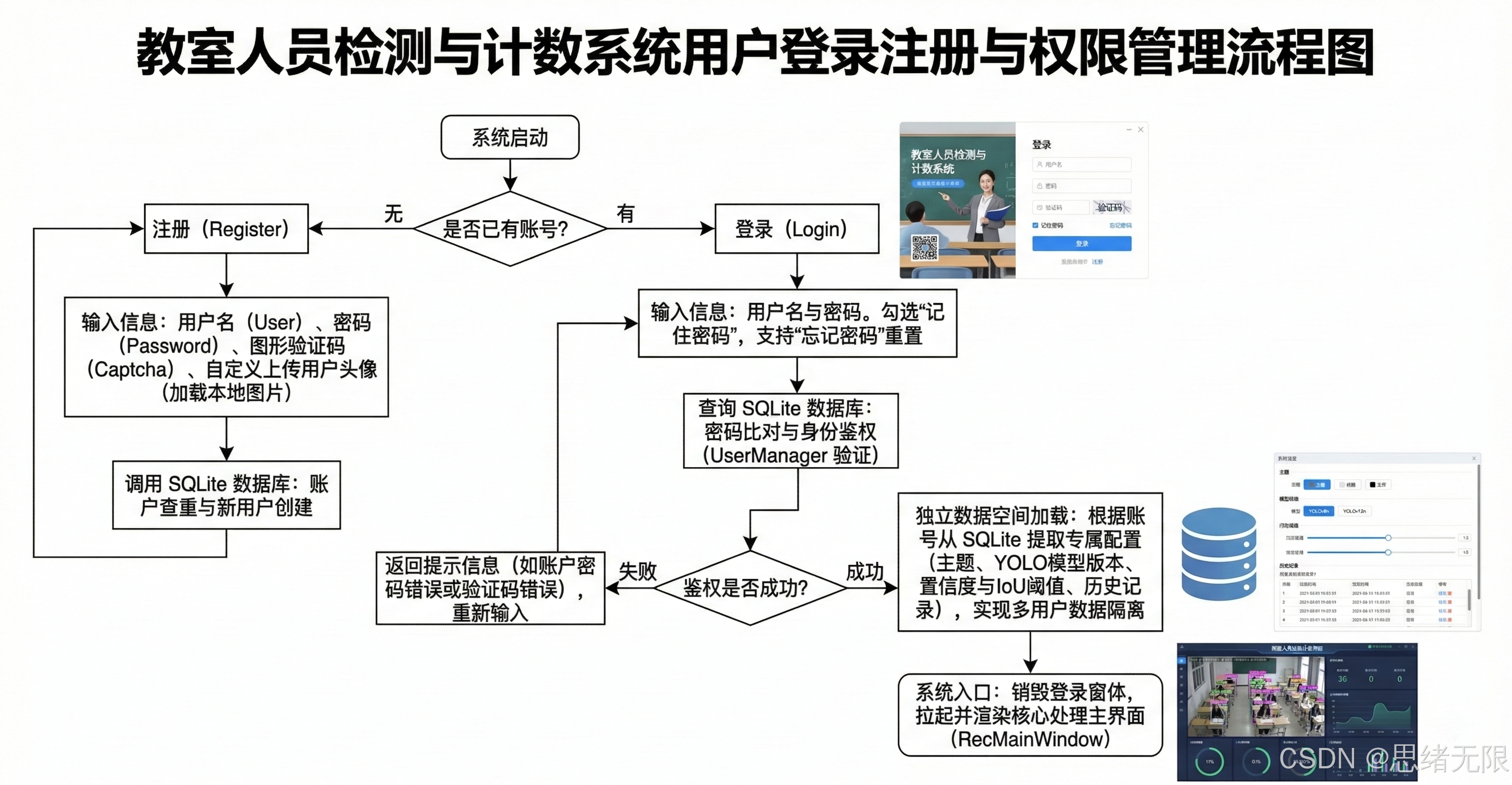
登录与账户管理模块在系统中承担"入口鉴权与个性化持久化"的双重角色:用户在登录/注册完成后,系统会从 SQLite 读取并恢复其主题、默认模型与阈值等偏好,同时加载历史检测记录以支持回溯与筛选导出;当用户在主界面修改头像或密码时,更新操作以事务方式写回数据库,确保配置与结果在多次启动间一致,从而使检测流程与账户体系形成自然衔接------既保证不同用户的结果空间互不干扰,又让长期使用时的交互成本显著降低。
7. 下载链接
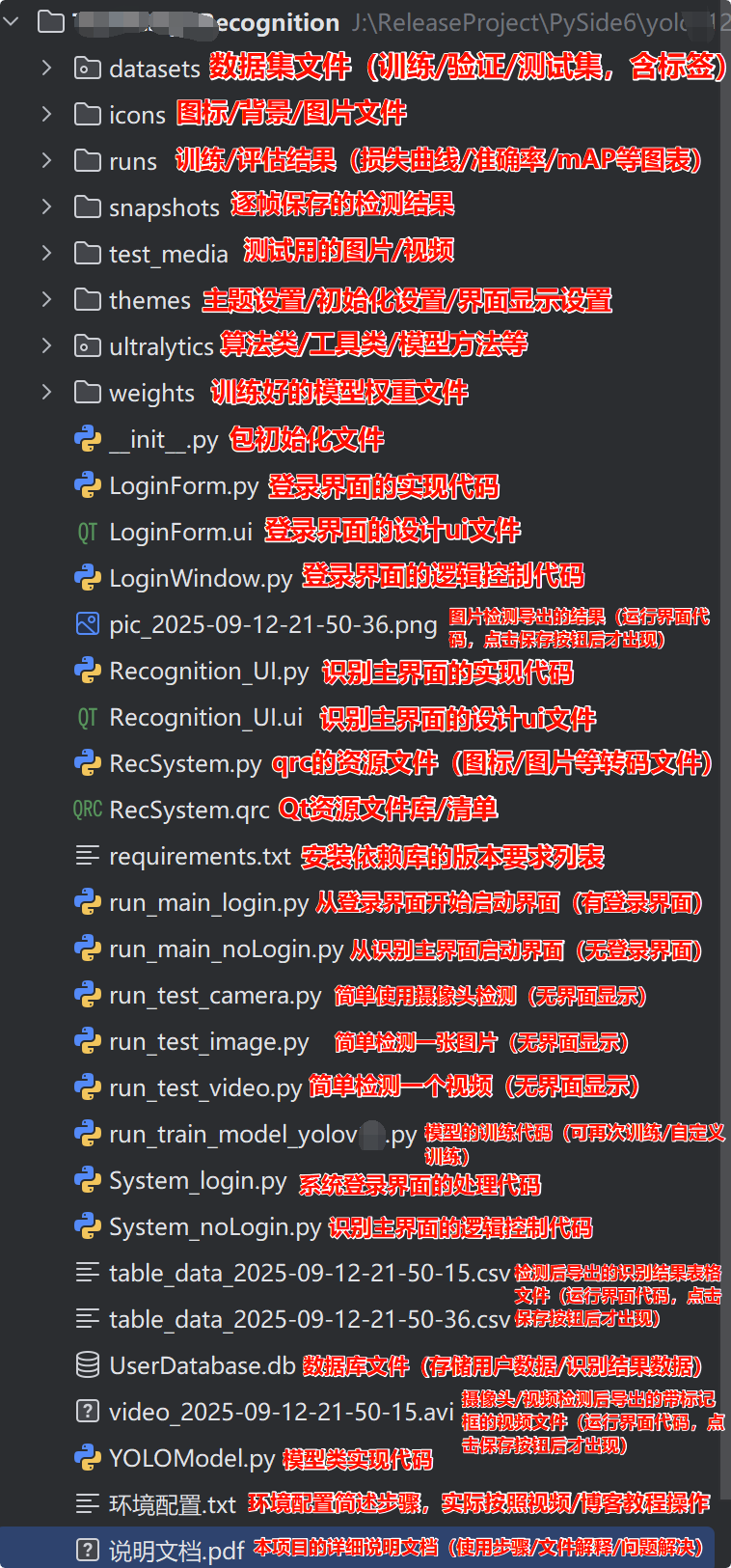
若您想获得博文中涉及的实现完整全部资源文件 (包括测试图片、视频,py, UI文件,训练数据集、训练代码、界面代码等),这里见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频:➷➷➷
详细介绍文档博客: YOLOv5至YOLOv12升级:教室人员检测与计数系统的设计与实现(完整代码+界面+数据集项目)
环境配置博客教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境配置教程;
或者环境配置视频教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境依赖配置教程
数据集标注教程(如需自行标注数据):数据标注合集
8. 参考文献(GB/T 7714)
1 FAN Z, ZHANG H, ZHANG Z, et al. A survey of crowd counting and density estimation based on convolutional neural networkJ. Neurocomputing , 2022, 472: 224-251. DOI:10.1016/j.neucom.2021.02.103.
2 LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common Objects in ContextC//FLEET D, PAJDLA T, SCHIELE B, TUYTELAARS T, eds. Computer Vision -- ECCV 2014 . Cham: Springer, 2014: 740-755. DOI:10.1007/978-3-319-10602-1_48.
3 REN S, HE K, GIRSHICK R, SUN J. Faster R-CNN: Towards real-time object detection with region proposal networksJ. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017, 39(6): 1137-1149. DOI:10.1109/TPAMI.2016.2577031.
4 LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single Shot MultiBox DetectorC//Computer Vision -- ECCV 2016 . Cham: Springer, 2016: 21-37. DOI:10.1007/978-3-319-46448-0_2.
5 REDMON J, DIVVALA S, GIRSHICK R, FARHADI A. You Only Look Once: Unified, real-time object detectionC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016: 779-788. DOI:10.1109/CVPR.2016.91.
6 LIN T Y, DOLLÁR P, GIRSHICK R, HE K, HARIHARAN B, BELONGIE S. Feature Pyramid Networks for Object DetectionC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017: 2117-2125. DOI:10.1109/CVPR.2017.106.
7 LI Y, ZHANG X, CHEN D. CSRNet: Dilated convolutional neural networks for understanding the highly congested scenesC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018: 1091-1100. DOI:10.1109/CVPR.2018.00120.
8 SHAO S, ZHAO Z, LI B, et al. CrowdHuman: A Benchmark for Detecting Human in a CrowdJ/OL. arXiv:1805.00123, 2018.
9 CARION N, MASSA F, SYNNAEVE G, et al. End-to-End Object Detection with TransformersC//Computer Vision -- ECCV 2020 . Cham: Springer, 2020: 213-229. DOI:10.1007/978-3-030-58452-8_13.
10 ZHANG Y, SUN P, JIANG Y, et al. ByteTrack: Multi-Object Tracking by Associating Every Detection BoxC//Computer Vision -- ECCV 2022 . Cham: Springer, 2022. DOI:10.1007/978-3-031-20047-2_1.
11 丛帅, 杨磊, 华征豪, 杨晓晖. 基于目标检测和迁移时间序列的教室人员检测J. 河北大学学报(自然科学版) , 2023, 43(4): 432-441.
12 GUPTA P, SINGH M. Evaluation of several YOLO architecture versions for person detection and countingJ. Multimedia Tools and Applications , 2025.
13 WANG C Y, YEH I H, LIAO H Y M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient InformationJ/OL. arXiv:2402.13616, 2024. DOI:10.48550/arXiv.2402.13616.
14 WANG A, CHEN H, LIU L, et al. YOLOv10: Real-Time End-to-End Object DetectionJ/OL. arXiv:2405.14458, 2024. DOI:10.48550/arXiv.2405.14458.
15 TIAN Y, YE Q, DOERMANN D. YOLOv12: Attention-Centric Real-Time Object DetectorsJ/OL. arXiv:2502.12524, 2025. DOI:10.48550/arXiv.2502.12524.