目录
[一.LangGraph 的其他特性](#一.LangGraph 的其他特性)
[1.使用 Overwrite 绕过 reducer](#1.使用 Overwrite 绕过 reducer)
[三.提示链模式(Prompt Chaining)](#三.提示链模式(Prompt Chaining))
六.协调者-工作者模式(Orchestrator-Workers)
七.评估器-优化器模式(Evaluator-optimizer)
一.LangGraph 的其他特性
1.使用 Overwrite 绕过 reducer

cpp
import operator
from typing import TypedDict, Annotated
from langgraph.constants import START,END
from langgraph.graph import StateGraph
from langgraph.types import Overwrite
import os
os.environ["LANGCHAIN_TRACING_V2"] = "false"
class State(TypedDict):
message: Annotated[list[str],operator.add]
#节点一.追加消息
def add_message(state: State):
return {"message": ["first message"]}
#节点二.覆盖消息
def replace_message(state: State):
return {"message": Overwrite(["replace message"])} #用新的列表覆盖老的列表
builder = StateGraph(State)
builder.add_node(add_message)
builder.add_node(replace_message)
builder.add_edge(START,"add_message")
builder.add_edge("add_message","replace_message")
builder.add_edge("replace_message",END)
graph = builder.compile()
result = graph.invoke({
"message": [""]
})
print(result["message"])


2.定义输入输出模式

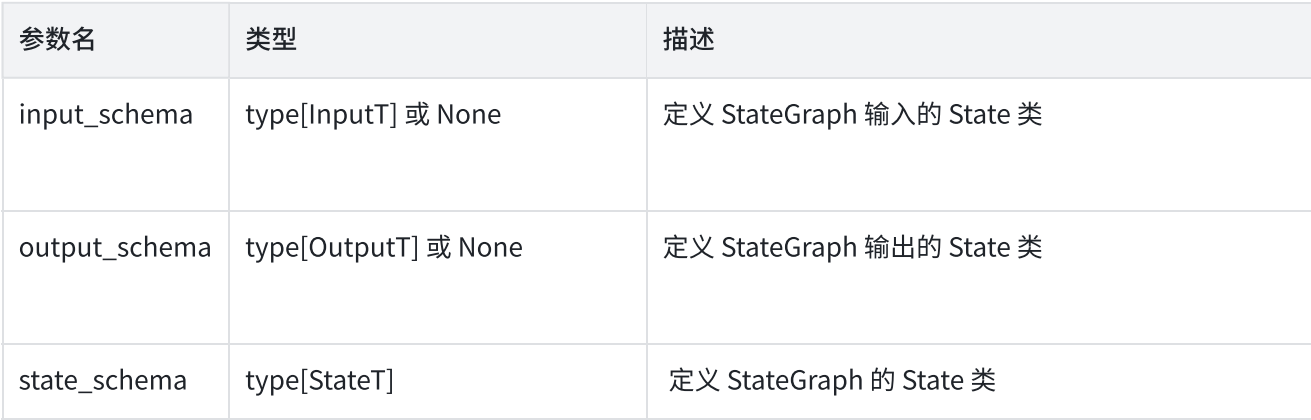
cpp
from typing import TypedDict
from langgraph.constants import START,END
from langgraph.graph import StateGraph
import os
os.environ["LANGCHAIN_TRACING_V2"] = "false"
class InputState(TypedDict):
question: str
class OuputState(TypedDict):
answer: str
class State(InputState,OuputState):
pass
def node(state: InputState):
"""通过问题生成答案"""
return {
"question": state["question"],
"answer": f"Answer to: {state['question']}"
}
builder = StateGraph(
State,
input_schema=InputState, #输入验证
output_schema=OuputState #输出验证
)
builder.add_node(node)
builder.add_edge(START,"node")
builder.add_edge("node",END)
graph = builder.compile()
result = graph.invoke({
"question":"i am a question"
})
#按照StateGraph(State)创建的图,执行后返回State
#希望得到的结果只有answer
print(result)
3.在节点间传递私有状态


cpp
from typing import TypedDict
from langgraph.constants import START,END
from langgraph.graph import StateGraph
import os
os.environ["LANGCHAIN_TRACING_V2"] = "false"
class State(TypedDict):
result: str
class Node1OutputState(TypedDict):
#隐式数据
sensitive_data: str
class Node2InputState(TypedDict):
#隐式数据
sensitive_data: str
def node_1(state: State) -> Node1OutputState:
"""第一步: 获取隐私数据"""
print("node1: 获取隐私数据")
return {
"sensitive_data": "我是隐私数据"
}
def node_2(state: Node2InputState) -> State:
"""第二步: 获取隐私数据,去处理(生成非隐私数据)"""
print("node2: 拿到隐私数据,去处理")
return {
"result": "处理后的数据"
}
def node_3(state: State):
"""第三步: 构造返回结果"""
print("node3: 构造返回结果")
return {
"result": state["result"] + "- 完成"
}
builder = StateGraph(State)
#sequence: 这里我们在没有分支的情况下,可以直接添加3个工作流
#并且是按照顺序的
builder.add_sequence([node_1,node_2,node_3])
builder.add_edge(START,"node_1")
# builder.add_edges("node_3",END) #可以不指向END
graph = builder.compile()
print(graph.invoke({
"result": ""
}))
二.工作流的常见模式

三.提示链模式(Prompt Chaining)
1.概念


2.模式实践

python
# 1. 定义输⼊模式 - 只包含⽤⼾输⼊
class InputState(TypedDict):
topic: str # ⽤⼾输⼊的主题
# 2. 定义输出模式 - 只包含最终结果
class OutputState(TypedDict):
final_content: str # 最终的内容
# 3. 定义完整状态模式(内部使⽤)
class OverallState(InputState, OutputState):
outline: str # 第⼀步:⽣成的⼤纲
draft: str # 第⼆步:⽣成的初稿
polished_draft: str # 第三步:润⾊后的稿件
python
from typing import TypedDict
from langchain_core.messages import HumanMessage
from langgraph.constants import START
from langgraph.graph import StateGraph
from langchain_community.chat_models import ChatZhipuAI
model = ChatZhipuAI(
model="glm-5",
# temperature=0.7,
# api_key="你的智谱API_KEY" # 如果你没配置环境变量就填这里
)
class InputState(TypedDict):
topic: str
class OutputState(TypedDict):
final_content: str
#3.过程中状态模式(内部使用)
class State(InputState, OutputState):
outline: str #第一步: 生成的大纲
draft: str #第二步: 生成的初稿
polished_draft: str #第三步: 润色后的稿件
#节点一
PROMPT_1 = (
"根据主题⽣成⽂章⼤纲。\n"
"主题:{topic}\n"
"要求:"
"1.只需两个最核⼼标题"
"2.不⽤进⾏说明,只返回最终⼤纲"
)
def node_1(state: InputState):
"""根据主题生成内容大纲"""
print("*" * 50)
print(f"内容大纲生成中....\n")
prompt = PROMPT_1.format(topic=state["topic"])
result = model.invoke([HumanMessage(content=prompt)])
print(f"大纲已经生成: \n{result.content}\n")
return {
"outline": result.content
}
#节点二
PROMPT_2 = (
"根据以下内容⽣成⽂章完整初稿。\n"
"主题:{topic}\n"
"⼤纲: "
"{outline}\n"
"要求:"
"1.每个标题下,最多使⽤三句话的内容即可"
"2.不⽤进⾏说明,只返回最终结果"
)
def node_2(state: State):
"""根据内容大纲生成完整初稿"""
print("*" * 50)
print(f"初稿生成中....\n")
prompt = PROMPT_2.format(topic=state["topic"],outline=state["outline"])
result = model.invoke([HumanMessage(content=prompt)])
print(f"初稿已经生成: \n{result.content}\n")
return {
"draft": result.content
}
#节点三
PROMPT_3 = (
"根据⽂章初稿进⾏润⾊。\n"
"主题:{topic}\n"
"初稿: "
"{draft}\n"
"要求:"
"1.润⾊后,⽂章不能太⻓"
)
def node_3(state: State):
"""润色初稿"""
print("*" * 50)
print(f"初稿润色中....\n")
prompt = PROMPT_3.format(topic=state["topic"],draft=state["draft"])
result = model.invoke([HumanMessage(content=prompt)])
print(f"初稿润色完成: \n{result.content}\n")
return {
"polished_draft": result.content
}
#节点四
PROMPT_4 = (
"根据润⾊版⽂章,⽣成⽂章终稿。\n"
"主题:{topic}\n"
"⼤纲: "
"{outline}\n"
"润⾊版⽂章: "
"{polished_draft}\n"
)
def node_4(state: State):
"""生成终稿"""
print("*" * 50)
print(f"终稿润色中....\n")
prompt = PROMPT_4.format(topic=state["topic"],outline=state["outline"], polished_draft=state["polished_draft"])
result = model.invoke([HumanMessage(content=prompt)])
print(f"终稿生成完成: \n{result.content}\n")
return {
"final_content": result.content
}
builder = StateGraph(
State,
input_schema=InputState, #输入验证
output_schema=OutputState#输出过滤
)
builder.add_sequence([node_1, node_2, node_3, node_4])
builder.add_edge(START,"node_1")
chain = builder.compile()
result = chain.invoke({"topic": "人工智能的未来发展"})
print(result)

四.并行化模式(Parallelization)
1.概念

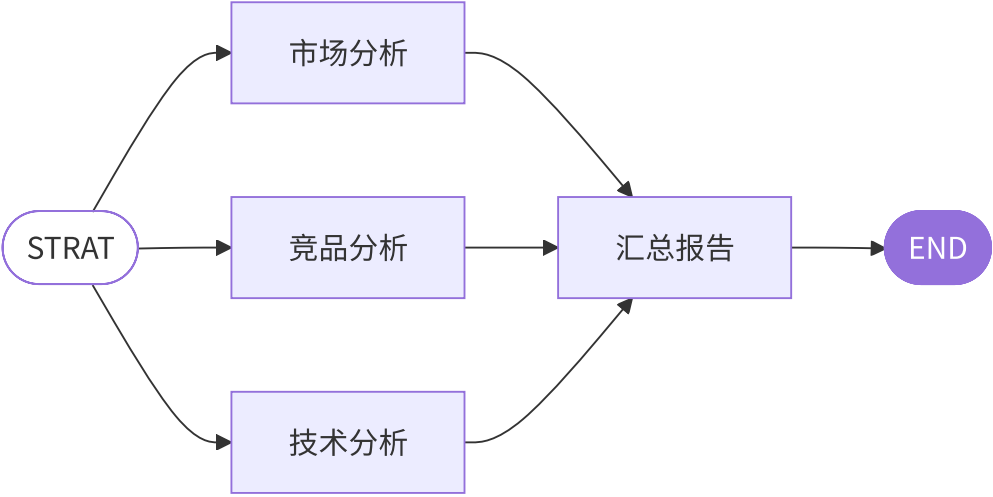
2.模式实践

python
from typing import TypedDict
from langgraph.constants import START, END
from langgraph.graph import StateGraph
import os
os.environ["LANGCHAIN_TRACING_V2"] = "false"
class AnalysisState(TypedDict):
concept: str # 概念
market: str # 市场分析
competitor: str # 竞品分析
tech: str # 技术分析
report: str # 汇总报告
# 三个并行分析任务
def market_task(state: AnalysisState):
"""市场分析"""
return {"market": "用户关注续航、重量、防盗,对骑行社交有兴趣..."}
def competitor_task(state: AnalysisState):
"""竞品分析"""
return {"competitor": "传统品牌智能化不足,互联网品牌续航和售后差..."}
def tech_task(state: AnalysisState):
"""技术分析"""
return {"tech": "轻量化电池车身、GPS防盗、社交App集成..."}
# 汇总结果
def combine_results(state: AnalysisState):
"""生成最终报告"""
report = f"产品分析报告\n\n"
report += f"市场分析:\n{state['market']}\n\n"
report += f"竞品分析:\n{state['competitor']}\n\n"
report += f"技术分析:\n{state['tech']}\n\n"
report += "建议:聚焦续航、防盗、社交功能的平衡发展"
return {"report": report}
# 构建工作流
builder = StateGraph(AnalysisState)
builder.add_node("market", market_task)
builder.add_node("competitor", competitor_task)
builder.add_node("tech", tech_task)
builder.add_node("combine", combine_results)
# 并行执行三个分析
builder.add_edge(START, "market")
builder.add_edge(START, "competitor")
builder.add_edge(START, "tech")
# 汇总结果
builder.add_edge("market", "combine")
builder.add_edge("competitor", "combine")
builder.add_edge("tech", "combine")
builder.add_edge("combine", END)
workflow = builder.compile()
print(workflow.get_graph(xray=True).draw_mermaid())
# 使用
result = workflow.invoke({"concept": "城市通勤智能电动自行车"})
print(result["report"])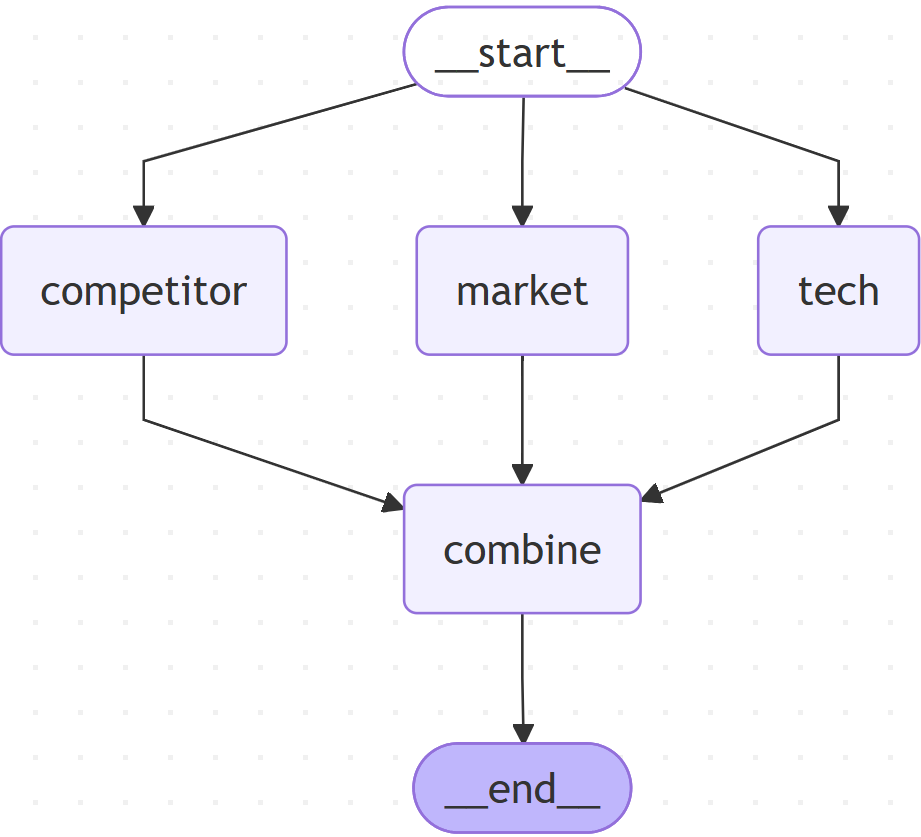
五.路由模式(Routing)
1.概念
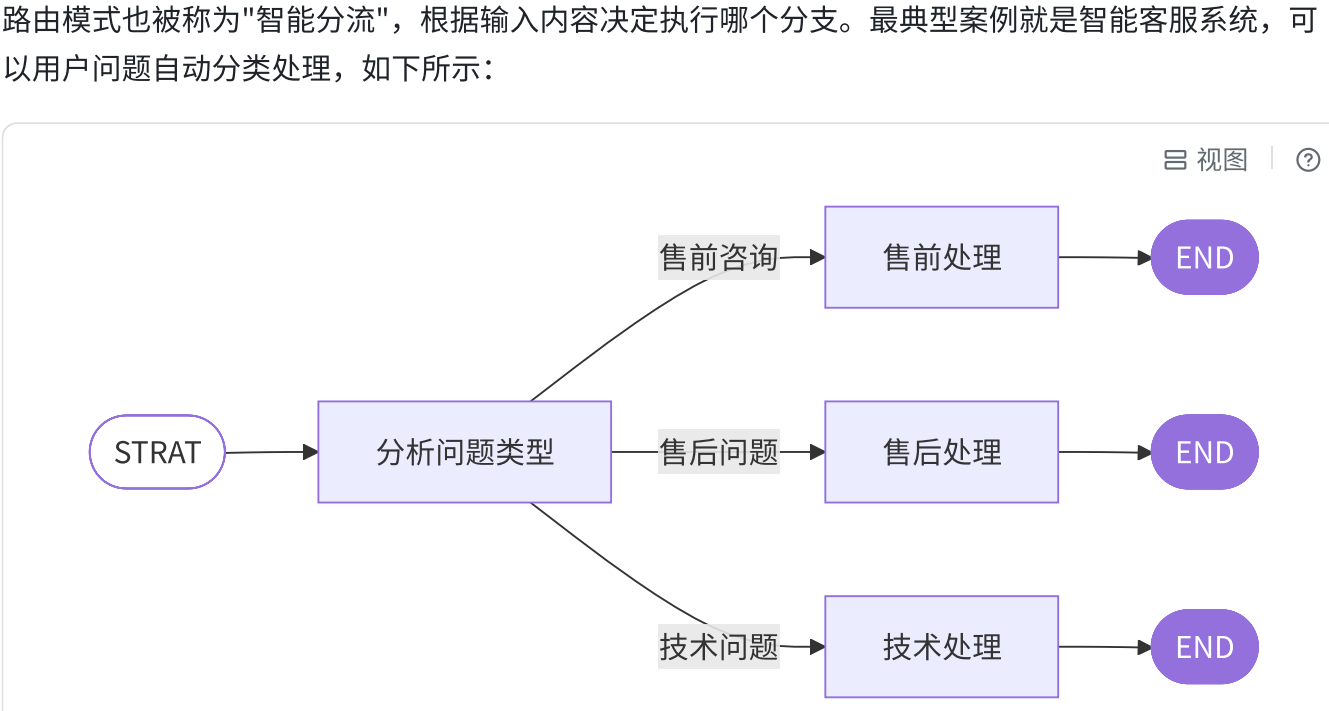
2.模式实践

python
# 定义路由决策的数据结构
class Route(BaseModel):
step: Literal["pre_sale", "after_sale", "technical"] = Field(
description="根据⽤⼾问题类型决定路由到售前、售后还是技术处理"
)
# 路由决策节点
def model_call_router(state: State):
"""分析⽤⼾输⼊,决定问题类型"""
model = init_chat_model("gpt-4o-mini")
decision = model.with_structured_output(Route).invoke(state["input"])
return {"decision": decision.step}
python
from langchain.chat_models import init_chat_model
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from typing_extensions import Literal, TypedDict
from pydantic import BaseModel, Field
class State(TypedDict):
input: str # 用户输入
decision: str # 路由决策
output: str # 最终输出
# 定义路由决策的数据结构
class Route(BaseModel):
step: Literal["pre_sale", "after_sale", "technical"] = Field(
description="根据用户问题类型决定路由到售前、售后还是技术处理"
)
# 路由决策节点
def model_call_router(state: State):
"""分析用户输入,决定问题类型"""
model = init_chat_model("gpt-4o-mini")
decision = model.with_structured_output(Route).invoke(state["input"])
return {"decision": decision.step}
# 三个不同的处理节点
def pre_sale_handler(state: State):
"""处理售前咨询"""
return {"output": "售前咨询已处理,处理内容....."}
def after_sale_handler(state: State):
"""处理售后问题"""
return {"output": "售后问题已处理,处理内容....."}
def technical_handler(state: State):
"""处理技术问题"""
return {"output": "技术问题已处理,处理内容....."}
# 路由函数 - 根据决策返回下一个节点
def route_decision(state: State):
if state["decision"] == "pre_sale":
return "pre_sale_handler" # 去售前处理节点
elif state["decision"] == "after_sale":
return "after_sale_handler" # 去售后处理节点
elif state["decision"] == "technical":
return "technical_handler" # 去技术处理节点
# 构建路由工作流
router_builder = StateGraph(State)
# 添加处理节点
router_builder.add_node(pre_sale_handler)
router_builder.add_node(after_sale_handler)
router_builder.add_node(technical_handler)
router_builder.add_node(model_call_router)
# 先经过路由决策
router_builder.add_edge(START, "model_call_router")
# 条件边:根据路由结果选择分支
router_builder.add_conditional_edges(
"model_call_router",
route_decision,
["pre_sale_handler", "after_sale_handler", "technical_handler"]
)
# 所有分支最终都结束
router_builder.add_edge("pre_sale_handler", END)
router_builder.add_edge("after_sale_handler", END)
router_builder.add_edge("technical_handler", END)
router_workflow = router_builder.compile()
# 测试
test_cases = [
"我想了解一下你们产品的价格和功能", # 售前咨询
"我购买的产品有质量问题,需要退货", # 售后问题
"这个软件安装后无法正常运行,报错代码0x80070005", # 技术问题
"请问你们的售后服务政策是什么", # 售前咨询
"我的订单已经发货但还没收到", # 售后问题
"如何配置数据库连接参数" # 技术问题
]
for test_case in test_cases:
print("*" * 50)
result = router_workflow.invoke({"input": test_case})
print(f"用户问题: {test_case}\n{result['output']}")
六.协调者-工作者模式(Orchestrator-Workers)
1.概念

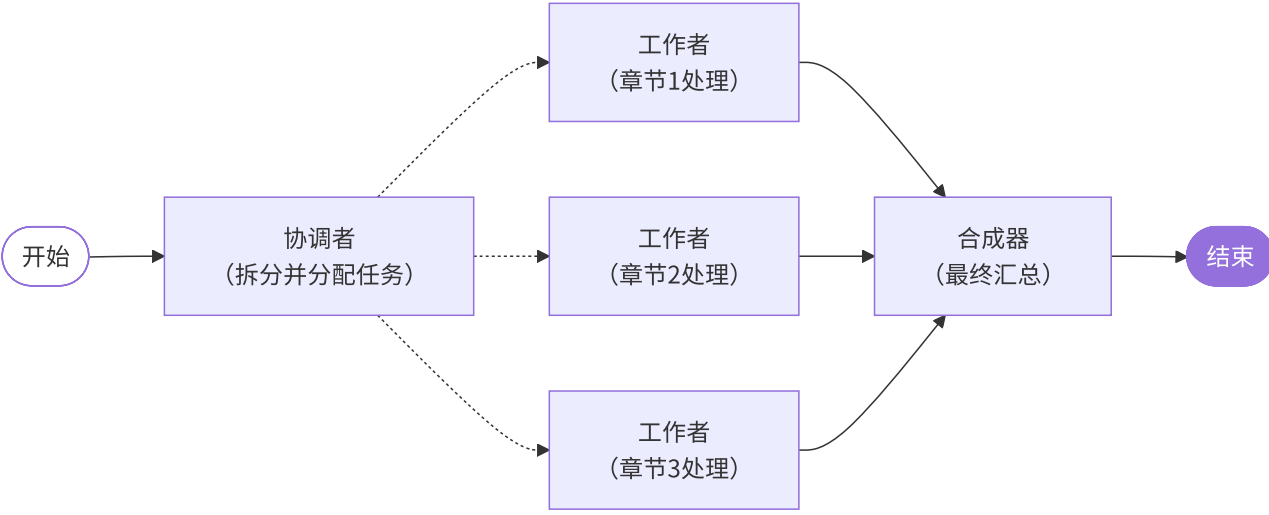

2.模式实践
python
# 任务分配函数 - 关键部分!
def assign_workers(state: State):
"""为每个任务创建⼯作者"""
# 为每个部分创建⼀个⼯作者任务
return [Send("llm_call", {"section": section}) for section in state["sections"]]
graph.add_conditional_edges("node", assign_workers)
python
from langchain.chat_models import init_chat_model
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langgraph.types import Send
from typing import Annotated, TypedDict, List
import operator
from pydantic import BaseModel
class State(TypedDict):
topic: str
sections: list # 协调者生成的计划
completed_sections: Annotated[list, operator.add] # 工作者完成的结果
final_report: str
# 定义数据结构-结构化输出
class Section(BaseModel):
name: str
description: str
class Sections(BaseModel):
sections: List[Section]
# 创建规划器
model = init_chat_model("gpt-4o-mini")
planner = model.with_structured_output(Sections)
# 协调者节点 - 制定计划
def orchestrator(state: State):
"""协调者: 分析任务并制定执行计划"""
report_sections = planner.invoke(
f"为主题'{state['topic']}'制定报告大纲,包含3个章节"
)
return {"sections": report_sections.sections}
# 工作者节点 - 执行具体任务
def llm_call(state: State):
"""工作者: 根据分配的任务生成内容"""
section = state["section"] # 从协调者接收的任务
result = model.invoke(
f"编写报告章节: {section.name}, 内容要求: {section.description}"
)
return {"completed_sections": [result.content]} # 结果会自动合并
# 汇总节点
def synthesizer(state: State):
"""汇总所有工作者的成果"""
completed_sections = state["completed_sections"]
final_report = "\n\n---\n\n".join(completed_sections)
return {"final_report": final_report}
# 任务分配函数 - 关键部分!
def assign_workers(state: State):
"""为每个任务创建工作者"""
# 为每个章节创建一个工作者任务
worker_tasks = []
for section in state["sections"]:
worker_tasks.append(
Send("llm_call", {"section": section}) # 发送任务给工作者
)
return worker_tasks
# 构建工作流
builder = StateGraph(State)
builder.add_node("orchestrator", orchestrator)
builder.add_node("llm_call", llm_call)
builder.add_node("synthesizer", synthesizer)
builder.add_edge(START, "orchestrator")
# 关键: 协调者后创建多个工作者
builder.add_conditional_edges(
"orchestrator",
assign_workers,
["llm_call"] # 创建的工作者都指向llm_call节点
)
# 所有工作者完成后汇总
builder.add_edge("llm_call", "synthesizer")
builder.add_edge("synthesizer", END)
worker = builder.compile()
response = worker.invoke({"topic": "中国近代史"})
print(response)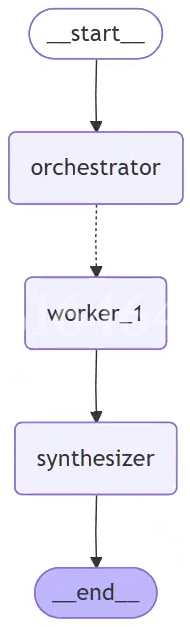

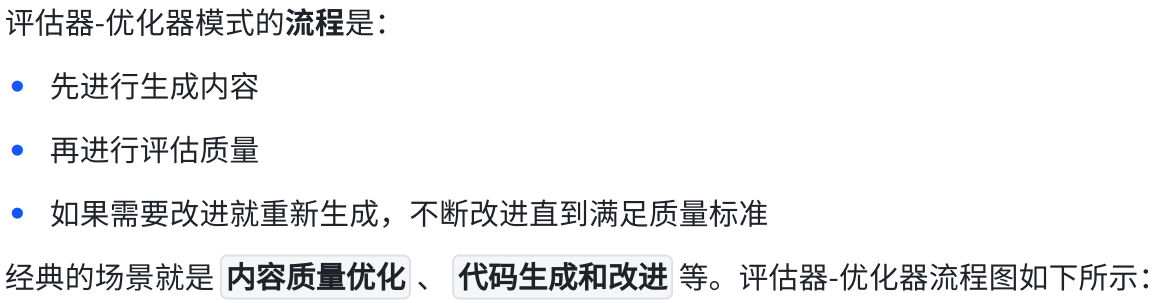
七.评估器-优化器模式(Evaluator-optimizer)
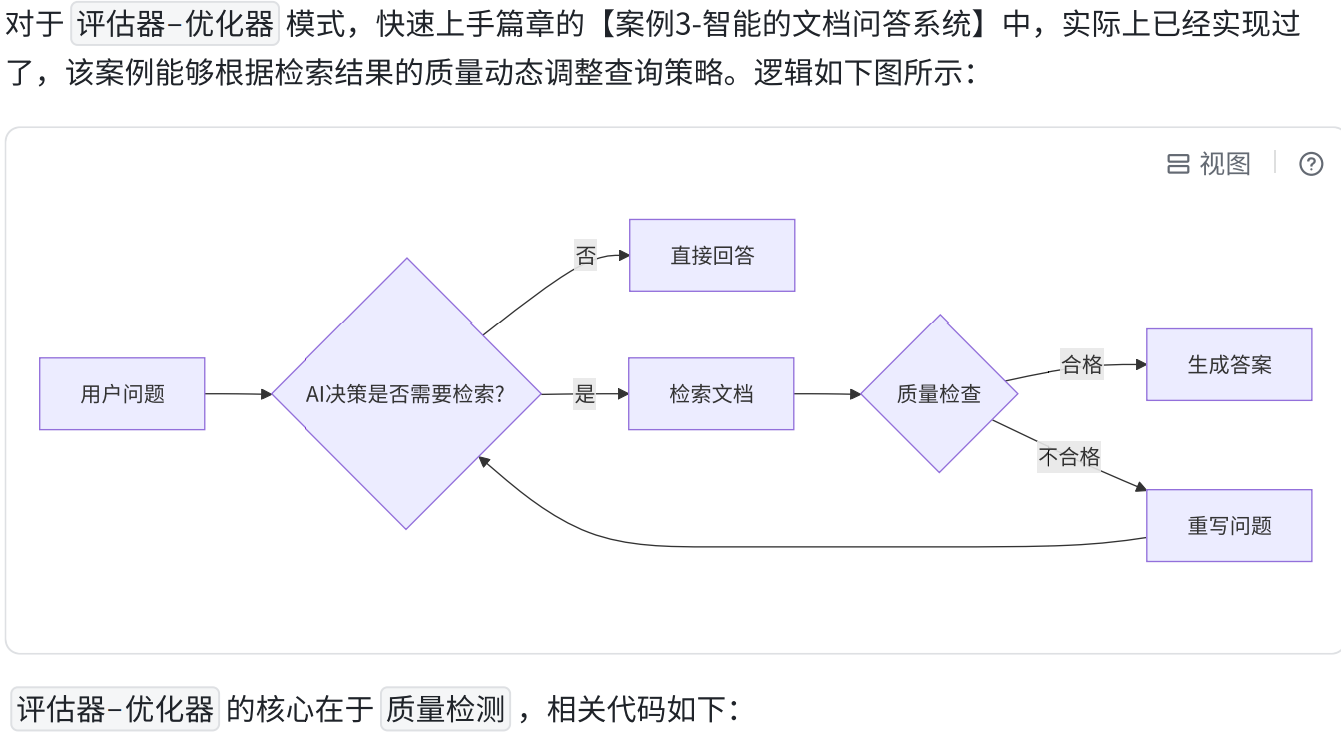
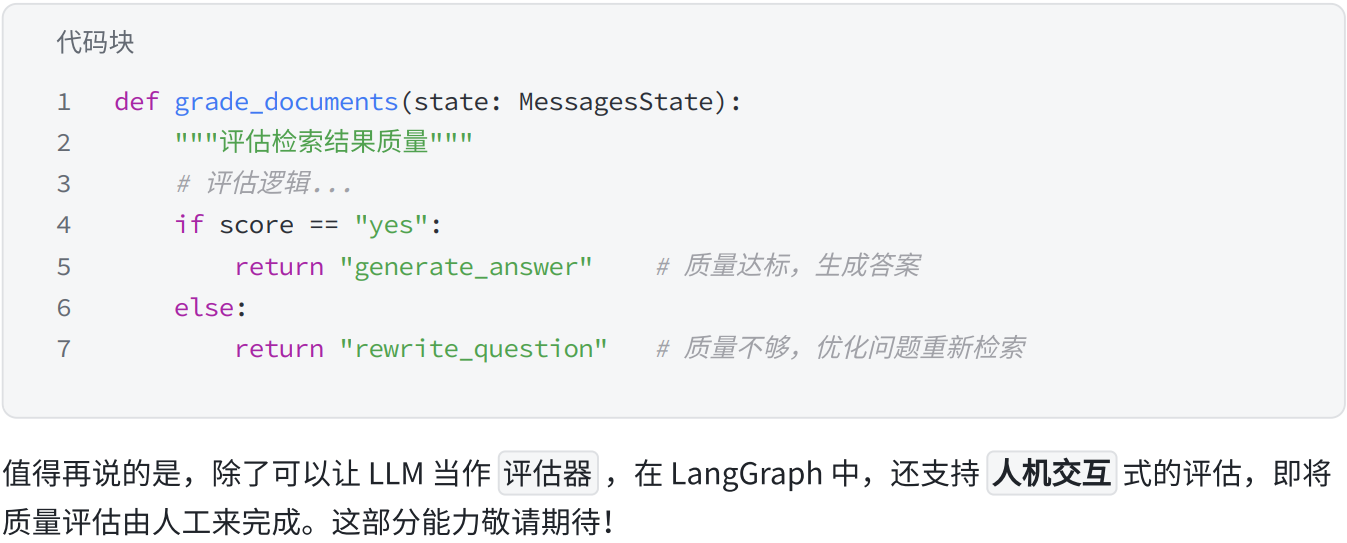
1.概念

2.模式实践