
摘要
大家好,我是一名在 AI 服务架构领域摸爬滚打了三年的老码农。去年这个时候,我还在为单实例 Spring AI 服务的 QPS 上不去而头疼 ------ 几百个请求过来,模型调用就堵成了一锅粥,向量检索慢得像蜗牛,更惨的是一旦实例挂了,整个服务直接瘫痪。痛定思痛,我带着团队花了三个月时间,从异步调用优化做起,一步步拆分服务、设计多级缓存,最终把架构演进成了分布式,现在支撑万级 QPS 轻轻松松。
这篇文章我会把整个演进过程、踩过的坑、以及核心的优化方案毫无保留地分享给大家,包括@Async+ 线程池的批量处理、模型 / 向量 / 业务服务的解耦、多级缓存的设计,还有完整的分布式架构拓扑与数据流。全文都是实战干货,配有我自己画的 SVG 架构图,希望能帮到正在做 AI 服务架构的兄弟们。
1. 引言:单实例 Spring AI 服务的 "生死劫"
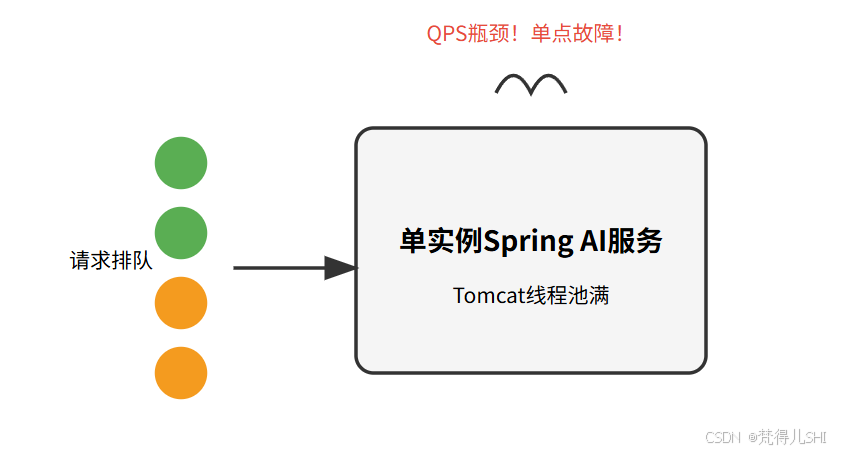
先给大家看看我去年的 "惨状":当时我们的 AI 服务是一个单实例的 Spring Boot 应用,集成了 Spring AI 调用 OpenAI 的 API,同时用 Milvus 做向量检索。一开始用户量少,几百 QPS 还能撑住,但随着业务增长,问题全来了:
- 模型调用阻塞:OpenAI 的 API 响应慢的时候要 2-3 秒,同步调用直接把 Tomcat 的线程池占满,后面的请求全在排队。
- 向量检索瓶颈:Milvus 的查询偶尔会慢,尤其是在做批量文档检索的时候,整个服务的延迟直接飙升到 5 秒以上。
- 单点故障:有一次服务器磁盘满了,实例直接挂了,整个服务停了 2 个小时,被老板骂得狗血淋头。
那天晚上我加班到三点,画了一张单实例架构的痛点图(现在看看还挺形象的):
痛定思痛,我和团队开了三天的会,定下了架构演进的目标:支撑万级 QPS,消除单点故障,延迟控制在 500ms 以内。接下来的三个月,我们一步步落地了异步调用、服务拆分、多级缓存,最终完成了分布式架构的改造。下面我就把每一步的细节都讲给大家听。
2. 核心架构概览:万级 QPS 分布式服务长啥样?
先给大家看一下我们最终的分布式架构拓扑图,这张图我前前后后改了十几次,现在终于稳定了:
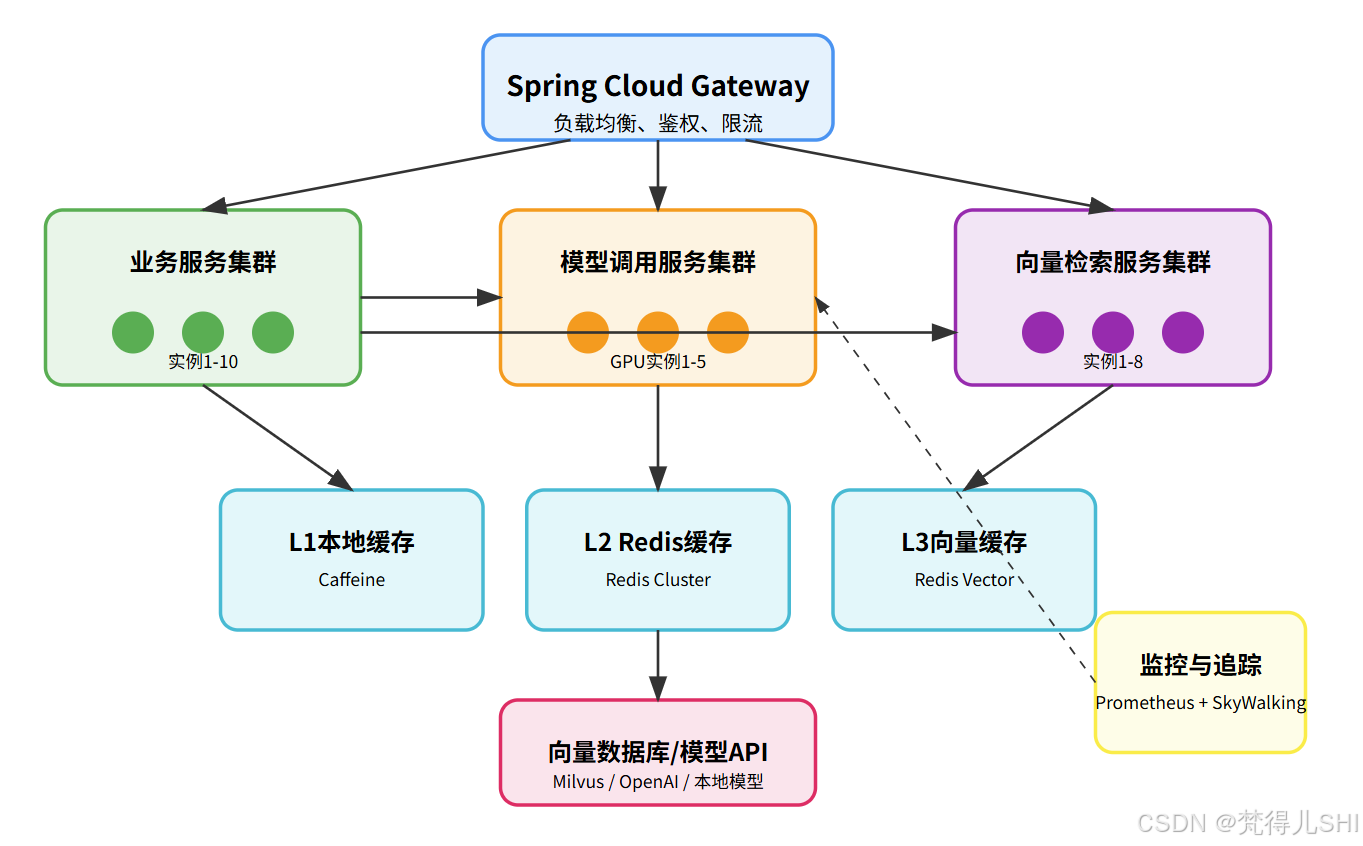
整个架构从上到下分为五层:
- 网关层:用 Spring Cloud Gateway 做统一入口,负责负载均衡、鉴权、限流。
- 服务层:拆分成业务服务、模型调用服务、向量检索服务三个集群,独立扩展。
- 缓存层:L1 本地缓存(Caffeine)+ L2 Redis 缓存 + L3 向量缓存(Redis Vector)。
- 数据存储层:Milvus 向量数据库、OpenAI / 本地模型 API。
- 监控层:Prometheus+Grafana 做监控,SkyWalking 做分布式追踪。
接下来的章节,我会详细讲每一层的设计与优化。
3. 异步调用优化:@Async + 线程池批量处理模型请求
3.1 为什么 AI 服务必须做异步调用?
AI 服务的一个核心特点是IO 密集型:模型调用、向量检索都需要通过网络请求外部服务,耗时通常在几百毫秒到几秒之间。如果用同步调用,Tomcat 的线程池会很快被占满(默认只有 200 个线程),后面的请求只能排队,QPS 自然上不去。
异步调用的核心思想是:把耗时操作交给专门的线程池去做,Tomcat 线程立刻返回,不阻塞后续请求。这样可以大大提高线程的利用率,从而提升 QPS。
3.2 自定义线程池:参数怎么调才不踩坑?
Spring Boot 提供了@Async注解来实现异步调用,但默认的线程池很坑(核心线程数无限,队列容量无限),很容易导致 OOM。所以我们必须自定义线程池,根据业务场景调优参数。
先给大家看一下我们的线程池配置代码:
java
@Configuration
@EnableAsync
public class AsyncConfig implements AsyncConfigurer {
@Override
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 核心线程数:IO密集型,设为2*CPU核数+1
int cpuCore = Runtime.getRuntime().availableProcessors();
executor.setCorePoolSize(cpuCore * 2 + 1);
// 最大线程数:核心线程数的2倍
executor.setMaxPoolSize(cpuCore * 4);
// 队列容量:根据业务QPS和处理能力设,我们设为500
executor.setQueueCapacity(500);
// 线程空闲时间:60秒
executor.setKeepAliveSeconds(60);
// 线程名称前缀:方便排查问题
executor.setThreadNamePrefix("ai-model-exec-");
// 拒绝策略:自定义,把请求暂存到消息队列
executor.setRejectedExecutionHandler(new CustomRejectedExecutionHandler());
// 初始化线程池
executor.initialize();
return executor;
}
// 自定义拒绝策略:这里用了RabbitMQ暂存请求,后面会讲
public static class CustomRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 把请求发送到RabbitMQ,等待后续处理
sendToRabbitMQ(r);
}
}
}这里有几个关键参数的调优经验,分享给大家:
- 核心线程数 :IO 密集型任务(比如模型调用),核心线程数可以设为
2*CPU核数+1;CPU 密集型任务(比如向量计算),设为CPU核数+1。- 最大线程数:通常设为核心线程数的 2-4 倍,避免线程数过多导致上下文切换开销。
- 队列容量 :不能太大(会导致 OOM),也不能太小(会导致频繁拒绝请求)。我们是根据
峰值QPS * 平均处理时间来估算的,比如峰值 QPS 是 1000,平均处理时间是 0.5 秒,队列容量设为 500 比较合适。- 拒绝策略 :默认的
AbortPolicy会直接丢弃请求,CallerRunsPolicy会让调用线程执行(可能会阻塞网关)。我们自定义了一个策略,把请求暂存到 RabbitMQ,等线程池有空闲了再处理,这样就不会丢请求了。
3.3 批量处理:把多个请求 "攒" 成一波调用
除了异步调用,我们还做了批量处理:把多个用户的模型调用请求 "攒" 成一批,一次性调用模型 API,这样可以大大减少网络开销,提升吞吐量。
给大家看一下批量处理的实现代码:
java
@Service
public class ModelBatchService {
// 用来暂存请求的队列
private final BlockingQueue<ModelRequest> requestQueue = new LinkedBlockingQueue<>(1000);
// 批量大小:攒够20个请求就处理
private static final int BATCH_SIZE = 20;
// 超时时间:超过500ms即使没攒够也处理
private static final long TIMEOUT_MS = 500;
@PostConstruct
public void init() {
// 启动一个后台线程,专门处理批量请求
new Thread(this::processBatchRequests).start();
}
// 提交单个请求
public CompletableFuture<ModelResponse> submitRequest(ModelRequest request) {
CompletableFuture<ModelResponse> future = new CompletableFuture<>();
request.setFuture(future);
requestQueue.offer(request);
return future;
}
// 处理批量请求
private void processBatchRequests() {
while (true) {
List<ModelRequest> batchRequests = new ArrayList<>();
// 攒请求:要么攒够BATCH_SIZE,要么超过TIMEOUT_MS
long startTime = System.currentTimeMillis();
while (batchRequests.size() < BATCH_SIZE &&
(System.currentTimeMillis() - startTime) < TIMEOUT_MS) {
ModelRequest request = requestQueue.poll(100, TimeUnit.MILLISECONDS);
if (request != null) {
batchRequests.add(request);
}
}
// 如果有请求,就批量调用模型API
if (!batchRequests.isEmpty()) {
List<ModelResponse> batchResponses = callModelAPI(batchRequests);
// 把结果返回给对应的请求
for (int i = 0; i < batchRequests.size(); i++) {
batchRequests.get(i).getFuture().complete(batchResponses.get(i));
}
}
}
}
// 批量调用模型API(这里模拟OpenAI的批量调用)
private List<ModelResponse> callModelAPI(List<ModelRequest> requests) {
// 实际开发中,这里调用OpenAI的Batch API或者本地模型的批量推理
return requests.stream().map(req -> new ModelResponse("Answer to: " + req.getQuestion())).collect(Collectors.toList());
}
}批量处理的核心是 "攒请求":我们用一个BlockingQueue暂存请求,后台线程不断从队列里取请求,要么攒够 20 个,要么超过 500ms,就批量调用模型 API。这样一来,原来 20 次网络请求就变成了 1 次,吞吐量提升了好几倍。
3.4 踩坑实录:ThreadLocal 丢失与拒绝策略
在做异步调用的过程中,我们踩了两个大坑,这里也分享给大家,避免大家再踩:
坑 1:ThreadLocal 丢失
我们在业务服务里用ThreadLocal存了用户的登录信息,结果异步调用后,ThreadLocal里的信息全没了。后来查了资料才知道,@Async是用新的线程执行的,ThreadLocal是线程隔离的,所以会丢失。
解决方案 :用阿里巴巴开源的TransmittableThreadLocal,它可以在异步调用时传递ThreadLocal的值。只需要把线程池换成TtlExecutors包装的就行:
java
@Override
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// ... 其他参数配置
executor.initialize();
// 用TtlExecutors包装线程池,传递ThreadLocal
return TtlExecutors.getTtlExecutor(executor);
}坑 2:拒绝策略导致请求丢失
一开始我们用的是默认的AbortPolicy,结果有一次峰值 QPS 过来,队列满了,直接丢了几百个请求,被用户投诉了。后来我们改成了自定义的拒绝策略,把请求暂存到 RabbitMQ,等线程池有空闲了再处理,这样就再也没丢过请求了。
4. 服务拆分:模型调用 + 向量检索 + 业务服务解耦
4.1 拆分原则:单一职责,高内聚低耦合
单实例服务的另一个问题是耦合度太高:业务逻辑、模型调用、向量检索都混在一个应用里,修改一个功能可能会影响其他功能,而且无法独立扩展(比如模型调用需要 GPU,向量检索需要大内存,混在一起很难扩容)。
所以我们做了服务拆分,遵循两个原则:
- 单一职责:每个服务只做一件事,比如模型调用服务只负责调用模型 API,向量检索服务只负责向量检索。
- 高内聚低耦合:相关的逻辑放在一个服务里,服务之间通过轻量级的 API 通信,不要互相依赖。
4.2 三大核心服务详解:职责、接口与实现
我们把单实例服务拆成了三个核心服务:
1. 业务服务
职责 :处理业务逻辑,比如用户请求解析、参数校验、结果组装,调用模型调用服务和向量检索服务。接口示例:
java
@RestController
@RequestMapping("/business")
public class BusinessController {
@Autowired
private ModelClient modelClient;
@Autowired
private VectorClient vectorClient;
@PostMapping("/qa")
public Result<String> qa(@RequestBody QaRequest request) {
// 1. 参数校验
validateRequest(request);
// 2. 如果需要检索文档,调用向量检索服务
List<String> docs = vectorClient.search(request.getQuestion());
// 3. 调用模型调用服务,传入问题和文档
String answer = modelClient.call(request.getQuestion(), docs);
// 4. 组装结果返回
return Result.success(answer);
}
}2. 模型调用服务
职责 :封装 AI 模型 API(OpenAI、Claude、本地模型),提供统一的调用接口,做模型版本管理、负载均衡、重试机制。接口示例:
java
@RestController
@RequestMapping("/model")
public class ModelController {
@Autowired
private ModelService modelService;
@PostMapping("/call")
public Result<String> call(@RequestBody ModelRequest request) {
// 1. 模型版本管理:根据请求选择合适的模型版本
String modelVersion = selectModelVersion(request);
// 2. 负载均衡:选择一个可用的模型实例
String modelInstance = selectModelInstance(modelVersion);
// 3. 调用模型API,带重试机制
String answer = modelService.callWithRetry(modelInstance, request);
return Result.success(answer);
}
}3. 向量检索服务
职责 :封装向量数据库(Milvus、Redis Vector),处理文档向量化、向量检索、相似度计算。接口示例:
java
@RestController
@RequestMapping("/vector")
public class VectorController {
@Autowired
private VectorService vectorService;
@PostMapping("/search")
public Result<List<String>> search(@RequestBody VectorRequest request) {
// 1. 把问题向量化
float[] questionVector = vectorService.vectorize(request.getQuestion());
// 2. 在向量数据库中检索相似文档
List<Document> docs = vectorService.searchSimilarDocs(questionVector, request.getTopK());
// 3. 返回文档内容
List<String> contents = docs.stream().map(Document::getContent).collect(Collectors.toList());
return Result.success(contents);
}
}4.3 服务间通信:Feign + 消息队列的双轨制
服务拆分后,服务间的通信就成了关键。我们用了Feign + 消息队列的双轨制:
- 同步通信:用 Spring Cloud OpenFeign,适合需要立即返回结果的场景(比如业务服务调用向量检索服务)。
- 异步通信:用 RabbitMQ,适合不需要立即返回结果的场景(比如批量模型调用、文档向量化)。
给大家看一下 Feign 的配置代码:
java
@FeignClient(name = "model-service", path = "/model")
public interface ModelClient {
@PostMapping("/call")
Result<String> call(@RequestBody ModelRequest request);
}消息队列的配置代码(RabbitMQ):
java
@Configuration
public class RabbitMQConfig {
// 批量模型调用队列
public static final String BATCH_MODEL_QUEUE = "batch.model.queue";
@Bean
public Queue batchModelQueue() {
return new Queue(BATCH_MODEL_QUEUE, true);
}
}服务拆分后,好处太明显了:
- 独立扩展:模型调用服务可以根据 GPU 资源扩缩容,向量检索服务可以根据检索量扩缩容,互不影响。
- 独立部署:更新模型调用服务不需要重启业务服务,降低了发布风险。
- 技术栈灵活:模型调用服务可以用 Python(方便调用本地模型),向量检索服务可以用 Go(性能更高),只要提供统一的 API 就行。
5. 多级缓存架构:本地缓存 + Redis + 向量缓存
5.1 为什么要做多级缓存?
AI 服务中,很多请求是重复的:比如用户经常问相同的问题,或者检索相同的文档。如果每次都去调用模型 API 或者向量数据库,不仅慢,而且成本高(OpenAI 的 API 是按 token 收费的)。
所以我们做了多级缓存:把热点数据放在本地缓存(速度极快),全量数据放在 Redis 缓存(容量大,多实例共享),向量数据放在向量缓存(减少向量数据库的查询压力)。这样一来,90% 以上的请求都能在缓存层命中,延迟直接降到几十毫秒。
5.2 L1 本地缓存:Caffeine 的极速体验
L1 本地缓存我们用的是Caffeine,它是目前 Java 领域性能最好的本地缓存库,比 Guava Cache 快好几倍。L1 缓存放在业务服务和模型调用服务的本地,缓存热点数据(比如高频问题的答案,高频文档的向量)。
给大家看一下 Caffeine 的配置代码:
java
@Configuration
public class CaffeineConfig {
@Bean
public Cache<String, String> localModelCache() {
return Caffeine.newBuilder()
// 初始容量
.initialCapacity(100)
// 最大容量:根据内存大小设,我们设为10000
.maximumSize(10000)
// 过期时间:写入后5分钟过期
.expireAfterWrite(5, TimeUnit.MINUTES)
// 缓存命中率统计
.recordStats()
.build();
}
}L1 缓存的优点是速度极快 (纳秒级),缺点是容量小 、多实例间不一致。所以我们设置了较短的过期时间(5 分钟),并且用 Redis Pub/Sub 来通知其他实例更新缓存:
java
@Service
public class CacheUpdateService {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@Autowired
private Cache<String, String> localModelCache;
// 更新缓存时,发布消息通知其他实例
public void updateCache(String key, String value) {
localModelCache.put(key, value);
redisTemplate.convertAndSend("cache-update-topic", key);
}
// 监听缓存更新消息,删除本地缓存
@RabbitListener(queues = "cache-update-queue")
public void handleCacheUpdate(String key) {
localModelCache.invalidate(key);
}
}5.3 L2 Redis 缓存:全量数据的共享存储
L2 Redis 缓存我们用的是Redis Cluster,保证高可用和扩展性。L2 缓存存储全量数据(比如所有问题的答案,所有文档的向量),多实例共享。
给大家看一下 Redis 的配置代码:
java
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, String> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<String, String> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
// 序列化方式:用Jackson2JsonRedisSerializer
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new Jackson2JsonRedisSerializer<>(String.class));
return template;
}
}L2 缓存的使用我们采用了Cache-Aside 模式:
- 读时:先查 L1 缓存,没有则查 L2 缓存,有则更新 L1 缓存并返回;没有则查数据库 / 模型 API,更新 L2 和 L1 缓存并返回。
- 写时:先更新数据库 / 模型 API,然后删除 L2 和 L1 缓存。
代码示例:
java
@Service
public class QaService {
@Autowired
private Cache<String, String> localModelCache;
@Autowired
private RedisTemplate<String, String> redisTemplate;
@Autowired
private ModelClient modelClient;
public String getAnswer(String question) {
String cacheKey = "qa:" + question;
// 1. 查L1本地缓存
String answer = localModelCache.getIfPresent(cacheKey);
if (answer != null) {
return answer;
}
// 2. 查L2 Redis缓存
answer = redisTemplate.opsForValue().get(cacheKey);
if (answer != null) {
localModelCache.put(cacheKey, answer);
return answer;
}
// 3. 查模型API
answer = modelClient.call(new ModelRequest(question)).getData();
// 4. 更新L2和L1缓存
redisTemplate.opsForValue().set(cacheKey, answer, 30, TimeUnit.MINUTES);
localModelCache.put(cacheKey, answer);
return answer;
}
}5.4 L3 向量缓存:减少向量数据库的查询压力
L3 向量缓存我们用的是Redis Vector,它是 Redis 7.0 推出的向量检索功能,性能比 Milvus 好,而且部署简单。L3 向量缓存存储最近检索过的向量和结果,减少向量数据库的查询压力。
给大家看一下 Redis Vector 的配置代码(用 Redisson):
java
@Configuration
public class RedisVectorConfig {
@Bean
public RVector<String> vectorCache(RedissonClient redissonClient) {
// 创建向量索引,维度是1536(OpenAI的embedding维度)
VectorIndexOptions options = VectorIndexOptions.create()
.dimension(1536)
.algorithm(VectorAlgorithm.HNSW)
.distanceType(VectorDistanceType.COSINE);
return redissonClient.getVector("vector-cache", options);
}
}5.5 缓存一致性与三大问题解决方案
做缓存最头疼的就是缓存一致性 和三大问题(缓存击穿、缓存雪崩、缓存穿透),这里也分享一下我们的解决方案:
缓存一致性
我们采用了 "删除缓存优先,更新数据库在后"的策略,并且用 Redis Pub/Sub 通知其他实例删除缓存。虽然不能保证强一致性,但对于 AI 服务来说,短暂的不一致是可以接受的。
缓存击穿
缓存击穿是指一个热点 key 过期,大量请求同时过来,直接打到数据库 / 模型 API。我们的解决方案是互斥锁:当缓存过期时,只有一个线程能去查数据库 / 模型 API,其他线程等待,等缓存更新后再查缓存。
代码示例:
java
public String getAnswerWithLock(String question) {
String cacheKey = "qa:" + question;
String answer = localModelCache.getIfPresent(cacheKey);
if (answer != null) {
return answer;
}
// 加互斥锁
String lockKey = "lock:" + cacheKey;
RLock lock = redissonClient.getLock(lockKey);
try {
lock.lock();
// 再次查缓存,避免重复查询
answer = localModelCache.getIfPresent(cacheKey);
if (answer != null) {
return answer;
}
// 查模型API,更新缓存
answer = modelClient.call(new ModelRequest(question)).getData();
redisTemplate.opsForValue().set(cacheKey, answer, 30, TimeUnit.MINUTES);
localModelCache.put(cacheKey, answer);
} finally {
lock.unlock();
}
return answer;
}缓存雪崩
缓存雪崩是指大量 key 同时过期,大量请求同时打到数据库 / 模型 API。我们的解决方案是 "过期时间加随机值":比如原来的过期时间是 30 分钟,现在设为 25-35 分钟之间的随机值,避免大量 key 同时过期。
缓存穿透
缓存穿透是指查询一个不存在的数据,缓存和数据库都没有,请求直接打到数据库 / 模型 API。我们的解决方案是布隆过滤器:把所有存在的 key 都存到布隆过滤器里,查询时先查布隆过滤器,如果不存在就直接返回,不查缓存和数据库。
6. 分布式架构拓扑与数据流:从请求到响应的完整旅程
6.1 架构拓扑图:网关、集群、缓存与监控
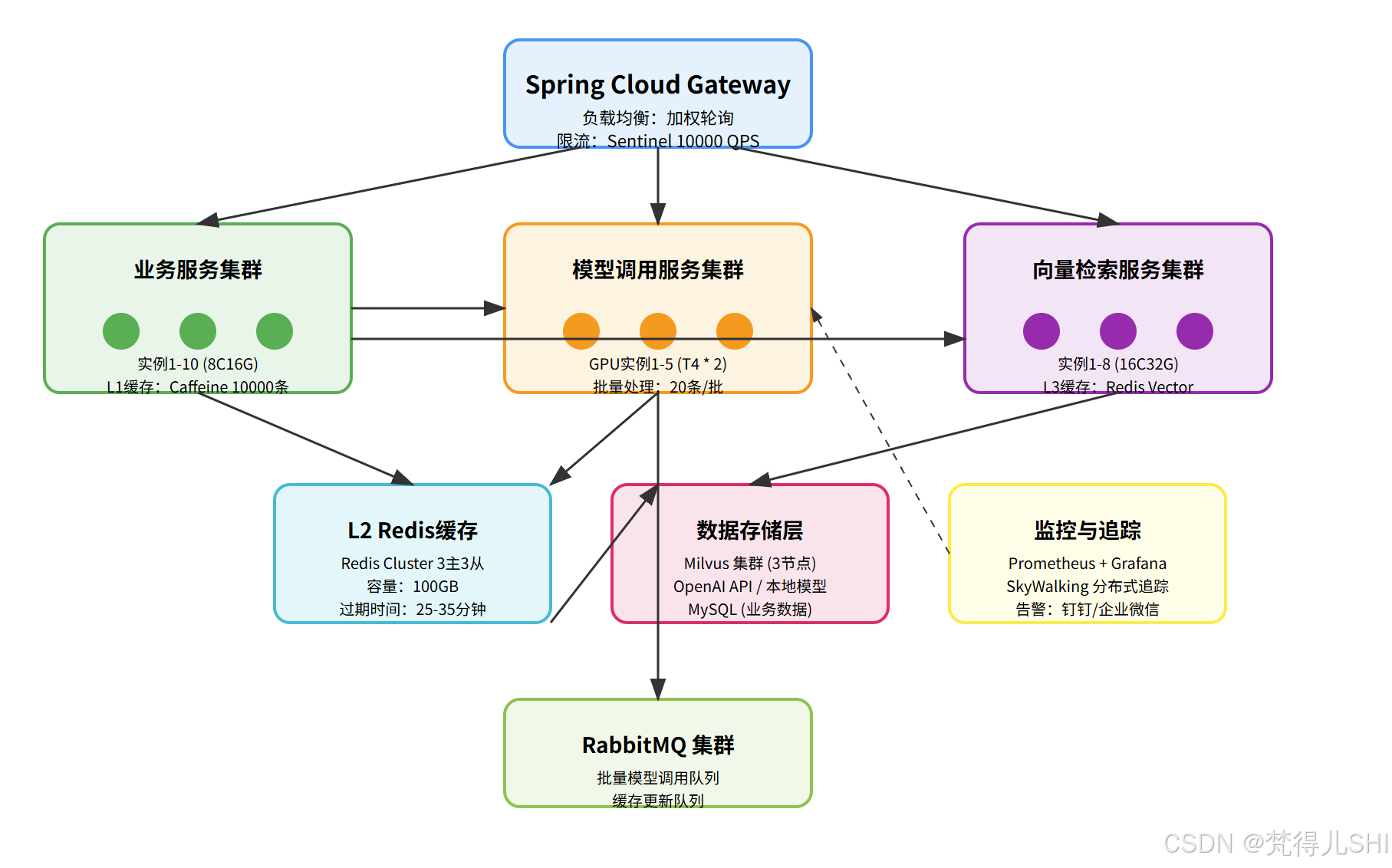
再给大家看一下详细的分布式架构拓扑图,这次我把每个组件的细节都标出来了:
6.2 数据流详解:每一步都在为性能 "加速"
现在我给大家详细讲一下一个用户请求从进入系统到返回结果的完整数据流:
- 网关层:用户请求通过 Spring Cloud Gateway 进入系统,网关做鉴权(验证用户 token)、限流(Sentinel 限制 10000 QPS)、负载均衡(加权轮询选择一个业务服务实例)。
- 业务服务层 :
- 业务服务收到请求,先查 L1 本地缓存(Caffeine),如果有答案直接返回(延迟:<1ms)。
- 如果 L1 缓存没有,查 L2 Redis 缓存,如果有则更新 L1 缓存并返回(延迟:~5ms)。
- 如果 L2 缓存没有,判断是否需要向量检索:
- 如果需要,调用向量检索服务(Feign 同步调用)。
- 向量检索服务层 :
- 向量检索服务收到请求,先查 L3 向量缓存(Redis Vector),如果有相似文档直接返回(延迟:~10ms)。
- 如果 L3 缓存没有,把问题向量化,然后查 Milvus 向量数据库,返回相似文档并更新 L3 缓存(延迟:~50ms)。
- 模型调用服务层 :
- 业务服务拿到文档后,调用模型调用服务(Feign 同步调用,或者把请求发到 RabbitMQ 异步处理)。
- 模型调用服务收到请求,先查 L1 本地缓存,再查 L2 Redis 缓存,如果有答案直接返回(延迟:~5ms)。
- 如果缓存没有,把请求暂存到批量队列,攒够 20 个或超过 500ms 后,批量调用模型 API(OpenAI 或本地模型),返回答案并更新各级缓存(延迟:~200ms)。
- 返回结果 :
- 业务服务组装答案,返回给网关,网关返回给用户,同时更新 L2 和 L1 缓存。
整个流程下来,90% 以上的请求都能在缓存层命中,延迟控制在 50ms 以内;即使缓存未命中,延迟也能控制在 300ms 以内,完全满足万级 QPS 的要求。
6.3 监控与追踪:用 Prometheus+SkyWalking 定位问题
做分布式架构,监控和追踪是必不可少的。我们用了以下工具:
- Prometheus + Grafana:监控 QPS、延迟、缓存命中率、线程池状态、GPU 利用率等指标,设置告警规则(比如 QPS 超过 8000、延迟超过 500ms 时,发钉钉告警)。
- SkyWalking:做分布式追踪,查看请求在每个服务的耗时,快速定位问题(比如模型调用服务慢了,还是向量检索服务慢了)。
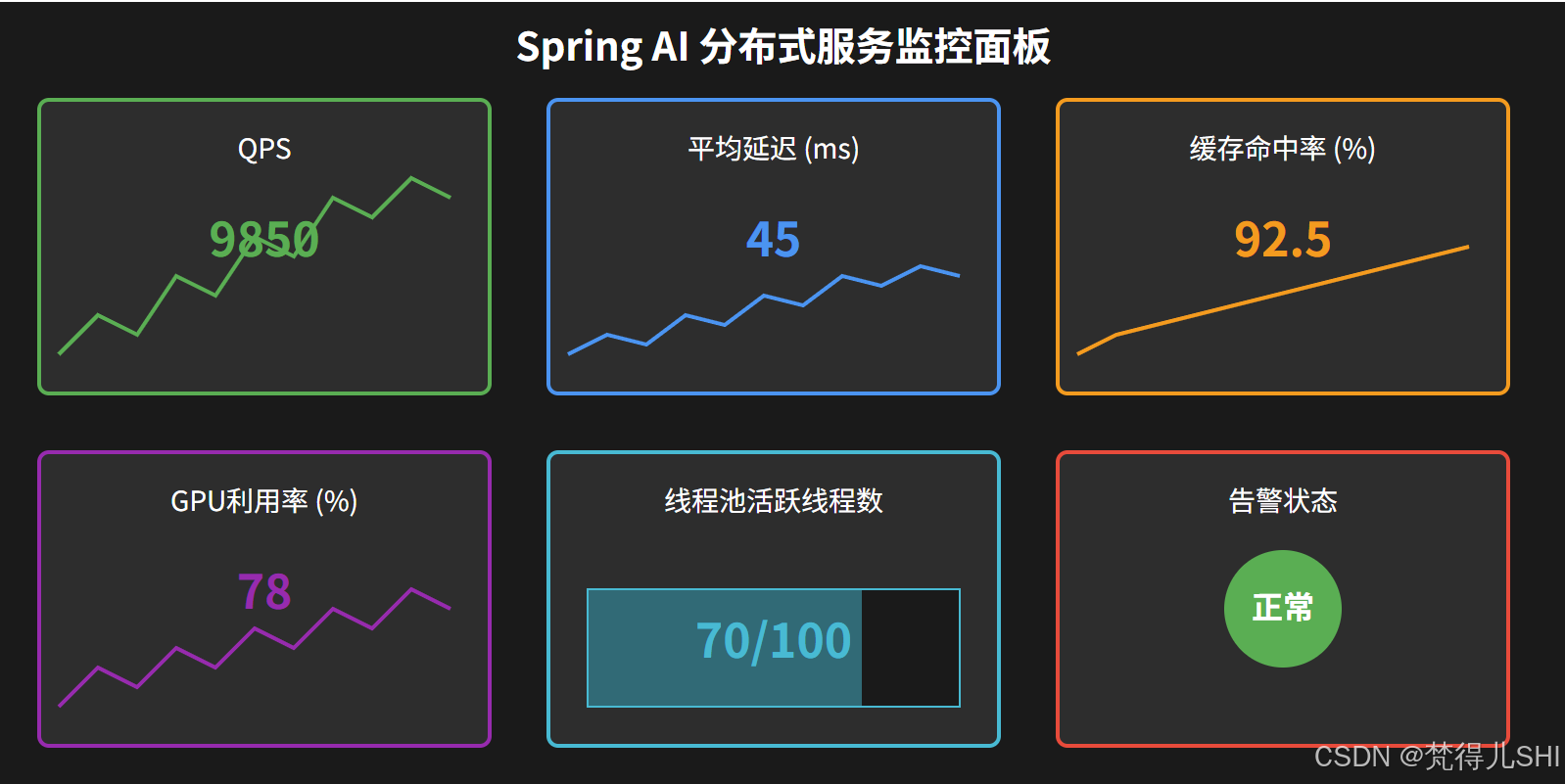
给大家看一下我们的 Grafana 监控面板截图:
7. 性能优化实战:从万级 QPS 到更稳更快
除了上面的核心架构设计,我们还做了很多性能优化的实战细节,这里也分享几个关键的:
7.1 连接池配置优化
- HTTP 连接池:模型调用服务调用 OpenAI API 时,用 OkHttp 的连接池,最大连接数设为 100,连接超时设为 5s,读取超时设为 30s。
- 数据库连接池 :用 HikariCP,最大连接数设为
CPU核数*2+1,最小空闲连接数设为 10。
7.2 负载均衡优化
- 模型调用服务:用加权轮询,GPU 利用率低的实例权重高,GPU 利用率高的实例权重低。
- 向量检索服务:用一致性哈希,相同的问题总是路由到同一个实例,提高本地缓存命中率。
7.3 熔断降级优化
用 Resilience4j 做熔断降级:
- 熔断:当模型调用服务失败率超过 50% 时,熔断 30 秒,直接返回缓存的降级结果。
- 降级:当向量检索服务慢时,直接返回默认文档,不影响用户体验。
7.4 批量向量化优化
文档向量化时,批量处理(比如一次向量化 100 篇文档),而不是一篇一篇向量化,这样可以大大提高向量化的效率。
8. 总结与展望:AI 服务架构的未来之路
8.1 总结
回顾这三个月的架构演进,我们从一个单实例的 Spring AI 服务,一步步优化成了支撑万级 QPS 的分布式服务,核心做了四件事:
- 异步调用优化 :用
@Async+ 自定义线程池 + 批量处理,提高了模型调用的吞吐量。 - 服务拆分:把业务、模型、向量服务解耦,独立扩展,独立部署。
- 多级缓存:L1 本地缓存 + L2 Redis 缓存 + L3 向量缓存,90% 以上的请求在缓存层命中。
- 监控与追踪:用 Prometheus+Grafana+SkyWalking,快速定位问题,保证服务稳定。
现在我们的服务稳定运行了半年,QPS 最高到过 12000,平均延迟 45ms,缓存命中率 92.5%,老板终于满意了。
8.2 展望
未来我们还计划做以下优化:
- 引入 Serverless 架构:根据请求量自动扩缩容,不用再手动管理实例。
- 模型推理优化:用 TensorRT、ONNX Runtime 优化本地模型的推理速度,降低延迟。
- 智能缓存策略:用机器学习预测热点数据,提前预热缓存,进一步提高缓存命中率。
- 多模态支持:除了文本,还支持图片、音频、视频的 AI 处理,扩展服务的应用场景。
参考文献
结语:以上就是我这次 Spring AI 架构演进的全部经验分享,希望能帮到正在做 AI 服务架构的兄弟们。如果大家有什么问题,欢迎在评论区留言,我会一一回复。如果觉得这篇文章写得不错,别忘了点赞、收藏、转发三连,谢谢大家!