文章目录
- 爬虫技术详解:从传统爬虫到浏览器自动化------以豆瓣读书笔记为例
-
- 前言
- [一、传统爬虫方式:requests + BeautifulSoup](#一、传统爬虫方式:requests + BeautifulSoup)
-
- [1.1 技术原理](#1.1 技术原理)
- [1.2 技术细节](#1.2 技术细节)
-
- [1.2.1 Cookie 与登录态管理](#1.2.1 Cookie 与登录态管理)
- [1.2.2 请求频率控制](#1.2.2 请求频率控制)
- [1.2.3 代理 IP 池](#1.2.3 代理 IP 池)
- [1.3 传统方式存在的风险与局限](#1.3 传统方式存在的风险与局限)
-
- [1.3.1 被识别为非浏览器流量](#1.3.1 被识别为非浏览器流量)
- [1.3.2 无法处理动态内容](#1.3.2 无法处理动态内容)
- [1.3.3 登录态难以维护](#1.3.3 登录态难以维护)
- [1.3.4 IP 维度风控](#1.3.4 IP 维度风控)
- [二、更好的爬虫方式:Playwright 浏览器自动化](#二、更好的爬虫方式:Playwright 浏览器自动化)
-
- [2.1 技术原理](#2.1 技术原理)
- [2.2 技术细节](#2.2 技术细节)
-
- [2.2.1 浏览器上下文与登录态持久化](#2.2.1 浏览器上下文与登录态持久化)
- [2.2.2 反自动化检测对抗](#2.2.2 反自动化检测对抗)
- [2.2.3 User-Agent 与浏览器指纹一致性](#2.2.3 User-Agent 与浏览器指纹一致性)
- [2.2.4 页面导航与等待策略](#2.2.4 页面导航与等待策略)
- [2.2.5 服务端 JavaScript 执行](#2.2.5 服务端 JavaScript 执行)
- [2.3 仍然具有的风险与局限](#2.3 仍然具有的风险与局限)
-
- [2.3.1 IP 级别频率限制](#2.3.1 IP 级别频率限制)
- [2.3.2 验证码拦截](#2.3.2 验证码拦截)
- [2.3.3 浏览器版本更新导致的兼容性问题](#2.3.3 浏览器版本更新导致的兼容性问题)
- [2.3.4 资源消耗](#2.3.4 资源消耗)
- 三、豆瓣实战:读书笔记爬虫全流程
-
- [3.1 页面逻辑与数据结构分析](#3.1 页面逻辑与数据结构分析)
-
- [3.1.1 笔记列表页](#3.1.1 笔记列表页)
- [3.1.2 笔记详情页](#3.1.2 笔记详情页)
- [3.1.3 书籍详情页](#3.1.3 书籍详情页)
- [3.2 代码结构设计](#3.2 代码结构设计)
- [3.3 核心设计模式](#3.3 核心设计模式)
-
- [3.3.1 安全导航模式(safe_goto)](#3.3.1 安全导航模式(safe_goto))
- [3.3.2 分层延迟策略](#3.3.2 分层延迟策略)
- [3.3.3 断点续爬机制](#3.3.3 断点续爬机制)
- [3.3.4 HTML 到 Markdown 的精确转换](#3.3.4 HTML 到 Markdown 的精确转换)
- [3.4 脚本化设计思路](#3.4 脚本化设计思路)
-
- [3.4.1 CLI 参数设计](#3.4.1 CLI 参数设计)
- [3.4.2 两阶段执行模型](#3.4.2 两阶段执行模型)
- [3.4.3 数据聚合与去重](#3.4.3 数据聚合与去重)
- [3.4.4 错误处理与容错](#3.4.4 错误处理与容错)
- [3.5 实战展示与代码分享](#3.5 实战展示与代码分享)
-
- [3.5.1 实战展示](#3.5.1 实战展示)
- [3.5.2 代码分享](#3.5.2 代码分享)
- 四、总结
爬虫技术详解:从传统爬虫到浏览器自动化------以豆瓣读书笔记为例
前言
豆瓣读书提供了笔记(Annotation)功能,允许用户为书籍的特定章节撰写读书笔记。当积累了一定量的笔记后,自然会产生将它们批量导出、备份的需求。然而,豆瓣并没有提供官方的笔记导出接口,而其完善的反爬机制也让数据获取变得不那么简单。
本文将从技术视角完整剖析这个过程:首先介绍传统爬虫方式的技术原理和固有风险,然后深入讲解基于 Playwright 浏览器自动化的改进方案,最后以豆瓣读书笔记的实际抓取为案例,详细展开页面分析、代码架构和脚本化设计的全流程。所有内容均基于实际开发中遇到的问题和解决方案,不涉及理论空谈。
一、传统爬虫方式:requests + BeautifulSoup
1.1 技术原理
传统爬虫的核心思路非常直接:用 Python 的 requests 库发送 HTTP 请求,获取服务器返回的 HTML 文本,再用 BeautifulSoup 或 lxml 等解析库从中提取目标数据。整个过程模拟的是"浏览器查看源代码",但实际上跳过了浏览器渲染 JavaScript 的步骤,直接与服务器进行 HTTP 层面的通信。
典型的代码结构如下:
python
import requests
from bs4 import BeautifulSoup
session = requests.Session()
session.headers.update({
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36"
})
response = session.get("https://book.douban.com/people/xxx/annotation/")
soup = BeautifulSoup(response.text, "lxml")
# 提取书籍列表
items = soup.find_all("div", class_="annotations-item")
for item in items:
title = item.find("h3").find("a").get_text(strip=True)
# ... 提取更多数据这种方式的工作流程可以拆解为以下几个步骤:
- 第一步,构造 HTTP 请求,设置请求头(User-Agent、Referer、Cookie 等)以模拟浏览器行为;
- 第二步,发送请求并获取响应体;
- 第三步,用 HTML 解析器将响应文本转化为可查询的 DOM 树;
- 第四步,通过 CSS 选择器或 XPath 定位目标元素,提取文本内容或属性值。
1.2 技术细节
1.2.1 Cookie 与登录态管理
豆瓣的笔记页面需要登录才能访问,因此 Cookie 管理是第一个必须解决的问题。使用 requests.Session() 可以自动维护 Cookie,但首次获取 Cookie 的方式有几种常见做法:
- 手动提取 Cookie :在浏览器中登录豆瓣后,打开开发者工具(F12),在 Network 面板中找到任意一个对
douban.com的请求,复制 Request Headers 中的Cookie字段值,粘贴到代码中。这种方式最简单但最脆弱------Cookie 有过期时间,一旦过期就需要重新手动复制。 - 使用 requests 的登录流程:模拟豆瓣的登录 POST 请求,提交用户名和密码,服务器返回 Set-Cookie 头,Session 自动保存。但豆瓣的登录流程已经演变为包含短信验证码、滑块验证等多步验证,纯代码模拟几乎不可能完成。
- 使用浏览器导出 Cookie :通过
browser-cookie3等库直接读取本地浏览器(Chrome、Firefox)的 Cookie 存储。这种方式不需要手动复制,但依赖本地浏览器环境。
python
import browser_cookie3
# 直接从 Chrome 中读取豆瓣的 Cookie
cookies = browser_cookie3.chrome(domain_name=".douban.com")
session = requests.Session()
session.cookies.update(cookies)1.2.2 请求频率控制
为了降低被识别为爬虫的概率,通常会在请求之间加入随机延迟:
python
import time
import random
time.sleep(random.uniform(1, 3)) # 每次请求间隔 1~3 秒更精细的做法是根据响应状态码动态调整延迟。如果收到 429(Too Many Requests)或 403(Forbidden),则延长等待时间甚至暂停:
python
response = session.get(url)
if response.status_code == 429:
retry_after = int(response.headers.get("Retry-After", 60))
time.sleep(retry_after)
elif response.status_code == 403:
# 被封禁,需要更换 IP 或等待更长时间
time.sleep(300)1.2.3 代理 IP 池
当单一 IP 被限流后,使用代理 IP 池轮换是传统爬虫的常见手段。代理可以是免费的公开代理(稳定性和速度差)、付费代理服务(质量有保障),或自建代理(通过云服务器部署):
python
proxies = {
"http": "http://user:pass@proxy_ip:port",
"https": "https://user:pass@proxy_ip:port",
}
response = session.get(url, proxies=proxies, timeout=10)1.3 传统方式存在的风险与局限
1.3.1 被识别为非浏览器流量
这是传统爬虫最致命的问题。豆瓣的反爬系统会从多个维度判断请求是否来自真实浏览器,而 requests 库发出的请求在多个层面与浏览器行为存在差异。
TLS 指纹(JA3/JA4) :这是现代反爬系统中最核心的检测手段之一。TLS 握手时,客户端会发送 Client Hello 消息,其中包含了支持的加密套件列表、扩展列表、椭圆曲线参数等信息。不同的 HTTP 客户端(Chrome、Firefox、curl、Python requests)会发出完全不同的参数组合,形成了独特的"TLS 指纹"。Python 的 requests 库底层使用 urllib3,它的 TLS 指纹与任何主流浏览器都不匹配。豆瓣的服务器或其 CDN 提供商可以在 TLS 握手阶段就直接判定这是一个自动化客户端,甚至在 HTTP 请求到达应用层之前就进行拦截。
HTTP/2 指纹 :类似地,HTTP/2 协议中客户端会发送 SETTINGS 帧、WINDOW_UPDATE 帧、优先级帧等,这些帧的参数顺序和取值也因客户端实现而异。requests 库不支持 HTTP/2(默认使用 HTTP/1.1),这本身就是一个可被检测的特征。
请求头特征 :浏览器发出的请求会携带几十个 HTTP 头,包括 Accept、Accept-Encoding、Accept-Language、sec-ch-ua、sec-fetch-dest 等。爬虫通常只设置了 User-Agent,缺少其他浏览器默认会发送的头部,或者头部的组合不自然。比如,一个声明自己是 Chrome 124 的请求,却没有 sec-ch-ua 头,这在反爬系统看来是非常可疑的。
1.3.2 无法处理动态内容
豆瓣的页面大量使用 JavaScript 动态渲染。笔记列表页的某些内容可能是通过 AJAX 异步加载的,或者页面结构会根据登录状态和用户交互动态变化。requests 只能获取服务端首次返回的 HTML 静态文本,不会执行 JavaScript,因此可能拿到不完整的 DOM 结构,导致解析失败。
更严重的是,豆瓣的某些页面会使用"骨架屏 + 异步填充"的渲染模式------首次 HTML 返回的只是一个空壳框架,真正的内容通过 fetch 或 XMLHttpRequest 在页面加载后才请求并填充。这种情况下,requests 拿到的 HTML 中根本不包含目标数据。
1.3.3 登录态难以维护
豆瓣的登录过程涉及复杂的验证流程,包括但不限于:图形验证码、短信验证码、滑块验证等。requests 无法执行 JavaScript,因此无法完成这些需要浏览器环境的验证步骤。即使通过手动方式获取了 Cookie,这些 Cookie 也有时效限制,过期后需要重新获取,而每次重新获取都需要手动操作,无法实现自动化。
此外,豆瓣可能使用了基于行为的 Cookie 刷新机制。真实浏览器在浏览过程中会自动执行某些 JavaScript(如刷新 bid Cookie),而 requests 无法触发这些机制,导致 Cookie 在短时间内就失效。
1.3.4 IP 维度风控
豆瓣会基于 IP 维度进行请求频率统计。当一个 IP 在短时间内发起了大量页面请求,即使每次请求间隔几秒,也容易被标记为异常流量。传统爬虫的应对手段是使用代理 IP 轮换,但高质量代理成本较高,免费代理又极不稳定。而且在实际使用中,即使使用了代理,如果请求模式(如请求间隔过于均匀)暴露了自动化特征,仍然可能被识别。
二、更好的爬虫方式:Playwright 浏览器自动化
2.1 技术原理
Playwright 是微软开发的新一代浏览器自动化框架(也是 Puppeteer 的继任者),它的核心思路与传统爬虫完全不同:不再尝试模拟浏览器的 HTTP 请求,而是直接驱动一个真实的 Chromium/Firefox/WebKit 浏览器实例。所有的页面导航、JS 执行、Cookie 管理都在真实的浏览器进程中完成,因此服务端看到的就是一个正常的浏览器会话。
这种方案从根本上解决了传统爬虫的几个核心问题:TLS 指纹与真实浏览器一致(因为用的就是真实浏览器)、JavaScript 可以正常执行(动态内容完整渲染)、Cookie 自动管理(浏览器原生的会话管理机制)。
Playwright 支持两种 API 模式:同步 API(sync_api)和异步 API(async_api)。对于脚本化爬虫这种场景,同步 API 更直观易用,代码结构与普通的 Python 脚本没有区别。以下示例展示了 Playwright 的基本用法:
python
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto("https://book.douban.com/")
content = page.content() # 获取完整渲染后的 HTML
browser.close()2.2 技术细节
2.2.1 浏览器上下文与登录态持久化
Playwright 的 BrowserContext 是一个独立的浏览器会话,类似于浏览器的"隐身模式"窗口。每个 Context 有自己独立的 Cookie、localStorage、sessionStorage 等存储。这意味着可以在一个 Context 中完成登录,然后将整个状态序列化保存,下次启动时直接恢复。
在豆瓣爬虫的实现中,登录态持久化是最关键的设计之一。首次运行时通过 --login 参数打开可见浏览器窗口,用户手动完成登录后,程序自动将浏览器状态(Cookies + localStorage)保存为 JSON 文件。后续运行时直接加载这个文件,无需再次登录。
python
# 首次登录后保存状态
state = context.storage_state() # 返回包含 cookies 和 origins 的字典
with open("douban_auth_state.json", "w") as f:
json.dump(state, f, ensure_ascii=False, indent=2)
# 后续运行时加载状态
context = browser.new_context(
storage_state="douban_auth_state.json"
)这种方式的优势在于:浏览器状态是完整的,不仅仅是 Cookie。它还包括 localStorage 数据、sessionStorage 数据等,这些都是维持登录态可能需要的。而且,由于是真实浏览器的状态,刷新机制(如 bid Cookie 的自动更新)也会在后续的页面浏览中自然生效。
2.2.2 反自动化检测对抗
即使使用了真实浏览器,豆瓣仍然可能通过 JavaScript 检测来判断是否是自动化程序。Playwright 和 Selenium 等框架在控制浏览器时会设置一些标志,比如 navigator.webdriver 属性会被设为 true。以下代码展示了几种常见的反检测措施:
python
# 通过启动参数禁用自动化检测标志
browser = playwright.chromium.launch(
headless=True,
args=[
"--disable-blink-features=AutomationControlled", # 移除 webdriver 标志
"--no-sandbox",
],
)
# 通过注入脚本覆盖自动化检测点
context.add_init_script("""
Object.defineProperty(navigator, 'webdriver', { get: () => undefined });
window.chrome = { runtime: {} };
Object.defineProperty(navigator, 'plugins', {
get: () => [1, 2, 3, 4, 5],
});
Object.defineProperty(navigator, 'languages', {
get: () => ['zh-CN', 'zh', 'en'],
});
""")这段注入脚本的原理是:在页面加载之前(通过 add_init_script 注册为初始化脚本),修改浏览器的几个关键属性。navigator.webdriver 是最常见的检测点------当 Playwright 控制浏览器时,此属性为 true,而正常浏览器中为 undefined。将其覆盖后,基于此属性的检测就失效了。
window.chrome 的注入是为了模拟 Chrome 浏览器的特有对象,因为 Playwright 的 Chromium 实例在某些情况下可能不会自动填充这个对象。navigator.plugins 和 navigator.languages 的覆盖则是为了使浏览器指纹更加逼真。
2.2.3 User-Agent 与浏览器指纹一致性
使用 Playwright 时,User-Agent 应当与实际使用的 Chromium 版本保持一致。如果在 browser.new_context() 中手动设置了 User-Agent,需要确保版本号与 Playwright 内置的 Chromium 版本匹配。不一致的 User-Agent 可能被更高级的指纹检测系统捕获。
python
context = browser.new_context(
viewport={"width": 1280, "height": 800}, # 设置合理的视口大小
locale="zh-CN", # 设置语言环境
user_agent=(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36" # 与 Chromium 版本匹配
),
)视口大小(viewport)也是一个常被忽视但可能影响指纹一致性的参数。如果设置为不常见的分辨率(如 375x667,即手机分辨率),但 User-Agent 声明的是桌面浏览器,就会被判定为异常。将视口设为常见的桌面分辨率(1280x800 或 1920x1080)是最稳妥的做法。
2.2.4 页面导航与等待策略
Playwright 提供了多种页面加载等待策略,不同策略在速度和可靠性之间有不同的权衡:
python
# domcontentloaded:DOM 解析完成即返回,不等待图片和样式表
page.goto(url, wait_until="domcontentloaded", timeout=30000)
# load:等待所有资源(包括图片)加载完成
page.goto(url, wait_until="load", timeout=30000)
# networkidle:网络空闲(无新请求持续 500ms)后返回
page.goto(url, wait_until="networkidle", timeout=30000)对于爬虫场景,推荐使用 domcontentloaded 策略。因为它只需要 HTML 文档解析完成,此时 DOM 树已经可用,可以开始提取数据,而不必等待所有图片、CSS 等资源加载完毕,大幅提升抓取效率。如果页面有 AJAX 动态内容需要等待,可以配合 page.wait_for_selector() 精确等待特定元素出现。
2.2.5 服务端 JavaScript 执行
在某些复杂场景下,使用 Playwright 的 page.evaluate() 可以直接在浏览器上下文中执行 JavaScript 代码。这对于处理豆瓣的书籍信息页面(/subject/XXXXX/)特别有用,因为该页面的元信息区域 HTML 结构复杂,标签嵌套层级深,用 Python 解析容易出错,而直接用 JavaScript 在 DOM 上操作则更加精确:
python
result = page.evaluate("""() => {
const div = document.querySelector('#info');
if (!div) return {};
function extractValue(labelSpan) {
let value = '';
let node = labelSpan.nextSibling;
while (node) {
if (node.nodeName === 'BR' || node.nodeName === 'SPAN') break;
if (node.nodeName === 'A') {
let text = node.textContent.trim();
if (text.endsWith(';')) text = text.slice(0, -1).trim();
value += (value ? ' / ' : '') + text;
} else if (node.nodeType === Node.TEXT_NODE) {
let text = node.textContent.replace(/[::]/g, '').trim();
if (text) value += text;
}
node = node.nextSibling;
}
return value.trim();
}
const spans = div.querySelectorAll('span.pl');
const data = {};
for (const span of spans) {
const label = span.textContent.trim().replace(/[::]/g, '');
const value = extractValue(span);
if (label === '作者') data.author = value;
if (label === '出版社') data.publisher = value;
// ...
}
return data;
}""")这段 JavaScript 直接在浏览器中运行,利用 DOM API 精确遍历 #info 区域的节点关系,提取每个 <span class="pl"> 标签后面的文本兄弟节点内容。由于是在真实的渲染环境中执行,不存在解析偏差的问题。
2.3 仍然具有的风险与局限
2.3.1 IP 级别频率限制
这是 Playwright 方案无法绕过的核心限制。无论使用多逼真的浏览器指纹,豆瓣仍然会基于 IP 地址进行请求频率统计。当同一个 IP 在短时间内访问了大量页面,就会触发"访问频繁,稍后再试"的限制。这种限制是 IP 级别的,与浏览器指纹、Cookie 等无关。
实际测试中,即使每次页面导航之间加入 2~5 秒的随机延迟,连续抓取 20~30 个页面后仍然可能触发限制。根本原因在于:普通用户的浏览行为中,不可能在几分钟内连续访问几十个不同的笔记详情页。豆瓣的风控系统会根据用户的"页面浏览速度"来判断是否为自动化行为。
解决方案是在不同的层级之间设置差异化的延迟策略。在本项目的最终版本中,采用了分层延迟设计:基础页面跳转延迟 2~5 秒,笔记详情页之间 4~10 秒,不同书籍之间 10~20 秒,列表翻页之间 5~10 秒。所有延迟都使用随机浮动(random.uniform),避免出现固定间隔的机械化模式。这种策略大幅降低了触发风控的概率,代价是整体抓取时间显著延长。
2.3.2 验证码拦截
当风控系统检测到异常行为时,会将用户重定向到安全验证页面(sec.douban.com)或在当前页面叠加验证码。由于验证码类型多样(图形验证码、滑块验证、短信验证等),自动化解决方案难以通用。本项目的策略是:检测到验证码时暂停执行,打印提示信息,等待用户在浏览器窗口中手动完成验证,验证通过后程序自动继续。
但经过实验测试,爬虫一旦被风控,手动解决了验证码也会显示"您的请求过于频繁,请稍后再试"。因此除了等待风控冷却,基本没有别的解决办法。实验表明,大约 1-4 个小时之内即可解除风控。
2.3.3 浏览器版本更新导致的兼容性问题
Playwright 绑定的 Chromium 版本是固定的(不同于系统安装的 Chrome),当豆瓣更新其页面结构或反爬策略时,可能需要更新 Playwright 版本来获取新的 Chromium。同时,add_init_script 中的反检测脚本也需要随 Chromium 版本更新进行调整,因为新版 Chromium 可能改变内部属性名称或行为。
2.3.4 资源消耗
Playwright 需要启动一个完整的 Chromium 浏览器进程,内存占用通常在 200~500MB,远高于 requests 库的几 MB。如果同时运行多个浏览器实例(多线程场景),资源消耗会成倍增加。因此,对于大规模抓取任务,需要在并发度和资源消耗之间做出权衡。
三、豆瓣实战:读书笔记爬虫全流程
3.1 页面逻辑与数据结构分析
豆瓣的读书笔记系统涉及三种关键页面,每种页面的 HTML 结构和数据提取逻辑各不相同。理解这些页面之间的导航关系和 DOM 结构,是编写可靠爬虫的前提。
3.1.1 笔记列表页
URL 格式 :https://book.douban.com/people/{user_id}/annotation/
分页机制 :每页展示 5 个书籍条目(annotations-item),翻页通过 URL 参数 start 控制,每页偏移量为 5。第一页 URL 不带参数,第二页为 ?start=5,第三页为 ?start=10,以此类推。
DOM 结构:页面核心结构如下:
html
<div class="paginator">
<!-- 分页器,包含"后页"等链接,href 中含 start 参数 -->
</div>
<div class="annotations-item">
<h3>
<a href="/subject/XXXXX/" title="书名 (笔记数)">书名 (笔记数)</a>
</h3>
<h5>
<a href="/annotation/XXXXX/">章节名 1</a>
</h5>
<h5>
<a href="/annotation/XXXXX/">章节名 2</a>
</h5>
<!-- 更多笔记链接 -->
</div>
<!-- 更多 annotations-item -->从这个页面中需要提取三类信息:书籍名称(从 <h3> 中的 <a> 的 title 属性获取)、笔记数量(从书名末尾的括号中解析数字)、以及每条笔记的链接和章节名(从 <h5> 中的 <a> 获取)。需要注意的是,同一本书的笔记可能分散在多个列表页中(跨页),需要在聚合阶段进行合并去重。
3.1.2 笔记详情页
URL 格式 :https://book.douban.com/annotation/{annotation_id}/
这是最核心的页面,包含了用户的笔记正文内容。其 DOM 结构中,笔记内容位于 <div id="link-report"> 内:
html
<div id="link-report">
<div class=" epub-image-section">
<a href="/subject/XXXXX/">
<img src="..." alt="书籍封面">
</a>
</div>
<figure>
<figcaption>引自《章节名》</figcaption>
</figure>
<p>笔记段落一</p>
<p>笔记段落二</p>
<br> <!-- 或 <br/> -->
<p>更多笔记内容...</p>
<!-- 页面底部的 UI 按钮文字(需要过滤) -->
</div>
<div class="mod profile">
<a class="name" href="/subject/XXXXX/">书名</a>
<!-- 书籍信息侧边栏 -->
</div>提取笔记正文是整个爬虫中最复杂的技术环节。直接使用 BeautifulSoup 的 get_text() 方法会把所有标签内容混成一段文本,丢失段落结构。因此需要采用手动处理 HTML 标签的策略:将 <p> 标签替换为双换行符(段落分隔)、<br> 标签替换为单换行符(行内换行)、然后移除所有剩余 HTML 标签。
此外,<figcaption> 中包含了"引自《章节名》"的信息,需要单独提取后从内容区域中移除。页面底部还散落着"投诉""举报""赞"等 UI 按钮文字,这些不属于笔记内容,需要通过正则匹配进行过滤。
另一个重要信息是书籍详情页的 URL(/subject/XXXXX/),它可以从侧边栏 <div class="mod profile"> 中提取,后续用于获取书籍的元信息。
3.1.3 书籍详情页
URL 格式 :https://book.douban.com/subject/{subject_id}/
这个页面包含书籍的完整元信息,存储在 <div id="info"> 区域中。其 HTML 结构非常不规则,标签嵌套层级深,标签之间混用文本节点和 <a> 链接节点,用 Python 的 BeautifulSoup 解析容易出错:
html
<div id="info">
<span class="pl">作者</span>: <a href="...">作者A</a> / <a href="...">作者B</a><br>
<span class="pl">副标题</span>: 副标题文字<br>
<span class="pl">出版社</span>: 出版社名称<br>
<span class="pl">出版年</span>: 2024-1<br>
<span class="pl">页数</span>: 320<br>
<span class="pl">定价</span>: 58.00 元<br>
<!-- 更多信息 -->
</div>每个信息字段的格式都是 <span class="pl">标签</span>: 值内容,但"值内容"部分可能是纯文本、<a> 链接、或者两者的混合(如多个作者之间用 / 分隔)。这种情况下,使用 page.evaluate() 在浏览器中直接操作 DOM API 是最可靠的方式------通过遍历 <span class="pl"> 的 nextSibling 链,逐个节点提取文本和链接内容。
3.2 代码结构设计
基于上述页面分析,整个爬虫的代码结构采用分层模块化设计,每个模块负责一个明确的功能域。以下是核心模块的职责划分:
douban_notes_scraper.py
├── 浏览器管理层
│ ├── create_browser_and_context() # 启动浏览器 + 加载登录态 + 反检测注入
│ └── save_auth_state() # 序列化保存浏览器状态
├── 页面导航层
│ ├── is_blocked() # 检测验证码/安全拦截
│ ├── wait_for_captcha_solved() # 暂停等待人工解决验证码
│ └── safe_goto() # 安全导航封装(自动处理拦截 + 基础延迟)
├── 页面解析层
│ ├── get_total_pages() # 解析列表页获取总页数
│ ├── parse_list_page() # 解析列表页提取书籍和笔记链接
│ ├── parse_annotation_page() # 解析笔记详情页提取正文
│ └── fetch_book_info() # 解析书籍详情页提取元信息
├── 数据聚合层
│ └── fetch_all_books() # 遍历分页 + 合并去重
├── 输出层
│ ├── generate_markdown() # 生成 Markdown 格式文本
│ └── process_book() # 单本书的完整处理流程
└── 控制层
├── do_login() # 登录流程控制
└── main() # CLI 参数解析 + 执行流程编排这种分层设计的核心思想是关注点分离。页面导航层负责处理与反爬直接相关的逻辑(验证码检测、安全导航),页面解析层只关心 DOM 结构和数据提取,输出层只关心数据格式化。当豆瓣的页面结构变化时,只需要修改解析层的代码;当反爬策略变化时,只需要修改导航层的代码。各层之间的耦合度降到最低。
3.3 核心设计模式
3.3.1 安全导航模式(safe_goto)
所有页面跳转都通过 safe_goto() 函数进行,而非直接调用 page.goto()。这个函数封装了三个关键能力:页面导航、验证码检测和自动恢复、基础延迟注入。
python
def safe_goto(page, url, context=None, state_file=None):
try:
page.goto(url, timeout=30000, wait_until="domcontentloaded")
except TimeoutError:
logger.warning(f"页面加载超时: {url},继续尝试...")
if is_blocked(page):
wait_for_captcha_solved(page, context, state_file)
page.goto(url, timeout=30000, wait_until="domcontentloaded")
time.sleep(2 + random.random() * 3) # 基础延迟 2~5 秒
return page.content()这个设计确保了:
- 超时不会导致程序崩溃,而是打印警告后继续;
- 任何页面跳转后都会自动检测是否被拦截;
- 每次导航后都有随机延迟,从源头控制请求频率。所有上层调用者无需关心这些细节,只需调用
safe_goto即可安全地导航到任何页面。
3.3.2 分层延迟策略
为了在抓取速度和风控规避之间取得平衡,设计中采用了分层延迟策略,根据请求的"敏感度"设置不同的等待时间:
| 请求类型 | 延迟范围 | 设计理由 |
|---|---|---|
| 基础页面跳转 | 2 ~ 5 秒 | 每次导航的最低间隔 |
| 笔记详情页之间 | 4 ~ 10 秒 | 连续请求同域不同页面,较高风险 |
| 书与书之间 | 10 ~ 20 秒 | 切换目标对象,模拟阅读行为 |
| 列表翻页之间 | 5 ~ 10 秒 | 翻页频率不应太快 |
所有延迟都使用 random.uniform() 生成随机值,避免固定间隔暴露自动化特征。日志中会打印每次延迟的具体时间,方便调试和观察。
3.3.3 断点续爬机制
断点续爬是提高爬虫健壮性的关键设计。当程序因验证码、网络错误或用户中断而停止时,已抓取的数据不应丢失,下次运行时应能从上次中断的位置继续。
实现方式是在 process_book() 中检查目标文件是否已存在,如果存在且其内容中的 ## 章节标题数量大于等于该书的笔记总数,则判定为已完成并跳过:
python
if os.path.exists(filepath):
with open(filepath, "r", encoding="utf-8") as f:
existing = f.read()
if existing.count("\n## ") >= len(annotations) and len(existing) > 100:
logger.info(f"跳过已有: 《{book_name}》")
return filepath这种基于文件内容的检查方式虽然简单,但很可靠------它不依赖任何外部状态文件,只看输出文件本身是否完整。即使程序在处理某本书的中途崩溃(已保存了部分笔记),下次运行时会重新处理这本书(因为笔记数量不完整),不会遗漏也不会重复。
同时,程序在多个关键节点都会保存登录态:每处理完 5 本书保存一次、程序正常结束时保存一次、KeyboardInterrupt 和异常捕获时也会保存。这确保了在任何情况下退出,下次运行都能恢复登录态。
3.3.4 HTML 到 Markdown 的精确转换
将 HTML 笔记内容转换为干净的 Markdown 文本是一个容易被忽视但技术含量不低的环节。豆瓣的笔记内容中,段落用 <p> 标签分隔,行内换行用 <br> 标签,还有 <figcaption> 标注章节来源,以及散落的 UI 按钮文字需要过滤。
转换流程分为五个步骤:
- 第一步,提取
<figcaption>中的章节来源信息,然后从 DOM 中移除该标签; - 第二步,将
<p>标签替换为双换行符(Markdown 段落分隔)、<br>标签替换为单换行符; - 第三步,用正则移除所有剩余 HTML 标签;
- 第四步,解码 HTML 实体(
&→&、 → 空格等); - 第五步,过滤 UI 按钮文字(投诉、举报、赞等),合并多余空行。
最后一步是将所有单个换行符替换为双换行符。这是因为 Markdown 的标准渲染规则中,单个换行符会被忽略(合并为一个空格),只有在行尾添加两个空格或在行与行之间留一个空行才能实现换行。由于笔记内容的换行在语义上都应该被保留,直接将所有 \n 替换为 \n\n 是最简单有效的方案。
3.4 脚本化设计思路
3.4.1 CLI 参数设计
脚本通过 argparse 提供了完整的命令行接口,支持以下使用模式:
bash
# 首次登录(只需一次,会打开浏览器窗口)
python douban_notes_scraper.py --login
# 后台模式抓取(无浏览器窗口)
python douban_notes_scraper.py
# 可见窗口模式(推荐,遇到验证码可以手动处理)
python douban_notes_scraper.py --visible
# 测试模式(只抓前 N 本书,用于验证功能)
python douban_notes_scraper.py --limit 3
# 自定义输出目录
python douban_notes_scraper.py --output ./my_notes这种设计将"登录"和"抓取"解耦为两个独立的操作。登录只需要做一次(或 Cookie 过期后重新做),之后的所有抓取操作都是全自动的。--visible 参数的存在是为了处理验证码------但在实验中,该功能并不能解决 IP 被风控的问题,只能等待时间冷却。
3.4.2 两阶段执行模型
整个抓取流程分为两个阶段:第一阶段遍历所有列表页,收集所有书籍和笔记链接的索引信息;第二阶段逐本书、逐条笔记地访问详情页,获取完整内容。
这种两阶段设计有几个好处:首先,第一阶段完成后可以给出全局统计信息(共 N 本书、M 条笔记),让用户对任务量有清晰的预期;其次,第一阶段的数据量小(只是链接列表),即使触发风控影响也有限;第三,第二阶段可以精确控制每本书、每条笔记之间的延迟,最大化风控规避效果。
3.4.3 数据聚合与去重
在第一阶段收集数据时,同一本书的笔记可能分散在不同的列表页中(因为列表是按最近更新时间排序的,同一本书的不同笔记可能出现在不同页)。因此在数据聚合阶段需要按书籍名称合并笔记列表,并按笔记 URL 去重:
python
# 合并:同一本书跨页的笔记合并到一起
for book in books:
name = book["book_name"]
if name not in all_books:
all_books[name] = {"annotations": []}
all_books[name]["annotations"].extend(book["annotations"])
# 去重:基于笔记 URL 去除重复
for name, data in all_books.items():
seen_urls = set()
unique = []
for ann in data["annotations"]:
if ann["url"] not in seen_urls:
seen_urls.add(ann["url"])
unique.append(ann)
unique_books[name] = {"annotations": unique}3.4.4 错误处理与容错
在整个流程中,每个可能失败的操作都有 try-except 包裹,确保单个笔记或单本书的失败不会影响整体流程。笔记级别的失败会记录错误信息并在输出中标注 [获取失败: 错误信息],书籍级别的失败会计入统计并在最终报告中体现。只有网络完全不可用或浏览器崩溃等严重错误才会中断整个流程。
3.5 实战展示与代码分享
3.5.1 实战展示
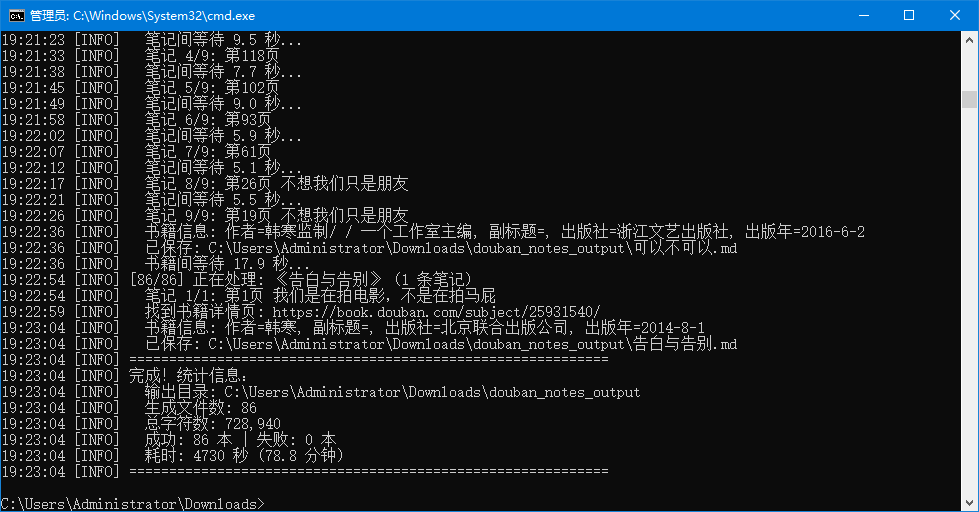
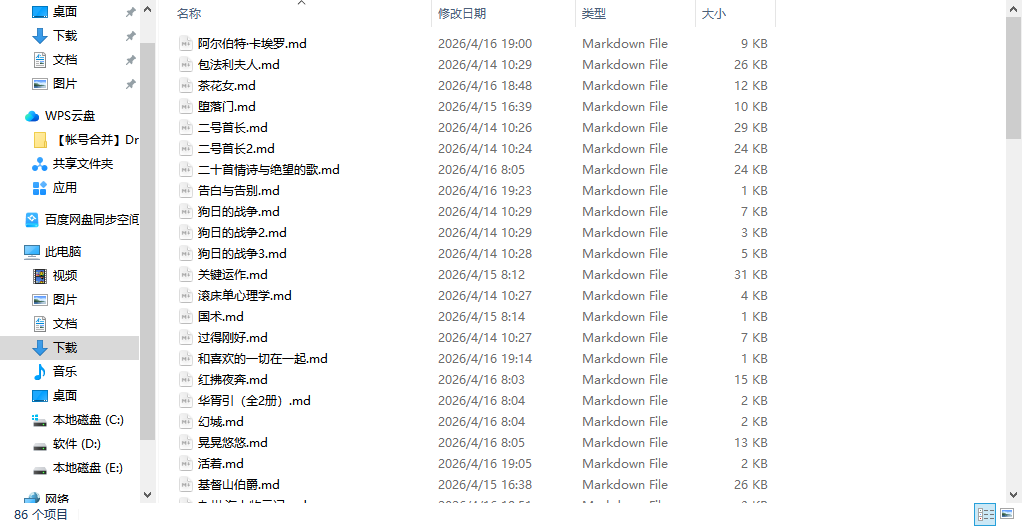

3.5.2 代码分享
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
豆瓣读书笔记爬虫 (Playwright 真实浏览器版)
使用 Chromium 浏览器自动化,豆瓣无法区分你和真人操作。
特性:
- 真实 Chromium 浏览器,完美绕过反爬
- 登录态持久化:首次登录后自动复用,无需重复输入
- 遇到验证码自动暂停,手动解决后继续
- 支持断点续爬(已有完整内容的书籍会跳过)
- 自动提取书籍元信息(作者、副标题、出版社、出版年)
安装依赖(只需一次):
pip install playwright bs4
playwright install chromium
使用方法:
1. 首次登录(只需一次):
python douban_notes_scraper.py --login
2. 正常抓取:
python douban_notes_scraper.py # 全量抓取(后台浏览器)
python douban_notes_scraper.py --visible # 显示浏览器窗口(推荐首次用)
python douban_notes_scraper.py --limit 3 # 只抓前3本书(测试用)
python douban_notes_scraper.py --output ./notes # 自定义输出目录
输出:
每本书一个 .md 文件,保存在 output_dir 目录中
"""
import os
import re
import sys
import json
import time
import random
import logging
import argparse
from pathlib import Path
from urllib.parse import urljoin
from bs4 import BeautifulSoup
try:
from playwright.sync_api import sync_playwright, TimeoutError as PWTimeout
except ImportError:
print("=" * 60)
print(" 需要安装 Playwright,请运行:")
print(" pip install playwright bs4")
print(" playwright install chromium")
print("=" * 60)
sys.exit(1)
# ============================================================
# 配置
# ============================================================
BASE_URL = "https://book.douban.com/people/{user_id}/annotation/"
DEFAULT_OUTPUT_DIR = "douban_notes_output"
AUTH_STATE_FILE = "douban_auth_state.json"
PAGE_TIMEOUT = 30000
CAPTCHA_MAX_WAIT = 300
# ============================================================
# 日志
# ============================================================
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(message)s",
datefmt="%H:%M:%S",
stream=sys.stdout,
force=True,
)
logger = logging.getLogger("douban_notes")
# ============================================================
# 浏览器管理
# ============================================================
def create_browser_and_context(playwright, visible=False, state_file=None):
"""启动浏览器并创建上下文,可选加载已保存的登录态"""
try:
browser = playwright.chromium.launch(
headless=not visible,
args=[
"--disable-blink-features=AutomationControlled",
"--no-sandbox",
],
)
except Exception as e:
if "Executable doesn't exist" in str(e) or "browserType.launch" in str(e):
print("=" * 60)
print(" Chromium 未安装,请运行:")
print(" playwright install chromium")
print("=" * 60)
sys.exit(1)
raise
context_kwargs = {
"viewport": {"width": 1280, "height": 800},
"locale": "zh-CN",
"user_agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36"
),
}
if state_file and os.path.exists(state_file):
try:
with open(state_file, "r", encoding="utf-8") as f:
saved_state = json.load(f)
context_kwargs["storage_state"] = saved_state
logger.info(f"已加载登录态: {state_file}")
except Exception as e:
logger.warning(f"加载登录态失败: {e},将使用全新浏览器")
context = browser.new_context(**context_kwargs)
# 注入反检测脚本
context.add_init_script("""
Object.defineProperty(navigator, 'webdriver', { get: () => undefined });
window.chrome = { runtime: {} };
Object.defineProperty(navigator, 'plugins', {
get: () => [1, 2, 3, 4, 5],
});
Object.defineProperty(navigator, 'languages', {
get: () => ['zh-CN', 'zh', 'en'],
});
""")
return browser, context
def save_auth_state(context, state_file):
"""保存浏览器登录态(cookies + localStorage)"""
try:
state = context.storage_state()
script_dir = os.path.dirname(os.path.abspath(__file__))
save_path = os.path.join(script_dir, state_file)
with open(save_path, "w", encoding="utf-8") as f:
json.dump(state, f, ensure_ascii=False, indent=2)
except Exception as e:
logger.warning(f"保存登录态失败: {e}")
# ============================================================
# 页面导航(含验证码检测)
# ============================================================
def is_blocked(page):
"""检测是否被重定向到安全验证页面"""
url = page.url
if "sec.douban.com" in url or "misc/sorry" in url:
return True
try:
captcha = page.query_selector(".captcha-image, #captcha_image")
if captcha and captcha.is_visible():
return True
except Exception:
pass
return False
def wait_for_captcha_solved(page, context, state_file):
"""检测到验证码时暂停,等待用户在浏览器中手动解决"""
logger.warning("=" * 60)
logger.warning(" 检测到豆瓣安全验证/验证码!")
logger.warning(" 请在浏览器窗口中手动完成验证。")
logger.warning(f" 最长等待 {CAPTCHA_MAX_WAIT} 秒,完成后自动继续...")
logger.warning("=" * 60)
start = time.time()
while time.time() - start < CAPTCHA_MAX_WAIT:
time.sleep(3)
try:
if not is_blocked(page):
logger.info("验证通过,继续抓取...")
save_auth_state(context, state_file)
time.sleep(1)
return True
except Exception:
pass
raise RuntimeError(
f"等待验证码超时({CAPTCHA_MAX_WAIT}秒)。"
f"请使用 --visible 参数重新运行,手动解决验证码。"
)
def safe_goto(page, url, context=None, state_file=None):
"""安全导航到指定 URL,自动处理验证码"""
try:
page.goto(url, timeout=PAGE_TIMEOUT, wait_until="domcontentloaded")
except PWTimeout:
logger.warning(f"页面加载超时: {url},继续尝试...")
if is_blocked(page):
if context and state_file:
wait_for_captcha_solved(page, context, state_file)
else:
raise RuntimeError(
f"被豆瓣安全限制拦截: {url}。"
f"请使用 --visible 参数运行以手动处理验证码。"
)
try:
page.goto(url, timeout=PAGE_TIMEOUT, wait_until="domcontentloaded")
except PWTimeout:
pass
time.sleep(2 + random.random() * 3) # 基础延迟 2~5 秒
return page.content()
# ============================================================
# 文件名工具
# ============================================================
def sanitize_filename(name):
name = re.sub(r'[\\/:*?"<>|\r\n]', "_", name)
name = name.strip(". ")
return name or "unnamed"
# ============================================================
# 核心页面解析
# ============================================================
def get_total_pages(page, context, state_file):
"""从第一页获取总页数"""
logger.info("正在获取总页数...")
html = safe_goto(page, BASE_URL, context, state_file)
soup = BeautifulSoup(html, "lxml")
paginator = soup.find("div", class_="paginator")
if not paginator:
logger.info("未找到分页器,可能只有一页")
return 1
page_links = paginator.find_all("a", href=True)
max_page = 1
for link in page_links:
href = link["href"]
match = re.search(r"start=(\d+)", href)
if match:
page_num = int(match.group(1)) // 5 + 1
max_page = max(max_page, page_num)
logger.info(f"总页数: {max_page}")
return max_page
def parse_list_page(page, url, context, state_file):
"""解析笔记列表页,返回该页所有书籍及其笔记信息"""
html = safe_goto(page, url, context, state_file)
soup = BeautifulSoup(html, "lxml")
books = []
items = soup.find_all("div", class_="annotations-item")
for item in items:
h3 = item.find("h3")
if not h3:
continue
book_link = h3.find("a", href=True)
if not book_link:
continue
book_name = book_link.get("title", "").strip() or book_link.get_text(strip=True)
book_name_clean = re.sub(r"\s*\(\d+\)\s*$", "", book_name)
count_match = re.search(r"\((\d+)\)", book_name)
annotation_count = int(count_match.group(1)) if count_match else 0
annotations = []
note_links = item.find_all("h5")
for nl in note_links:
a_tag = nl.find("a", href=True)
if a_tag:
chapter = a_tag.get_text(strip=True)
note_url = a_tag["href"]
if not note_url.startswith("http"):
note_url = urljoin(BASE_URL, note_url)
annotations.append({"url": note_url, "chapter": chapter})
books.append({
"book_name": book_name_clean,
"annotation_count": annotation_count,
"annotations": annotations,
})
return books
def parse_annotation_page(page, url, context, state_file):
"""解析笔记详情页,返回完整笔记内容、书籍 subject URL"""
html = safe_goto(page, url, context, state_file)
soup = BeautifulSoup(html, "lxml")
content_div = soup.find(id="link-report")
content = ""
chapter = ""
book_subject_url = ""
if content_div:
# 提取章节来源
figcaption = content_div.find("figcaption")
if figcaption:
chapter = figcaption.get_text(strip=True)
chapter = re.sub(r"^引自\s*", "", chapter)
figcaption.decompose()
# ---- 文本提取:手动处理 HTML 标签,精确控制换行 ----
# 不用 get_text(),因为它会把所有标签内容混在一起
# 改为手动转换:p → 段落分隔,br → 行内换行,其他标签 → 移除
inner_html = str(content_div)
# <p> 标签 → 段落分隔(两个换行)
inner_html = re.sub(r"<p[^>]*>", "\n\n", inner_html, flags=re.IGNORECASE)
inner_html = re.sub(r"</p>", "", inner_html, flags=re.IGNORECASE)
# <br> 标签 → 行内换行
inner_html = re.sub(r"<br\s*/?>", "\n", inner_html, flags=re.IGNORECASE)
# 去掉所有剩余 HTML 标签
inner_html = re.sub(r"<[^>]+>", "", inner_html)
# 解码常见 HTML 实体
inner_html = inner_html.replace("&", "&")
inner_html = inner_html.replace("<", "<")
inner_html = inner_html.replace(">", ">")
inner_html = inner_html.replace(" ", " ")
inner_html = inner_html.replace(" ", " ")
# 合并多余空行为最多一个空行
content = inner_html.strip()
content = re.sub(r"\n{3,}", "\n\n", content)
# ---- 过滤 UI 按钮文字 ----
content_lines = content.split("\n")
cleaned = []
for line in content_lines:
stripped = line.strip()
# 跳过仅包含 UI 按钮文字的行
if re.match(r"^(投诉|举报|赞|回应|\d+人阅读|收藏|分享|转发)\s*$", stripped):
continue
cleaned.append(line)
content = "\n".join(cleaned).strip()
# ---- Markdown 换行 ----
# 单个换行 → 两个换行符(确保 Markdown 渲染时换行)
content = re.sub(r"(?<!\n)\n(?!\n)", "\n\n", content)
# ---- 从笔记页提取书籍详情页 URL ----
# HTML: <div class="mod profile">...<a class="name" href="/subject/XXXXX/">书名</a></div>
profile_div = soup.find("div", class_="mod profile")
if profile_div:
name_link = profile_div.find("a", class_="name", href=re.compile(r"/subject/\d+"))
if not name_link:
name_link = profile_div.find("a", href=re.compile(r"/subject/\d+"))
if name_link:
book_subject_url = name_link.get("href", "")
if book_subject_url and not book_subject_url.startswith("http"):
book_subject_url = urljoin("https://book.douban.com/", book_subject_url)
if not book_subject_url:
for link in soup.find_all("a", href=re.compile(r"/subject/\d+")):
href = link.get("href", "")
if "/search/" not in href:
book_subject_url = href
if not book_subject_url.startswith("http"):
book_subject_url = urljoin("https://book.douban.com/", book_subject_url)
break
return {"chapter": chapter, "content": content, "book_subject_url": book_subject_url}
def fetch_book_info(page, book_subject_url, context, state_file):
"""从书籍详情页(/subject/XXXXX/)提取元信息"""
info = {"author": "", "subtitle": "", "publisher": "", "pub_year": ""}
if not book_subject_url or "/subject/" not in book_subject_url:
return info
try:
safe_goto(page, book_subject_url, context, state_file)
result = page.evaluate("""() => {
const div = document.querySelector('#info');
if (!div) return {};
function extractValue(labelSpan) {
let value = '';
let node = labelSpan.nextSibling;
while (node) {
if (node.nodeName === 'BR' || node.nodeName === 'SPAN') break;
if (node.nodeName === 'A') {
let text = node.textContent.trim();
if (text.endsWith(';')) text = text.slice(0, -1).trim();
value += (value ? ' / ' : '') + text;
} else if (node.nodeType === Node.TEXT_NODE) {
let text = node.textContent.replace(/[::]/g, '').trim();
if (text) value += text;
}
node = node.nextSibling;
}
return value.trim();
}
const spans = div.querySelectorAll('span.pl');
const data = {};
for (const span of spans) {
const label = span.textContent.trim().replace(/[::]/g, '');
const value = extractValue(span);
if (label === '作者' && !data.author) data.author = value;
if (label === '副标题' && !data.subtitle) data.subtitle = value;
if (label === '出版社' && !data.publisher) data.publisher = value;
if (label === '出版年' && !data.pub_year) data.pub_year = value;
}
return data;
}""")
info.update(result)
if any(info.values()):
logger.info(f" 书籍信息: 作者={info.get('author', '')}, "
f"副标题={info.get('subtitle', '')}, "
f"出版社={info.get('publisher', '')}, "
f"出版年={info.get('pub_year', '')}")
else:
logger.warning(f" 未能从 {book_subject_url} 提取到书籍信息")
except Exception as e:
logger.warning(f" 获取书籍信息失败: {book_subject_url} | {e}")
return info
# ============================================================
# 数据聚合
# ============================================================
def fetch_all_books(page, context, state_file):
"""遍历所有分页,获取所有书籍及其笔记链接"""
total_pages = get_total_pages(page, context, state_file)
all_books = {}
for p in range(1, total_pages + 1):
url = BASE_URL if p == 1 else f"{BASE_URL}?start={(p - 1) * 5}"
logger.info(f"正在解析第 {p}/{total_pages} 页...")
books = parse_list_page(page, url, context, state_file)
for book in books:
name = book["book_name"]
if name not in all_books:
all_books[name] = {"annotations": []}
all_books[name]["annotations"].extend(book["annotations"])
logger.info(f" 本页 {len(books)} 本书")
# 列表页之间额外等待,避免频繁翻页触发风控
if p < total_pages:
wait = 5 + random.random() * 5
logger.info(f" 翻页等待 {wait:.1f} 秒...")
time.sleep(wait)
# 去重
unique_books = {}
for name, data in all_books.items():
seen_urls = set()
unique = []
for ann in data["annotations"]:
if ann["url"] not in seen_urls:
seen_urls.add(ann["url"])
unique.append(ann)
unique_books[name] = {"annotations": unique}
return unique_books
# ============================================================
# Markdown 生成
# ============================================================
def generate_markdown(book_name, annotations, book_info):
"""根据书籍笔记信息和书籍元信息生成 Markdown 文本"""
lines = [f"# {book_name}", ""]
meta_parts = []
if book_info.get("author"):
meta_parts.append(f"作者:{book_info['author']}")
if book_info.get("subtitle"):
meta_parts.append(f"副标题:{book_info['subtitle']}")
if book_info.get("publisher"):
meta_parts.append(f"出版社:{book_info['publisher']}")
if book_info.get("pub_year"):
meta_parts.append(f"出版年:{book_info['pub_year']}")
if meta_parts:
lines.append("> " + " | ".join(meta_parts))
lines.append("")
lines.append("---")
lines.append("")
sorted_annotations = list(reversed(annotations))
for ann in sorted_annotations:
chapter = ann.get("chapter", "")
content = ann.get("content", "")
if not content:
continue
lines.append(f"## {chapter}")
lines.append("")
lines.append(content)
lines.append("")
return "\n".join(lines)
# ============================================================
# 书籍处理
# ============================================================
def process_book(page, book_name, annotations, output_dir,
book_idx, total_books, context, state_file):
"""处理一本书:抓取笔记 → 提取 subject URL → 获取书籍信息 → 生成 Markdown"""
filename = sanitize_filename(book_name) + ".md"
filepath = os.path.join(output_dir, filename)
# 断点续爬检查
if os.path.exists(filepath):
try:
with open(filepath, "r", encoding="utf-8") as f:
existing = f.read()
if existing.count("\n## ") >= len(annotations) and len(existing) > 100:
logger.info(f"[{book_idx}/{total_books}] 跳过已有: 《{book_name}》")
return filepath
except Exception:
pass
logger.info(f"[{book_idx}/{total_books}] 正在处理: 《{book_name}》 ({len(annotations)} 条笔记)")
# 逐条抓取笔记(从第一条笔记页提取书籍 subject URL)
book_subject_url = ""
complete_annotations = []
for i, ann in enumerate(annotations):
logger.info(f" 笔记 {i + 1}/{len(annotations)}: {ann['chapter']}")
try:
detail = parse_annotation_page(page, ann["url"], context, state_file)
if not book_subject_url and detail.get("book_subject_url"):
book_subject_url = detail["book_subject_url"]
logger.info(f" 找到书籍详情页: {book_subject_url}")
complete_annotations.append({
"chapter": detail["chapter"] or ann["chapter"],
"content": detail["content"],
})
except Exception as e:
logger.error(f" 笔记失败: {ann['url']} | {e}")
complete_annotations.append({
"chapter": ann["chapter"],
"content": f"[获取失败: {e}]",
})
# 笔记页之间额外等待,降低连续请求频率
if i < len(annotations) - 1:
wait = 4 + random.random() * 6
logger.info(f" 笔记间等待 {wait:.1f} 秒...")
time.sleep(wait)
# 获取书籍元信息
book_info = {}
if book_subject_url:
book_info = fetch_book_info(page, book_subject_url, context, state_file)
markdown = generate_markdown(book_name, complete_annotations, book_info)
with open(filepath, "w", encoding="utf-8") as f:
f.write(markdown)
logger.info(f" 已保存: {filepath}")
return filepath
# ============================================================
# 登录流程
# ============================================================
def do_login(browser, context, state_file):
"""打开可见浏览器,让用户手动登录豆瓣,完成后保存登录态"""
page = context.new_page()
logger.info("正在打开浏览器,请在页面中登录豆瓣账号...")
logger.info("")
page.goto("https://www.douban.com/", wait_until="domcontentloaded")
logger.info("等待登录完成...")
logger.info("登录后,请在终端按任意键继续(或程序会自动检测)")
logger.info("")
login_detected = False
max_auto_wait = 600
start = time.time()
has_stdin = sys.stdin and sys.stdin.isatty()
while time.time() - start < max_auto_wait:
# 自动检测
try:
if not is_blocked(page):
page.goto(BASE_URL, wait_until="domcontentloaded", timeout=10000)
if not is_blocked(page):
content = page.content()
if "annotations-item" in content or "paginator" in content:
login_detected = True
logger.info("自动检测到登录成功!")
break
except Exception:
pass
# 手动确认(跨平台兼容)
if has_stdin:
try:
key_pressed = False
if sys.platform == "win32":
import msvcrt
key_pressed = msvcrt.kbhit()
if key_pressed:
msvcrt.getch()
else:
import select
key_pressed = bool(select.select([sys.stdin], [], [], 0)[0])
if key_pressed:
sys.stdin.readline()
if key_pressed:
logger.info("收到确认,假定登录已完成。")
login_detected = True
break
except Exception:
pass
time.sleep(1)
if not login_detected:
logger.warning("登录等待超时,请重试。")
page.close()
return
save_auth_state(context, state_file)
page.close()
logger.info("")
logger.info("=" * 60)
logger.info(" 登录态已保存!现在可以运行抓取命令了:")
logger.info(" python douban_notes_scraper.py")
logger.info("=" * 60)
# ============================================================
# 主程序
# ============================================================
def main():
parser = argparse.ArgumentParser(
description="豆瓣读书笔记爬虫 (Playwright 真实浏览器版)",
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog="""
使用示例:
# 首次登录(只需一次)
python douban_notes_scraper.py --login
# 正常抓取
python douban_notes_scraper.py
# 显示浏览器窗口(推荐,可手动处理验证码)
python douban_notes_scraper.py --visible
# 测试前 3 本
python douban_notes_scraper.py --limit 3
""",
)
parser.add_argument("--output", "-o", default=None,
help=f"输出目录 (默认: {DEFAULT_OUTPUT_DIR})")
parser.add_argument("--limit", "-l", type=int, default=None,
help="只抓取前 N 本书(测试用)")
parser.add_argument("--visible", action="store_true",
help="显示浏览器窗口(推荐,可手动处理验证码)")
parser.add_argument("--login", action="store_true",
help="登录模式:打开浏览器让你手动登录")
parser.add_argument("--auth-file", default=AUTH_STATE_FILE,
help=f"登录态保存文件 (默认: {AUTH_STATE_FILE})")
args = parser.parse_args()
output_dir = args.output or os.path.join(
os.path.dirname(os.path.abspath(__file__)), DEFAULT_OUTPUT_DIR
)
os.makedirs(output_dir, exist_ok=True)
logger.info(f"输出目录: {output_dir}")
logger.info(f"浏览器模式: {'可见窗口' if args.visible else '后台运行'}")
with sync_playwright() as p:
browser, context = create_browser_and_context(
p, visible=args.visible or args.login, state_file=args.auth_file
)
if args.login:
do_login(browser, context, args.auth_file)
browser.close()
return
page = context.new_page()
try:
logger.info("=" * 60)
logger.info("第一步:获取所有书籍和笔记链接")
logger.info("=" * 60)
all_books = fetch_all_books(page, context, args.auth_file)
total_books = len(all_books)
total_annotations = sum(
len(data["annotations"]) for data in all_books.values()
)
logger.info(f"共发现 {total_books} 本书,{total_annotations} 条笔记")
book_items = list(all_books.items())
if args.limit:
book_items = book_items[:args.limit]
logger.info(f"测试模式:仅处理前 {args.limit} 本书")
logger.info("=" * 60)
logger.info(f"第二步:获取笔记完整内容 (共 {len(book_items)} 本书)")
logger.info("=" * 60)
start_time = time.time()
completed = 0
failed = 0
for idx, (book_name, data) in enumerate(book_items, 1):
try:
process_book(
page, book_name, data["annotations"],
output_dir, idx, len(book_items),
context, args.auth_file,
)
completed += 1
except Exception as e:
logger.error(f"[{idx}/{len(book_items)}] 《{book_name}》 处理失败: {e}")
failed += 1
# 书与书之间额外等待,避免连续抓取多本书触发风控
if idx < len(book_items):
wait = 10 + random.random() * 10
logger.info(f" 书籍间等待 {wait:.1f} 秒...")
time.sleep(wait)
if idx % 5 == 0:
save_auth_state(context, args.auth_file)
elapsed = time.time() - start_time
save_auth_state(context, args.auth_file)
logger.info("=" * 60)
logger.info("完成!统计信息:")
logger.info(f" 输出目录: {output_dir}")
md_files = list(Path(output_dir).glob("*.md"))
logger.info(f" 生成文件数: {len(md_files)}")
total_chars = sum(f.stat().st_size for f in md_files)
logger.info(f" 总字符数: {total_chars:,}")
logger.info(f" 成功: {completed} 本 | 失败: {failed} 本")
logger.info(f" 耗时: {elapsed:.0f} 秒 ({elapsed / 60:.1f} 分钟)")
logger.info("=" * 60)
except KeyboardInterrupt:
logger.info("\n用户中断,正在保存进度...")
save_auth_state(context, args.auth_file)
logger.info("登录态已保存,下次运行会自动跳过已完成的书籍。")
except Exception as e:
logger.error(f"运行出错: {e}")
save_auth_state(context, args.auth_file)
logger.info("登录态已保存。")
raise
finally:
try:
browser.close()
except Exception:
pass
if __name__ == "__main__":
main()四、总结
从传统 requests 到 Playwright 浏览器自动化,爬虫技术的演进本质上是"伪装能力"的升级。传统爬虫试图在 HTTP 协议层模拟浏览器,但 TLS 指纹、HTTP/2 指纹、JavaScript 执行环境等方面的差异使其越来越容易被识别。Playwright 则从根本上解决了这个问题------直接使用真实浏览器,服务端无法区分自动化流量和人工操作。
然而,无论伪装多么逼真,基于 IP 的频率限制始终是无法绕过的底线。这是服务端风控的最后一道防线,也是最有效的。应对策略不是技术上的对抗,而是行为上的模拟------放慢速度、增加随机性、在人机协作中找到平衡。最终版本的爬虫在速度上做了很大妥协,但换来的是稳定性和可靠性。
这也反映了一个更本质的认识:爬虫不是"越快越好",而是"越像人越好"。真正的反爬对抗不是技术层面上的军备竞赛,而是行为层面上的博弈。