基于高斯径向基函数(GRBF)的多输入单输出神经网络模型
在机器学习和复杂系统建模的浩瀚星海中,多层感知机(MLP)和深度神经网络(DNN)往往占据了各大新闻的头条。然而,在诸多工程领域、控制理论以及高精度拟合任务中,有一种网络凭借其独特的局部逼近能力 和扎实的数学基础 始终占据着不可替代的地位------这就是径向基函数神经网络(RBFNN)。
今天,我们将褪去代码的外衣,纯粹从理论和数学的视角,深度解剖一个经典的架构:基于高斯径向基函数(GRBF)的多输入单输出(MISO)神经网络模型。
一、 什么是多输入单输出(MISO)的 GRBF 网络?
在探讨内部机制之前,我们需要先明确模型的输入输出形态:
- 多输入(Multiple-Input): 意味着模型接收的是一个特征向量。例如,在预测房价时,输入可能包含面积、房间数、房龄等多个维度的信息。
- 单输出(Single-Output): 意味着模型最终只输出一个标量值,即我们关注的预测目标(如具体的房价)。
而 GRBF (Gaussian Radial Basis Function) 则是这个网络的心脏。与传统神经网络使用 Sigmoid 或 ReLU 作为激活函数不同,GRBF 网络在隐藏层使用"高斯径向基函数"来进行非线性空间变换。
二、 架构解剖:经典的三层拓扑
GRBF 网络结构极其简练,严格遵循前馈型三层拓扑结构。这种结构不仅在数学上被证明具有"万能逼近"特性,在逻辑上也极为清晰。
1. 输入层 (Input Layer)
输入层本身不进行任何计算。它的唯一任务是将 nnn 维的输入向量 x=x1,x2,...,xnTx = x_1, x_2, ..., x_n^Tx=x1,x2,...,xnT 传递给隐藏层。
2. 隐藏层 (Hidden Layer) ------ 核心变换区
隐藏层由 kkk 个神经元组成。这里的每一个神经元都代表着多维空间中的一个"基点"(或中心)。
当输入向量 xxx 到达隐藏层时,模型不再计算简单的线性加权和(即不计算 wTx+bw^Tx + bwTx+b),而是计算输入向量 xxx 与各个神经元中心点 ccc 之间的"距离"。
3. 输出层 (Output Layer) ------ 线性整合
经过隐藏层的非线性变换后,原本在低维空间难以线性分割的数据,被映射到了高维空间。此时,输出层只需对隐藏层的输出进行简单的线性加权求和,即可得到最终的预测结果。
三、 核心数学原理:解密"高斯"与"径向基"
为了真正理解 GRBF,我们需要拆解它的数学公式。
为什么叫"径向基 (Radial Basis)"?
"径向"意味着该函数的值仅仅取决于输入向量 xxx 到某个中心点 ccc 的径向距离 。在绝大多数情况下,这个距离采用的是欧几里得距离 ∣∣x−c∣∣||x - c||∣∣x−c∣∣。你可以把它想象成水面上投入一颗石子后荡起的圆形波纹,离中心越远,波纹(函数值)的衰减越有规律。
高斯核函数 (Gaussian Kernel)
在众多的径向基函数中,高斯函数是最常用且表现最优异的。第 iii 个隐藏层神经元的输出 ϕi(x)\phi_i(x)ϕi(x) 定义为:
ϕi(x)=exp(−∣∣x−ci∣∣22σi2)\phi_i(x) = \exp\left( -\frac{||x - c_i||^2}{2\sigma_i^2} \right)ϕi(x)=exp(−2σi2∣∣x−ci∣∣2)
在这个公式中,藏着 GRBF 网络的两个核心参数:
- cic_ici (中心点/Center): 决定了该神经元对输入空间中哪个区域最敏感。当输入 xxx 刚好等于 cic_ici 时,距离为 0,ϕi(x)\phi_i(x)ϕi(x) 达到最大值 1。
- σi\sigma_iσi (宽度/Width 或 Spread): 决定了高斯函数的"胖瘦"(即感受野的大小)。σ\sigmaσ 越大,函数的衰减越慢,神经元的影响范围越广;σ\sigmaσ 越小,函数越尖锐,神经元只对极其靠近中心的数据有反应。
最终的输出方程
对于单输出网络,最终的预测值 yyy 是隐藏层激活值的线性组合:
y=∑i=1kwiϕi(x)+by = \sum_{i=1}^{k} w_i \phi_i(x) + by=i=1∑kwiϕi(x)+b
其中,wiw_iwi 是第 iii 个隐藏神经元到输出层的连接权重,bbb 是偏置项(有时可省略)。
四、 局部逼近 vs. 全局逼近
理解 GRBF 网络的一个关键切入点,是对比它与传统多层感知机(MLP)的非线性映射机制:
- MLP 的全局逼近: 像 Sigmoid 或 ReLU 这样的激活函数,其影响是全局的。改变网络中的某一个权重,可能会牵一发而动全身,导致整个输入空间的输出发生变化。
- GRBF 的局部逼近: 高斯函数的特性决定了,当输入远离中心点 ccc 时,激活值呈指数级衰减至极小值。这意味着,每一个隐藏神经元只负责"认领"并拟合输入空间中的一小块局部区域。
这种"局部逼近"特性赋予了 GRBF 网络一个巨大的优势:抗遗忘能力强。在增量学习或在线更新时,调整某一区域的参数,几乎不会干扰到模型在其他区域已学到的知识。
五、 参数学习策略
一个 MISO 的 GRBF 网络需要确定三组关键参数:中心点 ccc 、宽度 σ\sigmaσ 以及输出权重 www。与传统 DNN 暴力使用梯度下降进行端到端训练不同,GRBF 通常采用**两步走(Two-Stage)**的混合学习策略,这使得它的训练效率极高。
- 第一阶段(无监督学习 - 确定 ccc 和 σ\sigmaσ):
- 中心点 ccc: 通常使用 K-Means 聚类算法在训练数据中寻找代表性的簇中心,将其作为高斯核的中心。
- 宽度 σ\sigmaσ: 常用启发式方法,例如计算簇内样本的平均距离,或使用最邻近中心之间的距离来设定,确保各个高斯核之间既有重叠,又不会过度干涉。
- 第二阶段(有监督学习 - 确定 www):
- 当 ccc 和 σ\sigmaσ 确定后,隐藏层的输出 ϕi(x)\phi_i(x)ϕi(x) 就变成了已知常量。此时,整个网络退化为一个简单的多元线性回归模型。
- 权重 www 可以直接通过**最小二乘法(Least Squares)或伪逆矩阵(Pseudo-inverse)**一步求解,彻底避免了梯度下降中的局部最优和收敛缓慢问题。
(注:当然,也可以使用非线性优化算法或反向传播对所有参数进行全局微调,但这通常会增加计算成本。)
六、 部分代码
c
clear;
clc;
close all;
rng(2);
tic;
%% 1. 读取数据
data = xlsread('data.xlsx');
X = data(:,1:end-1)';
Y = data(:,end)';
% 数据划分
[trainInd, ~, testInd] = dividerand(size(X,2), 0.7, 0, 0.3);
X_train = X(:, trainInd);
Y_train = Y(:, trainInd);
X_test = X(:, testInd);
Y_test = Y(:, testInd);
% 归一化
[X_train, ps_input] = mapminmax(X_train, 0, 1);
[Y_train, ps_output] = mapminmax(Y_train, 0, 1);
X_test = mapminmax('apply', X_test, ps_input);
Y_test = mapminmax('apply', Y_test, ps_output);
%% 2. 参数设置
input_dim = size(X_train,1);
num_neurons = 10; % 隐藏层神经元数量
% 初始化可学习参数
centers = rand(input_dim, num_neurons); % 核中心 (原名 C)
widths = 0.1 + 0.2*rand(1, num_neurons); % 核宽度 (原名 Sigma)
output_weights = randn(1, num_neurons); % 输出权重 (原名 W)
% 将参数打包成向量
params_init = [centers(:); widths(:); output_weights(:)]; % 原名 theta0七、 运行截图
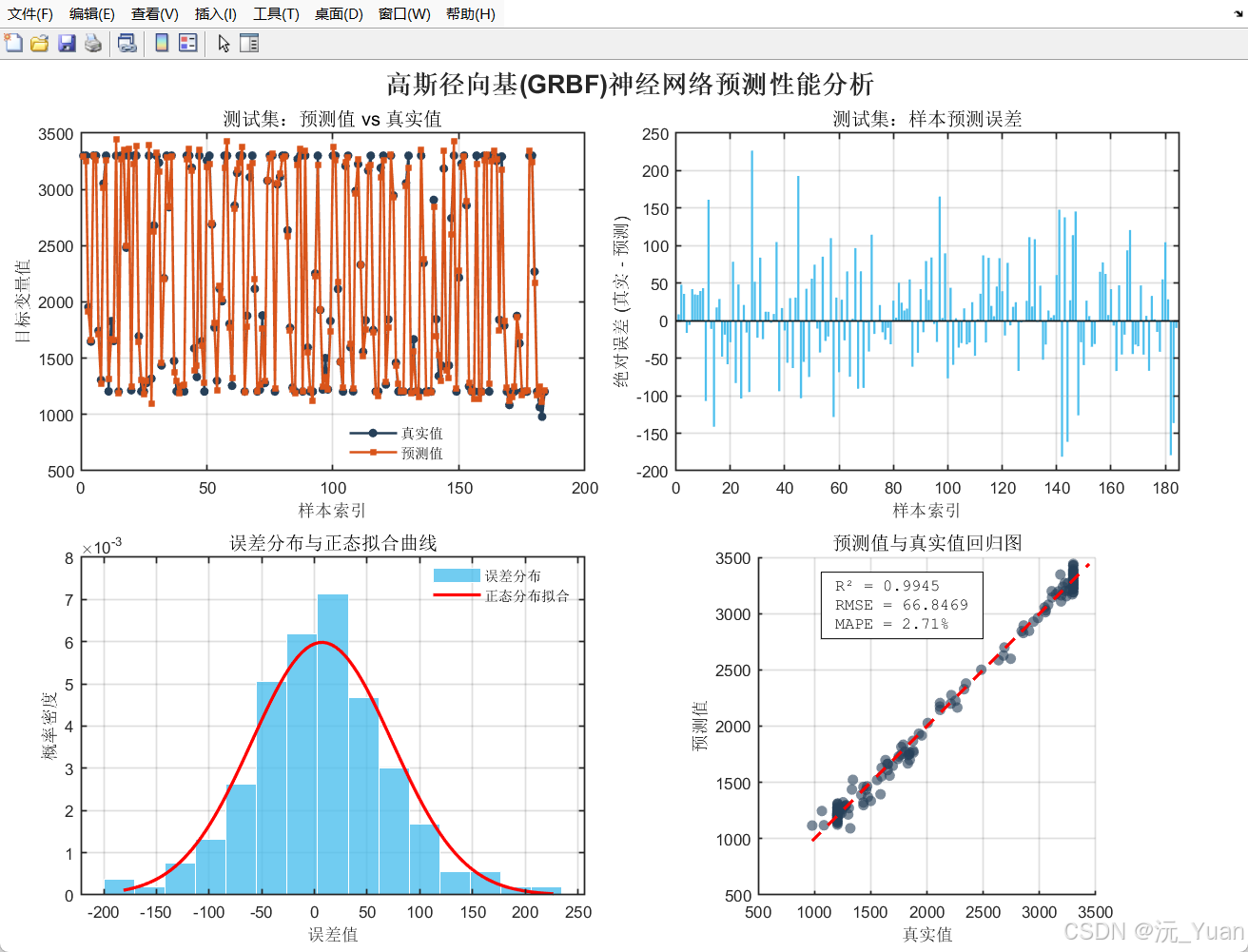
八、 总结与思考:优势与局限同在
💡 核心优势
- 极强的非线性拟合能力: 基于理论证明,只要隐藏层神经元足够多,GRBF 可以以任意精度逼近任意连续函数。
- 训练速度快: 若采用两步混合学习法,尤其是输出权重的解析求解,使得其训练速度远超传统反向传播网络。
- 解释性相对较好: 相比于完全"黑盒"的深度网络,GRBF 的隐层节点具有明确的物理意义(即输入空间的原型/聚类中心)。
⚠️ 面临的挑战
- 维数灾难(Curse of Dimensionality): 当输入特征维度(多输入的 nnn)非常高时,为了覆盖整个庞大的输入空间,所需的中心点数量会呈指数级爆炸。
- 对中心点敏感: 网络的性能高度依赖于中心点 ccc 和宽度 σ\sigmaσ 的选取。如果聚类效果不佳,模型的泛化能力会大幅下降。
结语: 基于高斯径向基函数的多输入单输出神经网络,以其优雅的数学结构和高效的局部逼近机制,在非线性时间序列预测、复杂工业控制等领域绽放着持久的生命力。理解其背后的理论逻辑,将帮助我们在面对具体数据时,更从容地选择和调优这一强大的算法工具。