本文覆盖范围:SFT 监督微调、RLHF(PPO)强化学习对齐、DPO 直接偏好优化,以及它们的变体、工具链、实战代码和选择决策。结合 InstructGPT、LLaMA 2/3、Zephyr、DeepSeek-R1、Qwen3 等真实案例说明。
一、为什么需要后训练(Post-Training)?
预训练(Pre-Training)让一个语言模型学会了"下一个 token 是什么"------它掌握了语言规律、广博的世界知识、甚至初步的推理能力。但预训练的优化目标是最大化训练语料的对数似然,这意味着模型学会的是"互联网平均水平的文字接龙",而不是"对人类有帮助、无害、诚实的回答"。
给一个纯预训练模型发送"帮我写一封道歉信",它可能会继续生成"帮我写一封道歉信的示例......"或者索性开始胡说八道------因为训练数据里这类格式的文本不少。它不理解"用户"和"助手"的角色关系,不知道什么是有用的回答,也不懂得拒绝有害请求。
后训练(Post-Training)正是解决这个问题的一套流程,其核心目标是:
- 行为对齐(Behavioral Alignment):让模型按照指令行事,而不只是续写文本
- 偏好对齐(Preference Alignment):让模型的输出符合人类的价值偏好(有用、无害、诚实)
- 能力激活(Capability Activation):激发模型在推理、代码、数学等特定领域的潜力
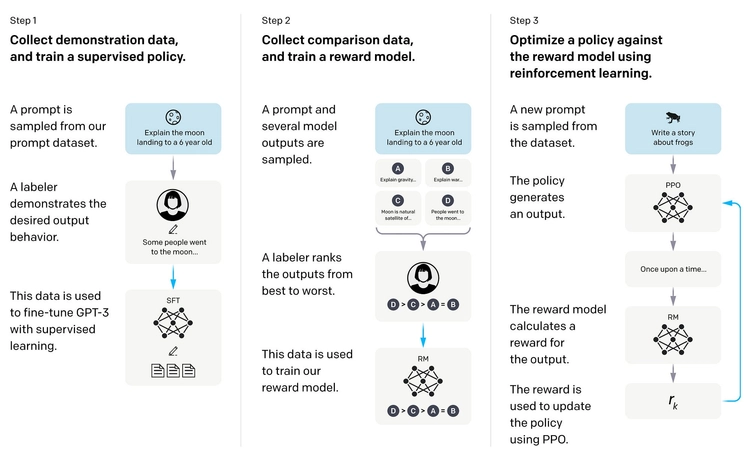
一个完整的后训练历史可以分为三个阶段:第一阶段,InstructGPT 提出了 SFT + RLHF 的标准流程,让模型能够遵循指令,代表模型是 GPT-3.5 和早期 ChatGPT;第二阶段,DPO 通过消除独立奖励模型降低了对齐的复杂度,让中小团队也能做对齐,代表模型是 Zephyr、Intel NeuralChat、早期 LLaMA 微调版本;第三阶段,DeepSeek-R1 证明了纯 RL 能产生突破性推理能力,GRPO 成为标准,代表模型是 DeepSeek-R1、QwQ、Kimi k1.5。
理解这三个阶段,就等于理解了整个后训练技术的演化逻辑。下面我们逐一深入。
二、SFT:监督微调,一切的起点
2.1 什么是 SFT?
SFT(Supervised Fine-Tuning,监督微调)是后训练的第一步,也是最直观的一步:给模型看大量高质量的(指令,回答)对,用标准的交叉熵损失训练模型去模仿这些示范回答。
从优化角度,SFT 的损失函数是:
其中 是指令(prompt),
是期望的回答,
是模型。这与预训练的语言建模损失在形式上完全一样,差别只在于:SFT 的数据是精心设计的高质量(指令, 回答)对,而且只在回答部分计算 loss,不对指令部分计算 loss(让模型学会"如何回答",而不是"如何提问")。
这一点在代码上体现为:将指令部分的 token 的 label 设置为 -100(PyTorch 会忽略 label=-100 的位置),只让模型在回答 token 上反向传播。
2.2 SFT 数据的格式
现代大模型的 SFT 数据通常用 ChatML 格式组织多轮对话:
<|im_start|>system
你是一个有帮助的助手。<|im_end|>
<|im_start|>user
帮我解释一下什么是黑洞。<|im_end|>
<|im_start|>assistant
黑洞是宇宙中一种极端的天体,其引力强到连光都无法逃脱......<|im_end|>这种格式明确区分了系统提示、用户输入和模型回答,让模型学会角色扮演。
2.3 SFT 用在哪些模型中?
Stanford Alpaca(2023):最早的开源 SFT 实验之一。用 GPT-3.5 生成的 52K 条指令-回答对,对 LLaMA-7B 做 SFT,就能得到一个基本能对话的模型。成本极低但效果惊人,开启了"用 AI 生成 SFT 数据"的先河。
InstructGPT(OpenAI, 2022):SFT 是 RLHF 三阶段流程的第一步。先用人工标注的约 13000 条(prompt, 演示回答)对做 SFT,得到一个基础对话模型,再继续做 RLHF。
LLaMA 2-Chat(Meta, 2023):在经过 SFT 预热后,再做 RLHF(迭代式 PPO + 拒绝采样)。SFT 数据来自 Meta 内部的人工标注对话。
DeepSeek-R1-Distill 系列:通过对 LLaMA 3 和 Qwen2.5 基座模型,用 DeepSeek-R1 生成的 80 万条长链式推理(CoT)数据做 SFT,直接蒸馏出了具备推理能力的小模型------完全不用 RL。这说明 SFT 在数据质量足够高时,能够有效传递大模型的推理模式。
2.4 SFT 的局限性
SFT 的本质是模仿学习(Imitation Learning),它有两个根本局限:
第一,覆盖范围限于训练数据。模型只能学到训练数据中展示过的行为模式。对于训练数据没有涉及的新场景,SFT 模型的泛化能力有限。
第二,无法表达"哪个更好"。SFT 给模型展示的是"正确"答案,但没有展示"哪种正确答案更好"。对于同一个问题,简洁清晰的回答和冗长啰嗦的回答,在 SFT 的 loss 里差别不大------只要都是"正确"的。
第二个局限正是 RLHF 和 DPO 要解决的问题。
2.5 用 TRL 的 SFTTrainer 做实战
HuggingFace TRL 库提供了 SFTTrainer,封装了 SFT 的完整流程:
python
from datasets import load_dataset
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import SFTConfig, SFTTrainer
from peft import LoraConfig
# 加载基础模型
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2.5-7B",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B")
# LoRA 配置:只训练部分参数,节省显存
lora_config = LoraConfig(
r=64,
lora_alpha=128,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 加载对话数据集(ChatML 格式)
dataset = load_dataset("trl-lib/Capybara", split="train")
# SFT 训练配置
sft_config = SFTConfig(
output_dir="./sft_output",
num_train_epochs=3,
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
learning_rate=2e-4,
warmup_ratio=0.03,
lr_scheduler_type="cosine",
bf16=True,
logging_steps=10,
save_steps=500,
max_length=2048,
# 关键:只在 assistant 的回答部分计算 loss
dataset_text_field="messages",
)
trainer = SFTTrainer(
model=model,
args=sft_config,
train_dataset=dataset,
peft_config=lora_config,
tokenizer=tokenizer,
)
trainer.train()
trainer.save_model("./sft_final")对于自定义数据集,数据格式需要包含 messages 字段,每条样本是一个对话列表:
# 自定义数据集格式
{
"messages": [
{"role": "system", "content": "你是一个专业的法律顾问。"},
{"role": "user", "content": "合同违约怎么处理?"},
{"role": "assistant", "content": "合同违约的处理方式包括......"}
]
}TRL 的 SFTTrainer 会自动检测对话格式,应用对应的 chat template,并将 assistant 之外的 token 的 label 设为 -100。
三、RLHF:用人类反馈做强化学习
3.1 为什么需要 RLHF?
SFT 之后,模型已经能按格式回答问题了,但回答质量的细微差别------是否更有帮助、是否更安全、语气是否合适------SFT 数据难以精确刻画。
这里有一个著名的洞察,来自 InstructGPT 论文:与其让标注员写出"完美答案"(这很难),不如让他们比较两个答案哪个更好(这相对容易)。人类擅长做评判,不擅长从头创作完美示范。
RLHF(Reinforcement Learning from Human Feedback)正是利用了这一点:收集人类对模型输出的偏好比较,训练一个奖励模型来量化这种偏好,然后用强化学习(通常是 PPO)来优化模型使其最大化奖励模型的得分。
3.2 RLHF 的三个阶段
阶段一:SFT(已覆盖)
预训练模型 → SFT 微调 → 得到 ,作为后续的初始策略和参考模型。
阶段二:训练奖励模型(Reward Model, RM)
收集偏好数据:对同一个 prompt,让 SFT 模型生成多个回答,让人工标注员对这些回答进行排序(哪个更好)。这个排序数据被整理成对 ,其中
是被偏好的(chosen)回答,
是被拒绝的(rejected)回答。
奖励模型的训练目标是:让 ,即给好的回答打更高的分。标准做法是在 SFT 模型的基础上添加一个回归头(regression head),训练损失为:
这是一个 Bradley-Terry 模型------只关心两个回答奖励分的相对大小,不需要绝对分数。
阶段三:用 PPO 做强化学习
有了奖励模型,现在把语言模型的生成过程视为一个强化学习问题:
- 状态(State):当前的 prompt 和已生成的 token 序列
- 动作(Action):生成下一个 token(词表大小的离散动作空间)
- 奖励(Reward):只在序列结束时给予一次奖励(来自奖励模型的评分)
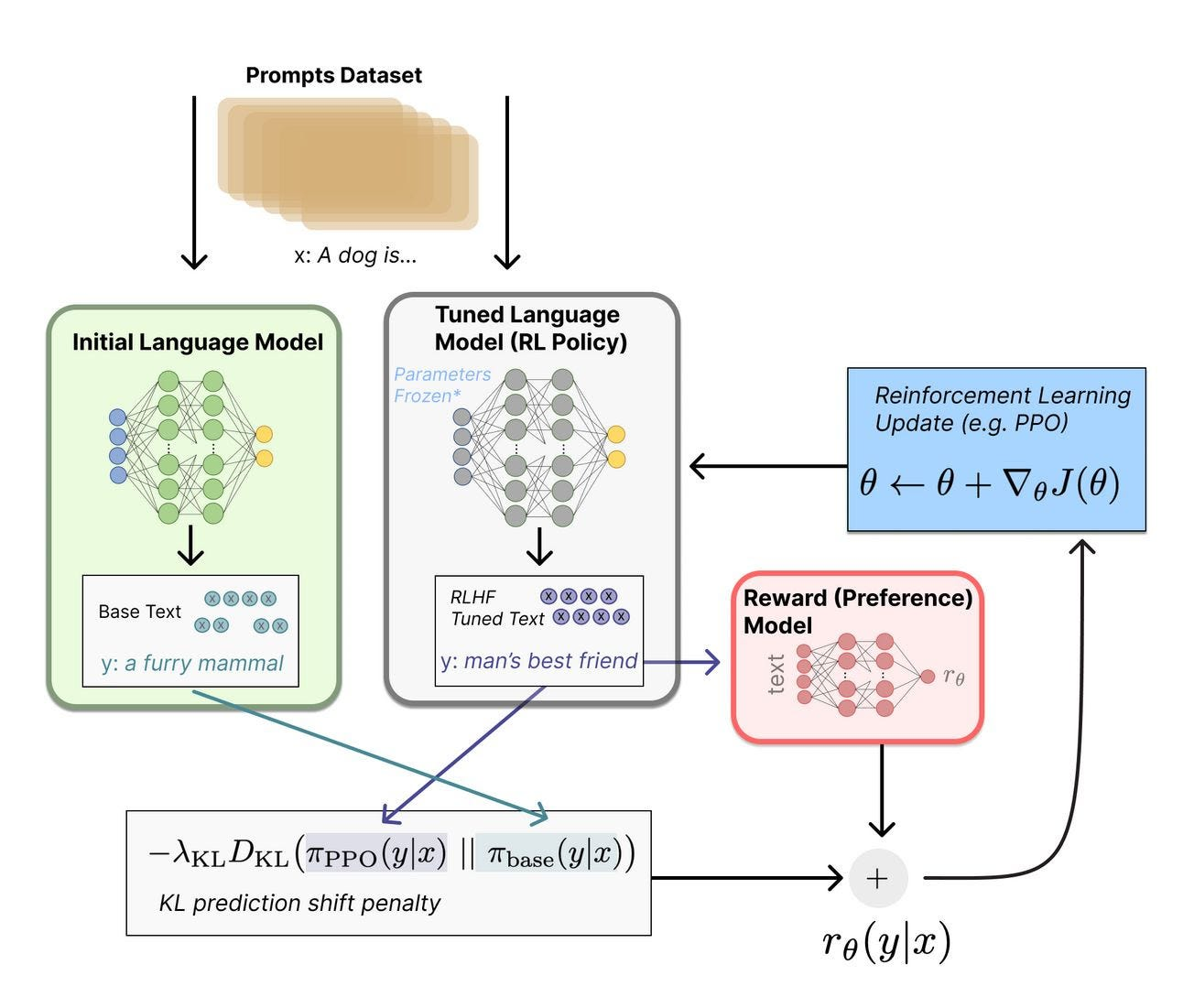
问题是奖励函数不连续、序列很长(稀疏奖励),直接做梯度优化困难。PPO 通过重要性采样和 clip 操作解决了训练稳定性问题,同时加入 KL 散度约束防止模型偏离 SFT 版本太远。在3.3中详细补充解释了使用PPO的重要性。
完整的 PPO 优化目标是:
其中 是 KL 惩罚系数。KL 项有两个作用:防止奖励黑客(reward hacking,模型学会用奇怪的方式骗过奖励模型而不是真正有用);防止模型能力退化(偏离 SFT 太远会丢失已学到的知识)。
3.3 语言模型的 RL 难题,以及 PPO 如何解决它
要理解为什么 PPO 是 RLHF 的标准算法,需要先搞清楚"直接用 RL 优化语言模型"面临哪些根本性困难。
困难一:动作空间是离散的,无法直接求梯度
强化学习的目标是最大化期望累积奖励。在连续动作空间(比如控制机器人关节角度)里,可以直接对动作求梯度,用梯度上升来改进策略。
但语言模型的"动作"是从词表中采样一个 token------这是一个离散的采样操作。离散采样不可微,梯度无法通过采样操作反向传播回模型参数。这意味着你没法用一个简单的 loss.backward() 来更新模型,RL 必须用策略梯度(Policy Gradient)方法:通过"好的回答就增大其概率,坏的回答就减小其概率"这样的估计来间接更新参数。
困难二:稀疏奖励
一个完整的回答可能有几百到几千个 token。但奖励模型只在整条回答生成完毕之后,对整个回答打一个分数------这就是稀疏奖励(Sparse Reward)。
"稀疏"的意思是:模型在生成过程中,对每一步(每个 token)的决策都是在"盲飞",没有任何即时信号告诉它这一步走得好不好,直到最后才得到一个全局评分。举个极端的例子:生成了 500 个 token,奖励模型打了 6 分。你不知道是前 100 个 token 写得好、还是后 100 个,还是某个关键转折点决定了这个分。
这种信用分配(credit assignment)问题让训练极其困难------模型很难从稀疏信号中学到"哪一步导致了好结果"。
困难三:每步 policy 更新后数据立即过期
策略梯度方法要求用"当前策略"生成的数据来计算梯度更新当前策略(on-policy)。这意味着每次更新模型参数之后,刚才生成的那批数据就作废了,必须重新采样------计算效率极低。
更糟的是,如果你想多次利用同一批数据做几步梯度更新(提升数据效率),每更新一步,当前策略就和生成数据时的旧策略之间的差距就大了一步。如果差距太大,梯度估计就会偏差很大,甚至导致策略崩溃(更新步子太大,模型直接退化)。
PPO 如何解决这三个问题
PPO(Proximal Policy Optimization,近端策略优化)是一个策略梯度算法,专门为解决上面第三个问题------"如何安全地多次利用旧数据"------而设计的,同时配合其他机制处理前两个问题。
重要性采样(Importance Sampling):让旧数据可以复用
核心思路是:用当前策略 的期望奖励来表达,但实际采样来自旧策略
,通过乘以一个修正系数(重要性权重)来补偿两者之间的分布差异:
这个比值 就是重要性权重。当
时,说明当前策略比旧策略更倾向于生成这个 token;
则相反。通过乘以这个比值,就可以用旧数据来近似估计当前策略的梯度。
但问题是:如果 和
差距太大,这个比值可以变得非常大或非常小,导致梯度估计方差爆炸,更新极不稳定。
Clip 截断:给更新幅度加保险
PPO 的核心创新就在这里------对重要性权重进行截断(clip),防止单步更新幅度过大:
其中 通常取 0.1 或 0.2。这个公式的含义是:
- 如果
(这个 token 是好的,应该增大概率),当
- 如果
取 min 的目的是:总是选择"更保守"的那个估计,确保策略更新是悲观的而非激进的。这个简单的截断操作使得 PPO 在实践中极其稳定,即便在每批数据上做多次梯度更新也不容易崩溃。
优势函数(Advantage):解决稀疏奖励的信号分配
策略梯度不能直接用原始奖励 ,而是用优势函数
。优势函数的定义是:在状态
下采取动作
的实际回报,与该状态下平均期望回报之差:
其中 是价值函数(当前状态的期望回报),
是采取了动作
之后的实际累积回报。
意味着这步动作比平均水平好,应该增强;
意味着比平均水平差,应该抑制。
用优势而非原始奖励的好处是:减少了梯度估计的方差(即使奖励绝对值很大,优势函数代表的是相对增益,更稳定),并且通过价值函数 对奖励信号做了时序上的分解,缓解了稀疏奖励带来的信用分配问题。
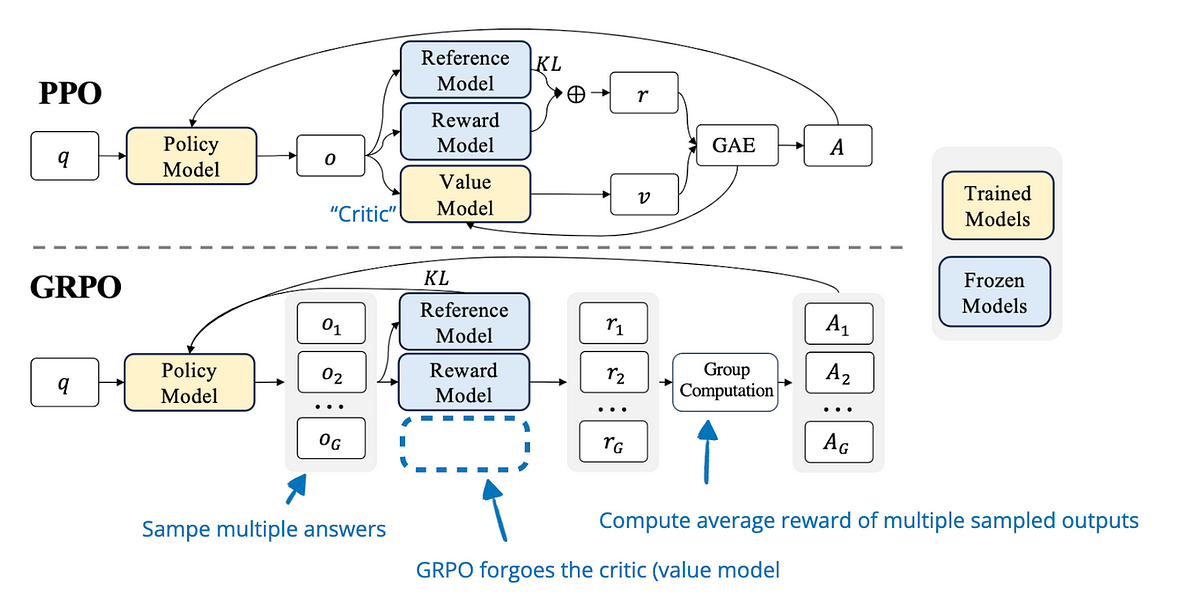
但要计算 ,你需要一个能估计"当前序列接下来能拿多少分"的网络------这就是 Critic 模型的来历。
为什么 PPO 需要四个模型
这里从头捋清楚。在进入 PPO 阶段之前,已经存在三个模型:
① SFT 模型(Reference Model,参考模型)
SFT 阶段训练完的模型,在 PPO 阶段被冻结,不参与训练。它的作用是提供 KL 散度约束的基准------PPO 在优化策略模型时,会惩罚策略模型与 SFT 模型之间的 KL 散度过大。这防止了奖励黑客:如果策略模型可以无限偏离 SFT 模型,它可能会学会用乱码或奇怪格式来骗奖励模型打高分,同时完全丧失语言能力。冻结的参考模型是一个"语言能力的锚点"。
② 奖励模型(Reward Model,RM)
用人类偏好数据(chosen/rejected 对)单独训练的一个打分网络,在 PPO 阶段也被冻结。它负责对策略模型生成的每条完整回答给出一个标量分数,这个分数就是稀疏奖励信号的来源。没有奖励模型,PPO 就不知道往哪个方向优化。
这两个模型(参考模型和奖励模型)加在一起,就是 RLHF 体系在进入 PPO 前就需要准备好的部分。
③ Actor 模型(策略模型,Policy)
这是我们真正要训练的目标模型,初始化自 SFT 模型,在 PPO 过程中持续更新。它负责接收 prompt,生成回答,参数不断被梯度更新。
④ Critic 模型(价值模型,Value Model)
如上所述,Critic 是 PPO 引入的额外模型,负责估计当前状态(已生成的序列)的期望未来奖励 ,用于计算优势函数
。没有 Critic,PPO 无法计算优势,只能用原始奖励做策略梯度,方差极大,训练极不稳定。
Critic 通常初始化自奖励模型(因为奖励模型已经理解了"什么样的输出是好的"),并在训练过程中与 Actor 一起更新。在实现上,Critic 的大小通常与 Actor 相同------因为它需要处理同样的长序列输入,同样需要深度理解语义。
四个模型的协作流程是这样的:
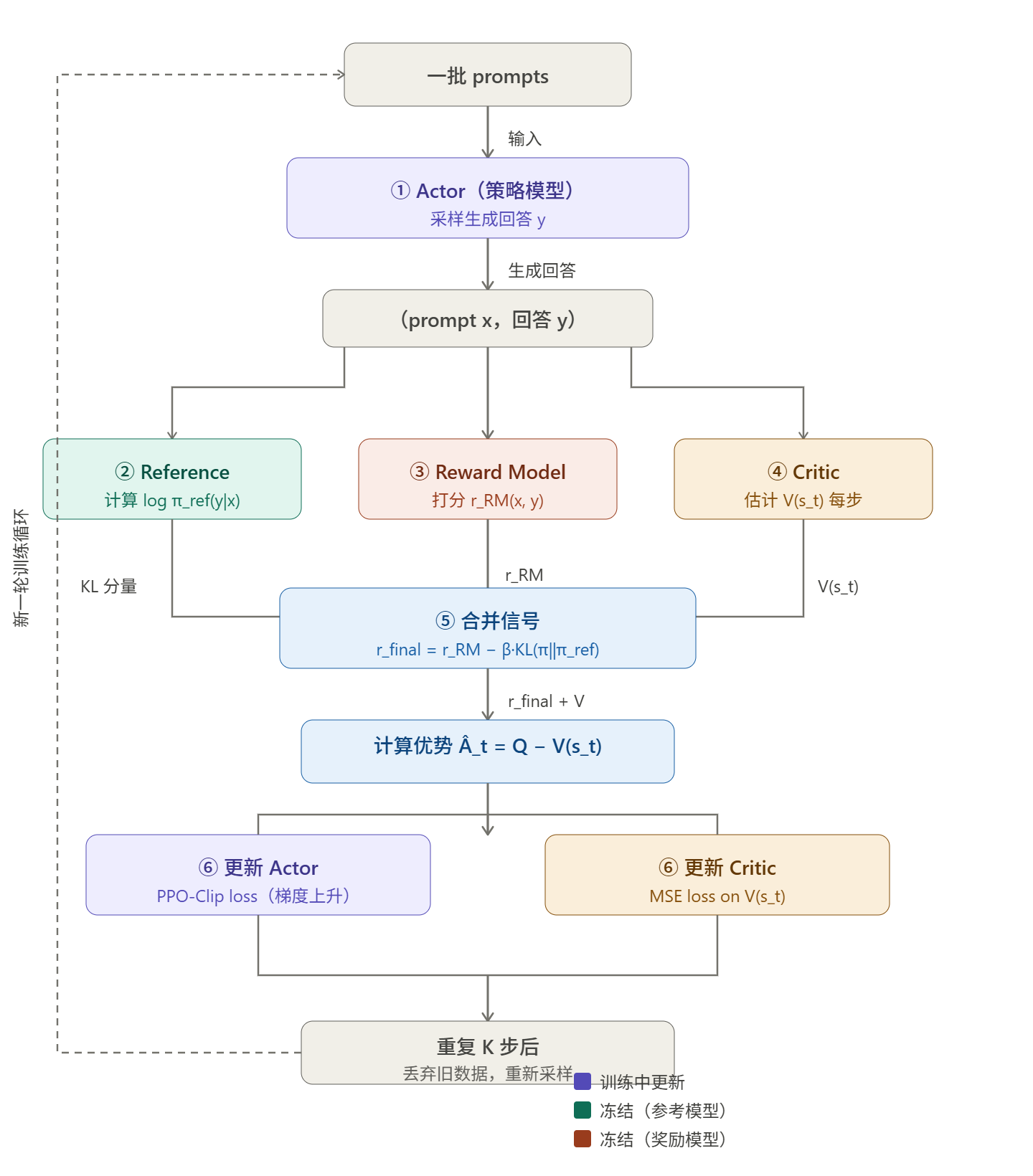
这四个模型在训练时通常需要同时保持在 GPU 内存中(或通过 offload 换出),这正是 PPO-RLHF 内存开销极大的根本原因。对于一个 7B 的 Actor,在 BF16 下约需 14GB;Critic 同样 14GB;Reference 14GB;RM 14GB------合计约 56GB,还不算梯度、优化器状态、激活值。这就是为什么完整的 PPO-RLHF 需要多卡甚至大规模集群,也是 DPO(只需 Actor + Reference,两个模型)和 GRPO(消除 Critic)被广泛采用的核心动机。
3.4 真实案例:InstructGPT 和 LLaMA 2
InstructGPT(OpenAI, 2022):标准 RLHF 三阶段流程的教科书案例。用约 33000 个偏好比较对训练奖励模型,用 PPO 对策略模型做 RL 优化。论文中著名的结论是:经过 RLHF 的 1.3B 参数模型在人类偏好评分上超过了未经 RLHF 的 175B 参数模型------说明对齐的重要性远超单纯的参数规模。
LLaMA 2-Chat(Meta, 2023):Meta 的 LLaMA 2-Chat 模型通过对大规模助手风格语料做 SFT,然后用迭代式 RLHF 训练。训练了独立的有用性和安全性奖励模型,使用来自 Meta 自身聊天数据集的数百万人类偏好比较。RLHF 在拒绝采样和 PPO 步骤之间交替进行。
3.5 RLHF 的局限性
RLHF/PPO 的工程复杂度和计算成本极高,而且存在以下问题:
奖励黑客(Reward Hacking):模型学会了取悦奖励模型而不是真正有用。例如,某些奖励模型喜欢长回答,模型就会不断生成冗余内容来刷高分,而不是给出简洁有效的回答。
训练不稳定:PPO 本身就对超参数敏感,在语言模型这种极大的动作空间(词表大小的动作)上更难调优。
数据收集成本:收集高质量的人类偏好标注数据成本高昂,且难以规模化。
这些局限性催生了 DPO 的出现。
四、DPO:把 RLHF 重新表述为分类问题
4.1 DPO 的核心洞察
DPO(Direct Preference Optimization,直接偏好优化)由 Rafailov et al. 在 2023 年提出,它的出发点是:RLHF 的 PPO 优化步骤是否真的必要?
答案是------在某些条件下,不必要。DPO 论文的关键贡献是一个数学推导,证明了:在 RLHF 的 KL 约束优化问题中,最优策略 与参考策略
之间存在一个闭合形式的关系,可以直接用来绕过奖励模型的显式训练。
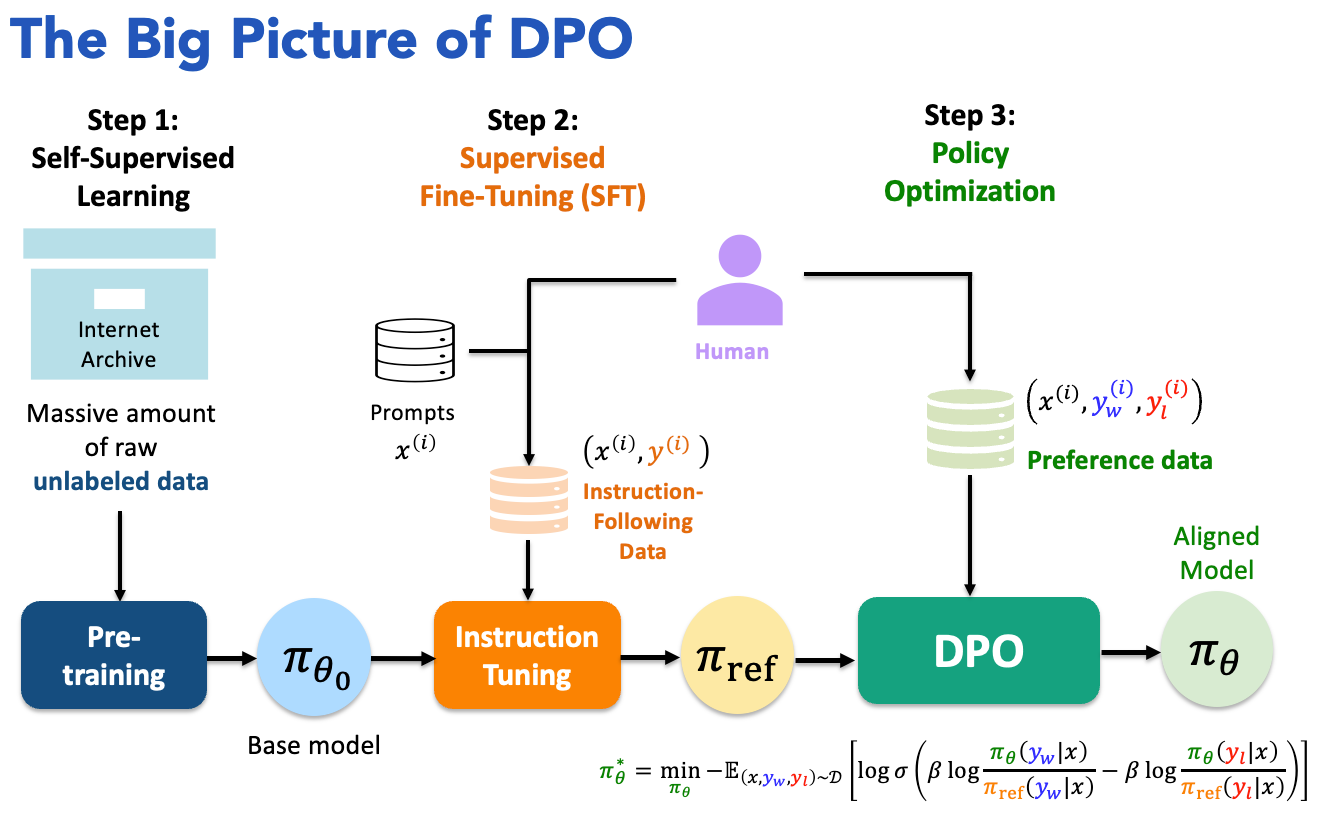
推导步骤如下:
第一步:RLHF 的优化目标(带 KL 约束):
第二步 :可以证明,该优化问题的最优解 满足:
其中 是归一化常数。
第三步 :从上式反解出奖励函数 :
第四步 :将这个表达式代入 Bradley-Terry 奖励模型的偏好概率公式, 被约掉,得到 DPO 的损失函数:
这个公式可以用语言来解读:DPO 希望模型在偏好回答 上的相对提升 (相比参考模型)大于在拒绝回答
上的相对提升 。简单说:让好的回答的概率增大,让坏的回答的概率减小,同时约束不要偏离参考模型太远(由
控制)。
这里的关键字是"相对" :DPO 不是直接最大化 ,而是最大化
与
的差距。
(冻结的 SFT 模型)起到了归一化的作用。
4.2 DPO 的优势与代价
优势:
- 不需要显式训练奖励模型
- 不需要 PPO 的复杂 RL 循环
- 只需要 Actor 和 Reference 两个模型(内存需求减半)
- 训练稳定,像普通的有监督训练一样,超参数易调
代价:
- 依赖静态的离线偏好数据(offline)------如果数据是由另一个模型生成的,DPO 是"off-policy"的,效果可能不如 on-policy 的 PPO
- DPO 的隐式奖励无法用于其他目的(如奖励信号用于 RL 探索)
- 数据质量高度依赖偏好对的质量
4.3 DPO 在真实模型中的应用
Zephyr-7B(HuggingFace, 2023):Mistral-7B 基础上,用 ChatGPT 生成大规模合成数据集(UltraChat),再用奖励集成模型(UltraFeedback)打分得到偏好对,最后用 dDPO(蒸馏版 DPO)训练。这是 DPO 在开源生态的第一批成功案例之一。
LLaMA 3(Meta, 2024):DPO 也被用在 LLaMA-3 的后训练流程中,Meta 不满足于纯 PPO 的复杂性,引入了 DPO 进行偏好对齐。
DeepSeek LLM(DeepSeek, 2024):DeepSeek LLM 没有使用流行的 RLHF,而是选择了 DPO 进行人类偏好对齐。这种方法直接将两个不同生成结果之间的概率差异作为训练目标,相比 RL 更直观,更易于设计。
4.4 DPO 的变体
自 DPO 提出以来,研究社区提出了大量变体,每个都在解决 DPO 的某个具体问题:
IPO(Identity Preference Optimization):DPO 在某些条件下可能过拟合偏好对,IPO 通过直接对偏好概率做约束来解决。
KTO(Kahneman-Tversky Optimization):不需要偏好对(chosen/rejected)数据,只需要(prompt, response, 是否满意)的二元标注,数据收集成本更低。
SimPO(Simple Preference Optimization):用序列的平均对数概率(而非所有 token 的对数概率之和)计算奖励,减少了对生成长度的偏见,不需要参考模型,效果在很多任务上超过 DPO。
Online DPO(在线 DPO):用当前模型(而非历史模型)实时生成偏好对,变成"on-policy"训练。研究表明在线 DPO 效果显著优于离线 DPO。
ORPO(Odds Ratio Preference Optimization):把 SFT 损失和偏好对齐损失合并为一步,不需要参考模型,一步完成 SFT + 对齐。
4.5 用 TRL 的 DPOTrainer 做实战
以下是一个完整的 DPO 训练流程,包括数据准备和训练:
python
from datasets import load_dataset, Dataset
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import DPOConfig, DPOTrainer
from peft import LoraConfig
import torch
# 1. 加载 SFT 之后的模型作为起点
model = AutoModelForCausalLM.from_pretrained(
"./sft_final", # 用上一步 SFT 训练好的模型
torch_dtype=torch.bfloat16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("./sft_final")
# 2. 偏好数据集格式:每条样本需要 prompt, chosen, rejected 三个字段
# 使用 UltraFeedback 二元偏好数据集
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
# 该数据集的格式:{"prompt": [...], "chosen": [...], "rejected": [...]}
# 其中 prompt/chosen/rejected 均为 messages 列表(ChatML 格式)
# 3. 也可以自定义偏好数据集
def create_preference_dataset():
data = [
{
"prompt": [{"role": "user", "content": "解释量子纠缠"}],
"chosen": [{"role": "assistant", "content": "量子纠缠是指两个或多个粒子...(详细准确的解释)"}],
"rejected": [{"role": "assistant", "content": "量子纠缠就是两个东西纠缠在一起,没什么好解释的。"}],
},
# 更多样本...
]
return Dataset.from_list(data)
# 4. DPO 训练配置
dpo_config = DPOConfig(
output_dir="./dpo_output",
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
learning_rate=5e-7, # DPO 的学习率应比 SFT 小得多
beta=0.1, # KL 惩罚系数,控制偏离参考模型的程度
warmup_ratio=0.1,
bf16=True,
logging_steps=10,
save_steps=500,
# 重要:不要设置 max_length,防止截断偏好对
max_length=None,
max_prompt_length=512,
)
# 5. LoRA 配置(DPO 也支持 PEFT)
peft_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
task_type="CAUSAL_LM"
)
# 6. DPOTrainer 自动处理 reference model
# 如果传入 peft_config,ref_model 会自动从 model 的 base model 创建
trainer = DPOTrainer(
model=model,
ref_model=None, # 使用 LoRA 时设为 None,TRL 会自动处理
args=dpo_config,
train_dataset=dataset,
peft_config=peft_config,
tokenizer=tokenizer,
)
trainer.train()
# 7. DPO 训练完成后,合并 LoRA 权重
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained(
"./sft_final", torch_dtype=torch.bfloat16
)
peft_model = PeftModel.from_pretrained(base_model, "./dpo_output/checkpoint-xxx")
merged_model = peft_model.merge_and_unload()
merged_model.save_pretrained("./dpo_final")关于 beta 参数 :这是 DPO 最重要的超参数。beta 越大,对偏离参考模型的惩罚越重,模型改变越保守;beta 越小,模型能更自由地向偏好方向优化,但也更可能过拟合或退化。通常取值范围是 0.01~0.5,0.1 是常用的默认值。
五、GRPO:DeepSeek-R1 的新范式
严格来说 GRPO 属于 RLHF 的变体,但它的影响力足以单独成章,尤其是在推理模型的训练上。
5.1 GRPO 的动机:消除 Critic 模型
PPO 需要一个与 Actor 等大的 Critic 模型来估计状态价值函数(Value Function),作为计算优势函数(Advantage)的基线。这个 Critic 模型是 RLHF/PPO 内存开销巨大的主要来源之一。
GRPO(Group Relative Policy Optimization)的思路是:用同一 prompt 的多个采样回答的平均奖励作为基线,代替 Critic 模型 。对于每个 prompt,生成一组 个回答
,用可验证奖励函数评分,然后用组内归一化的相对奖励作为每个回答的优势:
这样完全不需要 Critic 模型,内存减少约 25%~50%(取决于具体实现)。
5.2 GRPO 与可验证奖励(RLVR)
GRPO 特别适合与可验证奖励(Verifiable Rewards)结合。可验证奖励是指可以用程序判断对错的任务:数学题(答案是否正确)、代码(是否能通过测试用例)、逻辑推理(结论是否有效)。
DeepSeek-R1 使用了 RLVR(Reinforcement Learning with Verifiable Rewards)结合 GRPO,完全绕开了人类偏好和奖励模型。与标准 RLHF 不同,RLVR 从确定性工具(如计算器、编译器)获取直接的二元反馈(正确或错误),而不是从人工标注示例中学习什么是"好"答案。
这一方案的优势是彻底:不需要人工标注偏好,不需要奖励模型,奖励信号来自程序化验证,无法被"黑客"。DeepSeek-R1 的成功证明了这条路线的可行性,也直接催生了整个开源推理模型生态(QwQ、Kimi k1.5、Qwen3 的 Thinking 模式等)。
用 TRL 训练 GRPO 的最简示例:
python
from datasets import load_dataset
from trl import GRPOTrainer, GRPOConfig
from trl.rewards import accuracy_reward # 内置的准确率奖励函数
# 数学推理数据集
dataset = load_dataset("trl-lib/DeepMath-103K", split="train")
config = GRPOConfig(
output_dir="./grpo_output",
num_train_epochs=1,
per_device_train_batch_size=1,
gradient_accumulation_steps=16,
learning_rate=1e-6,
num_generations=8, # 每个 prompt 采样 8 个回答
max_new_tokens=512,
bf16=True,
)
trainer = GRPOTrainer(
model="Qwen/Qwen2.5-7B-Instruct",
reward_funcs=accuracy_reward, # 可验证的答案准确率奖励
args=config,
train_dataset=dataset,
)
trainer.train()六、方法选择:什么时候用哪个?
这是最实际的问题。下面用几个维度帮你做决策。
6.1 按任务目标选择
你的目标是让模型学会某个特定领域的知识或格式 → SFT
例如:让通用模型学会回答医疗问诊、提取结构化信息、按特定格式输出 JSON、学习公司内部 FAQ。这类任务的关键在于数据质量,有 500~5000 条高质量的(指令, 回答)对,SFT 通常就足够了。不需要 RLHF 或 DPO。
你的目标是让模型的回答风格更贴合人类偏好(更友好、更安全、更有帮助) → DPO(优先)或 RLHF
例如:通用对话助手的偏好对齐、减少有害内容、改善回答的礼貌程度。如果资源有限,DPO 是首选------它稳定、高效,数据要求相对低(只需偏好对,不需要复杂的 RL 基础设施)。
你的目标是提升数学、代码、推理等可验证任务的能力 → GRPO/RLVR
如果任务的对错可以用程序验证,GRPO + 可验证奖励是目前最有效的方案,也是 DeepSeek-R1、Qwen3 Thinking 等模型的核心路线。
你的目标是通用旗舰模型,追求极致的对话质量 → SFT → RLHF(PPO)
这是 OpenAI(GPT-4)、Anthropic(Claude)等顶级实验室的路线,效果最好,但需要巨大的工程投入和人工标注成本,不适合中小团队。
6.2 按资源约束选择
| 约束条件 | 推荐方法 |
|---|---|
| 单卡 24G 显存,快速验证 | SFT + LoRA,或 DPO + LoRA |
| 多卡服务器(4×80G),中等规模 | DPO 全参数,或 SFT → DPO 两阶段 |
| 大规模集群(100+ GPU) | SFT → RLHF(PPO),或 SFT → GRPO |
| 无 GPU,只有 API 预算 | 用 GPT-4 生成 SFT 数据,再 SFT 小模型 |
| 无标注预算 | 用 AI 模型(如 GPT-4)生成偏好数据,再 DPO |
6.3 按数据类型选择
| 数据类型 | 推荐方法 |
|---|---|
| 高质量(指令, 回答)对 | SFT |
| (prompt, 好回答, 坏回答)偏好三元组 | DPO |
| (prompt, 回答, 满意/不满意)二元标注 | KTO |
| 数学/代码题目 + 正确答案 | GRPO + 可验证奖励 |
| 人工排序的多个回答 | RLHF(PPO) |
6.4 现实的流水线建议
新兴共识是一个模块化流水线:SFT 用于指令遵循 → DPO/SimPO 用于通用偏好对齐 → GRPO/DAPO 结合可验证奖励用于推理能力。每一层解决不同类型的对齐问题------行为对齐、偏好对齐和逻辑对齐。
对于大多数工程实践者,以下两种组合最常见:
方案 A(通用对话模型) :SFT(1-3轮)→ DPO(1轮) 这是 Zephyr、LLaMA 3 Instruct 等开源模型常用的轻量路线,效果稳定,工程简单。
方案 B(推理/代码模型) :SFT 冷启动(少量 CoT 数据)→ GRPO/RLVR(大量可验证任务) 这是 DeepSeek-R1、Qwen3 Thinking 的路线,适合以推理能力为核心目标的模型。
七、完整工具链
7.1 HuggingFace TRL
TRL(Transformer Reinforcement Learning)是目前最广泛使用的后训练框架,支持:
| Trainer | 用途 |
|---|---|
SFTTrainer |
监督微调 |
RewardTrainer |
训练奖励模型 |
DPOTrainer |
DPO 及其变体(SimPO, IPO, KTO 等) |
PPOTrainer |
标准 RLHF PPO |
GRPOTrainer |
GRPO(DeepSeek-R1 的方法) |
ORPOTrainer |
ORPO(SFT + 对齐一步完成) |
TRL 还提供了命令行接口,可以不写代码直接训练:
bash
# SFT 训练
trl sft \
--model_name_or_path Qwen/Qwen2.5-7B \
--dataset_name trl-lib/Capybara \
--output_dir ./sft_output \
--num_train_epochs 3 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--learning_rate 2e-4 \
--use_peft \
--lora_r 64 \
--bf16
# DPO 训练
trl dpo \
--model_name_or_path ./sft_output \
--dataset_name trl-lib/ultrafeedback_binarized \
--output_dir ./dpo_output \
--beta 0.1 \
--learning_rate 5e-7 \
--use_peft \
--lora_r 167.2 ModelScope ms-swift
ms-swift 是 ModelScope 社区提供的大模型微调框架,支持 600+ LLM 和 400+ 多模态大模型的全参数或 PEFT 微调,包括 SFT、DPO、GRPO 等方法,以及 Megatron 并行训练技术。
bash
# DPO 微调 Qwen3
CUDA_VISIBLE_DEVICES=0 swift rlhf \
--rlhf_type dpo \
--model Qwen/Qwen3-4B-Instruct \
--dataset hjh0119/shareAI-Llama3-DPO-zh-en-emoji \
--tuner_type lora \
--output_dir output
# GRPO 微调
CUDA_VISIBLE_DEVICES=0,1,2,3 NPROC_PER_NODE=4 swift rlhf \
--rlhf_type grpo \
--model Qwen/Qwen3-4B-Instruct \
--use_vllm true \
--dataset AI-MO/NuminaMath-TIR \
--output_dir output7.3 OpenRLHF
专为大规模 RLHF 设计,基于 Ray 分布式架构,支持 70B+ 模型的全参数 PPO 训练:
bash
# 70B 模型的完整 PPO-RLHF(需要大规模集群)
ray job submit --address="http://127.0.0.1:8265" -- \
python3 -m openrlhf.cli.train_ppo_ray \
--pretrain OpenRLHF/Llama-3-8b-sft-mixture \
--reward_pretrain OpenRLHF/Llama-3-8b-rm-700k \
--save_path ./checkpoint/llama3-8b-rlhf \
--train_batch_size 128 \
--rollout_batch_size 1024 \
--actor_num_nodes 1 \
--actor_num_gpus_per_node 8 \
--reward_num_nodes 1 \
--reward_num_gpus_per_node 87.4 Unsloth
针对单卡或小规模环境优化,通过内核级优化使训练速度提升 1.7x,显存减少 60%:
python
from unsloth import FastLanguageModel
from trl import SFTTrainer
model, tokenizer = FastLanguageModel.from_pretrained(
"unsloth/Qwen2.5-7B-Instruct-bnb-4bit", # 4bit 量化
max_seq_length=2048,
load_in_4bit=True,
)
# 添加 LoRA
model = FastLanguageModel.get_peft_model(
model,
r=64,
lora_alpha=128,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"],
)
# 后续与标准 TRL 完全兼容八、常见坑与实战经验
8.1 SFT 的常见问题
灾难性遗忘(Catastrophic Forgetting):SFT 数据太集中在某个领域,导致模型在通用任务上退化。解决方法是在 SFT 数据里混入 5%~10% 的通用指令数据(如 Alpaca、OpenHermes),保持通用能力。
学习率过大:SFT 的学习率通常在 1e-5 到 2e-4 之间,大于此范围容易破坏预训练权重。推荐使用余弦调度(cosine schedule)配合 warmup。
过拟合:SFT 只需要 1~3 个 epoch,超过 3 个 epoch 通常会过拟合,导致模型回答死板、缺乏多样性。
8.2 DPO 的常见问题
偏好数据质量比数量更重要:差的偏好对(chosen 和 rejected 区别不明显)比没有偏好数据更糟糕,会把模型训歪。宁可用 1000 条高质量偏好对,也不用 10000 条模糊的偏好对。
beta 值过小导致退化 :beta 过小时,DPO 对 KL 约束的惩罚太弱,模型会在偏好方向上过度优化,丢失多样性甚至出现重复生成。建议从 0.1 开始,如果回答变得僵硬或重复,适当增大。
On-policy vs Off-policy:如果偏好数据是由另一个模型(如 GPT-4)生成的,这是 off-policy 数据,DPO 效果可能不如期望。理想情况是用当前模型本身生成候选回答,再通过奖励模型或规则筛选偏好对(on-policy DPO),实验证明效果更好。
8.3 RLHF/PPO 的常见问题
奖励模型过拟合:奖励模型如果在分布外输入上给出极端分数,PPO 会利用这一点进行奖励黑客。解决方法是加入 KL 惩罚(TRL 默认启用),并监控 KL 值不超过 5~10。
训练崩溃:PPO 训练不稳定时可能突然崩溃(loss 突然变为 NaN 或奖励骤降)。建议:降低学习率(1e-6 量级)、增大 KL 系数、使用梯度裁剪(max grad norm = 0.5~1.0)。
九、总结:三种方法的定位
把三种方法放在一个框架里看:
SFT 是"教会模型做某件事"。它通过示范回答告诉模型"这样做",是行为对齐的基础。几乎所有大模型都需要 SFT,是必经之路而非可选项。
RLHF/PPO 是"让模型越做越好"。通过奖励信号引导模型在给定的偏好分布上探索,适合追求极致效果的大规模训练场景。代价是工程复杂、计算昂贵,是顶级实验室的专属工具。
DPO 是"告诉模型什么更好"。通过偏好对直接优化策略,绕过了 RL 循环,是平衡效果与工程复杂度的最佳选择,适合大多数工程实践者。
GRPO 是"让模型通过试错发现推理方式"。结合可验证奖励,适合推理、代码等有客观正确答案的任务,是 2025 年后推理模型训练的主流范式。
理解这三者(以及它们的扩展),等于掌握了现代大模型后训练的核心工具箱。选对工具,远比堆参数更能决定模型的最终质量。
参考资料
- Ouyang et al., Training language models to follow instructions with human feedback(InstructGPT), NeurIPS 2022
- Rafailov et al., Direct Preference Optimization: Your Language Model is Secretly a Reward Model, NeurIPS 2023
- Shao et al., DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, 2024
- Guo et al., DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, 2025
- HuggingFace TRL Documentation: https://huggingface.co/docs/trl
- Philschmid Blog: How to align open LLMs in 2025 with DPO, 2025
- Sebastian Raschka: The State of Reinforcement Learning for LLM Reasoning, 2025