文章目录
- 信号基本框架
- 信号的基本概念
- 信号产生的异步性
- 信号不一定立即处理
- [信号的"未决状态"(Pending Signal)](#信号的“未决状态”(Pending Signal))
- 信号处理方式
-
- [默认处理(Default Action)](#默认处理(Default Action))
- [自定义处理(Signal Handler)](#自定义处理(Signal Handler))
- 忽略信号(Ignore)
- 信号处理的一般流程
- 信号机制的关键特性
- 信号的基本共识
- 进程处理信号的三种方式
-
-
- [默认处理(Default Action)](#默认处理(Default Action))
- [捕捉信号(Signal Catch)](#捕捉信号(Signal Catch))
- 忽略信号(Ignore)
-
- 信号发送
-
- 用户发送信号必须依赖系统调用
- [kill 命令的底层实现](#kill 命令的底层实现)
- 信号产生
-
- 键盘组合键
-
- [Ctrl+C 的工作机制](#Ctrl+C 的工作机制)
-
- [SIGINT 的默认行为](#SIGINT 的默认行为)
- 信号处理方式
- [signal 函数原型](#signal 函数原型)
- 信号处理函数的执行机制
- 键盘信号的产生机制
- [前台进程(Foreground Process)](#前台进程(Foreground Process))
- 系统调用
-
- [kill 系统调用](#kill 系统调用)
- 信号发送的权限模型
- 小结
- 信号默认处理行为
- 触发条件
-
- 硬件条件触发
-
- 除零异常产生信号的底层机制
-
- 操作系统检测到异常
- 操作系统转换为信号
- [为什么捕捉 SIGFPE 后信号会不断出现](#为什么捕捉 SIGFPE 后信号会不断出现)
- [CPU 寄存器属于进程上下文](#CPU 寄存器属于进程上下文)
- 除零异常的状态不会被用户进程修复
- 信号不会必然导致进程终止
- 进程未退出仍然可能继续执行
- [为什么 SIGFPE 会不断触发](#为什么 SIGFPE 会不断触发)
- 语言层面的异常本质是系统层面的硬件异常
- 野指针导致程序崩溃的原因
-
- 空指针访问为什么会触发异常
- [为什么访问 0 地址会出错](#为什么访问 0 地址会出错)
- [MMU 异常如何变成信号](#MMU 异常如何变成信号)
- [SIGSEGV 的默认处理行为](#SIGSEGV 的默认处理行为)
- 程序异常与信号的关系
- 硬件异常触发信号的基本过程
- 信号产生的第四种方式:软件条件触发
-
- 管道写入错误(SIGPIPE)
-
- [SIGPIPE 的产生原因](#SIGPIPE 的产生原因)
- 定时器信号
-
- [alarm 的基本作用](#alarm 的基本作用)
- [alarm() 的工作机制](#alarm() 的工作机制)
- [alarm() 的返回值](#alarm() 的返回值)
- 取消闹钟
- [为什么 alarm 属于"软件条件触发信号"](#为什么 alarm 属于“软件条件触发信号”)
-
- [I/O 操作对性能的影响](#I/O 操作对性能的影响)
- 不终止进程时的行为
- 软件条件触发信号的本质
- 信号产生方式总结
- 信号捕获
-
- 异常机制与信号机制的类比
- 异常或信号通常意味着程序无法继续正常执行
- 为什么仍然需要区分不同类型的异常或信号
- 信号处理
- 终止信号
-
- [Term与 Core 两种终止方式的区别](#Term与 Core 两种终止方式的区别)
-
- [Term 类型终止](#Term 类型终止)
- [Core 类型终止](#Core 类型终止)
- [Core Dump(核心转储)](#Core Dump(核心转储))
-
- [云服务器默认关闭 Core Dump](#云服务器默认关闭 Core Dump)
- [Core Dump 的作用:事后调试(Post-mortem Debugging)](#Core Dump 的作用:事后调试(Post-mortem Debugging))
- [使用 GDB 分析 Core Dump](#使用 GDB 分析 Core Dump)
- 数组越界为什么不一定崩溃
-
- [C 语言语义角度](#C 语言语义角度)
- 进程虚拟地址空间角度
- 操作系统为什么有时检测不到越界
- 总结
- 信号捕捉机制
-
- 捕捉所有信号的实验
- 为什么进程仍然可以被终止
- 不可捕获信号
-
- [SIGKILL(信号 9)](#SIGKILL(信号 9))
- [SIGSTOP(信号 19)](#SIGSTOP(信号 19))
- 信号捕捉的本质
- 总结
- 信号的保存
-
- [信号递达(Signal Delivery)](#信号递达(Signal Delivery))
- [信号未决(Pending Signal)](#信号未决(Pending Signal))
- [信号阻塞(Signal Blocking)](#信号阻塞(Signal Blocking))
- [Pending 与 Block 的关系](#Pending 与 Block 的关系)
信号基本框架
信号通常分为几个阶段:
- 信号产生(Signal Generation)
- 信号保存(Signal Pending)
- 信号递达(Signal Delivery)
- 信号处理(Signal Handling)
信号的基本概念
信号(Signal)是操作系统向进程发送的一种异步事件通知机制,用于通知进程某种事件已经发生。
例如:
- 用户按下
Ctrl+C - 定时器到期
- 非法内存访问
操作系统会向进程发送相应的信号。
Linux 信号是一种异步事件通知机制,用于向进程通知某种事件已经发生。信号产生后会被记录为未决信号,并在适当时机由进程进行处理,其处理方式包括默认处理、自定义处理函数或忽略信号。
信号产生的异步性
信号具有 异步(Asynchronous)特性 。
专业表述:
信号的产生与进程当前执行的控制流程是相互独立的,因此信号的产生与进程执行之间是异步关系。
也就是说:
- 信号 可以在任何时刻产生
- 与进程正在执行的代码 没有时间顺序保证
例如:
text
进程正在执行代码
↓
信号随时可能到达因此:
信号属于异步事件通知机制。
信号不一定立即处理
由于信号是异步产生的,因此:
信号到达进程时,不一定会被立即处理。
原因:
- 进程可能正在执行关键代码
- 信号可能被暂时阻塞(blocked)
- 内核可能延迟调度信号处理
因此信号处理通常发生在:
进程返回用户态或安全点时。
信号的"未决状态"(Pending Signal)
由于信号 不会立即处理,因此必然存在一个时间窗口:
text
信号产生 → 信号被处理在这个时间窗口中:
操作系统必须记录该信号已经到达。
这在操作系统中称为:
未决信号(Pending Signal)
专业描述:
当信号产生但尚未被进程处理时,该信号处于未决状态,内核会在进程的信号集合中记录该信号。
Linux 内核中通常用 位图(bitmask) 来保存未决信号。
信号处理方式
当进程处理信号时,通常有三种处理方式:
默认处理(Default Action)
操作系统为每个信号定义了 默认行为 。
例如:
| 信号 | 默认行为 |
|---|---|
SIGINT |
终止进程 |
SIGTERM |
终止进程 |
SIGSTOP |
暂停进程 |
SIGCHLD |
忽略 |
自定义处理(Signal Handler)
进程可以通过系统调用注册信号处理函数:
c
signal(SIGINT, handler);或者:
c
sigaction()当信号到达时:
text
执行用户自定义的信号处理函数忽略信号(Ignore)
进程也可以选择忽略某些信号:
c
signal(SIGINT, SIG_IGN);表示:
text
信号到达后不执行任何操作注意:
有些信号 不能被忽略:
SIGKILLSIGSTOP
信号处理的一般流程
完整流程如下:
text
1 信号产生
↓
2 内核记录为 pending signal
↓
3 进程在合适时机检测信号
↓
4 根据信号处理策略执行动作处理策略包括:
- 默认动作
- 自定义处理函数
- 忽略信号
信号机制的关键特性
从操作系统角度总结,信号机制具有以下特性:
事件通知机制
信号用于通知进程某个事件已经发生。
异步性Asynchronous)
信号可以在任意时刻产生,与进程执行流程无关。 延迟处理
信号到达时不一定立即处理。
未决信号机制
信号产生后,如果未立即处理,会被记录为 pending signal 。
多种处理策略
信号处理方式包括:
- 默认动作
- 用户自定义处理函数
- 忽略信号
在操作系统中,信号是一种用于通知进程异步事件的机制。信号的产生具有异步性,因此进程在接收到信号时不一定立即处理。操作系统会在进程的未决信号集合中记录该信号,并在合适的时机进行处理。信号的处理方式包括默认处理、用户自定义信号处理函数以及忽略信号三种策略。
信号的基本共识
首先需要明确一个基本共识:信号是发送给进程的事件通知机制 。
在 Linux/Unix 系统中,可以通过命令:
kill -9 PIDkill -SIGINT PID
向指定 PID(Process ID) 的进程发送信号。
因此可以确认:
信号的接收对象是进程。
进程如何识别信号
类比人识别红绿灯需要:
- 能够识别信号
- 知道对应行为
进程识别信号同样需要两个要素:
识别信号
进程必须能够识别某种信号类型,例如:
- SIGINT
- SIGTERM
- SIGKILL
由于进程本质是程序代码的执行实例,因此:
进程对信号的识别能力是由程序员通过程序代码实现的。
换句话说:
信号识别逻辑由程序设计实现。
对信号产生行为
当进程识别到信号后,需要执行相应行为,例如:
- 终止进程
- 忽略信号
- 执行信号处理函数
这意味着:
每种信号必须定义对应的处理策略。
信号不一定被立即处理
当进程收到信号时,进程可能正在执行其他代码,因此:
信号不一定会被立即处理。
原因:
- 进程可能正在执行关键代码
- 当前代码优先级更高
- 系统调度策略影响
因此:
信号处理具有延迟性。
信号必须被暂存
由于信号可能无法立即处理,因此系统必须解决一个问题:
信号到达后,在被处理之前如何保存?
因此进程必须具备:
信号暂存能力
也就是说:
信号需要被记录下来,等待后续处理。
信号在进程中的存储位置
进程在操作系统中由 PCB(Process Control Block) 描述。
在 Linux 中,PCB 对应的数据结构是:
task_struct因此:
信号状态会被保存在进程的
task_struct中。
信号的存储方式(位图)
Linux 使用 位图(bitmap) 记录信号状态。
普通信号编号:
1 ~ 31因此可以使用一个 32位整数 来表示:
c
struct task_struct {
...
unsigned int signal;
...
};位图规则:
| 位位置 | 表示信号 |
|---|---|
| bit1 | signal1 |
| bit2 | signal2 |
| bit3 | signal3 |
| ... | ... |
| bit31 | signal31 |
| 位值含义: |
| 位值 | 含义 |
|---|---|
| 0 | 未收到信号 |
| 1 | 已收到信号 |
| 例如: |
00000000000000000000000000001000表示:
收到了 signal4信号发送的本质
教材中通常称为:
发送信号 (send signal)
但从系统实现角度来看:
信号发送的本质是修改进程PCB中的信号位图。
例如:
发送 signal9:
bit9 = 1即:
signal_bitmap |= (1 << 9)因此:
信号发送 ≈ 修改 PCB 中的信号标志位。
并不是真正意义上的"传输数据"。
谁有权限修改信号位图
需要注意:
- PCB 是 内核数据结构
task_struct由 操作系统维护
因此:
用户程序没有权限直接修改 PCB。
只有:
操作系统内核
才能修改进程的信号位图。
发送信号的最终结论
因此可以得到一个重要结论:
所有信号发送行为,本质上都是操作系统内核修改目标进程PCB中的信号状态。
即:
用户程序
↓
系统调用
↓
操作系统内核
↓
修改目标进程 PCB 信号位图进程处理信号的三种方式
当进程处理信号时,可以采取三种策略:
默认处理(Default Action)
操作系统定义默认行为,例如:
- 终止进程
- 产生 core dump
- 忽略
捕捉信号(Signal Catch)
进程可以注册:
signal handler即:
自定义信号处理函数
忽略信号(Ignore)
进程可以选择:
忽略该信号例如:
SIG_IGN信号发送
在 Linux / Unix 系统中,无论信号通过何种方式产生,其本质都是:
由操作系统内核向目标进程设置相应的信号状态。
原因如下:
- 进程的控制信息存储在 PCB(Process Control Block) 中
- Linux 中 PCB 对应的数据结构是:
c
task_struct- PCB 属于 内核数据结构
因此:
用户程序没有权限直接修改 PCB。
只有:
操作系统内核(Kernel)
才能修改进程的信号状态。
用户发送信号必须依赖系统调用
由于用户程序不能直接访问内核数据结构,因此如果希望用户程序能够发送信号,就必须通过:
系统调用(System Call)
来完成。
因此操作系统必须提供一组 信号相关系统调用接口,用于:
- 发送信号
- 设置信号处理方式
- 处理信号
例如常见接口:
| 系统调用 | 作用 |
|---|---|
kill() |
向进程发送信号 |
signal() |
设置信号处理方式 |
sigaction() |
更规范的信号处理接口 |
raise() |
向当前进程发送信号 |
kill 命令的底层实现
在 Linux 中常用命令:
bash
kill -9 PID虽然这是一个 shell 命令,但其本质是:
调用系统调用
kill()
执行流程如下:
用户命令 kill
↓
shell 调用 kill() 系统调用
↓
内核修改目标进程 PCB 信号位图
↓
目标进程收到信号因此可以得出结论:
所有信号发送最终都由操作系统内核完成。
信号产生
键盘组合键
在终端环境中,某些 键盘组合键 会触发信号。
例如:
| 组合键 | 信号 |
|---|---|
Ctrl + C |
SIGINT |
Ctrl + \ |
SIGQUIT |
Ctrl + Z |
SIGTSTP |
| 这些信号通常用于控制前台进程。 |
Ctrl+C 的工作机制
当用户在终端按下:
Ctrl + C执行流程如下:
键盘输入
↓
终端驱动识别按键
↓
操作系统内核解释为 SIGINT
↓
内核向前台进程发送 SIGINT
↓
进程处理该信号其中:
SIGINT = 信号编号 2SIGINT 的默认行为
在 Linux 中,可以通过手册查看信号说明:
bash
man 7 signalSIGINT 的默认行为是:
终止进程(Terminate Process)
因此:
当程序运行时按 Ctrl+C,进程会直接结束。
信号处理方式
进程收到信号后,可以采用三种处理策略:
默认处理(Default Action)
使用系统定义行为,例如:
- 终止进程
- 停止进程
- 忽略信号
忽略信号(Ignore)
进程可以选择忽略信号,例如:
c
signal(SIGINT, SIG_IGN);捕捉信号(Signal Catch)
进程可以定义 信号处理函数(Signal Handler) 。
例如:
cpp
#include <signal.h>
#include <iostream>
void handler(int signo)
{
std::cout << "捕捉到信号: " << signo << std::endl;
}注册信号处理函数:
cpp
signal(SIGINT, handler);signal 函数原型
Linux 提供的信号注册接口:
c
#include <signal.h>
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);参数说明:
| 参数 | 含义 |
|---|---|
signum |
信号编号 |
handler |
信号处理函数 |
| 其中: |
c
void handler(int signo)是一个 函数指针类型,表示信号处理回调函数。
信号处理函数的执行机制
需要注意:
调用 signal() 时:
只是注册信号处理函数,并不会立即执行。
执行流程如下:
程序启动
↓
注册 signal handler
↓
程序继续执行
↓
收到对应信号
↓
内核触发信号处理函数因此:
信号处理函数本质上是一种 回调函数(callback) 。
示例:
cpp
#include <iostream>
#include <unistd.h>
#include <signal.h>
void handler(int signo)
{
std::cout << "进程捕捉到信号: " << signo << std::endl;
}
int main()
{
signal(SIGINT, handler);
while(true)
{
std::cout << "我是一个进程 PID=" << getpid() << std::endl;
sleep(1);
}
return 0;
}运行程序后:
Ctrl+C输出:
进程捕捉到信号: 2说明:
SIGINT 已被程序捕获。
为什么 Ctrl+C 不再终止程序
因为:
我们通过
c
signal(SIGINT, handler);修改了 SIGINT 的默认行为。
默认行为:
terminate现在变为:
执行 handler()因此进程不会退出。
如果希望处理后退出,可以:
cpp
exit(0);SIGKILL 无法被捕捉
即使程序捕获了大量信号,仍然存在一个例外:
SIGKILL (9)特点:
| 特性 | 说明 |
|---|---|
| 不可捕捉 | Cannot be caught |
| 不可忽略 | Cannot be ignored |
| 不可阻塞 | Cannot be blocked |
| 因此: |
bash
kill -9 PID一定可以终止进程。
这是操作系统提供的 强制终止机制,用于防止恶意程序无法被杀死。
键盘信号的产生机制
键盘本质上是一个硬件输入设备。当用户按下特定组合键时,系统执行如下流程:
键盘输入
↓
终端驱动程序检测按键
↓
操作系统解释为特定信号
↓
向当前前台进程发送信号
↓
目标进程在适当时机处理该信号因此:
键盘组合键实际上是 触发操作系统发送信号的一种方式。
前台进程(Foreground Process)
在 Linux 终端环境中,同一时刻只能有一个前台进程与终端交互 。
默认情况下:
bash shell是前台进程。
当用户执行某个程序,例如:
bash
./my_signal执行流程如下:
bash shell
↓
启动新进程 my_signal
↓
my_signal 成为前台进程
↓
bash 退到后台等待此时:
- 键盘输入信号会发送给 my_signal
- 而不是 bash
可以通过命令查看进程关系:
bash
ps ax | grep my_signal例如:
PID PPID
1391 3815其中:
1391为程序进程 PID3815为父进程 bash
系统调用
除了键盘输入外,还可以通过 系统调用(System Call) 发送信号。
这是程序向进程发送信号的主要方式。
常见系统调用包括:
| 系统调用 | 作用 |
|---|---|
kill() |
向指定进程发送信号 |
raise() |
向当前进程发送信号 |
alarm() |
定时产生信号 |
| 本节重点介绍: |
kill()kill 系统调用
kill() 系统调用用于向指定进程发送信号。
函数原型:
c
#include <sys/types.h>
#include <signal.h>
int kill(pid_t pid, int sig);参数说明:
| 参数 | 含义 |
|---|---|
pid |
目标进程 PID |
sig |
要发送的信号编号 |
| 返回值: |
| 返回值 | 含义 |
|---|---|
| 0 | 成功 |
| -1 | 失败,并设置 errno |
信号发送的权限模型
需要明确一个关键原则:
信号发送的能力属于操作系统内核。
用户程序并不能直接修改进程 PCB。
因此:
用户程序
↓
系统调用
↓
操作系统内核
↓
修改目标进程 PCB 信号位图也就是说:
真正发送信号的是内核,而不是用户程序。
用户程序只是通过系统调用请求内核执行该操作。
系统调用的设计目的
操作系统通常遵循以下原则:
内核功能必须通过 系统调用接口 向用户空间提供服务。
原因包括:
- 安全性(Security)
- 权限控制(Permission Control)
- 系统稳定性(System Stability)
因此:
即使操作系统具备发送信号的能力,也必须通过系统调用向用户开放。
示例程序:通过 kill() 发送信号
可以实现一个简单程序,通过命令行向目标进程发送信号。
示例:
cpp
#include <iostream>
#include <unistd.h>
#include <signal.h>
#include <stdlib.h>
using namespace std;
void usage(const char* proc)
{
cout << "Usage: " << proc << " <PID> <SIGNAL>" << endl;
}
int main(int argc, char* argv[])
{
if(argc != 3)
{
usage(argv[0]);
exit(1);
}
pid_t pid = atoi(argv[1]);
int signo = atoi(argv[2]);
int ret = kill(pid, signo);
if(ret == 0)
cout << "Signal sent successfully" << endl;
else
perror("kill");
return 0;
}运行示例:
bash
./my_process 1391 2表示:
向 PID=1391 的进程发送 SIGINT 信号信号产生方式总结
Linux 中常见的信号产生方式包括:
| 方式 | 示例 |
|---|---|
| 键盘输入 | Ctrl+C |
| 系统调用 | kill() |
| 进程自身产生 | raise() |
| 定时器 | alarm() |
| 硬件异常 | 除零错误 |
| 软件异常 | 非法内存访问 |
小结
Linux 信号机制的关键结论:
-
信号的接收对象是进程
-
信号状态存储在 PCB(task_struct)
-
信号发送本质是 修改 PCB 中的信号位图
-
用户程序必须通过 系统调用 发送信号
-
键盘组合键(如 Ctrl+C)也是信号产生方式
-
Ctrl+C对应信号:SIGINT (2)
-
信号处理方式包括:
- 默认处理
- 自定义捕捉
- 忽略信号
signal()用于注册信号处理函数- 信号处理函数是 回调函数
SIGKILL无法被捕获或忽略,是系统提供的强制终止信号。
信号默认处理行为
在 Linux/Unix 系统中,当 进程收到信号(signal)时 ,系统会按照该信号的 默认处理动作(default action) 进行处理。
从整体上看:
大多数信号的默认处理行为是终止进程(Terminate)。
但不同信号虽然默认行为可能相同,其 语义(meaning)是不同的 。
换句话说:
- 信号的意义并不是由处理动作决定的
- 信号的意义由它所表示的事件决定
例如:
| 信号 | 含义 | 默认动作 |
|---|---|---|
| SIGINT | 用户按 Ctrl+C | 终止进程 |
| SIGQUIT | Ctrl+|终止并生成 core | |
| SIGFPE | 算术异常(如除零) | 终止进程 |
| SIGSEGV | 非法内存访问 | 终止进程 |
| 虽然这些信号 默认处理结果都是终止进程,但: |
不同信号表示不同类型的异常事件或系统状态。
因此:
信号的价值在于描述不同的系统事件,而不是区分不同的处理动作。
触发条件
硬件条件触发
信号可以通过多种方式产生,例如:
用户产生
用户在终端输入:
Ctrl + C
Ctrl + \终端驱动程序会向前台进程发送信号:
- Ctrl+C → SIGINT
- Ctrl+\ → SIGQUIT
软件方式产生
进程可以通过系统调用主动发送信号,例如:
kill(pid, signo)
raise(signo)kill()可以向任意进程发送信号raise()给当前进程发送信号
硬件异常产生
信号 不一定需要用户显式发送 ,有些信号会 由操作系统自动产生 。
例如:
int a = 10;
a = a / 0;执行该代码时会产生 除零异常 。
程序运行结果通常是:
Floating point exception (core dumped)其本质原因是:
CPU 在执行除零运算时产生了 硬件异常(Hardware Exception)
操作系统随后会将该异常 转换为信号 并发送给当前进程。
在除零情况下:
SIGFPE (signal 8)除零异常产生信号的底层机制
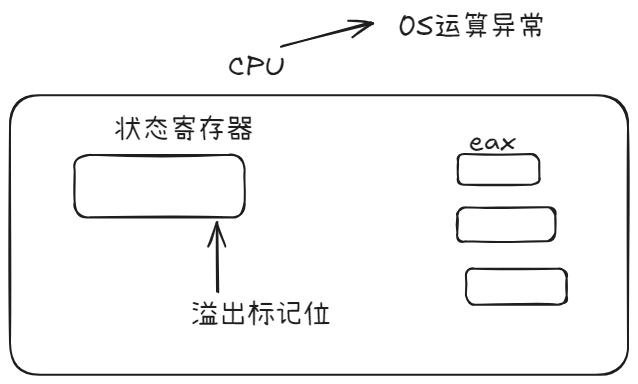
整个过程可以从 硬件 → 操作系统 → 进程 三个层次理解。
CPU 执行算术运算
程序代码:
a = 10 / 0CPU 在执行该指令时:
- 从寄存器读取操作数
- 执行除法运算
CPU 检测到异常
CPU 内部有一种特殊寄存器:
状态寄存器(Status Register / Flag Register)
其中包含各种 标志位(Flag) :
例如:
| 标志位 | 含义 |
|---|---|
| ZF | 零标志 |
| CF | 进位标志 |
| OF | 溢出标志 |
当执行 10 / 0 时: |
|
| CPU 会检测到 算术异常,并设置相应的异常标志。 | |
| 这就属于: |
CPU 硬件级异常(Hardware Exception)
操作系统检测到异常
CPU 产生异常后会触发 异常中断(Exception Trap) 。
此时:
- CPU 从用户态进入内核态
- 操作系统获得控制权
操作系统会判断: - 当前异常类型
- 当前执行的进程
操作系统转换为信号
操作系统会将硬件异常 映射为信号 :
例如:
除零异常 → SIGFPE (8)随后:
操作系统向当前进程发送该信号。
为什么捕捉 SIGFPE 后信号会不断出现
如果你捕捉了 SIGFPE,程序会出现一个现象:
信号处理函数不断被调用原因是:
-
CPU 指令仍然停留在 除零指令
-
处理函数返回后
-
程序继续执行该非法指令
于是:再次触发异常
→ 再次发送 SIGFPE
→ 再次调用 handler
因此就形成 无限触发信号的循环。
CPU 寄存器属于进程上下文
在计算机系统中:
- CPU 寄存器在硬件上 只有一份
- 但寄存器中的数据 属于当前运行进程的执行上下文
所谓 进程上下文(Process Context) 包括: - 通用寄存器
- 程序计数器(PC)
- 栈指针(SP)
- 状态寄存器(Flags Register)
当操作系统发生 进程切换(Context Switch) 时:
- 保存当前进程寄存器内容
- 恢复下一个进程寄存器内容
因此:
CPU 寄存器的值实际上是进程上下文的一部分。
除零异常的状态不会被用户进程修复
当 CPU 执行除零运算时:
10 / 0CPU 会产生 算术异常(Arithmetic Exception) ,并在 状态寄存器(Status Register) 中设置异常标志位。
例如:
- Overflow Flag
- Divide Error Flag
这些标志位: - 由 CPU 硬件维护
- 用户程序 无法直接修改
因此:
用户进程无法修复 CPU 的异常状态。
信号不会必然导致进程终止
在 Linux/Unix 系统中:
进程收到信号并不一定会终止。
原因是:
每个信号都有三种处理方式:
- 默认处理(Default Action)
- 忽略信号(Ignore)
- 自定义处理函数(User-defined handler)
例如:
cpp
signal(SIGFPE, handler);当进程收到 SIGFPE 时:
- 系统不会执行默认终止动作
- 而是调用用户注册的
handler函数
因此:
通过自定义信号处理函数,可以改变信号的默认处理行为,从而避免进程终止。
进程未退出仍然可能继续执行
如果信号处理函数执行完毕后:
- 进程 没有退出
- 也 没有修复异常状态
那么该进程仍然是可调度的。
换句话说:
只要进程没有终止,它仍然会被操作系统调度继续运行。
信号机制是 Linux 中用于 通知进程发生特定事件的一种异步机制 。
其特点包括:
-
信号表示系统中的某种 事件或异常
-
信号可以由 用户、进程或操作系统自动产生
-
硬件异常(如除零)会被操作系统转换为信号
-
进程收到信号后可以
- 执行默认动作
- 忽略信号
- 自定义处理函数
例如:
除零异常
→ CPU 检测异常
→ 操作系统捕获异常
→ 转换为 SIGFPE
→ 发送给当前进程
→ 进程执行默认终止动作
为什么 SIGFPE 会不断触发
当发生除零异常时,系统执行流程如下:
- CPU 执行非法算术运算
- CPU 触发硬件异常
- 操作系统检测异常
- 操作系统向进程发送
SIGFPE
如果进程:
- 捕获了
SIGFPE - 但没有终止
- 也没有修复异常
那么程序状态仍然存在问题。
当进程再次被调度时:
-
操作系统恢复该进程的寄存器上下文
-
状态寄存器中的异常标志仍然存在
-
操作系统再次检测到异常状态
-
再次向进程发送
SIGFPE
于是形成循环:异常状态存在
↓
操作系统发送 SIGFPE
↓
信号处理函数执行
↓
进程继续运行
↓
再次调度
↓
异常状态仍然存在
↓
再次发送 SIGFPE
因此就会出现:
信号处理函数被反复调用的现象。
可以总结为以下几个关键点:
- 信号不会必然导致进程终止
如果进程注册了信号处理函数,默认终止行为会被替换。 - CPU 寄存器属于进程上下文
在进程切换时会被保存和恢复。 - 硬件异常状态由 CPU 维护
用户进程无法直接修改状态寄存器。 - 异常状态未被修复时
每次进程恢复执行时操作系统都会重新检测到异常。
因此:
如果异常状态未被修复,而进程又没有退出,操作系统可能会反复向该进程发送相同的信号。
语言层面的异常本质是系统层面的硬件异常
在 C/C++ 程序中,一些常见的运行时错误,例如:
- 除零运算
- 空指针解引用
- 数组越界
- 野指针访问
在语言层面通常被认为是 程序错误 。
但从操作系统角度来看:
这些错误本质上都是 硬件异常(Hardware Exception)。
当 CPU 或相关硬件检测到异常时:
- 硬件触发异常
- 操作系统捕获异常
- 操作系统将异常转换为 信号(signal)
- 将信号发送给当前进程
- 进程按照信号的默认动作或自定义动作处理
因此:
很多程序崩溃的根本原因是进程收到了某种信号。
野指针导致程序崩溃的原因
考虑如下代码:
cpp
int *p = NULL;
*p = 100;分析:
cpp
int *p = NULL;该语句只是定义了一个指针变量 p,并将其值设为 0,不会产生错误。
但:
cpp
*p = 100;表示对地址 0 进行写操作。
也就是:
访问地址 0空指针访问为什么会触发异常
在 Linux 中,进程访问内存的过程如下:
程序
↓
虚拟地址
↓
页表
↓
MMU
↓
物理内存每个进程都有:
- 虚拟地址空间
- 页表(Page Table)
虚拟地址必须通过 页表映射 才能访问物理内存。
指针本质是虚拟地址
例如:
cpp
int *p指针变量 p 中保存的值,本质上是一个 虚拟地址 。
当执行:
cpp
*p = 100;系统执行过程为:
- 取出
p中的值(0) - 将 0 当作虚拟地址
- 通过 MMU(Memory Management Unit) 进行地址转换
- 查页表
为什么访问 0 地址会出错
在现代操作系统中:
虚拟地址 0 一般不会映射到任何物理内存。
这是为了防止:
-
空指针访问
-
程序错误
因此:
当 MMU 尝试进行地址转换时:虚拟地址 0
↓
查页表
↓
没有合法映射
MMU 会触发:
内存访问异常(Memory Fault)
MMU 异常如何变成信号
当 MMU 检测到非法内存访问时:
-
MMU 产生 硬件异常
-
CPU 进入 异常处理流程
-
操作系统内核获得控制权
-
操作系统判断异常类型
如果是非法内存访问:
操作系统会向进程发送信号:SIGSEGV
信号编号:
11含义:
Segmentation Fault
段错误SIGSEGV 的默认处理行为
查询:
man 7 signal可以看到:
| 信号 | 名称 | 默认动作 | 含义 |
|---|---|---|---|
| 11 | SIGSEGV | Terminate + core | 非法内存访问 |
| 因此: | |||
当进程收到 SIGSEGV 时: |
默认行为是 终止进程并生成 core dump。
于是程序就会崩溃。
野指针访问的完整过程如下:
程序执行 *p = 100
↓
p = 0(空指针)
↓
访问虚拟地址 0
↓
MMU 查页表
↓
发现地址非法
↓
MMU 产生硬件异常
↓
CPU 进入异常处理
↓
操作系统捕获异常
↓
操作系统向进程发送 SIGSEGV (11)
↓
进程执行默认动作
↓
进程终止从系统层面来看:
- C/C++ 程序中的很多运行时错误本质上是硬件异常。
- 硬件异常会被操作系统捕获,并转换为 信号(Signal)。
- 常见对应关系:
| 程序错误 | 信号 |
|---|---|
| 除零 | SIGFPE (8) |
| 非法内存访问 | SIGSEGV (11) |
| 非法指令 | SIGILL |
- 进程收到信号后:
- 默认行为通常是 终止进程
因此程序表现为 崩溃(crash)。
所有程序崩溃,本质上都是进程收到了某个信号。
最常见三个:
SIGSEGV 段错误
SIGABRT abort()
SIGFPE 算术异常程序异常与信号的关系
在 C/C++ 程序运行过程中,如果发生某些 非法操作,例如:
- 除零运算
- 空指针或野指针访问
- 非法内存访问
程序通常会直接 崩溃终止 。
从操作系统的角度来看,其本质原因是:
程序的非法操作会触发 硬件异常(Hardware Exception) ,操作系统检测到该异常后,会将其转换为 信号(Signal) 并发送给对应进程。
硬件异常触发信号的基本过程
当程序执行非法操作时,系统内部会经历如下过程:
- 程序执行异常指令
例如:
10 / 0(除零运算)*p = 100且p == NULL(空指针访问)
这些操作属于 非法或未定义行为。
- 硬件检测异常
CPU 或相关硬件组件会检测到异常,例如:
- CPU 运算单元检测到算术异常(除零)
- **MMU(Memory Management Unit)**检测到非法内存访问
此时硬件会触发 异常(Exception)。
- 操作系统接管异常
当硬件产生异常后:
- CPU 会进入 内核态
- 操作系统内核获得控制权
- 操作系统分析异常类型
- 异常转换为信号
操作系统会将硬件异常 转换为对应的信号,并发送给当前进程,例如:
| 异常类型 | 信号 |
|---|---|
| 除零运算 | SIGFPE |
| 非法内存访问 | SIGSEGV |
| 非法指令 | SIGILL |
- 进程处理信号
进程收到信号后,可以:
- 执行 默认处理动作
- 忽略信号
- 自定义信号处理函数
但对于大多数硬件异常信号而言:
默认处理动作通常是 终止进程(Terminate)。
因此程序会表现为 崩溃(crash)。
信号产生的第四种方式:软件条件触发
在 Linux/Unix 系统中,信号不仅可以通过:
- 用户操作产生 (如
Ctrl+C) - 系统调用产生 (如
kill()、raise()) - 硬件异常产生 (如除零、非法内存访问)
还可以由 软件条件(Software Condition) 触发。
所谓 软件条件触发信号,是指:
操作系统在检测到某种特定的软件运行状态或系统条件时,自动向相关进程发送信号。
这种信号的产生 并不依赖用户操作,也不由硬件异常直接触发,而是由操作系统根据系统运行状态主动产生。
管道写入错误(SIGPIPE)
在 Linux 中,管道(Pipe)是一种常见的 进程间通信(IPC)机制 。
假设存在两个进程:
-
写进程(writer):向管道写入数据
-
读进程(reader) :从管道读取数据
结构如下:进程A (writer) → pipe → 进程B (reader)
如果发生以下情况:
- 读端关闭(reader 关闭文件描述符)
- 写端仍然继续向管道写数据
此时会出现一个问题:
写入的数据将没有任何进程读取。
为了避免这种 无意义的资源消耗 ,操作系统会采取措施。
当写进程继续写入时:
-
操作系统检测到 管道读端已经关闭
-
内核会向写进程发送一个信号:
SIGPIPE
信号编号:
13其默认处理行为为:
终止写进程(Terminate)
因此写进程通常会被系统终止。
SIGPIPE 的产生原因
SIGPIPE 的产生并不是由于硬件异常,而是由于一种 软件运行条件:
管道读端关闭 + 写端继续写入因此:
SIGPIPE 是由 操作系统根据软件运行状态自动产生的信号。
这种情况被称为:
Software Condition Generated Signal
定时器信号
在 Linux 系统中,信号不仅可以由用户操作、系统调用或硬件异常产生,还可以由 软件条件(software condition) 触发。其中一个典型例子是 进程定时器信号 。
Linux 提供了 alarm() 系统接口,用于为当前进程设置一个定时器。
该接口定义如下:
c
#include <unistd.h>
unsigned int alarm(unsigned int seconds);其功能是:
为当前进程设置一个定时器,当指定的时间间隔(以秒为单位)到达后,内核会向该进程发送 SIGALRM 信号。
SIGALRM 的信号编号为 14,其默认处理行为是:
终止进程(Terminate Process)
其行为如下:
-
进程调用
alarm(n) -
内核启动一个定时器
-
当 n 秒时间到达 时
-
操作系统向该进程发送信号
发送的信号为:SIGALRM
信号编号:
14默认处理行为:
终止进程
alarm 的基本作用
alarm() 的作用可以理解为:
为当前进程设置一个 闹钟(Timer)。
例如:
c
alarm(5);含义是:
5 秒之后
操作系统向该进程发送 SIGALRM 信号如果进程没有捕获该信号,则默认行为是:
终止进程Linux 中信号的产生方式可以总结为四类:
| 产生方式 | 示例 |
|---|---|
| 用户操作 | Ctrl+C → SIGINT |
| 系统调用 | kill(), raise() |
| 硬件异常 | 除零 → SIGFPE |
| 软件条件 | SIGPIPE、SIGALRM |
其中:
软件条件产生信号指的是:
操作系统根据程序运行时的某种逻辑条件或系统状态,自动向进程发送信号。
典型例子包括:
- SIGPIPE:管道读端关闭但写端继续写
- SIGALRM:定时器时间到达
alarm() 的工作机制
alarm() 的语义类似于为进程设置一个"闹钟"。
当进程调用:
c
alarm(1);其含义是:
- 当前时刻 不会立即触发信号
- 内核启动一个 1 秒的定时器
- 当 1 秒时间到达 时
- 内核向该进程发送 SIGALRM 信号
如果进程未对该信号进行捕获或处理,则会执行默认行为:
text
进程被终止因此在终端中通常会看到类似信息:
text
Alarm clock这表示进程因为接收到 SIGALRM 信号而退出。
alarm() 的返回值
alarm() 具有返回值:
unsigned int返回值含义如下:
| 返回值 | 含义 |
|---|---|
| 0 | 之前没有设置定时器 |
| 非0 | 返回 之前定时器剩余的秒数 |
| 这意味着: |
如果在旧定时器尚未触发时再次调用
alarm(),旧定时器会被取消,并返回其剩余时间。
取消闹钟
如果调用:
c
alarm(0);其语义是:
取消当前进程已经设置的定时器
同时函数返回:
原定时器剩余的秒数因此 alarm(0) 的作用等价于:
取消定时器 + 查询剩余时间为什么 alarm 属于"软件条件触发信号"
在信号分类中,SIGALRM 被归类为 软件条件产生的信号 。
其原因在于:
-
该信号并非由 用户操作 触发
-
也不是由 硬件异常 产生
-
而是由 操作系统内部的软件机制 在满足某种条件时触发
具体条件是:系统时间 >= 设定的超时时间
因此它属于 软件条件触发信号(Software-generated signal)。
I/O 操作对性能的影响
循环中包含输出操作:
cpp
while(true)
{
cout << cnt++ << endl;
}运行结果大约为:
4 万次左右原因是:
每次循环都执行一次 I/O 输出操作
I/O 操作属于 外设访问 ,其速度远慢于 CPU 运算。
因此程序的大部分时间都消耗在:
- 控制台输出
- 缓冲区刷新
- 系统调用
- 终端或网络传输
从而严重降低了循环执行次数。
将输出移出循环:
cpp
while(true)
{
cnt++;
}并在收到信号后打印结果:
cpp
void handler(int signo)
{
printf("%d\n", cnt);
}此时 1 秒内的统计结果可以达到:
3 亿次左右相比之前约 提高了 10⁴(10000)倍 。
性能差异的根本原因在于:
I/O 操作远慢于 CPU 计算
CPU 执行一次自增操作只需要极少的指令周期,而一次输出操作通常涉及:
-
用户态到内核态切换
-
写入内核缓冲区
-
终端设备处理
-
可能的网络传输(远程终端)
在远程服务器环境中,输出数据还需要:服务器 → 网络 → 本地终端
因此 I/O 延迟会进一步增加。
I/O 是程序性能的重要瓶颈
在高性能程序设计中,应尽量避免:
text
在高频循环中执行 I/O 操作因为 I/O 的性能开销远高于普通计算操作。
SIGALRM 信号只触发一次
在实验代码中,我们为进程设置了一个定时器:
c
alarm(1);该调用会在 1 秒后向进程发送一个 SIGALRM 信号 。
如果程序捕获该信号,例如:
c
signal(SIGALRM, handler);则当信号到达时会执行对应的 信号处理函数(signal handler) 。
在实验中可以观察到一个重要现象:
- 信号处理函数只被调用 一次
- 程序只接收到 一个 SIGALRM 信号
原因在于:
alarm()设置的定时器是 一次性定时器(one-shot timer)
即:
- 定时器触发一次后
- 就会自动失效
- 不会再次触发信号
不终止进程时的行为
如果在信号处理函数中 不调用 exit() 终止进程,程序的执行流程如下:
- 程序运行并设置定时器
- 1 秒后收到 SIGALRM
- 内核调用信号处理函数
- 处理函数执行完毕
- 程序继续执行原来的代码
因此我们会看到:
-
处理函数只执行 一次
-
程序不会退出
这是因为我们 覆盖了 SIGALRM 的默认行为 。
默认情况下:SIGALRM → 终止进程
但如果注册了信号处理函数,则由用户代码决定如何处理。
如果希望 每隔一秒执行一次任务,可以在信号处理函数中重新设置定时器,例如:
c
void handler(int signo)
{
printf("%d\n", cnt);
alarm(1); // 重新设置定时器
}程序流程变为:
-
设置
alarm(1) -
1 秒后收到 SIGALRM
-
执行
handler -
在 handler 中再次调用
alarm(1) -
再过 1 秒再次触发信号
这样就形成了一个 周期性定时器(periodic timer) 。
其逻辑可以表示为:SIGALRM → handler() → alarm(1) → SIGALRM → handler() ...
与 sleep 的逻辑类比
这种机制在逻辑上类似于:
c
while (true)
{
sleep(1);
printf("%d\n", cnt);
}区别在于:
| 方法 | 特点 |
|---|---|
| sleep | 主线程阻塞 |
| alarm + signal | 通过信号异步触发 |
alarm() 的方式属于: |
异步事件驱动机制而 sleep() 属于:
同步阻塞机制通过该实验可以得到几个关键结论:
- I/O 操作远慢于 CPU 运算,频繁输出会严重降低程序执行效率。
alarm()设置的定时器是 一次性定时器。- 若需要周期性触发信号,需要在信号处理函数中 重新调用 alarm()
- 使用
alarm()与信号机制可以实现 基于时间的事件触发模型。
操作系统如何管理多个闹钟
任何进程都可以调用 alarm() 设置定时器,因此系统中可能同时存在大量定时器。
操作系统必须对这些定时器进行统一管理。
在操作系统设计中通常遵循一个基本原则:
先描述(Describe),再组织(Organize)即:
-
使用数据结构描述对象
-
再通过某种结构组织这些对象
在操作系统中,多个进程都可以调用alarm()设置定时器,因此内核中可能同时存在 大量定时器对象 。为了高效管理这些定时器,操作系统需要使用合适的数据结构进行组织。
常见的定时器管理策略包括:
时间轮(Time Wheel)
时间轮是一种高效的定时器管理结构,通过将时间划分为多个槽(slot)来组织定时任务。
其核心思想是:时间 → 离散化 → 映射到时间槽
当时间推进时,只需要检查当前时间槽中的定时器即可。
这种结构具有:
- 插入复杂度:O(1)
- 删除复杂度:O(1)
- 检查复杂度:O(1)
因此常用于 高并发服务器定时器系统 。
例如: - Nginx
- Nett
- Redis
都使用类似的思想实现定时任务管理。
最小堆(Min Heap)
另一种经典实现方式是使用 最小堆(优先级队列) 。
假设系统中存在 100 个定时器,每个定时器都有一个 超时时间:
5s
10s
20s
55s
...可以按 超时时间排序 构建最小堆:
5
/ \
10 20
/ \
55 ...最小堆的特点是:
堆顶元素 = 最早到期的定时器操作流程如下:
-
定时器加入系统
→ 插入最小堆 -
操作系统检查定时器
检查堆顶节点
-
如果:
current_time >= heap.top().expire_time
说明定时器到期。
此时:
1. 取出堆顶
2. 向目标进程发送 SIGALRM
3. 调整堆结构
4. 再次检查新的堆顶重复该过程直到:
堆顶未超时这种设计的时间复杂度:
| 操作 | 复杂度 |
|---|---|
| 插入定时器 | O(log n) |
| 删除定时器 | O(log n) |
| 查询最近超时 | O(1) |
| 因此非常适合 中等规模定时器管理。 |
内核中定时器对象的抽象
在概念上,操作系统可以为每一个定时器维护一个结构体,例如:
c
struct alarm
{
uint64_t when; // 超时时间(时间戳)
int type; // 定时器类型(一次性 / 周期性)
task_struct *task; // 所属进程
struct alarm *next; // 指向下一个定时器
};各字段含义如下:
| 字段 | 作用 |
|---|---|
| when | 定时器触发的时间点 |
| type | 定时器类型(one-shot / periodic) |
| task | 关联的进程 |
| next | 用于组织定时器结构 |
| 例如: | |
| 如果当前时间为: |
1000进程设置:
alarm(100)则:
when = 1100表示未来触发时间。
定时器数据结构组织
操作系统需要对所有定时器进行组织,例如:
alarm_list_head → alarm1 → alarm2 → alarm3 → ...当某个进程调用 alarm() 时:
- 内核创建一个 alarm 对象
- 填充定时信息
- 将其加入 定时器队列
定时器检查机制
操作系统会周期性检查这些定时器,例如:
当前时间 = now对于每个定时器:
if (now >= alarm.when)说明:
定时器已经到期此时内核会执行:
向对应进程发送 SIGALRM伪代码示意:
c
for each alarm in alarm_list
{
if (current_time >= alarm.when)
{
send_signal(SIGALRM, alarm.task);
}
}因此,从操作系统内部实现角度来看:
alarm()本质上是 向内核注册一个定时器对象。
操作系统负责:
-
管理所有定时器
-
维护触发时间
-
在条件满足时发送信号
换句话说:alarm() ≈ 在内核中创建一个定时器任务
Linux 中 alarm() 的工作机制可以概括为:
- 进程调用
alarm(seconds) - 内核创建一个定时器对象
- 将其加入定时器管理结构
- 内核周期性检查定时器
- 当时间到达时发送 SIGALRM
- 进程执行默认或自定义信号处理
因此:
SIGALRM属于 由软件条件(时间到达)触发的信号。
软件条件触发信号的本质
通过上述机制可以看到:
操作系统会 周期性检查定时器是否超时 。
判断条件为:
current_time >= timer.expire_time当条件成立时:
内核 → 向目标进程发送 SIGALRM整个过程包括:
-
定时器创建
-
数据结构管理
-
时间检查
-
信号发送
这些行为全部由 操作系统软件逻辑完成 。
因此:SIGALRM 属于 软件条件触发信号
条件就是:
定时器超时信号产生方式总结
在 Linux 系统中,常见的信号产生方式包括以下几类:
| 产生方式 | 示例 |
|---|---|
| 用户输入 | Ctrl+C → SIGINT |
| 命令/工具 | kill 命令 |
| 系统调用 | kill(), raise() |
| 硬件异常 | 除零 → SIGFPE |
| 软件条件 | 定时器超时 → SIGALRM |
| 无论信号来源如何: |
最终发送信号的主体都是操作系统因为只有操作系统才具有 修改进程状态和向进程发送信号的权限。
信号捕获
理论上,进程可以通过信号机制 捕获并处理这些信号,例如:
cpp
signal(SIGSEGV, handler);但是对于由 硬件异常产生的信号,即使捕获该信号:
- 程序内部状态通常已经处于 不可恢复状态
- 因此继续执行往往没有实际意义
所以实际开发中:
大多数情况下仍然会让程序终止。
可以将整个机制总结为:
程序非法操作 → 硬件检测异常 → 操作系统识别异常 → 转换为信号 → 发送给进程 → 默认终止进程
因此:
C/C++ 程序在发生除零或野指针访问时之所以会崩溃,本质上是因为进程收到了操作系统发送的异常信号。
异常机制与信号机制的类比
在高级语言(如 C++、Java )中,程序通常使用 异常机制(Exception Mechanism) 来处理运行时错误。
异常机制的基本流程包括:
- 抛出异常(Throw)
当程序检测到异常情况时,可以主动抛出异常,例如:
cpp
throw ExceptionType;- 捕获异常(Catch)
程序可以在适当位置捕获异常并进行处理:
cpp
try {
// code
}
catch(ExceptionType e) {
// handle
}这一机制与操作系统中的 信号机制(Signal Mechanism) 在概念上具有一定相似性。
| 高级语言 | 操作系统 |
|---|---|
| throw | 发送信号 |
| catch | 捕捉信号 |
| exception | signal |
| 因此可以类比理解为: |
异常机制是语言层面对错误处理的抽象,而信号机制是操作系统层面对异常事件的处理机制。
异常或信号通常意味着程序无法继续正常执行
在实际开发中,无论是:
- 语言层面的异常
- 操作系统层面的信号
大多数情况下都表示:
当前程序已经进入 异常状态(abnormal state)。
因此常见处理方式通常是:
- 记录错误信息(日志)
- 输出提示信息
- 终止程序
例如:
text
记录日志 → 打印错误信息 → 程序退出对于由 硬件异常产生的信号 (例如 SIGSEGV、SIGFPE),程序通常已经处于不可恢复状态,因此继续执行往往没有实际意义。
为什么仍然需要区分不同类型的异常或信号
虽然许多异常或信号的最终结果都是 终止程序 ,但仍然需要区分不同类型的异常。
原因是:
不同异常或信号反映了不同类型的错误原因。
这对于 问题定位和调试(Debugging) 非常重要。
例如:
| 信号 | 含义 | 可能原因 |
|---|---|---|
| SIGSEGV | Segmentation Fault | 野指针、非法内存访问 |
| SIGFPE | Floating Point Exception | 除零、算术溢出 |
| SIGILL | Illegal Instruction | 非法指令 |
| SIGABRT | Abort | 程序主动终止 |
| 当程序崩溃时,通过 错误信息或信号类型,开发者可以快速判断问题来源。 | ||
| 例如: |
- 如果出现 Segmentation Fault
→ 通常说明存在 非法内存访问或野指针问题 - 如果出现 Floating Point Exception
→ 通常说明存在 除零或算术运算异常
因此:
不同的异常或信号可以帮助开发者快速定位问题原因。
可以从两个层面理解这一机制:
语言层面
高级语言通过 异常机制(Exception) 来处理运行时错误:
throw抛出异常catch捕获异常
操作系统层面
操作系统通过 信号机制(Signal) 来处理系统级异常:
- 硬件异常或系统事件产生信号
- 进程接收并处理信号
核心结论
即使大多数异常或信号最终都会导致程序终止,不同类型的异常或信号仍然具有重要意义,因为它们能够反映 程序发生错误的具体原因,从而帮助开发者定位和修复问题。
信号处理
信号是否会立即处理
信号产生之后,并 不会立即执行处理逻辑 。
实际流程是:
信号产生
↓
内核记录信号
↓
等待合适时机处理信号通常会被记录在 进程控制块(PCB) 中。
PCB 内部会维护:
pending signal bitmap用于表示:
当前进程有哪些信号正在等待处理信号处理行为是预先定义的
在信号真正发生之前,系统已经定义好了处理方式。
每个信号都有 默认行为(Default Action),例如:
| 行为 | 含义 |
|---|---|
| Terminate | 终止进程 |
| Ignore | 忽略信号 |
| Stop | 暂停进程 |
| Continue | 继续执行 |
| 程序员也可以通过接口修改: |
signal()
sigaction()来自定义信号处理逻辑。
因此:
即使信号尚未发生,进程也已经知道该如何处理该信号。
操作系统发送信号的本质
在操作系统内部,发送信号并不是直接"调用函数",而是:
修改目标进程 PCB 中的信号状态具体来说就是:
设置 pending signal bitmap 中的某一位例如:
SIGALRM → 设置第14位随后在合适时机:
内核触发信号处理流程终止信号
很多信号的默认行为都是 终止进程,但在 Linux 文档中通常有两种标记:
-
Terminate(Term)
终止进程
特点:
-
进程退出
-
不生成 core dump
例如:SIGTERM
SIGINT
SIGALRM
-
Core Dump(Core)
终止进程 + 生成 core 文件
core 文件用于:
程序崩溃调试例如:
SIGSEGV
SIGABRT
SIGFPEcore 文件中保存:
- 进程内存
- 寄存器状态
- 调用栈
开发者可以使用调试工具分析,例如:
GNU Debugger
信号系统的核心理解可以归纳为:
- 信号产生方式很多,但 最终由操作系统发送
- 信号不会立即处理,而是 记录在 PCB 中等待处理
- 每个信号在发生之前就已经定义了 默认处理行为
- 发送信号的本质是 修改 PCB 的信号状态位
Term与 Core 两种终止方式的区别
在 Linux 信号机制中,不同信号具有不同的默认处理动作(default action) 。
其中最常见的终止类型有两种:
| 类型 | 含义 | 行为 |
|---|---|---|
| Term(Terminate) | 普通终止 | 进程直接被终止,不生成调试信息 |
| Core(Terminate + Core Dump) | 异常终止 | 终止进程,同时生成 core dump 文件 |
Term 类型终止
Term 类型信号的默认行为:
-
终止目标进程
-
不保存进程运行时状态
典型信号: -
SIGTERM -
SIGINT -
SIGKILL
终止流程:信号产生
↓
内核修改PCB中的信号位图
↓
进程被调度时检测到信号
↓
执行默认处理动作
↓
进程终止
特点:
- 不保留调试信息
- 不生成 core 文件
- 通常用于正常终止进程
Core 类型终止
Core 类型信号的默认行为:
- 终止进程
- 生成 Core Dump 文件
Core Dump 文件包含: - 进程虚拟地址空间
- 寄存器状态
- 调用栈
- 内存数据
主要用于:
程序崩溃后的调试分析
常见 Core 信号:
| 信号 | 含义 |
|---|---|
SIGSEGV |
段错误 |
SIGABRT |
程序异常终止 |
SIGFPE |
浮点异常 |
SIGBUS |
总线错误 |
| 例如: |
Segmentation fault (core dumped)表示:
-
发生了
SIGSEGV -
同时生成 core 文件
开发者可以使用gdb program core
分析崩溃原因。
Core Dump(核心转储)
Core Dump 是操作系统在进程异常终止时执行的一种调试机制。
定义:
当进程发生异常终止时,操作系统会将该进程在崩溃时刻的内存状态转储到磁盘文件中,用于后续调试分析。
Core 文件通常包含:
-
进程虚拟地址空间
-
寄存器状态
-
调用栈信息
-
线程状态
-
全局变量与局部变量数据
生成文件形式:core.
例如:
core.8961其中:
PID = 发生异常的进程 ID云服务器默认关闭 Core Dump
在很多 云服务器环境 中,系统默认关闭 Core Dump。
原因:
-
防止生成大文件占用磁盘
-
提高系统安全性
可以使用命令查看资源限制:ulimit -a
其中:
core file size (blocks, -c) 0表示:
Core Dump 被禁用开启 Core Dump
可以通过以下命令开启:
ulimit -c 1024含义:
允许生成最大 1024 blocks 的 core 文件再次查看:
ulimit -a会看到:
core file size (blocks, -c) 1024当程序崩溃时:
Segmentation fault (core dumped)并且当前目录会生成:
core.<PID>Core Dump 的作用:事后调试(Post-mortem Debugging)
Core Dump 的主要作用是:
支持 程序崩溃后的离线调试
这种调试方式称为:
Post-mortem Debugging即:
事后调试
使用 GDB 分析 Core Dump
为了使 Core 文件包含完整调试信息,程序编译时需要加入:
-g示例:
gcc -g main.c -o program程序崩溃后:
gdb program core.<pid>例如:
gdb mysignal core.8961GDB 会自动加载:
-
程序
-
Core 文件
-
崩溃现场数据
随后可以直接定位崩溃位置,例如:Program terminated with signal SIGSEGV
并显示:
mysignal.c:31即:
程序在 第 31 行代码发生崩溃。
数组越界为什么不一定崩溃
在学习 C 语言时,调试阶段(如 Debug / Release 模式分析 )经常会遇到一种现象:
例如:
c
int arr[10];
for(int i = 0; i < 13; i++)
{
arr[i] = i;
}数组实际大小为 10 个元素 ,但程序访问到了 arr10、arr11、arr12 。
在实际运行时可能出现以下情况:
- 程序 没有崩溃
- 编译 没有报错
- 程序 仍然正常运行
这种现象的原因涉及多个层次:
语言层原因
C 语言属于 不进行边界检查的语言(No Bounds Checking) 。
数组访问:
c
arr[i]在编译后会转换为:
c
*(arr + i)本质上只是 指针偏移访问 。
因此:
- 编译器不会检测数组越界
- 运行时也不会自动检查
这种行为属于:
Undefined Behavior(未定义行为)
操作系统层原因
即使发生数组越界,程序也 不一定崩溃 ,原因是:
操作系统的内存保护机制是 以页(Page)为单位 进行管理,而不是变量级别。
典型页大小:
4KB假设:
int arr[10] = 40 Bytes即使访问:
arr[100]仍可能位于 同一虚拟页内 。
只要访问地址:
-
属于当前进程的合法虚拟地址空间
-
且权限允许访问
CPU 和操作系统都不会触发异常。
只有当访问: -
未映射地址
-
受保护区域
-
内核空间
CPU 才会产生 Page Fault,随后内核向进程发送:SIGSEGV
即:
Segmentation FaultC 语言语义角度
C 语言:
不进行数组越界检查(No Bounds Checking)
因此:
-
编译器不会报错
-
运行时也不会自动检测
所以:a[100]
编译后只是:
*(a + 100)即:
一个普通指针访问操作
进程虚拟地址空间角度
数组 a 通常位于:
栈区(Stack)例如函数栈布局:
高地址
│
│ 局部变量
│ a[10]
│
│ 其他栈数据
│
低地址当访问:
a[100]可能出现三种情况:
情况1:仍然在合法栈空间
a[100]仍然落在:
当前进程栈页(stack page)结果:
- 操作系统不会检测到异常
- 程序继续运行
- 但可能破坏其他变量
这种情况叫:
Silent Memory Corruption(静默内存破坏)
情况2:访问未映射页
如果越界访问:
访问未映射虚拟页CPU 会触发:
Page Fault
内核检查后发现:
-
该地址没有映射
于是发送信号:SIGSEGV
结果:
Segmentation fault情况3:访问受保护区域
例如:
-
内核空间
-
只读页
CPU 会产生:
Protection Fault
同样导致:SIGSEGV
操作系统为什么有时检测不到越界
关键原因:
操作系统只检查页级别(Page Level Protection),不会检查变量级别边界
内存保护粒度:
4KB Page而数组:
int a[10] = 40B远小于一页。
因此:
a[10] → a[100]可能仍在同一页中。
操作系统无法识别。
- 数组越界不一定导致程序崩溃
原因:
- C 语言不进行数组边界检查
- 数组访问在编译后仅表现为指针偏移
- 操作系统只在访问非法虚拟地址时才会触发异常
触发条件:
-
访问未映射页
-
访问权限违规
-
地址空间越界
此时 CPU 触发异常,内核发送:SIGSEGV
- 如果越界仍处于合法虚拟页内
则:
- 操作系统无法检测
- 程序继续运行
- 但可能破坏栈或其他数据
这类错误属于:
未定义行为(Undefined Behavior)
在 C 语言中,数组越界属于未定义行为。
编译器不会进行边界检查,而操作系统只在访问非法虚拟地址时才会触发
SIGSEGV。如果越界访问仍然位于进程合法虚拟页中,程序可能不会崩溃,而是造成内存数据破坏。
总结
可以用以下专业结论总结:
- C 语言数组越界属于 未定义行为,编译器不会自动检测。
- 操作系统只在访问非法虚拟地址时才会触发异常并发送
SIGSEGV。 - Linux 信号终止类型分为 Term 与 Core。
- Core 类型信号会在进程异常终止时生成 **Core Dump 文件
- Core Dump 用于 事后调试(Post-mortem Debugging),可以借助 GDB 快速定位程序崩溃位置。
信号捕捉机制
在 Linux 中,可以通过 signal() 或 sigaction() 为信号注册 自定义处理函数 。
示例:
c
#include <signal.h>
void handler(int sig)
{
printf("signal received: %d\n", sig);
}
int main()
{
signal(SIGINT, handler);
}此时:
- 当进程接收到
SIGINT时 - 将执行 自定义处理函数
而不是执行默认动作。
需要注意:
调用
signal()只是 注册信号处理函数,并不会立即执行该函数。
处理函数只有在 信号实际到达时 才会被调用。
捕捉所有信号的实验
可以通过循环为多个信号注册同一个处理函数:
c
for(int sig = 1; sig <= 31; sig++)
{
signal(sig, handler);
}该程序的行为是:
- 为所有普通信号注册相同的捕捉函数
- 当信号到达时执行
handler
同时程序通过循环保持运行:
c
while(1)
{
sleep(1);
}在此情况下:
- 进程收到信号时不会执行默认终止动作
- 仅执行自定义处理函数
因此许多信号将 无法终止该进程。
为什么进程仍然可以被终止
如果允许进程捕获 所有信号 ,将导致严重的系统安全问题:
例如:
- 恶意程序可以屏蔽所有终止信号
- 系统管理员无法结束该进程
为了解决这一问题,Linux 内核设计了 不可捕获信号(Uncatchable Signals)。
不可捕获信号
Linux 中有两个特殊信号:
| 信号 | 编号 | 特性 |
|---|---|---|
| SIGKILL | 9 | 不可捕获、不可忽略 |
| SIGSTOP | 19 | 不可捕获、不可忽略 |
SIGKILL(信号 9)
特点:
- 无法被程序捕获
- 无法被忽略
- 无法被屏蔽
因此系统管理员可以通过:
bash
kill -9 <pid>强制终止进程 。
该操作由 内核直接执行,不会进入用户态信号处理函数。
SIGSTOP(信号 19)
作用:
- 强制暂停进程
同样: - 不可捕获
- 不可忽略
可以通过以下信号恢复运行:
bash
kill -18 <pid>对应信号:
SIGCONT信号捕捉的本质
调用:
c
signal(sig, handler);本质上只是:
在进程的 PCB(Process Control Block) 中注册信号处理函数。
当信号到达时:
- 内核修改进程的 信号位图
- 进程在合适的执行点检测到信号
- 进入用户态执行注册的 handler
因此:
如果没有信号产生,处理函数不会被执行。
总结
核心结论:
- Linux 信号机制包括 产生、保存和处理 三个阶段。
- 当程序异常终止时,本质上是 进程接收到了某个信号。
- 如果信号属于 Core 类型 ,系统可以生成 Core Dump 文件 用于调试。
- Core Dump 支持 事后调试(Post-mortem Debugging),可以通过 GDB 快速定位错误代码。
- 程序可以通过
signal()注册 自定义信号处理函数,改变信号默认行为 - 为了保证系统可控性,Linux 内核保留了 不可捕获信号 :
SIGKILL (9)SIGSTOP (19)
SIGKILL可以确保系统管理员始终能够 强制终止任意进程。
信号的保存
在 Linux 信号机制中,完整的生命周期通常包括三个阶段:
- 信号产生(Signal Generation)
- 信号保存(Signal Pending / Signal Masking)
- 信号处理(Signal Handling)
此前已经介绍了信号产生的多种方式,例如:
- 硬件异常
- 软件条件
- 键盘输入
- 系统调用(如
kill) - 进程间通信
需要注意的是:
无论信号由哪种方式触发,最终都必须由 操作系统内核 负责向目标进程发送信号。
用户程序并不能直接修改进程控制块(PCB),所有信号操作都必须通过系统调用进入内核完成。
信号递达(Signal Delivery)
定义
当进程实际执行某个信号对应的处理动作时,该过程称为:
信号递达(Signal Delivery)
信号递达可能对应以下几种行为:
- 执行默认处理动作(如终止进程)
- 调用用户自定义信号处理函数
- 执行忽略操作
例如:
text
SIGINT → 执行用户自定义 handler
SIGTERM → 终止进程上述实际执行处理逻辑的过程,即为 信号递达。
信号未决(Pending Signal)
在 Linux 中,信号并不是在产生后立即被处理。
定义
从信号产生到信号递达之间的状态,称为 未决状态(Pending)。
即:
Signal Generated
↓
Pending (未决)
↓
Signal Delivered因此,一个信号在系统中可能处于:
- 已产生
- 尚未处理
的状态。
该机制的原因在于: - 进程可能正在执行关键代码
- 内核需要在合适的时机进行信号处理
因此信号会被 暂时保存。
信号阻塞(Signal Blocking)
除了"未决状态"外,Linux 还允许进程主动 阻塞某些信号 。
定义
进程可以通过设置 信号屏蔽字(Signal Mask),使某些信号暂时无法被递达。
如果某个信号被阻塞:
- 当该信号产生时
- 不会立即被处理
- 会一直保持在 Pending 状态
只有在 解除阻塞(Unblock) 后,该信号才可能被递达。
因此信号处理流程可以表示为:
Signal Generated
↓
Pending
↓
(若被阻塞 → 保持 Pending)
↓
解除阻塞
↓
Signal Delivery阻塞与忽略的区别
在信号处理机制中,阻塞(Block) 与 忽略(Ignore) 是两个完全不同的概念。
阻塞(Block)
特点:
-
信号不会被递达
-
信号会被保存在 Pending 状态
-
解除阻塞后仍然可能被处理
即:Signal Generated
↓
Pending
↓
Blocked
↓
Unblock
↓
Delivered
无信号时仍可设置阻塞
信号阻塞机制 并不依赖于信号是否已经产生 。
也就是说:
- 即使当前没有任何信号
- 进程仍然可以提前设置 阻塞某些信号
当未来这些信号产生时: - 它们将直接进入 Pending 状态
- 不会立即递达。
信号阻塞与进程阻塞的区别
需要区分两个容易混淆的概念:
| 概念 | 含义 |
|---|---|
| 进程阻塞(Process Blocking) | 进程因等待资源进入阻塞状态 |
| 信号阻塞(Signal Blocking) | 进程屏蔽某些信号 |
两者完全不同:
进程阻塞
Running → Waiting → Ready原因:
-
等待 I/O
-
等待锁
-
等待资源
信号阻塞Signal Masking
作用:
- 控制哪些信号可以被递达
因此:
信号阻塞与进程状态无关。
忽略(Ignore)
忽略是一种 信号处理方式 。
当信号递达时:
-
系统执行的处理动作是 Ignore
因此流程是:Signal Generated
↓
Pending
↓
Delivered
↓
Ignore
也就是说:
忽略是 一种处理结果 ,而阻塞是 一种递达控制机制。
Pending 与 Block 的关系
需要注意:
Pending(未决) 与 Block(阻塞) 是两种完全不同的概念。
| 概念 | 含义 |
|---|---|
| Pending | 信号已经产生但尚未递达 |
| Block | 进程主动禁止该信号递达 |
它们之间可能存在组合关系:
- 未阻塞信号 → 可以递达
- 阻塞信号 → 会保持 Pending