目录
[1. 项目背景与开发目标](#1. 项目背景与开发目标)
[2. 项目整体架构设计](#2. 项目整体架构设计)
[3. 图形界面是如何设计的](#3. 图形界面是如何设计的)
[4. 多模型切换机制是怎么实现的](#4. 多模型切换机制是怎么实现的)
[5. 核心算法原理详解](#5. 核心算法原理详解)
[5.1 BP 神经网络:我为什么把它作为神经网络基线](#5.1 BP 神经网络:我为什么把它作为神经网络基线)
[5.2 CNN:为什么我把表格数据也做成了 1D-CNN](#5.2 CNN:为什么我把表格数据也做成了 1D-CNN)
[5.3 XGBoost:为什么它是这个系统里最重要的表格模型之一](#5.3 XGBoost:为什么它是这个系统里最重要的表格模型之一)
[5.4 遗传算法:为什么我要用启发式方法做超参数优化](#5.4 遗传算法:为什么我要用启发式方法做超参数优化)
[6. 参数优化模块是怎么工作的](#6. 参数优化模块是怎么工作的)
[7. 系统运行流程与实验结果展示](#7. 系统运行流程与实验结果展示)
[8. 我在开发中遇到的关键问题](#8. 我在开发中遇到的关键问题)
[8.1 GUI 不能被训练过程卡死](#8.1 GUI 不能被训练过程卡死)
[8.2 多模型接口不统一](#8.2 多模型接口不统一)
[8.3 不同模型的输入格式不一样](#8.3 不同模型的输入格式不一样)
[8.4 参数面板不能写死](#8.4 参数面板不能写死)
[8.5 依赖不完整不能让系统直接崩](#8.5 依赖不完整不能让系统直接崩)
[8.6 优化过程太耗时](#8.6 优化过程太耗时)
[9. 项目可改进方向](#9. 项目可改进方向)
[10. 总结](#10. 总结)
1. 项目背景与开发目标
我做这个项目的出发点其实很直接:很多机器学习项目算法能跑,但展示性不够。最常见的情况是,模型训练写在 Notebook 里,参数改动依赖手工改代码,结果看图也 scattered 在不同脚本中。对于课程设计、毕业设计,甚至项目演示来说,这种方式不够友好,也不够"系统化"。
所以我想做一个真正能交互的机器学习桌面系统,把数据导入、任务识别、模型切换、参数设置、启发式优化、训练控制、结果展示、模型保存和预测都放到一个 GUI 里。这样它既可以作为一个完整的工程作品,也能让我把"算法原理"和"软件实现"真正揉在一起,而不是只停留在某一层。
从当前代码结构来看,ml_gui_system 并不是典型的前后端分离项目,而是一个基于 PySide6 的单体桌面应用。这反而很适合这个题目:界面层、算法层、数据层、优化层都在一个 Python 进程里,通过信号槽和线程做解耦,减少了额外的网络通信复杂度,也更适合教学和演示。
我给这个系统设定的核心目标有四个:
- 让用户不用改代码,就能在界面中切换不同模型。
- 让优化算法不是"概念展示",而是真正参与超参数搜索。
- 让结果展示不仅有数字,还要有图、有对比、有报告。
- 让工程结构足够清晰,后续继续加模型、加优化器、加数据类型都不至于推倒重来。
2. 项目整体架构设计
我先把整个工程拆成了几个相对清晰的层次:ui 负责交互,models 负责模型封装,data 负责预处理,optimizers 负责启发式搜索,utils 负责配置、指标和可视化。这样做的好处是,我在加模型时基本不碰 GUI 主流程,在改界面时也不用去侵入模型实现。
从核心模块如下:
| 模块 | 路径 | 作用 |
|---|---|---|
| 应用入口 | main.py | 初始化 QApplication,处理高 DPI,启动主窗口 |
| GUI 主界面 | ui/main_window.py | 负责界面布局、事件绑定、训练线程调度、结果更新 |
| 图表组件 | ui/plot_widget.py | 封装结果图、优化图、模型对比图三个标签页 |
| 通用控件 | ui/widgets.py | 封装参数表单、数据预览表、指标表、比较表、预测对话框 |
| 数据处理 | data/data_processor.py | 缺失值处理、编码、标准化、划分训练/测试集 |
| 模型层 | models/*.py | 封装 BP、CNN、XGBoost、SVM、RF、KNN 等模型 |
| 模型工厂 | models/model_factory.py | 动态注册和创建模型,按任务和依赖过滤 |
| 优化器层 | optimizers/*.py | 实现 GA、PSO、SA |
| 配置中心 | utils/config.py | 统一维护模型参数 schema、搜索空间、样式和示例数据 |
| 指标与图表 | utils/metrics.py、utils/visualization.py | 评估与可视化 |
| 示例数据 | sample_data/ | 提供可直接演示的 CSV / Excel 数据和生成脚本 |
3. 图形界面是如何设计的
这次我在 GUI 设计上花的心思,甚至不比模型少。因为一个机器学习系统只要一上 GUI,就会立刻面临两个现实问题:控件多、状态多。如果布局没有设计好,用户会觉得系统"堆满了东西但不会用"。
我最后采用的是"顶部概览 + 中部左右分栏 + 右侧上下分割"的结构。顶部放项目概览,左边是控制面板,右边是结果区。左侧整体放进 QScrollArea,这样即使模型参数很多,界面也不会把下半部分挤没;右侧再用一个垂直 QSplitter 分成上半部分图表区和下半部分结果/日志区,保证笔记本屏幕上也能完整操作。
这部分布局核心代码就在 ui/main_window.py 里:
python
main_splitter = QSplitter(Qt.Orientation.Horizontal)
left_scroll = QScrollArea()
left_scroll.setWidgetResizable(True)
right_splitter = QSplitter(Qt.Orientation.Vertical)
self.plot_tabs = PlotTabWidget()
right_splitter.addWidget(self.plot_tabs)
lower_tabs = QTabWidget()
lower_tabs.addTab(self._build_metrics_tab(), "指标结果")
lower_tabs.addTab(self._build_comparison_tab(), "模型比较")
lower_tabs.addTab(self._build_log_tab(), "训练日志")
right_splitter.addWidget(lower_tabs)这段代码背后的思路很明确:左边解决"参数太多"的问题,右边解决"图表、指标、日志争空间"的问题。我没有继续用纯粹的纵向堆叠布局去硬塞内容,而是把"滚动"和"可拖动分割"都交给 Qt 的现成控件,这会让界面在不同分辨率下稳很多。
我把界面划成了几个固定职责区:
| 区域 | 主要控件 | 作用 |
|---|---|---|
| 顶部概览 | QGroupBox + QLabel | 显示数据规模、目标列、任务、模型、优化方式、状态 |
| 数据区 | 数据导入按钮、示例数据按钮、预览表、目标列选择 | 导入 CSV/Excel,选择目标列,显示任务建议 |
| 模型区 | 模型下拉框、说明标签、参数表单 | 选择模型并动态刷新参数 |
| 优化区 | 优化方式、目标指标、范围表格 | 配置 GA/PSO/SA 以及搜索空间 |
| 控制区 | 训练、停止、保存、加载、预测 | 管理训练生命周期 |
| 图表区 | PlotTabWidget | 显示结果图、优化曲线、模型对比图 |
| 底部标签页 | 指标表、比较表、日志 | 提供结构化结果与运行日志 |
为了让参数区不是写死的,我又做了一个通用的 ParameterFormWidget。它接收一个 schema,然后自动创建 QSpinBox、QDoubleSpinBox、QComboBox、QCheckBox 等控件:
python
def set_schema(self, schema: list[dict[str, Any]]) -> None:
self.schema = list(schema)
self._clear_form()
self.widgets.clear()
for config in self.schema:
widget = self._create_widget(config)
self.widgets[config["name"]] = widget
self.form_layout.addRow(config["label"], widget)这个设计对我帮助很大。因为我后面新增模型时,不是去"新增一个参数面板类",而是给 config.py 加一段配置,界面层就能自动把它渲染出来。这个模式本质上是把界面做成了 配置驱动的动态表单。
另外,从当前实现看,我还专门做了几个界面体验优化点:
- 按钮和 Tabs 样式统一走 APP_STYLESHEET
- 图表画布设置了最小宽高,避免被压缩得太难看
- 模型说明区会提示模型适用任务和当前环境未显示的模型
- 支持"恢复默认参数"
- 支持"加载示例数据"
- 通过 statusBar().showMessage() 和顶部状态区同步反馈运行状态
4. 多模型切换机制是怎么实现的
这个系统最核心的能力之一,就是"模型可以切换,而且切换后参数面板、训练流程、保存加载流程都还能工作"。如果这部分设计得不好,后面每加一个模型,主窗口都会变得更乱。
我最后用的是 统一接口 + 工厂模式 + 配置映射 的组合方式。
首先,我在 models/base_model.py 里定义了统一接口。所有模型都必须实现 fit、predict、save、load,并且统一带上 task_type 和 params:
python
class BaseModel:
model_name = "Base"
supported_tasks = ("classification", "regression")
def __init__(self, task_type: str, params: dict | None = None) -> None:
self.task_type = task_type
self.params = params or {}
self.training_history: list[float] = []然后我又在 models/sklearn_base_model.py 里做了一层通用封装,把绝大部分 sklearn 模型的重复逻辑抽掉了。像 SVM、RandomForest、DecisionTree、KNN、LogisticRegression、LinearRegression、NaiveBayes、AdaBoost 这些模型,本质上都是在声明:
- 分类 estimator 是谁
- 回归 estimator 是谁
- 默认参数是什么
- 是否需要少量 _prepare_params() 修正
这让模型层非常整洁。比如 SVM 的实现就很轻:
python
class SVMModel(SklearnBaseModel):
model_name = "SVM"
estimator_cls_classification = SVC
estimator_cls_regression = SVR
default_params = {
"C": 1.0,
"kernel": "rbf",
"gamma": "scale",
"degree": 3,
"epsilon": 0.1,
}
def _prepare_params(self):
params = dict(self.params)
if self.task_type == "classification":
params["probability"] = True
params.pop("epsilon", None)
else:
params.pop("degree", None)
return params真正把"多模型切换"串起来的,是 models/model_factory.py。我没有把模型类直接硬编码到主窗口里,而是先定义 MODEL_IMPORT_SPECS,再通过动态导入去装配模型:
python
def _load_registry() -> tuple[dict[str, type[BaseModel]], dict[str, str]]:
registry = {}
unavailable = {}
for model_name in MODEL_DISPLAY_ORDER:
module_name, class_name = MODEL_IMPORT_SPECS[model_name]
try:
module = import_module(module_name)
registry[model_name] = getattr(module, class_name)
except Exception as exc:
unavailable[model_name] = str(exc)
return registry, unavailable这个设计有两个工程上的好处。
第一,模型列表不再和 GUI 强耦合。MainWindow 只需要问一句 ModelFactory.list_models(task_type),就知道当前任务下应该显示哪些模型。
第二,我解决了一个很常见但很容易忽视的问题:可选依赖。比如当前仓库里虽然已经有 CNNModel、XGBoostModel、LightGBMModel 的代码,但如果运行环境里缺少 torch、xgboost 或 lightgbm,我不希望程序一启动就崩。所以我在工厂里把导入失败的原因记到 UNAVAILABLE_REASONS,界面上则提示"安装依赖后自动出现"。
这意味着从当前实现来看,模型切换逻辑并不是一堆 if...elif...else... 的堆砌,而是:
- config.py 声明模型参数和任务适配信息
- ModelFactory 负责动态装配
- MainWindow 根据任务刷新下拉框
- ParameterFormWidget 根据 schema 动态渲染表单
这种结构对扩展新模型特别友好。
我把当前系统中比较核心的模型角色概括成下面这张表:
| 模型 | 任务类型 | 底层实现 | 在系统中的角色 |
|---|---|---|---|
| BP | 分类 / 回归 | MLPClassifier / MLPRegressor | 神经网络基线模型 |
| CNN | 分类 / 回归 | 自定义 PyTorch 1D-CNN | 深度学习演示模型 |
| XGBoost | 分类 / 回归 | 官方 XGBClassifier / XGBRegressor | 强表格模型 |
| SVM | 分类 / 回归 | SVC / SVR | 中小样本边界建模 |
| RandomForest | 分类 / 回归 | sklearn 随机森林 | 稳定的树模型基线 |
| DecisionTree | 分类 / 回归 | sklearn 决策树 | 可解释、训练快 |
| KNN | 分类 / 回归 | sklearn KNN | 距离度量型模型 |
| LogisticRegression | 分类 | sklearn 逻辑回归 | 分类经典基线 |
| LinearRegression | 回归 | sklearn 线性回归 | 回归经典基线 |
| NaiveBayes | 分类 | GaussianNB | 轻量级分类基线 |
| AdaBoost | 分类 / 回归 | sklearn AdaBoost | 集成学习扩展 |
| LightGBM | 分类 / 回归 | LGBMClassifier / LGBMRegressor | 可选扩展模型 |
5. 核心算法原理详解
这一部分我不想只讲概念,而是想把"原理"和"当前代码里的实现方式"放在一起讲。因为算法真正有意思的地方,不只是它的数学形式,而是它落到工程里以后,输入输出究竟怎么流。
5.1 BP 神经网络:我为什么把它作为神经网络基线
在这个项目里,BP 神经网络并不是我手写的反向传播,而是封装了 sklearn 的 MLPClassifier 和 MLPRegressor。这其实是一个很实用的选择:对于课程设计和桌面建模系统来说,自己手搓一个完整的前馈网络训练器不是不行,但会把大量精力消耗在数值稳定性和训练细节上,反而削弱了系统整体性。
BP 神经网络的核心思想,是用多层线性变换加非线性激活去逼近复杂映射。对第 ll 层来说,前向传播可以写成:
如果是回归任务,我更关心的是均方误差:
参数更新遵循梯度下降或其变体:
在当前项目中,我的 BP 模型实现很直接:
python
class BPModel(SklearnBaseModel):
model_name = "BP"
estimator_cls_classification = MLPClassifier
estimator_cls_regression = MLPRegressor
default_params = {
"hidden_layer_sizes": 64,
"learning_rate_init": 0.001,
"batch_size": 32,
"max_iter": 200,
"activation": "relu",
"alpha": 0.0001,
}
def _prepare_params(self):
params = dict(self.params)
hidden_value = params.get("hidden_layer_sizes", 64)
params["hidden_layer_sizes"] = (int(hidden_value),)
return params这段代码说明了两个实现细节。
第一,我把 hidden_layer_sizes 做成了单值输入,然后在 _prepare_params() 里转成 tuple。这样界面上参数更简单,用户也更容易理解。
第二,我把 BP 放在了 SklearnBaseModel 体系里,而不是单独搞一套保存加载和预测逻辑。这让它在训练线程、模型工厂、结果展示里的行为和其他传统机器学习模型保持一致。
在这个系统里,BP 更像是一个"神经网络基线"角色。它适合中小规模表格数据,尤其适合展示"非线性拟合"能力。但它也有明显局限:
- 对输入尺度较敏感,所以我必须在 DataProcessor 里做标准化
- 参数比较多,容易受学习率、层宽、迭代次数影响
- 对纯表格数据,它未必总能打赢树模型
也正因为如此,我才让它特别适合和 GA 配合:BP 的超参数空间比较典型,拿来做启发式优化展示很有代表性。
5.2 CNN:为什么我把表格数据也做成了 1D-CNN
很多人一看到 CNN,就会先想到图像。但从当前项目代码来看,我实现的是 表格数据 1D-CNN,而不是 2D 图像卷积。这是一个很有现实感的工程取舍:当前项目的数据入口是 CSV / Excel,系统里没有图像目录加载器,所以我需要一个能在表格数据上跑通的 CNN 版本。
对于一维卷积来说,一个卷积核在位置 tt 的输出可以写成:
如果把每一列特征看成序列上的一个位置,那么 1D-CNN 就可以在"特征维度"上学习局部组合模式。
我在 models/cnn_model.py 里定义的网络结构是:
python
self.network = nn.Sequential(
nn.Conv1d(1, conv_channels, kernel_size=kernel_size, padding=padding),
nn.BatchNorm1d(conv_channels),
nn.ReLU(),
nn.Conv1d(conv_channels, mid_channels, kernel_size=kernel_size, padding=padding),
nn.BatchNorm1d(mid_channels),
nn.ReLU(),
nn.AdaptiveAvgPool1d(1),
nn.Flatten(),
nn.Linear(mid_channels, hidden_dim),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, output_dim),
)这个结构很轻,但很完整:
- 两层 Conv1d 负责提取局部模式
- BatchNorm1d 提升训练稳定性
- AdaptiveAvgPool1d(1) 把不同长度的特征图压成统一尺寸
- 全连接层完成最终分类或回归
为了让表格数据能进入这个网络,我在训练前做了一个关键 reshape:
python
X_tensor = torch.tensor(X, dtype=torch.float32).unsqueeze(1)也就是说,我把输入变成了:
shape=batch,1,feature_dimshape=batch,1,feature_dim
这里的 1 不是图像通道,而是"单通道特征序列"。这和经典图像 CNN 不同,但对当前这个系统是合理的。因为我的目标不是做 SOTA,而是让系统在 tabular 数据场景下也能展示卷积网络的训练、可视化和参数优化流程。
我认为 CNN 在这个系统里的角色更偏"深度学习分支"的展示:
- 它能补齐系统的模型谱系,不至于只有传统 ML
- 它适合和 BP 做神经网络风格对比
- 它能带出 QThread、epoch 进度、loss 日志这些更丰富的 GUI 交互
但我也必须诚实地说,从当前实现来看,它还不是图像任务的完整 CNN 系统。DataProcessor 里只是通过列名是否像 pixel 去提示"可扩展为 2D-CNN",并没有真正实现图像文件夹读取和 2D 卷积分支。这一点在后面的改进方向里我会再讲。
5.3 XGBoost:为什么它是这个系统里最重要的表格模型之一
如果说 BP 和 CNN 主要承担"神经网络分支"的角色,那 XGBoost 在这个系统里就是典型的"强表格模型"。
XGBoost 的核心思想,是以加法模型的方式逐轮叠加树模型:
每一轮都在优化下面这个目标函数:
其中正则项控制树复杂度:
这也是 XGBoost 在工程上很有优势的原因:它不是一味堆树,而是把损失下降和模型复杂度都纳入目标函数。
在我的代码里,XGBoostModel 最重要的部分是根据任务类型和类别数动态选择 objective:
python
if self.task_type == "classification":
n_classes = len(np.unique(y))
if n_classes <= 2:
return XGBClassifier(objective="binary:logistic", eval_metric="logloss", **common_kwargs)
return XGBClassifier(
objective="multi:softprob",
eval_metric="mlogloss",
num_class=n_classes,
**common_kwargs,
)
return XGBRegressor(objective="reg:squarederror", eval_metric="rmse", **common_kwargs)这段实现我很喜欢,因为它体现了"系统型项目"该有的样子:模型不是写死在某一个任务上,而是根据当前数据自动切换到合适的目标。
另外我还在参数里固定了:
- tree_method="hist"
- n_jobs=1
- verbosity=0
这几个细节其实都很工程化。hist 能让树构建更快,verbosity=0 保证日志不污染 GUI,n_jobs=1 则避免桌面端把 CPU 占满导致界面卡顿。
在这个系统里,我把 XGBoost 看成"表格数据的主力模型":
- 对非线性和特征交互很敏感
- 对缺失值和复杂分布通常更稳
- 很适合与 RF、DT、BP 做横向比较
- 超参数空间丰富,非常适合接入 GA 做优化展示
它的缺点也很明显:参数多,训练与调参成本高。如果没有统一的超参数优化模块,用户其实很难把它调到比较理想的状态。
5.4 遗传算法:为什么我要用启发式方法做超参数优化
我在这个系统里引入遗传算法,不是为了"看起来高级",而是因为它确实适合这个场景。
超参数优化和普通梯度下降不一样。像 hidden_layer_sizes、n_estimators、kernel_size、max_depth 这类参数,很多都是离散的,或者混合了离散与连续变量。对这类问题,GA 这种 无梯度、全局搜索倾向明显 的方法就很自然。
我在 optimizers/ga_optimizer.py 里实现的 GA,是一个比较标准但足够实用的版本。整体流程是:
- 随机初始化种群
- 评估当前种群的适应度
- 按分数排序
- 保留精英个体
- 锦标赛选择父代
- 交叉生成子代
- 做边界约束下的变异
- 重复迭代
核心循环代码是这样的:
python
for generation in range(self.generations):
scored_population = []
for candidate in population:
score = self.objective_func(candidate)
scored_population.append((score, candidate))
scored_population.sort(key=lambda item: item[0], reverse=self.direction == "max")
current_best_score, current_best_params = scored_population[0]
next_population = [copy.deepcopy(candidate) for _, candidate in scored_population[: self.elite_size]]
while len(next_population) < self.population_size:
parent_one = self._tournament_select(scored_population)
parent_two = self._tournament_select(scored_population)
child = self._crossover(parent_one, parent_two)
child = self._mutate(child)
next_population.append(child)我这里最想强调两点。
第一,我没有把适应度写死为某一个值,而是让 TrainingWorker 提供 objective_func,再通过 metric_direction() 决定当前指标是该最大化还是最小化。也就是说:

只是对于回归任务,我并没有简单地把指标取负,而是让优化器显式支持 "min" 方向。这个设计更清晰,也更容易扩展。
第二,我的浮点参数交叉不是简单二选一,而是做了线性混合:
变异则是带边界约束的随机扰动:
这和代码里的 _crossover()、_mutate() 是一致的。
遗传算法在这个系统里承担的角色非常明确:它不是替代模型训练,而是一个"模型外层的搜索器"。它只负责找到更好的超参数组合,真正的训练和评估仍然由模型类本身完成。
从当前代码来看,我还实现了 PSO 和 SA。这说明系统在优化器设计上已经不是单一算法,而是预留了"优化器工厂"的结构。只是从工程重心看,当前版本最完整、最适合重点讲解的仍然是 GA。
6. 参数优化模块是怎么工作的
如果说上一节讲的是"GA 本身是什么",那这一节我更想讲"GA 在这个系统里是怎么接进训练流程的"。
我在 ui/main_window.py 的 TrainingWorker 里,把优化过程放进了后台线程,而不是放在主线程里直接跑。这样一来,超参数搜索即使会多次训练模型,也不会卡死界面。
更关键的是,我不是直接拿测试集调参,而是先在训练集内部再切一份验证集:
python
X_sub_train, X_val, y_sub_train, y_val = train_test_split(
X_train,
y_train,
test_size=0.2,
random_state=42,
stratify=stratify,
)这一步很重要,因为如果直接用测试集搜索参数,测试集就失去"最终评估"的意义了。虽然这里还不是交叉验证,但至少守住了最基本的训练/验证/测试分离思路。
适应度函数则由训练线程动态构造:
python
def objective_func(candidate_params: dict[str, Any]) -> float:
merged_params = {**self.model_params, **candidate_params}
candidate_model = ModelFactory.create(self.model_name, self.task_type, merged_params)
candidate_model.fit(X_sub_train, y_sub_train, stop_callback=lambda: self._stop_requested)
metrics = self._evaluate_model(candidate_model, X_val, y_val, class_labels)
return extract_metric_value(metrics, self.objective_metric)这段代码其实就是"把超参数优化问题翻译成模型训练问题"的关键桥梁:
- 候选参数来自优化器
- 模型实例来自工厂
- 训练数据来自子训练集
- 评价指标来自验证集
- 返回值就是适应度
我还专门做了一步"基线模型训练",用于展示优化前后对比。也就是说,当用户选择 GA/PSO/SA 时,系统不是直接开始优化,而是先用原始参数跑一遍,得到 baseline 指标,再去搜索最优参数,最后再训练最终模型。这一点在教学和演示上非常有价值,因为用户能直观看到"优化到底有没有带来变化"。
从 config.py 来看,我已经给多个模型配置了搜索空间。比较有代表性的参数如下:
| 模型 | 待优化参数 | 搜索范围示例 | 优化目标 |
|---|---|---|---|
| BP | hidden_layer_sizes、learning_rate_init、batch_size、max_iter | 16256、0.00050.03、16128、120500 | 分类最大化 Accuracy/F1,回归最小化 RMSE/MAE |
| CNN | conv_channels、kernel_size、learning_rate、batch_size、epochs | 864、25、0.00050.02、16128、10~60 | 同上 |
| XGBoost | n_estimators、max_depth、learning_rate、subsample | 50400、210、0.010.3、0.51.0 | 同上 |
| SVM | C、degree/epsilon | 0.120、25 或 0.01~0.5 | 同上 |
| RandomForest | n_estimators、max_depth、min_samples_split | 50400、320、2~10 | 同上 |
我还处理了一个比较现实的问题:并不是所有模型都适合在当前阶段启用所有优化器。如果某个模型没有配置搜索空间,系统不会直接报错,而是通过 optimization_note 和界面提示告诉用户"当前模型暂未配置搜索空间,已跳过优化"。这点看起来小,但它极大提升了系统的鲁棒性。
7. 系统运行流程与实验结果展示
为了让系统可以开箱即用,我额外加了 sample_data/ 目录和 generate_sample_data.py。这三个示例数据不是随便拼的,而是故意设计成既能演示分类/回归,又能覆盖缺失值处理和类别特征编码。
从当前生成结果来看,示例数据大致如下:
| 数据集 | 形状 | 任务 | 特点 |
|---|---|---|---|
| binary_classification.csv | 420 × 10 | 二分类 | 8 个数值特征 + 1 个类别特征 + 二分类目标,约 111 个缺失值 |
| multiclass_classification.csv | 480 × 8 | 多分类 | 6 个数值特征 + 1 个类别特征 + 三分类目标,约 99 个缺失值 |
| regression_demo.csv | 420 × 8 | 回归 | 6 个数值特征 + 1 个类别特征 + 连续目标,约 86 个缺失值 |
这里我专门做了两件事。
第一,我故意加入了类别型特征,比如 feature_9、feature_7,这样能测试 ColumnTransformer + OneHotEncoder 的分支逻辑。
第二,我故意注入了少量缺失值,这样系统的缺失值填补流程就不是摆设,而是真正在示例数据上发生作用。
整个训练流程,按系统实际逻辑可以概括成这样:
- 用户导入 CSV/Excel,或点击"加载示例数据"
- 系统读取 DataFrame,自动填充目标列下拉框
- 根据目标列类型给出任务建议
- 用户选择任务类型后,模型列表自动过滤
- 用户切换模型后,参数表单与搜索空间自动刷新
- 点击"开始训练"后,DataProcessor.fit_transform() 完成预处理
- TrainingWorker 在后台线程中执行训练
- 如果启用了优化,先跑基线,再做搜索,再训练最终模型
- 主界面收到训练完成信号后,更新指标表、报告文本、图表和模型比较表
- 用户可以保存模型,或加载新数据执行预测
预测流程则相对简单: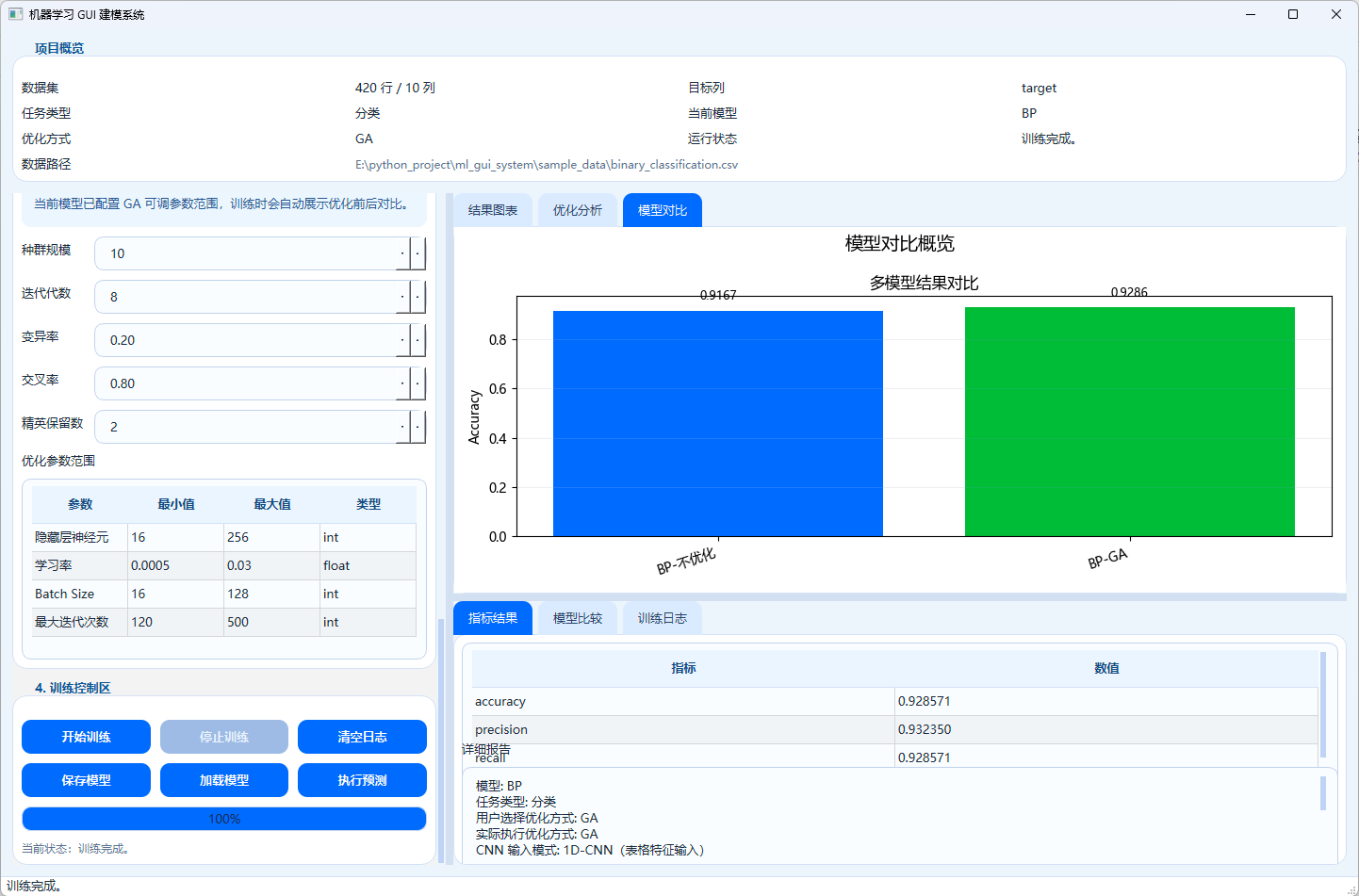
- 加载已训练模型和对应的 processor
- 读取待预测文件
- transform_features() 做同样的预处理
- 模型预测
- 把 prediction 列拼回原始数据
- 在对话框中预览,并可导出 CSV
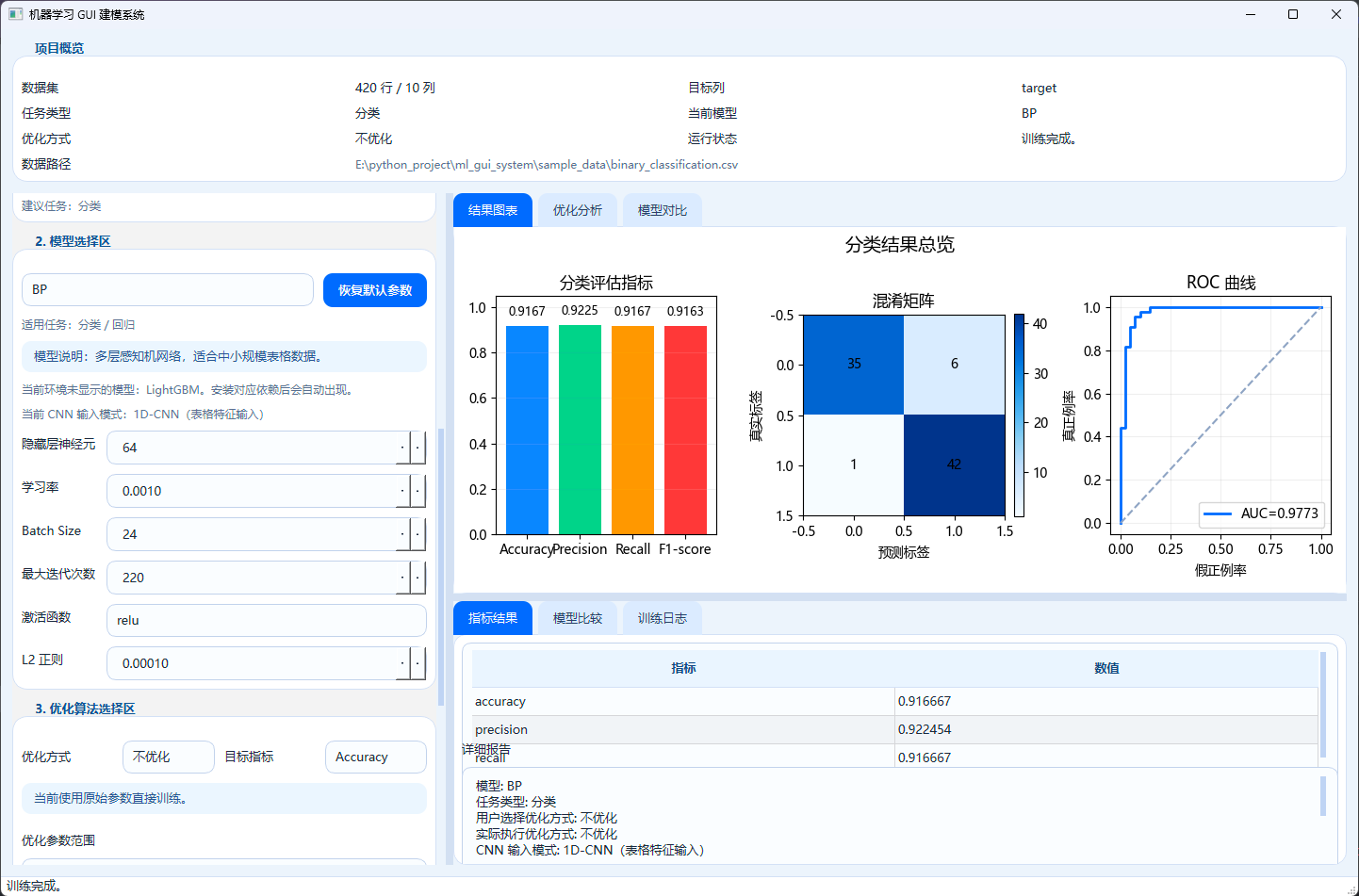
结果展示部分我也尽量做得"像系统,而不是像脚本"。utils/visualization.py 里我把结果图拆成了三类:
- 分类任务:Accuracy、Precision、Recall、F1、混淆矩阵、ROC
- 回归任务:MSE、RMSE、MAE、R²、真实值 vs 预测值、残差图
- 优化任务:优化过程曲线、优化前后对比图
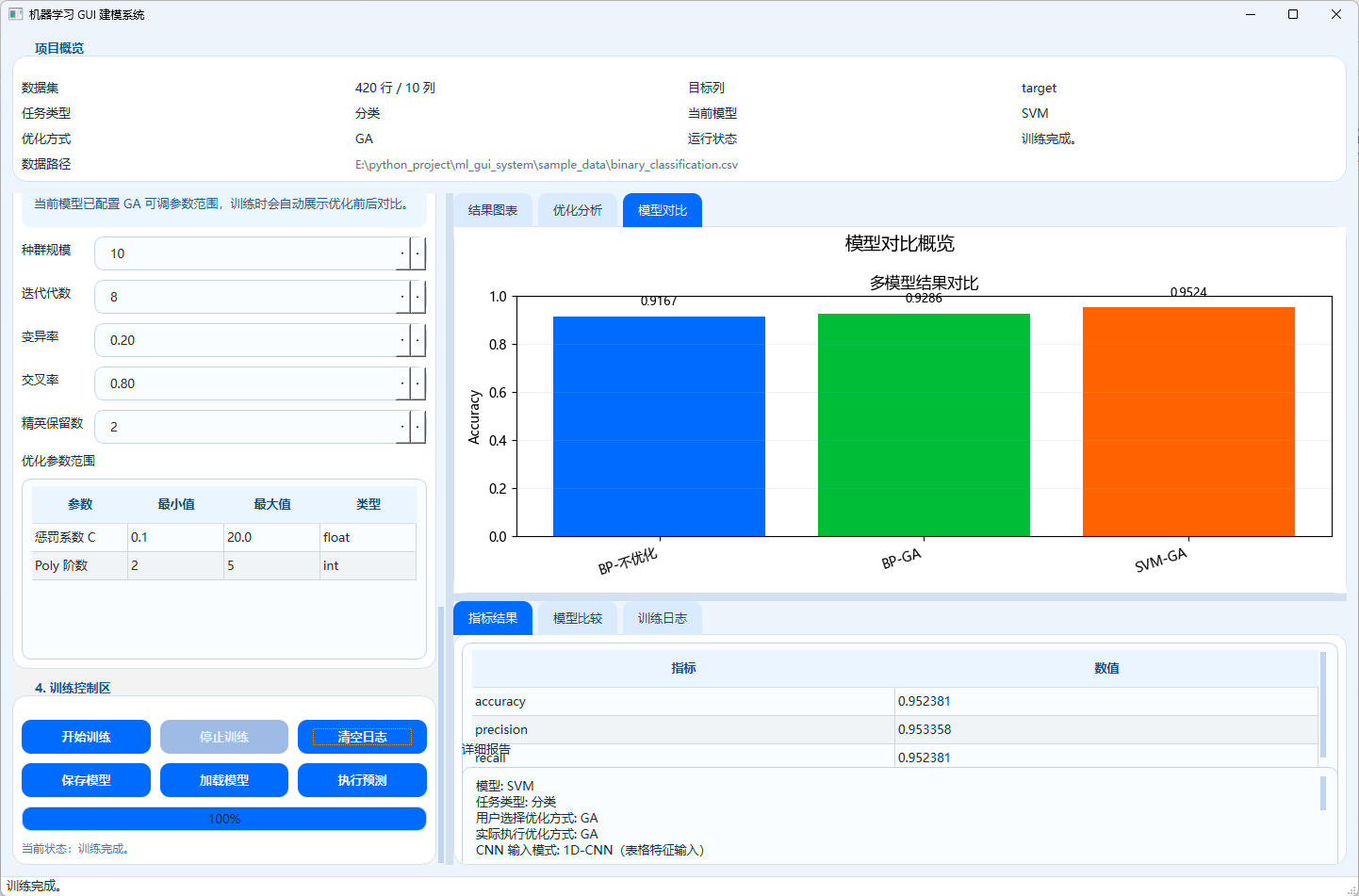
另外,ComparisonTable 会按任务类型生成结构化对比表,PlotTabWidget 则会在同一任务下累计生成模型对比柱状图。这说明这个系统不是"单次训练结果查看器",而是具备了初步的 多次实验对比能力。虽然目前对比结果只保存在内存里,但对演示来说已经足够实用。
8. 我在开发中遇到的关键问题
8.1 GUI 不能被训练过程卡死
这是我最早遇到的问题。只要把模型训练和 GA 搜索直接丢进主线程,界面就会立刻"假死"。所以我最终把训练逻辑放进了 TrainingWorker(QObject),再移动到 QThread 中运行。主界面只负责发起任务、接收信号和刷新结果。
这个决定的直接收益是:即便 CNN 训练多个 epoch,或者 GA 评估多个候选参数,界面仍然能响应停止按钮、进度条和日志刷新。
8.2 多模型接口不统一
如果每个模型都各写一套 fit/predict/save/load,主窗口很快就会充满分支逻辑。我后来用 BaseModel + SklearnBaseModel + ModelFactory 把这部分统一掉了。这样无论是 LogisticRegression 还是 RandomForest,主线程看到的都是同一套接口。
这件事的价值,不只体现在"代码优雅",更体现在扩展成本上。因为后面我新增模型时,主窗口几乎不需要改。
8.3 不同模型的输入格式不一样
BP、SVM、RF、XGBoost 这类模型喜欢二维表格输入;CNN 则要求 batch, channel, feature_dim。我没有让数据层去迁就某一个模型,而是让 DataProcessor 统一输出标准二维特征,再由 CNNModel 自己在 fit() 和 predict() 里做 unsqueeze(1)。
这是一种很典型的工程分层思路:数据层负责"通用预处理",模型层负责"特定输入重排"。
8.4 参数面板不能写死
如果参数控件全部写死在界面里,模型一多就会非常难维护。我后来把参数 schema 全部收到了 config.py,再用 ParameterFormWidget 动态渲染。这个改动虽然不涉及算法,但实际上是整个系统扩展性的关键。
8.5 依赖不完整不能让系统直接崩
这也是做桌面系统时很现实的问题。比如别人下载你的项目,未必第一时间就装好了 torch、xgboost、lightgbm。如果启动就报 ImportError,体验会很差。所以我在 ModelFactory 里做了动态装配和不可用原因记录,界面上则只显示当前环境真正可用的模型。
8.6 优化过程太耗时
GA 的本质决定了它会反复训练模型,这在桌面端尤其要小心。我做了几件事来控制成本:
- 优化只在训练集内部再拆一个验证集,不重复动测试集
- 搜索空间尽量收敛,不追求夸张的大范围
- 对没有搜索空间的模型直接优雅跳过
- 训练失败的候选参数直接记为差分数,不让整个优化中断
这些策略让系统在"能演示"和"别太慢"之间找到了一个平衡。
9. 项目可改进方向
从当前代码来看,这个系统已经能完成完整的表格建模闭环,但如果我要继续往下做,我最想改进的方向有这几个:
| 改进方向 | 当前状态 | 后续思路 |
|---|---|---|
| 2D-CNN 图像支持 | 仅有输入模式提示,没有真正图像管线 | 增加图像目录加载器与 2D 卷积分支 |
| LightGBM | 已有模型文件,依赖可选 | 正式加入 requirements 可选安装说明 |
| 贝叶斯优化 | 还未实现 | 在 optimizers/ 下新增统一接口 |
| 交叉验证 | 当前优化用单次验证集 | 引入 KFold / StratifiedKFold |
| 实验记录 | 只有日志与内存中的比较结果 | 增加结果持久化与实验报告导出 |
| 配置管理 | 当前用 Python 字典 | 后续可迁移到 YAML / JSON |
| 自动测试 | 当前没有测试脚本 | 为数据处理、模型工厂、优化器补单元测试 |
如果我继续做这个项目,我会优先做三件事:第一是补完整的图像数据工作流,第二是补实验管理,第三是把配置从 Python 常量表升级成外部可维护配置文件。这样项目就会从"一个完整的课程设计"进一步走向"一个更像产品原型的工具"。
需要源代码的,请联系作者,制作不易,请各位看官老爷点个赞!!!