一、项目介绍
本项目是一个基于 Text-CNN 的中文文本情感识别 Web 应用,采用前后端分离架构:后端使用 Flask 构建 RESTful API,模型侧采用 TensorFlow/Keras 实现的 Text-CNN 卷积神经网络,前端支持跨终端访问与交互。
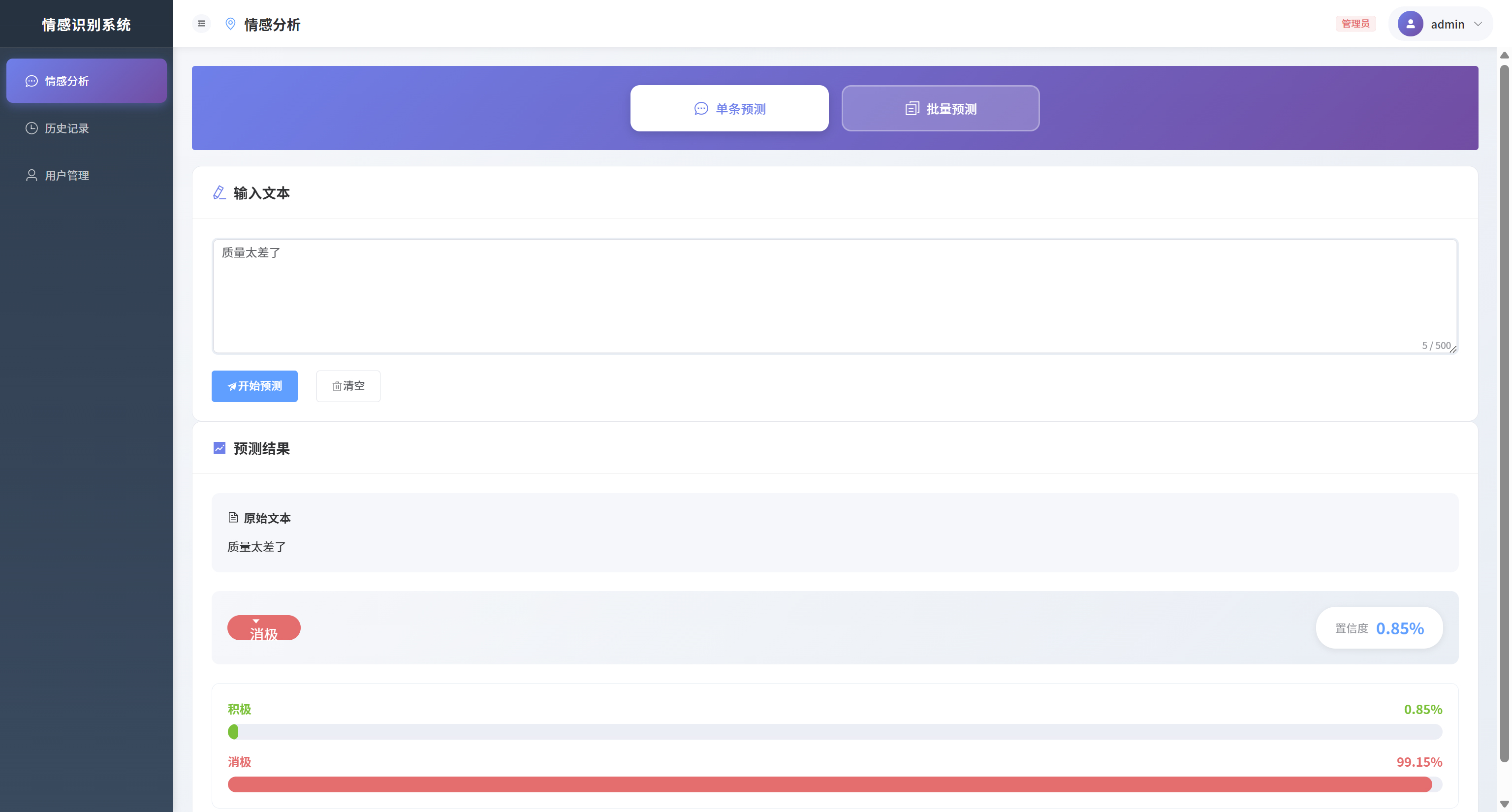
系统核心能力覆盖用户注册登录、JWT 身份认证、中文文本情感分析、批量预测与历史记录管理等模块。文本预处理使用 jieba 分词,将分词序列输入训练好的 Text-CNN,对情感进行二分类(积极/消极),并输出置信度用于可视化展示。权限方面支持普通用户与管理员角色,并基于 RBAC 控制接口访问范围,降低越权风险。数据层使用 SQLite 存储用户与预测历史,配合 Flask-Migrate 管理数据库版本,提升后续迭代与部署的可维护性。

二、选题背景与意义
互联网与社交媒体产生了海量用户生成文本,其中蕴含丰富的情感倾向信息,对产品设计、运营策略与舆情管理具有参考价值。完全依赖人工标注与阅读不仅成本高,而且难以覆盖大规模、实时性要求高的分析任务。自动化情感识别能够把文本快速映射为「积极/消极」及置信度,为评论分析、客服质检与舆情监控提供基础能力。本系统在工程上验证 Text-CNN 在中文情感二分类中的可用性,并强调可扩展的数据库与权限体系,便于后续引入更多标签体系或更强的预训练语言模型。
从研究与应用角度看,探索卷积结构在中文文本上的特征抽取规律,有助于理解「局部 n-gram 模式」与情感极性之间的关系;从业务角度看,系统可服务于电商评论、舆情监控与客户反馈等场景,为运营与产品迭代提供可量化的文本侧信号。
三、关键技术栈:text-cnn
Text-CNN 的典型结构包含嵌入层、卷积层、池化层与全连接层。嵌入层将分词映射为稠密向量,捕获词语语义;卷积层使用多种窗口尺寸(如 3、4、5 个词)提取局部 n-gram 模式;池化层采用最大池化从每个卷积通道中抽取最强响应,压缩维度并突出关键情感线索;全连接层整合特征后经 Softmax 输出类别概率。该结构训练并行度高、实现相对轻量,适合作为中文情感分析的基线方案。
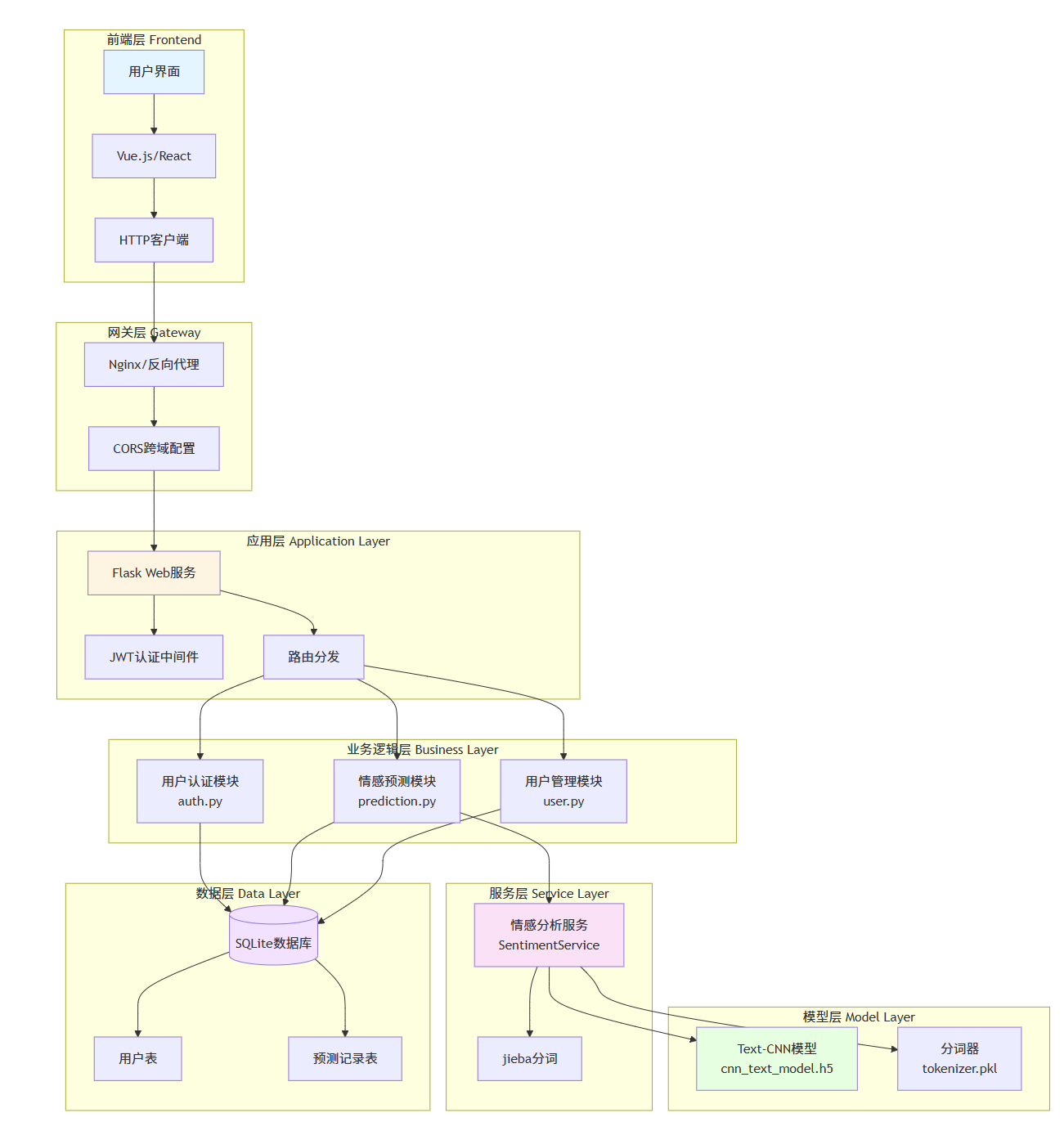
四、技术架构图
五、系统功能模块图