大模型与多模态 AI 的竞争,本质是高质量数据的竞争。再强的模型、再聪明的智能体,如果没有精准、一致、场景化的标注数据,也无法落地、迭代和进化。高质量标注数据不再是单纯的"燃料",而是决定模型上限的战略资产。
然而,传统标注模式面临三重困局:
-
效率瓶颈:纯人工标注无法跟上模型快速迭代的节奏
-
质量参差:多模态、细粒度任务依赖大量专家经验,一致性难保障
-
闭环断裂:标注平台与模型训练流程割裂,数据无法反哺模型优化
-
工具分散:多模态(图像 / 文本 / 音频 / 视频)工具分散、流程割裂
天纪标注平台TLP 正是面向大模型时代打造的全模态、智能化、可自定义的 AI 数据生产基础设施。它承担着把 "原始数据" 变成 "训练养料" 的核心使命,为模型训练、指令微调、智能体任务执行,提供从标注、质检、管理到回流的全链路能力。
有了标注平台,标注不再是体力活儿,而是AI产业链的核心生产力。
一、背景:为什么需要数据标注?
原始数据(文本、图片、音频、视频)对机器来说是无意义的乱码 ,只有经过标注,把人类的认知、规则、意图 "翻译" 给机器,AI 才能学会识别、理解、判断、执行任务。数据标注就是给 AI 贴标签、划边界、定类别,相当于教 AI "认东西",这是所有 AI 模型能跑起来的基础。
而高质量标注,是 AI 从可用到好用的核心基础。
二、天纪标注平台TLP介绍
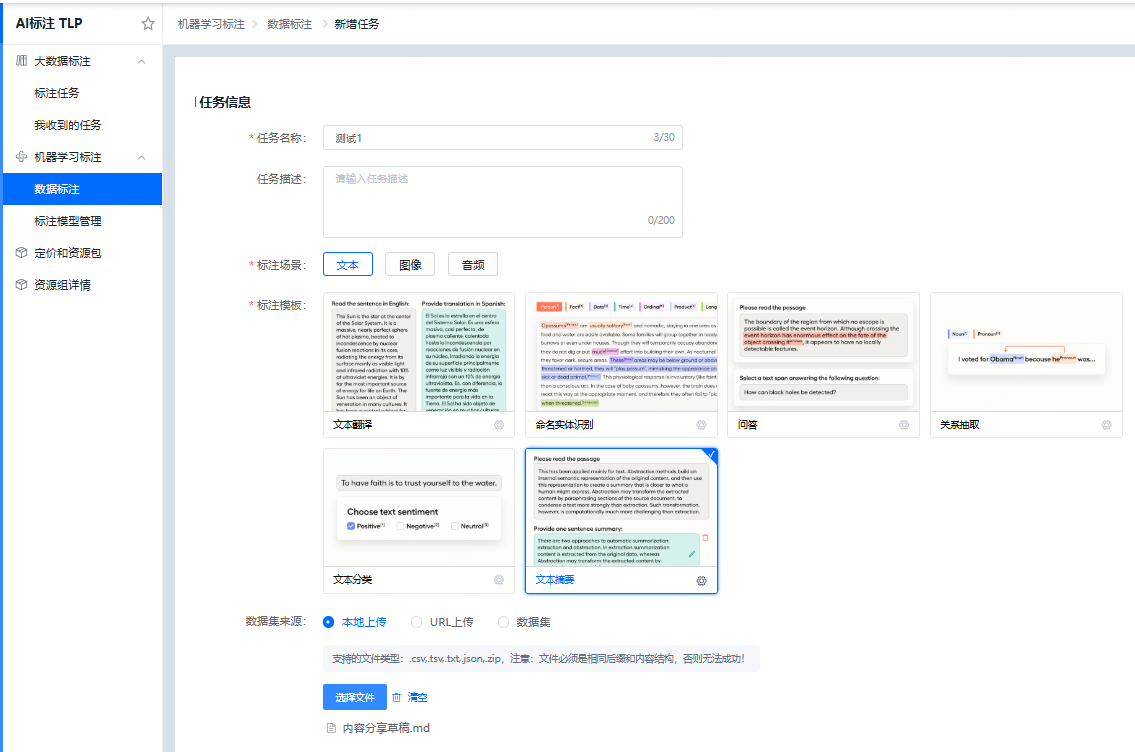
天纪标注平台TLP,支持大模型、传统机器学习数据集的标注,包含图像、文本、视频、音频等多种数据类型的标注。内置丰富的标注模版,并提供大模型自动化标注功能,帮助用户更好的完成标注工作。
三、标注平台升级:从"人工打标"到"人机协同"
1、一键AI标注
大模型时代,标注效率的天花板由AI预标决定。TLP全面接入领先的多模态大模型与自研垂直小模型,覆盖:
-
文本类:实体识别、关系抽取、文本分类、情感分析
-
图像类:目标检测、语义分割、关键点、图像描述
-
语音类:ASR转写、意图分类、情感识别、语种区分
基于先进的大语言模型与多模态AI技术,平台全面升级"预标注+人工复核"工作流。
用户点击AI标注后,系统即可自动完成标注,覆盖文本类、图像类、语音类标注的主流任务。标注效率最高可提升70%以上,实现"AI打底、人工精修"的高效协同模式,大幅降低标注成本。
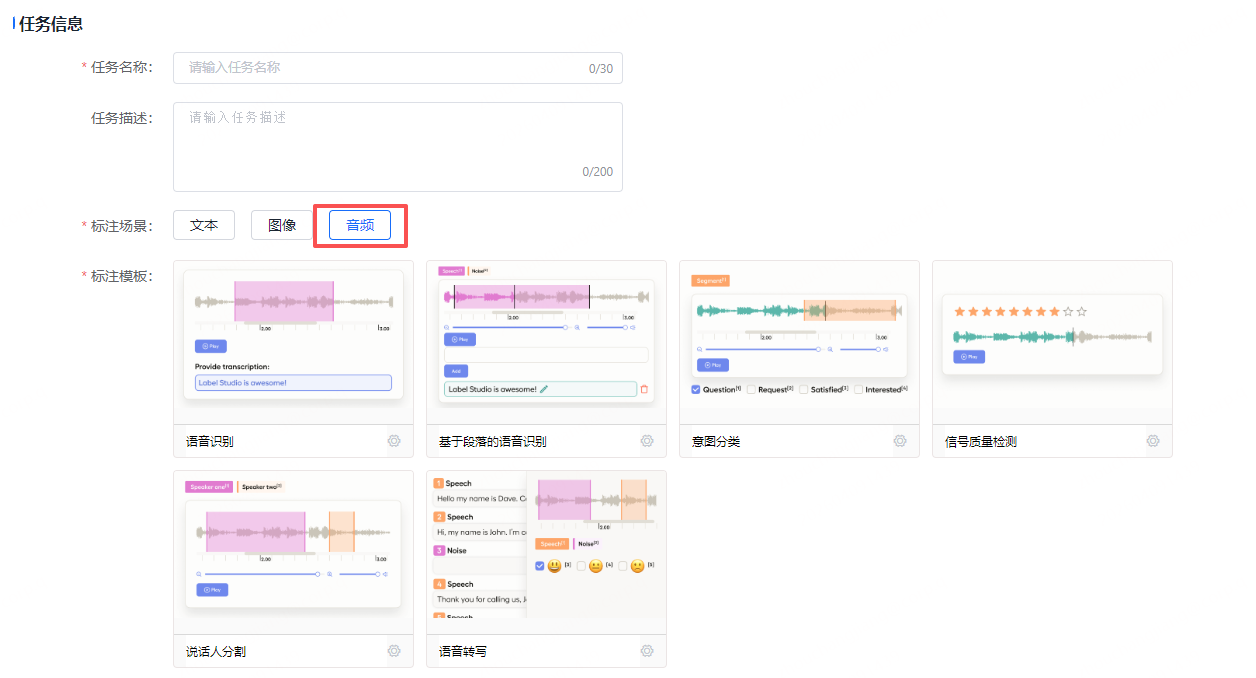
2. 音频标注
全新音频模块不仅支持传统ASR标注,更深度适配语音大模型预训练 与智能交互系统的精细化需求:
-
多任务支持:说话人分离与归并、副语言事件标记(笑声/呼吸/停顿)、声学场景分类、信号质量评分
-
智能预处理:内置降噪、去混响、增益均衡算法,在嘈杂环境、多方言、重叠语音等挑战场景下仍能清晰判听
-
无缝对接训练:导出格式兼容Kaldi、ESPnet、Whisper、Riva等主流框架,直接用于客服质检、会议转写、车载语音等场景的模型微调
3. 标注模型自定义
专业用户再也不怕通用模型不懂业务术语了!
TLP开放模型自定义能力------不再是被动的标注工具使用者,而是标注AI的共建者。用户可以引入热门的开源模型,可自己训练模型并应用到标注中。
不同的项目可独立维护专属标注模型,灵活切换、按需部署,真正打造贴合企业场景的"专属AI标注大脑"。
四. 为什么选择天纪标注平台TLP
| 需求维度 | TLP产品能力 |
|---|---|
| 效率 | AI预标+人工精修,70%+效率提升;支持标注规则自动生成、快捷键批量操作 |
| 质量 | 多人协同+仲裁机制;帧级对齐精度;质量检测自动抽检与异常预警 |
| 数据安全 | 私有化部署可选;数据不出域;支持角色级权限与操作审计 |
| 与训练集成 | 导出格式即训练格式(COCO、JSONL、TFRecord等);支持将标注结果直接回传至MLOps流水线 |
| 自定义能力 | 模型、标签体系、工作流、质检策略均可按需定制 |
此次新版升级,天纪数据标注TLP以更智能的AI预标能力、更专业的多模态编辑体验与更开放的模型自定义生态,全面重塑AI数据生产Pipeline。无论是算法团队快速验证,还是企业级大规模数据治理,均可实现高质量、高效率、高一致性的标注交付。
立即体验天纪TLP,让您的数据标注从"成本中心"变为"价值引擎": https://zyun.360.cn/product/tlp