编者按: 你是否曾好奇,当我们向大语言模型输入一段文字、看着它逐字逐句生成回复时,背后那些动辄千亿参数的神经网络究竟在"计算"什么?它们又是如何在短短几秒内完成如此复杂的推理过程?
我们今天为大家带来的文章,作者的观点是推理引擎的价值不仅在于调度,更在于通过重写模型代码与深度优化底层计算逻辑,将静态的权重转化为高效的智能输出。
作者 | Neutree AI
编译 | 岳扬
01 模型内部机制、KV Cache 与张量并行(Tensor Parallelism)
在 Part 1 中,我们探讨了 Nano-vLLM 的工程架构:请求如何在系统中流转、Scheduler(调度器)如何对 sequences(序列)进行批处理,以及 Block Manager(块管理器)如何追踪 KV Cache 的分配。当时我们特意将模型计算视为一个黑盒。现在,是时候打开这个盒子了。
本部分将深入探究模型内部原理:Token(词元)如何转化为向量、每个 decoder 层内部究竟发生了什么、KV Cache 在 GPU 显存中的物理存储方式,以及张量并行如何将计算任务拆解到多个 GPU 上。 阅读完本节,你将对从 Prompt 进入系统到文本生成输出的全过程建立起完整的认知。
02 模型究竟是什么?
说到"模型",我们往往想到的是那些权重文件 ------ 动辄数十亿参数、体积庞大的二进制文件。但一个真正能跑起来、能做推理的模型,其实需要三个部分协同工作:
- Vocabulary:token 和其对应 ID 之间的静态映射表。它负责在人类可读的文本与模型实际处理的数值表征之间做双向翻译。
- Weights:训练过程中学出来的参数,也就是模型积累的"知识"本身。比如一个 7B 模型,就代表它拥有 70 亿个这样的可调参数。
- Runtime Code:定义如何使用这些权重、把输入一步步转换成输出的执行逻辑。这才是真正落到 GPU 上跑起来的部分。
2.1 为何推理引擎要自己实现模型代码(model code)
你可能会疑惑:既然模型提供方都开源了权重,为什么不干脆把 runtime code(运行时代码)也一起给了?其实很多情况下他们确实给了,但问题是,这份代码往往不是"开箱即用"的。Runtime code 需要针对具体场景做深度优化:训练还是推理?用什么型号的 GPU?跑 FP16 还是 INT4 精度?在一套 A100 集群上训练效果出色的代码,放在单个消费级 GPU 上做推理可能就不那么理想了。
这正是 vLLM 这类推理引擎选择自己重写 model code 的原因。完整的 vLLM 代码库包含了对数十种模型架构的优化实现,涵盖 Qwen、LLaMA**、DeepSeek、Mistral 等。Nano-vLLM 则做了简化,仅支持 Qwen 模型,但背后遵循的工程模式和优化思路,其实是通用的。
03 模型 pipeline
现在,我们来追踪一个 token(词元)在模型中的完整流转过程。
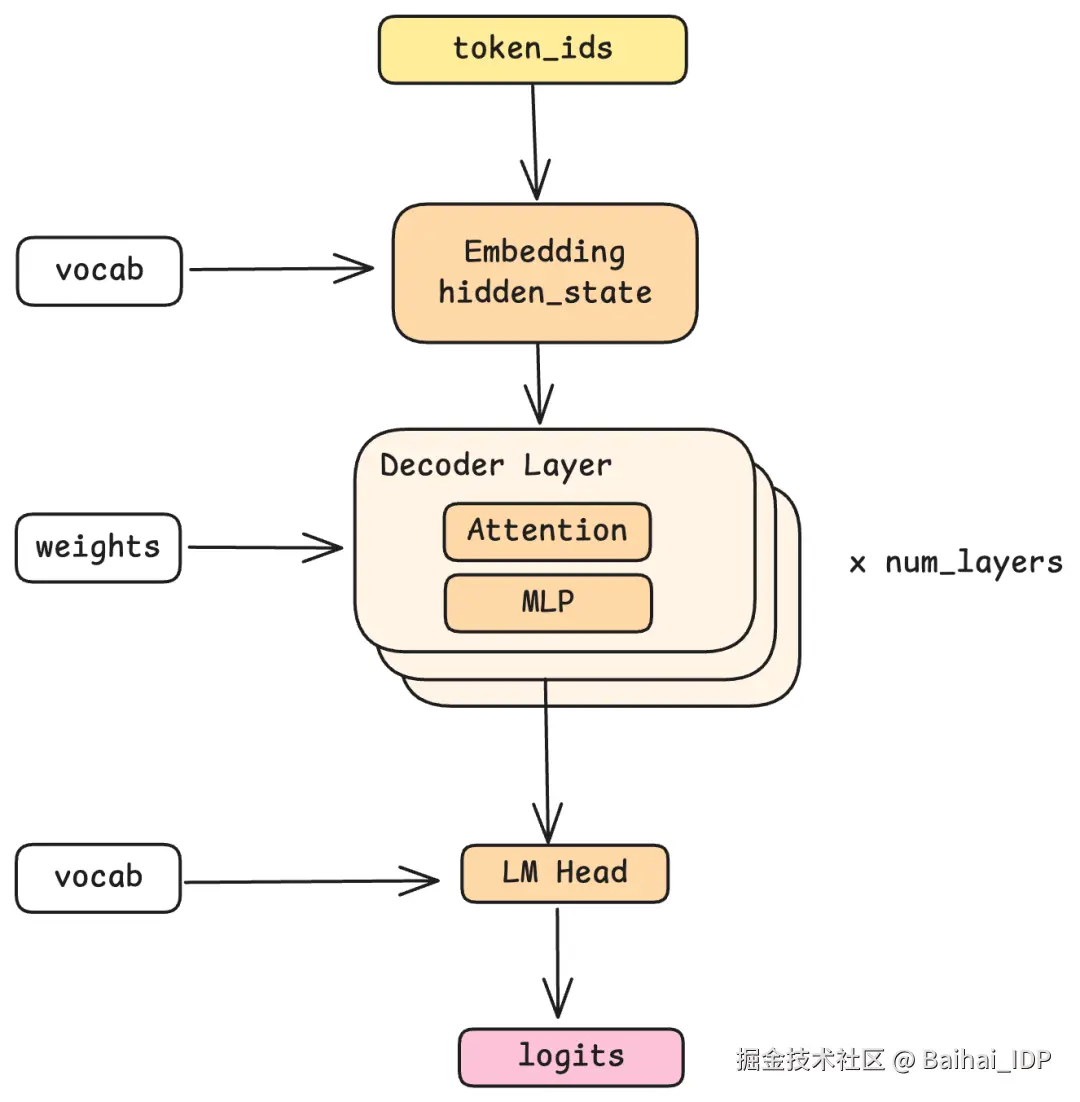
3.1 Embedding:从 Token 到向量
旅程始于 embedding。token ID 不过只是一个数字,比如 1547。嵌入层(embedding layer)在词表中查找这个 ID,并检索出一个向量:一个高维的浮点数数组(Nano-vLLM 使用的 Qwen 模型中为 4096 维)。这个向量被称为隐藏状态(hidden state),是模型对该 token 的内部表征。
为什么是 4096 维?这是一个在表达能力与计算成本之间做了一番权衡的设计选择。更多的维度可以捕捉更细微的语义,但需要更多的计算量和显存占用。
3.2 Decode Layers:魔法发生的地方
随后,隐藏状态(hidden state)会流经一叠解码层,Nano-vLLM 支持的 Qwen 模型共有 24 层。每层执行相同的操作,但使用不同的学习权重,逐层对表征进行精细化加工。不妨这样理解,每一层都在前一层的基础上,让模型对输入的理解再深一度:也许某一层捕捉句法关系,另一层捕捉语义含义,还有一层处理事实知识。(实际上,每一层具体学到什么,是训练过程中自然涌现的结果,并非预先设计。)
这里的关键特性在于:每一层接收的是隐藏状态,输出的也是隐藏状态,而且 shape 始终保持不变(4096 维)。这种统一性使得层与层之间可以堆叠。
3.3 LM Head:从向量回到 Token
经过所有解码层之后,最终的隐藏状态被转换回词表上的概率分布。这是 LM Head(语言模型头)的工作,其功能可以视为嵌入过程的逆向操作。输出是 logits,即对每个可能的下一个 token 的打分,后续的采样环节再根据这些分值,最终选出实际输出的词元。
04 解码层(Decode Layer)的内部构造
每个解码层都包含两大核心模块:注意力机制(Attention)和多层感知机(MLP)。下面我们逐一拆解。
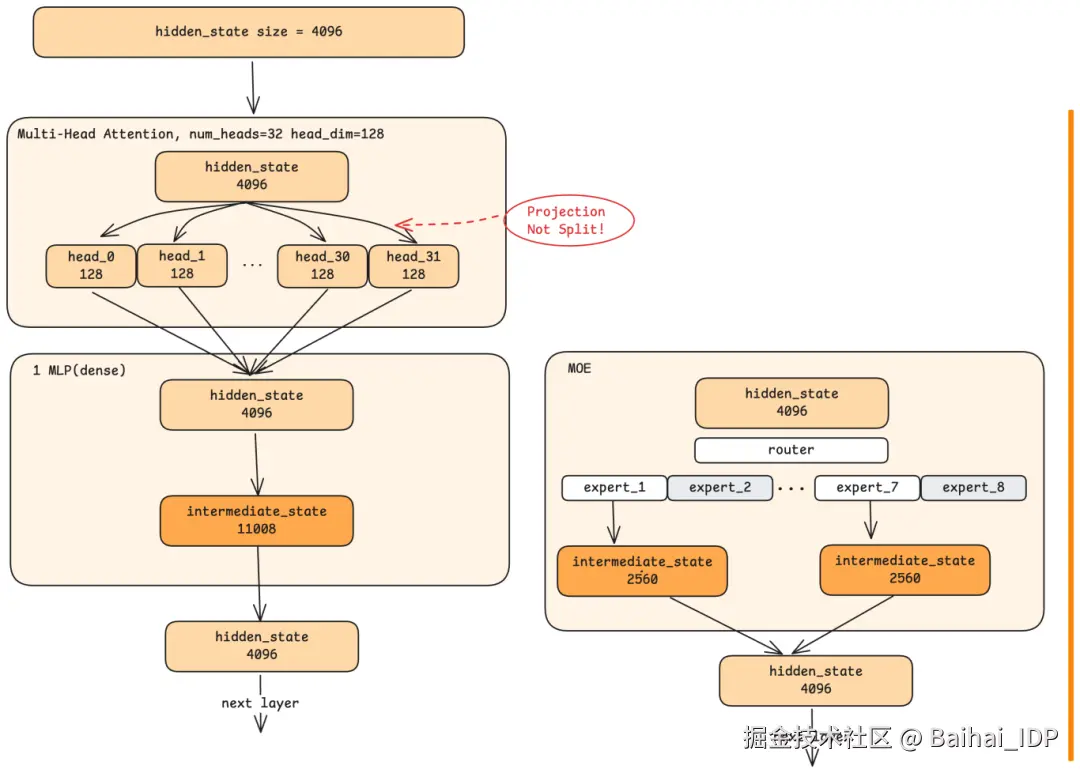
4.1 多头注意力机制(Multi-Head Attention)
注意力机制让每个 token 能够"关注"序列中的其他 token。但现代 LLM 并不使用简单的注意力机制。它们使用多头注意力机制(multi-head attention),将注意力计算拆分到多个并行的"heads"中。
在 Qwen 模型中,共有 32 个 heads,每个处理 128 维的切片(32 × 128 = 4096,即完整的 hidden state 大小)。这不仅仅是把 4096 维切分成 32 组。相反,每个 head 执行一次投影(projection),这是一种通过学习得到的变换方式,将完整的 4096 维输入压缩成该 head 特有的 128 维表征。
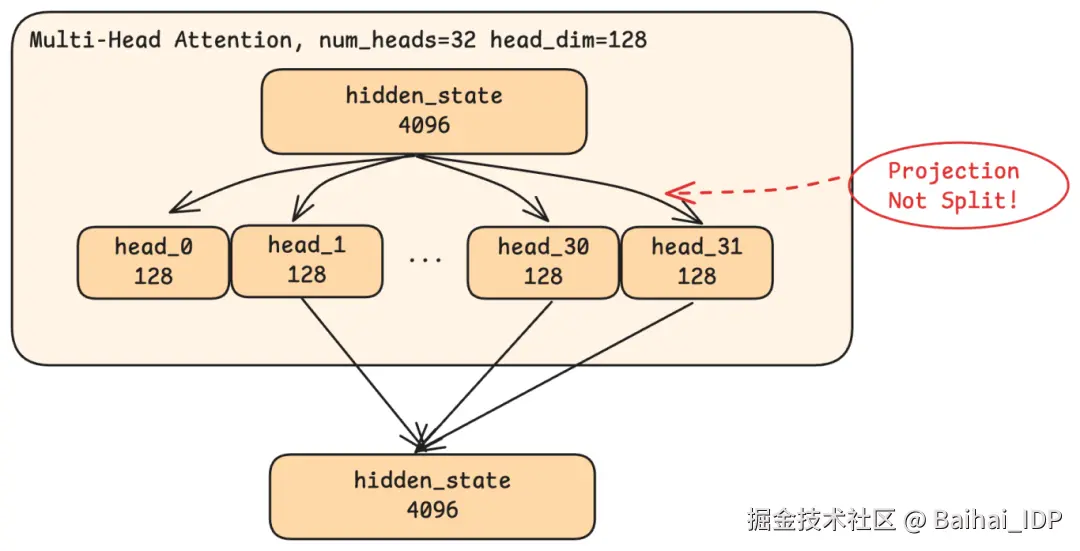
可以把它想象成一个工厂,装配线上有 32 个专用工作站。每个工作站接收相同的原材料(完整的 4096 维输入),但使用不同的工具将其塑造成特定形状。一个工作站可能负责"修剪"语法适配度,另一个负责"打磨"语义连贯性,还有一个负责"测量"位置对齐度。但实际上,每个工作站学到什么也是在训练中自然涌现出来的,未必能如此清晰地划分。
每个 head 还参与真正的注意力机制:它计算当前 token 应该关注序列中每个先前 token 的程度。模型就在这里捕捉上下文(context),理解在"The cat sat on the mat. It was comfortable."中,It 指的是"the cat"。
所有 heads 完成计算后,它们的输出被拼接(concatenated)并投影(projected)回 4096 维,生成该层的注意力机制输出。
4.2 MLP:自我优化
MLP(Multi-Layer Perceptron)阶段接收注意力机制的输出并进一步优化。与注意力机制不同,MLP 不看其他 token。它独立处理每个 token 的 hidden state(隐藏状态)。
MLP 首先将 hidden state 从 4096 扩展到一个更大的中间维度(intermediate dimension)(Qwen 中为 11008),应用非线性激活函数,然后压缩回 4096。为什么要这样扩展和压缩呢?
可以把它想象成提升分辨率。4096 维的 hidden state 就像一张压缩图像。扩展到 11008 维就像上采样(upscale):它创造了可添加细节的空间,这些细节由 MLP 的学习权重决定。再压缩回 4096 则是对这种经过信息增强后的表征(enriched representation)的提炼。通过这个过程,模型将训练中的知识融入每个 token 的表征中。
4.3 Dense 架构与 MoE 架构的对比
我们刚才描述的 MLP 是一种 dense 架构:每个 token 都经过同一个 MLP(多层感知机)模块处理。但有些现代模型使用 Mixture of Experts (MoE)这种不同的思路。
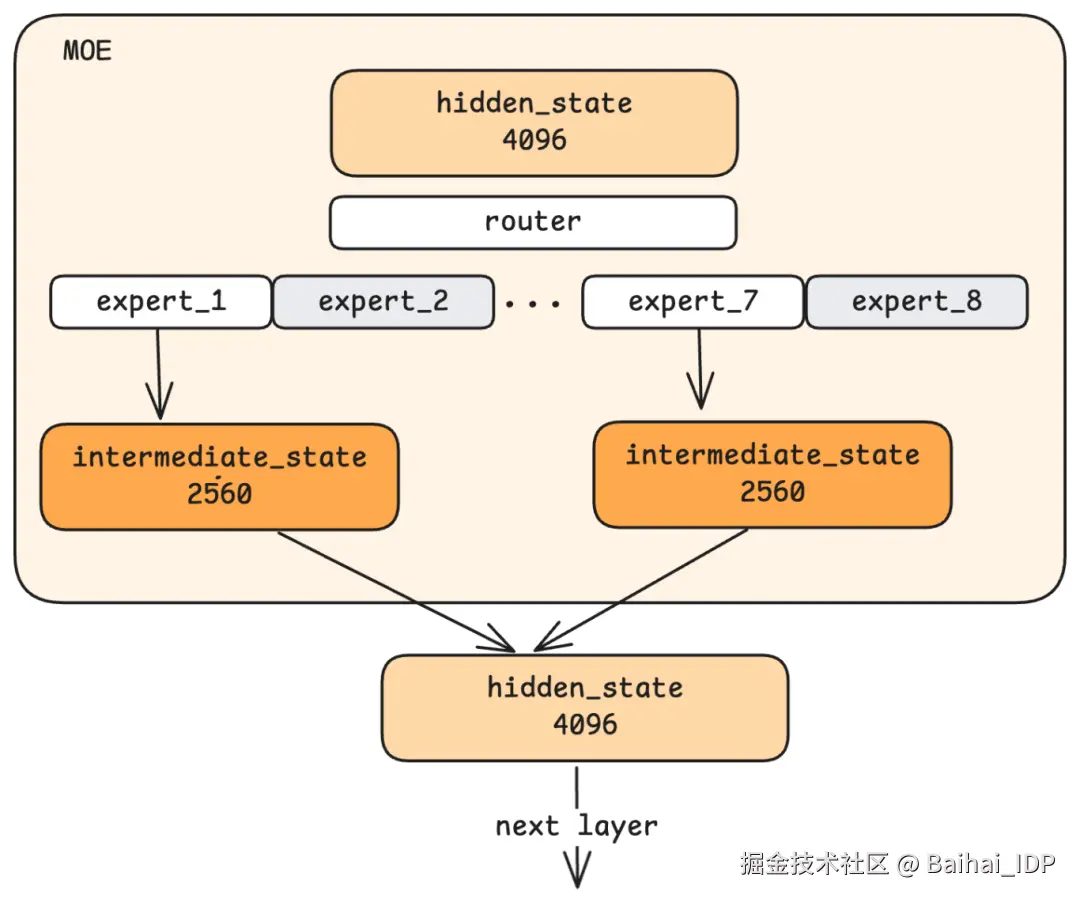
在 MoE 中,不是用一个大型 MLP,而是有多个小型"expert" MLPs,比如 8 个。由一个路由网络(router network)负责检查每个输入的 hidden state,并决定由哪些 experts(专家)来处理它。例如,对于任何给定 token,只激活 8 个中的 2 个 experts(专家)。
"expert"这个叫法容易让人联想到这样的专业分工:一个专家负责数学,另一个负责语言,还有一个负责编写代码。实际上,每个 expert 学到什么也是从训练中涌现的,并非经过明确设计。我们很难说清楚 Expert 3 与 Expert 5 有何不同。
那为什么要用 MoE?主要动机是计算效率(computational efficiency),而不是输出质量(output quality)。 有了 MoE,你可以拥有一个总参数量很大(所有 experts 合计)的模型,同时每个 token 只激活其中一部分参数。这大幅减少了每个 token 的计算量。
这部分进行了权衡考量:给定相同的总参数量,dense 模型通常会产生比 MoE 模型更高质量的输出,因为 dense 模型对每个 token 都使用了所有参数。但超大规模下的 dense 模型训练起来计算成本高得令人望而却步。MoE 允许扩展到 dense 架构无法实现的参数量,接受每个参数的效率(per-parameter efficiency)稍低一些,以换取实际的可训练性(practical trainability)。
05 KV Cache:数据平面
在第一部分中,我们将 Block Manager 讨论为 KV 缓存的控制平面,负责在 CPU memory 中追踪分配状态。现在让我们聚焦数据平面:KV 缓存究竟是如何实际存储在 GPU memory 中的。
5.1 什么被缓存了
在 Attention 计算过程中,每个 token 产生两个向量:K(key)和 V(value)。它们用于与后续 token 计算 Attention 分数。为了避免在每一步 decode 时都重新计算所有先前 token 的 K 和 V,我们选择将它们缓存起来。
5.2 物理布局
GPU 上的 KV cache 被组织为一个多维结构:
- Block 维度:与 Block Manager 的逻辑块对应(例如,每块 256 个 token)
- Layer 维度:24 个解码层每层都有自己的缓存,因为注意力是在每一层独立计算的
- K/V 维度:每层两个独立的缓存,一个存 key,一个存 value
- Token 维度:在每个块内,为每个 token 的缓存向量预留空间
因此,Block Manager 中的一个逻辑块对应 GPU 上 24 × 2 = 48 个物理缓存区域:24 层每层各一个 K 缓存和一个 V 缓存。
5.3 用于缓存访问的 Triton Kernel
Nano-vLLM 不直接通过 CUDA API 操作 GPU 内存,而是使用 Triton Kernel ------ 一种高级 GPU 编程语言,编译为高效的 CUDA 代码。这些 Kernel 处理从 KV cache 的读写操作,将 GPU memory 管理的底层复杂性封装起来,让上层逻辑更简洁清晰。
06 张量并行(Tensor Parallelism):计算层面
在第一部分中,我们介绍了张量并行的通信模式,以及 leader 如何通过共享内存(shared memory)广播命令。现在来看看实际计算是如何拆分到各 GPU 上的。
6.1 Attention 中的并行
以 TP=2(两张 GPU)为例。当一个隐藏状态进入 Attention 阶段时:
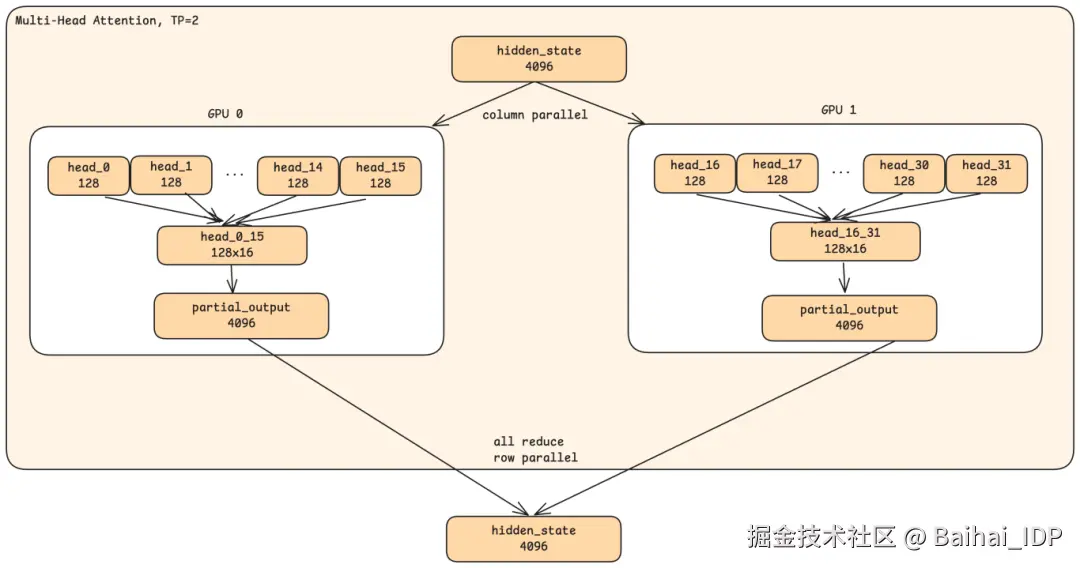
1)两张 GPU 都接收完整的隐藏状态(4096 维)。这里没有拆分,每张 GPU 都拥有完整的输入。
2)每张 GPU 负责处理一半的 head(注意力头)。GPU 0 处理 head 0-15;GPU 1 处理 head 16-31。
3)每张 GPU 产生部分输出。GPU 0 的输出只包含 head 0-15 的信息;GPU 1 的输出只包含 head 16-31 的信息。
4)通过 All-reduce 合并结果。两张 GPU 交换各自的部分输出并求和,这样两者最终都得到完整的 Attention 输出。
并行发生在 head(注意力头)维度,而非隐藏状态维度。每张 GPU 都看到完整的输入,但只计算分配给它的一部分 head。
6.2 MLP 中的并行
MLP 并行遵循类似的模式:
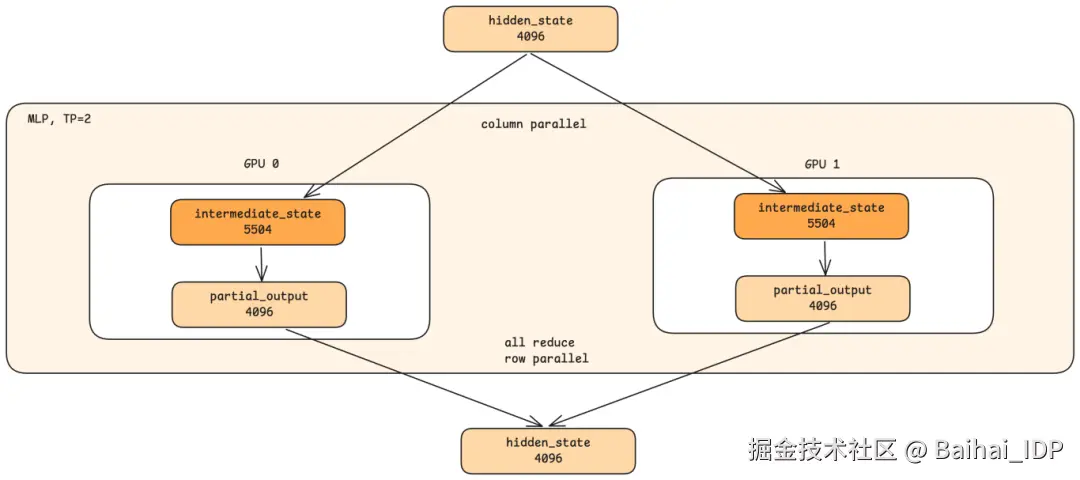
1)两张 GPU 都接收完整的隐藏状态。
2)中间维度(intermediate dimension)被拆分。如果 MLP 层扩展到 11008 维,每张 GPU 计算 5504 维。
3)每张 GPU 产生部分输出。
4)All-reduce 合并结果。
6.3 通信的开销
张量并行并非没有开销。All-reduce 操作需要 GPU 之间进行通信,这会增加延迟。这就是为什么 TP 在单机多 GPU 且具备高速互联(如 NVLink)的场景下最有效,而在通过网络连接的机器之间使用时,通信延迟会成为主导因素,效果就会大打折扣。
它的优势在于:每块 GPU 只需存储模型权重的一部分(TP=2 时存储一半,TP=8 时存储八分之一)。这使得我们能够运行那些单个 GPU 内存装不下的模型。
07 思考:设计上的权衡取舍
在了解了内部机制之后,让我们来探讨一些常见的设计问题。
7.1 网络层(Layers)数与注意力头(Heads)数分别控制什么?
更多的网络层数通常意味着更深的推理能力。每一层都会对隐藏状态进行一次额外的细化处理。 更多的注意力头数则支持更丰富的注意力模式(attention patterns),为理解词元之间的关系提供更多"视角"。
我们能否为特定的深度推理任务创建一个"窄而深"的模型(注意力头数少、网络层数多)?或者为了覆盖更广的知识而创建一个"宽而浅"的模型(注意力头数多、网络层数少)?研究表明,这种做法的效果并不理想。就像人类学习一样,模型似乎也需要在广度与深度之间取得平衡。极端不平衡的架构往往表现不佳。大多数成功的模型在这些维度之间保持着一个大致均衡的比例。
真正能撬动模型能力的实用杠杆,仍然是训练数据(有哪些知识可用)和训练方法(这些知识能被多有效地习得),而不是追求极端的架构设计。
7.2 为什么 MoE 架构越来越流行?
混合专家模型(MoE)架构的兴起,并非因为它在单位参数下能产出更优的结果。事实恰恰相反:一个 70B 的稠密模型,通常表现会优于同参数量(所有专家参数之和)的 MoE 模型。
MoE 受欢迎,是因为它让规模扩展成为可能。 用当前基础设施训练一个 600B 的稠密模型,计算成本高到难以承受。但一个总参数量 600B、每词元仅激活 50B 参数的 MoE 模型呢?这个是可以训练出来的。尽管单位参数的效率有所损失,但凭借其庞大的总体规模,它可以达到的能力,是任何可训练的稠密模型都无法企及的。
这是一种务实的工程权衡:以单位参数效率的适度下降,换取触及原本无法达到的模型规模。
08 结语
至此,我们已经完整梳理了从输入提示词到生成文本的整个流程:
- Tokenization 将文本转换为 token ID
- Embedding 将 token ID 映射为隐藏状态向量
- Decode layers 通过 Attention(跨词元理解)和 MLP(知识整合)不断细化隐藏状态
- KV cache 缓存中间 Attention 结果,避免重复计算
- LM head 将最终隐藏状态转换为 token 概率分布
- Sampling 从概率分布中选择输出 token
- Tensor parallelism 让上述所有步骤得以在多张 GPU 间扩展
推理引擎负责统筹整条流水线 ------ 从请求调度、内存管理,到协调并行执行;而模型架构则定义了每个步骤内部的具体计算逻辑。
理解这些内部机制,能让看似"魔法"的过程变得清晰可解。大语言模型的本质,其实是一个精密的函数:输入向量,输出向量。所谓的"智能",源于参数规模的积累、训练数据的质量,以及让这一切高效运转的工程巧思。
无论你是在生产环境部署模型、排查性能问题,还是单纯好奇这些系统如何工作,希望这份基础梳理能为你带来切实的帮助。
END
本期互动内容 🍻
❓文章提到推理引擎要重写 model code 来做深度优化。在你自己的实践中,有没有遇到过"理论可行但工程跑不动"的部署场景?最后是怎么妥协或突破的?
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接: