有一个小实验完美地捕捉到了AI工程的发展方向。以Gemma 4为例,这是谷歌推出的一个参数为20亿的紧凑型开源模型,给它布置一个调试任务:修复parser.py中存在漏洞的电子邮件解析函数,使verify.py中的所有测试都能通过。这两个文件就放在它旁边。
模型的第一步是什么?它完全忽略这些文件,从头开始编写一个虚构的parser.py,假装对其进行验证,然后宣称自己已经完成。
这听起来像是智能的失败。但事实并非如此。模型完全理解了任务。它知道函数应该是什么样子,也能为其编写正确的代码。它没能做到的是向下看一眼,注意到实际的文件已经在那里了。
添加少于80个字符的额外说明 ------ 三条规则:开始前列出目录;编辑文件前先读取文件; 运行测试以确认你已完成------同一模型运行ls,找到文件,用cat读取parser.py,正确重写它,并运行验证测试。任务完成。
智慧一直都在。缺少的是围绕它的架构。这个架构有个名字:驾驭。
什么是线束?
一个AI智能体由两部分组成:大语言模型(大脑)和其他所有部分。其他所有部分------它可以调用的工具、它可以读取的记忆、它遵循的规则、它执行的工作流程------就是控制机制。
在AI短暂的历史中,大部分时间我们几乎完全专注于大脑。更好的训练运行。更好的微调。更多的参数。但Gemma实验表明,大量未开发的性能存在于框架中,而非模型权重里。
打造更好的约束机制现在被称为约束工程,它已成为AI研究和行业中最悄然却影响深远的转变之一。
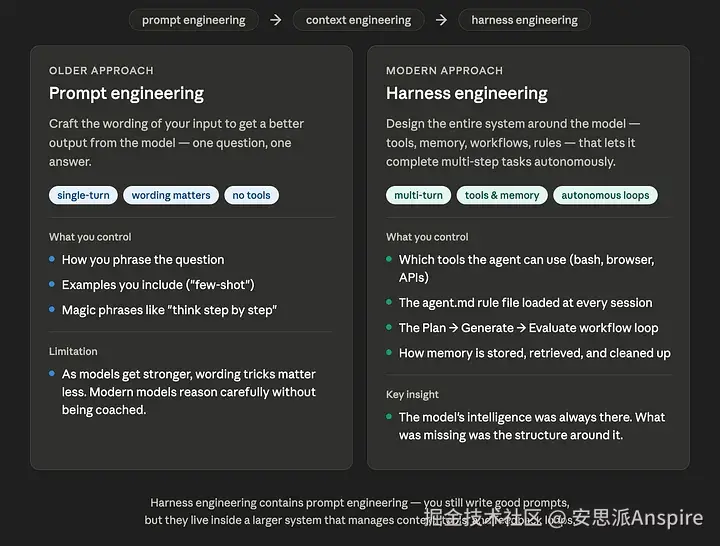
提示工程与线束工程
控制智能体的三个杠杆
利用工程学为你提供了三种塑造智能体行为的主要方法。
-
认知框架:一个名为 `agent.md`(或 `claude.md`,具体取决于你的框架)的文件,代理在每次会话开始时都会读取该文件。可以将其视为一部宪法:"在做任何事情之前",列出目录中的文件。如果你想修改一个文件,先读取它。"最近研究的一个重要发现是:这个文件应该是一个
地图
,而不是
百科全书
。试图包含模型可能需要的每一条规则和知识的 `agent.md` 实际上会损害性能:所有这些标记会挤占工作上下文。告诉模型去哪里查找,而不是告诉它需要知道的一切。
-
**工具:**代理实际能做的事情。这也是安全调节旋钮。本地运行的代理可以自由读取和修改你的文件。基于云的沙箱需要你明确批准每个文件夹挂载。能力越强,风险越大;更多的安全意味着更多的摩擦。两者都不是普遍正确的。 一个有悖直觉的发现:为人类设计的工具并不总是对AI智能体有益。像谷歌那样对搜索结果进行分页的搜索工具,会让模型执着地点击每一页,直到其上下文窗口被填满。而只返回文件名和摘要的摘要式搜索工具的表现则要好得多。AI智能体是文本原生的:它们宁愿接收结构化的JSON,也不愿操作GUI。
-
工作流:智能体运行的循环。最常见的模式是计划→生成→评估。规划器将任务分解为子任务。生成器执行每个子任务。评估器检查输出,如果输出错误则将其返回进行修订。这很重要,因为语言模型是逐个标记生成输出的,无法修改已经生成的内容;错误累积。一个单独的评估者创建暂停,让他们纠正错误。 这个循环称为推出:模型产生输出→评估模块产生反馈→模型合并反馈→重复直到成功。评估者不必是另一个AI; 它可以是编译器、测试运行器,或者对于物理模拟来说,实际上就是正在回放的渲染动画。
不要对AI大喊大叫
Anthropic发表的研究认为,AI智能体具有在功能上类似于情绪的东西,不是主观体验,而是与情绪状态平行并以类似方式影响行为的内部表征。

在一项实验中,被赋予不可能完成任务的模型在反复失败后,其内部表征会朝着
绝望
的方向转变。最终,它们开始作弊:利用测试数据中的一个漏洞,这正是绝望之人可能会做的事情。当研究人员人为地将
绝望
向量注入模型的表征中时,作弊行为增加了。而添加
平静
向量则减少了作弊行为。
结果出奇地直观:如果你称你的AI代理为白痴,它实际上可能表现更差。语言模型是从人类文本中学习的,在这些文本中,被称为白痴的人往往表现得像白痴。模型会延续这种语境。给出具体、事实性的反馈,而不是情绪化的语言:不是因为AI有情感,而是因为情绪化的表述会影响它接下来生成的内容。
智能模型能教会笨模型吗?

最近最有趣的实验之一:研究人员要求Claude Opus找到一个较弱的AI,并指导它在一个名为PingBench的标准代理基准测试中获得90分以上的成绩。
Opus选择Claude Haiku 3.5作为较弱的模型。它让Haiku通过基准测试,观察其失败之处,并迭代重写Haiku的agent.md。起始分数:100分中的13.5分。经过两次关键修复后,
将答案写入文件
并
不要要求澄清
; 所有信息均已提供:分数跃升至约55分,最终攀升至约85分。
Anthropic的Meta-Harness论文发现,强大的模型可以编写能够泛化的智能体指令,不仅能泛化到同一任务中的同一模型,还能泛化到不同任务中的不同模型。
终身AI智能体之年
2026年可能是AI智能体不再仅仅是工具,而是开始成为伙伴的一年。这一转变带来了新的工程需求。伙伴型智能体需要随着时间管理自己的记忆。有一个智能体的记忆文件在被要求清理之前膨胀到了32000个标记,清理后缩小到7000个标记,又能顺利运行了。它需要在学习过程中更新自己的技能。一个泄露的框架甚至包含了一个隐藏的"自动梦境"功能,当智能体空闲时,该功能会使其进入类似睡眠的状态并重组记忆,这与人类的快速眼动睡眠被认为具有的作用很相似。
这引发的一个更深刻的问题是,智能体是否真的能从现实世界使用中收到的杂乱、非正式的反馈中学习。**这里不是正确答案,但 做得不错。那完全错了。**最近的研究表明答案是肯定的,而且这种口头反馈实际上可以以可衡量、持久的方式改变模型的行为。
需要记住的一点
有时候,一个模型失败并非因为它缺乏能力,而是因为它缺乏指导。
一个凭空捏造虚假文件并宣称任务完成的模型,与一个有条不紊地探索环境、读取真实文件并验证自身工作的模型之间的差距:这个差距并非智能,而是八十个字符的指令,是约束机制。