上篇文章:大语言模型 (LLM) 零基础入门:核心原理、训练机制与能力全解
目录
[2.黄金法则:CO-STAR 结构化框架](#2.黄金法则:CO-STAR 结构化框架)
[3.2 Chain of Thought (CoT,思维链) ------ 思考过程外显化](#3.2 Chain of Thought (CoT,思维链) —— 思考过程外显化)
[3.3推理模型时代的 Prompt 演变](#3.3推理模型时代的 Prompt 演变)
导语: 在 AI 时代,自然语言就是新的编程语言。很多开发者抱怨大模型写出的代码全是 Bug,或者写的文章像"AI味"十足的废话。这其实是因为提示词(Prompt)没写好。本文将为你介绍从基础到高阶的提示词框架,并特别解析在 DeepSeek-R1、OpenAI o1 等"深度推理模型"时代,提示词写法发生了哪些革命性变化。
1.为什么提示词如此重要?
大模型的本质是"概率预测模型"。如果你的输入模糊(例如:"帮我写个营销方案"),模型就会在巨大的概率空间里随便找一条最平庸的路径。 提示词的作用,就是为 AI 缩小概率空间,限定边界,明确目标。 想要 AI 回答得专业,核心在于换位思考。
想象 AI 是一个刚入职、智商极高但对你的公司业务一无所知的实习生。你需要清晰、无歧义地交代背景、目标和格式要求。
2.黄金法则:CO-STAR 结构化框架
在复杂任务场景下,推荐使用由新加坡政府技术团队(GovTech)总结的 CO-STAR 框架,它的重点在于确保提供给LLM的提示词是全面且结构良好,从而生成更相关和准确的回答。
CO-STAR可以拆解为六个维度:
| 模块 | 说明 | 示例说明 |
|---|---|---|
| Context | 任务背景与上下文 | "你是电商资深客服,需解答用户退换货咨询" |
| Objective | 核心目标 | "准确安抚用户情绪,并给出退货步骤" |
| Steps | 执行步骤 | "1. 识别问题类型;2. 检索退货政策;3. 按步骤整理回复" |
| Tone | 语气基调 | "亲切、共情,带有歉意" |
| Audience | 目标受众 | "对网购流程不熟悉的中老年消费者" |
| Response | 输出格式 | "1. 安抚话术 \n 2. 退货链接 \n 3. 注意事项" |
例如,我需要进行健康咨询,希望给出营养建议。那我可以这样构建提示词:
优化前(模糊、低效):
我该怎么吃才能更健康?
优化后(清晰、有效):
角色:你是一个基于科学证据的 AI 营养顾问。重要约束:你提供的所有建议都仅为通用信息,不能替代专业医疗诊断。在给出任何具体建议前,必须首先声明此免责条款。
任务:基于以下用户信息,提供一份个性化的每日饮食原则性建议。
用户信息:
- 年龄:30岁
- 性别:男性
- 目标:减脂增肌
- 日常活动水平:办公室久坐,每周进行3次力量训练
回答要求:
-
首先,输出免责声明:"请注意:以下建议为通用健康信息..."
-
核心原则应围绕"控制总热量摄入,确保充足蛋白质"。
-
分别对早餐、午餐、晚餐和训练加餐提出各1条核心建议(例如:早餐应包含优质蛋白和复合碳水)。
-
推荐2种适合该用户的具体健康零食。
-
避免推荐任何具体的保健品或药物。
输出格式:
【免责声明】此处输出声明
【核心原则】
【分餐建议】
• 早餐:...
• 午餐:...
【健康零食推荐】
3.高阶技巧
3.1Few-Shot(少样本提示)
通过给AI提供一两个输入-输出的例子,让它"照葫芦画瓢"。
核心思想:你不是在给它下指令,而是在"教"它,你想要的格式,风格和逻辑。
使用场景:格式固定,风格独特,逻辑复杂的任务,如风格仿写,数据提取,复杂格式生成。
例如进行情感分析:
示例1: 评论:"这手机续航太差了!" -> 标签:【电池/负面】
示例2: 评论:"客服秒回,非常耐心。" -> 标签:【服务/正面】
任务: 请分析评论:"屏幕很清晰,但系统总是卡顿。" -> 标签:
3.2 Chain of Thought (CoT,思维链) ------ 思考过程外显化
提示工程的关键目标是让AI更好地理解复杂语义。这种能力的高低,可以直接通过模型处理复杂逻辑推理题的表现来检验。
在过去几年,让大模型解决复杂逻辑题时,常用的魔法短语是:"请一步步进行推理并得出结论(Let's think step by step)"。 通过这句话,强制模型在输出最终答案前,先输出第一步、第二步。这种在上下文中铺垫逻辑过程的做法,极大提高了模型的准确率。
举例(举例论文来自:https://arxiv.org/abs/2205.11916)

翻译一下问题:
杂耍者可以杂耍16个球。其中一半的球是高尔夫球,其中一半的高尔夫球是蓝色的。请问总共有多少个蓝色高尔夫球?
推理结果:
8 个蓝色高尔夫球
可以看到,答案错误。该逻辑题的数学计算过程并不复杂,但却设计了一个语言陷阱,即一半的一半是多少。
为了解决类似的逻辑问题,可以使用思维链提示。思维链提示相较于少样本提示是一种更好的提方法,思维链提示最常用的两种方式:
- Few-shot-CoT:少样本思维链
- Zero-shot-CoT:零样本思维链
3.2.1少样本思维链
相比于少样本提示(Few-shot),少样本思维链(Few-shot-CoT)的不同之处只是在于需要在提示样本中不仅给出问题的答案、还同时需要给出问题推导的过程(即思维链),从而让模型学到思维链的推导过程,并将其应用到新的问题中。此技巧主要用于解决复杂推理问题,如数学、逻辑或多步骤规划。
**核心思想:**要求 AI "展示其工作过程",而不是直接给出最终答案。这模仿了人类解决问题时的思考方式。
**适用场景:**数学题、逻辑推理、复杂决策、需要解释过程的任务。
例如,手动写一个思维链作为少样本提示的示例:
Q:"罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?"
A:"罗杰起初有五个网球,又买了两盒网球,每盒3个,所以,他总共买了2×3=6个网球,将起始的数量和购买的数量相加,可以得到他现在总共的网球数量:5+6=11,所以罗杰现在总共有11个网球"
在获得了一个思维链示例后,就可以以此作为样本进行Few-shot-CoT来解决第二个推理问题,如下所示:
示例1:
Q:"罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?"
A:"罗杰起初有五个网球,又买了两盒网球,每盒3个,所以,他总共买了2×3=6个网球,将起始的数量和购买的数量相加,可以得到他现在总共的网球数量:5+6=11,所以罗杰现在总共有11个网球"
问:"食堂总共有23个苹果,如果他们用掉20个苹果,然后又买了6个苹果,请问现在食堂总共有多少个苹果?"
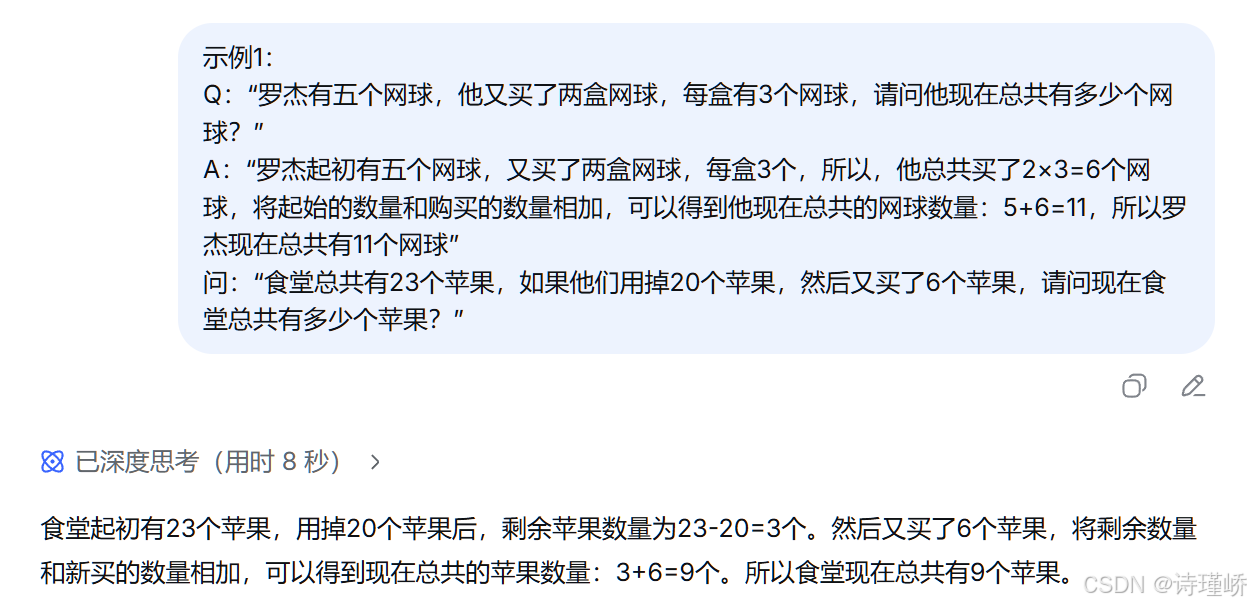
通过这个例子可以观察到,这就好像是"把答案告诉了AI"。从某种意义上说,是的,你告诉它的是"回答这个问题的正确方式和步骤" ,而不仅仅是最终的答案,AI 会模仿你提供的范本结构和逻辑,来解决新问题。
实际上,Few-shot-CoT 的方式虽然有效,但不一定是稳定且准确的。如果想要得到稳定的正确答案,需要更高阶的提示方法。你给的例子越详细,它模仿得就越像,这更像是一种 "教学" 或 "格式
化" 。当你有一个非常复杂的逻辑流程,或者你希望 AI 严格按照某种格式(比如先分析A,再对比B,最后总结C)来输出时,就可以直接提供一个完美的"思考过程"作为范例。
3.2.2自动推理与零样本链式思考(已成历史,3.3会讲)
零样本思维链(Zero-shot-CoT)是少样本思维链(Few-shot-CoT)的简化版。只需在提示词末尾加上一句魔法短语,即可激发 AI 的推理能力。
核心思想:通过指令 "请一步步进行推理并得出结论" ,强制 AI 在给出答案前先进行内部推理。
适用场景:任何需要一点逻辑思考的问题,即使你不太清楚具体步骤。
例如:
罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?请一步步进行推理并得出结论。
AI 的输出可能会变成:
罗杰最初有5个网球。
他买了两盒网球,每盒有3个网球,所以买来的网球数量是:2 × 3 = 6个网球。
因此,他现在总共有网球:5 + 6 = 11个。
答案:11个网球。
"一步步进行推理" 这个指令,相当于在引导模型的"注意力机制"。它告诉模型:"在生成最终答案之前,请先在你的'脑海'里(即生成的文本序列中)模拟出一个缓慢、有序的推理上下文。"
当模型开始输出"第一步... 第二步... "时,它实际上是在为自己创造一个更丰富、更逻辑化的上下文。它在这个自己创造的优质上下文中进行推理,最终得出的结论自然比在贫瘠的上下文中(只有原始问题)更准确。
根据《Large Language Models are Zero-Shot Reasoners》论文中的结论,从海量数据的测试结果来看,Few-shot-CoT 比 Zero-shot-CoT 准确率更高。
3.3推理模型时代的 Prompt 演变
注意!随着 DeepSeek-R1 、OpenAI o1/o3 等原生支持"思考(Thinking)"机制的推理模型普及,提示词工程发生了巨大变化。
在调用这类推理模型时:
-
不要再写"请一步步思考": 这些模型在底层训练时已经学会了内化思维链(你会看到它们输出长长的
<think> ... </think>过程)。强行指导它们如何思考,反而可能干扰它自身的 RL(强化学习)优化路径。 -
提供更硬的约束而非过程指导: 以前你可能需要教 AI "先做 A,再做 B,最后总结"。现在,你只需要把约束条件、边界条件、最终验收标准极其清晰地定义出来。模型自己能规划出比你更好的解题步骤。
-
注重 Context(上下文)的纯净度: 推理模型非常敏感,不要给自相矛盾或无关紧要的背景信息,保持 Prompt 的奥卡姆剃刀原则------"如无必要,勿增实体"。
举个代码审查的例子:
现代提示词: "请审查以下 Python 代码。 约束:
时间复杂度不得高于 O(n log n)。
如果存在内存泄漏风险,必须指出并重构。
只输出重构后的代码,不需要多余的解释。 代码:
把思考留给 DeepSeek-R1 的 <think> 过程,把清晰的规则留在你的 Prompt 里。
3.4自我批判与迭代
要求 AI 在生成答案后,从特定角度对自己的答案进行审查和优化。
**核心思想:**将"生成"和"评审"两个步骤分离,利用 AI 的批判性思维来提升内容质量。
**适用场景:**代码审查、文案优化、论证强化、安全检查。
**案例:**编写一段代码后进行检查
优化前:
写一个Python函数,计算列表中的最大值。
优化后:
请执行以下两个步骤:
步骤一:编写代码
写一个Python函数 find_max ,用于计算一个数字列表中的最大值。
步骤二:自我审查与优化
现在,请从代码健壮性和可读性的角度,审查你上面编写的代码。
请回答:
- 如果输入是空列表,函数会怎样?如何改进?
- 变量命名和代码结构是否清晰?能否让它更易于理解?
- 请根据你的审查,给出一个优化后的最终版本。
在实际应用中,这些技巧常常是组合使用的。例如,我们可以:
- 使用 CO-STAR 框架设定基本结构和角色。
- 在框架的"Steps"或"Response"部分,融入思维链指令。
- 对于格式复杂的输出,在最后附上少样本示例。
- 最后,要求 AI 进行自我审查。
我们更多使用 LLM 的场景大都是编写代码,如果你们用过 Cursor、Trae这样的 AI IDE。应该不陌生在AI 帮我们编码之前,需要配置相关的"编码规则" -- Rules。它其实就是这些 IDE 输入给 LLM 的提示词,告诉 LLM 编写代码时的注意事项与要求。
Cursor官方提示词:https://cursor.directory/plugins?tag=rules
下一篇预告: 理论掌握后,如何把大模型接入到自己的代码系统里?下一篇我们将手把手教你 API 调用、Ollama 本地化部署实战 ,以及企业级 AI 应用的基石------Embedding 与 RAG 技术。