目录
- [1. 机器阅读理解](#1. 机器阅读理解)
- [2. pipeline 快速问答](#2. pipeline 快速问答)
- [3. 数据预处理](#3. 数据预处理)
- [3.1 加载问答数据集](#3.1 加载问答数据集)
- [3.2 Tokenizer 如何编码](#3.2 Tokenizer 如何编码)
- [3.3 单样本对齐函数](#3.3 单样本对齐函数)
- [3.4 prepare_train_features](#3.4 prepare_train_features)
- [4. 模型训练](#4. 模型训练)
- TrainingArguments
- [创建 Trainer 并训练](#创建 Trainer 并训练)
- [5. 模型测试](#5. 模型测试)
模型预训练:Hugging Face Transformers 基础
我们已经了解了 Hugging Face Transformers 的基础组件,包括 Pipeline、Tokenizer、Model、Datasets、Evaluate、Trainer
本文选择 阅读理解问答 作为 NLP 实战任务,完成一个抽取式问答任务,包括:
原始问答样本
→ tokenizer 编码成模型输入
→ 把答案字符位置转换成 token 位置
→ 问答模型预测 start_logits / end_logits
→ 后处理还原成文本答案
→ 用 EM / F1 评估
→ 保存模型并用 pipeline 推理
1. 机器阅读理解
机器阅读理解的常见任务形式是给定一段文章 context,再给定一个问题 question,模型需要根据文章内容回答问题,例如:
text
context:
Hugging Face is a company based in New York City. It develops tools for building machine learning applications.
question:
Where is Hugging Face based?
answer:
New York City这种任务可以分成两类。第一类是 抽取式问答 ,答案必须是原文中的一段连续文本;第二类是 生成式问答 ,模型自己生成答案,答案不一定是原文中的连续片段。这里是第一类:抽取式问答 。它和第一部分的基础组件衔接更紧密。它仍然主要使用 BERT、DistilBERT 这类 Encoder 模型,但任务目标从分类 变成了预测答案位置。
从文本分类到阅读理解
之前的内容中,我们用文本分类串过基础组件。它输入一句话,输出一个类别,模型输出通常是:
text
logits: [batch_size, num_labels]每条样本输出一个类别分数向量。但是机器阅读理解不一样。输入是 question + context,输出是答案在 context 中的起始位置、结束位置。仍以 New York City 为例,模型需要预测:
start_position = New 这个 token 的位置
end_position = City 这个 token 的位置
所以问答模型输出两个向量:
start_logits: batch_size, sequence_length
end_logits: batch_size, sequence_length
start_logits 表示每个 token 作为答案开始位置的分数,end_logits 表示每个 token 作为答案结束位置的分数
2. pipeline 快速问答
先用已经训练好的问答模型,看一下问答任务最终效果是什么样。
继续使用之前的 VS Code 虚拟环境。创建文件 pipeline_demo.py
python
from transformers import pipeline
qa_pipeline = pipeline(
task="question-answering",
model="distilbert-base-cased-distilled-squad"
)
context = """
Hugging Face is a company based in New York City.
It develops tools and libraries for building machine learning applications.
The Transformers library provides thousands of pretrained models.
"""
question = "Where is Hugging Face based?"
result = qa_pipeline(
question=question,
context=context
)
print(result)
print("answer:", result["answer"])
print("score:", result["score"])
print("start:", result["start"])
print("end:", result["end"])
输出了答案文本、置信度、答案在原始字符串中的起始、结束字符位置。
pipeline 帮我们隐藏了很多细节。
question + context
→ tokenizer 编码
→ model 前向传播
→ 得到 start_logits 和 end_logits
→ 选择最可能的答案起点和终点
→ 根据 offset_mapping 还原成原始文本
→ 输出 answer
3. 数据预处理
3.1 加载问答数据集
使用 SQuAD 格式数据集作为实验数据。SQuAD 是经典的抽取式问答数据集,每条样本包含:
id:样本编号
title:文章标题
context:上下文文章
question:问题
answers:标准答案
新建 load_dataset.py
python
from datasets import load_dataset
raw_datasets = load_dataset("squad")
print(raw_datasets)
print("\nexample:")
print(raw_datasets["train"][0])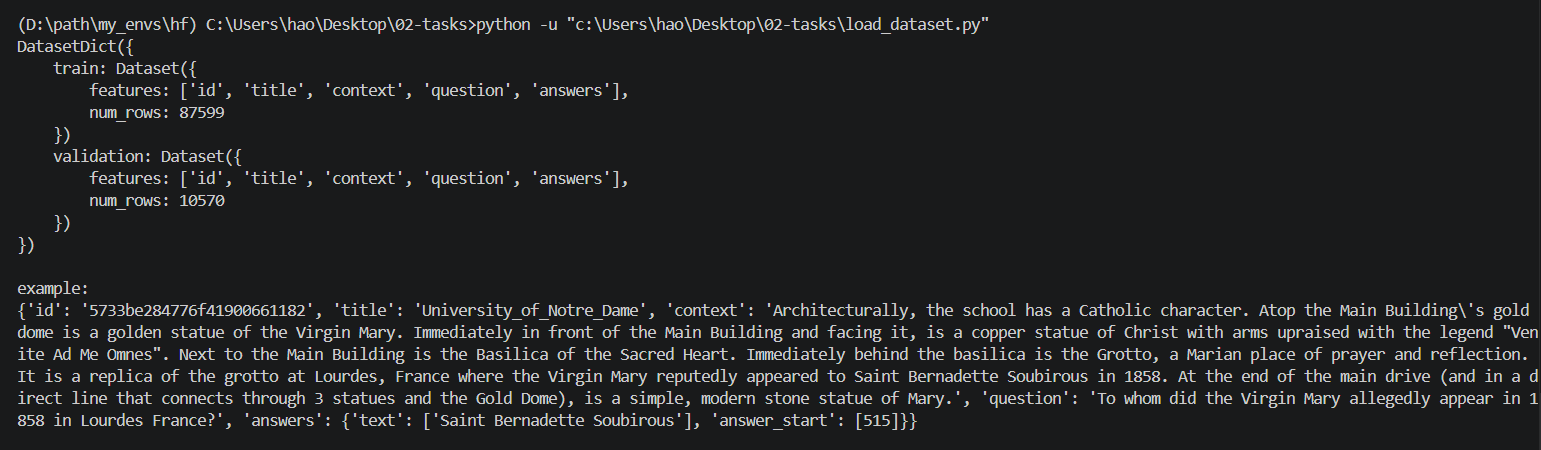
这里最重要的是 answers 字段。它包含两个内容:
answers"text":答案文本
answers"answer_start":答案在 context 中的起始字符位置
3.2 Tokenizer 如何编码
在文本分类任务中,tokenizer 通常只需要处理一句话;但是在阅读理解任务中,模型需要同时看到两个内容:question与context
要解决三个问题:
- tokenizer 会怎样把 question 和 context 拼在一起?
- 拼接之后,模型怎么知道哪些 token 属于 question,哪些属于 context?
- 如果答案在原文中是字符位置,怎么找到它对应的 token 位置?
对应阅读理解任务中最核心的内容:答案位置对齐。
新建文件 tokenizer_demo.py,写最简单的 tokenizer 编码,将question 和 context 作为输入:
python
from transformers import AutoTokenizer
checkpoint = "distilbert-base-cased-distilled-squad"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
question = "Where is Hugging Face based?"
context = "Hugging Face is a company based in New York City."
encoding = tokenizer(question, context)
print(encoding.keys())输出:
python
dict_keys(['input_ids', 'attention_mask'])input_ids 是 token 对应的数字编号。模型不能直接处理字符串,所以 tokenizer 会先把文本切成 token,再把 token 转成词表里的 id。attention_mask 用来告诉模型哪些位置是真实 token,哪些位置是 padding 补齐出来的 token。input_ids 是一串数字,不方便观察。我们把它转回 token 看一下。加上:
python
tokens = tokenizer.convert_ids_to_tokens(encoding["input_ids"])
for index, token in enumerate(tokens):
print(index, token)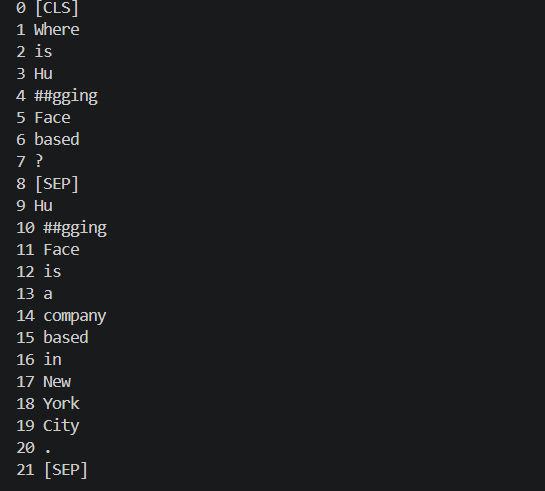
可以看出,Tokenizer 把它们拼成了一个 token 序列:
text
[CLS] question [SEP] context [SEP][CLS] 通常放在整个输入开头;[SEP] 用来分隔两个文本,也用来表示输入结束。
sequence_ids
在当前输入中,token 序列由三类内容组成:特殊 token、question 的 token、context 的 token,可以用 sequence_ids() 查看每个 token 属于哪一部分。
添加代码:
python
sequence_ids = encoding.sequence_ids()
for index, token in enumerate(tokens):
print(index, token, sequence_ids[index])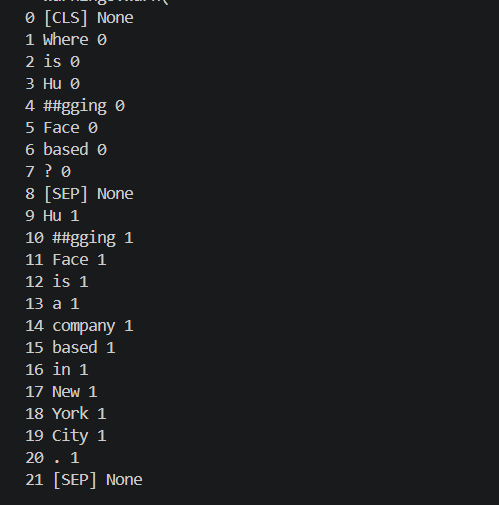
None代表特殊 token,比如 CLS、SEP;0是第一个输入,也就是 question;1是 context。阅读理解任务中,答案必须来自 context。所以后面寻找答案开始位置和结束位置时,只能在 sequence_idsindex == 1 的 token 里面找。
offset_mapping
现在我们知道每个 token 属于 question 还是 context。但还没有解决另一个问题,数据集里的answers 字段是字符位置,但一个 token 可能对应多个字符,而模型需要的是 token 下标。
例如原始 context 是:Hugging Face is a company based in New York City.
答案是:New York City。模型训练需要的是 token 下标:
17 New
18 York
19 City
所以我们需要知道每个 token 对应原始字符串中的哪一段字符,这就需要 offset_mapping。
重新编码时加上:
python
encoding = tokenizer(
question,
context,
return_offsets_mapping=True
)然后打印 token、sequence_id 和 offset:
python
tokens = tokenizer.convert_ids_to_tokens(encoding["input_ids"])
sequence_ids = encoding.sequence_ids()
offset_mapping = encoding["offset_mapping"]
for index, token in enumerate(tokens):
print(index, token, sequence_ids[index], offset_mapping[index])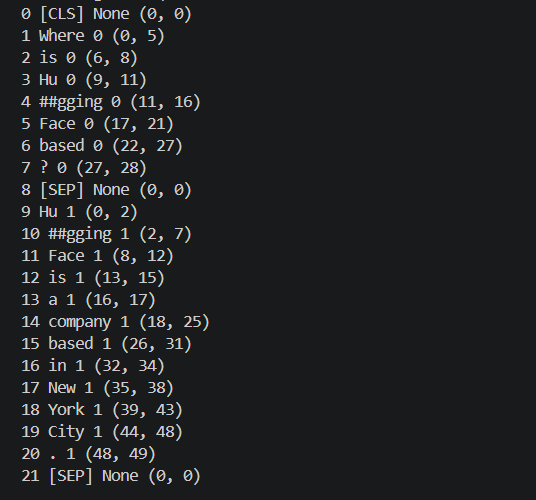
这里每一行可以这样理解:
text
17 New 1 (35, 38)表示第 17 个 token 是 New,它属于 context,它对应 context 原文中的第 35 到 38 个字符。
答案 New York City 对应的 token 范围是:
start_position = 17
end_position = 19
这就是 offset_mapping 的作用,它建立了字符位置与token 位置的桥梁
总结一下,
1.tokenizer(question, context) 会把问题和上下文拼成一个序列:[CLS] question [SEP] context [SEP];
2.sequence_ids() 可以告诉我们每个 token 属于哪一部分:
None:特殊 token
0:question
1:context
3.模型真正处理的是 token,不是原始字符串。一个单词可能被拆成多个 token,每一个token 对应多个字符,offset_mapping 可以告诉我们每个 token 对应原文中的字符范围。
3.3 单样本对齐函数
新建文件:align_one_example.py
python
from transformers import AutoTokenizer
checkpoint = "distilbert-base-cased-distilled-squad"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
question = "Where is Hugging Face based?"
context = "Hugging Face is a company based in New York City."
answer_text = "New York City"
answer_start = context.index(answer_text)
answer_end = answer_start + len(answer_text)这里用 context.index(answer_text) 自动找到答案在原文里的字符起点。
接下来编码:
python
encoding = tokenizer(
question,
context,
return_offsets_mapping=True
)
tokens = tokenizer.convert_ids_to_tokens(encoding["input_ids"])
offsets = encoding["offset_mapping"]
sequence_ids = encoding.sequence_ids()现在要遍历所有 token,找到答案起点和终点。
python
start_token = None
end_token = None
for i, offset in enumerate(offsets):
if sequence_ids[i] != 1: ## 当前 token 不属于 context
continue
start, end = offset
if start <= answer_start < end: # 答案的起始字符在当前token内
start_token = i
if start < answer_end <= end: # 答案的结束字符在当前token内
end_token = i最后打印结果:
python
print("answer_start:", answer_start)
print("answer_end:", answer_end)
print("start_token:", start_token, tokens[start_token])
print("end_token:", end_token, tokens[end_token])
print("answer tokens:", tokens[start_token:end_token + 1])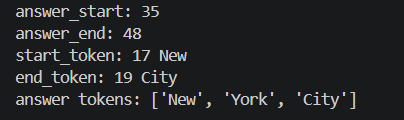
真实的处理没这么简单,很多时候context 可能很长,如果 question + context 超过最大长度,就必须截断。一条长 context 可能要切成多个片段,这时一条原始样本会变成多个训练特征 feature。
因此真实训练时要用三个参数:
max_length:每个输入片段的最大长度
doc_stride:相邻片段之间保留多少重叠 token
return_overflowing_tokens:把长文本切出来的多个片段全部返回
设置相邻片段的重叠,为了防止答案刚好被切断
3.4 prepare_train_features
构造问答模型的训练输入,新建:train_qa.py
python
import torch
from datasets import load_dataset
from transformers import AutoTokenizer
checkpoint = "distilbert-base-cased-distilled-squad"
max_length = 384
doc_stride = 128
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_datasets = load_dataset("squad")取一小部分数据:
python
train_examples = raw_datasets["train"].shuffle(seed=42).select(range(1000))
eval_examples = raw_datasets["validation"].shuffle(seed=42).select(range(200))(1)函数目标
接下来定义训练数据预处理函数,这个函数的思路是:
原始 examples
tokenizer 编码 question + context
长 context 切成多个 feature
把答案的字符位置转换成 token 位置
生成 start_positions 和 end_positions
原始 SQuAD 样本里,答案是这样保存的:
python
answers = {
"text": ["New York City"],
"answer_start": [35]
}答案文本是 "New York City",从 context 的第 35 个字符开始。但是模型训练时不需要字符串答案,而是需要答案开始 token 的下标 和答案结束 token 的下标 ,所以 prepare_train_features 的任务就是将字符答案位置 转换为 token 答案位置
(2)批量编码
python
def prepare_train_features(examples):
questions = [q.strip() for q in examples["question"]] ## 去掉问题前后的空格
tokenized_examples = tokenizer(
questions,
examples["context"],
truncation="only_second",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length"
)truncation="only_second" 表示只截断第二个输入,也就是 context。问题通常很短,文章通常很长,所以应该截断文章。
此时tokenized_examples 的数据格式为:
tokenized_examples = {
"input_ids": [
feature0 的 384 个 token id,
...
],
"attention_mask": [
feature0 的 384 个 0/1,
...
],
"offset_mapping": [
feature0 的 384 个字符位置,
...
],
"overflow_to_sample_mapping": [
0, 0, 1, 2, 2
]
}
继续在函数里:
python
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
offset_mapping = tokenized_examples.pop("offset_mapping")如前文所说,长 context 会被切成多个片段,一条原始样本可能变成多个 feature。所以在处理第 i 个 feature 时,必须知道它来自原始数据中的哪条样本,才能拿到对应的标准答案。这是sample_mapping 的作用
offset_mapping 的作用是把 token 位置和原始字符位置对应起来。
tokenized_examples 的数据格式变为:
tokenized_examples = {
"input_ids": [
feature0 的 384 个 token id,
...
],
"attention_mask": [
feature0 的 384 个 0/1,
...
],
}
(3)提取 feature 对应的答案
tokenizer 已经把原始样本转换成了若干个 feature。接下来要做的事情是:逐个检查每个 feature,看它是否包含答案;如果包含,就计算答案在当前 feature 中的 token 起止位置;如果不包含,就把答案位置标成 [CLS]。
逐个 feature 计算 start/end 标签:
python
start_positions = []
end_positions = []
for i, offsets in enumerate(offset_mapping):
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
sequence_ids = tokenized_examples.sequence_ids(i)enumerate(offset_mapping) 同时包含:i 当前 feature 的编号、offsets 当前 feature 中每个 token 的字符位置映射。对每一个 feature,取出它的 input_ids。并找到 [CLS] 的位置。
继续找到当前 feature 对应的原始答案
python
sample_index = sample_mapping[i]
answers = examples["answers"][sample_index]
start_char = answers["answer_start"][0]
answer_text = answers["text"][0]
end_char = start_char + len(answer_text)前面说过,如果长 context 被切成多个片段,一条 example 可能对应多个 feature,所以现在处理第 i 个 feature 时,通过sample_mappingi 找到它原来是哪条 example。
然后从原始样本中取出答案:
python
answers = examples["answers"][sample_index]这里再次得到的是字符位置
start_char:答案开始字符位置
end_char:答案结束字符位置
下一步是真正的对齐
(4)字符位置转换为 token 位置
找到 context 在 token 中的范围
python
token_start_index = 0
while sequence_ids[token_start_index] != 1:
token_start_index += 1
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != 1:
token_end_index -= 1答案只能出现在 context 里,我们先从左往右找第一个 sequence_ids == 1 的 token,它就是 context 的开始;再从右往左找最后一个 sequence_ids == 1 的 token,它就是 context 的结束。后面只在这个范围内找答案。
判断当前片段是否包含答案
python
if not (
offsets[token_start_index][0] <= start_char
and offsets[token_end_index][1] >= end_char
):
start_positions.append(cls_index)
end_positions.append(cls_index)
continueoffsets = offset_mappingi,它的格式是这样的
(0, 0), # \[CLS
(0, 5), # Where
(6, 8), # is
...
(0, 0), # SEP
(0, 7), # Hugging
(8, 12), # Face
(13, 15), # is
...
]
每一个元素都是一个二元组(start, end),表示当前 token 对应原始文本中的字符范围。
offsets[token_start_index][0] 是当前片段第一个 context token 的起始字符;offsets[token_end_index][1] 是当前片段最后一个 context token 的结束字符。
如果当前片段没有完整答案,就标成:
python
start_positions.append(cls_index)
end_positions.append(cls_index)然后 continue,直接处理下一个 feature,直到真正找到答案的 token 起点和终点
python
while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
token_start_index += 1
start_positions.append(token_start_index - 1)
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
end_positions.append(token_end_index + 1)最后把标签放回 tokenized_examples:
python
tokenized_examples["start_positions"] = start_positions
tokenized_examples["end_positions"] = end_positions
return tokenized_examples最终 tokenized_examples 的数据格式为
tokenized_examples = {
"input_ids": [
384个token id,
...
],
"attention_mask": [
384个0/1,
...
],
"start_positions": [
24,
...
],
"end_positions": [
26,
...
]
}
总结一下,函数首先对问题和上下文批量编码,切分为多个特征片段;随后利用样本映射找到每个片段的答案,通过位置映射判断答案是否完整落在当前片段中。
若不包含完整答案,则将答案位置标记为 [CLS];若包含答案,则将答案在原文中的字符级位置转换为当前片段中的 token 级起止位置,最终生成 start_positions 和 end_positions,作为模型训练标签。
4. 模型训练
函数写完后,继续在 train_qa.py 中添加:
python
tokenized_train_dataset = train_examples.map(
prepare_train_features,
batched=True,
remove_columns=train_examples.column_names
)这里的 batched=True 表示一次处理一批样本。remove_columns=train_examples.column_names 表示删除原始字段。
因为原始字段id、title、context、question、answers不能直接送进模型。模型训练只需要input_ids、attention_mask、start_positions、end_positions
此时打印检查:
python
print(tokenized_train_dataset[0].keys())输出:
text
dict_keys(['input_ids', 'attention_mask', 'start_positions', 'end_positions'])现在数据已经变成模型可以理解的格式了。导入训练相关组件:
python
from transformers import (
AutoModelForQuestionAnswering,
TrainingArguments,
Trainer,
DefaultDataCollator
)
model = AutoModelForQuestionAnswering.from_pretrained(checkpoint)
data_collator = DefaultDataCollator() ## 数据整理器TrainingArguments
训练参数:
python
training_args = TrainingArguments(
output_dir="outputs/qa_model",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
logging_steps=20,
evaluation_strategy="epoch",
save_strategy="epoch",
fp16=torch.cuda.is_available(), ## 如果有 GPU,就尝试使用半精度训练
report_to="none"
)创建 Trainer 并训练
先处理验证集:
python
tokenized_eval_dataset = eval_examples.map(
prepare_train_features,
batched=True,
remove_columns=eval_examples.column_names
)创建 Trainer:
python
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train_dataset,
eval_dataset=tokenized_eval_dataset,
tokenizer=tokenizer,
data_collator=data_collator
)开始训练并保存模型:
python
trainer.train()
trainer.save_model("outputs/qa_model/final")
tokenizer.save_pretrained("outputs/qa_model/final")5.模型测试
5.1 pipeline 推理
新建文件 inference.py,加载本地模型并执行问答
python
from transformers import pipeline
model_dir = "outputs/qa_model/final"
qa = pipeline(
"question-answering",
model=model_dir,
tokenizer=model_dir
)
context = """
Hugging Face is a company based in New York City.
It is known for the Transformers library.
"""
question = "What library is Hugging Face known for?"
result = qa(question=question, context=context)
print(result)输出:
text
{'score': 0.718795657157898, 'start': 71, 'end': 91, 'answer': 'Transformers library'}说明训练、保存、加载、推理已经跑通。
5.2 模型评估
问答任务的常用指标中,EM 表示预测答案和标准答案是否完全一致;F1 看两者之间有多少词重合。
在开展评估之前,需要首先进行后处理,假设 tokenizer 之后得到下面这些 token:
0 CLS
1 Where
2 is
3 Hu
4 ##gging
5 Face
6 based
7 ?
8 SEP
9 Hu
10 ##gging
11 Face
12 is
13 a
14 company
15 based
16 in
17 New
18 York
19 City
20 .
21 SEP
模型会给每个 token 一个 start 分数和一个 end 分数。如果模型认为答案是 New York City,那么理想情况下 start_logits17 最大,end_logits19 最大。于是答案 token 区间就是17 ~ 19。再通过 offset_mapping 找到这些 token 对应原文中的字符位置:
17 New (35, 38)
18 York (39, 43)
19 City (44, 48)
答案在原始 context 中的字符范围是35 ~ 48,最后从原文中切片:
python
answer = context[35:48]得到New York City,这就是后处理的基本思路。
最直观的想法是直接取 argmax,但可能出现非法答案,如答案结束位置不能在开始位置前面、答案不能来自 question、不应包含 [CLS]、[SEP] 这样的特殊 token......更合理的做法是:
找出分数最高的前 n 个位置,枚举所有 start/end 组合,删除不合法的组合,在剩下的组合中选总分最高的答案
验证集预处理
训练阶段的 prepare_train_features 会生成 start_positions 和 end_positions,给模型提供监督标签。评估阶段不一样,评估阶段需要保留 offset_mapping,因为后处理要靠它把 token 位置还原成原文中的字符串。
新建文件 evaluate_qa.py:
python
import collections
import numpy as np
import evaluate
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForQuestionAnswering, TrainingArguments, Trainer, DefaultDataCollator
model_dir = "outputs/qa_model/final"
max_length = 384
doc_stride = 128
n_best_size = 20
max_answer_length = 30
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForQuestionAnswering.from_pretrained(model_dir)
raw_datasets = load_dataset("squad")
eval_examples = raw_datasets["validation"].shuffle(seed=42).select(range(200))接下来写验证集预处理函数:
python
def prepare_validation_features(examples):
questions = [q.strip() for q in examples["question"]]
tokenized_examples = tokenizer(
questions,
examples["context"],
truncation="only_second",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length"
)
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
tokenized_examples["example_id"] = []
for i in range(len(tokenized_examples["input_ids"])):
sample_index = sample_mapping[i]
tokenized_examples["example_id"].append(examples["id"][sample_index])
sequence_ids = tokenized_examples.sequence_ids(i)
offsets = tokenized_examples["offset_mapping"][i]
tokenized_examples["offset_mapping"][i] = [
offset if sequence_ids[k] == 1 else None
for k, offset in enumerate(offsets)
]
return tokenized_examples这里新增了 example_id 这个字段,记录当前 feature 对应的原始样本 id。
接下来处理 offset_mapping。sequence_ids 用来判断每个 token 属于哪一部分,问答任务的答案只能来自 context,不能来自 question,也不能来自 [CLS]、[SEP]、[PAD]。所以我们把不属于 context 的 token 位置全部设置为 None
处理验证集:
python
validation_features = eval_examples.map(
prepare_validation_features,
batched=True,
remove_columns=eval_examples.column_names
)这里得到的 validation_features 是编码后的 feature。包含:
input_ids
attention_mask
offset_mapping
example_id
评估时,我们需要先让模型在验证集上跑一遍,得到每个 token 的开始分数和结束分数。
python
training_args = TrainingArguments(
output_dir="outputs/qa_eval",
per_device_eval_batch_size=8,
report_to="none"
)
data_collator = DefaultDataCollator()
trainer = Trainer(
model=model,
args=training_args,
tokenizer=tokenizer,
data_collator=data_collator
)
raw_predictions = trainer.predict(validation_features)
start_logits, end_logits = raw_predictions.predictions
print(start_logits.shape)
print(end_logits.shape)把 validation_features 输入模型,得到模型输出的两个矩阵 start_logits 和 end_logits
输出
(204, 384)
(204, 384)
验证集被切成了 204 个 feature,模型会给每个 token 一个作为答案开始位置的分数和一个结束位置的分数
后处理预测结果
接下来需要把 start_logits 和 end_logits 转换成真正的答案文本。
基本思路是:
- 找到每条原始样本对应的所有 feature
- 在每个 feature 中选出分数最高的若干个 start 位置
- 在每个 feature 中选出分数最高的若干个 end 位置
- 枚举 start/end 组合
- 删除非法答案
- 用 offset_mapping 从原始 context 中切出答案文本
- 对同一条样本,保留总分最高的答案
非法答案主要包括:start 或 end 不在 context 中、end 在 start 前面、答案长度超过 max_answer_length、start 或 end 位置越界,添加后处理函数:
首先创建一个字典,用来保存每条原始样本对应哪些 feature
python
def postprocess_qa_predictions(examples, features, raw_predictions):
all_start_logits, all_end_logits = raw_predictions
example_id_to_index = {
example_id: i for i, example_id in enumerate(examples["id"])
}
features_per_example = collections.defaultdict(list)
for i, feature in enumerate(features):
example_index = example_id_to_index[feature["example_id"]]
features_per_example[example_index].append(i)接下来开始逐条处理原始样本,遍历当前原始样本对应的所有 feature,逐个处理
python
predictions = {}
for example_index, example in enumerate(examples):
context = example["context"]
valid_answers = []
for feature_index in features_per_example[example_index]:具体取出当前 feature 的三个东西
start_logit:当前 feature 中每个 token 作为答案开始位置的分数
end_logit:当前 feature 中每个 token 作为答案结束位置的分数
offsets:当前 feature 中每个 token 对应原文的字符范围
保存分数最高的前若干个答案起点和答案终点。枚举所有的答案组合,并排除非法情况
python
start_logit = all_start_logits[feature_index]
end_logit = all_end_logits[feature_index]
offsets = features[feature_index]["offset_mapping"]
start_indexes = np.argsort(start_logit)[-1: -n_best_size - 1: -1].tolist()
end_indexes = np.argsort(end_logit)[-1: -n_best_size - 1: -1].tolist()
for start_index in start_indexes:
for end_index in end_indexes:
if start_index >= len(offsets) or end_index >= len(offsets):
continue
if offsets[start_index] is None or offsets[end_index] is None:
continue
if end_index < start_index:
continue
if end_index - start_index + 1 > max_answer_length:
continue通过这些判断之后,当前是一个合法答案区间,下面把 token 位置转换成字符位置,并计算这个候选答案的总分
python
start_char = offsets[start_index][0]
end_char = offsets[end_index][1]
text = context[start_char:end_char]
score = start_logit[start_index] + end_logit[end_index]然后保存这个候选答案,最后选分数最高的那个
python
valid_answers.append({
"score": score,
"text": text
})
if len(valid_answers) > 0:
best_answer = max(valid_answers, key=lambda x: x["score"])
predictions[example["id"]] = best_answer["text"]
else:
predictions[example["id"]] = ""
return predictions返回所有样本的预测答案。格式为:
{
"56be85543aeaaa14008c9063": "Denver Broncos",
"56be85543aeaaa14008c9065": "Carolina Panthers",
"56be85543aeaaa14008c9066": "Santa Clara, California"
}但 evaluate.load("squad") 需要的预测格式是:
{
"id": 样本id,
"prediction_text": 预测答案
}
继续添加:
python
predictions = postprocess_qa_predictions(
eval_examples,
validation_features,
raw_predictions.predictions
)
formatted_predictions = [
{
"id": example_id,
"prediction_text": prediction_text
}
for example_id, prediction_text in predictions.items()
]
references = [
{
"id": example["id"],
"answers": example["answers"]
}
for example in eval_examples
]
metric = evaluate.load("squad")
results = metric.compute(
predictions=formatted_predictions,
references=references
)
print(results)metric = evaluate.load("squad")这一步加载 SQuAD 的评估指标。会计算 exact_match、f1
results = metric.compute(
predictions=formatted_predictions,
references=references
)最后正式计算指标。把模型预测答案和标准答案一一比较,得到结果
text
{'exact_match': 76.0, 'f1': 84.84380470602314}问答任务的模型输出是每个 token 的起点分数和终点分数。评估时必须先根据 start_logits 和 end_logits 枚举候选答案,再过滤非法片段,用 offset_mapping 将 token 位置还原为原文中的答案文本。得到预测文本后,才能与标准答案计算 EM 和 F1。