TSF 微服务熔断实战:从原理到落地,杜绝级联故障
在微服务架构中,一个下游服务故障可能引发「雪崩效应」------ 比如支付服务超时,导致订单服务线程阻塞,进而拖垮整个链路。腾讯微服务框架(TSF)提供的熔断机制,正是解决这一问题的核心手段。本文将从原理、规划、配置到落地,带你吃透 TSF 熔断的全流程实践。
一、为什么需要熔断?
先看一个真实场景:
-
商品服务因数据库宕机响应超时(5s+)
-
订单服务调用商品服务时,线程池被占满
-
前端大量超时重试,订单服务彻底不可用
-
最终波及支付、用户等核心服务,系统全面瘫痪
熔断的核心价值:当下游服务异常时,快速「切断」调用链路,避免故障扩散,同时保留探活恢复能力,待服务正常后自动恢复调用。
二、TSF 熔断核心原理
TSF 熔断基于 Resilience4J 实现(替代老旧的 Hystrix),核心是「状态机 + 精细化控制」,比传统熔断更灵活。
1. 三段式状态机
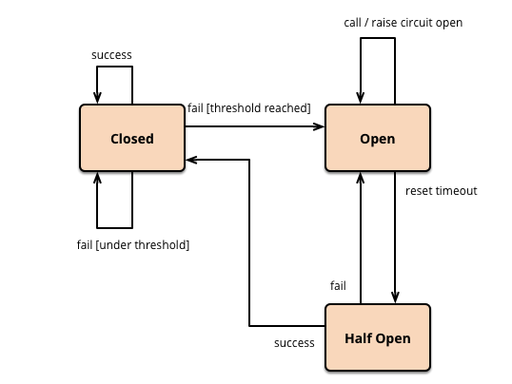
-
Closed(闭合状态):正常放行请求,同时统计滑动窗口内的失败率、慢请求率
-
Open(打开状态):当触发阈值时,直接拒绝请求(快速失败),避免无效等待
-
Half-Open(半开状态):熔断到期后,放行少量请求探活。若成功则恢复闭合,失败则重回打开状态
2. 触发条件(双重保障)
熔断不会轻易触发,需同时满足以下条件:
-
滑动窗口内请求数 ≥ 最小请求数(避免小流量误判)
-
失败率 ≥ 阈值 或 慢请求率 ≥ 阈值
示例:10s 内有 20 个请求,其中 10 个失败(失败率 50%),则触发熔断。
3. 三级隔离级别(TSF 特色)
TSF 支持更精细化的隔离控制,避免「一刀切」:
| 隔离级别 | 作用范围 | 适用场景 |
|---|---|---|
| 服务级 | 整个下游服务 | 非核心服务、全量异常 |
| 实例级 | 单个异常实例 | 部分实例故障(如集群中 1 台机器宕机) |
| API 级 | 单个接口 | 核心服务的特定接口(如支付接口) |
三、熔断规划:按业务分层设计
好的熔断策略不是「一刀切」,而是结合业务重要性差异化配置。
1. 场景分级策略表
| 业务等级 | 隔离级别 | 核心参数配置 | 适用场景 |
|---|---|---|---|
| 核心链路 | API / 实例级 | 失败率 30%、慢率 20%、熔断 10s | 支付、订单创建、用户登录 |
| 通用服务 | API 级 | 失败率 50%、慢率 40%、熔断 30s | 商品查询、地址管理 |
| 非核心服务 | 服务级 | 失败率 60%、熔断 60s | 日志上报、数据统计 |
2. 关键注意点
-
异常分类:仅统计系统异常(5xx、超时、连接拒绝),业务异常(参数错误、规则校验失败)不计入失败率
-
联动机制:熔断需与限流、降级配合 ------ 限流拦截峰值流量,熔断保护异常链路,降级返回兜底数据(如缓存数据)
四、落地实操:3 种配置方式
TSF 支持控制台配置(推荐生产)、YAML 本地配置(联调)、代码配置(灵活扩展),零侵入业务代码。
1. 控制台配置(生产首选)
最便捷的配置方式,支持动态生效,无需重启服务:
-
登录 TSF 控制台 → 进入目标命名空间 → 服务治理 → 服务熔断 → 新建规则
-
基础配置:选择下游服务、隔离级别(如 API 级)
-
策略参数配置(以通用服务为例):
-
滑动窗口:10s(统计周期)
-
最少请求数:10(避免小流量误判)
-
失败率阈值:50%
-
慢请求阈值:3000ms、慢率阈值 40%
-
熔断时长:30s(Open 状态持续时间)
-
半开放行比例:10%(探活请求占比)
- 高级配置:指定 API 路径(如
/api/goods/detail),仅对该接口生效
2. YAML 本地配置(开发联调)
本地开发时,可通过 application.yml 配置,快速测试效果:
tsf:
circuit-breaker:
rules:
- targetServiceName: goods-service # 下游服务名
targetNamespaceId: default # 命名空间
isolationLevel: API # 隔离级别
slidingWindowSize: 10 # 滑动窗口(s)
minimumNumberOfCalls: 10 # 最小请求数
failureRateThreshold: 50 # 失败率阈值(%)
waitDurationInOpenState: 30 # 熔断时长(s)
slowCallDurationThreshold: 3000 # 慢请求阈值(ms)
slowCallRateThreshold: 40 # 慢请求率阈值(%)
maxEjectionPercent: 50 # 实例级最大熔断比例
strategyList:
- path: /api/goods/detail # 仅对该接口生效
feign:
hystrix:
enabled: false # 关闭Hystrix,避免冲突3. 降级兜底(Fallback)
熔断触发后,为了给用户友好反馈,可配置降级逻辑(可选):
// 1. Feign客户端接口
@FeignClient(name = "goods-service", fallback = GoodsFallback.class)
public interface GoodsClient {
@GetMapping("/api/goods/detail")
Result getGoodsDetail(@RequestParam("id") Long id);
}
// 2. 降级实现类
@Component
public class GoodsFallback implements GoodsClient {
@Override
public Result> getGoodsDetail(Long id) {
// 返回兜底数据(如缓存数据、默认值)
GoodsDTO defaultGoods = new GoodsDTO();
defaultGoods.setId(id);
defaultGoods.setName("商品暂时无法获取");
return Result.success(defaultGoods);
}
}五、监控与运维:熔断效果可视化
1. 核心监控指标
TSF 控制台提供完善的监控面板,重点关注:
-
熔断器状态分布(Closed/Open/Half-Open)
-
失败率、慢请求率实时曲线
-
熔断触发次数、恢复时间
-
实例熔断比例(实例级隔离时)
2. 告警配置
为避免故障漏报,建议配置以下告警:
-
熔断触发次数 > 5 次 / 10min → 短信 / 企业微信告警
-
实例熔断比例 > 50% → 紧急告警(需人工介入)
-
半开状态连续失败 > 3 次 → 升级告警
3. 常见问题排查
| 问题现象 | 排查方向 |
|---|---|
| 熔断不生效 | 1. 未关闭 Hystrix;2. 规则未发布到目标命名空间;3. 流量未达到最小请求数 |
| 误熔断 | 1. 最小请求数设置过小;2. 慢请求阈值设置过严;3. 业务异常被计入失败率 |
| 恢复缓慢 | 1. 熔断时长设置过长;2. 半开放行比例过低 |
六、最佳实践总结
-
核心接口必配 API 级熔断:避免因单个接口故障影响整个服务
-
压测校准阈值:通过压测获取正常服务的失败率、响应时间基线,阈值设置为基线 + 20% 冗余
-
灰度发布规则:新熔断规则先在测试环境验证,再灰度到生产
-
定期复盘:分析熔断事件日志,优化阈值配置(如调整慢请求阈值、最小请求数)
-
避免过度配置:非核心服务无需配置过细规则,避免增加运维成本
结语
TSF 熔断机制通过简单的配置,即可实现微服务链路的稳定性保障,核心是「精准触发、快速恢复、最小影响」。在实际落地时,需结合业务场景差异化设计,同时联动限流、降级机制,形成完整的服务治理体系。
如果你的项目正在使用 TSF,不妨从核心接口开始试点熔断配置,逐步完善服务治理能力。如果需要根据具体业务接口生成专属配置模板,欢迎留言交流!