我经常听到刚接触数据分析的人的抱怨:"SQL要学,Python要学,报表要做,汇报还要写,感觉门槛高得吓人。"
但真相是,SQL和Python更多是数据挖掘工具,PPT、BI不过是数据展示手段。学会了当然好,不会也别慌,因为数据分析的核心从来不是技术,而是思维。
真正厉害的数据分析,是帮你梳理业务、找到方向、解决问题。这并不需要你懂所有技术,只需要记住3个步骤,掌握3个模型,就能轻松上手。
今天,我就把这3个步骤和3个模型讲清楚,直接帮你建立这套思维习惯!
开始之前分享一下我整理的一份数据分析流程知识图谱 ,需要可自取。内含数据分析多个常见分析模型、理论分支、详细知识要点和实际分析场景案例,不懂或不记得的知识点拿出地图就能查,数据人必备!https://s.fanruan.com/t2dhe(复制到浏览器)
一、3个步骤
我一直认为真正有效的分析,第一步永远不是看报表,而是先把目标拆清楚。这里就有一套很实用的思路:确定目标------列出公式------确认元素。
1.确定目标
分析之前,可以先问问自己:这次最想改善的结果是什么。
是增长销售额,是提升转化率,是提高复购,还是降低流失。因为不同的目标会导致完全不一样的分析路径。
我们举个例子吧,假设一家连锁烘焙品牌最近最关心的是营业额增长。那这次分析就不能泛泛地看用户、看门店、看商品,而是要围绕营业额这个核心结果去拆。
目标一旦定清楚,后面看什么数据、做什么分析、提什么动作,才不会跑偏。
2.列出公式
目标确定之后,下一步不是继续盯着结果看,是要把结果拆开。
因为任何一个业务结果,背后都不是凭空发生的,它一定由几个关键因素共同决定。
还拿连锁烘焙品牌举例。如果核心目标是营业额,那营业额大致可以拆成到店人数、下单转化率、客单价这几个部分。再往下拆,客单价又可能受套餐购买率、加购率、单次购买件数影响。
你会发现,一旦把目标拆成公式,原本模糊的问题就开始变具体了。
营业额上不去,到底是客流不够,还是进店的人很多但下单少,还是下单了但买得不够多。
这一步的价值就在于,它能帮你从结果走到原因。
3.确认元素
目标拆完以后,还不能马上开始做动作。因为公式里不是每个元素都值得你下手。
有些因素你能直接影响,有些却未必。
继续用刚才的例子。营业额拆开之后,有些门店可能会发现,客单价主要受商品结构影响,下单转化率更多跟导购话术、活动力度、收银效率有关,而到店人数则可能和商圈位置、投放曝光、天气变化相关。
这时候就要继续判断,哪些元素是当前阶段最值得优先发力的。
这一步说白了,就是找到真正的发力点。
做到这里,其实分析已经成功一半了。
因为你已经不是在模糊地讨论数据,而是在清楚地思考并尝试回答这三个问题了:
- 我的目标是什么
- 我想要到结果由什么组成
- 现阶段我应该最先从哪开始行动
这一套3个步骤的思路教会你的不是教你怎么做图表,而是能够真正帮你把问题拆成能行动的东西。
二、3个模型
当你用前三个步骤找到关键元素后,接下来就会进入真正的实战阶段。
这个时候,通常会遇到三个最常见的问题:
- 关键指标怎么做上去
- 如何给不同对象分配不同资源
- 怎么判断策略到底有没有效果
而这三个问题,正好对应三种特别常用的分析模型。它们分别是漏斗模型、多维坐标、分组表格。在理解这三个模型时最重要的是要明白它们分别适合解决什么问题。
1.漏斗模型
漏斗模型专门解决那些需要经过多步才能完成的结果问题。
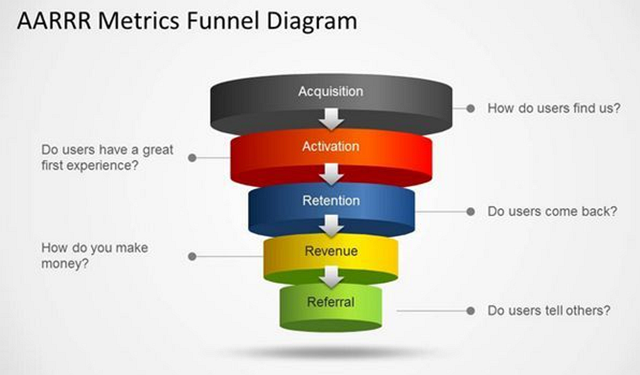
比如在线教育平台想提升试听变转正的比例,用户需要从浏览课程内容、预约试听、填写信息、参与试听课到最后付费报名,一步步走下来,每个环节都会有人流失。
这个时候,漏斗模型能帮你找到问题的关键在哪。
比如内容页访问量很大,但预约试听的人却很少,可能是课程吸引力不够或者预约入口太隐蔽。如果预约人数都不错,但到课的人很少,可能提醒不到位或者时间安排不贴合。如果试听课参加率挺高,但真正付费的人还不够,那问题可能就在课程定价、设计内容或者顾问跟进上。
它的价值就在于,让你不再泛泛地说"转化差",而是清楚地知道问题到底卡在吸引、承接还是成交上。
漏斗分析不仅能提升单层转化,还能优化整条用户路径。
有时候转化率低,并不是某一步有问题,而是整个流程太复杂。比如用户想领优惠券,还得先关注账号、再注册会员、填写资料,然后再点开活动页。走太多步,很多人根本没坚持到最后。这种情况下,与其死抠每一步转化率,不如直接把流程简化,环节少了,效果更好。
所以,**漏斗模型特别适合用来提转化、提规模、找关键问题。**只要你的目标要经过多个步骤达成,漏斗分析就可以派上大用场。
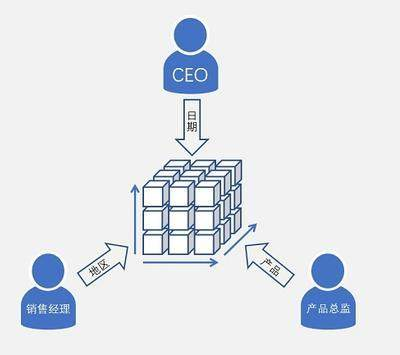
2.多维坐标
如果说漏斗模型解决的是过程中的转化问题,那多维坐标解决的就是分层运营的问题。
现实中,最忌讳的就是把用户、商品、门店这些对象都当成同一类来对待。每个对象的特征、价值和潜力都不一样,硬套统一策略,不仅资源浪费,效果也不会好。这个时候,多维坐标就能帮你把对象清晰分层,再因人而异地制定策略。
来看看一个例子。
一家母婴电商平台在做会员运营时,单看消费金额,只知道谁买得多;单看购买频次,只知道谁来得勤。这两个维度如果单独看,信息不完整。但当这两个维度放在一起,用户差异立马显现。
高消费高频次的用户是平台最核心的人群。高消费低频次的用户价值也很高,但习惯还不够稳定。低消费高频次的用户黏性不错,但还有提升空间。至于低消费低频次的用户,大多是普通用户或待激活人群。
这时候,分层后的运营策略会明显不同。
对于高消费高频次用户,重点是维护,确保他们长期留在平台。高消费低频次用户,可以通过会员日活动,慢慢培养消费习惯。低消费高频次用户更适合做套餐推荐或连带促销,提升每单金额。而低消费低频次用户,适合先筛查,再决定是否要重点激活,避免浪费资源。
多维坐标最大的价值就在这里。它不是为了单纯分四类看着好,而是帮助你精准投放资源,让每一次动作都更加高效、精准。
因此,**多维坐标特别适合用来解决分层运营、资源分配和策略优先级判断的问题。**只要你面对的对象有两个或更多维度需要考虑,这个方法都能派上用场。
3.分组表格
有时候做数据分析会发现,前期拆解目标、找到问题都没毛病,但最后却卡在了验证上。那么此时就需要分组表格上场了,它特别适合用来分析那种会随时间变化的指标,比如留存、复购、活跃、回访这些。
它的核心思路很简单,就是把同一时间进入系统的对象分成一组,然后观察这组人在接下来的表现。
举个例子,一家健身平台想分析新用户的留存情况,可以把每周新开卡的用户分组。第一周开卡的用户是一组,第二周的是另一组。然后分别观察这些组的数据,比如到店率、续费率、课程完成率。
这样分析,和只看整体总量完全是两回事。
如果你发现某段时间活跃度飙升,可能是因为新客量暴增,也可能是老用户回流,还可能上周的留存更好了。数据只看总量,很难判断具体原因,但一旦分组后,你就能看清问题出在哪。
分组表格让你可以横向看单组用户随时间的表现,了解生命周期走势;也可以纵向看某一时间点的整体数据,搞明白它是由哪些批次构成的。
分组表格的厉害之处在于,它能把原本复杂的数据变化拆开,让问题清晰可见。
因此,**分组表格是用来监测变化、验证策略效果和识别趋势的利器。**如果你要判断一个策略是否有效,分组表格几乎是一个绕不过去的工具。
三、高效落地
看到这里,你可能会不禁心想,上面的三个步骤和三个模型看起来都挺简单的,我也认同这个观点,因为我一直都觉得真正难的其实是落地。
原因很简单,因为在真实业务里,卡住分析的地方往往不是思路,而是流程。这时候想要高效地落地,除了方法,还得有一套能支撑落地的工具和流程。
我认为一个比较通畅的做法,就是固定一套分析流程:
- 先把目标拆成指标,再把指标对应到数据源
- 再把关键链路搭起来,做成可重复使用的主题分析
- 最后把结果沉淀成图表、看板和分析结论,让团队能持续看、持续用
这个时候,自助式 BI 工具 的优势就开始显现了。比如FineBI ,它特别适合连接数据和业务,帮团队把繁琐的分析工作变得更轻松高效。日常做联合分析时,经常需要把销售、库存、会员、活动等多个表的数据整合到一起,这一步很多人觉得麻烦。这时FineBI 就可以通过公共字段就能快速建立数据模型,把分散的数据整合成一个完整的分析视图。这样一来,业务人员做下一步分析时,就会省去了大量手工拼表的复杂步骤,整体工作效率就会提升很多:https://s.fanruan.com/0j1bm(复制到浏览器)
四、总结
这套框架里的三个步骤和三个模型,已经足够应对大多数日常工作场景了。我建议大家先把它吃透,用到自己的业务里。至于其他更复杂的技巧,留着日后遇到新问题再深入学习。相信等你真正掌握了这三个步骤和三个模型,那些原本看起来杂乱无章的数据就会变得清晰、有逻辑,还能转化成具体的行动。这才是数据分析最大的意义。