目录
[二、list 的迭代器](#二、list 的迭代器)
[2.1 迭代器类别](#2.1 迭代器类别)
[三、简述 emplace_back 接口](#三、简述 emplace_back 接口)
[四、list 特色接口使用细节](#四、list 特色接口使用细节)
[4.1 简单接口概述](#4.1 简单接口概述)
[4.2 细讲 splice 接口](#4.2 细讲 splice 接口)
[五、list 的排序效率问题](#五、list 的排序效率问题)
一丶list是什么
list 是定义于<list>头文件下的 STL 序列式容器,以类模板的形式实现。从底层结构来看,list 的本质是带头结点的双向循环链表。


list支持在常数时间O(1) 内完成任意位置的插入与删除操作 ,执行效率极高。但受链表内存空间不连续的底层结构限制,list原生不支持operator\[\]随机访问。若手动封装实现operator\[\]接口,其时间复杂度会从O(1)退化为O(N),因为必须遍历链表节点才能定位到目标元素。
二、list 的迭代器
2.1 迭代器类别
STL 迭代器分为五大类别,不同类别支持的运算操作不同,list迭代器的核心特性可通过下表清晰区分:
| 迭代器类别 | ++ | -- | + | - |
|---|---|---|---|---|
| Input(输入迭代器) | ✔ | ✘ | ✘ | ✘ |
| Output(输出迭代器) | ✔ | ✘ | ✘ | ✘ |
| Forward(单向迭代器) | ✔ | ✘ | ✘ | ✘ |
| Bidirectional(双向迭代器) | ✔ | ✔ | ✘ | ✘ |
| Random Access(随机访问迭代器) | ✔ | ✔ | ✔ | ✔ |
list底层为双向链表,其迭代器属于Bidirectional(双向迭代器),仅支持前后单向遍历(++/--),不支持随机访问运算(+/-)。
迭代器分为多种类别,上文已完整列举。vector的迭代器属于随机访问迭代器 ,支持 ++、--、+、- 等多种随机访问操作。与vector、string 不同,list底层内存空间不连续 ,其迭代器并非简单的原生指针封装。因此,作为双向链表实现的list,迭代器为双向迭代器,仅支持 ++ 和 -- 遍历,不支持 +、- 这类随机访问运算。

因为list用的是双向迭代器,不支持随机跳转,所以它没法像vector那样,直接把迭代器挪到中间去插入数据。
cpp
auto it = lt.begin();
int k = 3;
while (k--)
++it;
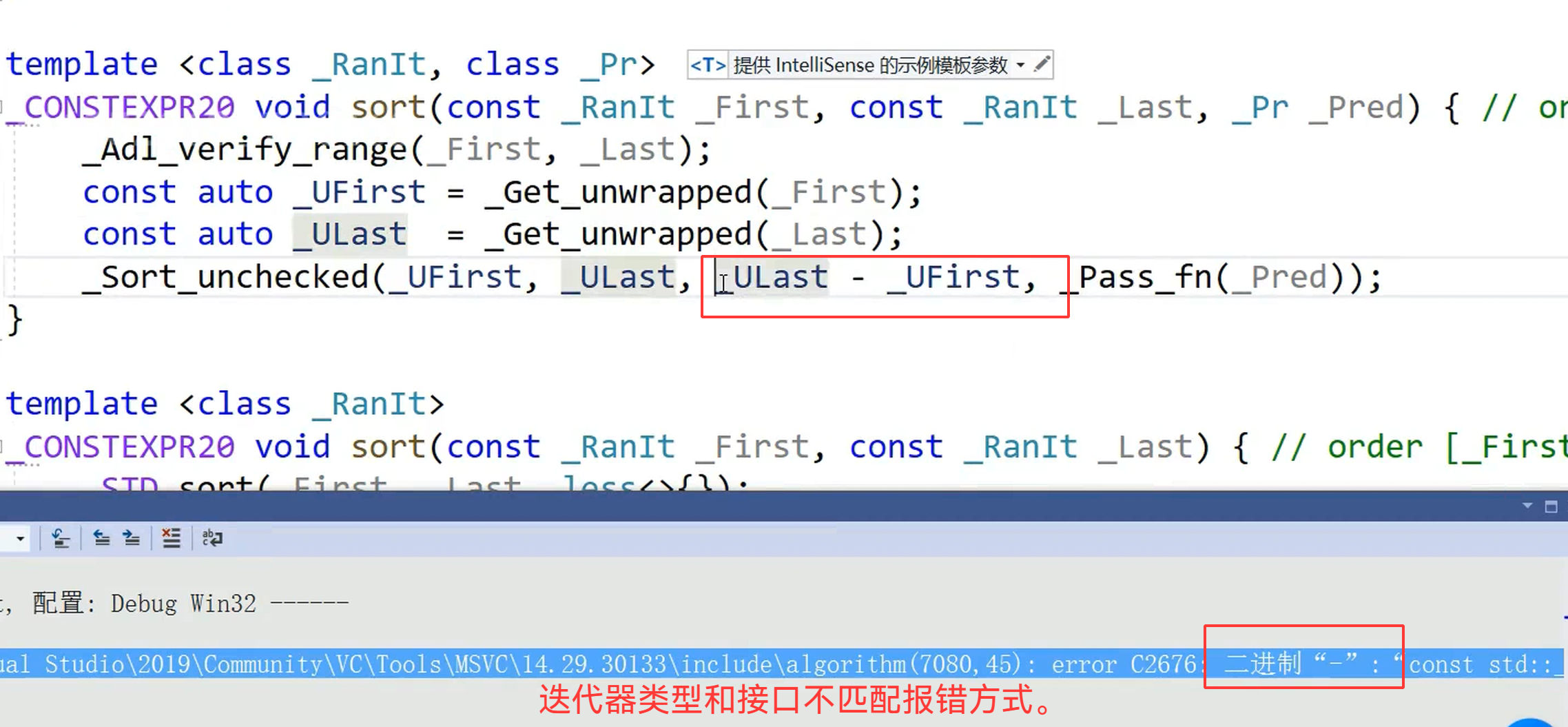
lt.insert(it, 30);迭代器的类型,其实会直接限制容器能调用哪些接口。我们拿两个典型例子来说。首先是标准库的 sort 排序算法,它底层实现需要频繁用operator\[\]这类随机访问操作,所以只支持随机访问迭代器。

我们看看sort的底层代码:如你所见,使用了 - 操作符,自然不支持。
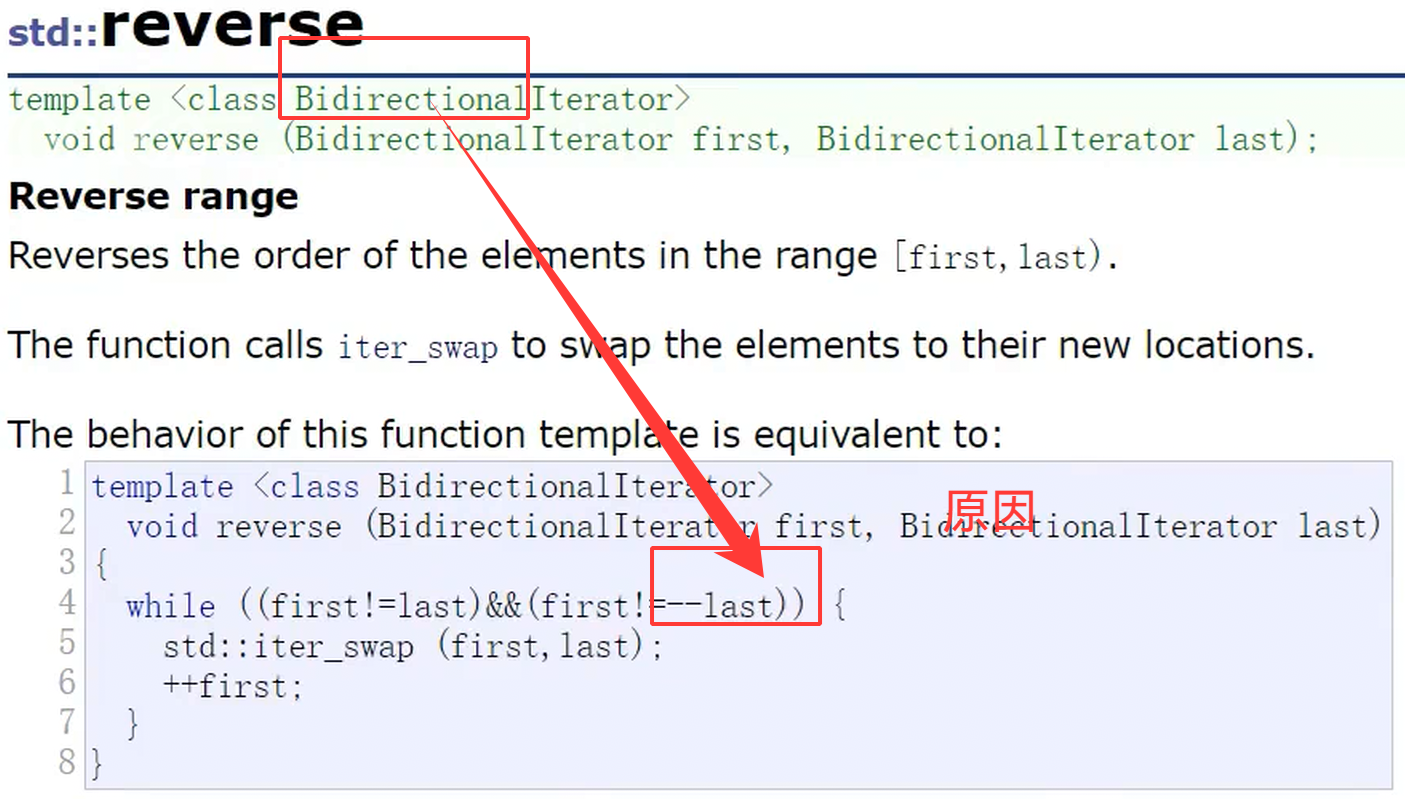
第二个例子就是reverse逆序算法 。它的底层实现需要用到**--**操作,所以只要求迭代器能够双向移动,也就只需要支持双向迭代器就够了。
这里还要分清直接支持和间接支持的区别:
- 直接支持:reverse本身就是直接面向双向迭代器设计的;
- 间接支持:随机访问迭代器本身也完全支持 -- 操作,所以reverse也同样可以兼容随机迭代器。
一个迭代器能不能被某个接口正常使用,说到底,还是看接口底层到底需要哪些迭代器操作。
其实我们可以把它们理解成一层包含的关系:双向迭代器本身就是一种特殊的单向迭代器,而随机访问迭代器,又是一种特殊的双向迭代器、单向迭代器。
这和面向对象里的继承逻辑很像,子类本身就是一种特殊的父类。虽然标准库没有用类继承明确定义迭代器类型,但一个迭代器完全可以传递给要求它上层任意 "父类" 迭代器的接口使用。
三、简述 emplace_back 接口
emplace_back是C++11推出的新接口,我们这里先简单提一下:它的用法和 push_back 完全一样,日常使用中绝大多数场景下效率也基本一致。接下来我们重点说说两者的核心区别:
cpp
list<A> lt;
A aa1(1, 1);
lt.push_back(aa1);
lt.push_back(A(2,2));
lt.push_back(3, 3);
lt.emplace_back(aa1);
lt.emplace_back(A(2,2));
lt.emplace_back(3, 3);这里假设A是一个提前定义好、包含两个成员变量的类。向容器中插入元素时,push_back有两种常用写法:传入已定义的有名对象,或是传入临时匿名对象 。而emplace_back还多出第三种用法:直接传入参数,在容器原地构造对象。
emplace_back在前两种插入方式下,效率和push_back基本持平;但在第三种方式中,它会比push_back更高效,而push_back本身并不支持这种用法。原因很简单:emplace_back(3, 3)是直接在容器空间内构造出A对象,而push_back的两种写法都需要先构造对象,再通过拷贝构造(或移动)将其放入容器,多了一步额外开销。
四、list 特色接口使用细节
4.1 简单接口概述
- swap:为规避std::swap拷贝数据带来的低效问题,list重载了 swap接口,底层仅交换两个链表的头指针,无任何数据拷贝,效率极高;
- find:list 未实现专属的查找成员函数,查找元素需调用标准库通用算法std::find;
- merge:用于合并两个有序链表,底层采用归并排序的双指针遍历逻辑,依次选取较小元素插入目标链表,合并完成后,被合并的源链表会变为空链表;
- unique:链表去重接口,必须要求链表有序,因底层仅会判断相邻节点是否重复;
- splice:名义上是拼接接口,本质为节点的剪切转移,是list的特色核心接口,我们会展开详细讲解;
- reverse:用于对链表进行原地翻转操作;
- remove:根据元素的具体值,直接删除容器中匹配的节点;
- remove_if:根据自定义的条件规则,删除满足条件的节点。
代码示例
cpp
#include <iostream>
#include <list>
#include <algorithm> // 包含 std::find
using namespace std;
template <class T>
void print_list(const list<T>& lt, const string& name) {
cout << name << ": ";
for (const auto& x : lt) cout << x << " ";
cout << endl;
}
int main() {
cout << "swap" << endl;
list<int> lt1 = {1, 2, 3};
list<int> lt2 = {10, 20, 30};
print_list(lt1, "交换前 lt1");
print_list(lt2, "交换前 lt2");
lt1.swap(lt2); // 仅交换头指针,无数据拷贝
print_list(lt1, "交换后 lt1");
print_list(lt2, "交换后 lt2");
cout << endl;
cout << "std::find" << endl;
list<int> lt_find = {10, 20, 30, 40};
auto it = find(lt_find.begin(), lt_find.end(), 30);
if (it != lt_find.end()) {
cout << "找到元素: " << *it << endl;
} else {
cout << "未找到元素" << endl;
}
cout << endl;
cout << "merge" << endl;
list<int> lt_m1 = {1, 3, 5}; // 必须有序
list<int> lt_m2 = {2, 4, 6}; // 必须有序
print_list(lt_m1, "合并前 lt_m1");
print_list(lt_m2, "合并前 lt_m2");
lt_m1.merge(lt_m2); // 归并合并,lt_m2 变为空
print_list(lt_m1, "合并后 lt_m1");
print_list(lt_m2, "合并后 lt_m2");
cout << endl;
cout << "unique" << endl;
list<int> lt_u = {1, 1, 2, 2, 2, 3, 3}; // 必须有序
print_list(lt_u, "去重前 lt_u");
lt_u.unique(); // 仅去除相邻重复元素
print_list(lt_u, "去重后 lt_u");
cout << endl;
cout << "splice" << endl;
list<int> lt_s1 = {1, 2, 3};
list<int> lt_s2 = {10, 20, 30};
print_list(lt_s1, "拼接前 lt_s1");
print_list(lt_s2, "拼接前 lt_s2");
//拼接整个 lt_s2 到 lt_s1 末尾
lt_s1.splice(lt_s1.end(), lt_s2);
print_list(lt_s1, "拼接整个 lt_s2 后 lt_s1");
print_list(lt_s2, "拼接整个 lt_s2 后 lt_s2 (已空)");
//重新创建 lt_s2,拼接单个节点
lt_s2 = {100, 200};
auto it_s = lt_s2.begin();
lt_s1.splice(lt_s1.begin(), lt_s2, it_s);
print_list(lt_s1, "拼接单个节点后 lt_s1");
print_list(lt_s2, "拼接单个节点后 lt_s2");
cout << endl;
cout << "reverse" << endl;
list<int> lt_r = {1, 2, 3, 4, 5};
print_list(lt_r, "翻转前 lt_r");
lt_r.reverse(); // 原地翻转
print_list(lt_r, "翻转后 lt_r");
cout << endl;
cout << "remove" << endl;
list<int> lt_rm = {1, 2, 3, 2, 4, 2};
print_list(lt_rm, "按值删除前 lt_rm");
lt_rm.remove(2); // 删除所有值为 2 的节点
print_list(lt_rm, "按值删除后 lt_rm");
cout << endl;
cout << "remove_if" << endl;
list<int> lt_rmif = {1, 2, 3, 4, 5, 6};
print_list(lt_rmif, "条件删除前 lt_rmif");
// 删除所有大于 3 的元素
lt_rmif.remove_if([](int val) { return val > 3; });
print_list(lt_rmif, "条件删除后 lt_rmif");
return 0;
}4.2 细讲 splice 接口
splice是list独有的核心特色接口,它的本质是节点的剪切与转移 ,全程不发生任何数据拷贝、构造和析构 ,仅通过修改链表指针完成操作,时间复杂度为 O (1),效率极高。该接口主要支持两种使用方式:
- 跨链表操作:将一个list中的节点,剪切到另一个list的指定位置前方;
- 自身内部操作:将当前list自身的节点,剪切到自身的指定位置前方。

cpp
int main ()
{
std::list<int> mylist1, mylist2;
std::list<int>::iterator it;
// set some initial values:
for (int i=1; i<=4; ++i)
mylist1.push_back(i); // mylist1: 1 2 3 4
for (int i=1; i<=3; ++i)
mylist2.push_back(i*10); // mylist2: 10 20 30
it = mylist1.begin();
++it; // points to 2
mylist1.splice (it, mylist2); // mylist1: 1 10 20 30 2 3 4
// mylist2 (empty)
// "it" still points to 2 (the 5th element五、list 的排序效率问题
测试list的排序效率时,必须在Release模式下进行测试 ,千万不要用Debug版本。因为Debug模式会附带大量调试信息、关闭编译器优化,会严重干扰测试结果,无法体现容器真实的运行效率。

在Release版本下,两者的效率表现会截然不同!即便使用相同的排序算法,vector的排序速度也会远超list。
核心原因就是缓存利用率:
- list 的内存空间不连续,CPU缓存命中率极低,每次只能读取一个节点到缓存中,后续访问需要反复重新加载,效率大打折扣;
- 而vector内存连续,缓存可以一次性加载大量数据,充分利用高速缓存,性能优势非常明显。
最优的解决办法也很简单:先把list的数据拷贝到vector中完成排序,排序结束后再拷贝回 list。听起来是两次数据拷贝会有开销,但实际测试中,整体效率反而能直接提升两倍以上。

cpp
#include <iostream>
#include <vector>
#include <list>
#include <algorithm>
#include <ctime>
using namespace std;
const int DATA_SIZE = 1800000;
int main()
{
srand((unsigned int)time(NULL));
vector<int> origin_data;
origin_data.reserve(DATA_SIZE);
for (int i = 0; i < DATA_SIZE; ++i)
{
origin_data.push_back(rand());
}
// vector排序测试
vector<int> v(origin_data.begin(), origin_data.end());
clock_t start = clock();
sort(v.begin(), v.end());
clock_t end = clock();
int vec_time = (int)((double)(end - start) / CLOCKS_PER_SEC * 1000);
cout << "vector sort:" << vec_time << " debug" << endl;
// Release模式 cout << "vector sort:" << vec_time << " release" << endl;
// list排序测试
list<int> lt(origin_data.begin(), origin_data.end());
start = clock();
lt.sort();
end = clock();
int list_time = (int)((double)(end - start) / CLOCKS_PER_SEC * 1000);
cout << "list sort:" << list_time << endl;
list<int> lt_opt(origin_data.begin(), origin_data.end());
start = clock();
vector<int> tmp(lt_opt.begin(), lt_opt.end());
sort(tmp.begin(), tmp.end());
lt_opt.assign(tmp.begin(), tmp.end());
end = clock();
int opt_time = (int)((double)(end - start) / CLOCKS_PER_SEC * 1000);
cout << "list copy vector sort copy list sort:" << opt_time << endl;
list<int> lt2(origin_data.begin(), origin_data.end());
start = clock();
lt2.sort();
end = clock();
int list_time2 = (int)((double)(end - start) / CLOCKS_PER_SEC * 1000);
cout << "list sort:" << list_time2 << endl;
return 0;
}