题意: 给你一个非严格递增排列 的数组 nums ,请你原地删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的相对顺序应该保持一致 。然后返回 nums 中唯一元素的个数。考虑 nums 的唯一元素的数量为 k。去重后,返回唯一元素的数量 k。 nums 的前 k 个元素应包含排序后的唯一数字。下标 k - 1 之后的剩余元素可以忽略。
题目链接:hhttps://leetcode.cn/problems/remove-duplicates-from-sorted-array/
视频链接:https://www.bilibili.com/video/BV1fc2FByE4f/
一、看到题目的第一想法
这是一道典型的有序数组去重 题,核心思路是双指针法(快慢指针):
- 暴力解法:新建一个数组,遍历原数组,把不重复的元素存进去,时间复杂度 O (n),空间复杂度 O (n),不符合题目 "原地修改" 的要求。
- 最优思路:快慢指针 ,原地修改,时间复杂度 O (n),空间复杂度 O (1)。
fast(快指针):遍历整个数组,负责找 "新的、不重复的元素"slow(慢指针):记录下一个 "不重复元素" 应该放的位置- 因为数组是有序的,重复元素一定是连续的,所以只要和前一个元素比较就能判断是否重复。
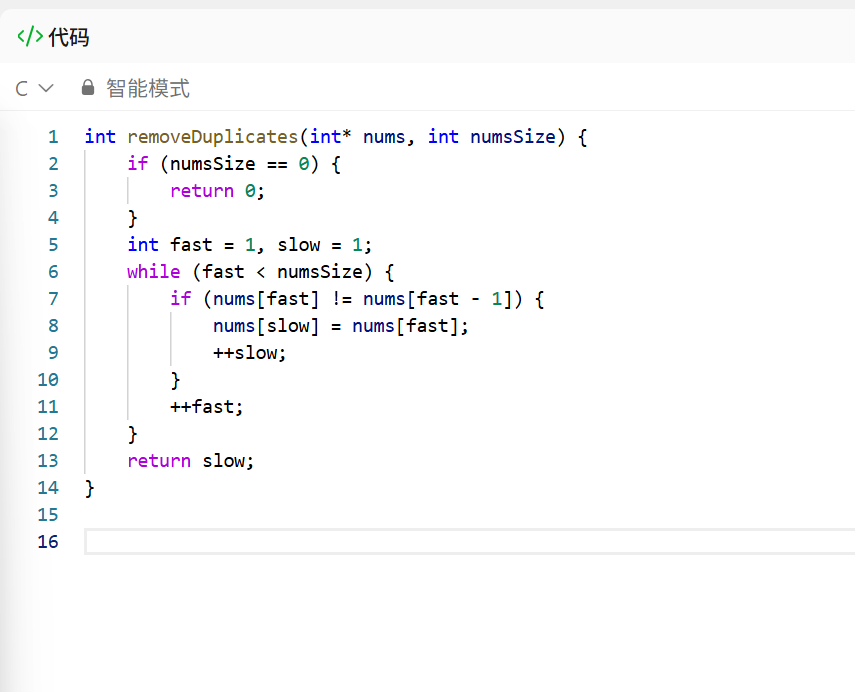
二、实现过程中遇到的困难
这里你提到了 "哈希表实现",但这道题其实用双指针是最优解,哈希表反而会增加空间复杂度,所以这里我分两部分说:
1. 双指针实现的坑
- 指针初始化错误 :一开始可能会把 slow 初始化为 0,或者 fast 从 0 开始,导致逻辑混乱。
- 比如 slow=0,fast=0,会把第一个元素也重复比较一次,逻辑上虽然能跑,但不符合 "第一个元素默认唯一" 的优化思路。
- 边界情况处理 :
- 数组为空
numsSize=0时,直接返回 0,否则nums[fast-1]会越界。 - 数组长度为 1 时,循环不会执行,直接返回 slow=1,是正确的。
- 数组为空
nums[fast] != nums[fast-1]的判断逻辑 :- 一开始可能会写成
nums[fast] != nums[slow-1],这也是正确的,但nums[fast-1]更直接,因为数组是有序的,fast 前面的元素一定是已经处理过的。
- 一开始可能会写成
2. 哈希表实现的问题
这道题如果用哈希表,会有几个问题:
- 空间复杂度从 O (1) 变成 O (n),不符合题目 "原地修改" 的隐含最优解要求。
- 哈希表实现需要手动处理
uthash库,和你之前两数之和的问题类似,会遇到:- 结构体必须包含
UT_hash_handle成员。 - 哈希表的插入、查找、删除操作的 API 不熟悉,容易传错参数。
- 内存管理问题,每次插入元素都要
malloc,不释放会导致内存泄漏。
- 结构体必须包含
- 而且,因为数组是有序的,哈希表的优势(O (1) 查找)在这里完全体现不出来,反而增加了实现难度。
三、今日收获心得
- 有序数组的特性是解题关键:题目给的是 "非严格递增" 数组,重复元素一定是连续的,所以不需要用哈希表,直接用双指针和前一个元素比较就能判断是否重复,空间复杂度降到 O (1)。
- 快慢指针是有序数组去重的通用模板:不仅可以做 "保留 1 个重复元素",还可以拓展到 "保留 2 个重复元素"(比如 LeetCode 80),只需要修改判断条件即可。
- 边界情况是代码健壮性的关键 :空数组、长度为 1 的数组、全重复的数组(如
[2,2,2])都要提前考虑到,否则会出现越界或逻辑错误。 - 不要盲目追求哈希表:哈希表是解决无序数组问题的利器,但在有序数组的场景下,双指针往往更优,要学会根据题目条件选择合适的算法。