0 引言
预期寿命是衡量一个国家或地区人口健康状况与社会发展水平的核心综合指标, 综合体现医疗卫生、人民健康、生活质量和社会发展状况,是联合国人类发展指数的三个合成指标之一1。随着全球可持续发展目标的推进,理解并预测预期寿命的变化趋势,对于制定科学的卫生政策、优化资源配置以及促进社会公平具有重要意义。
传统预期寿命预测方法主要包括机器学习方法(如多元线性回归、随机森林、支持向量机)和神经网络(如多层感知器)。其中,线性模型虽具有结构简单、可解释性强的优势,但受限于线性假设,难以有效处理预期寿命预测中多影响因素(如经济水平、医疗资源、公共卫生政策、人口结构等)间复杂的交互作用与非平稳动态关系,易导致预测结果出现系统性偏差;而传统神经网络模型虽突破了线性假设的束缚,能够捕捉变量间的复杂非线性关联,但其核心依赖节点权重的迭代更新实现特征学习,对人口政策调整、突发公共卫生事件等导致的结构突变数据适应性较差,泛化能力有限。
近年来,Kolmogorov--Arnold Network(KAN)2作为一种受Kolmogorov--Arnold表示定理启发的全新网络架构,通过将非线性变换显式编码于边激活函数而非节点权重,在保持高表达效率的同时,显著提升了模型对复杂函数结构的适应能力。KAN不仅能够自然处理变量间的交互作用与非平稳关系,还可通过稀疏正则化与符号回归提取解析形式的预测规律,为预期寿命建模提供了新范式。鉴于此,本文引入KAN构建预期寿命预测模型,旨在超越传统方法与常规神经网络的局限,实现对预期寿命的精准预测。
目录
[0 引言](#0 引言)
[1 数据](#1 数据)
[1.1 数据可视化](#1.1 数据可视化)
[2 KAN模型](#2 KAN模型)
[3 实验](#3 实验)
[4 结果与讨论](#4 结果与讨论)
[4.1 KAN模型训练损失变化](#4.1 KAN模型训练损失变化)
[4.2 KAN模型与MLP、MLR、RF、SVM的对比分析结果](#4.2 KAN模型与MLP、MLR、RF、SVM的对比分析结果)
[4.3 与已有研究进行对比分析结果](#4.3 与已有研究进行对比分析结果)
1 数据
本文数据来源于Kaggle平台整理的预期寿命数据集,共包含18个特征指标。分别是(1)Unemployment(失业率);(2)GDP(国内生产总值);(3)GNI(国民总收入);(4)Per Capita(人均指标,通常搭配 GDP/GNI 使用);(5)Urban population(城镇人口 );(6)Rural population(农村人口);(7)Infant Mortality(婴儿死亡率);(8)Clean fuels and cooking technologies(清洁燃料与烹饪技术);(9)Basic sanitation services(基础卫生服务);(10)Mortality caused by road traffic injury(道路交通伤害死亡率);(11)Tuberculosis Incidence(结核病发病率);(12)Tuberculosis treatment(结核病治疗覆盖率 / 完成率);(13)Non-communicable Mortality(非传染性疾病死亡率);(14)Sucide Rate(自杀率);(15)DPT Immunization(百白破疫苗接种率);(16)HepB3 Immunization(乙肝 3 针疫苗接种率);(17)Measles Immunization(麻疹疫苗接种率);(18)Hospital beds(医院床位数 / 每千人床位数)。
数据链接: 预期寿命数据集
数据处理代码:
python
import pandas as pd
import os
base_path = r"data\impv\without_pca"
train_path = os.path.join(base_path, "X_train.csv")
test_path = os.path.join(base_path, "X_test.csv")
df_train = pd.read_csv(train_path)
df_test = pd.read_csv(test_path)
df_combined = pd.concat([df_train, df_test], axis=0, ignore_index=True)
output_path = os.path.join(base_path, "X_combined.csv")
df_combined.to_csv(output_path, index=False)
y_train_path = os.path.join(base_path, "y_train.csv")
y_test_path = os.path.join(base_path, "y_test.csv")
df_y_train = pd.read_csv(y_train_path)
df_y_test = pd.read_csv(y_test_path)
df_y_combined = pd.concat([df_y_train, df_y_test], axis=0, ignore_index=True)
output_y_path = os.path.join(base_path, "y_combined.csv")
df_final = pd.concat([df_combined, df_y_combined], axis=1)1.1 数据可视化
(1)直方图
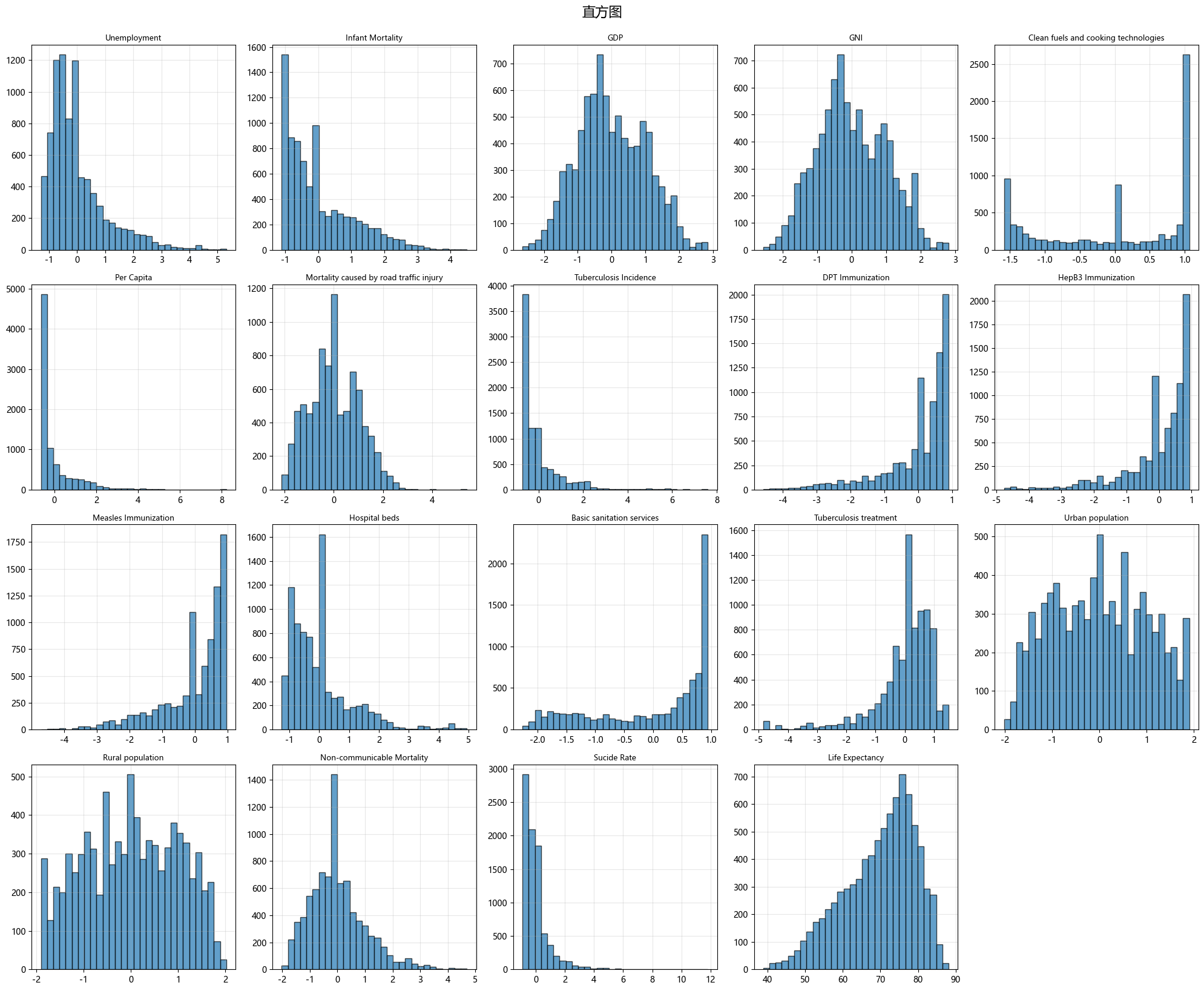 图1 预期寿命数据集各指标的直方分布图
图1 预期寿命数据集各指标的直方分布图
代码:
python
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
total_cols = len(df_final.columns)
rows = (total_cols + 4) // 5
cols = 5
fig, axes = plt.subplots(rows, cols, figsize=(20, 4 * rows))
axes = axes.flatten()
for i, col in enumerate(df_final.columns):
axes[i].hist(df_final[col].dropna(), bins=30, color='#1f77b4', alpha=0.7, edgecolor='black')
axes[i].set_title(f'{col}', fontsize=9, pad=5)
axes[i].grid(alpha=0.3)
for j in range(i + 1, len(axes)):
axes[j].set_visible(False)
plt.tight_layout()
plt.suptitle('直方图', fontsize=16, y=1.02)
plt.show()(2)相关系数图
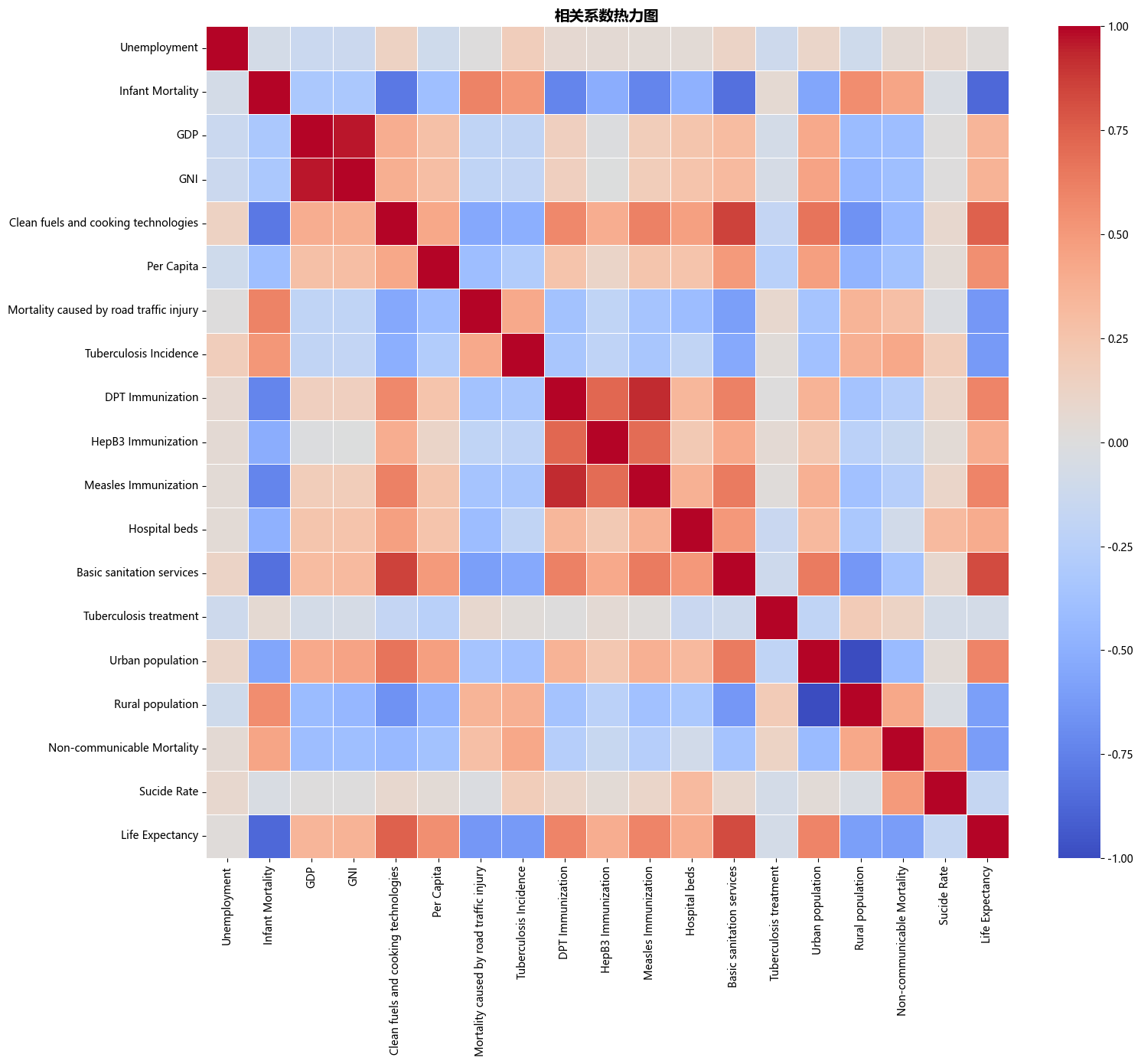 图2 18个特征指标与预期寿命的相关系数热力图
图2 18个特征指标与预期寿命的相关系数热力图
代码:
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(16, 14))
sns.heatmap(df_final.corr(), cmap='coolwarm', annot=False, linewidths=0.5, fmt='.2f')
plt.title('相关系数热力图', fontsize=14, weight='bold')
plt.tight_layout()
plt.show()2 KAN模型
KAN(Kolmogorov‑Arnold Network)是基于科尔莫戈罗夫‑阿诺德表示定理提出的新型神经网络,多层感知器(MLP) 在节点("神经元")上具有固定的激活函数,而 KAN 在边("权重")上具有可学习的激活函数。在数据拟合和 PDE 求解中,较小的 KAN 可以比较大的 MLP 获得更好的准确性,与传统的MLP 相比,KAN 有4个主要特点3:
1)激活函数位于"边"而不是节点(Node)上;
2)激活函数是可学习的而不是固定的;
3)可以使用非线性核函数来替代MLP"边"(Edge)上的线性函数;
4)可以设定细粒度的结点(Knot)来提高逼近精度。
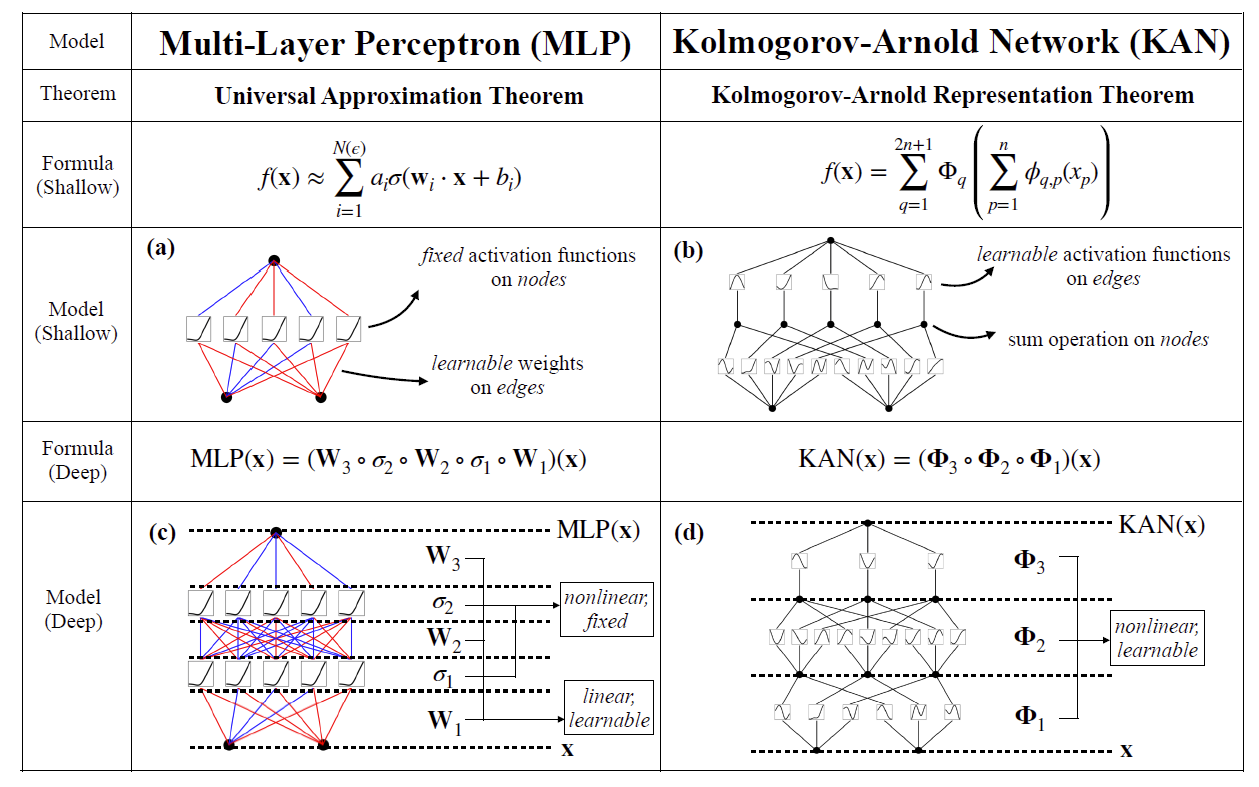 图3 MLP与KAN的对比分析图
图3 MLP与KAN的对比分析图
KAN的结构如图4所示,非线性变换被置于网络的连接边而非神经元节点上,其前向传播过程如下:输入向量的每个分量首先通过对应边的一维非线性函数进行变换,再由目标神经元对所有边的输出结果进行求和,数学表达为:
其中 表示从第
个输入节点到第
个输出节点的边函数。
为实现可学习的非线性变换,B - 样条 KAN 将边函数参数化为 B - 样条基函数的线性组合:
其中,是第
个 B-样条基函数,为可学习的系数。这种参数化方式使得 KAN 能够以平滑、可微且易于扩展的方式逼近复杂函数。
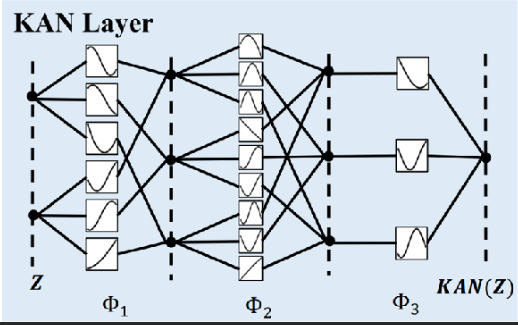 图4 KAN结构图
图4 KAN结构图
注:图片来自于 kan模型 - 搜索 图片
3 实验
实验采用KAN网络构建回归预测模型。实验数据集按照 6:1:3 的比例划分为训练集、验证集与测试集,其中 60% 用于模型训练,10% 用于训练过程中的验证,30% 用于最终模型性能评估。网络结构设计为四层 KAN 架构,输入维度为 18,依次经过 64、32 个神经元的两层隐藏层,最终输出 1 维预测结果,即网络结构为 KAN([18, 64, 32, 1])。模型训练采用方误差(MSE)作为损失函数,优化器选用 Adam。训练过程共执行 50 个 epoch,每个 epoch 完成训练集前向传播、损失计算、反向传播与参数更新,并在验证集上同步评估模型性能。训练过程中保留验证集 MSE 最低的最优模型,最终保存最优模型参数用于后续预测。
此外,为全面验证 KAN 模型的有效性与优越性,本研究设置对照实验 ,选取经典机器学习与深度学习模型作为基准方法,包括多层感知机(MLP)、多元线性回归(MLR)、随机森林(RF)、支持向量机(SVM),通过多维度指标对比各模型的回归预测性能。本实验采用决定系数 R²、平均绝对误差 MAE、均方误差 MSE、均方根误差 RMSE 及平均绝对百分比误差 MAPE五项指标,综合评估模型回归预测精度与泛化能力。其评价指标定义如下4-5:
(1)决定系数 R²
(2) 平均绝对误差 MAE
(3)均方误差 MSE
(4)均方根误差 RMSE
(5)平均绝对百分比误差 MAPE
其中,:真实值,
:预测值;
:真实值的均值;
:样本数量。 R² 用于衡量模型拟合程度,MAE、MSE、RMSE 反映预测误差的绝对与平方偏差大小,MAPE 体现相对预测精度,共同全面评估模型回归性能。
机器学习代码:
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
X = df_final.iloc[:, :-1]
y = df_final.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
def evaluate_model(y_true, y_pred, model_name):
r2 = r2_score(y_true, y_pred)
mae = mean_absolute_error(y_true, y_pred)
mse = mean_squared_error(y_true, y_pred)
rmse = np.sqrt(mse)
def calculate_mape(y_t, y_p):
mask = y_t != 0
return np.mean(np.abs((y_t[mask] - y_p[mask]) / y_t[mask]))
mape = calculate_mape(y_true, y_pred)
return r2, mae, rmse, mape
def plot_predictions(y_true, y_pred, model_name):
plt.figure(figsize=(10, 5))
plt.scatter(y_true, y_pred, s=20, alpha=0.6)
plt.title(f'{model_name} - Predicted vs. Actual', fontsize=14)
plt.xlabel('Actual Value', fontsize=12)
plt.ylabel('Predicted Value', fontsize=12)
plt.plot([min(y_true), max(y_true)], [min(y_true), max(y_true)], 'r--', lw=2)
plt.tight_layout()
plt.show()
# 1) MLR 多元线性回归
mlr = LinearRegression()
mlr.fit(X_train, y_train)
y_pred_mlr = mlr.predict(X_test)
evaluate_model(y_test, y_pred_mlr, "MLR 多元线性回归")
plot_predictions(y_test, y_pred_mlr, "MLR")
# 2) RF 随机森林回归
rf = RandomForestRegressor(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
evaluate_model(y_test, y_pred_rf, "RF 随机森林回归")
plot_predictions(y_test, y_pred_rf, "RF")
# 3) SVR 支持向量回归
svr = SVR(kernel='rbf') # 常用核函数:rbf、linear、poly
svr.fit(X_train, y_train)
y_pred_svr = svr.predict(X_test)
evaluate_model(y_test, y_pred_svr, "SVR 支持向量回归")
plot_predictions(y_test, y_pred_svr, "SVR")MLP代码:
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.preprocessing import StandardScaler
df_final = pd.concat([df_combined, df_y_combined], axis=1)
X = df_final.iloc[:, :-1]
y = df_final.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
mlp = MLPRegressor(
hidden_layer_sizes=(64, 32),
activation='relu',
solver='adam',
max_iter=1000,
random_state=42,
verbose=True
)
mlp.fit(X_train_scaled, y_train)
y_pred_mlp = mlp.predict(X_test_scaled)
def calculate_mape(y_true, y_pred):
mask = y_true != 0
return np.mean(np.abs((y_true[mask] - y_pred[mask]) / y_true[mask]))
# 计算指标
r2 = r2_score(y_test, y_pred_mlp)
mae = mean_absolute_error(y_test, y_pred_mlp)
mse = mean_squared_error(y_test, y_pred_mlp)
rmse = np.sqrt(mse)
mape = calculate_mape(y_test, y_pred_mlp)
plt.figure(figsize=(10, 5))
plt.scatter(y_test, y_pred_mlp, s=20)
plt.title('MLP - Predicted vs. Actual')
plt.xlabel('Actual Value')
plt.ylabel('Predicted Value')
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], 'r--', lw=2)
plt.tight_layout()
plt.show()KAN模型代码可联系私信博主。
4 结果与讨论
4.1 KAN模型训练损失变化
从该 KAN 模型的训练损失曲线(图5)可以看出:模型在训练过程中,训练集与验证集的 MSE 损失均呈现快速下降并逐步趋于稳定的趋势,其中训练损失在前期下降更为剧烈,随后以缓慢速率持续降低,而验证损失在同步下降后逐渐收敛至平稳状态,两条曲线在训练后期的差距较小且无明显增大现象,表明模型未出现显著过拟合问题,整体训练过程稳定收敛,模型在训练集上的拟合效果良好,且在验证集上具备稳定的泛化性能。
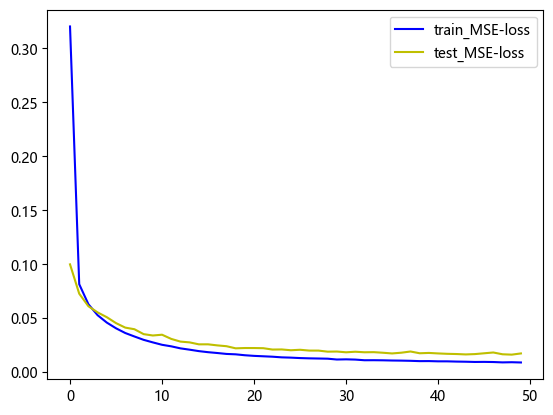 图5 KAN模型训练损失变化图
图5 KAN模型训练损失变化图
4.2 KAN模型与MLP、MLR、RF、SVM的对比分析结果
如表1所示,从各项回归评价指标来看,KAN 模型在本研究中展现出最优的预测性能:其决定系数 R2 达到 0.9853,为所有对比模型中最高,表明模型对数据的整体拟合程度最佳;同时,其 MAE、MSE、RMSE 与 MAPE 指标分别低至 0.7469、1.3258、1.1514 和 0.0107,均优于 MLR、RF、SVM 及 MLP 模型,证明 KAN 模型在预测精度、误差控制和泛化能力上均表现出显著优势,相比传统机器学习与基础深度学习方法,能够更精准地捕捉数据间的复杂非线性关系,具备更可靠的回归预测能力。证实了 KAN 模型在挖掘预期寿命相关复杂非线性关系方面的优势,其预测结果更为精准稳定。
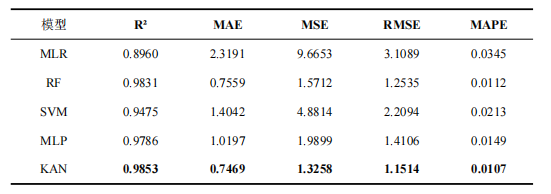 表1 与常规机器学习对比结果
表1 与常规机器学习对比结果
从预测值与真实值的散点图(图6)对比可以清晰看出,KAN 模型的预测结果最接近理想的 1:1 红线,数据点分布最集中,离散程度最小。这表明 KAN 模型在捕捉预期寿命的复杂影响机制方面优于 MLR、RF、SVM 和 MLP 模型,能够实现预测值与真实值的高度精准匹配,进一步验证了该模型在预期寿命预测任务中的优越性与可靠性。
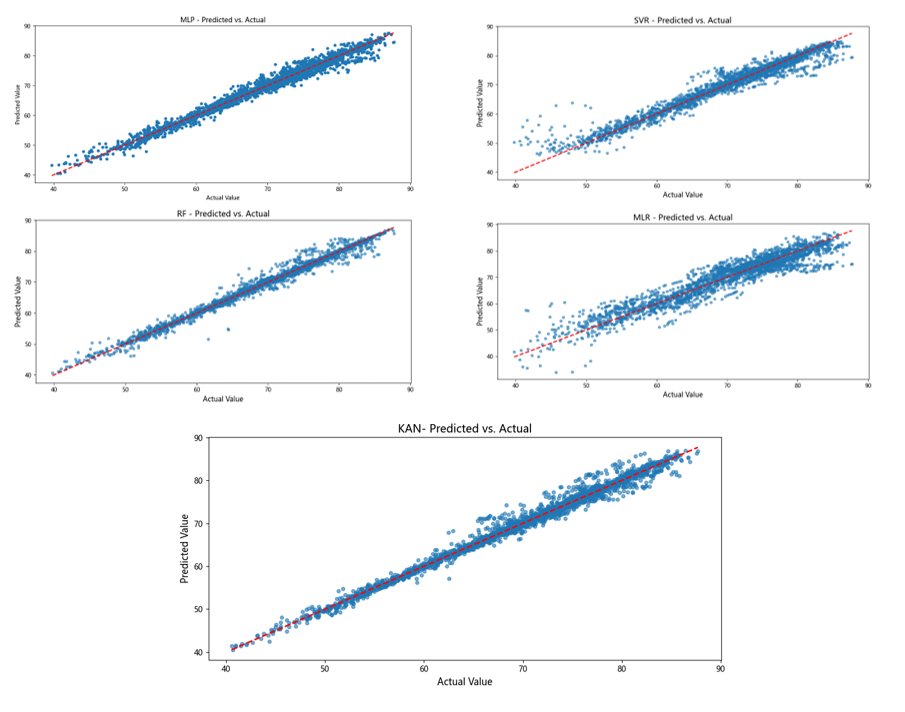 图6 各个模型预测值与真实值的拟合散点图
图6 各个模型预测值与真实值的拟合散点图
4.3 与已有研究进行对比分析结果
表2对比结果显示,KAN 模型在预期寿命预测中表现最优。虽然 PCA+RF 模型6取得了 0.9848 的高 R2,但 KAN 模型在 MAE、MSE、RMSE 及 MAPE 指标上均表现更低,分别达到 0.7469、1.3258、1.1514 与 0.0107。这充分证明 KAN 模型在处理预期寿命相关的复杂生理数据时,具备更强的非线性拟合能力与泛化能力,其预测准确性显著优于基于 PCA 特征提取的随机森林模型。通过对比PCA+RF与KAN模型的预测值与真实值散点图7可以发现,两种模型均呈现出良好的正相关趋势,预测值与真实值高度拟合。但在数据离散程度与拟合精度上,KAN 模型展现出明显优势。从散点分布形态来看,PCA+RF 模型的散点虽整体沿对角线分布,但在中高数值区间(存在一定程度的离散,且部分点偏离 1:1 参考线略远;而KAN 模型的数据点分布更为紧凑、密集,几乎无明显的离群点,整体预测稳健性显著优于基于 PCA 特征降维的随机森林模型。
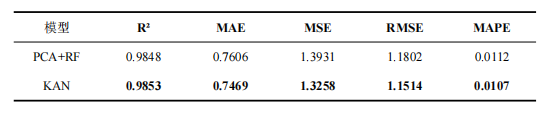 表2 与PCA+RF的对比分析定量结果
表2 与PCA+RF的对比分析定量结果
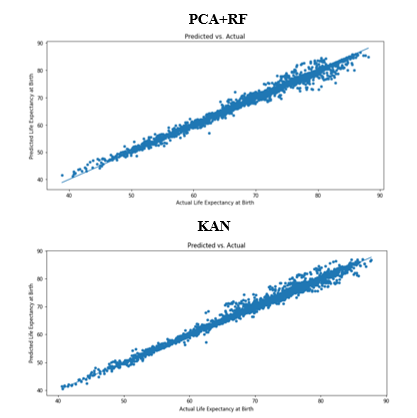 图7 与PCA+RF的对比分析的散点图
图7 与PCA+RF的对比分析的散点图
本研究针对预期寿命预测任务,系统对比了传统机器学习模型(MLR、RF、SVM)、多层感知器(MLP)与 KAN 网络的预测性能。实验结果表明,KAN 模型在所有评价指标上均取得最优表现,其决定系数R2达到 0.9853,MAE、MSE、RMSE 与 MAPE 误差指标均为所有模型中最低;同时,预测值与真实值的散点分布也显示,KAN 模型的数据点最紧密地贴合于 1:1 参考线,离散程度显著低于其他模型,展现出对预期寿命相关复杂非线性关系的极强拟合能力。对比传统线性模型(MLR)与常规神经网络(MLP)可以发现,前者因受限于线性假设,难以捕捉多因素间的复杂交互作用,预测精度明显不足;而后者虽具备非线性建模能力,但受限于权重驱动的特征学习方式,对数据分布变化的适应性有限,易出现过拟合或泛化性能不佳的问题。KAN 通过将非线性变换显式编码于边激活函数的架构优势,能够更高效地挖掘预期寿命与经济水平、医疗资源、人口结构等多维度特征间的深层关联,无需依赖复杂的前置特征工程,即可实现更精准的预测。从实际应用价值来看,预期寿命预测不仅要求模型具备高精度,更需对政策调整、公共卫生事件等外部冲击具备一定的鲁棒性。本研究中 KAN 模型在验证集上稳定收敛的训练曲线与优异的泛化性能,表明其在面对数据分布变化时仍能保持可靠的预测能力,可为卫生政策制定、医疗资源优化配置提供更科学的量化依据。
参考
2 Liu Z, Wang Y, Vaidya S, et al. Kan: Kolmogorov-arnold networksJ. arXiv preprint arXiv:2404.19756, 2024.
3 陈巍:KAN网络技术最全解析------最热KAN能否干掉MLP和Transformer? - 知乎
4 基于领域自适应神经网络(DANN)的无创血压估计方法-CSDN博客
5 基于贝叶斯函数型线性模型的PPG信号对心血管动力学参数预测研究-CSDN博客
6 Machine Learning Prediction - Random Forest
注:若有侵权部分,请留言将会删除。
个人观点,仅供参考