35.1 概率图模型的推断方法
基于概率图模型定义的联合概率分布,我们能对以某些可观测变量为条件的++条件分布++ ,或对目标变量的++边际分布++ (marginal distribution)进行推断。
条件分布,例如在隐马尔可夫模型中估算观测序列x在给定参数λ <λ=A,B,π> 的条件概率分布 P(x|λ),评估模型λ与观测序列x之间相匹配的程度。
边际分布,则是指对其他变量所有可能取值求和或积分之后得到结果,例如在马尔可夫网中,变量x的联合分布被表示成极大团的势函数乘积 <P(x) = (1/Z) ∏(Q∈C)ΨQ(xQ) >,给定参数θ求解某个变量x的分布,就变成对联合分布中其他变量进行积分的过程,这称为"边际化"(marginalization)。
<边际分布是概率论描述多变量系统中单个变量的"独立概率分布"。在联合概率分布中,单个变量的边际分布通过对其他变量所有可能取值进行求和或积分得到。例如:
离散变量:X的边际分布P(X=x) = ∑(y)P(X=x,Y=y) (将Y的所有取值对应的联合概率相加)
连续变量:P(X=x)=∫P(X=x,Y=y)dy (对Y的取值范围进行积分)
>
对于概率图模型,需要确定具体分布的参数 (通常使用极大似然估计或最大后验概率估计求解),但若将参数视为待推测的变量,则参数估计过程和推断十分相似,可以"吸收"到推断问题中。因此,下面讨论概率图模型的推断方法。
假设图模型对应的变量集 X={x1, x2, ..., xN} 能分为XE和XF两个不相交的变量集,++推断问题的目标是计算边际概率P(XF)或条件概率P(XF|XE)++ 。由条件概率定义有
P(XF|XE) = P(XE,XF)/P(XE) = P(XE,XF)/Σ(XF)P(XE,XF)
其中联合概率P(XF,XE)可基于概率图模型获得 (例如马尔可夫随机场),因此,++推断问题的关键就是如何高效地计算边际分布,即P(XE)=Σ(XF)P(XE,XF)++
概率图模型的推断方法大致可分为两类。第一类是++精确推断方法++ ,希望能计算出目标变量的边际分布或条件分布的精确值;遗憾的是,一般情形下,此类算法的计算复杂度随着极大团规模的增长呈指数增长,适用范围有限。第二类是++近似推断方法++,希望在较低的时间复杂度下获得原问题的近似解;此类方法在现实任务中更常用。
35.2 精确推断:变量消去法
精确推断的一种代表性方法:变量消去
精确推断的实质是一类动态规划算法,它利用图模型所描述的条件独立性来削减计算目标概率值所需的计算量。变量消去法是最直观的精确推断算法,也是构建其他精确推断算法的基础。
如图 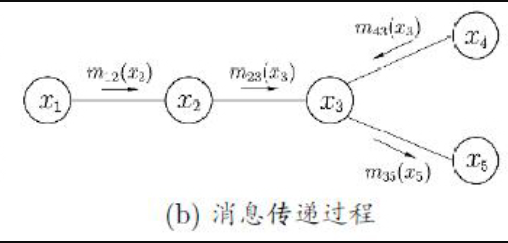 假定推断目标是计算边际概率P(x5) -- 只需通过加法消去变量{x1,x2,x3,x4},基于有向图模型所描述的条件独立性:
假定推断目标是计算边际概率P(x5) -- 只需通过加法消去变量{x1,x2,x3,x4},基于有向图模型所描述的条件独立性:
P(x5) = Σ(x4)Σ(x3)Σ(x2)Σ(x1)P(x1,x2,x3,x4,x5)
= Σ(x4)Σ(x3)Σ(x2)Σ(x1)P(x1)P(x2|x1)P(x3|x2)P(x4|x3)P(x5|x3)
= Σ(x3)P(x5|x3) Σ(x4)P(x4|x3) Σ(x2)P(x3|x2) Σ(x1)P(x1)P(x2|x1)
= Σ(x3)P(x5|x3) Σ(x4)P(x4|x3) Σ(x2)P(x3|x2) m12(x2)
其中,mij(xj)的i表示是对xi求加,j表示"在此项中固定的"其它变量 - mij(xj)是关于xj的函数。
= Σ(x3)P(x5|x3) Σ(x4)P(x4|x3) m23(x3)
= Σ(x3)P(x5|x3) m43(x3) m23(x3)
= m35(x5)
最后得 m35(x5) 是关于x5的函数,仅与变量x5的取值有关。
<变量消去法能简化此类计算的原因推导过程:
... Σ(x1)P(x1)P(x2|x1) = ... Σ(x1)∅x1(x2) = ... Σ(x2)P(x3|x2)∅(x2) = ... Σ(x2)∅x2(x3) = ... Σ(x4)P(x4|x3)∅(x3) = ... Σ(x4)∅x4(x3) = Σ(x3)P(x5|x3)∅x3 = Σ(x3)∅x3(x5) = ∅(x5)>
35.3 近似推断:MCMC采样法
如上一图的贝叶斯网,推断概率分布 P(x5) 是为了通过计算x5取值的概率得出变量x5的期望。++若"直接计算或逼近"这个期望比推断概率分布更容易++,则 ... 采样法正是基于这个思路。
假定目标是计算函数f(x)在概率密度函数P(x) <x在每个分布下的概率> 下的期望 E(f)=∫f(x)P(x)dx 。
++可根据P(x)抽取一组样本{x1, x2, ..., xN}++ ,++++然后计算f(x)在这些样本上的均值 (1/N)Σ(i=1,N)f(xi) 近似目标期望E(f)++++ -- ++若样本{x1, x2, ..., xN}独立,基于大数定律,通过大量采样能获得较高的近似精度++。
问题的关键是如何采样。对概率图模型来说,是++如何高效地基于图模型所描述的概率分布获取样本++。++概率图模型中最常用的采样技术是马尔可夫链-蒙特卡罗 (Markov Chain Monte Carlo,简称MCMC)方法++。
x是一个高维多元变量且服从一个非常复杂的分布P(x),对目标期望E(f)求积分通常很困难。为此,MCMC先构造出服从P分布的独立同分布随机变量 x1, x2, ..., xN <for (1/N)Σ(i=1,N)f(xi) 近似目标期望E(f)>。
若(P(x)很复杂)构造服从P分布的独立同分布样本也很困难,MCMC方法的关键就在于++++通过构造马尔可夫链使其收敛到平稳分布P来产生样本,生成的样本x近似服从于分布P++++。
如何使马尔可夫链收敛到平稳分布P?
35.3.1 MH算法
Metropolis-Hastings (简称MH)算法 是MCMC的重要代表。++++它基于"拒绝采样"(reject sampling)逼近平稳分布P++: 算法每次根据上一轮采样结果xt-1获得候选状态样本x*++ ,++但这个候选样本会以一定的概率被"拒绝"掉++。
假定 Q(x*|xt-1) 是用户给定的从xt-1到x*的++状态转移先验概率++ ,**A(x*|xt-1)**是x*被接受的概率。
MH算法流程与解读:
初始化 x0
for t=1,2,... do
根据状态转移先验概率 Q(x*|xt-1) 得出候选样本 x*
根据均匀分布U从(0,1)范围内采样出阈值u
if u ≤ A(x*|xt-1) then xt = x* <x*被接受>
else xt = xt-1 <x*被拒绝>
++++7. 如果在某个时刻马尔可夫链状态分布p满足平稳条件 :++++
++++p(xt-1)Q(x*|xt-1)A(x*|xt-1) = p(x*)Q(xt-1|x*)A(xt-1|x*),++++
++++则马尔可夫链在满足此条件时已收敛到平稳状态,p是此马尔可夫链的平稳分布。++++
end for
- return x1, x2, ...
输出:++++x1, x2, ... <为构造出的服从稳定分布p的样本>++++
<使用生成的样本x1, x2, ... 计算 (1/N)Σ(i=1,N)f(xi) 近似目标期望 E(f) >
为了达到平稳状态,需将接受率设置为
A(x*|xt-1) = min(1, p(x*)Q(xt-1|x*) / p(xt-1)Q(x*|xt-1))
<状态转移先验概率 Q(x*|xt-1) 具体用例:
- 正态分布 (以xt-1为均值、标准差为σ) :
xt_1 = 0 # 当前状态值
sigma = 1 # 标准差 σ控制采样范围:σ越大,x∗离xt−1越远;σ越小,采样越集中。
生成标准正态分布随机数 Z~N(0,1) 方法一:
++++z = np.random.randn()++++
方法二:Z的生成依赖均匀分布随机数,通过数学变换逼近正态分布。
u1 = np.random.rand()
u2 = np.random.rand() # 生成两个均匀分布随机数
z = np.sqrt(-2 * np.log(u1)) * np.cos(2 * np.pi * u2) # Box-Muller变换 Z
++++x_star = xt_1 + sigma * z # 生成候选样本 x*++++
-
由于正态分布是对称的,Q(x∗∣xt−1)=Q(xt−1∣x∗),接受率简化为:A(x*|xt-1) = min(1, p(x*)/p(xt-1))
-
通过调整标准差σ,可控制候选样本的离散程度:σ过大:候选样本离当前状态远(接受率低);σ过小:链移动缓慢,收敛速度慢。
- 均匀分布:
Q(x∗∣xt−1) = U(x(t−1) −a, x(t−1) +a),其中a是区间半径。同样具有对称性,接受率简化为min(1,p(x∗)/p(xt−1))。
- 拉普拉斯分布:
Q(x∗∣xt−1) = (1/2b) exp(-|x*-x(t-1)|/b),b是尺度参数。
>