0. 引言:此章并非Transformer入门
这一章表面上是在讲Transformer和介绍一些现代大模型结构,但是重点是要理解现代LLM在归一化、FFN、激活函数、位置编码、注意力机制这些模块上到底改了什么,为什么要改,以及这些改动分别解决了哪些问题,比如训练稳定性、显存、上下文长度。
学完这章应该要建立一个判断:以后看到别的大模型结构时,能立刻判断它在归一化、FFN、位置编码,KV Cache和训练稳定性等等这些方面有什么改进,该模型会具备什么特点。
1. 标准Transformer
原始Transformer的标准配置可以概括为四点:
- 绝对位置编码:正余弦位置编码直接加到 token embedding 上;
- 多头注意力;
- Post-LN+ 残差连接;
- 带偏置的 FFN + ReLU。
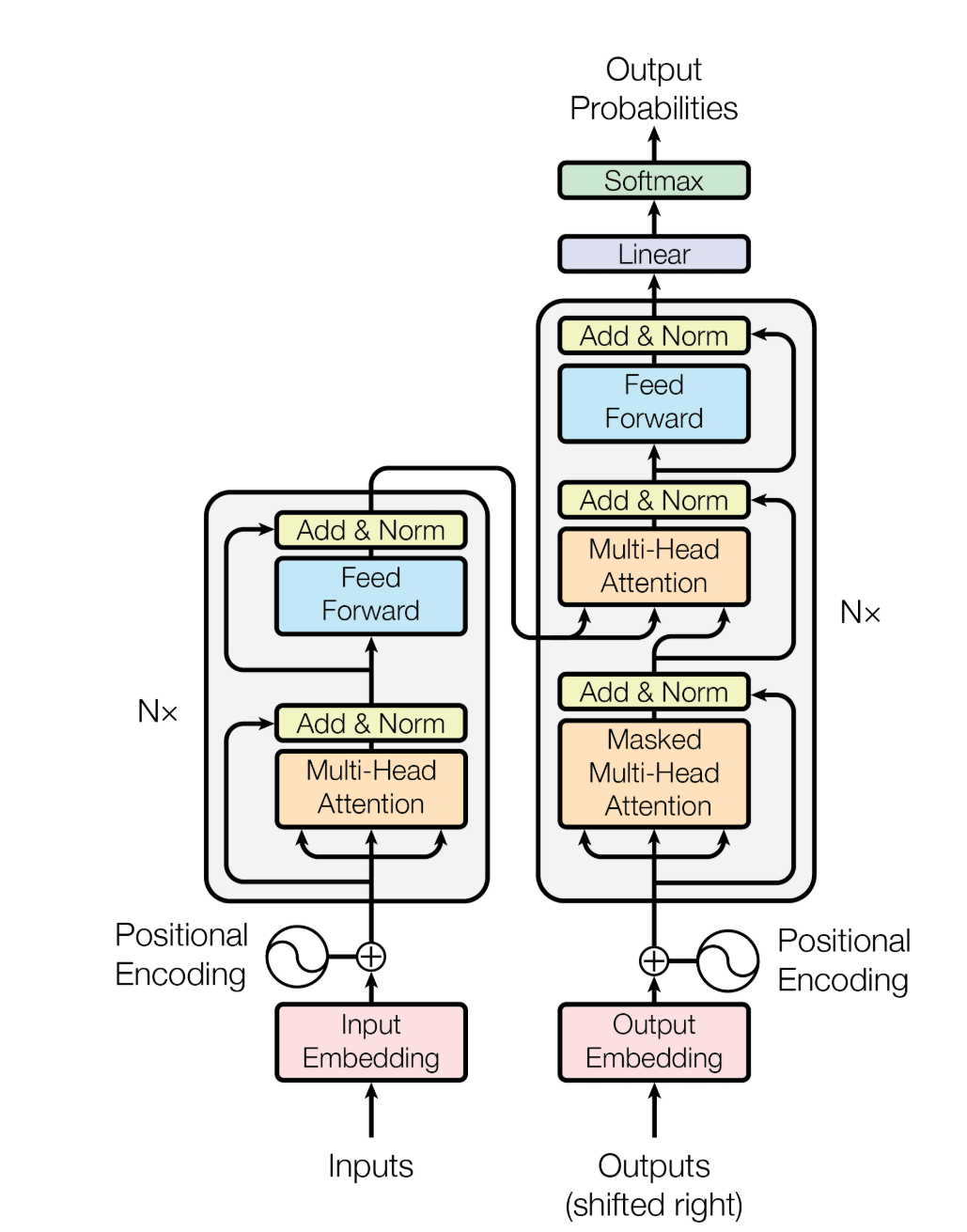
这里最需要回忆的不是公式本身,而是这些模块各自负责什么功能:位置编码负责补顺序信息,注意力负责建模依赖,FFN 提供非线性表达,残差和归一化负责让深层网络能训练起来。后面所有改动,本质上都没有跳出这个分工框架。
细节:注意力里的
softmax ( Q K T d k ) \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) softmax(dk QKT)
中除以 d k \sqrt{d_k} dk ,是为了防止高维点积的方差膨胀,后面关于训练稳定性部分还会提到。
2. 归一化
演化:
Post-LN → Pre-LN → RMSNorm
原始Transformer使用的是:
X = LayerNorm ( X + Sublayer ( X ) ) X=\text{LayerNorm}(X+\text{Sublayer}(X)) X=LayerNorm(X+Sublayer(X))
现代主流:
X = X + Sublayer ( LayerNorm ( X ) ) X=X+\text{Sublayer}(\text{LayerNorm}(X)) X=X+Sublayer(LayerNorm(X))
这个表面上只是LayerNorm位置交换了一下,但实际上是在保护残差主干,让深层模型训练更稳定,否则层归一化会破坏残差连接中梯度的传递。
现在主流的RMSNorm:
RMSNorm ( v ) = γ v 1 d ∑ i = 1 d v i 2 + ε \text{RMSNorm}(v)=\gamma \frac{v}{\sqrt{\frac{1}{d}\sum_{i=1}^{d} v_i^2+\varepsilon}} RMSNorm(v)=γd1∑i=1dvi2+ε v
去掉了偏置项 β β β,也不再减去均值,只保留基于方差(准确说是均方根 RMS)的缩放,发现这效果也很好,计算开销还减少了。
有研究表明,均值平移对语义表达贡献极小,真正承载语义信息的是激活值的相对比例(模长)和方向,而偏置容易引发训练过程中的数值不稳定,且矩阵乘法已足够拟合。
3. FFN与激活函数
原始Transformer的FFN是:
FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x)=\max(0,xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2
现代模型去掉偏置:
FFN ( x ) = max ( 0 , x W 1 ) W 2 \text{FFN}(x)=\max(0,xW_1)W_2 FFN(x)=max(0,xW1)W2
和RMSNorm类似,参数能删就删,无用的自由度能少就少,大模型里很多偏置并没有带来收益,反而会增加训练负担。虽然目前没有完全统一的理论解释为什么偏置对稳定性特别不利,但经验结论已经很明确了。
激活函数的演化:
ReLU → GeLU → GLU家族
GeLU把ReLU变得更平滑,结构性真正变化是在GLU家族。
GLU 的基本形式:
GLU ( x ) = ( x W ) ⊙ σ ( x V ) \text{GLU}(x)=(xW)\odot \sigma(xV) GLU(x)=(xW)⊙σ(xV)
GLU可理解为 "门控+内容" 双通道机制:
- 内容通道 : x W xW xW提供原始信息。
- 门控通道 : σ ( x V ) σ(xV) σ(xV)生成0-1之间的"开关",决定每个神经元的通过量。
- 动态激活:每个token的门控值都不同,实现输入依赖的稀疏性。
GeGLU和SwiGLU只是进一步把门控函数替换为更平滑的GeLU或Swish,现代很多模型使用SwiGLU。
4. 位置编码
演化:
绝对位置编码,正弦嵌入 → RoPE
原始正余弦位置编码无参数、简单、有一定外推性,但问题在于它本质上是直接加一个绝对位置标签,无法直接建模相对距离,并且长序列性能会衰减。
RoPE不是加位置向量,而是在注意力里对Q K做旋转操作,把相对位置信息写进内积本身。
二维旋转矩阵为:
R ( θ ) = cos θ − sin θ sin θ cos θ R(\theta)= \begin{bmatrix} \cos\theta&-\sin\theta\\ \sin\theta&\cos\theta \end{bmatrix} R(θ)=cosθsinθ−sinθcosθ
关键思想:把高维向量拆成多个二维子空间分别旋转,于是不同位置的Q、K做内积时,数学上天然只和相对位置差有关(推导省略)。
补充:旋转矩阵的数学性质
- 正交性:旋转矩阵是正交矩阵,这意味着它的列向量和行向量都是单位向量,并且两两正交。因此,旋转矩阵的逆矩阵等于它的转置矩阵。
- 行列式为1:旋转矩阵的行列式为1,这表示旋转操作不会改变向量的长度,只改变其方向。
- 周期性:旋转矩阵具有周期性,即 R(θ+2π)=R(θ) 。
- 基础运算 :旋转矩阵的乘法遵循矩阵乘法的规则,即 R(a+b)=R(a)R(b) 。我们马上就会用到这一条。
5. 注意力变体
文本生成是自回归的,即逐个生成Token且无法并行,为了避免重复计算历史Token的Key和Value,模型会将其缓存起来供后续直接使用,这被称为KV Cache。
5.1 MHA、MQA、GQA:KV Cache的共享程度不同
- MHA(传统多头注意力):每个头独立QKV,表达最完整,缓存最贵。
- MQA(多查询注意力):多个头共享同一组KV,只保留独立Q,最省显存。
- GQA(分组查询注意力):按组共享KV,MHA和MQA 之间的折中。
5.2 MLA:低秩压缩
MLA(多头潜在注意力)和上面的思路不一样,它是先把KV下投影到低维潜在空间缓存,再在计算前上投影回去。
本质上,MLA 是一种对KV有损压缩的办法,用更多计算,换更少显存。
5.3 稀疏/滑动窗口/DSA
- 滑动窗口注意力:每个Query不看全部,只看局部窗口。
- DSA(DeepSeek 稀疏注意力):先用Lightning Indexer(闪电索引器)给历史token的重要性打分,只把Top-k送入注意力计算,复杂度强制降为 O ( L ⋅ k ) O(L·k) O(L⋅k),传统注意力的复杂度为 O ( L 2 ) O(L^2) O(L2)。
MQA/GQA/MLA 主要是少存K/V或压缩地存KV Cache。
滑动窗口和DSA主要是少算。
6. 超参数设计
6.1 FFN 比例
标准ReLU FFN经验: d f f = 4 d m o d e l d_{ff}=4d_{model} dff=4dmodelGLU变体经验: d f f ≈ 8 3 d m o d e l ≈ 2.66 d m o d e l d_{ff}\approx \frac{8}{3}d_{model}\approx 2.66d_{model} dff≈38dmodel≈2.66dmodelGLU比例缩减并非因其不需要宽度,而是为抵消额外投影带来的参数量与FLOPs增长,从而维持相同的计算预算。
T5和Gemma 2等不符合案例表明,2.66倍仅是经验而非绝对铁律。
6.2 头数与模型维度比例
经验:
n u m _ h e a d s × h e a d _ d i m d m o d e l ≈ 1 \frac{num\_heads \times head\dim}{d{model}} \approx 1 dmodelnum_heads×head_dim≈1
Bhojanapalli等人2020年的研究,他们提出如果注意力头数量不断增加,其秩会越来越低。如果每个头的维度非常少,就会开始影响注意力操作的表达能力。
6.3 宽深比
约100左右常较优。
这个参数既影响表达能力,也会被张量并行、流水线并行等系统限制反向约束,它不是单纯的模型参数,也是分布式训练参数。
6.4 词表大小
原文给出的一个很实用的判断是:大词表未必显著提升英语、中文这种高资源语言的单语性能,但它对低资源语言更有意义,因为能减少 token 数量,从而降低推理成本。词表大小本质上是一个"覆盖能力与压缩效率"的折中问题。
6.5 dropout 与 weight decay
这里有点反直觉:
- 预训练通常只有单轮甚至不到一轮,过拟合本来就不严重,
- 因此dropout逐渐退场,
- 但weight decay仍被保留。
更关键的是,weight decay在这里主要并不是防过拟合,而是会和学习率调度等因素产生复杂的隐式作用,在训练后期带来更好的优化动力学,获得更低的训练损失。
7. 稳定性
Transformer的softmax其实很危险,而且还出现了两次,一次在输出层,一次在注意力里。
7.1 输出层softmax
z-loss:
L t o t a l = L C E + λ log 2 Z \mathcal{L}{total}=\mathcal{L}{CE}+\lambda \log^2 Z Ltotal=LCE+λlog2Z
其中:
Z:softmax的归一化因子(partition function), Z = ∑ i = 1 V e x p ( z i ) Z=∑_{i=1}^V exp(z_i) Z=∑i=1Vexp(zi)
λ:权重系数(PaLM使用 10−4)
zi:logits(未归一化的预测分数)
它的作用是为了控制softmax归一化因子 Z Z Z的数值范围,让训练更加稳定。z-loss是在给logits的无意义的平移自由度加一个约束,防止它们在数值上乱漂。
λ \lambda λ很小,说明主任务仍然是交叉熵,z-loss只是个惩罚项,使得Z接近1。
7.2 注意力softmax
先让查询向量和键向量通过层归一化层:
Q = L a y e r N o r m ( W q ( x ) ) Q=LayerNorm(W_q(x)) Q=LayerNorm(Wq(x))
K = L a y e r N o r m ( W k ( x ) ) K=LayerNorm(W_k(x)) K=LayerNorm(Wk(x))
l o g i t s = Q K T / d k logits=QK^T/\sqrt d_k logits=QKT/d k
注意力里的softmax不靠z-loss,而靠:
- 除以 d k \sqrt{d_k} dk ,抑制高维点积方差膨胀。
- 对 Q K 做归一化,进一步控制 logits 范围。
8. 理解与反思
了解了这章的内容现在看模型的结构,应该会自然地把它们放到不同的问题上面去理解,而不是仅仅只是知道了模型长这样。
- Pre-LN/RMSNorm:为了深层网络的稳定与加速。
- Pre-LN保障了深层网络的梯度能顺利回传。
- RMSNorm证明了均值平移是多余的,只保留方差缩放来约束数值,从而提升了计算速度。
- GLU家族:提升FFN的表达能力。
- 引入了逐元素相乘的门控机制,并在保持总计算量和参数量不变的条件下,将隐藏层宽度经验值调整为约2.66倍。
- RoPE:实现相对位置的显式编码。
- 放弃了将位置向量直接相加的做法,改为通过矩阵旋转操作,在计算注意力内积时自然带入两个Token之间的相对距离。
- MQA/GQA/MLA/DSA:降低显存占用与计算开销。
- MQA/GQA/MLA 通过共享头或低秩压缩,大幅减少推理时的KV Cache显存。
- DSA通过提前筛选关键Token,降低了长文本注意力的计算复杂度。
- Weight Decay与z-loss:解决训练过程的数值崩溃。
- 在单轮预训练中,Weight Decay用于限制权重范数,防止有效学习率下降。
- z-loss 则用于约束Softmax分母,防止Logits漂移导致的数值溢出和梯度消失。
现代大模型的结构演进,大概是是在模型性能、显存、训练稳定性等之间的trade-off。