分区是隶属于主题之下的。
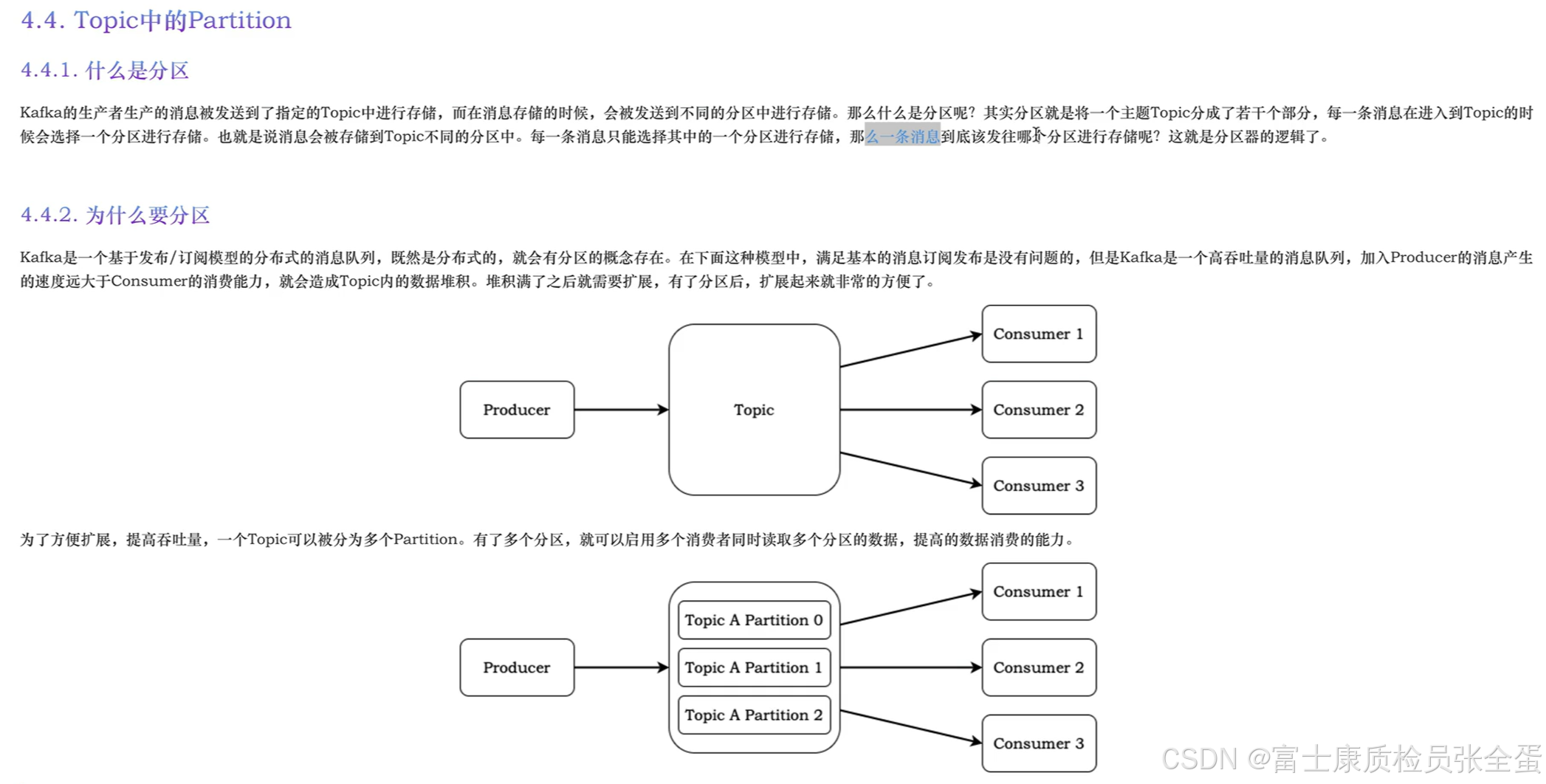
第一个图满足了最基本的消息的发布订阅,但是kafka是一个高吞吐量的消息队列,假如producer生产的速度远远大于consumer的消费能力,那么会造成topic下的数据堆积。
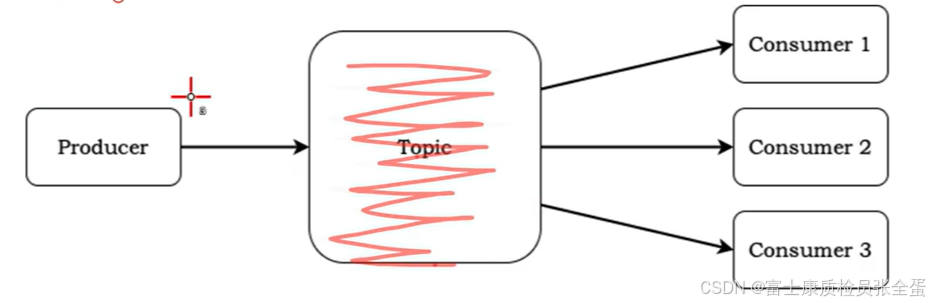
消息堆积满之后就需要扩展了,否则效率低下。于是就需要通过分区扩展了。分区的作用其实就是为了提高数据的吞吐量,提高消费能力了。
有三个消费者就可以同时消费三个分区里面的数据,这样就是上面没有分区的三倍了。
如果没有分区,那么三个消费者从分区当中拉取数据,数据是有offset的,这时候offset是单调递增的,也就意味着在同一个时间点所有的consumer只能读取一条数据。
但是有三个分区,这三个分区互不影响互不打扰,每一套分区里面都有自己的offset,每个consumer消费对应分区的数据,这样同一个时间点是可以读取到3条数据。所有有三个分区是单分区的3倍吞吐量。
为了提高吞吐量和提高处理数据的能力,它们去做了多个分区。

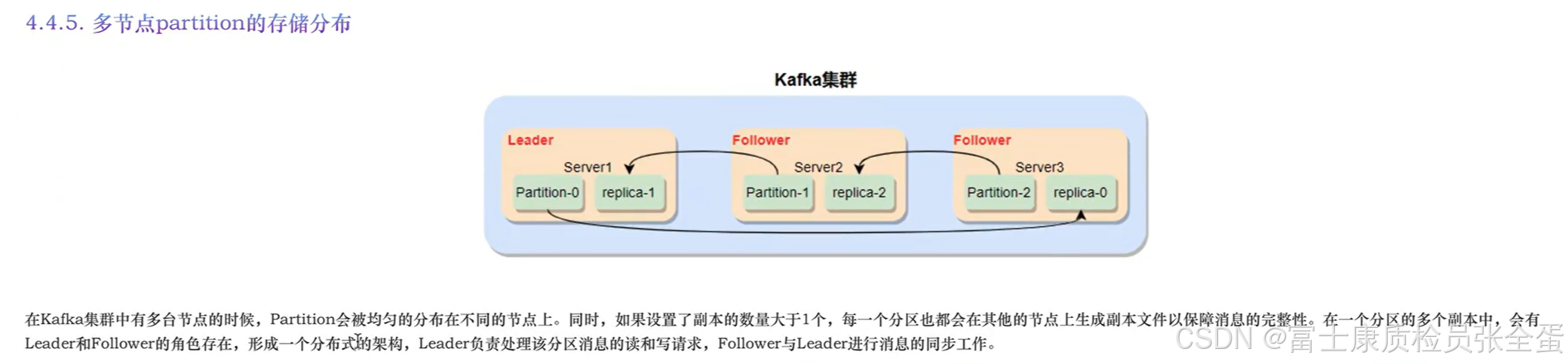
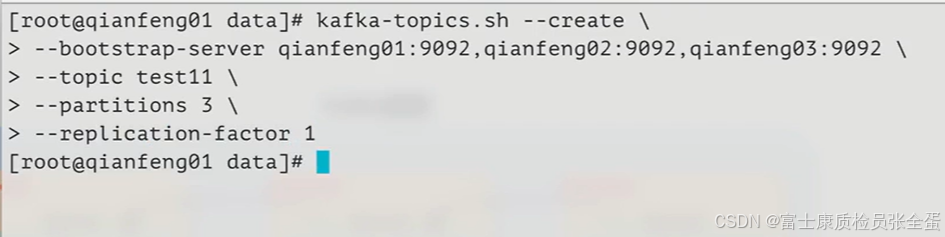
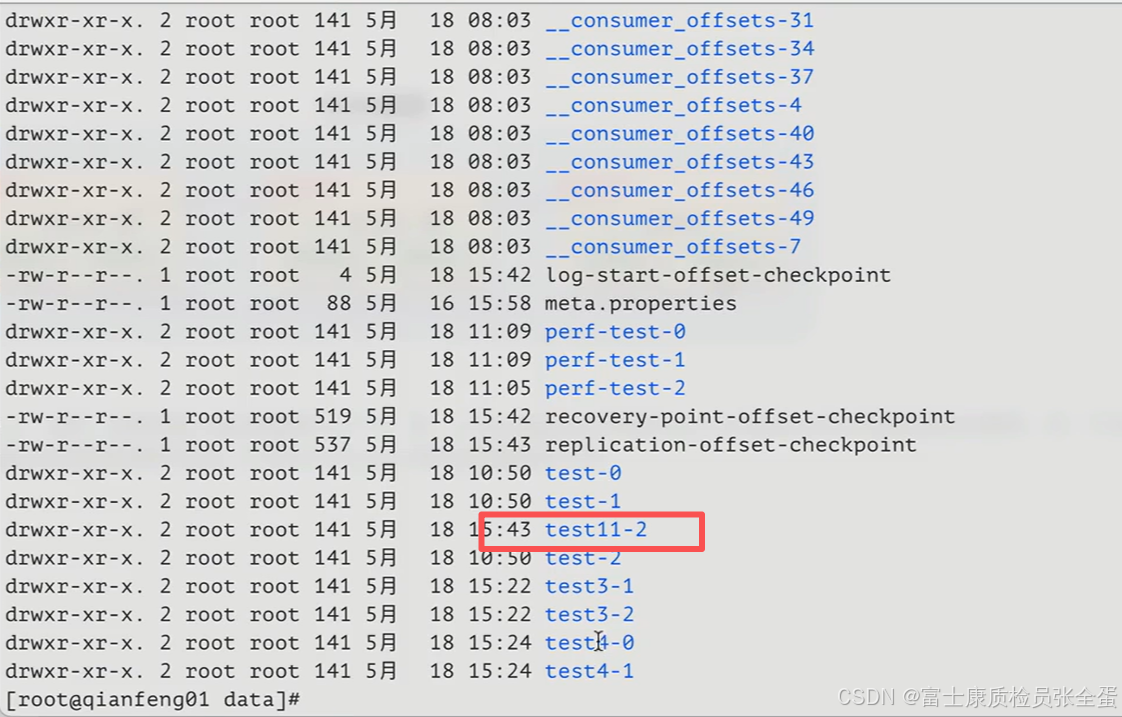
另外的两个分区在其他broker上面
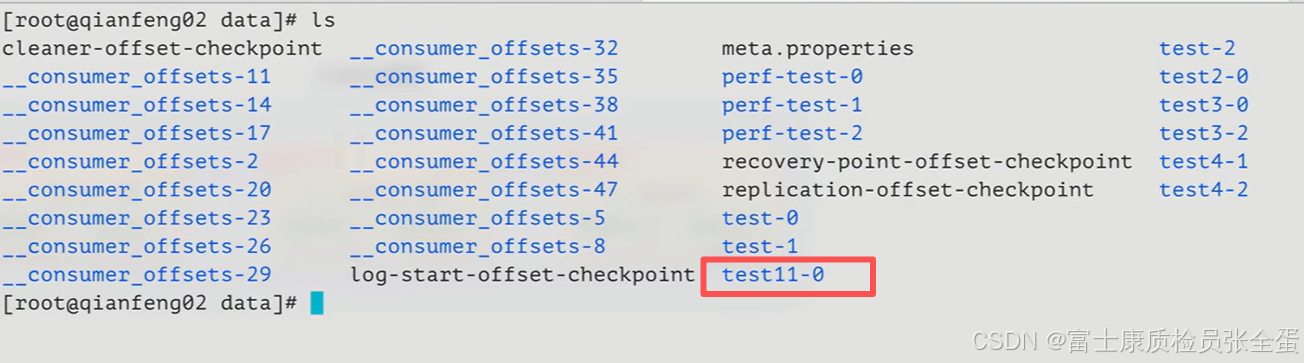
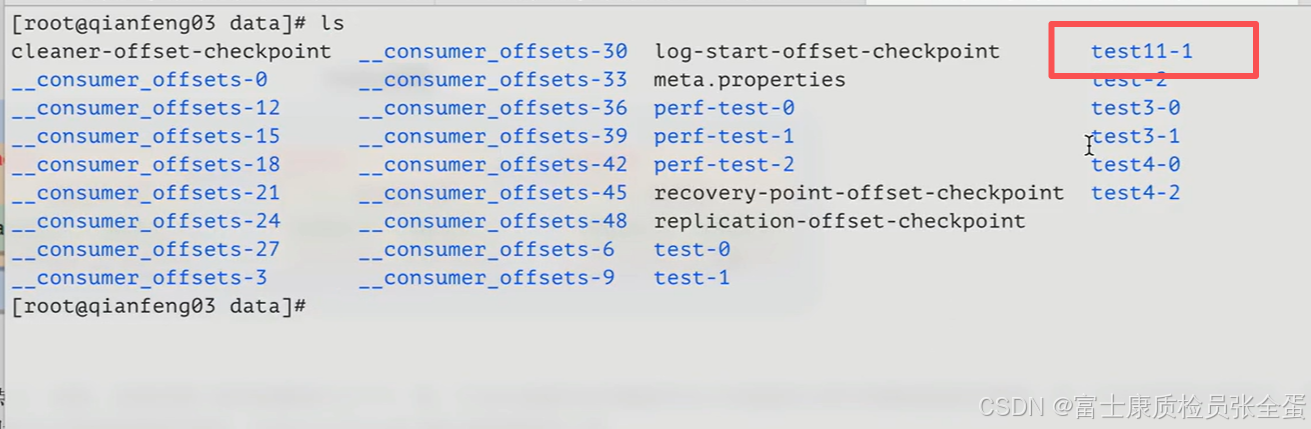
也就是说这个topic有三个分区,这三个分区尽量均匀的发布在3个broker上面。
为什么要使用分区?其实最直观的原因是为了提高kafka集群的数据吞吐能力,数据消费能力。有了分区之后就可以去启动多个消费者同时去消费不同分区中的数据来提高这样的并行度。
分区就是把kafka当中的主题分成了若干个部分,分区是一个物理概念,我们可以实实在在看到这样的目录存在。而这样的目录也会尽量去做一个均衡的处理。
就像上面创建的一个主题,它会将三个分区尽量的均匀分布在每一个broker上。