论文基本信息
标题:Pyramid Scene Parsing Network
会议:CVPR 2017
单位:香港中文大学、商汤科技
代码:https://github.com/hszhao/PSPNet
论文:https://arxiv.org/pdf/1612.01105.pdf
前言
在语义分割领域,FCN虽然实现了端到端像素级预测,但在复杂场景中经常闹笑话:把河里的船认成汽车、把楼认成摩天楼、小目标枕头直接忽略。核心原因就是缺乏全局上下文信息。
PSPNet横空出世,提出金字塔池化模块(PPM) ,把不同尺度、不同区域的全局特征融合进来,再搭配深度监督损失稳定训练,直接拿下2016年ImageNet场景解析、PASCAL VOC 2012、Cityscapes三个榜单第一,单模型mIoU高达85.4%,成为语义分割史上的里程碑模型。

图 1.ADE20K 数据集中复杂场景的示例图。
一、FCN做场景解析的三大致命问题
作者在ADE20K数据集上分析FCN预测结果,总结出三大通病:
- 关系不匹配:缺乏场景常识,汽车不会出现在河里,FCN却把船认成汽车
- 类别混淆:墙/房子/大楼/摩天楼外观相似,FCN会给同一个物体标多个类
- 小目标忽略 :路灯、招牌、枕头等不显眼物体,FCN容易分类错误
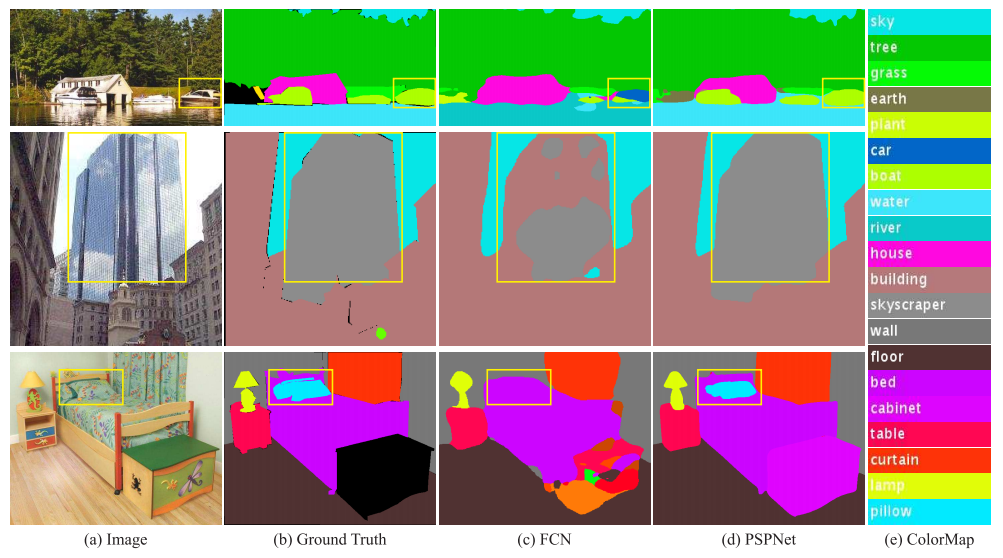
图 2.我们在 ADE20K 43 数据集上观察到的场景解析问题。第一行显示了关系不匹配的问题------汽车很少会浮在水面上,而船只则不然。第二行展示了混淆的类别,其中"建筑物"类别很容易被误认为是"摩天大楼"。第三行展示了不显眼的类别。在这个例子中,枕头在颜色和质地方面与床单非常相似。这些不显眼的物体很容易被全卷式网络(FCN)错误分类。
图片分析:FCN预测结果错误百出,PSPNet借助全局上下文完美修正,精准识别物体类别与边界。
二、核心创新:金字塔池化模块PPM
2.1 设计思路
CNN理论感受野远大于实际感受野,无法有效捕捉全局信息。全局平均池化又过于简单,会丢失空间关系。
金字塔池化模块 :对特征图做四种不同尺度的池化,融合全局+局部+不同区域的上下文信息。
2.2 结构与计算流程
- 输入:ResNet+空洞卷积输出的特征图,尺寸为输入图像的1/8
- 四层金字塔池化:bin大小分别为1×1、2×2、3×3、6×6
- 每层经过1×1卷积降维,减少通道数
- 上采样到原特征图尺寸
- 拼接原始特征+四层金字塔特征,得到融合全局信息的最终特征
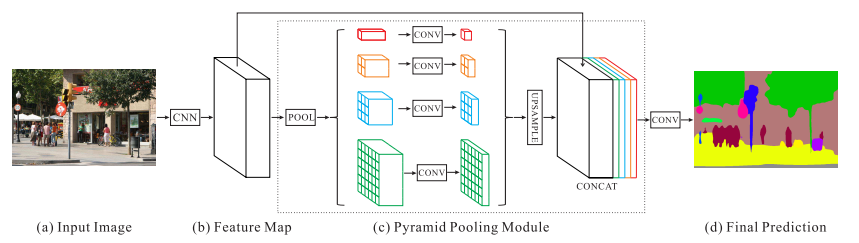
图 3.我们所提出的 PSPNet 的概述。给定一个输入图像(a),我们首先使用卷积神经网络(CNN)获取最后一层卷积层的特征图(b),然后应用金字塔解析模块来获取不同的子区域表示,接着经过上采样和拼接层来形成最终的特征表示(c),该表示包含了局部和全局的上下文信息。最后,该表示被输入到卷积层中以获得最终的像素级预测(d)。
图片分析:输入图像→CNN提取特征→金字塔池化融合多尺度全局特征→卷积输出像素级预测。
2.3 数学表达
最终特征 FfinalF_{final}Ffinal 由原始特征 F0F_{0}F0 与金字塔各层特征 F1,F2,F3,F4F_{1},F_{2},F_{3},F_{4}F1,F2,F3,F4 拼接而成:
Ffinal=Concat(F0,F1,F2,F3,F4)F_{final} = Concat(F_{0}, F_{1}, F_{2}, F_{3}, F_{4})Ffinal=Concat(F0,F1,F2,F3,F4)
- F0F_{0}F0:CNN主干输出的原始特征
- F1−F4F_{1}−F_{4}F1−F4:金字塔四层池化+降维+上采样后的特征
- ConcatConcatConcat:通道维度拼接(通俗解释:把不同尺度的特征叠在一起,让模型同时看到全局和局部)
三、训练技巧:深度监督损失
深层ResNet训练困难,作者提出辅助损失分支:
- 在ResNet第4阶段后添加辅助分类器
- 主损失+辅助损失共同优化网络
- 辅助损失权重设为0.4
- 测试时丢弃辅助分支,不影响推理速度
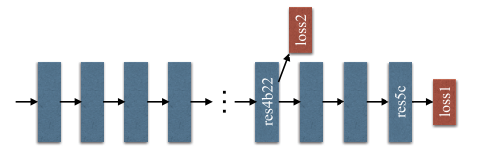
图 4.ResNet101 中辅助损失的示例。每个蓝色方框代表一个残差块。辅助损失是在第 4b22 个残差块之后添加的。
图片分析:蓝色块为残差块,res4b22后添加辅助损失,帮助梯度回传,让深层网络更好收敛。
损失函数:
Loss=Lossmain+0.4×LossauxLoss = Loss_{main} + 0.4 × Loss_{aux}Loss=Lossmain+0.4×Lossaux
- LossmainLoss_{main}Lossmain:主分支分割损失
- LossauxLoss_{aux}Lossaux:辅助分支分割损失
- 0.4:辅助损失权重(实验最优值)
四、核心代码实现(PyTorch)
4.1 金字塔池化模块PPM
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class PyramidPooling(nn.Module):
def __init__(self, in_channels, pool_sizes, out_channels):
super().__init__()
# 1×1卷积降维
self.convs = nn.ModuleList()
for pool_size in pool_sizes:
self.convs.append(
nn.Sequential(
nn.AdaptiveAvgPool2d(pool_size),
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
)
def forward(self, x):
features = [x]
h, w = x.shape[2:]
for conv in self.convs:
out = conv(x)
# 上采样到原尺寸
out = F.interpolate(out, size=(h, w), mode='bilinear', align_corners=False)
features.append(out)
# 拼接所有特征
return torch.cat(features, dim=1)
# 初始化PPM:输入通道2048,池化尺度[1,2,3,6],降维到512
ppm = PyramidPooling(in_channels=2048, pool_sizes=[1,2,3,6], out_channels=512)4.2 PSPNet主干
python
class PSPNet(nn.Module):
def __init__(self, num_classes):
super().__init__()
# 假设使用ResNet101作为主干
self.resnet = resnet101(pretrained=True)
# 金字塔池化:2048→4×512,拼接后共2048+2048=4096通道
self.ppm = PyramidPooling(2048, [1,2,3,6], 512)
# 最终分类卷积
self.cls_conv = nn.Sequential(
nn.Conv2d(4096, 512, 3, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
nn.Conv2d(512, num_classes, 1)
)
# 辅助损失分支
self.aux_conv = nn.Sequential(
nn.Conv2d(1024, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
nn.Conv2d(256, num_classes, 1)
)
def forward(self, x):
# 主干前向
x = self.resnet.conv1(x)
x = self.resnet.bn1(x)
x = self.resnet.relu(x)
x = self.resnet.maxpool(x)
x = self.resnet.layer1(x)
x = self.resnet.layer2(x)
x = self.resnet.layer3(x)
aux = self.resnet.layer4(x) # 辅助分支特征
x = self.resnet.layer5(aux) # 主分支特征
# 金字塔池化
x = self.ppm(x)
out = self.cls_conv(x)
out = F.interpolate(out, size=x.shape[2:], mode='bilinear', align_corners=False)
if self.training:
aux_out = self.aux_conv(aux)
aux_out = F.interpolate(aux_out, size=x.shape[2:], mode='bilinear', align_corners=False)
return out, aux_out
return out五、实验结果:三大榜单屠榜验证
5.1 金字塔池化消融实验
| 方法 | Mean IoU(%) | Pixel Acc.(%) |
|---|---|---|
| ResNet50-Baseline | 37.23 | 78.01 |
| ResNet50+全局池化 | 40.07 | 79.52 |
| ResNet50+PPM(AVG) | 41.68 | 80.04 |
表格1 出处:论文表1
表格分析:
- 单纯全局池化提升有限
- 四层金字塔池化比基线高4.45% mIoU,效果显著
- 平均池化效果优于最大池化
5.2 辅助损失消融实验
| 损失权重α | Mean IoU(%) | Pixel Acc.(%) |
|---|---|---|
| 无辅助损失 | 35.82 | 77.07 |
| α=0.3 | 37.01 | 77.87 |
| α=0.4 | 37.23 | 78.01 |
表格2 出处:论文表2
表格分析:
- 辅助损失有效提升精度
- 权重α=0.4时效果最优
5.3 三大数据集SOTA
- PASCAL VOC 2012 :单模型mIoU85.4%,超越所有同期方法
- Cityscapes :mIoU80.2%,大幅领先DeepLab、FCN
- ImageNet场景解析:冠军,单模型超多数集成模型

图 7.对 PASCAL VOC 2012 数据集的视觉效果进行了改进。PSPNet 能够生成更准确、更详细的结果。
图片分析:基线把牛认成马和狗,PSPNet精准修正;对小物体、遮挡物体识别更准确。
六、全文总结
核心贡献
- 金字塔池化模块PPM:融合多尺度全局上下文,解决FCN缺乏场景信息的问题
- 深度监督损失:稳定训练深度ResNet,加速收敛、提升精度
- 工程化实现:公开完整代码与模型,语义分割落地标配
- 三榜第一:验证方法通用性与强性能
核心逻辑
空洞卷积扩大感受野 → 金字塔池化抓取全局上下文 → 深度监督稳定训练 → 精准像素级预测。
PSPNet证明了全局上下文在场景解析中的重要性,后续的DeepLabv3、SegFormer等模型都借鉴了多尺度上下文融合思想,至今仍是学习语义分割必读的经典算法。