一、引言
在离线任务的世界里,一个任务失败了,大不了重跑一次。但实时任务不同:数据在源源不断地流入,任何一个环节的阻塞都可能造成数据积压、延迟飙升,甚至整个集群雪崩。一个没有监控的Flink作业,本质上是一颗定时炸弹------它今天可能每秒处理百万条消息,明天就可能静默地落在后面,直到下游消费者抱怨数据延迟,你才后知后觉。
在我们早期的生产环境下,也经历了很多 Flink 作业因监控缺失或不到位,导致背压失控、Checkpoint 失效、状态 OOM、数据延迟陡增等故障,未及时干预处理而引发业务影响。本文将从 Flink 监控底层逻辑出发,系统梳理生产必盯核心指标,构建一套完整的 Flink 作业监控体系。
二、Flink 监控底层逻辑:全维度指标体系框架
1.Flink 原生 Metric 分层体系(Job/Task/Operator/TM 层级)
Flink 的 Metric 系统采用层级化设计,从宏观到微观全面覆盖作业运行状态,核心层级如下:
| 层级 | 核心指标范围 | 典型指标示例 | 监控价值 |
|---|---|---|---|
| JobManager | 作业整体状态、资源使用、Checkpoint 全局信息 | numRestarts、runningTime、numFailedCheckpoints、taskSlotsAvailable | 作业级健康度总览 |
| TaskManager | 资源使用、JVM 状态、网络指标 | Status.JVM.CPU.Load、Status.JVM.Memory.Heap.Used、Status.Network.AvailableMemorySegments | 集群资源瓶颈定位 |
| Task | 子任务执行状态、背压、Checkpoint 进度 | numRecordsIn、isBackPressured、backPressuredTimeMsPerSecond、checkpointAlignmentTime | 任务级性能问题定位 |
| Operator | 算子输入输出、反压、延迟 | numRecordsInPerSecond、backPressuredTimeMsPerSecond、currentEmitEventTimeLag、KafkaConsumer.records.lag.max | 算子级业务性能监控 |
2.标配监控工具适配(Prometheus+Grafana、内置 Web UI 指标对应关系)
Flink 官方推荐Prometheus+Grafana作为生产级监控方案,同时提供内置 Web UI 用于快速排查问题。
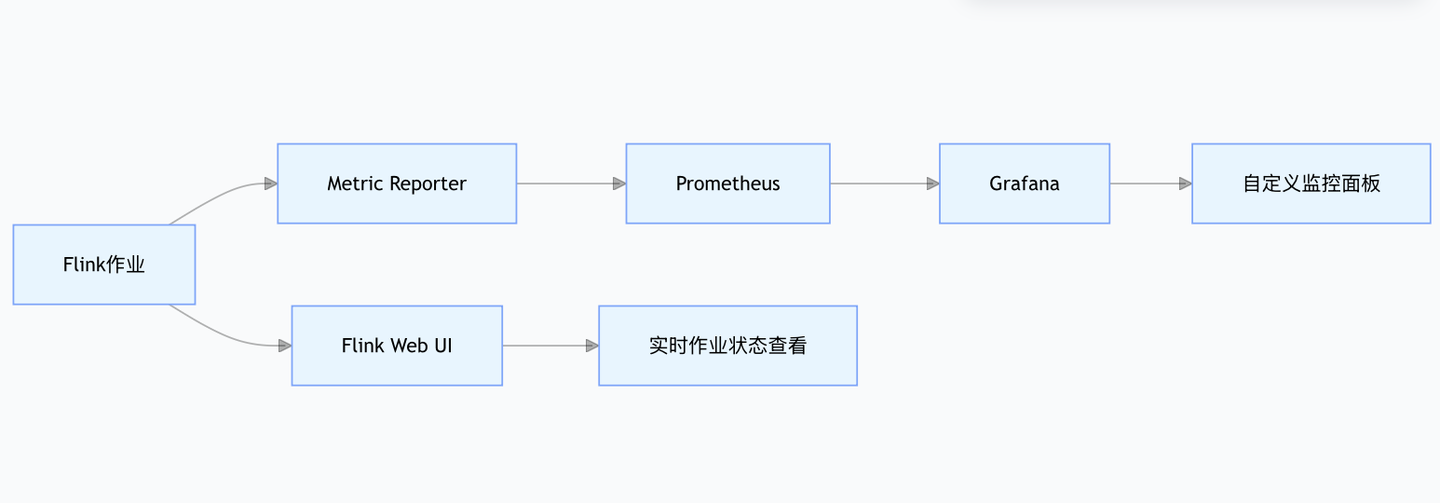
关键配置示例:
metrics.reporters:prom
metrics.reporter.prom.factory.class:org.apache.flink.metrics.prometheus.PrometheusReporterFactory
metrics.reporter.prom.port:9249三、Flink 生产作业必盯核心指标
1.吞吐量指标
吞吐量是最直观的健康信号------如果记录停止流动,肯定出问题了。
| 指标名称 | 含义 |
|---|---|
| numRecordsIn / numRecordsInPerSecond | 算子累计/每秒输入记录数 |
| numRecordsOut / numRecordsOutPerSecond | 算子累计/每秒输出记录数 |
| numBytesIn / numBytesInPerSecond | 算子累计/每秒输入字节数 |
| numBytesOut / numBytesOutPerSecond | 算子累计/每秒输出字节数 |
2.处理延迟指标
延迟指标回答一个核心问题:"数据从进入Flink到被处理完成,用了多长时间?"
| 指标名称 | 含义 |
|---|---|
| currentEmitEventTimeLag | kafka数据摄取时间与事件时间的延迟时间 |
| KafkaConsumer.records.lag.max | kafkasource算子消费分区滞后的最大偏移量 |
| currentInputWatermark | 算子最新收到数据的水位时间 |
| mailboxLatencyMs | task处理等待延迟 |
3.反压指标
反压是流处理中最典型的性能瓶颈信号------下游处理能力不足,导致数据在传输缓冲区中堆积。
| 标名称 | 含义 | 诊断意义 |
|---|---|---|
| outPoolUsage | 输出缓冲区使用率(0~1) | 高 → 下游处理慢,上游在等待下游 |
| inPoolUsage | 输入缓冲区使用率(0~1) | 高 → 上游发送快,或自身处理慢 |
| inputFloatingBuffersUsage | 浮动缓冲区使用率 | 高 → 全局缓冲区资源紧张 |
| inputExclusiveBuffersUsage | 独占缓冲区使用率 | 高 → 特定子任务缓冲区紧张 |
| backPressuredTimeMsPerSecond | 每秒反压的毫秒数(0-1000) | 高 → 下游处理慢 |
| busyTimeMsPerSecond | 每秒繁忙的毫秒数(0-1000) | 高 → taks/operator有瓶颈 |
4.Checkpoint健康度指标
Checkpoint是Flink保证容错和数据一致性的核心机制。一个持续失败的Checkpoint意味着作业在故障后将无法恢复到一致状态。
| 指标名称 | 含义 | 健康基准 |
|---|---|---|
| lastCheckpointDuration | 最近一次Checkpoint耗时(ms) | 建议 < Checkpoint间隔 |
| lastCheckpointSize | Checkpoint数据大小(bytes) | 应保持稳定或缓慢增长 |
| lastCheckpointAlignmentDuration | Barrier对齐耗时(ms) | 反压时会升高 |
| numberOfCompletedCheckpoints | 成功Checkpoint总数 | 应持续增长 |
| numberOfFailedCheckpoints | 失败Checkpoint总数 | 应接近0 |
5.Flink稳定性指标
| 指标名称 | 含义 | 健康基准 |
|---|---|---|
| runningTime | 运行时间 | 越大越健康 |
| numRestarts | 运行至今自动重启次数 | 0表示作业一直稳定运行,因网络抖动等偶发性因素导致次数增加也属正常 |
6.状态后端指标
状态是 Flink 处理有状态计算的核心,状态异常会导致性能下降甚至作业崩溃。
| 指标名称 | 含义 | 监控意义 |
|---|---|---|
| state.backend.rocksdb.metrics.block-cache-hit | RocksDB 缓存命中率 | 状态访问效率低 |
| state.backend.rocksdb.metrics.actual-delayed-write-rate | RocksDB写入延迟 | 状态存储性能差 |
| state.backend.rocksdb.metrics.block-cache-usage | RocksDB内存使用率 | 状态内存不足 |
| state.backend.rocksdb.metrics.compaction-pending | RocksDB 文件合并是否排队 | 状态后端io性能 |
| state.backend.rocksdb.metrics.mem-table-flush-pending | 等待刷盘的memtable数量 | 状态写入性能 |
重要提醒:RocksDB内部指标需通过配置开启,开启RocksDB监控会对性能造成5%~10%的损耗,生产环境中建议在排查问题时临时开启,优化完成后关闭。
7.资源指标
资源是 Flink 作业运行的基础,资源不足或分配不合理是最常见故障根源。
| 指标 | 含义 | 告警阈值参考 |
|---|---|---|
| Status.JVM.Memory.Heap.Used | 堆内存使用量 | > 80% 预警 |
| Status.JVM.Memory.Direct.MemoryUsed | 直接内存使用量 | > 80% 预警 |
| Status.JVM.CPU | cpu使用量 | > 80% 预警 |
| Status.JVM.GarbageCollector.*.Count / Time | GC次数与耗时 | Full GC时间 > 1s/分钟 |
| Status.JVM.Threads.Count | 线程总数 | 异常突增需排查 |
| Status.Network.* | 网络收发量 | 接近网卡上限 |
四、可视化大盘(Grafana)
推荐看板布局:
- 作业总览区:
- 作业状态、并行度、运行时长
- Checkpoint 成功率、最近一次耗时
- 总输入 / 输出 TPS、延迟概览
- 资源监控区:
- CPU 使用率(按 TaskManager)
- 内存使用率(堆 / 堆外)
- GC 停顿时间统计
- 背压监控区:
- 各算子背压状态热力图
- 背压时间趋势图
- 繁忙 / 空闲时间比例
- Checkpoint 详情区:
- Checkpoint 耗时分布
- 状态大小趋势
- Barrier 到达时间、对齐时间
- 延迟与水位线区:
- 端到端延迟分布
- 水位线滞后时间
- 数据积压量趋势
五、总结展望
监控的本质,是建立对作业"正常基线"的认知,然后识别出任何偏离基线的"异常偏差"。当你的Flink作业平稳运行时,你不需要紧盯着每一个指标------你需要的是在指标开始偏离基线的那一刻,快速收到告警,并知道从哪里开始排查。
最后,监控不是一次性工作,而是持续迭代的过程。随着业务发展和作业规模扩大,监控体系也需要不断优化,才能真正成为 Flink 实时作业的 "保命符"。