目录
[一、梯度下降法 回顾](#一、梯度下降法 回顾)
[1.了解 ------ 指数移动加权平局](#1.了解 —— 指数移动加权平局)
[1.1 公式](#1.1 公式)
[1.2 图例说明](#1.2 图例说明)
[1.3 结论](#1.3 结论)
[2.1 图解](#2.1 图解)
[2.2 如何选择优化方法](#2.2 如何选择优化方法)
[2.3 对应API](#2.3 对应API)
[动量法 Momentum](#动量法 Momentum)
[AdaGrad 自适应学习率](#AdaGrad 自适应学习率)
[RMSprop 自适应学习率](#RMSprop 自适应学习率)
[Adam 自适应矩估计](#Adam 自适应矩估计)
[AdamW 自适应矩估计](#AdamW 自适应矩估计)
[2.4 梯度下降法优化方法总结](#2.4 梯度下降法优化方法总结)
一、梯度下降法 回顾
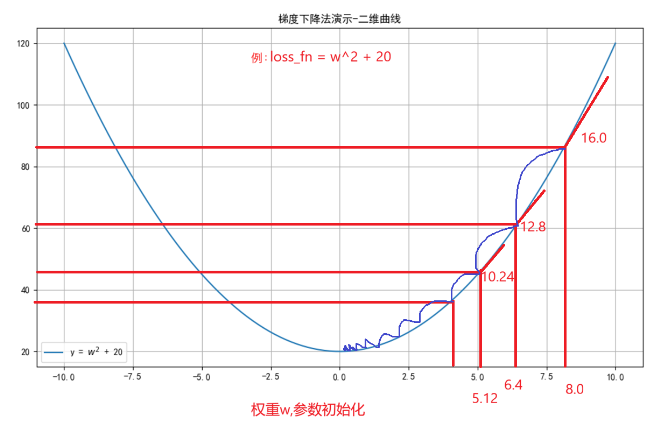
W新 = W旧 - 学习率 * 梯度
假设 学习率 lr = 0.1.
① 6.4 = 8.0 - 0.1 * 16.0
② 5.12 = 6.4 - 0.1 * 12.8
③ 4.01 = 5.12 - 0.1 * 10.24
...
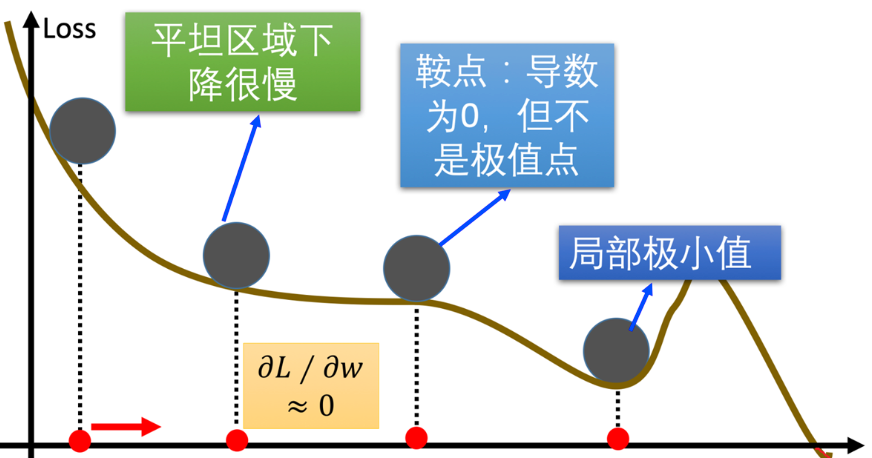
二、梯度下降法的缺点
1.碰到平缓区间,梯度值较小,参数优化变慢
2.碰到"鞍点",梯度为0,参数无法优化
3.碰到局部最小值,参数不是最优。无法跳出
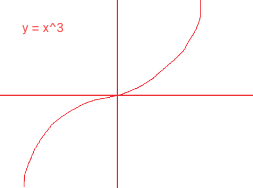
比如 y = x ^ 3 。x = 0的时候 就是"鞍点" 导数为0
三、如何选择优化方法
1.了解 ------ 指数移动加权平局
1.1 公式

1.2 图例说明
β = beta 一组散点天气数据
beta = 0 beta = 0.5
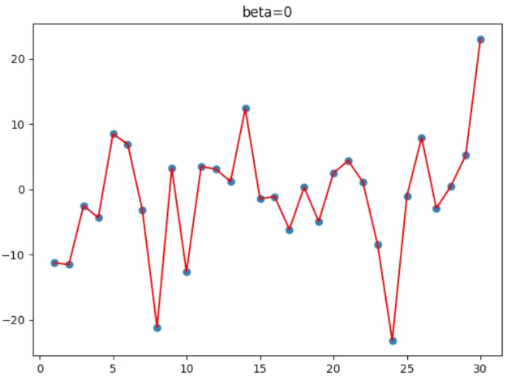
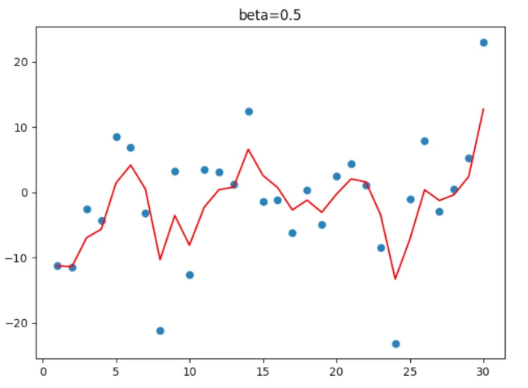
beta = 0.9 beta = 1
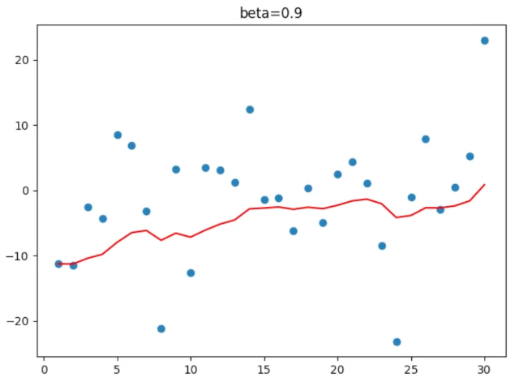
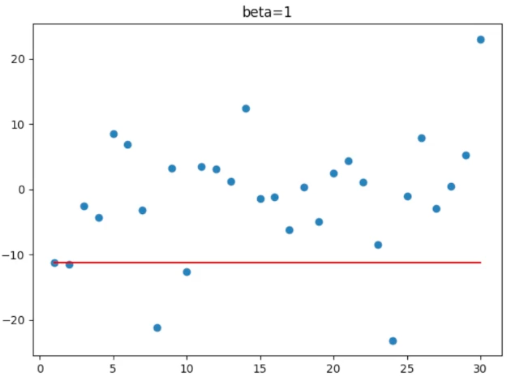
1.3 结论
1.对于指数移动加权平均值
β 值(调节系数)越大,移动加权平均值越平缓,越考虑历史数据。
β 值 越小,移动加权平均值越接近当前数据。
2.特例:β 值 = 0,就是当前数据的原始值
β 值 = 1,就是第一天的初始值
2.优化方法:
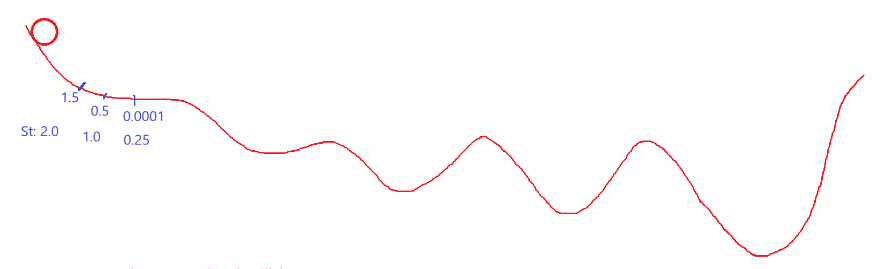
2.1 图解
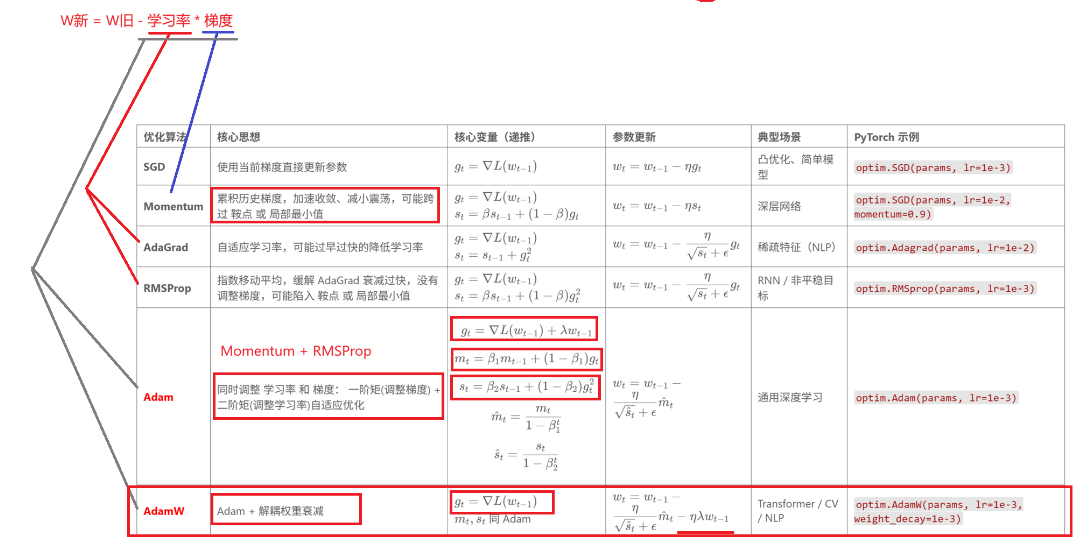
2.2 如何选择优化方法
++* Adam / AdamW (推荐) -> RMSprop -> 动量法 Momentum -> 原始SGD,AdaGrad (不建议)++
++对比 Adam 和 AdamW++
Adam:
① 同时调整 学习率 和 梯度
② 使用梯度一阶矩来调整梯度,二阶矩来调整学习率
AdamW:
① Adam的优化版
② 解耦了权重衰减
③ 原始Adam直接在梯度中添加了 权重衰减项,使得调整梯度和调整学习率藕合在一起,会造成模型训练后期不稳定。
④ AdaW 使用原始梯度,在更新参数时直接添加权重衰减项目,解耦了调整梯度和调整学习率
2.3 对应API
python
# 优化器模块,实现梯度下降法以及梯度下降的优化方法
import torch.optim as optim 动量法 Momentum
python
optim.SGD([w],lr=0.01,momentum=0.95)AdaGrad 自适应学习率
python
optim.Adagrad([w],lr=0.01)RMSprop 自适应学习率
python
optim.RMSprop([w],lr=0.01)Adam 自适应矩估计
python
optim.Adam([w],lr=0.01)AdamW 自适应矩估计
python
optim.AdamW([w],lr=0.01)2.4梯度下降法优化方法总结
-
SGD原始梯度下降法:optim.SGD, 使用当前梯度直接更新参数,用于凸优化问题,容易陷入局部最优解
-
动量法Momentum: optim.SGD(momentum=0.9), 引入动量概念,利用历史梯度信息,加速收敛
-
AdaGrad: optim.Adagrad, 自动调整学习率,学习率下降过快过早,导致模型更新慢
-
RMSprop: optim.RMSprop, 自动调整学习率,对AdaGrad的改进
-
Adam: optim.Adam, 结合 动量法和RMSprop,同时调整学习率和梯度,训练稳定
-
AdamW: optim.AdamW, 对Adam的改进,解决权重衰减问题,推荐使用