快速了解部分
基础信息(英文):
- 题目: Being-H0.7: A Latent World-Action Model from Egocentric Videos
- 时间: 2026.04
- 机构: BeingBeyond Team
- 3个英文关键词: Latent World-Action Model, Egocentric Videos, Robot Learning
1句话通俗总结本文干了什么事情
在VLA和WAM之间找平衡:用少量latent query在隐空间做"未来推理",既保留VLA的推理效率,又获得WAM的未来感知能力,预训练20万小时第一人称视频后在多个机器人benchmark上SOTA。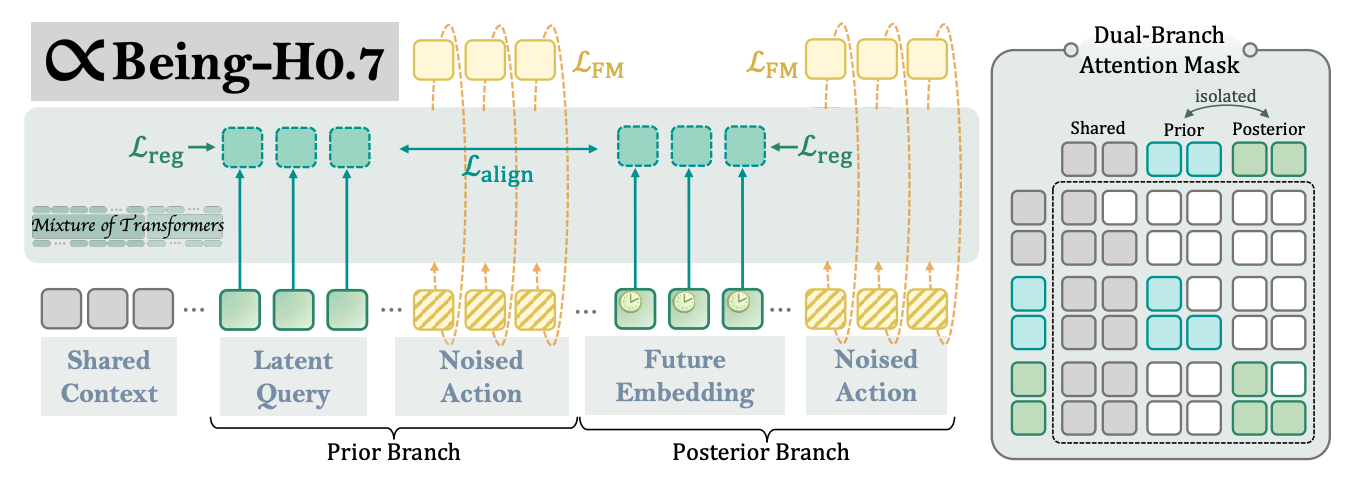
研究痛点:现有研究不足 / 要解决的具体问题
- VLA: 直接从观测映射到动作,但动作监督稀疏,容易学到表面相关性而非物理规律,行为模式单一易崩溃
- WAM: 通过视频生成建模未来,但推理时需要rollout未来帧,延迟高,像素预测误差会传播到动作导致长程任务失败
- 训练成本悬殊:Cosmos Policy训练需3000+ H100小时,而VLA如Being-H0.5仅需~50小时,效率差60倍
核心方法:关键技术、模型或研究设计(简要)
- 引入少量learnable latent queries作为compact reasoning interface,位于multimodal context和action之间
- 双分支设计:prior分支(仅当前上下文)+ posterior分支(可看未来观测),通过hidden state alignment让prior学会从当前上下文推断未来相关信息
- 仅prior分支用于推理,posterior仅训练时用,实现"训练时看未来,推理时靠直觉"
- 用norm和rank regularization防止latent空间magnitude/directional collapse
深入了解部分
作者想要表达什么
世界建模不必在像素空间显式预测未来帧,可以在action-oriented的latent space中隐式完成。关键不是"选VLA还是WAM",而是用latent reasoning space桥接两者:抽象到能捕捉任务语义,紧凑到能过滤像素冗余,grounded到能支持dense控制。
相比前人创新在哪里
- 不同于VLA直接观测→动作,引入latent reasoning space组织未来相关信息,避免行为崩溃
- 不同于WAM在像素空间rollout未来,在latent space对齐future-aware表示,推理时无需生成未来帧,保持低延迟
- 双分支joint alignment + lightweight regularization,用单前向传播(MoT结构)实现双分支训练,效率远高于独立双模型
解决方法/算法的通俗解释
想象机器人要做决策:
- 传统VLA:看到什么就马上动,不太考虑"接下来会怎样",容易在动态场景中翻车
- 传统WAM:先脑补一堆未来画面再决定怎么动,慢且容易脑补错,错一步步步错
- Being-H0.7:在脑子里先快速过一遍"关键的未来信息"(用16个latent query表示),再决定动作。训练时偷偷给模型看真实未来,让它学会哪些未来信息对决策有用;推理时不用看未来,靠学过的"直觉"快速推理。
解决方法的具体做法
- 序列构造:instruction; obs history; state; latent queries Q; noised action chunk,Q∈R^K×d参与Transformer逐层传播
- 双分支实现(单前向传播,MoT结构):
- Prior: 输入=当前上下文+learnable Q → 预测动作
- Posterior: 输入=当前上下文+future embeddings(由未来观测经frozen ViT+Perceiver编码)→ 预测动作
- 双分支attention mask:shared context可见,branch-specific tokens隔离,仅通过对齐的latent states交互
- 损失函数:
- Flow matching loss:两分支分别预测action velocity,监督动作生成
- Alignment loss: L2对齐两分支在latent query位置的hidden states(多层)
- Regularization: norm约束防magnitude collapse + rank约束(Gram矩阵熵)防directional collapse
- 推理:仅用prior分支,latent queries已通过学习具备"未来感知"能力
基于前人的哪些方法
- VLA框架(π0, Being-H0.5):multimodal input + flow matching action head + chunked action prediction
- World modeling for robotics(DreamZero, Cosmos Policy, Fast-WAM):用video prior增强策略
- JEPA-style latent predictive learning:在表示空间而非像素空间做预测
- Mixture-of-Transformers:高效实现多分支共享主干
实验设置、数据、评估方式、结论
- 数据:200,000小时egocentric human videos(~15×Being-H0.5)+ 15,000小时robot demonstrations,32种pretrained embodiments
- 模型:3B参数,flow matching action head,K=16 latent queries,H=4观测horizon,T=20 action chunk
- Simulation benchmark(6个):LIBERO(99.2%), RoboCasa-50(62.1%), GR1(49.2%), LIBERO-plus(82.1%/84.8%), RoboTwin 2.0(90.2%/89.6%), CALVIN(4.67/4.48 avg tasks),整体SOTA
- Real-world(3平台12任务):PND Adam-U/Unitree G1/Franka FR3 + Linkerbot O6手,5类能力suite(dynamic scene/physical reasoning/motion reasoning/long horizon/generalization),Being-H0.7全领先
- 效率:推理延迟3.5ms/step(UAC机制),GPU显存5.6GB,与VLA相当,远低于WAM
提到的同类工作
- VLA路线:π0/π0.5, OpenVLA, gr00t-N1, Being-H0.5, StarVLA, UniVLA, X-VLA
- World-Action Model路线:DreamZero, Cosmos Policy, LingBot-VA, Fast-WAM, UWM, UVA, VPP, JEPA-VLA, VLA-JEPA
- Latent predictive方法:JEPA, FLARE, Motus
和本文相关性最高的3个文献
- Fast-WAM11: 同样关注推理效率,训练时用video co-training,推理时skip future generation,与本文"训练看未来/推理不用"理念最接近
- JEPA-VLA58/VLA-JEPA: 用latent predictive representation增强VLA,与本文latent world modeling在表示空间建模未来的思路高度相关
- Cosmos Policy9: 用pretrained video model fine-tune for robot control,代表pixel-space WAM路线,与本文形成效率/效果对比基准