摘要
极端环境中的微生物是新型代谢物的重要来源,但其全球多样性与生物合成潜力尚未被充分挖掘。本研究从2,293个公共宏基因组和3,214个微生物分离株中重构78,213个细菌和古菌基因组,构建了统一数据库------极端环境微生物组目录(EEMC)。EEMC扩充了全球已知的系统发育多样性,涵盖32,715个代表性物种和近40亿个非冗余基因,其中分别有63.00%和19.21%为此前未注释的新类群;该目录还包含163,693个生物合成基因簇,归为64,733个基因簇家族,其中58.68%为新型簇,凸显了各类极端生境中微生物群落的功能多样性。本研究进一步开发蛋白质大语言模型,从EEMC中预测基因组编码的候选抗菌肽(cAMPs),筛选出3,032个无毒候选肽。合成的100个肽中84%具有抗菌活性,所有50个受试cAMPs均表现出低细胞毒性。值得注意的是,6个活性最强的cAMPs在体外对多重耐药革兰氏阴性病原菌具有显著抑制效果,展现出生物医药应用潜力。综上,本研究构建的EEMC为挖掘新型微生物类群与生物合成功能提供了基础资源,彰显了其在药物研发中的重要价值,为生物技术与生物医学的未来发展奠定基础。
#极端环境微生物组 #微生物多样性 #生物合成基因簇 #抗菌肽 #蛋白质大语言模型 #宏基因组
结果
EEMC包含20,610个未被表征的微生物新物种
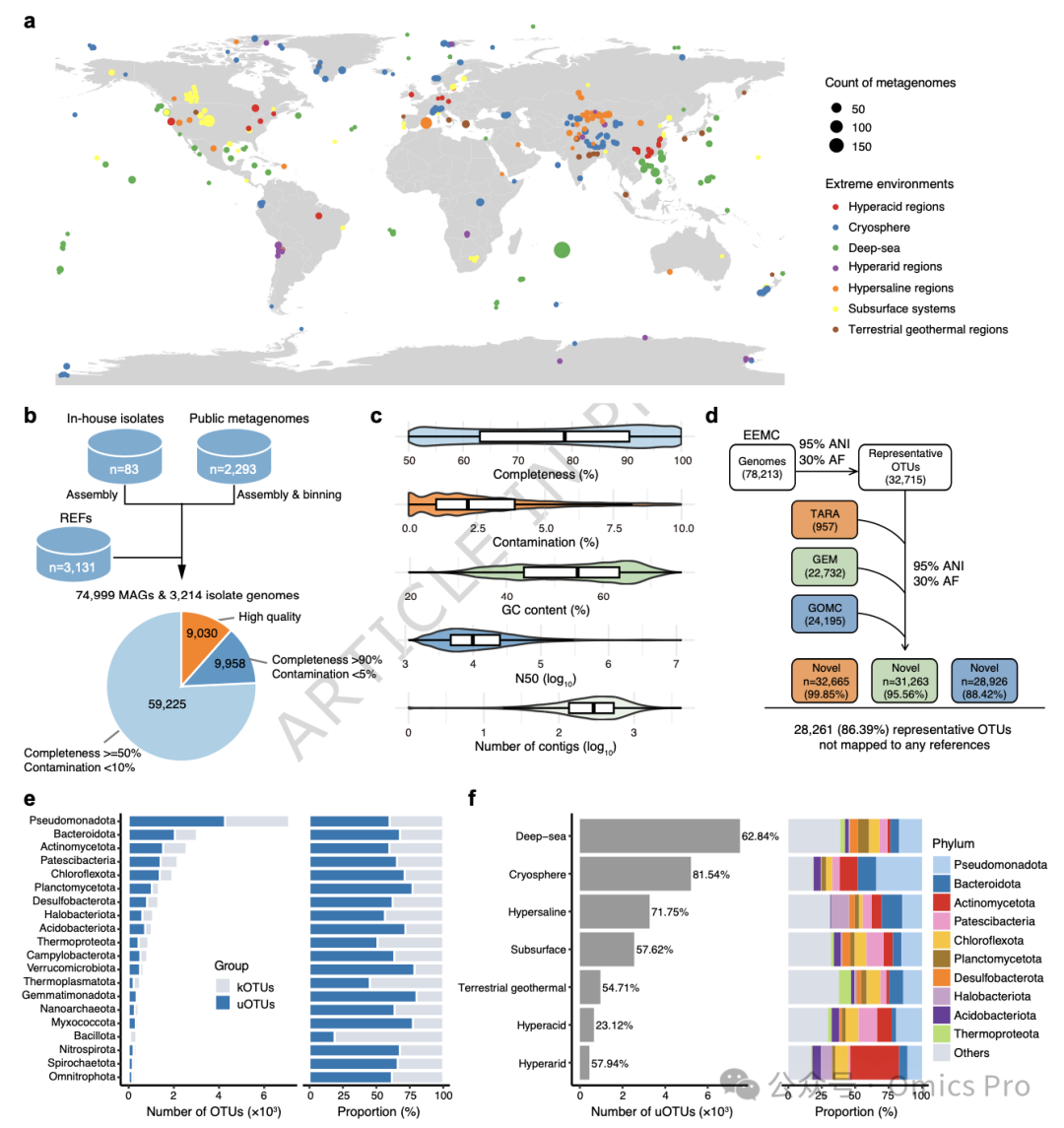
图 1 EEMC基因组的环境分布及其物种水平聚类
a,各生境中2,293个公共宏基因组的地理分布。
b,从2,293个宏基因组和3,214个可培养分离株中回收78,213个基因组,所有基因组均满足完整性≥50%、污染率<10%的质量标准。
c,78,213个基因组的质量指标分布,箱线图为第1至第3四分位距,内部横线为中位数,小提琴图展示数据全分布。
d,基于95%平均核苷酸一致性(ANI)和30%比对覆盖率(AF),将EEMC基因组聚类为32,715个物种水平可操作分类单元(OTU);通过与TARA、GEM、GOMC的代表性基因组聚类,评估EEMC物种新颖性。
e,前20个门中已知OTU(kOTU)和未分类OTU(uOTU)的数量与占比。
f,各极端环境中uOTU的数量及前10个门的组成,标注各环境uOTU占比。
EEMC包含近40亿个非冗余基因,展现出广泛的多样性与显著的新颖性
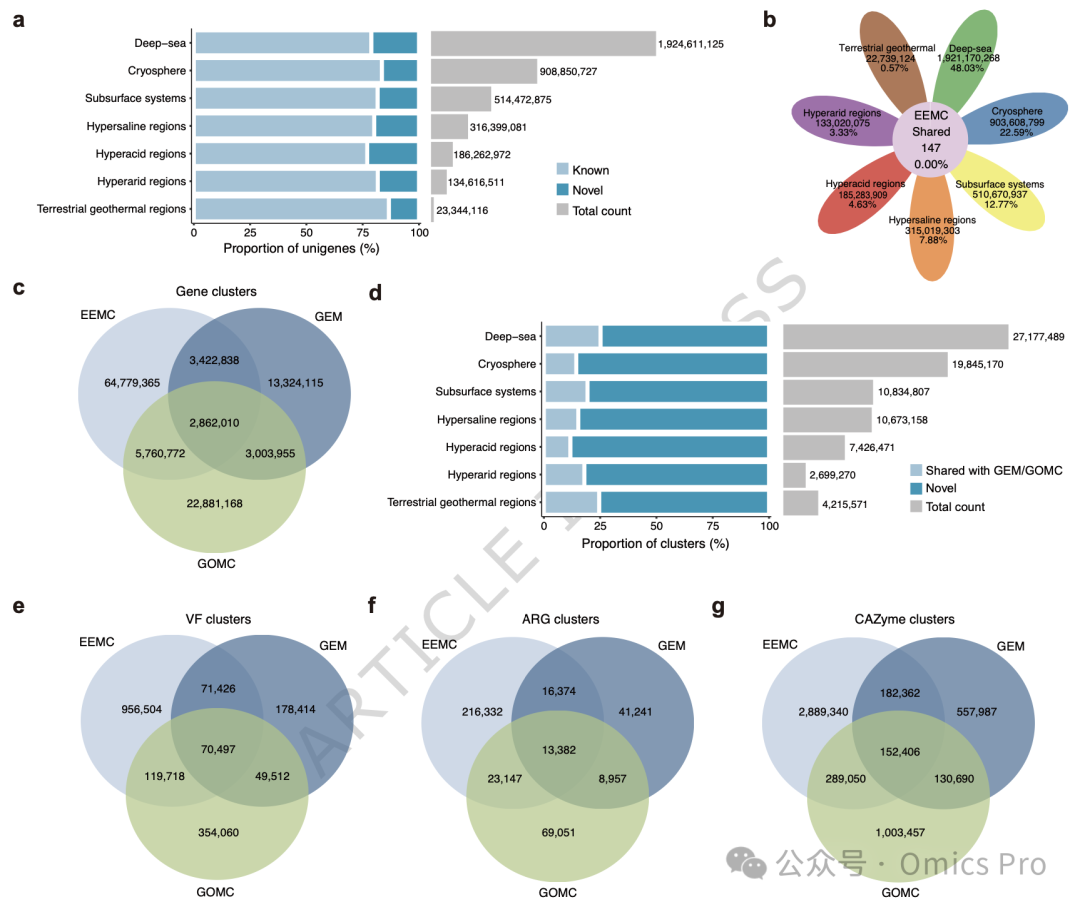
图 2 EEMC中非冗余基因与基因组来源基因簇概览
a,各极端环境中单基因的新颖性与总数。
b,各极端环境特有及所有环境共享的单基因数量。
c,维恩图展示EEMC、GEM、GOMC数据集间基因组来源基因簇的重叠情况。
d,各极端环境中基因组来源基因簇的新颖性与总数。
e-g,维恩图展示3数据集间毒力因子、抗生素抗性基因、碳水化合物活性酶相关基因簇的重叠情况。
EEMC具有广泛多样的生物合成潜力,包含超16.3万个生物合成基因簇
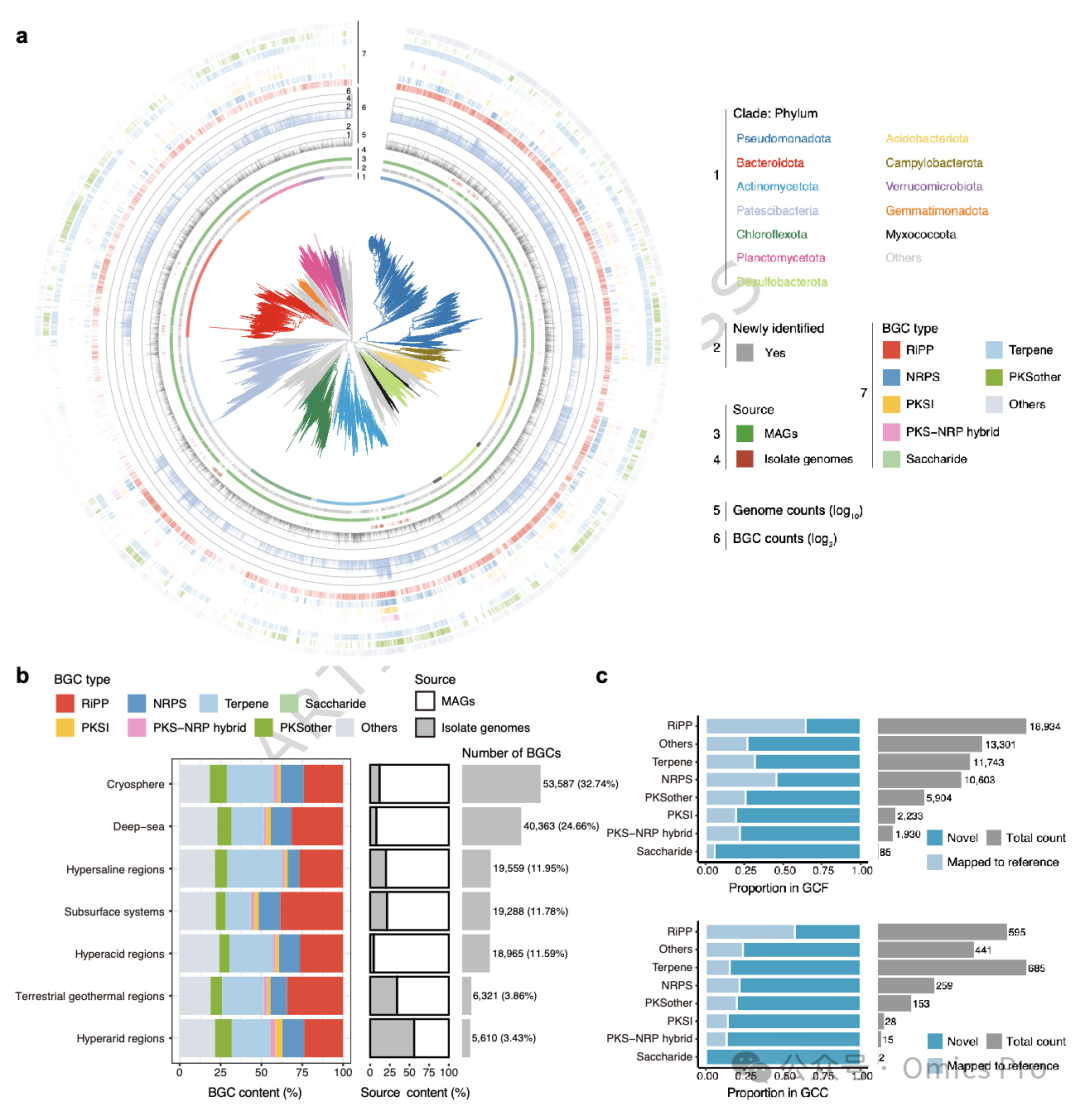
图 3 EEMC基因组的新颖性与系统发育组分布及其生物合成潜力
a,基于120个通用细菌单拷贝基因构建32,715个代表性OTU的系统发育树,分支与外层标注物种门、新颖性、基因组来源、数量、BGC数量及类型。
b,7类极端环境中BGC类型组成、MAG与分离株基因组BGC占比、各环境BGC数量。
c,163,693个BGC聚类为基因簇家族(GCF)和基因簇簇(GCC),展示各类型新颖性与总数。
预测抗菌活性与毒性的深度学习模型
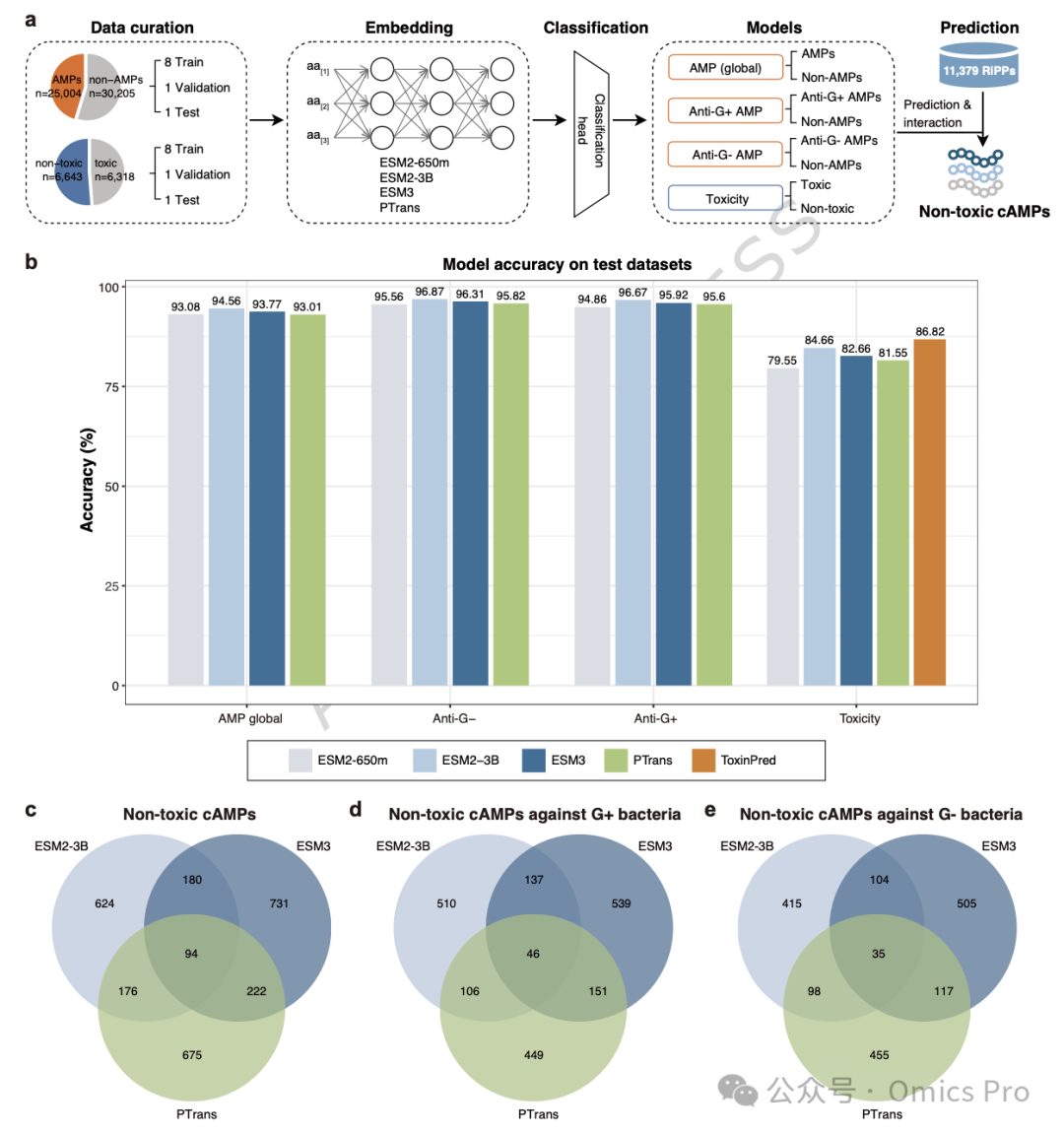
图4 抗菌肽与毒性预测深度学习模型的概览及性能
a,蛋白质大语言模型(pLLM)的数据收集与架构,全局/抗G+/抗G- AMP模型、毒性模型的训练数据,及对11,379个RiPP的预测流程。
b,4种pLLM在2元标签测试集上的准确率。
c-e,3种模型鉴定出的抗微生物、抗G+、抗G-无毒候选抗菌肽(cAMP)的交集分布。
EEMC的cAMPs对多种病原菌具有抑菌活性
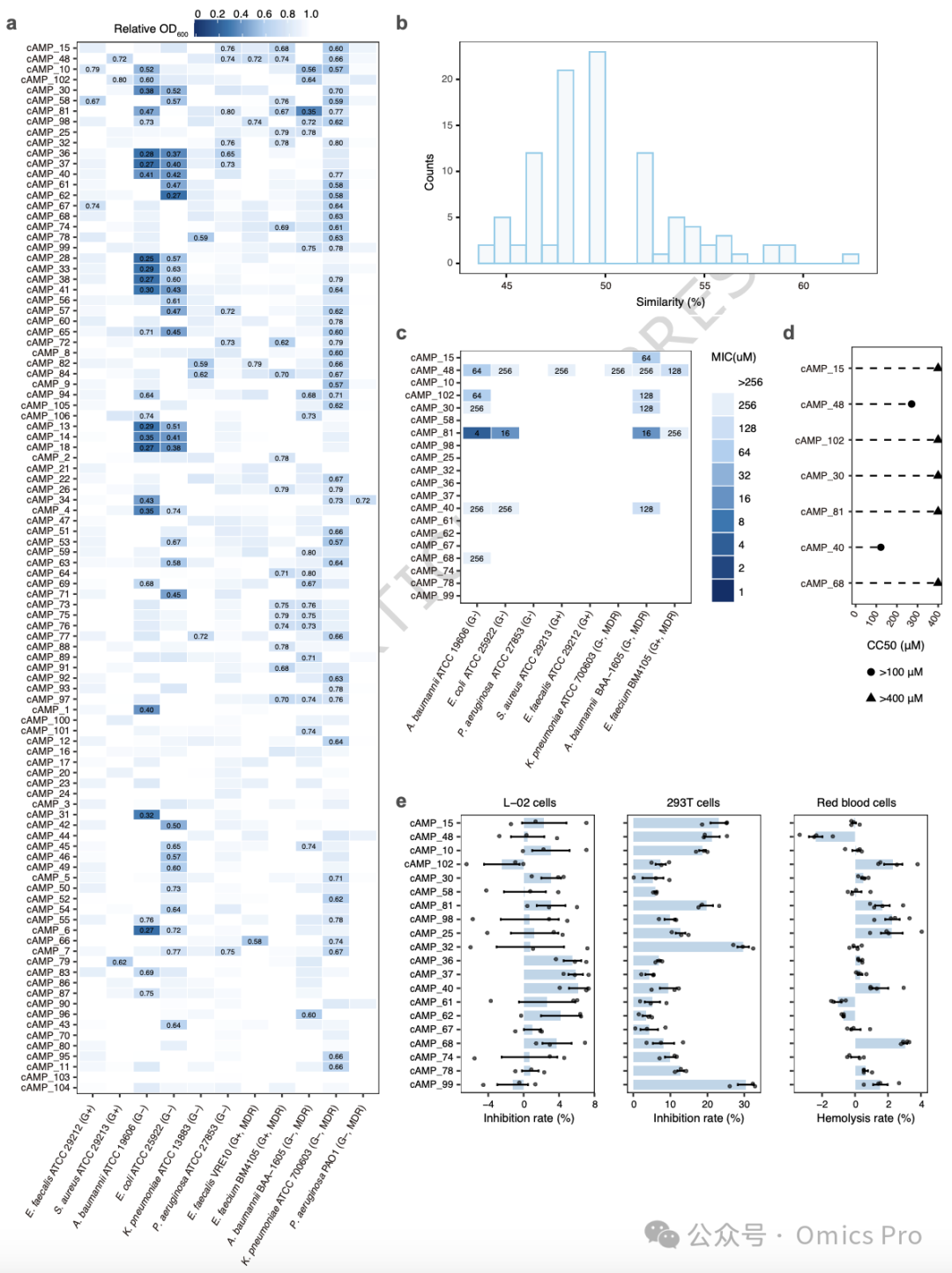
图5 候选抗菌肽的实验验证与效价检测
a,60μM cAMP处理下菌体相对OD600热图,标注抑菌有效数值。
b,合成cAMP与已知AMP的序列相似度分布。
c,20个优选cAMP对8种病原菌的最低抑菌浓度(MIC)。
d,7 个cAMP的50%细胞毒性浓度(CC50)。
e,优选cAMP的细胞毒性与溶血率检测结果。
圆2色谱的肽结构测定及cAMPs作用机制研究
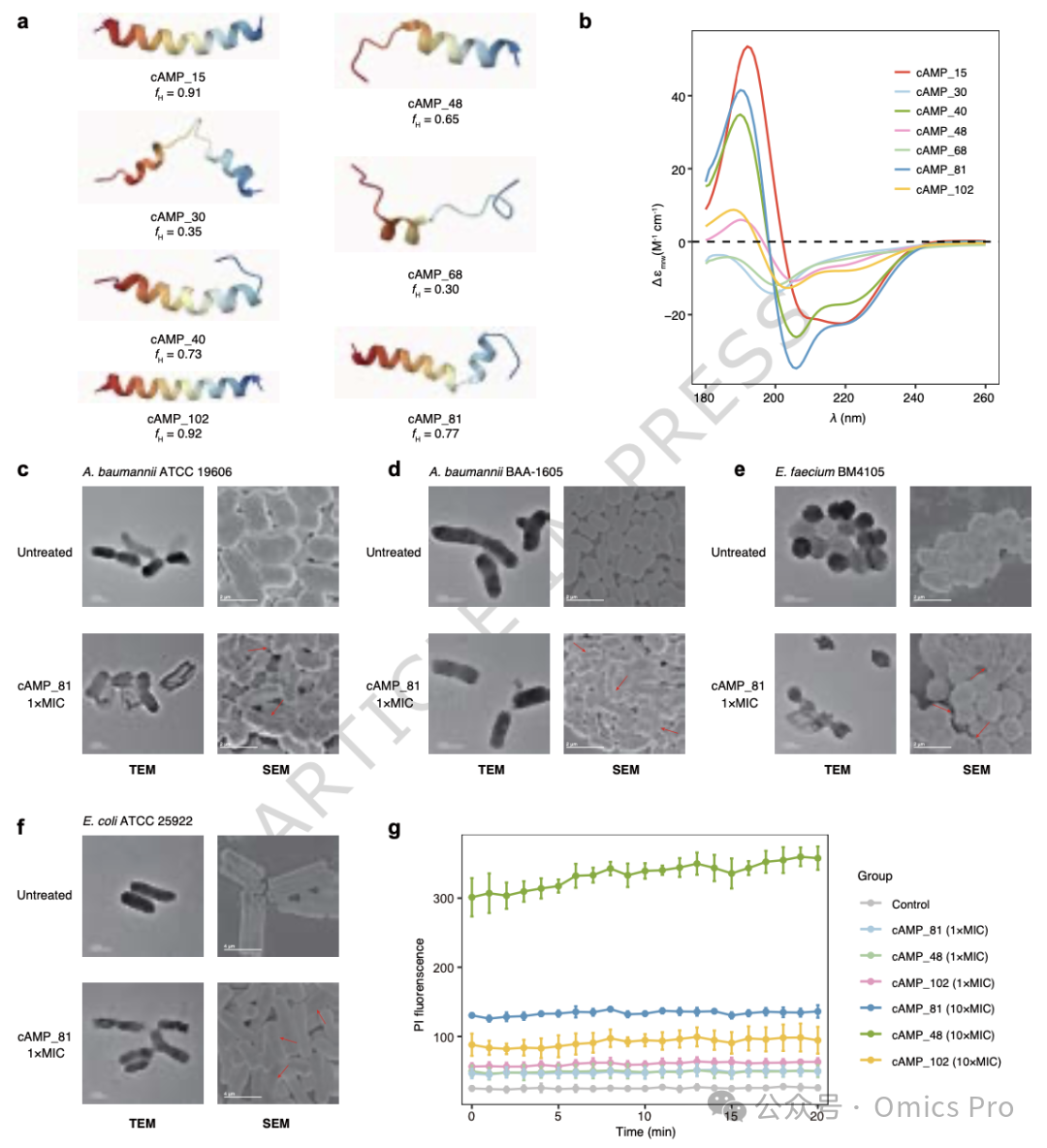
图6 肽结构的圆2色谱测定与候选抗菌肽作用机制研究
a,7个cAMP的AlphaFold3三维结构预测。
b,7 个cAMP的圆2色谱结果。
c-f,cAMP_81处理后病原菌的透射电镜与扫描电镜结果,显示细胞膜破损。
g,cAMP对鲍曼不动杆菌膜完整性的影响。
数据
本研究生成的全部74,999个宏基因组组装基因组(MAGs)、83个深海自研分离株基因组、来自组装重叠群与基因组的非冗余基因集,以及16,3693个生物合成基因簇(BGCs)均已提交至国家基因库数据库(CNGBdb),登录号为CNP0007106
https://db.cngb.org/search/project/CNP0007106/
参考代表性基因组包括:基因组分类数据库(GTDB)R220版的113,104个、地球微生物组基因组目录(GEM)的22,732个、全球海洋微生物组目录(GOMC)的24,195个、塔拉海洋计划(Tara Ocean)的957个
https://portal.nersc.gov/GEM/genomes/
https://db.cngb.org/maya/datasets/MDB0000002
https://merenlab.org/data/tara-oceans-mags/
人类肠道统一基因组目录v2.0版(UHGG v2.0)的4,472个代表性基因组
https://www.ebi.ac.uk/metagenomics/genome-catalogues/human-gut-v2-0-2
代码
Zenodo
https://zenodo.org/records/17613552
GitHub
https://github.com/BGI-METAI/Metagenome-AI
详细总结
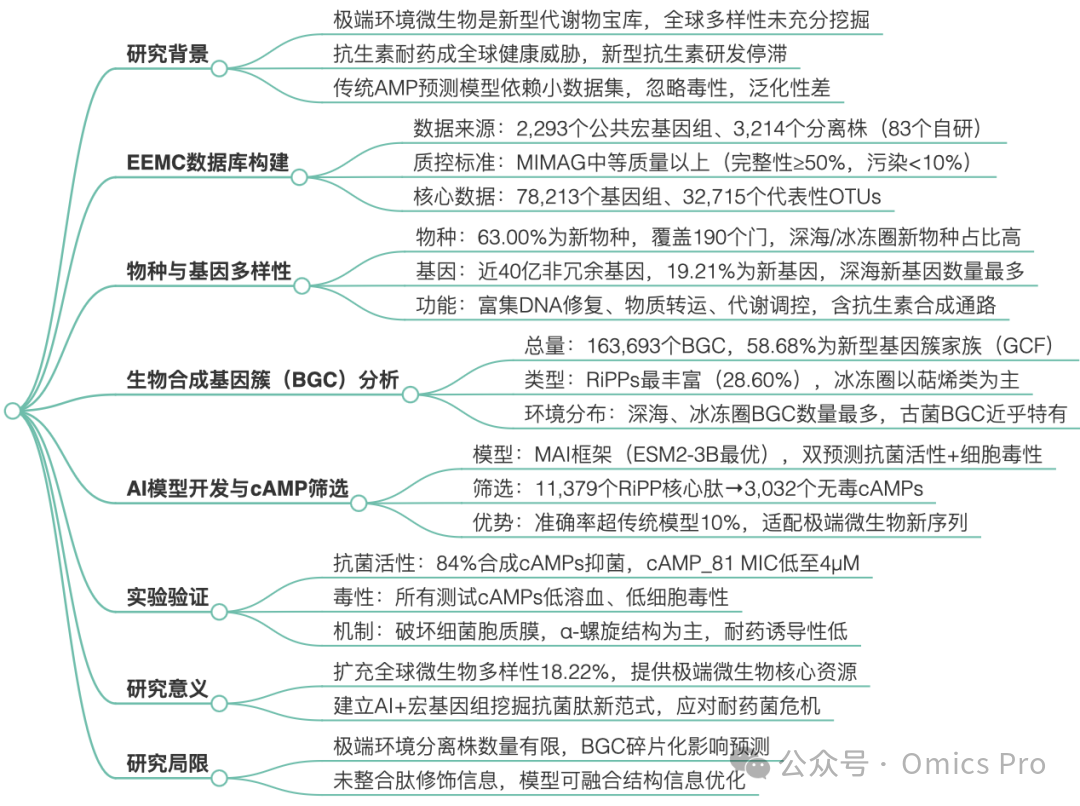
思维导图
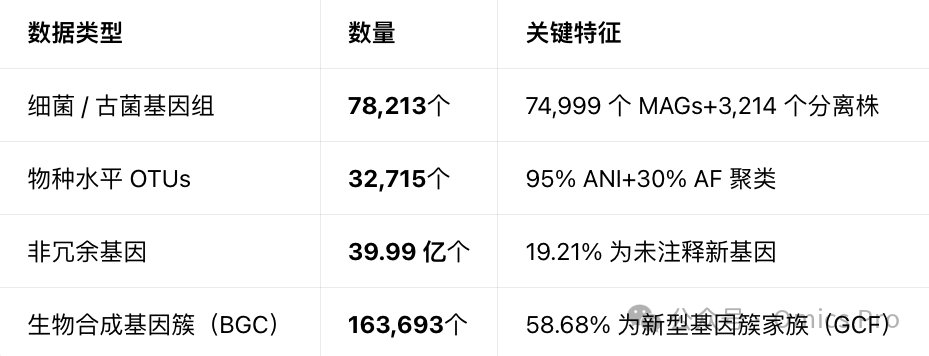
核心数据规模
参考
Nat Commun. 2026 Apr 2. doi: 10.1038/s41467-026-71145-0.
The Extreme Environment Microbiome Catalog (EEMC): a global resource for microbial diversity and antimicrobial discovery
注:AI辅助创作,如有错误欢迎指出。内容仅供参考,不构成任何建议。