LLMs之Memory之MIA:《Memory Intelligence Agent》翻译与解读
导读 :这篇论文的核心贡献,是把深度研究代理的"记忆"从简单的长上下文检索,升级为可压缩、可训练、可在线进化的双通道系统;MIA 通过 Manager-Planner-Executor 架构、交替 RL 和 test-time learning,把历史经验真正转化为规划能力与执行能力,因此在多模态、文本、多跳推理以及无监督自演化场景里都表现出稳定而明显的提升。
>> 背景痛点
● 长上下文记忆并不适合深度研究代理:现有深度研究代理(DRA)虽然会把历史轨迹放进长上下文里做检索,但这会带来注意力稀释、无关信息噪声、存储膨胀和检索开销上升等问题,反而影响推理效率与效果。论文进一步指出,这类方法更擅长存"结果是什么"的知识型记忆,而深度研究更需要"如何得到结果"的过程型记忆。
● 只做相似检索,难以真正复用经验:已有记忆系统往往只是从历史轨迹里找相似案例来提示模型,但它们通常缺少任务特定训练,Planner 规划能力不足,Executor 也难以真正理解并执行规划指令,因此整体收益有限。
● 记忆越多,成本越高,但效果未必更好:论文强调,传统长上下文记忆会让存储与检索成本持续增长,而对连续运行的 agent 来说,这种"越积越多"的机制很难长期维持。与此同时,历史经验若不能被有效压缩和内化,就只是在制造更大的上下文负担。
● 开放世界下还缺少自我演化能力:很多系统在有标注时还能工作,但在稀疏监督或无监督环境里,记忆系统如何持续进化、如何自我修正,仍然缺少有效机制。论文把这点视为深度研究代理走向长期自主能力的关键瓶颈。
>> 具体的解决方案
● 提出 MIA 框架:论文提出 Memory Intelligence Agent(MIA),采用 Manager-Planner-Executor 三层架构,把历史轨迹、参数化规划和动态执行拆分开来,让记忆不再只是"堆在上下文里",而是成为可压缩、可检索、可训练的系统能力。
● 用 Manager 压缩并管理非参数记忆:Manager 会把冗长的历史搜索轨迹压缩成结构化 workflow summary,并将图像转为文本 caption 后再做存储;检索时还同时考虑语义相似度、价值奖励、频率奖励,从而兼顾相关性、质量与长尾探索。
● 让 Planner 负责"思考与规划":Planner 作为认知中枢,接收检索到的历史轨迹后,用 few-shot CoT 把复杂问题拆成可执行子目标,并生成计划;随后还可以根据 Executor 的反馈触发 reflection,生成补充计划。
● 让 Executor 负责"执行与工具调用":Executor 在 ReAct 风格下完成工具调用、观察环境、产出中间推理与最终答案,并严格跟随 Planner 的计划与重规划指令,从而把"会想"和"会做"分开优化。
● 通过两阶段交替 RL 打通 Planner 与 Executor:第一阶段先训练 Executor 学会理解并执行 Planner 的计划;第二阶段冻结 Executor、训练 Planner 以增强规划和反思能力。该设计用 GRPO 作为基础,并通过交替训练让高层规划与低层执行互相对齐。
● 加入 test-time learning 做在线进化:在测试阶段,MIA 同时做探索、存储、学习,把新轨迹一边转成非参数记忆,一边更新 Planner 参数;这样可以在不打断推理流程的情况下,让系统边用边学、边查边长。
● 加入反思与无监督判断机制:MIA 通过 LLM Judger、reflection 以及无监督判别,把成功轨迹和失败轨迹都转化为训练信号;成功轨迹优先选最短正确路径,失败轨迹则随机采样以保留错误模式,帮助未来规避坑点。
>> 核心思路步骤
● 步骤一:检索历史经验:当 Memory Manager 中积累到足够轨迹后,系统会针对当前输入检索相似历史经验,并结合语义、价值、频率三项得分筛出更有用的轨迹,作为 Planner 的上下文先验。
● 步骤二:Planner 生成计划:Planner 基于检索结果输出分步骤计划,把复杂问题拆成一系列可执行子目标,同时在需要时生成 replan/reflect 指令。
● 步骤三:Executor 按计划执行并交互工具:Executor 根据计划进行工具调用、观察反馈、修正动作,并形成完整 trajectory;这个过程既是推理过程,也是后续记忆构建的原材料。
● 步骤四:结果评估与轨迹压缩:LLM Judger 会评估最终答案正确性,然后 Manager 将成功与失败轨迹分别抽取为正/负范式,压缩成结构化 workflow,更新到非参数记忆库。
● 步骤五:交替训练优化协作:先让 Executor 学会执行计划,再用训练好的 Executor 反向帮助 Planner 学会更好的计划与反思,两者交替优化,使规划与执行逐步协同。
● 步骤六:测试时持续吸收新经验:TTL 阶段中,MIA 会把探索过程中得到的新轨迹同步写入非参数记忆,并更新 Planner 的参数记忆,实现 context 与 parameter 两条路径的共同进化。
>> 优势
● 既降噪,又降存储负担:把冗长轨迹压缩成结构化 workflow 后,MIA 能显著减轻长上下文噪声和存储压力,同时提升检索精度与检索质量。
● 能把历史经验内化成能力:MIA 不只"记住"经验,还把经验转成 Planner 参数,形成 parametric memory,因此更容易把过去的成功策略内化为长期能力。
● 训练与测试都能持续变强:交替 RL 让 Planner 与 Executor 在训练期互相适配,TTL 让系统在测试期继续吸收新经验,因此它不是一次性训练完就结束,而是能持续演化。
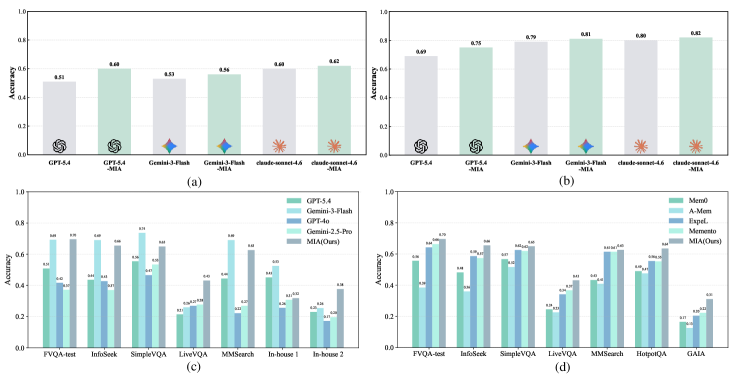
● 对小模型尤其友好:实验显示,使用 Qwen2.5-VL-7B 作为 Executor 时,MIA 在评测数据集上的平均提升达到 31%,并且在部分任务上甚至优于更大的 Qwen2.5-VL-32B,说明它对模型规模具有较强的放大效应。
● 对闭源与开源模型都有效:MIA 不仅提升开源模型,也能稳定增强 GPT-5.4、Gemini-3-Flash、Claude-Sonnet-4.6 这类闭源模型,说明它更像一种通用记忆增强层,而不是绑定某个基座模型的特定技巧。
● 工具简单但效果强:论文指出,MIA 只使用基础文本搜索和图像搜索工具,却能超过更复杂的 agentic 系统,说明性能提升主要来自记忆与经验内化,而不是更花哨的工具堆叠。
>> 论文结论与观点(侧重经验与建议)
经验
● 直接把历史上下文喂给模型并不划算:传统 contextual memory 往往比"No Memory"还差,说明"记得更多"不等于"答得更好",关键在于能否过滤噪声并把经验变成结构化先验。
● 让记忆服务于规划,比让记忆直接服务执行更有效:论文发现,把 memory 作为 Planner 的上下文先验,比直接喂给 Executor 更能提升性能;这说明记忆的最佳用法不是替代思考,而是先帮助制定更好的思考路径。
● 反思机制对复杂任务有实质帮助:在加入 reflection 后,系统在多跳推理上继续提升,尤其在 text-only 与 multimodal 任务中都出现了稳健增益,说明"执行---反思---再执行"比单次规划更适合深度研究。
● 交替 RL 能让小 Planner 追上甚至部分超越大 Planner 的效果:论文指出,使用更小的 Qwen3-8B Planner 通过 alternating RL 训练后,效果还能继续提升,这说明参数规模并不是决定性瓶颈,训练方式同样关键。
● TTL 是效果跃升的关键环节:在消融实验里,加入 TTL 后,multimodal 与 text-only 的平均准确率分别再提升 3.23 和 2.64,证明测试时在线进化是 MIA 性能闭环中非常重要的一环。
● 无监督场景也能逐步自我进化:论文发现,单纯无监督非参数记忆并不稳定,但加上 TTL 后性能显著提升,而且同一数据集重复见到第二、第三轮时,表现会继续稳步上升,说明系统能在探索中积累可复用经验。
建议
● 未来应把记忆系统做成"上下文 + 参数"双通道:论文实际上给出的建议是,不要只做显式记忆或只做参数更新,而要把两者结合起来,让经验既能被检索,也能被内化。
● 把深度研究代理训练成可持续学习的系统:作者在结论中明确表示,未来会把 MIA 扩展到更复杂、更动态的环境,这意味着研究方向应从一次性 benchmark 优化,走向长期自主演化。
目录
[《Memory Intelligence Agent》翻译与解读](#《Memory Intelligence Agent》翻译与解读)
[Figure 1:(a). Comparisons between frontier LLMs and their MIA-enhanced counterparts on the LiveVQA (multimodal) dataset. (b). Comparisons between frontier LLMs and their MIA-enhanced counterparts on the HotpotQA (text-only) dataset. (c). Comparisons between MIA based on Qwen2.5-VL-7B Executor with larger LLMs (in non-tool-calling settings) across seven diverse datasets. (d). Comparisons between MIA and SOTA memory frameworks based on Qwen-2.5-VL-7B Executor across seven diverse datasets.图 1:(a). 在 LiveVQA(多模态)数据集上前沿 LLM 与其 MIA 增强版本之间的比较。(b). 在 HotpotQA(纯文本)数据集上前沿 LLM 与其 MIA 增强版本之间的比较。(c). 基于 Qwen2.5-VL-7B 执行器的 MIA 与更大规模的 LLM(在非工具调用设置下)在七个不同数据集上的比较。(d). 基于 Qwen-2.5-VL-7B 执行器的 MIA 与 SOTA 记忆框架在七个不同数据集上的比较。](#Figure 1:(a). Comparisons between frontier LLMs and their MIA-enhanced counterparts on the LiveVQA (multimodal) dataset. (b). Comparisons between frontier LLMs and their MIA-enhanced counterparts on the HotpotQA (text-only) dataset. (c). Comparisons between MIA based on Qwen2.5-VL-7B Executor with larger LLMs (in non-tool-calling settings) across seven diverse datasets. (d). Comparisons between MIA and SOTA memory frameworks based on Qwen-2.5-VL-7B Executor across seven diverse datasets.图 1:(a). 在 LiveVQA(多模态)数据集上前沿 LLM 与其 MIA 增强版本之间的比较。(b). 在 HotpotQA(纯文本)数据集上前沿 LLM 与其 MIA 增强版本之间的比较。(c). 基于 Qwen2.5-VL-7B 执行器的 MIA 与更大规模的 LLM(在非工具调用设置下)在七个不同数据集上的比较。(d). 基于 Qwen-2.5-VL-7B 执行器的 MIA 与 SOTA 记忆框架在七个不同数据集上的比较。)
[6 Conclusion](#6 Conclusion)
《Memory Intelligence Agent》翻译与解读
|------------|--------------------------------------------------------------------------------------------------------------|
| 地址 | 论文地址:https://arxiv.org/abs/2604.04503 |
| 时间 | 2026年04月19日 |
| 作者 | 华东师范大学、上海创新研究院、哈尔滨工业大学、厦门大学、上海人工智能实验室 |
Abstract
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Deep research agents (DRAs) integrate LLM reasoning with external tools. Memory systems enable DRAs to leverage historical experiences, which are essential for efficient reasoning and autonomous evolution. Existing methods rely on retrieving similar trajectories from memory to aid reasoning, while suffering from key limitations of ineffective memory evolution and increasing storage and retrieval costs. To address these problems, we propose a novel Memory Intelligence Agent (MIA) framework, consisting of a Manager-Planner-Executor architecture. Memory Manager is a non-parametric memory system that can store compressed historical search trajectories. Planner is a parametric memory agent that can produce search plans for questions. Executor is another agent that can search and analyze information guided by the search plan. To build the MIA framework, we first adopt an alternating reinforcement learning paradigm to enhance cooperation between the Planner and the Executor. Furthermore, we enable the Planner to continuously evolve during test-time learning, with updates performed on-the-fly alongside inference without interrupting the reasoning process. Additionally, we establish a bidirectional conversion loop between parametric and non-parametric memories to achieve efficient memory evolution. Finally, we incorporate a reflection and an unsupervised judgment mechanisms to boost reasoning and self-evolution in the open world. Extensive experiments across eleven benchmarks demonstrate the superiority of MIA. First, MIA significantly enhances the current SOTA LLMs' performance in deep research tasks. For instance, MIA further boosts GPT-5.4 performance by up to 9% and 6% on LiveVQA and HotpotQA, respectively. Furthermore, with the lightweight Executor, like Qwen2.5-VL-7B, MIA can also achieve an average improvement of 31% across evaluated datasets, outperforming the much larger Qwen2.5-VL-32B by a margin of 18%, highlighting its remarkable performance. Additionally, training analysis reveals that reinforcement learning enables the Planner and Executor to synergistically optimize their strategies, effectively capturing dataset-specific characteristics and enhancing cross-domain reasoning and memory capabilities. Tool analysis reveals that long-context memory methods struggle with multi-turn tool interaction, while our proposed MIA significantly outperforms previous methods. Under unsupervised settings, MIA achieves performance comparable to its supervised counterpart, meanwhile exhibiting the progressive self-evolution performance across multiple training iterations. | 摘要 深度研究代理(DRAs)将大语言模型推理与外部工具相结合。记忆系统使 DRAs 能够利用历史经验,这对于高效推理和自主进化至关重要。现有方法依赖于从记忆中检索相似轨迹来辅助推理,但存在记忆进化效果不佳以及存储和检索成本不断增加的关键局限性。为了解决这些问题,我们提出了一种新颖的记忆智能代理(MIA)框架,该框架由管理器 - 规划器 - 执行器架构组成。记忆管理器是一个非参数记忆系统,能够存储压缩的历史搜索轨迹。规划器是一个参数记忆代理,能够为问题生成搜索计划。执行器是另一个代理,能够根据搜索计划搜索和分析信息。为了构建 MIA 框架,我们首先采用交替强化学习范式来增强规划器和执行器之间的协作。此外,我们使规划器能够在测试时学习期间持续进化,更新在推理过程中实时进行,而不会中断推理过程。此外,我们建立了参数化和非参数化记忆之间的双向转换循环,以实现高效的记忆进化。最后,我们引入了反思和无监督判断机制,以增强在开放世界中的推理和自我进化能力。在涵盖 11 个基准的广泛实验中,证明了 MIA 的优越性。首先,MIA 显著提升了当前最先进的 LLM 在深度研究任务中的表现。例如,在 LiveVQA 和 HotpotQA 上,MIA 分别将 GPT-5.4 的性能提高了 9% 和 6%。此外,借助轻量级的执行器,如 Qwen2.5-VL-7B,MIA 在评估数据集上平均提升了 31%,甚至超越了规模大得多的 Qwen2.5-VL-32B 18%,突显了其卓越的性能。此外,训练分析表明,强化学习使规划器和执行器能够协同优化其策略,有效地捕捉数据集特定的特征,并增强跨领域推理和记忆能力。工具分析表明,长上下文记忆方法在多轮工具交互中表现不佳,而我们提出的 MIA 显著优于先前的方法。在无监督设置下,MIA 达到了与其有监督版本相当的性能,同时在多次训练迭代中展现出逐步自我演进的性能。 |
| "Never memorize something that you can look up." ---Albert Einstein | "永远不要去记那些可以查到的东西。" ------阿尔伯特·爱因斯坦 |
Figure 1:(a). Comparisons between frontier LLMs and their MIA-enhanced counterparts on the LiveVQA (multimodal) dataset. (b). Comparisons between frontier LLMs and their MIA-enhanced counterparts on the HotpotQA (text-only) dataset. (c). Comparisons between MIA based on Qwen2.5-VL-7B Executor with larger LLMs (in non-tool-calling settings) across seven diverse datasets. (d). Comparisons between MIA and SOTA memory frameworks based on Qwen-2.5-VL-7B Executor across seven diverse datasets.图 1:(a). 在 LiveVQA(多模态)数据集上前沿 LLM 与其 MIA 增强版本之间的比较。(b). 在 HotpotQA(纯文本)数据集上前沿 LLM 与其 MIA 增强版本之间的比较。(c). 基于 Qwen2.5-VL-7B 执行器的 MIA 与更大规模的 LLM(在非工具调用设置下)在七个不同数据集上的比较。(d). 基于 Qwen-2.5-VL-7B 执行器的 MIA 与 SOTA 记忆框架在七个不同数据集上的比较。
1、Introduction
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Deep Research Agents (DRAs) (Xu and Peng, 2025; Zhang et al., 2025c; Huang et al., 2025) can combine the reasoning capabilities of LLMs with external tools, such as search engines, thereby empowering LLMs to complete complex, open-ended tasks. Based on tool-augmented LLMs (Schmidgall et al., 2025; Parisi et al., 2022; Li et al., 2023; Ma et al., 2024), DRAs follow a multi-round paradigm with repeatedly interleaved reasoning and external searching (Li et al., 2025; Du et al., 2025; Huang et al., 2023). As agents evolve toward long-horizon, multi-turn interactions, memory systems become a critical component (Wang et al., 2025b; Lerman and Galstyan, 2003; Wang and Chen, 2025). They determine whether the agent can accumulate experience, refine search strategies, and improve during each research process rather than repeatedly solving each task from scratch (Li et al., 2024b; Gandon et al., 2002). Existing research on agent memory has mainly focused on long context scenarios (Zhang et al., 2025a; Rasmussen et al., 2025), where information is stored based on the traces of search experience. Although such approaches have shown promising performance in many agentic applications (Xiao et al., 2024), long-context memory exhibits fundamental limitations when applied to deep research agents (Li et al., 2024a; Shi et al., 2025; Wu et al., 2024). First, long contexts may dilute attention, hindering the model's understanding of the current problem. Second, irrelevant or weakly related content in memory introduces noise, leading to degraded reasoning ability. Third, maintaining ever-growing context histories poses substantial storage challenges, particularly for agents operating continuously over extended periods. Finally, retrieval over massive memory incurs increasing computational costs, resulting in time inefficiency. Furthermore, long-context memory primarily captures knowledge-oriented or factual-oriented memory describing what the result is (e.g., user attributes, historical facts, and retrieved documents) (Wang et al., 2023; Yu et al., 2025; Kang et al., 2025). In contrast, deep research relies heavily on process-oriented memory (Fang et al., 2025) and conceptual knowledge describing how a result is obtained (e.g., search trajectories, failed attempts, and successful reasoning strategies). The objective of adopting memory is not merely to store retrieved knowledge, but to leverage historical experiences to guide future planning and exploration (Hu et al., 2025; Cao et al., 2025). Therefore, deep research agents require memory mechanisms that assist in search path planning and strategy reuse, rather than simply expanding the amount of stored textual context. | 深度研究代理(DRAs)(Xu 和 Peng,2025;Zhang 等人,2025c;Huang 等人,2025)能够将 LLM 的推理能力与外部工具(如搜索引擎)相结合,从而增强 LLM 完成复杂、开放性任务的能力。基于工具增强型 LLM(Schmidgall 等人,2025;Parisi 等人,2022;Li 等人,2023;Ma 等人,2024),DRAs 遵循多轮范式,其中推理和外部搜索交替进行(Li 等人,2025;Du 等人,2025;Huang 等人,2023)。随着代理向长时序、多轮交互发展,记忆系统成为关键组成部分(Wang 等人,2025b;Lerman 和 Galstyan,2003;Wang 和 Chen,2025)。它们决定了智能体能否在每次研究过程中积累经验、优化搜索策略并实现改进,而非每次都从零开始解决每个任务(Li 等人,2024b;Gandon 等人,2002)。目前关于智能体记忆的研究主要集中在长上下文场景(Zhang 等人,2025a;Rasmussen 等人,2025)上,其中信息是基于搜索经验的痕迹进行存储的。尽管此类方法在许多智能体应用中表现出了良好的性能(Xiao 等人,2024),但长上下文记忆在应用于深度研究智能体时存在根本性的局限性(Li 等人,2024a;Shi 等人,2025;Wu 等人,2024)。首先,长上下文可能会分散注意力,妨碍模型对当前问题的理解。其次,记忆中不相关或弱相关的内容会引入噪声,导致推理能力下降。第三,持续维护不断增长的上下文历史记录带来了巨大的存储挑战,尤其是对于长时间连续运行的智能体而言。最后,在海量记忆中进行检索会带来不断增加的计算成本,从而导致时间效率低下。 此外,长上下文记忆主要捕获知识导向型或事实导向型记忆,描述结果是什么(例如,用户属性、历史事实和检索到的文档)(Wang 等人,2023 年;Yu 等人,2025 年;Kang 等人,2025 年)。相比之下,深度研究则严重依赖过程导向型记忆(Fang 等人,2025 年)以及描述如何获得结果的概念性知识(例如,搜索轨迹、失败尝试和成功的推理策略)。采用记忆的目的不仅仅是存储检索到的知识,而是利用历史经验来指导未来的规划和探索(Hu 等人,2025 年;Cao 等人,2025 年)。因此,深度研究代理需要有助于搜索路径规划和策略复用的记忆机制,而不仅仅是扩大存储的文本上下文量。 |
| To address the limitations of long-context memory applied in deep research agents, existing memory systems typically utilize pre-trained models as planners to generate chain-of-thought (CoT) prompting for search path planning with few-shot cases (Zhou et al., 2025). While such methods have improved the deep research performance, they still suffer from several key challenges: (1) The Planner operates without task-specific training, resulting in suboptimal planning. (2) Previous CoT-based prompting methods select few-shot examples only based on relevance, while neglecting quality, frequency, and other significant dimensions. (3) The Executor fails to adequately interpret and follow planning instructions without task-specific training. In summary, the essence of prior works can be characterized as an incompetent Planner retrieving memories from bloated memory and using non-comprehensive in-context prompts to guide an unprepared Executor in conducting deep research. Consequently, introducing memory systems yields limited performance improvements. To address these challenges, we propose the Memory Intelligence Agent (MIA), a novel framework that integrates brain-inspired memory mechanisms into a Manager-Planner-Executor architecture. Specifically, MIA employs a hippocampus-like episodic memory to extract insights from historical trajectories. Meanwhile, it consolidates historical trajectories into parametric memory via Planner training, reducing storage overhead. Then, it trains the Executor to follow and execute the generated plan, enabling synergistic co-evolution between the two agents. Finally, it introduces a reflection mechanism to develop the autonomous re-planning ability, paving the way for self-evolution under sparse annotations or unsupervised conditions. Extensive experiments demonstrate that (1) MIA significantly elevates the performance of state-of-the-art (SOTA) Executors. Specifically, it yields a 9% improvement on the LiveVQA benchmark and a 6% gain on HotpotQA when integrated with GPT-5.4, showcasing its ability to further enhance even the most powerful models. (2) MIA exhibits remarkable improvements for smaller Executors. Using Qwen2.5-VL-7B as the Executor, our framework achieves an average gain of 31% across seven diverse datasets, notably outperforming its much larger counterpart, Qwen2.5-VL-32B, by 18%. (3) Under unsupervised settings, MIA empowers the trained Executor to achieve a 7% performance boost. Furthermore, we observe consistent performance growth over multiple training iterations, validating the effectiveness of our autonomous evolution mechanism. (4) MIA sets a new state-of-the-art. Building on the Qwen2.5-VL-7B Executor, our approach consistently outperforms previous SOTA memory baselines by an average margin of 5% across all seven evaluated benchmarks. | 为解决深度研究代理中长上下文记忆应用的局限性,现有的记忆系统通常利用预训练模型作为规划器,为搜索路径规划生成链式思维(CoT)提示,以处理少量样本的情况(Zhou 等人,2025 年)。尽管此类方法提升了深度研究的性能,但仍面临几个关键挑战:(1)规划器在没有针对特定任务进行训练的情况下运行,导致规划效果欠佳。(2)以往基于 CoT 的提示方法仅根据相关性选择少量样本示例,而忽略了质量、频率和其他重要维度。(3)执行器在没有针对特定任务进行训练的情况下,无法充分理解和遵循规划指令。总之,先前工作的本质可以概括为:一个能力不足的规划器从臃肿的记忆中检索记忆,并使用不全面的上下文提示来指导一个准备不足的执行器进行深度研究。因此,引入记忆系统带来的性能提升有限。为应对这些挑战,我们提出了记忆智能代理(MIA),这是一种将大脑启发式记忆机制整合到管理者-规划者-执行者架构中的新型框架。具体而言,MIA 采用类似海马体的情景记忆从历史轨迹中提取见解。同时,它通过规划者训练将历史轨迹整合为参数记忆,从而降低存储开销。然后,它训练执行者遵循并执行生成的计划,使两个代理实现协同共进化。最后,它引入了反思机制来培养自主重新规划的能力,为在稀疏标注或无监督条件下实现自我进化铺平了道路。大量实验表明:(1)MIA 显著提升了最先进的(SOTA)执行者的性能。具体来说,当与 GPT-5.4 集成时,在 LiveVQA 基准测试中提高了 9%,在 HotpotQA 中提高了 6%,展示了其进一步增强最强大模型的能力。(2)MIA 对较小的执行者表现出显著的改进。使用 Qwen2.5-VL-7B 作为执行器,我们的框架在七个不同的数据集上平均提升了 31%,显著优于其规模大得多的同类模型 Qwen2.5-VL-32B,高出 18%。(3)在无监督设置下,MIA 使训练好的执行器性能提升了 7%。此外,我们观察到在多次训练迭代中性能持续增长,这验证了我们自主进化机制的有效性。(4)MIA 创造了新的最先进水平。基于 Qwen2.5-VL-7B 执行器,我们的方法在所有七个评估基准上平均比之前的最先进内存基线高出 5%。 |
| Our contributions are as follows: • We introduce a Manager-Planner-Executor architecture that addresses the storage bottlenecks and reasoning inefficiencies of conventional deep research agents by decoupling of historic memory, parametric planning and dynamic execution. • We propose an alternating RL paradigm to optimize the interplay between the Planner and Executor. This ensures that high-level planning and low-level retrieval are mutually aligned. • We develop a continual test-time learning mechanism, allowing the Planner to update its parametric knowledge during inference. This enables the agent to adapt to new information without interrupting the reasoning workflow. • We integrate reflection and unsupervised judgment mechanisms, endowing the agent with self-assessment and correction capabilities in open-ended tasks. This not only enhances reasoning robustness but also ensures continual evolution when facing unknown tasks. • MIA surpasses existing memory baselines and exhibits strong scalability, significantly enhancing the performance of both frontier and small-scale LLMs in deep research tasks. | 我们的贡献如下: • 我们引入了一种管理器-规划器-执行器架构,通过将历史记忆、参数规划和动态执行解耦,解决了传统深度研究代理的存储瓶颈和推理效率低下的问题。 • 我们提出了一种交替强化学习范式来优化规划器和执行器之间的交互。这确保了高层次规划和低层次检索的相互协调。• 我们开发了一种持续的推理时学习机制,使规划器能够在推理过程中更新其参数化知识。这使得智能体能够在不中断推理工作流程的情况下适应新信息。 • 我们整合了反思和无监督判断机制,赋予智能体在开放式任务中进行自我评估和自我纠正的能力。这不仅增强了推理的稳健性,还确保了在面对未知任务时能够持续进化。 • MIA 超越了现有的记忆基线,并展现出强大的可扩展性,显著提升了前沿和小型语言模型在深度研究任务中的性能。 |
6 Conclusion
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| In this paper, we propose MIA, a memory framework to enhance the reasoning performance and self-evolution ability of Deep Research Agents. Based on the Executor agent, we design a novel Manager-Planner-Executor architecture. By compressing bloated historical trajectories into structured workflows via the Manager agent, MIA effectively mitigates the noise interference in long-context memory and improves the precision and quality of memory retrieval. By introducing the Planner agent, we transform the non-parametric memory into parametric memory, which reduces the storage burden and improves the planning performance. Furthermore, to bridge the gap between the Planner and Executor agents, we introduce a two-stage alternating RL paradigm. This training strategy not only improves the Planner's ability to generate precise plans and conduct autonomous reflection, but also significantly enhances the plan understanding and following capabilities of the Executor. Additionally, we propose an online test-time learning mechanism, enabling the Planner to absorb historical experiences during the exploration process. At the contextual level, it extracts high-quality positive and negative paradigms as non-parametric memory for explicit in-context contrastive learning. At the parametric level, MIA synchronously updates the Planner to capture latent knowledge representations and internalize planning ability. Extensive experiments demonstrate that MIA achieves state-of-the-art performance on both multimodal and text-only deep research benchmarks. Currently, our framework primarily focuses on deep research tasks. In the future, we plan to extend MIA to more complex and dynamic environments. | 在本文中,我们提出了 MIA ,这是一种用于增强深度研究代理推理性能和自我进化能力的内存框架。基于执行器代理,我们设计了一种新颖的Manager-Planner-Executor架构。通过管理器 代理将膨胀的历史轨迹压缩为结构化的工作流,MIA 有效地减轻了长上下文内存中的噪声干扰,并提高了内存检索的精度和质量。通过引入规划器 代理,我们将非参数化内存转换为参数化内存,这减轻了存储负担并提高了规划性能。此外,为了弥合规划器和执行器代理之间的差距,我们引入了一种两阶段交替强化学习 范式。这种训练策略不仅提高了规划器生成精确计划和进行自主反思的能力,还显著增强了执行器对计划的理解和遵循能力。此外,我们还提出了一种在线测试时学习机制,使规划器能够在探索过程中吸收历史经验。在上下文层面,它提取高质量的正负范例作为非参数记忆,用于显式上下文对比学习。在参数层面,MIA 同步更新规划器以捕获潜在的知识表示并内化规划能力。大量实验表明,MIA 在多模态和纯文本深度研究基准测试中均达到了最先进的性能。目前,我们的框架主要关注深度研究任务。未来,我们计划将 MIA 扩展到更复杂和动态的环境中。 |