拒绝无效内卷,只做高效搞钱的程序员;代码无 Bug,暴富不缺席。

一、单机Redis
1、单机Redis问题
Redis 是一个高性能的非关系型数据库,它使用键值对的方式存储数据,并将数据存放在内存中,所以读写性能极高。
单机模式Redis搭建简单、使用方便,利于学习入门。但是在实际使用中,单机Redis存在一些问题需要解决:
- 数据持久化问题:Redis为了提高性能,数据是在内存中存储的。而内存不能持久化存储数据,所以Redis提供了持久化机制。
- 并发能力问题:单机Redis的并发能力有限,可以通过主从集群来实现读写分离,从而提高并发能力。
- 故障恢复问题:在Redis集群中,一旦某个节点宕机,就必须要手动进行故障转换与恢复。Redis提供了哨兵模式来实现自动故障恢复。
- 存储能力问题:无论是主从模式的集群,还是哨兵模式的集群,都没有解决存储能力的扩展问题。Redis提供了分片集群模式,可以很方便的动态扩容。
2、单机Redis部署
把《redis-6.2.4.tar.gz》上传到Linux的/root目录下redis-6.2.4.tar.gz
执行命令安装redis:
shell
#1. 安装Redis需要的依赖程序包
yum install -y gcc tcl
#2. 切换到root用户的家目录
cd ~
#3. 解压Redis程序包
tar -xvf redis-6.2.4.tar.gz
#4. 切换到Redis目录里
cd ~/redis-6.2.4/
#5. 编译并安装Redis。如果此命令不出错,通常就表示安装成功了
make && make install配置redis.conf:
shell
#1. 在root家目录里创建文件夹
mkdir ~/01standalone
#2. 把Redis配置文件拷贝进来
cp ~/redis-6.2.4/redis.conf ~/01standalone/
#3. 切换到~/01standalone/目录里
cd ~/01standalone/
#4. 使用vi编辑redis.conf
vi redis.conf
# 绑定地址,默认是127.0.0.1,只能在本机访问Redis服务。修改为0.0.0.0则可以在任意IP访问Redis服务
bind 0.0.0.0
# 数据库数量,设置为1
databases 1
:wq 保存退出启动Redis:
shell
所有单机问题,我们全在`~/01standalone/`目录里操作,使用这个目录里的配置文件
* 启动Redis服务:`redis-server ~/01standalone/redis.conf`
* 使用Redis客户端连接:`redis-cli`,然后就可以使用Redis命令向服务器发请求(cs架构)
* 关闭Redis服务:`redis-cli shutdown (或者 kill -9 $(ps -ef | grep redis | grep -v grep | awk '{print $2}'))💡Redis服务安装好以后,可以同时启动多个实例,只要加载对应的配置文件,使用不同的端口即可。
简化操作:redis单机版部署脚本
二、Redis持久化机制
Redis是一个基于内存的高性能数据库,所有数据默认都存放在内存中,因此拥有极高的读写性能。我们知道,内存中的数据都是临时的,如果不做任何持久化配置,一旦Redis进程退出或服务器重启,内存中的所有数据都会被清空,无法恢复。
为了防止这样问题,Redis提供了持久化机制:
- RDB模式:快照模式,默认开启
- AOF模式:日志模式,需要手动开启
Redis4.0开始,提供了混合持久化(RDB+AOF)
shell
- AOF重写时先生成RDB快照
- 后续追加新的AOF命令
- 恢复时先加载RDB,再重放AOF命令
- 优势:恢复更快,文件更小1、RDB模式
RDB(Redis Database Backup file),也有人称为 数据快照。
如何持久化:把内存里所有数据,保存到磁盘文件上,当Redis服务重启时,就从磁盘上加载文件,把数据恢复到内存中。
RDB什么时候持久化:
- 执行save命令时:是一个阻塞命令,持久化时当前线程会阻塞,影响性能
- 执行bgsave命令时:是一个非阻塞式命令,会fork一个子进程,由子进程负责RDB持久化,由主进程负责处理客户端的操作命令
- Redis服务关闭时:当redis服务正常关闭时,会先执行一次save命令,之后才关闭服务。
- RDB自动触发条件:(redis.conf,默认会有)
RDB相关配置:
shell
# ===RDB自动触发机制===
# 如果3600秒内有1次数据变更,就执行一次RDB
# 如果300秒内有100次数据变更,就执行一次RDB
# 如果60秒内有10000次数据变更,就执行一次RDB
# 如果写成 `save ""`,表示禁用RDB
save 3600 1
save 300 100
save 60 10000
#===RDB的其它参数===
# 是否开启RDB文件压缩
rdbcompression yes
# rdb文件名
dbfilename dump.rdb
# 文件保存路径
dir ./bgsave原理:
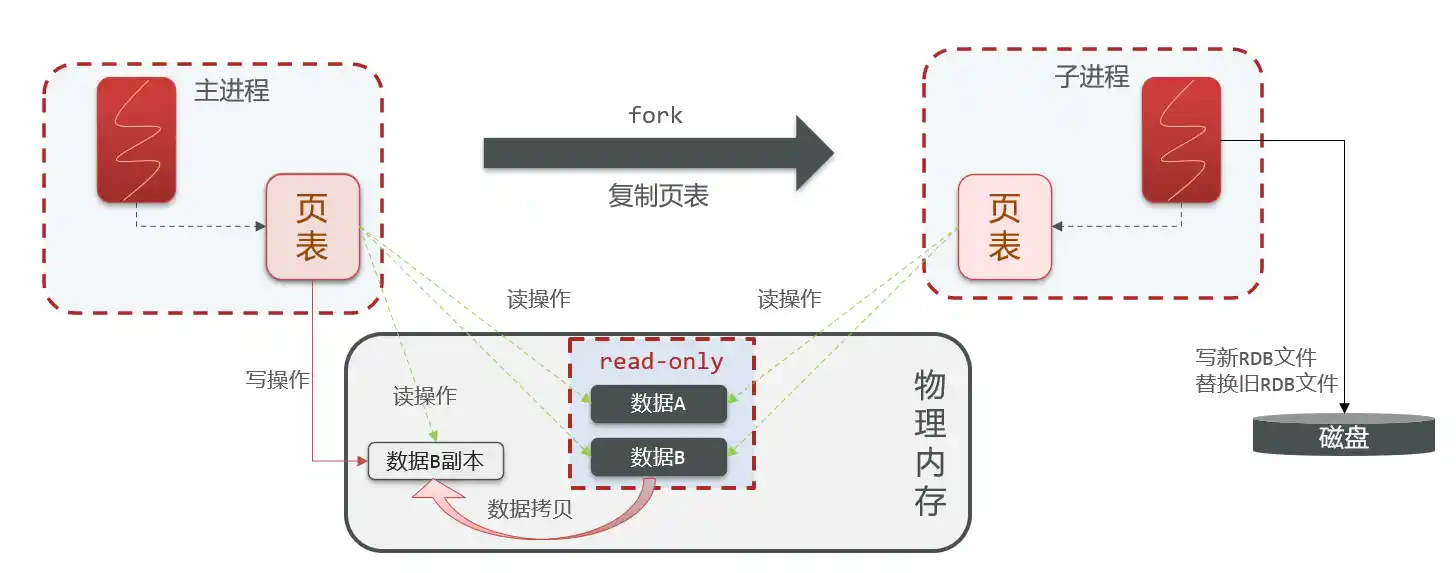
shell
在bgsave之前,由主进程通过页表操作物理内存里的数据
当执行bgsave时:
- 会fork一个子进程,拷贝主进程里的页表,然后子进程就可以通过页表读取物理内存里的数据,保存到磁盘文件上。
- 同时,为了防止子进程RDB过程中,物理内存里的数据被修改;会把物理内存里的数据设置为read-only只读,这样子进程RDB时,数据不会被修改。
- 如果这时主进程有新的命令要修改数据,物理内存里的数据时只读的,Redis会采用copy-on-write机制,把数据拷贝一个副本,对这个副本进行读写操作
- 当子进程RDB结束之后,会丢弃物理内存旧版本的数据,保留最新的副本数据。
# 补充资料
进程是一个程序运行的资源合集
线程是程序的一条执行路径
redis主进程通过页表操作物理内存数据,页表是内存地址映射
rdb持久化并不会阻塞主进程,在fork子进程复制页表时会阻塞 影响不是很大2、AOF模式
AOF(Append Only File)也有人称为日志模式。
AOF如何持久化:Redis会把执行所有数据变更的命令, 追加保存到磁盘文件上。当Redis重启恢复数据时,就加载磁盘文件,按顺序依次执行所有的命令。
Redis的AOF默认是关闭的,如果开启AOF模式,则需要如下步骤:
shell
1、修改redis.conf配置文件
# aof开关
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
2、重启服务
redis-cli shutdown
redis-server ~/01standalone/redis.confAOF什么时候持久化:
shell
#appendfsync always
appendfsync everysec
#appendfsync no
appendfsync有三种配置项:
- always: 同步刷盘,redis每执行完一个命令后,都会立即把命令追加保存到磁盘文件上
- everysec:每秒刷盘,redis每执行完一个命令后,会把命令放到AOF缓冲区,每秒一次的频率从缓冲区中把命令保存到磁盘文件上。(假如说丢数据,最多丢失一秒钟内的数据)
- no:由操作系统决定何时刷盘,redis每执行完一个命令后,会把命令放到AOF缓冲区,然后操作系统空闲时会刷盘
# 三种时机对比:
| 配置项 | 刷新时机 | 优点 | 缺点 |
| -------- | ----------- -- | ----------------------- | ------------------------|
| always | 同步刷盘 | 可靠性高,几乎不丢数据 | 对性能影响大 |
| everysec | 每秒刷盘 | 性能适中 | 最多丢失1秒的数据 |
| no | 由操作系统控制 | 性能最好 | 可靠性较差,可能丢失大量数据 |AOF文件大,命令冗余的处理:利用AOF重写
- 手动重写:执行命令bgrewiteaof
- 自动重写:根据配置文件里的参数,达到预值(默认64mb,增长100%)时会自动重写。
三、主从集群
单节点Redis支持的并发能力是有限的,一旦出现问题整个缓存全部崩了。
主从集群解决的问题:
- 并发能力问题:由多个节点共同组成集群,并发能力就提升了。特别读的并发能力
- 防止单点故障:只有一个节点的话,一旦节点宕机,整个服务不可用;集群可以防止这样的单点故障,提高可用性
主从集群角色划分:一主多从。
- 主节点:只有一个,可以提供读和写服务
- 从节点:可以有多个,只提供读数据的服务
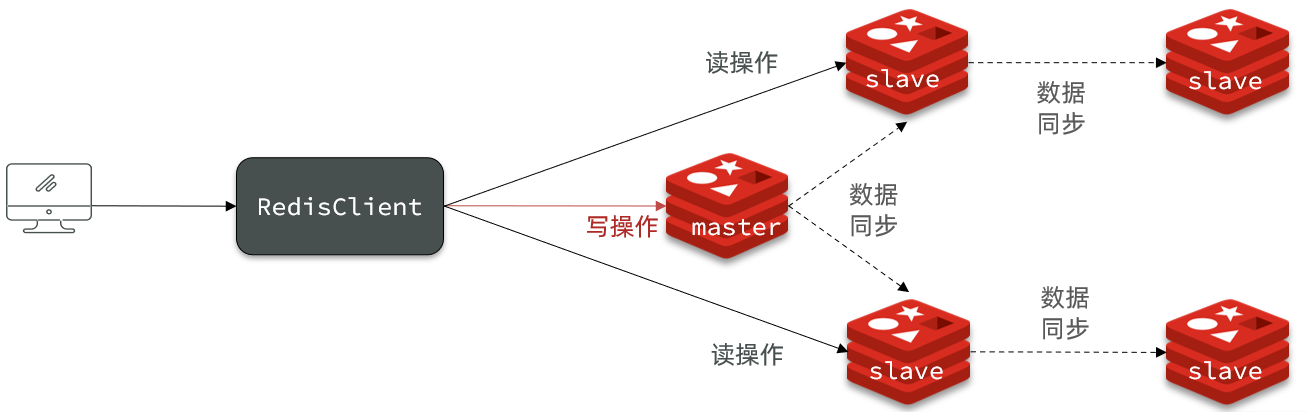
主从之间需要实现数据同步。
1、搭建主从集群
主从集群ip端口分配:
shell
角色 ip 端口
master 10.2.0.2 6380
slave 10.2.0.2 6381
slave 10.2.0.2 6382 1、构建三个redis节点的配置:
shell
#1. 准备一个文件夹02master,把主从集群所有相关的配置全放到这个文件夹里
mkdir ~/02master
#2. 在02master里准备三个文件夹,作为三个redis实例的工作目录
cd ~/02master/
mkdir 6380 6381 6382
#3. 把Redis的配置文件,分别拷贝到6380,6381,6382三个文件夹里。
echo 6380 6381 6382 | xargs -t -n 1 cp ~/redis-6.2.4/redis.conf
#4. 分别修改6380、6381、6382三个文件夹里的配置文件
# 把端口分别修改为6380、6381、6382
# 把配置文件里的dir,全部修改为各自的工作目录
cd ~/02master
sed -i -e 's/6379/6380/g' -e 's/dir .\//dir \/root\/02master\/6380\//g' -e 's/bind 127.0.0.1 -::1/bind 0.0.0.0/g' 6380/redis.conf
sed -i -e 's/6379/6381/g' -e 's/dir .\//dir \/root\/02master\/6381\//g' -e 's/bind 127.0.0.1 -::1/bind 0.0.0.0/g' 6381/redis.conf
sed -i -e 's/6379/6382/g' -e 's/dir .\//dir \/root\/02master\/6382\//g' -e 's/bind 127.0.0.1 -::1/bind 0.0.0.0/g' 6382/redis.conf
#5. 修改每个Redis实例的ip
# 虚拟机本身有多个虚拟网卡,有多个ip地址。为了防止地址混乱,我们直接在配置文件里指定要绑定的ip地址
# 6380、6381、6382三个文件夹里的配置文件都要修改,执行以下命令
cd ~/02master
printf '%s\n' 6380 6381 6382 | xargs -I{} -t sed -i '1a replica-announce-ip 10.2.0.2' {}/redis.conf2、启动集群:
shell
# 第一个Redis实例
redis-server ~/02master/6380/redis.conf
# 第二个Redis实例
redis-server ~/02master/6381/redis.conf
# 第三个Redis实例
redis-server ~/02master/6382/redis.conf
附加:如果想要一键停止所有Redis实例,可以执行以下命令
printf '%s\n' 6380 6381 6382 | xargs -I{} -t redis-cli -p {} shutdown3、开启主从关系:
- 永久生效:在redis.conf中增加一行配置,slaveof masterip masterport,然后重启redis服务。
- 临时生效:使用redis-cli连接Redis服务,执行 slaveof masterip masterport,服务重启会失效。
shell
# slave1 6381 连master
redis-cli -p 6381
slaveof 10.2.0.2 6380
# slave2 6382 连master
redis-cli -p 6382
slaveof 10.2.0.2 6380
#连接master 6380实例 查看集群状态
redis-cli -p 6380
info replication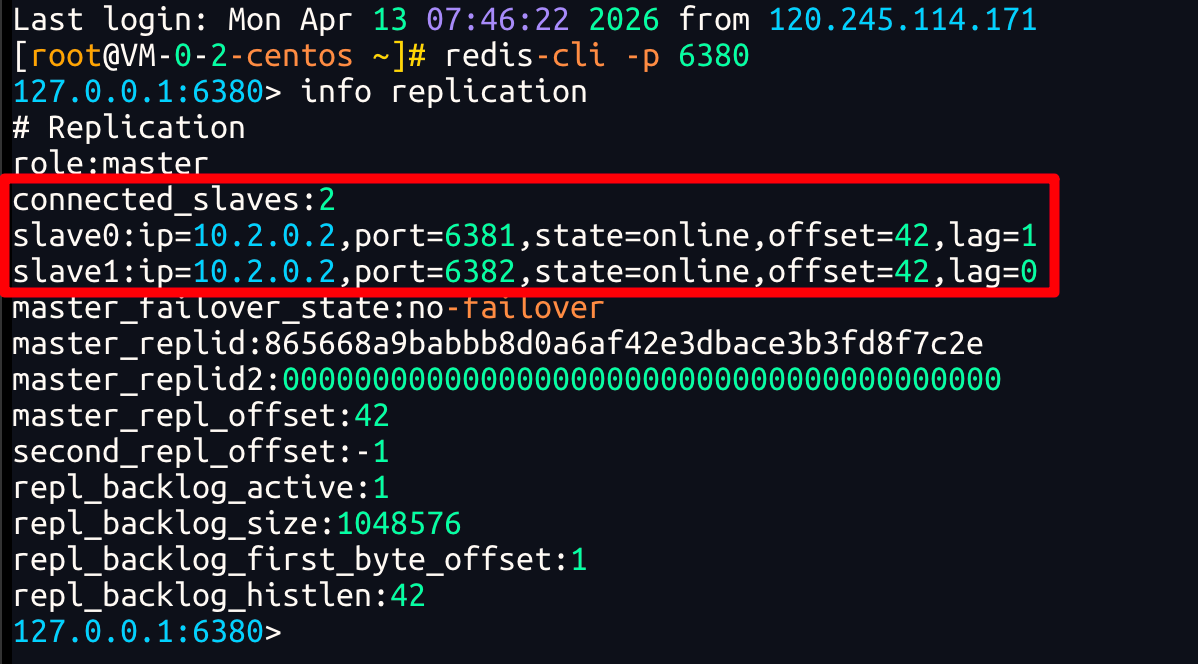
测试:
shell
按顺序执行以下操作:
* 使用redis-cli连接6380,执行 `set sum 100`
* 使用redis-cli连接6381,执行`get num`, 然后再执行`set num 101`
* 使用redis-cli连接6382,执行`get num`,然后再执行`set num 102`
结果发现:
* 只有6380这个节点上可以进行写操作
* 6381和6382两个节点上只能进行读操作
2、主从数据同步原理
主从全量同步发生在什么时候:一个节点第一次变成slave的时候,先进行一次全量同步。
全量同步的过程:
- 第一阶段:建立主从关系
- slave把自己数据集的id(replication id)发送给master
- master收到以后判断 slave给的replication id 和自己 replicationid不同:确定slave是第一次连接master
- master会首先把自己的replication id发送给slave;slave丢弃自己的replication id,接受master replication id
- 第二阶段:开始全量同步
- master执行bgsave,生成RDB。把RDB发送给slave
- slave丢弃自己的所有的旧数据,加载主节点提供的RDB
- 第三阶段:后续的增量同步
- 在第二阶段全量同步期间,master所执行的新命令会存储到repl_backlog里
- master在第二阶段结束,会把repl_backlog里的命令发送给slave
- slave再执行接收到的命令。最终slave的数据和master同步了

shell
扩展:
● Replication Id:简称replid,由40位十六进制字符组成。每个Master节点启动时都会给自己的数据集生成一个replid,而slave会继承其master的replid。
● offset:偏移量,是一个数字,是记录的指令的位置(数据读的位置),会随着记录在repl_baklog中的数据增多而增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave的数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据:
● 而slave原本也是一个master,有自己的replid和offset。当第一次变成slave,与master建立连接时,发送的replid和offset是自己的replid和offset。
● master判断发现slave发送来的replid与自己的不一致,说明这是一个全新的slave,就知道要做全量同步了。
● master会将自己的replid和offset都发送给这个slave,slave保存这些信息。以后slave的replid就与master一致了。3、repl_backlog原理
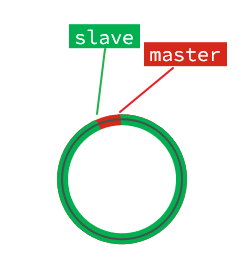
- repl_backlog是什么:是由Master创建并维护的一个环形缓冲区。其实就是一个数组,Master不断把它执行的命令添加到数组里,如果数组满了,就从头开始把旧的数据覆盖掉;slave要从repl_backlog里不断的读取命令,同步到slave里。
- 增量同步的过程:
- slave向master发请求,要求同步数据,会给master发送自己的replication id,和上次同步的位置offset
- master判断replication id和自己的相同,再判断offset和自己master的offset
- 如果slave的offset 与 master的offset 相差超过一圈:就只能全量同步了
- 如果slave的offset 与master的offset 相差不超过一圈:就从slave的offset开始,把后边的所有命令同步给slave,是增量同步
- 增量同步:
- 通常是在slave重启,会进行全量同步
- 如果slave节点宕机时间过长,可能就要进行全量同步了
4、主从集群的优化
- 单个redis节点尽量不要分配太大内存,这样主从同步时比较慢
- 可以启动无磁盘复制,减少磁盘IO操作
- 提升repl_backlog的大小,减少全量同步的机率和次数
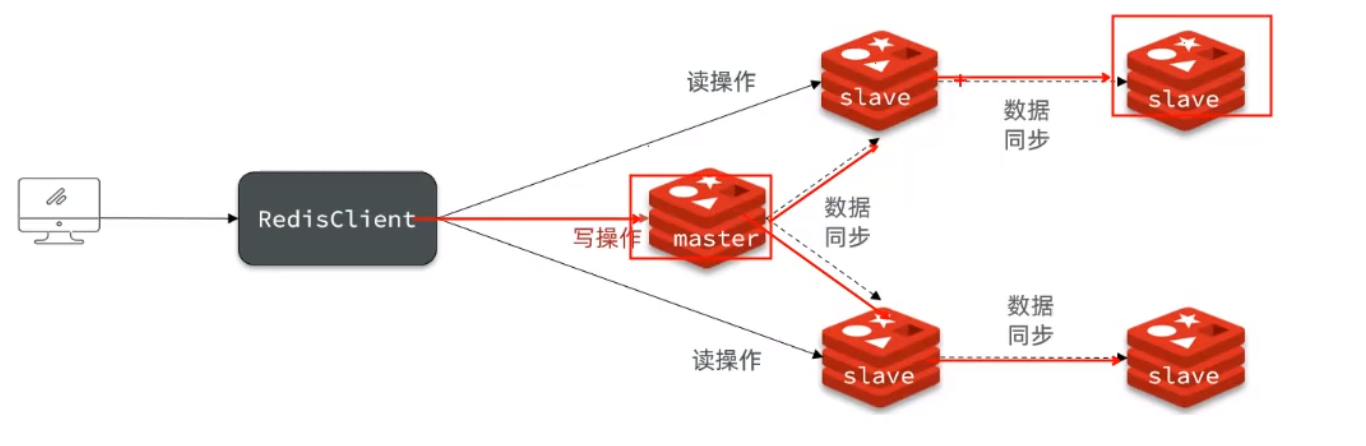
- 如果slave过多,可以采用主-从-从链式结构,减少master压力。
主-从-从链式结构如下:
四、哨兵模式
主从集群存在的问题:也就是故障转移的问题,一旦Master节点宕机,就需要人工干预切换Master主节点。
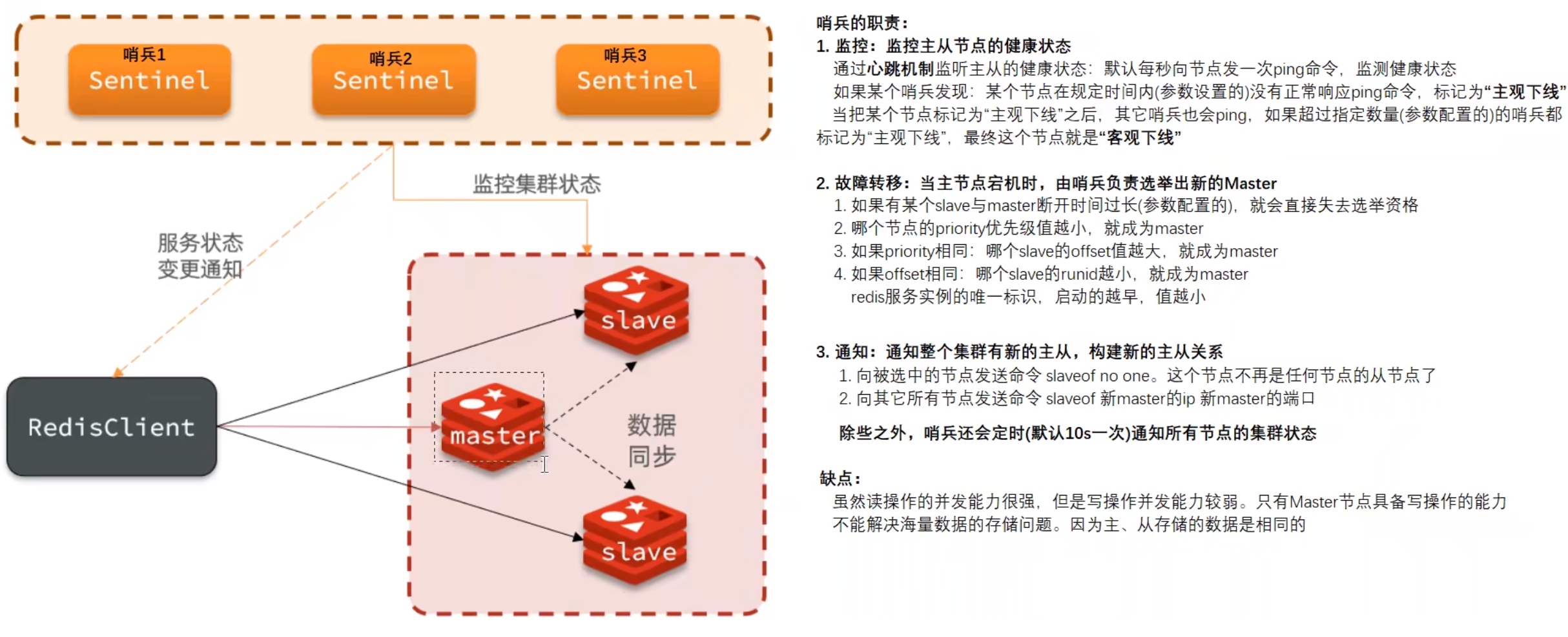 哨兵模式的特点是在主从集群基础上,增加哨兵集群。
哨兵模式的特点是在主从集群基础上,增加哨兵集群。
哨兵的职责:
- 监控:哨兵会监控主从集群的健康状态,采用的是心跳机制,默认每1条ping一次主观下线:某个哨兵在规定时间内ping节点,但是没有收到回应,就把节点标记为主观下线客观下线:超过指定数量的哨兵,都把某个节点标记为主观下线,就是客观下线
- 故障转移:哨兵在发现Master宕机之后,会自动选举挑选新的Master节点。选举的策略先把上次同步时间过长的slave节点排除掉,没有选举资格对比节点的slave-priority值。值越小,优先级越高。0表示不参与选举如果slave-priority相同,对比offset。offset越大,优先级越高。因为offset越大,说明数据和master越接近如果offset相同,对比runid。runid越小,优先级越高。因为runid越小,说明启动的越早
- 通知:通知主从切换、通知集群状态通知主从切换:通知新的Master执行 slaveof no one;通知其它所有节点执行 slaveof 新master的ip 新master端口还会通知整个集群的信息状态(默认10s一次)
1、搭建哨兵集群
sentinel集群ip、端口分配:
shell
节点 ip 端口
s1 10.2.0.2 16380
s2 10.2.0.2 16381
s3 10.2.0.2 16382 1、在<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">~/03sentinel</font>里创建三个文件夹,名字分别叫s1、s2、s3:
shell
mkdir ~/03sentinel
cd ~/03sentinel/
mkdir s1 s2 s32、准备sentinel配置文件
2.1 准备s1实例的配置
shell
# 切换到s1文件夹里
cd ~/03sentinel/s1
# 编写配置
vi sentinel.conf
# 添加如下内容
port 16380
sentinel announce-ip 10.2.0.2
sentinel monitor mymaster 10.2.0.2 6380 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
dir "/root/03sentinel/s1"配置说明:
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">port 16380</font>: 当前Sentinel实例的端口号<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">sentinel monitor mymaster 10.2.0.2 6380 2</font>:指定主节点master的信息<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">mymaster</font>:主节点名称,任意写<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">10.2.0.2 6380</font>:主节点的ip和端口<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">2</font>:选举时的<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">quorum</font>值(投票客观下线数量)
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">down-after-milliseconds</font>:哨兵心跳监测的时间间隔<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">failover-timeout</font>:故障转移的超时失败时间
2.2、准备s2和s3实例的配置
将<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">~/03sentinel/s1/sentinel.conf</font>拷贝到s2和s3两个目录中
shell
cp ~/03sentinel/s1/sentinel.conf ~/03sentinel/s2
cp ~/03sentinel/s1/sentinel.conf ~/03sentinel/s3修改s2和s3的配置文件,将其端口分别修改为16381、16382
shell
sed -i -e 's/16380/16381/g' -e 's/s1/s2/g' ~/03sentinel/s2/sentinel.conf
sed -i -e 's/16380/16382/g' -e 's/s1/s3/g' ~/03sentinel/s3/sentinel.conf3、启动
3.1 启动redis主从集群
shell
#使用Sentinel之前,我们必须保证Redis主从集群是启动运行状态,并且要保证6380是Master节点
#如果Redis主从集群未启动,就执行以下命令:
redis-server ~/02master/6380/redis.conf
redis-server ~/02master/6381/redis.conf
redis-server ~/02master/6382/redis.conf
# 设置主从集群关系
`redis-cli -p 6381`,然后执行命令 `slaveof 192.168.200.136 6380`
`redis-cli -p 6382`,然后执行命令 `slaveof 192.168.200.136 6380`
`redis-cli -p 6380`,然后执行命令查看集群状态 `info replication`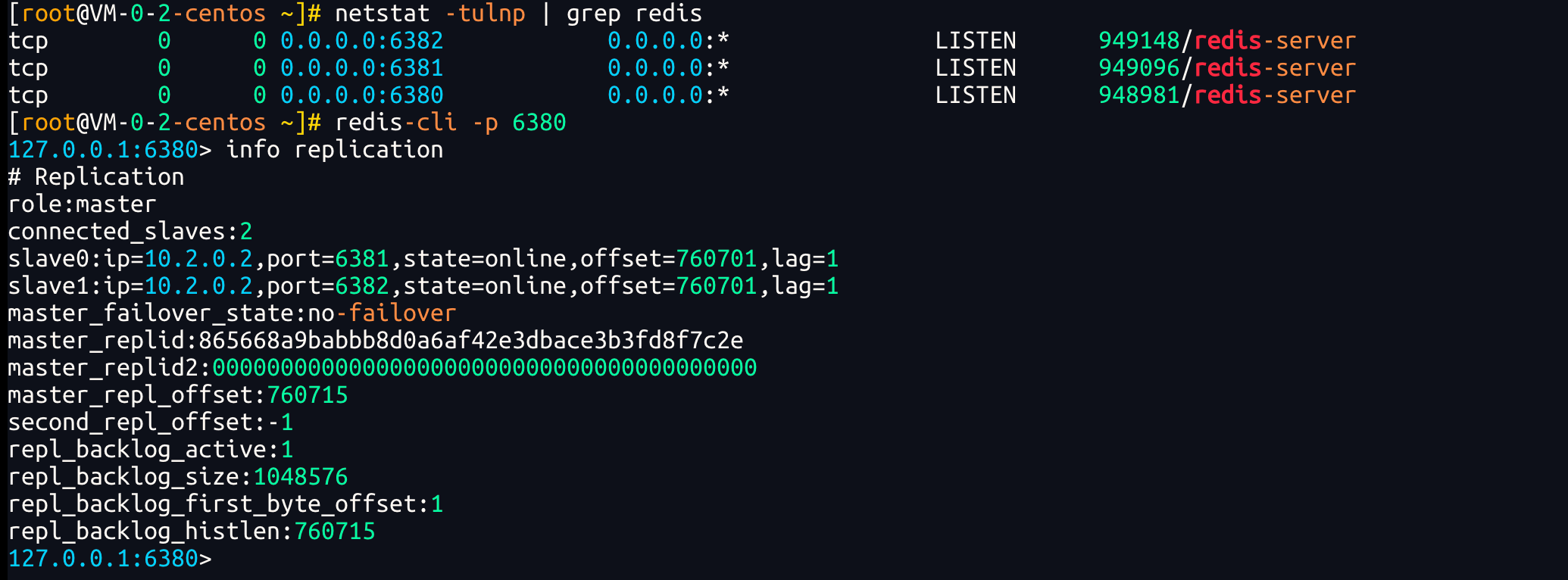
3.2 启动sentinel集群
shell
# 为了方便查看日志,我们打开3个ssh客户端 分别启动sentinel
# 第1个
redis-sentinel ~/03sentinel/s1/sentinel.conf
# 第2个
redis-sentinel ~/03sentinel/s2/sentinel.conf
# 第3个
redis-sentinel ~/03sentinel/s3/sentinel.conf4、测试
尝试让master节点6380宕机: <font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">redis-cli -p 6380 shutdown</font>
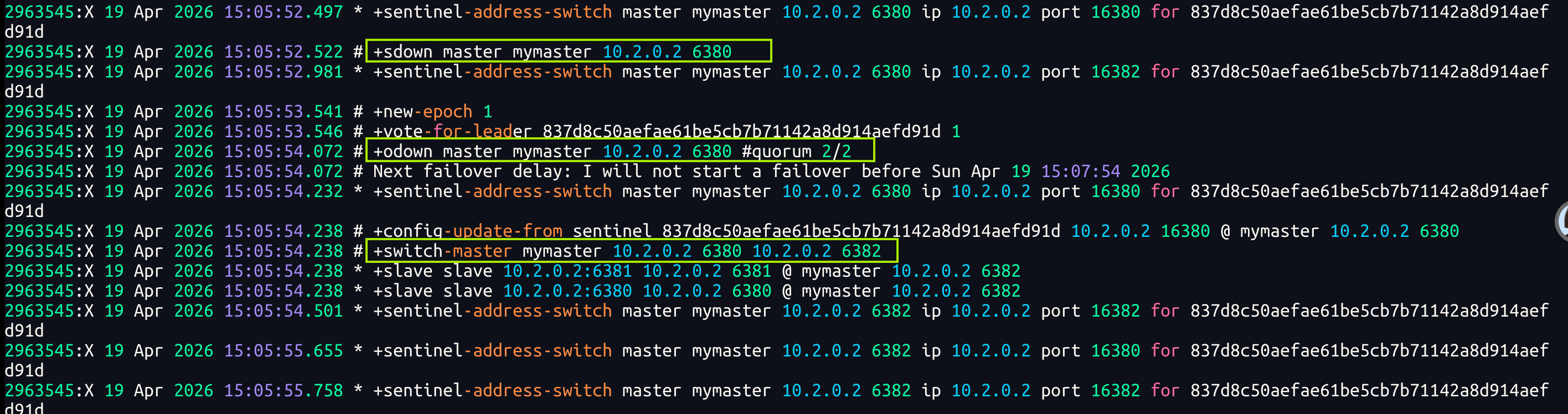
从sentinel日志上可以发现,已经选举了新的master节点:6382
shell
1. +sdown master mymaster 10.2.0.2 6380
含义:sdown = Subjectively Down(主观下线)
当前 Sentinel 节点认为 10.2.0.2:6380 这个原主节点已经失联。
这是 Sentinel 基于自身心跳检测做出的初步判断。
2. +odown master mymaster 10.2.0.2 6380 #quorum 2/2
含义:odown = Objectively Down(客观下线)
Sentinel 集群内达成了共识(quorum 2/2),确认原主节点确实故障,进入客观下线状态。
这是 Sentinel 开始执行故障转移的前置条件。
3. +switch-master mymaster 10.2.0.2 6380 10.2.0.2 6382
含义:主节点切换指令执行完成
旧主:10.2.0.2:6380
新主:10.2.0.2:6382
这条日志直接证明 Sentinel 已经成功将 6382 节点提升为新的主节点。故障转移完成后,原主节点 6380 重启后,只会被 Sentinel 自动配置为新主 6382 的从节点,不会再自动竞选为主节点。

2、RestTemplate访问哨兵集群
在Sentinel集群监管下的Redis主从集群,其节点会因为自动故障转移而发生变化,Redis的客户端必须感知这种变化,及时更新连接信息。Spring的RedisTemplate底层利用lettuce实现了节点的感知和自动切换。
添加依赖坐标:
xml
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.9.RELEASE</version>
<relativePath/>
</parent>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
</properties>
<dependencies>
<!--Redis起步依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>准备配置文件:
yaml
spring:
redis:
sentinel:
master: mymaster #主节点的名称。在创建Sentinel集群时指定的
nodes: #Sentinel哨兵的地址
- 10.2.0.2:16380
- 10.2.0.2:16381
- 10.2.0.2:16382配置Redis集群的读写策略:
java
/**
* 配置Redis的Sentinel集群读写策略
* ReadFrom.MASTER: 仅从master节点读数据
* ReadForm.REPLICA:仅从slave节点读数据
* ReadForm.MASTER_PREFERRED:优先从Master节点读数据
* ReadFrom.REPLICA_PREFERRED:优先从Slave节点读数据
*/
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer(){
return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}测试:
java
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
public class RedisSentinelTest {
@Autowired
private RedisTemplate<String,String> redisTemplate;
@Test
public void test(){
// redisTemplate.opsForValue().set("key::sentinel", "hello, sentinel");
String s = redisTemplate.opsForValue().get("key::sentinel");
System.out.println("s = " + s);
}
}3、小节
主从集群存在的问题:故障转移的问题,一旦Master节点宕机,就需要人工干预切换Master主节点。可以增加哨兵解决这个问题。
哨兵模式:在主从集群基础上,增加哨兵集群。哨兵的职责:
- 监控:哨兵会监控主从集群的健康状态,采用的是心跳机制,默认每1条ping一次主观下线:某个哨兵在规定时间内ping节点,但是没有收到回应,就把节点标记为主观下线客观下线:超过指定数量的哨兵,都把某个节点标记为主观下线,就是客观下线
- 故障转移:哨兵在发现Master宕机之后,会自动选举挑选新的Master节点。选举的策略先把上次同步时间过长的slave节点排除掉,没有选举资格对比节点的slave-priority值。值越小,优先级越高。0表示不参与选举如果slave-priority相同,对比offset。offset越大,优先级越高。因为offset越大,说明数据和master越接近如果offset相同,对比runid。runid越小,优先级越高。因为runid越小,说明启动的越早
- 通知:通知主从切换、通知集群状态通知主从切换:通知新的Master执行 slaveof no one;通知其它所有节点执行 slaveof 新master的ip 新master端口还会通知整个集群的信息状态(默认10s一次)
五、分片集群
分片集群解决了什么问题
- 解决了主从集群的高并发写的问题。因为主从集群里只有一个master具备写数据的能力;
- 解决了主从集群的海量数据存储问题。因为主从集群里各节点数据相同,如果数据太多,就存不下
分片集群的特征:
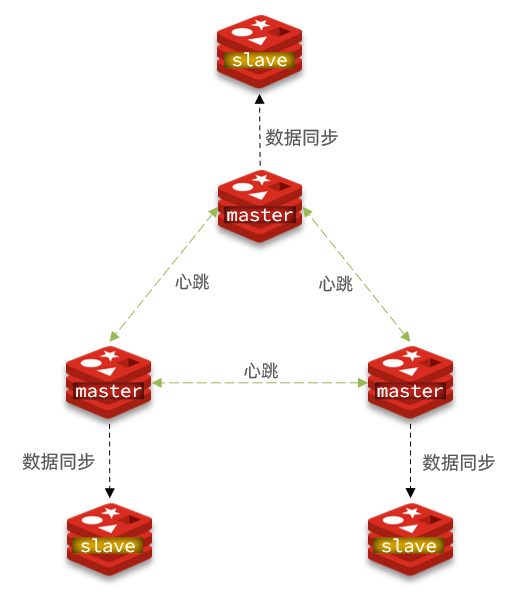
- 集群里可以有多个master主节点,每个主节点保存不同的数据(哈希槽)
- 每个master节点可以有多个slave节点,实现高可用
- 分片集群不需要再有哨兵监控和选举,而是master之间互相心跳监控、实现选举
- 连接任意一个master,master都会帮我们重定向到正确的master上存取数据__
1、搭建分片集群
1.1、准备实例和配置
分片集群需要的节点数量较多,这里我们搭建一个最小的分片集群,包含3个master节点,每个master包含一个slave节点。
shell
# 关闭所有redis、哨兵集群
redis-cli -p 6380 shutdown
redis-cli -p 6381 shutdown
redis-cli -p 6382 shutdown
redis-cli -p 16380 shutdown
redis-cli -p 16381 shutdown
redis-cli -p 16382 shutdown
#查看端口是否释放成功
netstat -tulnp | grep redis为了方便演示在同一台虚拟机中开启6个redis实例,模拟分片集群,信息如下:
shell
| ip | 端口 | 角色 |
| -------- | ---- | ------ |
| 10.2.0.2 | 7380 | master |
| 10.2.0.2 | 7381 | master |
| 10.2.0.2 | 7382 | master |
| 10.2.0.2 | 8380 | slave |
| 10.2.0.2 | 8381 | slave |
| 10.2.0.2 | 8382 | slave |1**、准备文件夹**
shell
# 创建04cluster文件夹,并在文件夹里准备7380 7381 7382 8380 8381 8382六个文件夹
mkdir ~/04cluster
cd ~/04cluster/
mkdir 7380 7381 7382 8380 8381 83822、****准备配置文件
2.1 准备7380端口实例配置
shell
cd ~/04cluster/7380
vi redis.conf
# 添加如下内容:
port 7380
# 开启集群功能
cluster-enabled yes
# 集群的配置文件名称,不需要我们创建,由redis自己维护
cluster-config-file /root/04cluster/7380/nodes.conf
# 节点心跳失败的超时时间
cluster-node-timeout 5000
# 持久化文件存放目录
dir /root/04cluster/7380
# 绑定地址
bind 0.0.0.0
# 让redis后台运行
daemonize yes
# 注册的实例ip
replica-announce-ip 10.2.0.2
# 保护模式
protected-mode no
# 数据库数量
databases 1
# 日志
logfile /root/04cluster/7380/run.log2.2 准备其它实例的配置
shell
# 将7380里的配置文件,拷贝到其它每个目录里
cd ~/04cluster
echo 7381 7382 8380 8381 8382 | xargs -t -n 1 cp ~/04cluster/7380/redis.conf
# 修改每个目录下的redis.conf,修改其端口:
printf '%s\n' 7381 7382 8380 8381 8382 | xargs -I{} -t sed -i 's/7380/{}/g' {}/redis.conf1.2、启动所有实例
因为已经配置了Redis后台运行,所以可以直接启动,不需要开多个shell端口。执行以下命令:
shell
cd ~/04cluster
#启动7380 7381 7382 8380 8381 8382 六个Redis服务
printf '%s\n' 7380 7381 7382 8380 8381 8382 | xargs -I{} -t redis-server {}/redis.conf查看是否成功启动,执行命令:<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">ps -ef | grep redis</font>。如果看到以下结果,说明6个redis实例都启动成功

如果要关闭所有进程,可以执行命令:
- 方式一:
ps -ef | grep redis | awk '{print $2}' | xargs kill- 方式二:
printf '%s\n' 7380 7381 7382 8380 8381 8382 | xargs -I{} -t redis-cli -p {} shutdown
1.3、创建集群
虽然服务已经成功启动,但目前6个Redis实例还是独立的,它们之间没有任何关系。
redis5.0开始创建集群的命令如下:
shell
redis-cli --cluster create --cluster-replicas 1 10.2.0.2:7380 10.2.0.2:7381 10.2.0.2:7382 10.2.0.2:8380 10.2.0.2:8381 10.2.0.2:8382命令说明:
<font style="color:rgb(51, 51, 51);">redis-cli --cluster</font>或者<font style="color:rgb(51, 51, 51);">./redis-trib.rb</font>:表示要操作redis集群<font style="color:rgb(51, 51, 51);">create</font>:表示要创建集群<font style="color:rgb(51, 51, 51);">--cluster-replicas 1</font>或者<font style="color:rgb(51, 51, 51);">--replicas</font>:指令集群中每个master的副本个数为1。这样:master节点的数量:节点总数 / (replicas + 1),得到的就是master节点的数量节点列表中前n个就是master节点,其它是slave节点。这些slave随机分配给不同的master
如果在执行上面的命令创建集群时报错:ERR Node 110.2.0.2:7380 is not empty. Either the node already knows other nodes
主要原因可能是:该节点默认生成的配置与历史存储的数据不一致导致的
解决的方法是:
- 关闭所有redis实例:
printf '%s\n' 7380 7381 7382 8380 8381 8382|xargs -I{} -t redis-cli -p {} shutdown- 清除对应节点的dump.rdb、nodes.conf等文件
find / -name nodes.conf | xargs rm -rffind / -name dump.rdb | xargs rm -rf- 然后重启redis实例,再执行创建集群的命令
cd ~/04clusterprintf '%s\n' 7380 7381 7382 8380 8381 8382 | xargs -I{} -t redis-server {}/redis.confredis-cli --cluster create --cluster-replicas 1 10.2.0.2:7380 10.2.0.2:7381 10.2.0.2:7382 10.2.0.2:8380 10.2.0.2:8381 10.2.0.2:8382
shell
[root@VM-0-2-centos 04cluster]# redis-cli --cluster create --cluster-replicas 1 10.2.0.2:7380 10.2.0.2:7381 10.2.0.2:7382 10.2.0.2:8380 10.2.0.2:8381 10.2.0.2:8382
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 10.2.0.2:8381 to 10.2.0.2:7380
Adding replica 10.2.0.2:8382 to 10.2.0.2:7381
Adding replica 10.2.0.2:8380 to 10.2.0.2:7382
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 557462ad6f49c016206b25d783a45fc8a014cb71 10.2.0.2:7380
slots:[0-5460] (5461 slots) master
M: 0a38122eb4aabb3ffd7dfb63b7a3f4f3c0c49d02 10.2.0.2:7381
slots:[5461-10922] (5462 slots) master
M: 860c19f8bfa4b6aa79377114cbacf79beb97e8dc 10.2.0.2:7382
slots:[10923-16383] (5461 slots) master
S: 79272acfd7f2f8dabdeb9bb48590d5ae3387b5fa 10.2.0.2:8380
replicates 557462ad6f49c016206b25d783a45fc8a014cb71
S: 8595de1a7364bec6fe7f5eb079c5e941d5b5e0de 10.2.0.2:8381
replicates 0a38122eb4aabb3ffd7dfb63b7a3f4f3c0c49d02
S: 318bc53de545cf631f6c379405997929e18c3a12 10.2.0.2:8382
replicates 860c19f8bfa4b6aa79377114cbacf79beb97e8dc
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
...
>>> Performing Cluster Check (using node 10.2.0.2:7380)
M: 557462ad6f49c016206b25d783a45fc8a014cb71 10.2.0.2:7380
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 0a38122eb4aabb3ffd7dfb63b7a3f4f3c0c49d02 10.2.0.2:7381
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: 860c19f8bfa4b6aa79377114cbacf79beb97e8dc 10.2.0.2:7382
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 79272acfd7f2f8dabdeb9bb48590d5ae3387b5fa 10.2.0.2:8380
slots: (0 slots) slave
replicates 557462ad6f49c016206b25d783a45fc8a014cb71
S: 318bc53de545cf631f6c379405997929e18c3a12 10.2.0.2:8382
slots: (0 slots) slave
replicates 860c19f8bfa4b6aa79377114cbacf79beb97e8dc
S: 8595de1a7364bec6fe7f5eb079c5e941d5b5e0de 10.2.0.2:8381
slots: (0 slots) slave
replicates 0a38122eb4aabb3ffd7dfb63b7a3f4f3c0c49d02
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[root@VM-0-2-centos 04cluster]#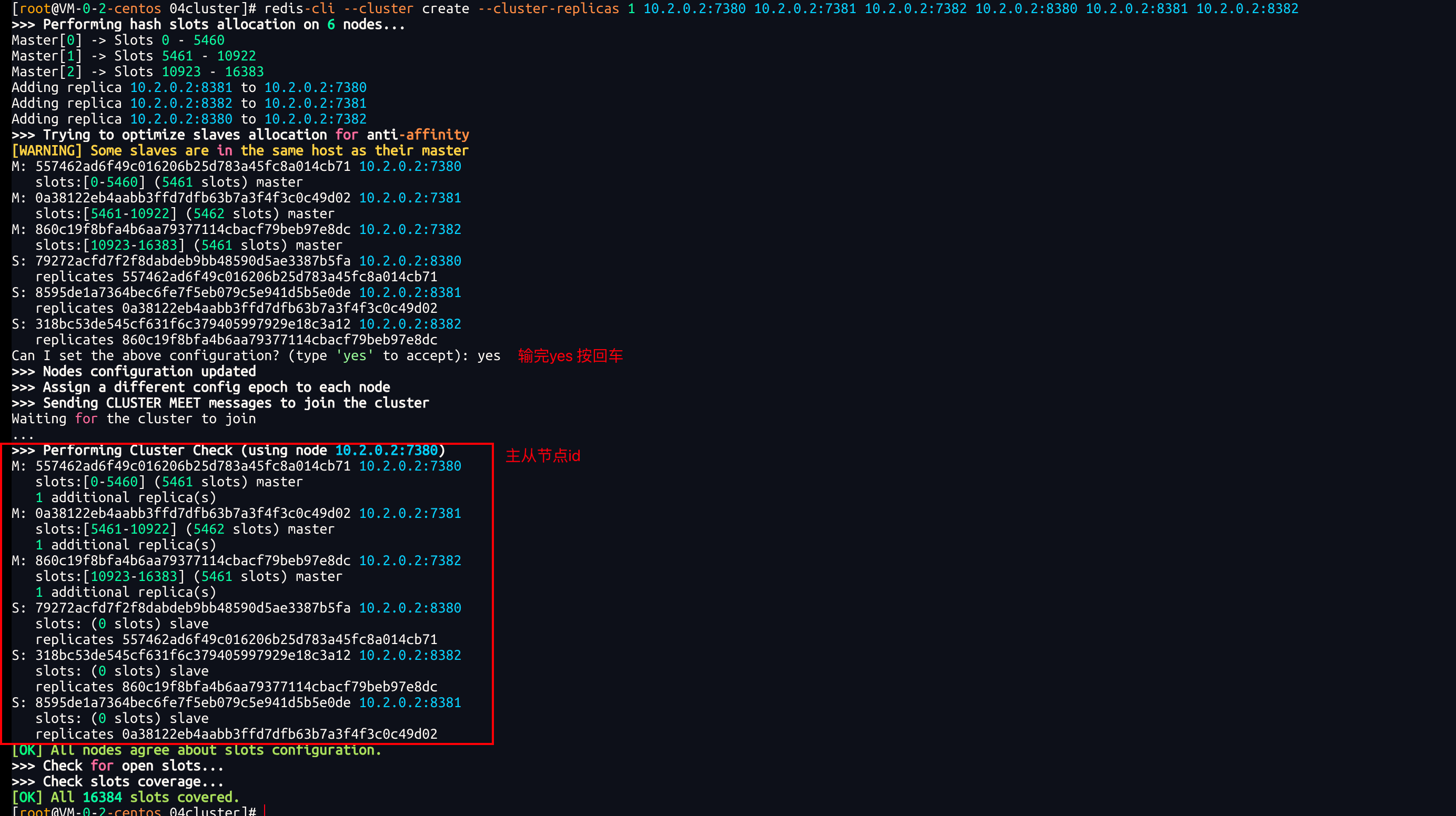
查看集群状态:
shell
redis-cli -p 7380 cluster nodes
1.4、测试
使用命令连接7380节点:<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">redis-cli -c -p 7380</font>,做如下操作:
- 存储数据:
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">set num 10</font> - 获取数据:
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">get num</font> - 再次存储:
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">set a 1</font>
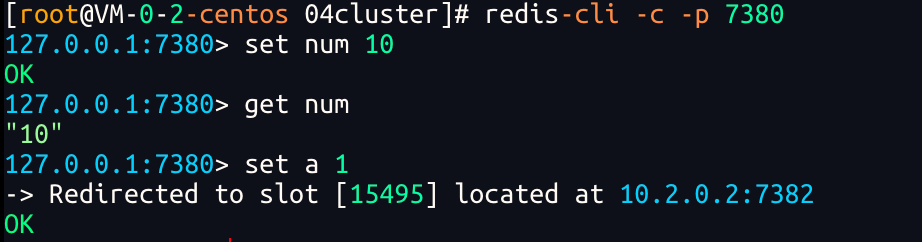
shell
127.0.0.1:7380> set a 1
-> Redirected to slot [15495] located at 10.2.0.2:7382
Redis 集群会把 key 做 CRC16 哈希,然后取模 16384 个槽
a 这个 key 计算出来的槽号是 15495
这个槽不在 7380 节点,而在 7382 节点
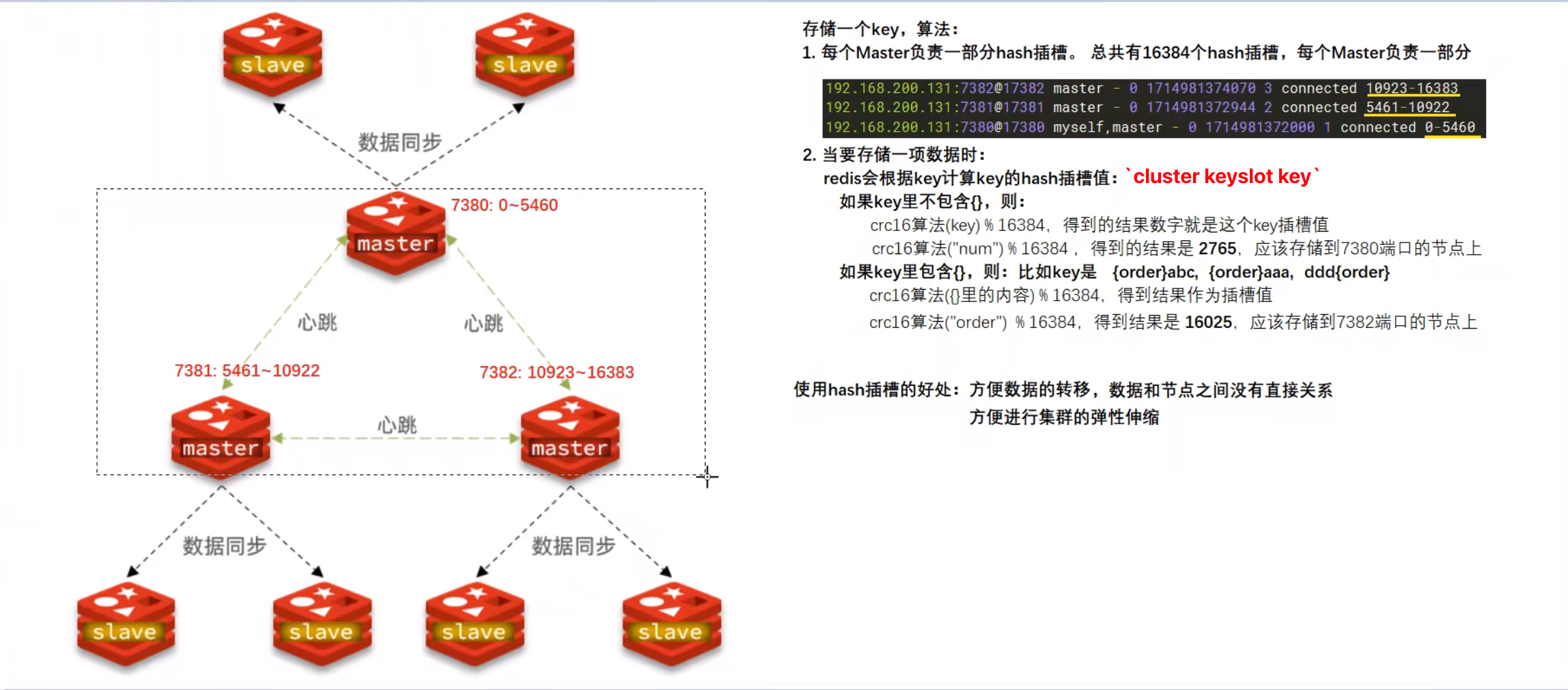
所以客户端自动重定向(Redirected) 到正确节点执行2、散列插槽(Hash插槽)
3、集群伸缩
因为Redis的分片集群,数据并没有与Redis节点直接进行绑定,而是:数据与插槽绑定,插槽与Redis节点绑定。这样就可以很方便的进行集群的伸缩,增加或减少Redis节点。
我们通过下面例子,演示一下给集群增加节点,需要如何实现。要求:向集群中添加一个新的master节点,并向其中存储num = 10
- 启动一个新的Redis实例,端口为7383
- 把7383节点添加到之前的集群,并作为一个master节点
- 给7383节点分配插槽,使得这个num可以存储到7383实例
这需要有两大步:
- 添加一个节点到集群中
- 转移插槽
1、添加新节点到集群中
shell
#创建7383文件夹
mkdir ~/04cluster/7383
#把配置文件拷贝到7383文件夹里
cp ~/04cluster/7380/redis.conf ~/04cluster/7383
#修改配置文件
sed -i s/7380/7383/g ~/04cluster/7383/redis.conf
#启动7383实例
redis-server ~/04cluster/7383/redis.conf
#把7383节点添加到集群
redis-cli --cluster add-node 10.2.0.2:7383 10.2.0.2:7380
#查看集群状态
redis-cli -p 7380 cluster nodes
2、转移插槽
如果要将num存储到7383节点,前提需要先看看num的插槽是多少:<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">redis-cli -c -p 7380 cluster keyslot key名称</font>

我们可以将0~3000插槽,从7380节点移动到7383节点上。
转移插槽命令如下:
1、建立连接:<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">redis-cli --cluster reshard 10.2.0.2:7380</font>
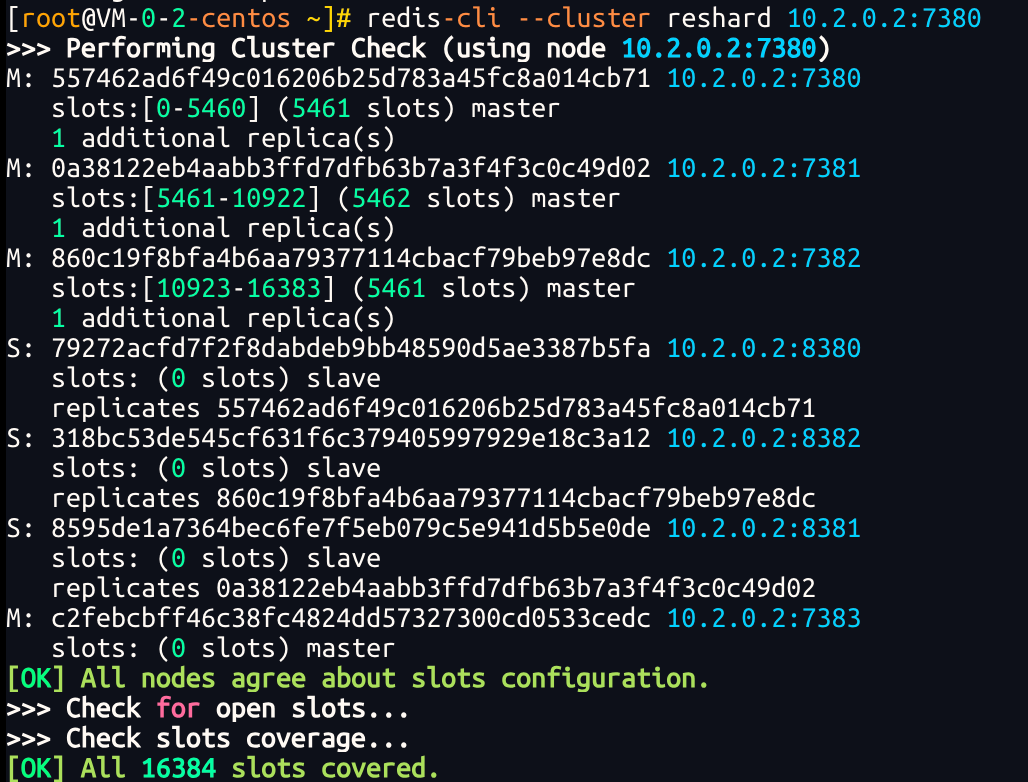
2、输入要移动的插槽数量,我们输入 3000

3、输入目标节点的id(哪个节点要接收这些插槽,就输入哪个节点的id)我们从刚刚的输出结果中,找到7383节点的id设置过来
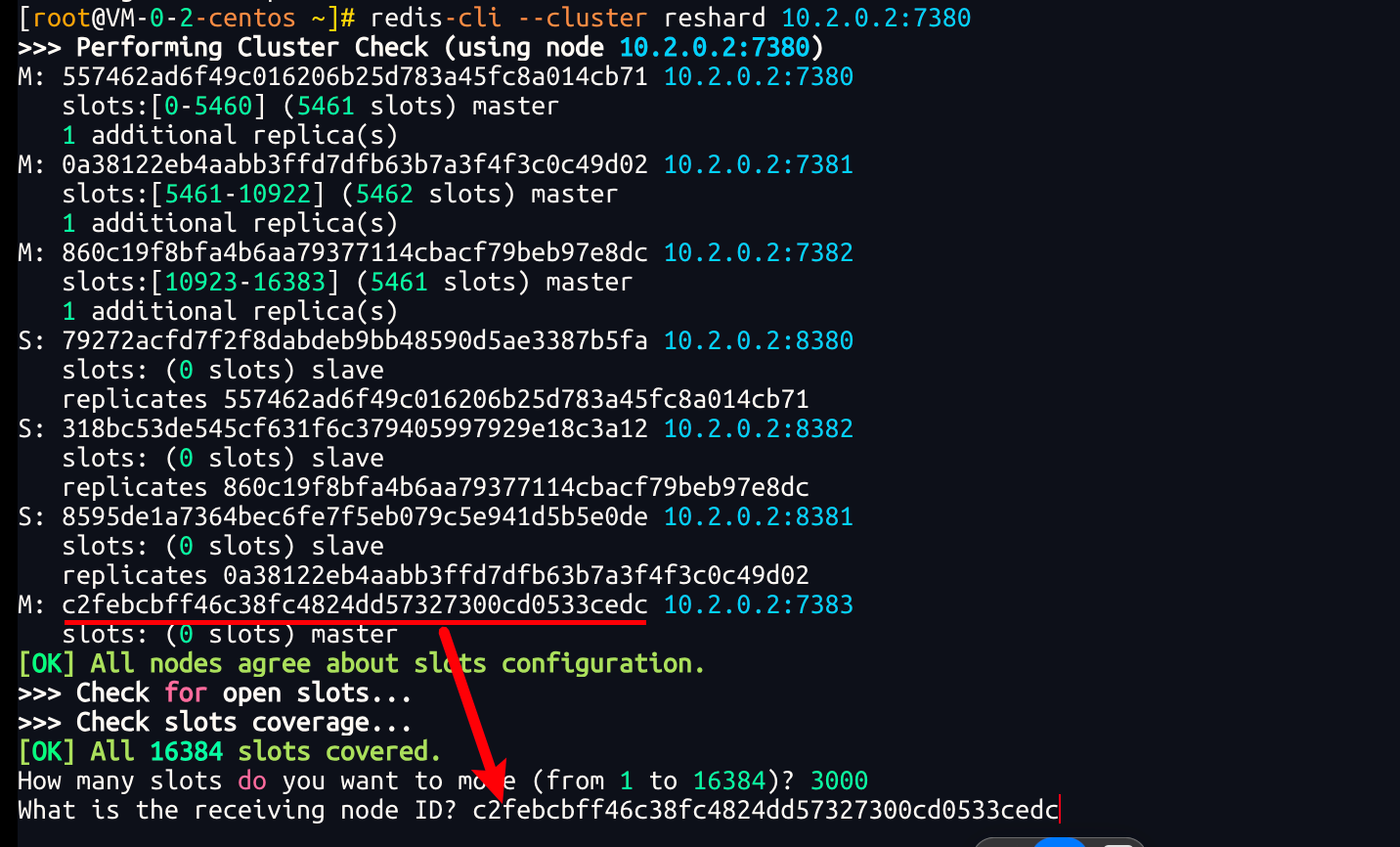
4、从哪个节点里转移出插槽?
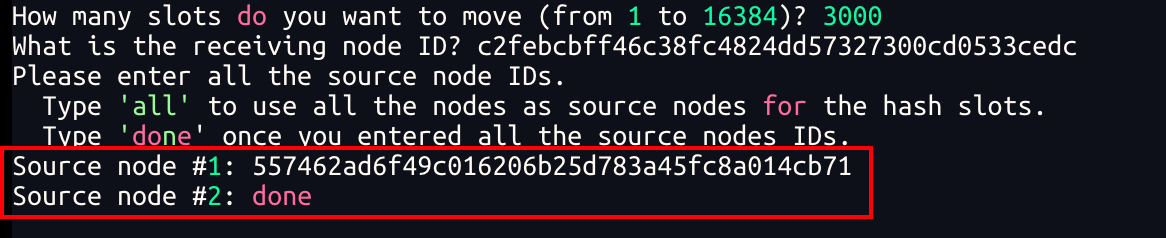
- 输入
all,表示全部。即从现有每个master节点中各转移一部分出来 - 输入节点id,表示从指定节点中转移出来
- 输入
done,表示输入完毕了
我们这里从7380节点转移出来一部分,要输入7380节点的id
5、输入<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">yes</font>,确认转移

6、确认结果
执行命令:<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">redis-cli -p 7380 cluster nodes</font>,可以看到7383节点拥有0~2999插槽,说明转移插槽成功了

4、故障转移
当master宕机时,Redis的分片集群同样具备故障转移的能力。
接下来给大家演示一下分片集群的故障转换,先确认一下集群的初始状态:
shell
[root@VM-0-2-centos ~]# redis-cli -p 7380 cluster nodes
0a38122eb4aabb3ffd7dfb63b7a3f4f3c0c49d02 10.2.0.2:7381@17381 master - 0 1776601316532 2 connected 5461-10922
860c19f8bfa4b6aa79377114cbacf79beb97e8dc 10.2.0.2:7382@17382 master - 0 1776601315000 3 connected 10923-16383
557462ad6f49c016206b25d783a45fc8a014cb71 10.2.0.2:7380@17380 myself,master - 0 1776601316000 1 connected 3000-5460
79272acfd7f2f8dabdeb9bb48590d5ae3387b5fa 10.2.0.2:8380@18380 slave 557462ad6f49c016206b25d783a45fc8a014cb71 0 1776601316532 1 connected
318bc53de545cf631f6c379405997929e18c3a12 10.2.0.2:8382@18382 slave 860c19f8bfa4b6aa79377114cbacf79beb97e8dc 0 1776601315530 3 connected
8595de1a7364bec6fe7f5eb079c5e941d5b5e0de 10.2.0.2:8381@18381 slave 0a38122eb4aabb3ffd7dfb63b7a3f4f3c0c49d02 0 1776601315530 2 connected
c2febcbff46c38fc4824dd57327300cd0533cedc 10.2.0.2:7383@17383 master - 0 1776601315530 7 connected 0-2999
###################################
主节点 → 对应的从节点
7380 (master) → 从节点:8380
7381 (master) → 从节点:8381
7382 (master) → 从节点:8382
7383 (master) → 无从节点(单独主节点)4.1、自动故障转移
当master宕机时,分片集群会自动将其slave节点提升为master。
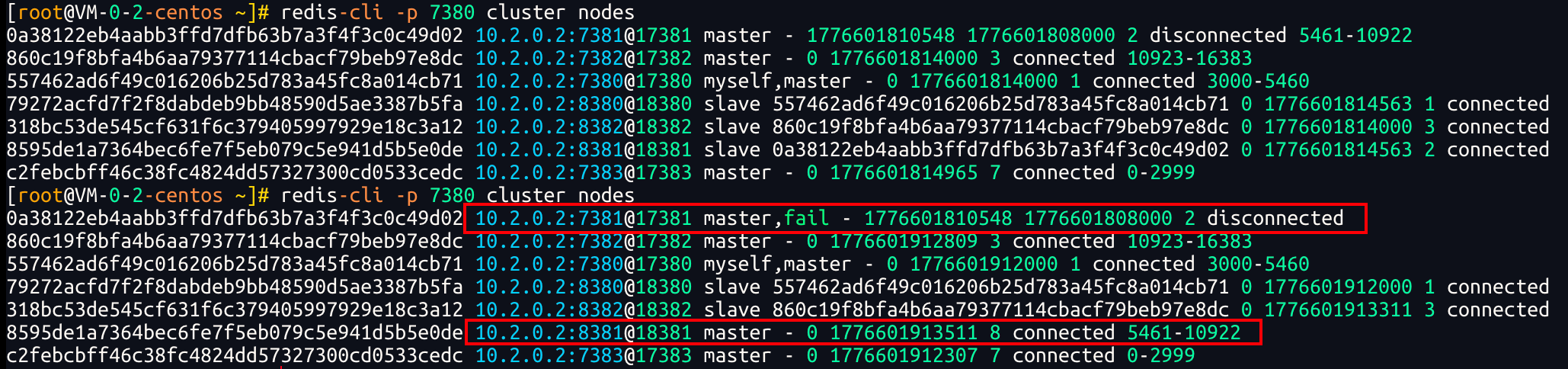
我们直接将7381节点关闭:<font style="color:rgb(51, 51, 51);">redis-cli -p 7381 shutdown</font>,
然后查看集群状态 <font style="color:rgb(51, 51, 51);">redis-cli -p 7380 cluster nodes</font>,发现7381是fail状态,8381已经提升成为master
再次启动7381节点:<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">redis-server ~/04cluster/7381/redis.conf</font>
再次查看集群状态:<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">redis-cli -p 7380 cluster nodes</font>,发现7381节点成为了slave

4.2、手动故障转
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移。
这种failover命令可以指定三种模式:
- 缺省:默认的流程,如图1~6歩
- force:省略了对offset的一致性校验
- takeover:直接执行第5歩,忽略数据一致性、忽略master状态和其它master的意见
其流程如下:
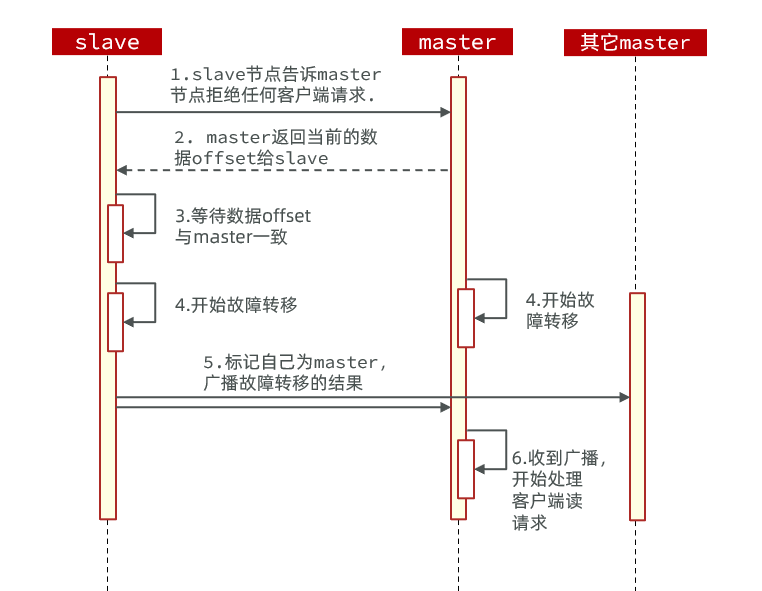
我们以7381这个slave节点为例,演示如何手动进行故障转移,让7381重新夺回master:
- 利用redis-cli连接7381这个节点:
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">redis-cli -p 7381</font> - 在7381节点上执行命令:
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">cluster failover</font> - 重新查看集群状态:
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">cluster nodes</font>

5、RedisTemplate访问分片集群
RedisTemplate底层同样基于lettuce实现了分片集群的支持,而使用的步骤与哨兵模式基本一致:
1、引入redis的starter依赖
2、配置分片集群地址
3、配置读写分离
与哨兵模式相比,其中只有分片集群的配置方式略有差异,如下:
shell
spring:
redis:
cluster:
nodes:
- 10.2.0.2:7380
- 10.2.0.2:7381
- 10.2.0.2:7382
- 10.2.0.2:8380
- 10.2.0.2:8381
- 10.2.0.2:8382六、缓存三剑客
shell
#### 缓存穿透
- 现象:缓存和 DB 都没有的数据,导致大量请求直接打到DB,导致 DB 崩溃
- 解决方案:
1. **缓存空值**
- DB 查询为空,仍向 Redis 存一个短有效期空值
- 下次直接返回,避免请求穿透
2. **布隆过滤器(BloomFilter)**
- 先判断 key 是否存在,不存在直接返回
- 特点:不存在一定不存在,存在可能误判;不易删数据
- 实现:Redisson、Guava
#### 缓存击穿
- 现象:**某个热点 key 过期**,大量并发请求同时击穿到 DB
- 解决方案:
1. **重建缓存加分布式锁**,只允许一个线程去 DB 加载
2. **逻辑过期**
- 数据永不过期,用字段标记过期时间
- 发现过期直接返回旧数据,后台异步重建缓存(加锁)
#### 缓存雪崩
- 现象:大量 key **同一时间过期** 或 Redis 宕机,流量全部打到 DB
- 解决方案:
- 过期时间:**基础时间 + 随机值**,打散过期
- 高可用:搭建 Redis 集群、多级缓存七、分布式锁
1、使用Redis String + SETNX 实现分布式锁
SETNX 是 SET if Not eXists(不存在则设置)的缩写,是 Redis 字符串(String)结构的核心命令,专门用来实现分布式锁------ 保证在分布式系统中,同一时间只有一个服务能执行某段代码 / 操作共享资源。
核心原理:
- 锁标识:用 Redis 的一个 String 键作为锁(比如 lock:order:1001)
- 加锁:执行 SETNX key value,返回 1 表示加锁成功(键不存在,创建成功);返回 0 表示加锁失败(键已存在,被其他线程持有)
- 解锁:删除这个 Redis 键,释放锁
- 防死锁:必须给锁设置过期时间,避免服务宕机导致锁永远不释放
问题:SETNX + EXPIRE 不是原子操作,锁的续期问题比较麻烦(没有Watchdog机制)
2、Redisson提供的分布式锁
Redisson 是一个增强版 Redis 客户端,在 Redis 基础上,用 Lua + 看门狗机制,封装了一套完整的分布式工具集,分布式锁只是它最出名、最常用的功能之一。
Redisson 定位:
- 基于 Netty 实现的高性能 Redis 客户端
- 兼容单机、哨兵、集群、云托管 Redis
- 提供了大量分布式场景下的高级工具:
- 分布式锁、分布式集合、分布式限流、分布式队列、分布式 ID 等
Redisson 提供的锁类型:
- 可重入锁 (Reentrant Lock)
- 描述 :最常用的分布式锁,等价于 Java 的
ReentrantLock。 - 特性 :
- 支持重入:同一个线程可多次加锁。
- 自动续期:内置看门狗(Watchdog)机制,防止业务未执行完锁过期。
- 底层实现:使用 Redis 的
HASH结构记录重入次数,通过 Lua 脚本保证原子性。
- 代码示例:
- 描述 :最常用的分布式锁,等价于 Java 的
java
RLock lock = redisson.getLock("lock:order");
lock.lock(); - 公平锁 (Fair Lock)
- 描述:保证先到先得,避免线程饥饿。
- 特性 :
- 按照请求顺序分配锁,后发线程不会先抢到锁。
- 相比非公平锁,性能略低(需维护等待队列)。
- 代码示例:
java
RLock fairLock = redisson.getFairLock("lock:fair");
fairLock.lock(); - 读写锁 (ReadWrite Lock)
- 描述:适用于读多写少的场景,提升并发效率。
- 特性 :
- 读锁:共享锁,多个线程可并发加锁。
- 写锁:排他锁,互斥,同一时刻只能有一个线程持有。
- 代码示例:
java
RReadWriteLock rwLock = redisson.getReadWriteLock("lock:rw");
RLock readLock = rwLock.readLock(); // 读锁
RLock writeLock = rwLock.writeLock(); // 写锁 - 联锁 (Multi Lock)
- 描述:将多个锁合并成一个逻辑锁,必须全部获取成功才算加锁成功。
- 特性 :
- 用于跨多个 Redis 实例或跨资源的强一致性操作。
- 任意一个锁获取失败,已获取的锁会被释放。
- 代码示例:
java
RLock lock1 = redisson.getLock("lock:resource1");
RLock lock2 = redisson.getLock("lock:resource2");
RLock multiLock = redisson.getMultiLock(lock1, lock2);
multiLock.lock(); - 红锁 (Red Lock)
- 描述:基于 Redis 官方 Redlock 算法,解决单机或主从异步复制导致的锁丢失问题。
- 特性 :
- 在多个独立 Redis 节点上加锁。
- 大多数节点加锁成功才算最终成功。
- 代码示例:
java
RLock lock1 = redisson.getLock("redlock1");
RLock lock2 = redisson.getLock("redlock2");
RLock redLock = redisson.getRedLock(lock1, lock2);
redLock.lock(); - 信号量 (Semaphore) & 可过期信号量
- 描述:用于分布式限流、控制并发数。
- 特性 :
- 控制同时访问资源的线程数量。
- 支持过期时间,防止资源一直占用。
- 代码示例:
java
RSemaphore semaphore = redisson.getSemaphore("semaphore");
semaphore.acquire(); // 获取许可
semaphore.release(); // 释放许可 - 闭锁 (CountDownLatch)
- 描述:分布式环境下等待一批任务完成。
- 特性 :
- 类似于 Java 的
CountDownLatch,但支持跨 JVM 同步。 - 用于等待多个分布式节点完成操作。
- 类似于 Java 的
- 代码示例:
java
RCountDownLatch latch = redisson.getCountDownLatch("latch");
latch.trySetCount(5);
latch.countDown(); // 任务完成计数减1
latch.await(); // 等待计数归零 示例:
xml
<!-- Redisson 分布式锁 -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.32.0</version>
</dependency>
yaml
spring:
redis:
host: localhost
port: 6379
# password: 你的密码
database: 0
java
@Autowired
private RedissonClient redissonClient;
public void handleBusiness() {
// 1. 获取锁对象
// 多个线程使用相同的 key 会竞争同一把锁
RLock lock = redissonClient.getLock("lock:business:key");
try {
// 2. 尝试加锁
// waitTime: 抢锁等待时间(单位秒)。如果在该时间内未获取到锁,则放弃,返回 false。
// leaseTime: 锁自动过期时间(单位秒)。如果在该时间内未解锁,锁会自动释放,防止死锁。
// 注意:如果 leaseTime 不设置,Redisson 会启动看门狗(Watchdog)自动续期(默认30秒)。
boolean lockSuccess = lock.tryLock(5, 30, TimeUnit.SECONDS);
if (!lockSuccess) {
// 3. 抢锁失败处理
System.out.println("抢锁失败,稍后重试");
return; // 或者抛出异常,根据业务需求决定
}
// ===================== 加锁成功,执行业务 =====================
// 建议:这里可以再加一层 try-catch,防止业务异常导致无法执行 finally 中的解锁逻辑
try {
System.out.println("业务执行中...");
// 模拟业务处理耗时
Thread.sleep(1000);
} catch (Exception e) {
System.err.println("业务执行异常: " + e.getMessage());
// 这里可以根据需要进行回滚或其他处理
throw e; // 重新抛出异常,让上层感知
}
} catch (InterruptedException e) {
// 4. 等待锁期间被中断
Thread.currentThread().interrupt(); // 恢复中断状态
System.err.println("获取锁等待过程中被中断");
} finally {
// 5. 解锁(必须放 finally)
// 只有当当前线程持有该锁时,才执行解锁操作,避免误解其他线程的锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
System.out.println("锁已释放");
}
}
} 有效期问题怎么解决的:用WatchDog机制,每1/3有效期自动给锁续期一次
锁的重入问题怎么解决:底层用了hash结构,key是锁名称,field是锁的持有者,value是重入次数。获取锁成功一次,次数+1;释放一次锁,次数-1
锁操作的原子性问题:底层使用LUA脚本操作Redis,是原子性的
Redis主从集群时锁丢失问题:可以使用Redisson的红锁RedLock实现