
⚙️ PostgreSQL技术文章
🧩 2026年6月至7月黑客工作坊

Robert Haas 宣布将在 2026 年 6 月/7 月举办 PostgreSQL 技术研讨会,邀请 Melanie Plageman 分享她关于"PostgreSQL 中 pg_stat_io 的额外 IO 可观测性"的议题。由于 pgconf.dev 会议后的疲劳,原定的每月例行研讨会有所推迟。本次会议将重点讨论 PostgreSQL 通过 pg...
🧩 Autobase2.8.0版本发布

Autobase 2.8.0 推出了重要变化,将产品分为两个版本。Community Edition 延续现有的开源 MIT 许可版本,适合个人开发者和业余项目使用。新增的 Enterprise Edition 是商业版本,专为需要在生产环境中集中管理 PostgreSQL、运营控制、治理、可扩展性和技术支持的企业设计。Autobase Enterpris...
🧩 工程日历:被忽视的数据库账单

这篇文章指出,数据库基础设施的成本不仅体现在云服务账单上,还包括"日程债务"------工程师在数据库维护上花费的重复性时间。对于高负载的PostgreSQL工作场景,这表现为持续的分区管理、autovacuum调优、复制监控和容量规划,可能占用资深工程师20-30%的时间。作者建议进行90天的日程审计,追踪与数据库相关的故障、会议和维护任务。随着数据量从百万级增...
📨 PostgreSQL Hacker 电子邮件讨论精选
🧩 提案:逻辑复制的冲突日志历史表
讨论集中在为PostgreSQL逻辑复制实现冲突日志历史表功能。Dilip Kumar发布了v44补丁,整合了包括Nisha、Amit和Vignesh在内多位审阅者的反馈。主要变更包括为新的pg_subscription列授予公共访问权限,使用适当的常量而非硬编码值,为清晰性重命名函数,以及合并补丁以简化审查流程。 Peter Smith对conflict...
🌐 社交媒体动态
🧩 全球线上参与数据AI峰会,6月16-17日免费虚拟体验
数据AI峰会将在6月16-17日举办免费的线上活动,全球用户均可参与。虚拟会议包含完整的主题演讲和精选会议环节,独家在线培训课程,峰会直播期间的专家解读,以及会后的点播回看功能。用户可通过在线注册参与这一全球性远程峰会。
🧩 应用开发应该更快速
来自 Databricks 的 Andre Landgraf 和来自 Cursor 的 Kevin Niparko 演示了如何在 Databricks 上构建和部署生产级应用。演示展示了如何利用内置治理功能和无服务器 Postgres 来避免基础设施管理拖慢开发进度。主要功能包括实时原型开发和迭代、事务数据的分支管理和扩展、通过单点登录和身份验证实现安全的...
🧩 分区一直是标准数据布局方法,但现代湖仓工作负载需要更灵活的方案
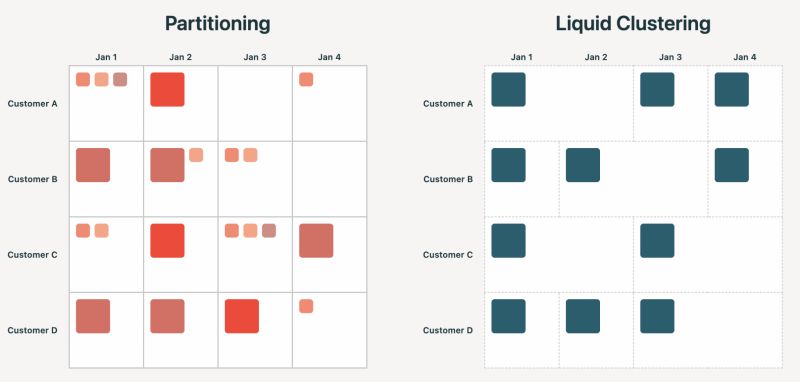
传统数据分区作为数据布局的标准方法正面临现代湖仓工作负载的挑战,这些工作负载需要更高的灵活性。由于八个常见误区的限制,越来越多的组织开始摆脱传统分区方法。液态聚类作为替代方案应运而生,在大规模场景下提供更好的性能、存储效率和数据新鲜度。使用液态聚类的PB级客户反馈显示,相比传统分区方法,查询速度更快、写入吞吐量更高、小文件问题更少,同时实现了更高效的存储和...